Juha Hakala
Helsinki University Library
With contributions from:
Preben Hansen
Swedish Institute of Computer Science
Ole Husby
BIBSYS
Traugott Koch
Lund University Library, NetLab
Susanne Thorborg
Danish Library Center
July 1998
Helsinki University Library
ISBN 951-45-8248-9
Metadata has rapidly become a hot topic among librarians and other information workers. The emergence of the Internet as an important IR tool has also fostered general awareness of serious problems associated with Internet information retrieval, of which massive recall, coupled with an equal lack of precision, is arguably the worst one.
The creation of more and better metadata – structured resource descriptions either embedded into documents themselves or external to them - is generally regarded as the best means to improve the current situation. Many specialists believe that any metadata is better than no metadata at all - we do not need to stick with the stringent quality requirements and complex formats of library catalogue systems. Instead, it is possible to live with something simple, which will be easily understandable to publishers, authors and other people involved with the publishing of electronic documents.
During the last two years it has become obvious that the most viable solution for Internet resource description is the Dublin Core Metadata Element Set, or just the Dublin Core. The number of projects building tools based on the Dublin Core has risen sharply, and there is already a significant number of documents in the Web which contain their own description in the Dublin Core.
However, back in 1996 it was not obvious that the Dublin Core would be a major success. In spite of this, The Nordic Council for Scientific Information, NORDINFO (
http://www.nordinfo.helsinki.fi) had the vision to support the Nordic metadata project (http://linnea.helsinki.fi/meta). It was the first international project, which made the choice of building Dublin Core –based tools.Fifty percent of the project funding, enough to cover 12 months of work came from NORDINFO, and the rest from participating organisations in the form of work. In practice, more than 24 months of work has been done thanks to liaison with other initiatives, and the project is therefore able to deliver more than was originally promised.
Having been one of the Dublin Core pioneers has been a somewhat mixed blessing to the project. The Nordic metadata project has become well-known all over the world, perhaps more so than any other NORDINFO project in the past - we have attracted visitors even from Australia. On the other hand, the steady and still continuing progress of the Dublin Core has forced the project to constantly modify the tools earlier made available. This has been possible because the project partners were involved in other metadata projects such as EVA - the acquisition and archiving of electronic network publications (
http://renki.helsinki.fi/eva/english.html), the Nordic Web Index (http://nwi.ub2.lu.se/?lang=en) and SAFARI (http://safari.hsv.se), which took the Nordic metadata tools and developed them according to their own needs. Many of the resulting new services were later incorporated into the basic product.Like the Dublin Core, our tools now have solid kernel functionality that will not be radically altered. These tools – especially the metadata template but also metadata harvesting and indexing software and URN generator – are in widespread use. This indicates that the project has been not only a media success, but also a technological success.
The following organisations and people were involved in the project:
|
Project participants |
|
|
Bibsys, Norway |
Ole Husby |
|
The Danish Library Center, Denmark |
Susanne Thorborg |
|
Helsinki University Library, Finland |
Juha Hakala |
|
Lund University Library, NetLab, Sweden |
Traugott Koch |
|
Munksgaard, Denmark |
Anders Geertsen |
|
The National and University Library of Iceland, Iceland |
Sigbergur Fridriksson |
|
The Swedish Institute of Computer Science, Sweden |
Preben Hansen |
The project manager and the main author of this report was Juha Hakala, who originated the idea for the project. Two other key people who strongly influenced the content of the project plan were Ole Husby and Traugott Koch. This trio attended, with NORDINFO’s funding, the second Dublin Core workshop in Warwick, UK (see
http://purl.oclc.org/oclc/rsch/metadataII). This workshop was in many ways the starting point for the Nordic metadata project, and marked the beginning of the active Nordic involvement in the development of the Dublin Core Metadata Element Set.Participating organisations are very well known on the Nordic library scene. Since an international audience may be familiar with these organisations, they are described below.
Bibsys (
http://www.bibsys.no) is a Norwegian library system and union catalogue of a large number of Norwegian research libraries. Bibsys personnel has been involved in a number of European development projects, including the classic Z39.50 projects Nordic SR Net and OPAC Network in Europe, ONE (http://www.dbc.dk/ONE/oneweb/). Bibsys maintains the Norwegian national Nordic Web Index database.The Danish Library Center, DBC (
http://www.dbc.dk/english/default.html) maintains the Danish national union catalogue, DANBIB. In addition to the national union catalogue DBC produces and maintains the Danish national bibliography database in co-operation with the Danish national library. DBC has been involved in many domestic and international projects in the area of library automation including the OPAC Network in Europe -project. In the Nordic metadata project DBC was an associated partner. DBC was not a member in the project group initially, but joined it when it became obvious that DBC’s InDoReg (http://purl.dk/rapport/html.uk/) project could use the tools developed by the Nordic metadata project.Helsinki University Library (
http://linnea.helsinki.fi/hyk/hul/) is the national library of Finland. Its Library Network Services Department is responsible of planning and co-ordinating library automation efforts in Finnish academic and research libraries. The department is involved in a number of domestic and EU projects, including ONE-2 and NEDLIB (http://www.konbib.nl/nedlib/).Lund University Library, NetLab (
http://www.lub.lu.se/netlab/) is well known in the field of library automation not only in Scandinavia, but also elsewhere in Europe for its pioneering work in e.g. Web harvesting and indexing. NetLab has participated in numerous projects such as DESIRE. In the Nordic metadata project NetLab had a key role, as they developed both the metadata template and the functionality in Nordic Web Index needed for metadata harvesting and indexing. NetLab has also programmed the URN generator, which was specified by the Helsinki University Library.Munksgaard (
http://www.munksgaard.dk) is a major Danish scientific publisher, which has been one of the pioneers in electronic publishing in Scandinavia. Unfortunately, they could not participate in the project as actively as intended. The role of the Munksgaard was to provide documents with embedded Dublin core metadata; in practice this work has been carried out by volunteers.The National and University Library of Iceland (
http://bok.hi.is) has a key position in Icelandic library automation. The library has been involved in several national, Nordic and international library IT initiatives. It maintains the national NWI database.The Swedish Institute of Computer Science (
http://www.sics.se) is a non-profit research foundation funded by the Swedish National Board for Technical and Industrial Development (NUTEK) and by a group of companies.The Nordic metadata project has been an excellent example of Nordic co-operation. Expert organisations from all Nordic countries co-operated in order to solve a set of common problems and provide new kinds of services suitable for all of them (and also for users outside Scandinavia). The project has enabled the Nordic countries to show a unified front to the international Dublin Core community. As a single unit we are an important pressure group, which has been able to influence the Dublin Core development work.
The applications developed in the project are being actively used in Scandinavian countries in national or regional metadata initiatives. Therefore, the Nordic metadata project, in spite of its significant experimental aspects, has also been a fruitful initiative from the practical point of view. This was of course one of our aims from the very beginning, but the extent to which we have attracted partners has been most pleasing.
The project group is very satisfied with the results we have achieved. Therefore it is not surprising that all project partners, except for Munksgaard, are willing to participate in a follow-up project, if it receives funding from NORDINFO. All the participants have found the project very useful, and wish to continue the work that is now well under way. We believe that metadata in general, and the Dublin Core in particular, will in the future be of vital importance. This fact has already been officially recognised in some countries. In Denmark and Finland the Dublin Core is the metadata format for public documents published by state and local governmental bodies; at least in Finland the decision to use the Dublin Core was influenced by the Nordic metadata.
Other Nordic countries may in the future follow the example set by Denmark and Finland, since the Dublin Core fits ideally for the purpose, and there is no competition in sight. This will not happen automatically, though: the Dublin Core needs to be advertised, and there must be new projects to enhance existing Dublin Core tools and develop new ones.
In a few years time there will be thousands of authors and publishers providing metadata in Dublin Core and local formats based on it. It is important to support metadata creation with user guides and appropriate tools. The resulting metadata must be properly indexed to motivate the providers to do the job properly. The experience from the Nordic metadata has shown that the applications and documentation required for Dublin Core production and use can be developed very effectively in international co-operation, and then adapted according to the local needs for national and regional projects.
The Nordic metadata project plan (
http://linnea.helsinki.fi/meta/projplan.html) was written shortly after the 2nd Dublin Core Metadata Workshop in spring 1996. Since then things have changed a lot, but the main aim of the project as written into the project plan is still valid:The Nordic Metadata Project will create a Nordic Metadata production, indexing and retrieval environment. This system is not intended for test use only, but primarily for production purposes.
From this basic aim a few subtasks were derived:
The results of tasks 3, 4 and 5 together form what can be called a Dublin Core toolbox. The toolbox will be discussed in chapter 2. We believe that a freely available Dublin Core toolbox such as the one built in this project is highly relevant to implementors of metadata applications, since the same tools can be applied everywhere with slight modifications.
In chapter 2 we will also cover the feedback collected from the users of the metadata template and user guide. Tasks 1 and 2 from the list above will be discussed later in this chapter. Documentation and project management is covered in chapter 3. Chapter 1.3 contains a description of the Dublin Core, without which it would be more difficult to understand the choices made in the project.
As a whole the project has followed the original guidelines quite well. There has been no need to change the basic aim of the project – building tools needed for a complete metadata utilisation environment. Developments elsewhere or in the project itself have not made it unnecessary to maintain and further develop a Nordic Dublin Core tool set. On the contrary – it is our belief that high-quality domestic services in this area are important. One should not rely on international tools that cannot be modified according to local requirements. Nordic services that can be easily parametrised to satisfy local needs in each country are a good choice for us.
The original project plan did not propose the creation of a metadata template, but it became clear to us very early that such a tool must be built to enable users to provide high quality metadata. Another change motivated by our aim to serve users better was the replacement of the Dublin Core test database with national metadata databases, which are a production service where Dublin Core records are only a fraction of all metadata available for searching.
As the project has built vital national services, long-time maintenance of our metadata utilisation tools must be guaranteed by some means. It is not acceptable that routine maintenance of for instance metadata databases is dependent on project money from NORDINFO or other agencies primarily funding library IT-related research and development. We propose that the national libraries and other organisations, which maintain national services and having national responsibilities should accept their responsibilities in guaranteeing the long-time availability of national library IT services. This can be realised by a) direct funding from these organisations and b) acceptance of responsibility for the service. This does not necessarily mean that the national library should maintain the service itself; it can nominate another organisation for the job.
As an interim solution we propose a follow-up project, Nordic Metadata II, which will improve and stabilise the tools of the previous projects so that it will be easy to take them into production.
Back in 1996 the Dublin Core Metadata Element Set was in the early stages of development. Therefore, a project dealing with metadata had to evaluate the choices available. Fortunately the project DESIRE published a report "A review of metadata: a survey of current resource description formats" (
http://www.ukoln.ac.uk/metadata/desire/overview/) in autumn 1996. The principal authors were Rachel Heery and Lorcan Dempsey, assisted by e.g. Traugott Koch who was also a member of the Nordic metadata team, so we were well aware of the work being done in DESIRE. The review document was of course up to date at the time of publication, and some format analyses have been modernised since the original publication. For instance, the Dublin Core evaluation was updated in May 1997 (which means that it was unfortunately out of date by May 1998). In general, the report is of such a high quality that there was no need to duplicate a similar effort in the Nordic metadata project.The report covers the following formats:
BibTexThis coverage was more than enough for the purposes of the Nordic metadata, since the only candidates we had seriously discussed in the planning stage were IAFA/whois++ Templates and the Dublin Core. The reason for this selectivity was that we did not want to choose a domain specific format like MARC. In 1996 IAFA Templates were fairly popular, but since then they have become much less used.
One of the conclusions of the report was that the Dublin Core is a good choice for a metadata format. This result was also reached by the BIBLINK (
http://hosted.ukoln.ac.uk/biblink/) project, which aims to establish a relationship between national bibliographic agencies and publishers of electronic material, in order to establish authoritative bibliographic information that will benefit both sectors. In the conclusion of the BIBLINK metadata report (http://hosted.ukoln.ac.uk/biblink/wp1/d1.1/) there is the following statement:In order to encompass the diverse range of publishers and material involved in the process, the use of a minimum set of data is attractive. If we are looking towards use of a core set then the Dublin Core element set is an obvious choice. There is international involvement in the consensus building, and project participants could influence the development of the format. It is a format that small publishers and web publishers could use without incurring significant overhead.
Let us take a closer look on our chosen format, the Dublin Core Metadata Element Set.
According to the Dublin Core homepage (
http://purl.oclc.org/metadata/dublin_core/) it isa 15-element metadata element set intended to facilitate discovery of electronic resources. Originally conceived for author-generated description of Web resources, it has also attracted the attention of formal resource description communities such as museums and libraries.
The Dublin Core has been developed by an informal group of librarians, networking people and content specialists. Since its creation in March 1995 in what is now called the first Dublin Core Metadata workshop (see
http://www.oclc.org:5046/oclc/research/conferences/metadata/), the Dublin Core has rapidly gained popularity as the format for describing document-like objects in the Web. The format discussion takes place over a mailing list which already in the winter of 1997/1998 had more than 700 readers. There are a number of projects using Dublin Core -see project lists at http://purl.oclc.org/metadata/dublin_core/projects.html and http://renki.lib.helsinki.fi/meta/projects.html.The kernel group of developers – 60-80 people - meets approximately twice a year in invitational Dublin Core metadata workshops. In these meetings the participants discuss and – when consensus is reached - approve solutions to major issues concerning the format and its development. One factor that may slow down the development a bit, but very likely contributes to the quality of the final result is that there are a lot of different interest groups represented in the DC group: librarians, Internet specialists, museum and archive people, and so on.
Several members of the Nordic metadata project team have participated actively in the Dublin Core meetings since the 2nd workshop held in Warwick, UK. The latest DC workshop – number five in the series - was held in Helsinki, Finland in October 1997 (see
http://linnea.helsinki.fi/meta/DC5.html) and the DC-4 in Canberra, Australia in March 1997 (see http://www.dstc.edu.au/DC4/).It has been agreed that the 6th workshop will be arranged in Washington, DC in the autumn of 1998. By then there will definitely be an Internet standard (so called Request for Comments) which defines the kernel of the Dublin Core, since consensus of the Core has been reached already. A draft of this document, called Dublin Core Metadata for Simple Resource Discovery: An introduction to the Dublin Core and a description of the semantics of the 15-element Dublin Core element set without qualifiers is already available at
ftp://ftp.ietf.org/internet-drafts/draft-kunze-dc-02.txt. Publication of the RFC is very likely to happen soon, as the Dublin Core community was in May 1998 about to submit the document to the IESG as a proposed RFC. The official DC standard will clarify the format’s currently somewhat unclear status among the actual and potential user communities, and encourage new investments in Dublin Core –based systems.According to the Internet draft,
The goals that motivate the Dublin Core effort are:
- Simplicity of creation and maintenance
- Commonly understood semantics
- International scope and applicability
- Extensibility
- Interoperability among collections and indexing systems
These goals are not necessarily very easy to attain, since
These requirements work at cross purposes to some degree, but all are desirable goals. Much of the effort of the Workshop Series has been directed at minimizing the tensions among these goals.
The tensions apparent in the aims are also transported into the projects using Dublin Core. For instance, one can develop a very simple Dublin Core template, or a complex one, which supports not only the full set of elements, but also a large number of element qualifiers. The Nordic metadata project has chosen to travel in the middle of the road in this respect. We have built for instance both a simple and a full featured template and two sets of user guides, since we wanted to give a good service to all kinds of users and – for experimental purposes – see if our users are really capable of providing full DC records.
The 1st RFC will define just the nucleus of the Dublin Core. There will be a few other RFC’s, which will standardise aspects of Dublin Core outside the actual core:
1. Encoding Dublin Core Metadata in HTML
A formal description of the convention for embedding unqualified Dublin Core metadata in an HTML file.
A non-formal specification for HTML 2.0 and 4.0 exists already; it would not have been possible to design the metadata template without it.
2. Qualified Dublin Core Metadata for Simple Resource Discovery
The principles of element qualification and the semantics of Dublin Core metadata when expressed with a recommended qualifier set known as the Canberra Qualifiers.
3. Encoding Qualified Dublin Core Metadata in HTML
A formal description of the convention for embedding qualified Dublin Core metadata in an HTML file.
4. The Dublin Core on the Web: RDF Compliance and DC Extensions
A formal description for encoding Dublin Core metadata with qualifiers in RDF (Resource Description Framework) compliant metadata, and how to extend the core element set.
Creating these documents will take some time as there are many stakeholders involved in the development process, and they do not always have the same interests. Finding compromises that work well is time consuming. Anyway, the better the design is done, the easier it will be to use the format.
The Nordic Metadata project has published two articles, which describe the development of the Dublin Core since 1996. See Juha Hakala’s "Dublin Core in 1997: A report from Dublin Core metadata workshops 4 & 5" (
http://linnea.helsinki.fi/meta/dcnord.html) and Traugott Koch’s "Warwick framework and Dublin core set provide acomprehensive infrastructure for network resource description" (
http://www.ub2.lu.se/tk/warwick.html) for more details. The official final report of the Helsinki workshop is (Weibel 98); it covers not only what happened in Helsinki but also developments since the Helsinki meeting up to February 1998. One of the results of the Helsinki meeting was the establishing of subject-specific groups, each of which concentrates on a certain problem or issue. One group is developing an international Dublin Core user guide for the non-qualified Dublin Core. As of now (June 1998) the latest user guide version was 5 (http://renki.lib.helsinki.fi/meta/UserGuide5.html). The group was confident that it had almost finished its task.The 10 working groups and the documentation they have provided are listed at
http://purl.oclc.org/metadata/dublin_core/work_groups.html.From 1995 to 1997 there was no official Dublin Core maintenance organisation. In 1998 the Online Computer Library Center (OCLC;
http://www.oclc.org) will become the Dublin Core Directorate; in practice this means that the OCLC is officially maintaining the Dublin Core. Senior research scientist Stuart Weibel from the OCLC is commonly regarded as the father of the Dublin Core in the DC community; certainly his personal devotion is one of the reasons why the Dublin Core has been such a success.Dublin Core workshops are not the only fora in which Dublin Core is being developed, although the workshop does have the final power to approve new features. In order to foster Dublin Core development, a decision has been made to form the Dublin Core Policy Advisory Committee and Dublin Core Technical Advisory Committee. Traugott Koch is a member in the former committee. During 1998 Traugott will be working in the OCLC, where he can closely follow Dublin Core and RDF development efforts and participate in this work.
Juha Hakala and Sigfrid Lundberg from the Lund University Library, NetLab unit represent Nordic interests in the Technical Advisory Committee. Sigfrid has been closely involved in the Nordic metadata project as a developer of the Nordic Web Index. Another important Dublin Core -related group is the joint NSF/ERCIM working group on metadata, where Ole Husby represents the Nordic metadata project.
The Dublin Core is designed to be usable by non-cataloguers as well as by those with previous experience with formal resource description models. This is one of the basic aims of the whole Dublin Core initiative: as libraries do not have resources for describing even the most relevant Web documents, it is necessary to build tools with which anyone can create metadata for his or her documents. The basic requirement is of course an easy-to-use format for resource description. MARC, and its underlying standard for bibliographic description, are definitely not easy enough to learn and use. On the contrary, the feedback we have received from our users (see chapter 2.5) indicates that the Dublin Core is easy to understand and utilise.
Many of the existing metadata formats have been built for a limited user community. A well-known example of this is MARC, which is used almost solely by the library community. The Dublin Core does not have this limitation – it is totally generic. However, because the format was developed by librarians and network specialists, it owes a lot to the library community. As the homepage says, the Dublin Core elements have a commonly understood semantics that represents what might be described as roughly equivalent to a (library) catalogue card for electronic resources.
In the early stages of its development the Dublin Core had 13 elements. In 1996 two more were added, so the final figure is now 15. Final means final, as a firm decision has been made to prevent further "element creep". Should somebody need to include a local element into an otherwise pure Dublin Core record, it has been decided that local DC elements should begin with "X-". The Nordic metadata project has not implemented local elements, but many of the domestic projects using Nordic metadata tools have added them according to their needs.
An interesting variant of the Dublin Core is under construction in the European Union’s BIBLINK project (
http://hosted.ukoln.ac.uk/biblink). The project has developed a Dublin Core superset, which enables the publisher to send to the national library a resource description that contains most elements needed in national bibliography cataloguing. This is a proof of the statement that although the Dublin Core is simple, this simplicity is deceptive in the sense that with qualifiers one may build a format, which surpasses MARC in complexity. The BIBLINK Core will be utilised also by another EU project, Networked European Deposit Library (NEDLIB; http://www.konbib.nl/nedlib).The normative description of Dublin Core is available at
http://purl.oclc.org/metadata/dublin_core/. The description is included as the Annex 1 of this report.During the Nordic metadata project the Dublin Core has been translated and published in Finnish (
http://linnea.helsinki.fi/meta/dcref-fin.html) and Norwegian (http://www.bibsys.no/meta/dc/dcref.html).Unofficial translations have been made to Swedish and Danish, and an Icelandic version is under preparation. National versions of Dublin Core are of vital importance, as they make the format easier to understand and use for domestic users. Many of the early users in Finland felt that the absence of a national Dublin Core version was a problem, although English is commonly spoken in Finland.
1.3.1 Dublin Core qualifiers
In addition to the 15 elements Dublin Core contains Language, Scheme and Type qualifiers. It has been difficult to come up with a universally acceptable core set of qualifiers. As of yet there is no authoritative list of qualifiers, although we have agreed on principles how to develop them. The basic axiom is that the (Type) qualifier must narrow the semantics of the element. Due to heavy pressure from the implementor's side – including the Nordic metadata project - this principle has already been loosened up a little - it is possible to provide the author's mail address in the Creator element.
If somebody needs to include a local element qualifier into an otherwise pure Dublin Core record, it has been decided that all local qualifiers should begin with "X-". The Nordic metadata project has implemented one such qualifier, Date.X-MetadataLastModified. This is a variant of the Date element that contains the date when the metadata record itself was last changed. This information may be very useful when updating the metadata database.
Language
Language qualifier specifies the language of the element value. If the actual document is written in English this can be pointed out in the Language element. With the language qualifier one can specify the language of data in for instance Subject, Title and Description tags. For instance, if subject terms are provided in English, Finnish and Swedish, this may be specified by using a Language qualifier in each Subject tag. Coupled with useful internationalisation features in HTML 4.0 like <HTML lang="en">, language qualifier will greatly enhance the capabilities of Web indexes to locate and index documents in different languages.
Scheme
Stu Weibel has defined scheme as "A formal data content standard or encoding standard with an authoritative maintenance agency". Common examples would be for instance MeSH, UDC and the ISO-8601 profile for encoding date information. The scheme qualifier specifies a context for the interpretation of a given element. Typically this will be a reference to an externally defined scheme or accepted standard. For example, a SUBJECT field might be SCHEME-qualified as YSA data (Finnish General Subject Headings List). If no scheme has been given even if it should be used (data in Date cannot be interpreted without a scheme) the Dublin Core community has agreed on defaults; for Date it is ISO 8601. By the way - the default used to be the American ANSI standard for dates, but this was changed after requests from non-American implementors, who have become an important pressure group in the DC community.
The Nordic metadata project collected a list of national subject headings lists and classifications commonly used in Nordic countries and fixed scheme names for them. These names are automatically given by the metadata template during the record creation process, on the basis of the choices users make in pull-down menus. If no choice is made, the default value is the one agreed on internationally. For date, the template shows an example of the correct syntax.
There are cases in which the scheme qualifier is critical to the use of the field. For instance, scheme is needed for the interpretation of a date. Unambiguous parsing of a date requires knowledge of the encoding standard (i.e. scheme) used in the expression of the content - does the string 1997-10-07 specify the tenth day of July or the seventh day of October (Weibel 97b)? In the same way, classifications put into the Subject tag must be specified with scheme, since otherwise a number like 681.03.06 will not make sense to an application trying to parse it. If the scheme tells the application that this is UDC notation, "understanding" it will be easy.
From an author's point of view Date is rather unproblematic, provided that there are tools available that support data input by generating the required HTML syntax. Subject is far more complicated, since controlled vocabularies used for content description are usually not available in the Web. We can not assume that authors and publishers will obtain SAB or UDC; instead, these systems must be put on-line and linked to metadata templates. From the IR point of view, it is very important that metadata contains not only decent bibliographic data, but also high-quality content descriptions made with controlled terms. Because of this, the metadata creator built in the Nordic metadata project maximises subject scheme support by linking directly to all Web accessible classifications and subject headings lists (see the metadata template's Subject help page, available at
http://www.ub.lu.se/metadata/subject-help.html).Type
The type qualifier specifies a facet of a given field. The official intent of a type qualifier is to narrow the semantics of an element. Another way of looking at the type is as a sub-element name; a type qualifier modifies the element name, not the content of the element field. In practice – and this has caused some headaches in format development – widely used Types do not always narrow the semantics. A good example of this is the qualifier Address for Creator element. This kind of "corruption" has been accepted because it is useful and widely implemented.
The Dublin Core community is as of now creating a core set of qualifiers, which should be understood by all Dublin Core –based systems. An early stage (autumn 1997) of this work is documented in Rebecca Guenther’s text Dublin Core Qualifiers/Substructure, available at
http://lcweb.loc.gov/marc/dcqualif.html. This text is included as Annex 2 of this report.Without qualifiers the Dublin Core would be a very simple and rigid metadata format. Due to extensive usage of qualifiers the Dublin Core is a flexible system which allows users to provide either very simple or extremely thorough resource descriptions, depending on the time and personnel resources available for the job. The problem with qualifiers is that they will, to some extent, limit interoperability between Dublin Core applications. Few systems outside Finland will support Subject Scheme "YSA", for Finnish General Subject Headings. But all well built Dublin Core applications will behave gracefully when meeting a qualifier they cannot process.
1.3.2 Dublin Core Syntax
Dublin Core metadata is usually embedded into the described object itself. Of course the Dublin Core can also be used as external metadata. This is important for e.g. the museum community, which wants to describe museum objects with the Dublin Core.
If metadata is embedded into the described resource, there must be a Dublin Core syntax for that document format. As of this writing the Dublin Core syntax has been defined for HTML 2.0 and 4.0 (see Syntactic Considerations for the Dublin Core, available at
http://purl.oclc.org/metadata/dublin_core/syntax.html). Concentration on HTML is understandable for two reasons: first, most Web documents have been written in HTML, and second, HTML allows for efficient coding of Dublin Core data, contrary to some other text formats.Below is an example of a Dublin Core record coded in HTML 4.0:
<META NAME="DC.Title" CONTENT="URN-tunnusten generointiohjelma. Opaste">
<META NAME="DC.Title" LANG="en" CONTENT="URN-generator. User guide">
<META NAME="DC.Creator.PersonalName" CONTENT="Hakala, Juha">
<META NAME="DC.Creator.PersonalName.Address" CONTENT="juha.hakala@helsinki.fi">
<META NAME="DC.Subject" CONTENT="elektroniset julkaisut">
<META NAME="DC.Subject" CONTENT="Uniform Resource Name">
<META NAME="DC.Subject" CONTENT="julkaisujen identifiointi">
<META NAME="DC.Subject" LANG="en" CONTENT="identification of publications">
<META NAME="DC.Publisher" CONTENT="Helsingin yliopiston kirjasto">
<META NAME="DC.Contributor.PersonalName" CONTENT="Koch, Traugott">
<META NAME="DC.Date" SCHEME="ISO8601" CONTENT="1998-05-03">
<META NAME="DC.Type" CONTENT="Text">
<META NAME="DC.Format" SCHEME="IMT" CONTENT="text/html">
<META NAME="DC.Identifier" CONTENT="http://linnea.helsinki.fi/meta/URN-opas.html">
<META NAME="DC.Identifier" SCHEME="URN" CONTENT="URN:NBN:fi-fe976201">
<META NAME="DC.Language" SCHEME="ISO639-1" CONTENT="fi">
<META NAME="DC.Coverage.PlaceName" CONTENT="Finland">
<META NAME="DC.Date.X-MetadataLastModified" SCHEME="ISO8601" CONTENT="1998-04-22">
Although the Dublin Core is a simple format, it does not mean that Dublin Core syntax for HTML or any other document format is simple. Complexity is required to allow extraction and correct interpretation of data by harvesting applications.
In the case of HTML, the META tag of the HEAD is used. In the recommended syntax, META NAME section tells us the format used (DC = Dublin Core) and the Dublin Core element. If Type qualifiers are used, they are added to the element name separated by dots. Creator.PersonalName indicates that the author of the document is a person, not an organisation. The actual data is put into the "CONTENT" section.
The prefix "DC." indicates that the metadata in this META tag is encoded according to the Dublin Core. The prefix allows users to embed data in many metadata formats into the same HTML head. Applications looking for Dublin Core data such as metadata harvesters and DC to MARC converters will be able to find relevant metadata from the document HEAD.
HTML 4.0 allows easy coding of Language and Scheme qualifiers. LANG="en" in the last repeat of the Subject element tells that the language of the subject term is English. Scheme qualifier is used in the example record for example to tell us that the latter Identifier element contains the Uniform Resource Name of this document.
Due to complexity of the Dublin Core HTML syntax it is necessary to build tools with which the potential authors can create Dublin Core metadata as easily as possible. This is the reason why the Nordic metadata project developed its metadata template, which is described in chapter 2.1. Our template – and other templates – can create the required HTML syntax, and allows the user to concentrate on the content.
The syntax shown above is the one that can be used to express Dublin Core data in HTML 4.0. The HTML 2.0 syntax is quite different, since in HTML 2.0 Language and Scheme are coded into the CONTENT part of the META tag. The resulting data is less neat, but still readable for humans and Web indexing applications. The fact that the Dublin Core community was able to influence the development of HTML 4.0 proves that Dublin Core holds an important status in Web developments in general.
It is also possible to encode Dublin Core –like metadata into the META tag in the simple form that can be understood by Alta Vista. Many of the details shown above will be lost, but all the data left will be available for searching via Alta Vista now. One may argue that this is necessary, because Alta Vista will support the Dublin Core in the future. Of course we hope that this will happen, and in the light of recent developments with RDF and XML (see below) it is quite likely that Alta Vista and other Web indexes will support the Dublin Core. But it may still take a while until there is enough Dublin Core data in the Web to convince the Alta Vista maintainers to improve the application. In the interim, simple Alta Vista –like syntax will be the only way of making one’s document more visible. Of course, DC record and Alta Vista –metadata can coexist in the same HTML document.
The next document format that will get its own Dublin Core syntax will probably be the Extensible Markup Language, XML (see
http://www.w3.org/XML/). In this context, Resource Description Framework (http://www.w3.org/RDF) deserves a mention as well. RDF is a formal structure for metadata systems, which uses XML as its syntax. Metadata with Dublin Core semantics will in the future be presented using the RDF structure and XML syntax. For more information about RDF and its use, see (Miller).An initial RDF schema for the simple Dublin Core Element Set is available at
http://www.w3.org/TR/WD-rdf-schema/. Many specialists believe that the RDF will be the "Trojan horse" with which the Dublin Core will be made popular in the Web. They may be correct, since as of this writing it seems that tools which support RDF will be ubiquitous in the Web – Netscape and Microsoft intend to add RDF support to the next major releases of their WWW browsers and servers.The Dublin Core community has also discussed defining syntax for a commonly used image formats such as TIFF. Unfortunately, there has not been much progress in this area since the 3rd Dublin Core workshop, which concentrated on the description of images with the Dublin Core.
Summary
During the lifetime of the Nordic metadata project the Dublin Core Metadata Element Set has gained a strong status as the format for the description of document-like Internet objects. At the moment it does not have any serious rivals – if we do not take domain-specific formats such as MARC as competitors with the more generic Dublin Core. We do not see the relationship of Dublin Core and domain specific formats as a competitive one. On the contrary, due to its flexibility the Dublin Core is an ideal exchange format, which can enable us to pass bibliographic information from one community to another in the same way that we now can exchange data between library systems thanks to ISO 2709 Exchange format.
Since 1996, the Dublin Core community has agreed on the basic 15 elements and their semantics. Work to define core qualifiers is as of this writing still going on, but luckily most elements are quite unproblematic as regards their qualifiers – Source, Relation and Coverage are the ones that still need some work. Syntax for HTML 4.0 is also complete. This trinity – elements, their semantics and the Dublin Core syntax – enable implementors to build Dublin Core –based tools.
In order to enable users to provide Dublin Core records, one essential aspect is largely missing, namely cataloguing rules. There is no authoritative text, which says from where in publication one is allowed to fetch the author’s name, or defines how to put the name into the Creator tag ("last name, first name" or "first name last name"). This kind of information is currently provided via project specific user guides. These documents represent the project's view on Dublin Core cataloguing rules.
In the future the "global" situation will improve to some extent, since the common Dublin Core user guide (for the unqualified Dublin Core) will be published in the summer of 1998. But as metadata production and usage environments differ a lot, no single guide will ever satisfy all needs. All serious Dublin Core –based projects need to develop their own user guides – hopefully using the general guide as a basis for their efforts. If this is not done, interoperability between the projects will suffer, due to unnecessary local variations.
The Nordic metadata project has participated in Dublin Core development activities at many different levels. As early implementors the project team members have collected a considerable amount of knowledge on the Dublin Core and its use. This fact has been widely acknowledged by the Dublin Core developers. As mentioned above, many of the team members hold important positions in the Dublin Core community.
The most important international acknowledgement of the Nordic metadata project was the decision to arrange the 5th Dublin Core metadata workshop in Helsinki in October 1997. This meeting, which was hosted by the Helsinki University Library, provided us an excellent chance to foster Dublin Core development, not least by presenting the metadata-related work carried out in Nordic projects. In Helsinki several special interest groups were formed to continue work with open issues like user guides. Almost all the project team members have joined one or a few of these groups.
On a more detailed level, the Nordic metadata project has had a strong influence on how Dublin Core metadata is actually provided. For instance, it was decided that the preferred form for author names is the normalised one ("last name, first name"). One reason for this decision was the fact that our project supported this view strongly. We pointed out in discussions that this name form is superior for sorting of indexes and conversion from the Dublin Core to formats like MARC, which require normalised names.
The metadata toolbox is a set of tools, which enables users to create, harvest and index Dublin Core metadata, and to convert this data into MARC format. The tools are:
All these tools will be available in the public domain. We do have two requirements for the users of our tools. The Nordic metadata project should be acknowledged as the originator of the application. In addition, if a project using our tools adds functionality, which may be useful to other implementors, this module should be made available to us, so that it can be included to the main program.
As of this writing the Dublin Core to MARC converter and URN generator are unique applications – other metadata projects have not built anything similar. However, it can be safely assumed that MARC converters will be widely used in other Dublin Core projects. The URN generators may also become popular, but this depends on whether the national libraries start delivering URN’s. We were also the first ones to release a fully functional Dublin Core template (see chapter 2.1) and a national metadata database based on the automatic harvesting of metadata from Web documents (see chapter 2.2).
With the exception of the Nordic Web Index all our tools were developed from scratch. The project had no resources for developing its own Web harvesting and indexing application; we assumed from the very beginning that we could use the Nordic Web Index software. The development of the NWI system has been partly funded by NORDINFO, and a new active NWI development phase started in 1997 thanks to the NWI II project.
The NWI is in different position than the other tools, which the Nordic metadata project has developed. There are a lot of applications used for Web harvesting and indexing. However, the NWI differs from most Web indexes in that it is non-commercial. This means that the functionality is developed according to the users’ needs, not according to the advertisers’ requests. For instance, if we want the NWI to harvest and index URN’s (and we do need this feature), this feature can be easily built into the main program.
All tools built in the Nordic metadata can be used to provide national services. Therefore it is of utmost importance to organise future development and support of these tools and services based on them. Dependency on project money is in the long run not acceptable, although projects are the best methods for the initial development of this kind of services.
The national librarians of the Nordic countries discussed in a meeting in Reykjavik on 30th of April 1998 how to organise future development of the NWI, and guarantee the existence of databases built with the application. As of this writing it seems likely that the national libraries will take the NWI under their wing. If this decision is made, it will guarantee the future availability of NWI-based services.
The development of our other metadata tools should continue in the near future on project basis. The Dublin Core Metadata Element Set now has a solid core, but it is still developing in fringe areas. Changes in Dublin Core qualifiers and syntax have a major influence on all our tools. For instance, from the point of view of MARC conversion there is no difference if a piece of data is coded into Dublin Core on the element level or with a qualifier: in both cases the DC data will be mapped to a MARC tag.
It is possible that it will take about two years for the Dublin Core to be stable. Up to that point in time it may be necessary to do major revisions to the tools. A project offers the most effective way to carry this task out. On the other hand, no matter what happens with the Dublin Core the Nordic metadata project team has, due to our experience and evaluation work, a vision of how to make our tools more effective.
This and the following chapter were written by Traugott Koch and Juha Hakala.
Goal
Tools are the most important element of an infrastructure project together with advice and support. The Dublin Core and its HTML syntax are new to all kinds of users, including the individual end-users as well as the professional project administrators in the libraries. On the other hand, the Dublin Core HTML syntax was rather complicated to use and write. We realised early on, that we needed to offer a very easy to use and fast template to encourage people to produce metadata. We could not expect them to write the raw DC syntax code. Especially, end-users would never do this in large numbers without the support of a template. Neither did we expect the producers of HTML authoring software to offer full DC support anytime soon. Unfortunately, this assumption has proved to be correct. Having full Dublin Core support in widely used HTML editor or a normal text editor, which can produce HTML, would of course be the best solution for providing Dublin Core in an easy way.
An additional advantage of a template under the project's control is the possibility of always keeping it up-to-date and in this way follow the DC developments very closely. This assures the best conditions possible for good metadata in the Nordic Web. We can monitor users' behaviour, check the real metadata produced in the Nordic Web (because we run and control the regional distributed Nordic Web Index, NWI) and react by developing high quality user guide support. The distribution of copies of our scripts for local bulk processing or adaptation to other projects would be under our control and help keep as much interoperability and contacts between the projects using the metadata as possible.
Versions
The first version of the metadata template was published in January 1997. The overall design was done by Traugott Koch and programming by Mattias Borell, both from the Lund University Library, NetLab unit. The first stable version of Dublin Core was released in December 1996, so the Nordic metadata project was definitely among the first Dublin Core tool implementors in the world. The template offered complete and detailed compliance with the Dublin Core syntax and semantics from the very beginning. The template included for instance support for Types (sub-elements) needed by most metadata providers. In this respect it still leads all the other templates known to us.
The template has since this date been continuously updated, changed and adapted to Dublin Core developments. Major versions were released in April 1997, according to changes at the 4th Dublin Core workshop in Canberra, Australia and introducing subject description support with Javascript. In late November 1997, developments from the 5th DC workshop in Helsinki, Finland were included. Among other things, HTML 4 was added as a new output syntax option and a possibility to preview metadata in table format was built. The latest major upgrade occurred in April 1998, offering changes in the Identifier field, integrating a link to the URN generator for Finnish and Swedish publications (cf. Chapter 2.4).
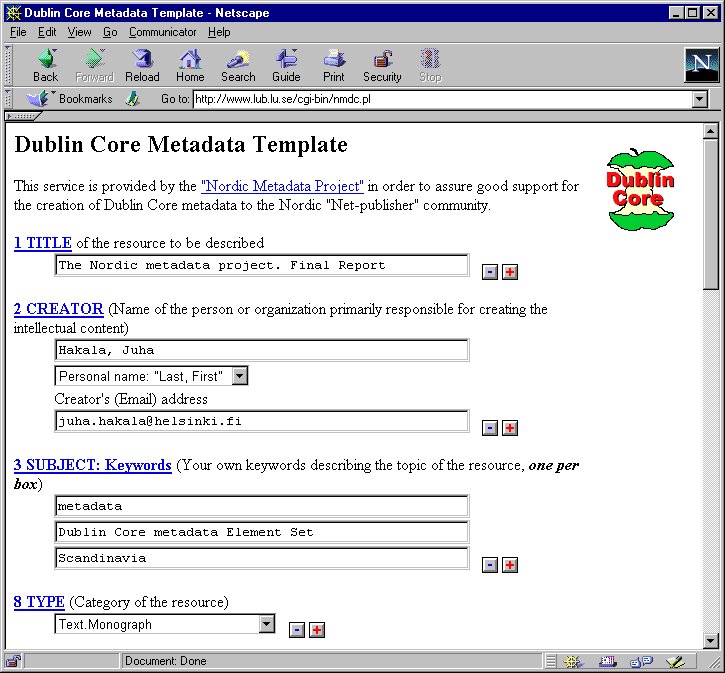
The user interface of this template, available at
http://www.lub.lu.se/cgi-bin/nmdc.pl, looks like this:
Image 1. Metadata template
Some improvements of the template have been initiated and directed by user responses to the evaluation form linked with the creator page (
http://www.sics.se/~preben/DC/usaq.html).Availability
Since the Nordic metadata project published its template in January 1997, Dublin Core metadata templates have become fairly common. However, thanks to periodic revisions our template is still one of the best ones from a technical point of view. For this reason many other projects use modified versions of the template. These projects include large national initiatives such as SAFARI (
http://safari.hsv.se/metadata/safari.pl?lang=sv) and InDoReg (http://purl.dk/metadata/meta_lang.htm). The national library of Denmark has published a template with which publishers can announce their publications (http://www.pligtaflevering.dk/anmeld/anmeld.pl). The National library of Finland has published an experimental template for a similar purpose (http://renki.lib.helsinki.fi/cgi-bin/dc.pl).A German translation will be published at the Max Planck Institut fuer Bildungsforschung in Berlin. Icelandic and Norwegian translations are in preparation. Slight adaptations are used by the Nordic metadata project's partner in Denmark for the Danish National Bibliography service, by the Swedish National Library, by the Swedish national research database SAFARI, the European School Network EUN project and several other projects run by NetLab. This creator has been and still is the model for other metadata templates, in Australia, USA, UK, Europe and the Nordic countries.
The template application is written in Perl. Source code will be linked to the project homepage (
http://linnea.helsinki.fi/meta). The Nordic metadata project cannot guarantee any support to implementors, but the creator will be continuously updated and developed as long as there is funding available for this purpose. However, it is our aim that when the project phase is over and the template is stable we will find a maintenance organisation for the application.Functionality
The template offers boxes for all Dublin Core attributes, schemes and standardised content options, all in accordance with Dublin Core development. As far as Schemes are concerned, commonly agreed default values are given as defaults in the template as well. In applicable cases Nordic Schemes (i.e. Subject schemes) are presented first. For content lists the most frequently occurring alternatives are presented as defaults. In a few cases the Nordic metadata project introduces recommendations which are not (yet) generally adopted by the Dublin Core community, i.e. the principle to use a separate box for every subject expression, allowing an unambiguous delimitation.
The script is written in a very flexible way, which allows every template implementor to choose his or her own default selection of the Dublin Core elements to be shown to the metadata providers. All other elements are available for interactive adding at the end of the template. It is also easy to modify the order, in which the schemes are shown, or to add or remove Schemes and other qualifiers from elements.
The Nordic metadata project decided to present all Dublin Core elements as the default option, in order to demonstrate the potential of the format and in this way attract librarians who are used to a more powerful format, MARC. At the top of the template is the button to the short and simple template, featuring six Dublin Core elements in a simplified version for the "normal" end-user, who might not want to spend more time and effort in resource description than absolutely necessary.
The boxes allow full copying and pasting from other texts, which speeds up records creation considerably. The template of course treats European and Nordic characters correctly and automatically converts all special characters into HTML codes, in order to assure correct display and indexing.
As far as the element qualifiers are concerned we have adopted the following strategies in the full template:
From the implementor’s point of view qualifiers are problematic, since on the one hand it is necessary to support them in the template to enable users to provide high-quality metadata, but on the other hand there is as of yet no consensus on what the core qualifiers are. This means that changes are not only possible – they are quite likely. This applies first and foremost to the Type qualifier. On the other hand, Schemes vary from one country or institution to another, so good support for Subject input will require local modifications. But a lot can be done on a global level as well, as can be seen in the next chapter.
Subject support
Since the main reason for providing metadata is to enhance the retrievability of content on the Internet, our project is focusing heavily on all types of support for subject description (and retrieval). For improved user support, the Dublin Core Subject element is shown in the full template in three different instances: Subject: Keywords, Subject: Controlled vocabulary and Subject: Classification, even if the Dublin Core does not offer different sub-elements for those usage policies (as of this writing). The simple template, by the way, offers the Subject: Keywords alternative only.
Distributed between scrolling windows in the template itself and the subject help page are links to all (as far as we know) vocabularies, e.g. controlled keyword lists, thesauri, classification systems, authority lists, general vocabulary systems et cetera, which are freely available for navigation on the Web. The beginning of the page is shown below.
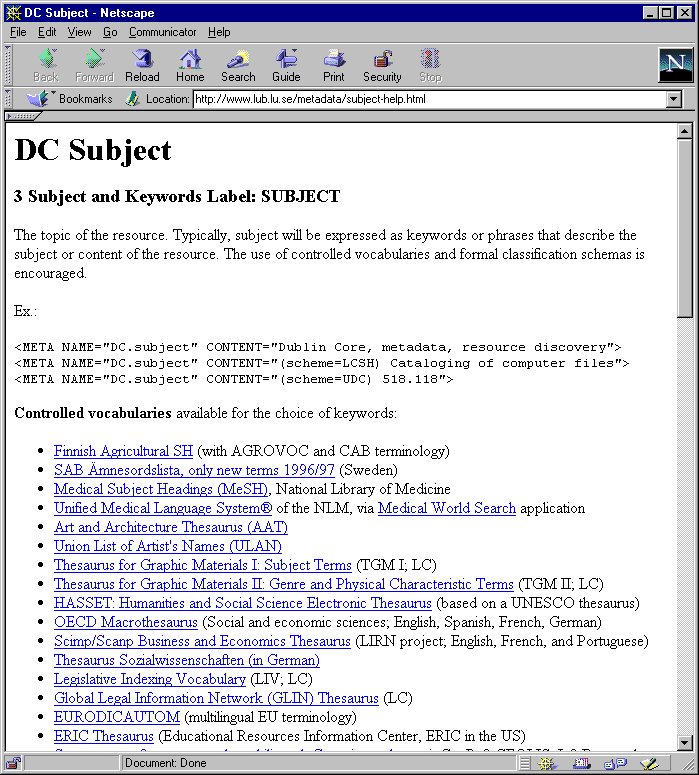
Image 2. Subject help screen of the metadata template
We also made an inventory of classification systems and subject headings lists commonly used in the Nordic libraries, and listed them on a pull-down menu. All these Schemes, together with important international Schemes, are listed even if the vocabularies are not available on the Internet.
With the help of Java script (written by Mårten Berggren) a direct connection to the site offering the chosen vocabulary is established and offered for navigation in a separate window. Suitable terms can then be copied and pasted into the appropriate Subject boxes.
URN generator
The Identifier field is, in a similar manner as the Subject field, logically subdivided in the user interface between Identifier:URL for the location and in Identifier for the "string or number used to uniquely identify the resource described". The second alternative provides a link to the URN generator, which offers an authorised URN for Swedish or Finnish publications (cf. Chapter 2.4). Once the URN has been delivered, the user can paste it into the appropriate window in the metadata template. In the future we will modify the template and URN generator so that the latter can write the URN directly into the Identifier window of the metadata template.
Help system
A comprehensive help system is provided with the template: Introductory and dialogue text, general help, guidelines, a tutorial, link to the DC reference version and links to help pages for every DC field, including examples. For details, see Chapter 2.5.
Output
At the moment, there are three output alternatives offered:
a) A preview listing the attributes and values given in table form, together with chosen schemes.
b) The DC metadata coded according to HTML 2.0 for inclusion into the HTML head of the document described.
c) The DC metadata coded according to HTML 4.0 for inclusion into the HTML head of the document described.
There are many other output formats the template should support in order to provide a comprehensive service. We intend to offer new alternatives, like XML. We have also plans to add new functionality, such as optional support for re-use of already existing metadata in the document to be described (based on its URL). The template will on the user’s request fetch all useful metadata from the resource such as Title, and put this data into the appropriate windows in the template.
This feature has already been implemented in e.g. the UKOLN’s metadata template, DC-dot. We have been cautious in providing such a service and will in any case make it optional. According to our experiences the metadata available in Web documents may be of very poor quality. Such metadata would not help in creating a Dublin Core record.
Metadata viewer
A related tool from our project, which will help to motivate users to produce metadata, is a metadata viewer tool (written by Sigfrid Lundberg from the NetLab). In order to use this tool, you just need to put the link:
<a href="http://www.lub.lu.se/dc/nmd_viewer.pl"> View Metadata for this page! </a>
somewhere in your HTML page, and the metadata will be visible to human beings as well as to harvesting robots and search engines. The presentation format is easy to read. Below is an example of viewer output extracted from the page
http://www.ub2.lu.se/koch.html as an example of a HTML page, which has both the link to the metadata viewer and high quality Dublin Core metadata in it.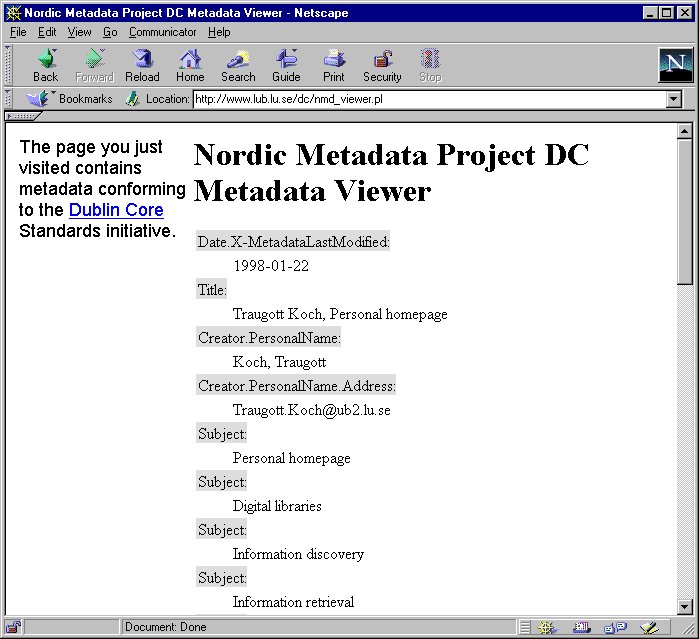
Image 3. Metadata viewer
Usage
The summary of usage data is available in the Appendix 5.
Since the release of the newest version (Five months between Dec 2, 1997 and May 3, 1998) the template has been visited approximately 50 times per day on the average. The visitors are from 64 domains/countries. The number of visits has been increasing steadily since the service was released. During spring 1998 the usage rose from about 1100 to about 1900 visits per month, in spite of the fact that the Finnish version of the template was published during this period as well.
During the analysed period one out of 4-5 visits resulted in the production of a metadata output file, 10 per day, 3 files per host. The producers were from 28 different domains/countries. It is impossible to estimate the total number of created records world wide, since many users may, instead of creating a new Dublin Core record, just modify the relevant elements from a record they have created previously. This can be done easily with almost any HTML editor. In the Nordic countries there were probably more than 4000 Dublin Core records in April 1998, most of which have been created by volunteers with the help of the metadata template.
The high usage figures indicate that the template design is successful and forms a good basis for further development work. This assumption is verified by the evaluation we have carried out (cf. Chapter 2.6).
Summary
The Dublin Core Metadata Creator Template is a highly flexible interactive tool providing good user support. It can and has been easily adapted to different projects and user groups. The code is freely available to everyone. It guarantees close adaptation to the DC development and to user needs and behaviour. There is rich support for content expressions and schemes and a focus on the best possible support for subject description. Help windows offer all known vocabularies freely available on the Web for navigation and term selection. The URN generator is integrated into the template, and a comprehensive help system in the form of linked user guides is offered. Supplementary tools like the metadata viewer, are provided.
The metadata creator supports a distributed model for metadata creation, storage and retrieval. Its full potential and highly motivating power is achieved by its integration with a regional distributed harvesting system and Web index (NWI) and its searchable metadata databases (see below).
A general metadata creator tool can in many ways have a much more powerful influence when tightly connected to a search service. Individual users will only be motivated to make the effort to produce metadata, when they are able to see the results – improved retrieval of their documents - very soon. Their documents should be indexed as soon as possible and in detail by a WWW index, at least a regional one, and be retrievable with higher precision because of a proper use of metadata in the web index.
Not one of the few general purpose metadata creators we know, controls or even co-operates with a Web index. Creators offered by specific projects are of course usually linked to a searchable database.
Our project's DC metadata creator template is closely linked to the robot-generated Nordic Web Index (NWI,
http://nwi.ub2.lu.se/?lang=uk), a virtual union catalogue of national Web indexes in Scandinavian countries. As of now, all documents from Sweden and Denmark, to which the author has provided the URL in metadata, are retrieved by the NWI harvester. All metadata present in the document is indexed into the Nordic Web Index. (see Ardö, A. and Lundberg, S.: A regional distributed WWW search and indexing service - the DESIRE way. In: Proceedings from the 7. WWW Conference, Brisbane, Australia, April 1998)Metadata enriched documents are of course harvested by other search engines, but in most Web indexes metadata, or at least the Dublin Core metadata, is either not indexed at all, or is not indexed properly. The NWI is as of this writing still the only major web index in the world, which is fully metadata aware and compliant to Dublin Core.
Several NWI programmers have been contributing to metadata extraction scripts, which use the results of intellectual decisions on which major metadata attributes found in the web contain meaningful metadata (cf. example lists of all used attributes respective to the extracted metadata attributes from:
http://www.ub2.lu.se/metadata/Nordic-MDusage.html). A lot of effort has been put into eliminating poor metadata.Metadata is extracted from documents and indexed into separate national metadata databases. As of this writing Swedish (Swemeta) and Danish (Danmeta) databases are available to users; Swemeta at
http://gungner.ub2.lu.se/cgi-bin/egwinit.pl/egwirtcl/metatargets.egw?swemeta and Danmeta at http://nwi.dtv.dk/uinwi/index_e.html).Our aim is that Norwegian, Icelandic and Finnish metadata databases will be opened in the summer of 1998. Since the NWI is based on Z39.50, we can release a Nordic virtual union metadata database in the autumn of 1998.
In February 1998, Swemeta contained 150 000 documents with meaningful metadata (about 8% of all Swedish WWW pages) and in May there were 105 000 documents (about 6% of the Danish WWW) in Danmeta. If documents with poor metadata had not been eliminated, the databases would be a lot bigger. The information in the metadata database is stored in SOIF format, but search semantics conform to the Dublin Core. In DANMETA (see below) it is possible to search with Title, Creator, Subject, Description, Identifier and Free text.
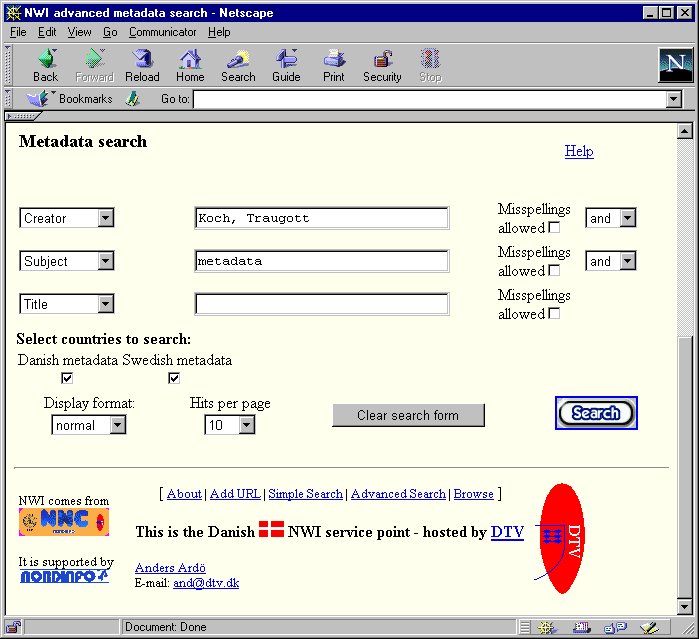
Image 4. DANMETA search screen
Of course, only a fraction of these records contain Dublin Core data, but the metadata there can be meaningfully mapped to Dublin Core. Generally, the willingness of Nordic authors to provide descriptions for their documents in order to help others to find them is very encouraging.
The next image is an example of how records are displayed for users. For the sake of simplicity, only the first reference is shown in full.
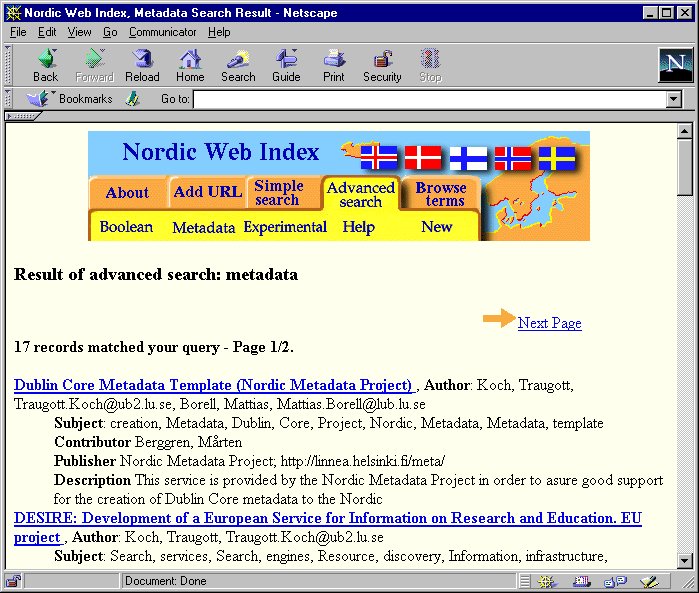
Image 5. DANMETA search result screen
We believe that the even current amount of useful metadata justifies the creation of a national metadata database, in parallel with a national full text Web index. Keeping in mind the fact that the amount of metadata in the Web will grow rapidly, we would like to encourage other projects to launch similar initiatives soon. But a functionality to wipe out useless metadata is important. It is known that some of the international Web indexes justify their omission of metadata by the poor quality of the existing metadata; our results indicate that this problem can be bypassed.
In the second step, all meaningful metadata attributes are mapped into Dublin Core elements to offer full interoperability to and from outside services. Other services we know of, like the German Fireball, convert to their own internal metadata scheme. A search interface building upon a Z39.50 profile is constructed, offering the most frequently occurring DC fields in the metadata databases for searching.
Using NWI's Z39.50 technology, with its in-built EUROPAGATE HTTP-Z39.50 server, we are able to offer for the time being two, and in the future five national metadata databases for simultaneous Web searching. Since structure, syntax and semantics follow standards, our metadata databases can be integrated into each other and to other Z39.50-compliant database services. For instance, the national metadata databases can be made available in parallel with other bibliographic databases such as union catalogues and national bibliography databases. The one prerequisite for this is that the Dublin Core search attributes and Z39.50 Bib-1 attributes can be mapped in a semantically correct way to, or combined with, each other. This mapping is currently specified internally within our project; in the future the mapping will be done in the Z39.50 standard. The work to incorporate Dublin Core search elements into the Z39.50 is as of this writing under way.
We decided to offer the meaningful Web metadata as separate databases and not as part of a full text Nordic Web Index database. The main reason for this is the comparably small percentage of metadata carrying documents in the database and the uneven distribution in usage of individual metadata elements. A separate database provides also better control and more precision in the search results. A cleaner solution would be to provide a controlled combined searching opportunity of searching metadata and the non-metadata bearing documents together, and to show the results from both different databases in clearly separated lists. See for instance the experimental EELS-All Engineering service at
http://borg.lub.lu.se/newegwindex.html (choose alternative AEELS II from the menu).Summary
The Nordic metadata project provides a unique integration between metadata creation and the possibility to see the outcome of this effort in high quality metadata databases covering the whole (regional) Web space.
This chapter was written by Juha Hakala, but much of the basic information was provided by Ole Husby.
One of the main reasons for developing the Dublin Core was that a simple format enables authors and publishers to provide descriptions of their documents. This information will be searchable via Web indexes, but from the libraries’ point of view this is not enough. It is very important to be able to utilise Dublin Core data in library OPACs and union catalogues as well. This requires conversion from the Dublin Core to MARC.
In theory it is easy to convert records from Dublin Core to MARC. The Library of Congress has been involved in the Dublin Core development from the very beginning. This may be the reason why conversion from non-qualified Dublin Core to MARC is quite simple. On the other hand, one might assume that OCLC – which hosts the largest MARC database in the world – would not support something that is not interoperable with MARC. But it should be kept in mind that there are many players involved in the Dublin Core developments, and compatibility with MARC is not of interest to anybody else than the library community. Some recent developments of the Dublin Core, such as elaboration of the Date Element, do not have a counterpart in the MARC format, and thus the Dublin Core has moved beyond the MARC capabilities in some areas. But this does not change the fact that a lot of useful information can be converted from a Dublin Core record to a MARC record (and vice versa).
In theory any structured data can be converted into another structure. This conversion will – again in theory - cause some loss of data. Actually the Dublin Core is an ideal target format due to its flexibility: any piece of information in the source record can be "saved" using a private element or qualifier. This very feature makes the Dublin Core problematic as a source format – there will be a legion of different flavours of Dublin Core, and no converter can ever be able to handle all elements and qualifiers it might find from a Dublin Core record. Anyway, it is relatively simple to map the 15 basic Dublin Core elements and also most of the core qualifiers as defined in Rebecca Guenther’s qualifiers list to USMARC and other MARC variants.
The goals of the Nordic metadata project in this subtask – which was carried out by BIBSYS - were to
As of this writing (June 1998) the application is not ready for distribution, but the converter has been available for the public at
http://www.bibsys.no/meta/d2m/ since the summer of 1997. One year later it is still the only DC to MARC converter that is available in the Internet. In addition to the planned formats it can create USMARC records. Development of this functionality was "a piece of cake", since NORMARC is quite close to USMARC. The project has also built an experimental Dublin Core to NORMARC converter, and proven that it is more difficult to convert from MARC to the Dublin Core than vice versa. The reason for this is, in very general terms, that although it is usually easier to convert from a complex format to simple one than vice versa, converting from MARC to anything is harder than converting from anything to MARC.Conversion tables
When creating a format converter there are actually two tasks to be taken care of. The first one is to build a conversion table, or crosswalk, from the source format to target format. If the formats involved are complex, this task is not easy. For instance the conversion tables built for MARC formats in the ONE project are several hundred pages long.
The complexity of a Dublin Core to MARC conversion table is dependent on what kind of Dublin Core is used as the source format. The first conversion table, the Library of Congress’ Dublin Core/MARC/GILS Crosswalk (
http://lcweb.loc.gov/marc/dccross.html) defines relations between USMARC, GILS and a relatively unqualified version of the Dublin Core.The Finnish Dublin Core/FINMARC/GILS crosswalk is included as Annex 7. The Finnish document (available at
http://linnea.helsinki.fi/meta/dcficross.html) has not only replaced USMARC with FINMARC; it has also wider coverage of DC qualifiers. Basically anything that a) could be produced with the Nordic metadata template and b) had a target tag in FINMARC was included in the crosswalk. If something is not defined in the crosswalk it cannot be converted, so the scope of the crosswalk was very easy to choose.In the Nordic metadata project crosswalks were developed also for Denmark, Norway and Sweden. Our experience is that crosswalks do not need much modification when fitted to a new format. One reason for this is the fact that the Dublin Core does not use code information in the same way as MARC. (008 codes are a nightmare to convert from one national MARC to another.)
The crosswalks in their current form are very readable for humans. Unfortunately this is not so for conversion software. No application will ever be capable of reading the crosswalk in its current form. There is a major need to formalise the structure of a DC to MARC conversion table. If this is done, then any converter application can just read the tables in and do whatever is needed.
Bibsys has started the formalisation of the Dublin Core to MARC conversion table. Unfortunately, there was no time to complete this task in the Nordic metadata project, mainly because there was no time at all allocated for this activity in the project plan. We hope that this work can be finalised in the proposed Nordic metadata II project, for the benefit of us, and the global Dublin Core community.
The proposed conversion table will look like this for the FINMARC format (which, like UKMARC, divides the author’s name in the tag 100 into subfield $a for the last name and $h for first name) and the Dublin Core Creator element:
|
Name |
Type |
Scheme |
Occurrence |
Tag |
Indicator |
Subfield |
|
Creator |
None |
None |
Any |
720 |
a |
|
|
PersonalName |
None |
First |
100 |
a + h |
||
|
- |
- |
Any |
700 |
a + h |
||
|
CorporateName |
None |
First |
110 |
a |
||
|
- |
- |
Any |
710 |
a |
||
|
PersonalName.Address |
None |
Any |
- |
|||
|
CorporateName.Address |
None |
Any |
- |
In practice this data will be produced by a spreadsheet application like Excel. From the spreadsheet the data will be exported into a semicolon-delimited table, which is well suited to be an input format for the converter. The data above will look like this:
Creator;None;None;Any;720;;a
Creator;PersonalName;None;First;100;;a
Creator;PersonalName;None;Any;700;;a
Creator;CorporateName;None;First;110;;a
Creator;CorporateName;None;Any;710;;a
Unfortunately, a conversion table like this will not be enough, since there are e.g. cases in which a single Dublin Core tag should be split into two or more MARC tags, and cases in which the data content of the element has an influence on the conversion. These situations can be taken care of with rules. An example of a situation in which a rule is required is the need to split author name in tag 100 into subfields $a (last name) and $h (first name) in UKMARC and numerous other MARC formats. If the Dublin Core data in the Creator tag is in normalised form (last name, first name) we can use a rule called for instance UK_NAME: split personal name into subfields $a and $h at first comma.
It will not be easy to build a generic conversion table incorporating conversion from the Dublin Core to all widely used MARC formats. The length of the table containing all Nordic formats is large, and so is the number of rules needed to handle the data properly. For the time being the worst problem is that there is no final list on the core set of qualifiers. Once the core qualifiers have been approved the implementors can safely write conversion tables, which must cover all core qualifiers. A related problem is the HTML syntax: it has changed a few times, and already there are different syntaxes for HTML 2.0 and 4.0. A good conversion table (and converter) should work fine with all variants of the Dublin Core used from the early history in 1996 to the present.
However, unless a conversion table is built and the way of representing data in it is formalised, any DC to MARC converter must include the conversion in the program code or use ad hoc solutions not suitable for other projects for importing the conversion specification into the program. This would be very inconvenient, since both the Dublin Core and MARC will change constantly, and all changes must then be done twice: first in the crosswalk, then in the actual program, and these steps would be repeated in all projects involved in MARC conversion. Using a common table will eliminate or at least significantly reduce the need to modify the program code. It will also make it easier to use the same basic applications everywhere (with some local functionality added) and thus save a lot of time and effort.
Conversion software
The DC to MARC converter is available to the public for test purposes at
http://www.bibsys.no/meta/d2m. The user interface is represented below.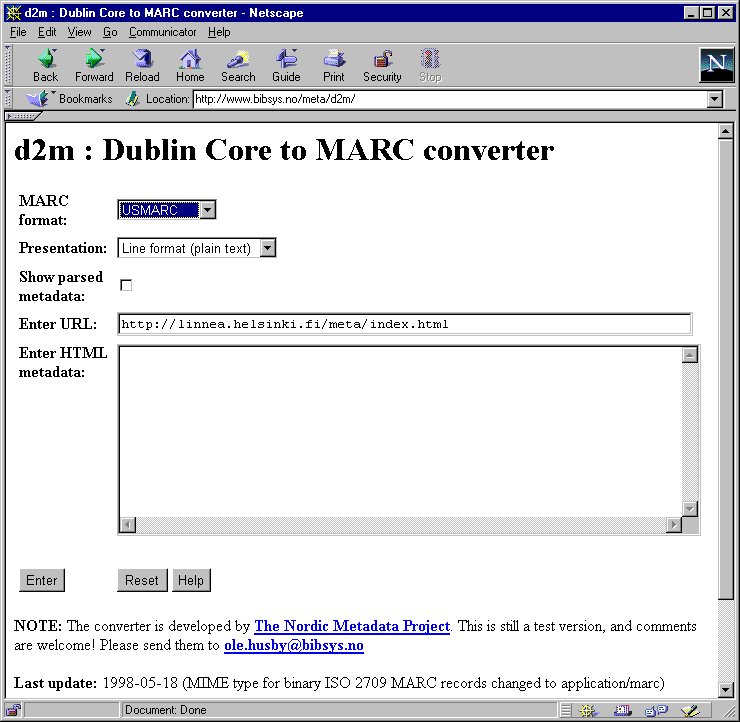
Image 6. The Dublin Core to MARC converter
The result for the example above looks like this:
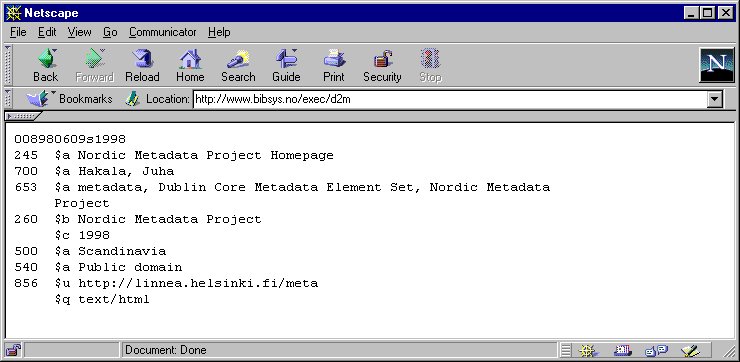
Image 7. The Dublin Core to MARC converter. MARC record display (plain text option)
The application uses a DC to USMARC crosswalk as a basis for handling NORMARC, SWEMARC and Icelandic UKMARC. The converter can produce records in ISO 2709 or in line format, which shows MARC data in a readable form on screen. The quality of the end result varies depending on the quality of the source data: at best the result can be very good; at worst it is not. The current version of the converter accepts as input either the record or the URL from which it can be fetched. The future version will be able to convert a file of Dublin core data into a file of MARC records in ISO 2709 format. In order to be able to do this, we must of course define the way in which DC records are represented within such a file, and build a module into the Nordic Web Index which enables the application to build these input files.
The DC parser requires DC. –prefix for the element name. It is case insensitive but does not allow typing errors; i.e. DC.Creator, DC.CREATOR and DC.creator will all do, but not DC.Cretor. The parser also recognises scheme and type qualifiers both in HTML 2.0 and HTML 4.0 versions.
Writing the DC to MARC converter application has not been as easy as we optimistically believed in the early stages of the project. There are quite a few problems, which make the converter development an "interesting" task. Some DC elements may be implicitly grouped together, and recognising this situation is not easy. Performing a conversion based on the data in the DC record is also difficult, especially because there is no way yet to code this information into the conversion table. Finally, the quality of source data will vary a lot, and it is difficult to know what a missing DC qualifier really means. The reason for omission may be a conscious decision of the metadata creator, or it may be that the "cataloguer" is just ignorant.
Summary
In spite of the fact that our project has not yet been able to deliver everything we promised to do in this area, it is actually in DC to MARC conversion that our technological lead is the biggest. As far as we know, nobody else has seriously ventured into this domain. The Nordic metadata project is therefore in a unique position: if we are able to continue work in this area, we may provide an application that can be used not only in Nordic countries, but also globally.
URN's - or Uniform Resource Names - make identification of Internet documents possible. URN identifiers are persistent and unique: The URN given to a document will never change, if the intellectual content remains the same. A "used" URN will never be given to another document.
The URN system is as of this writing under development. The Internet Engineering Task Force’s URN Working group (see
http://www.ietf.org/html.charters/urn-charter.html) is responsible for the work. As of this writing (June 1998) the standardisation effort is not quite complete, but most of the vital aspects, like the URN syntax, have been agreed on. The URN system is ready for implementation, and there is an urgent need for it in the Web.From the national libraries’ point of view identification of Web documents is vital, since it allows for efficient searching and archiving of resources. Unfortunately, existing bibliographic identifiers can be used for just a small fraction of all Internet documents. For this reason location, or URL, has often been used for identification purposes.
URL was never developed for identification purposes. It gives guidelines only on how to access a resource (protocol and address, consisting of machine name and a full file name). The URL as an identifier is actually counterproductive: the harvesting application knows the correct URL of the document anyway – otherwise it would not have found the resource – and if the document is copied somewhere else the old metadata is, unless corrected, false.
The Nordic metadata project wanted to enable users to get decent identification for their documents as part of the metadata creation process. Therefore, we started in the autumn of 1997, when the URN syntax was finished, negotiations with the IETF URN working group on how national bibliography numbers can be used as URN’s. The resulting syntax looks like this: URN:NBN:xx-yy
Every URN begins with "URN:"; this makes it possible to locate URN’s from flat documents with no structure or embedded metadata. NBN is the Namespace Identifier, or NID, for national bibliography numbers. The identifier part of the URN begins with the country code ("xx" above). This is necessary since the NBN’s ("yy" above) are not globally unique – each national library can use anything they want as an NBN.
An example of a Finnish URN:
URN:NBN:fi-fe19981001
Since the NBN usually consists of code information, year and a number, it is easy to automate NBN creation. This applies of course also to URN’s based on them. Helsinki University Library wrote a specification for an URN generator, which was then programmed by Mattias Borell from the Lund University Library, NetLab unit. The application is available at
http://www.lub.lu.se/cgi-bin/nmurn.pl. The user interface is very simple: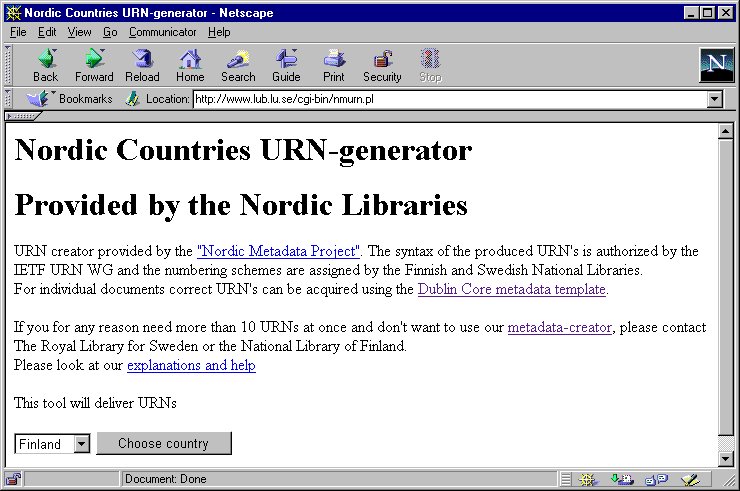
Image 8. The URN generator user interface
A help text is available at
http://www.lub.lu.se/metadata/URN-help.html. It is also included as Annex 4 of this report. As may be guessed, the help text does not talk very much about the usage of the URN generator itself. But there are two more complicated problems to solve: a) when does a document deserve an URN and b) how to embed the URN into the document. If the URN is not embedded, Web indexing applications will not be able to find it and make it available for searching and URN to URL translation purposes.The guidelines on how to use URN’s (listed in the user guide) can be derived from existing cataloguing rules. For librarians these rules are obvious, but explaining them to the end users may be difficult. Embedding the URN correctly to a resource may be equally tough to everyone, unless the URN generator and the metadata template are linked to one another. At the moment the template and the generator are interlinked, but not to the level where the generator is able to send a URN directly to the template’s Identifier window. This functionality will be added later as a part of the Nordic metadata II project.
The most effective way of embedding the URN into a document is the usage of the Dublin Core Identifier element. Then the syntax would be like this:
<META NAME="DC.Identifier" SCHEME="URN" CONTENT="URN code">
It is also possible to use META tag without the Dublin Core. Then the syntax will be like this:
<META SCHEME="URN" NAME="identifier" CONTENT="URN code">
The usefulness of the plain META usage stems from the fact that Alta Vista and some other services can index data coded in this way. But one must be careful – at least in the spring of 1998 Alta Vista indexed only NAME=keywords and NAME=description, and even that metadata is not separately searchable. Other global Web indexes have similar limitations. The Dublin Core –based metadata is as of this writing not indexed properly in any indexing service. Luckily this functionality will be available in the Nordic Web Index in the summer of 1998. CSC – The Center for Scientific Computing is as of this writing modifying the NWI in such a way that it indexes URN’s, if the identifier is coded into the META tag. The URN’s will be searchable both in the full text database and the metadata database.
The URN generator was published as an official service in Finland on 4th of May 1998. The Finnish version of the application is available at
http://linnea.helsinki.fi/cgi-bin/urn.pl. The help text is available in Finnish at http://linnea.helsinki.fi/meta/URN-opas.html. "Finlandisation" of the service was done as a part of the EVA project. The Finnish URN delivery service is, as far as we know, the first such service made public in the world.The Royal Library began delivery of URN’s in Sweden on the same day as the service was made available in Finland. It is very likely that other Nordic countries will follow the example set by Sweden and Finland later. Outside Scandinavia, the Conference of European National Librarians, CENL, is fostering the usage of URN’s at a European level. More specifically, Die Deutsche Bibliothek is planning to implement the URN generator as well.
This chapter was written by Juha Hakala. The project reports written by Preben Hansen were the main source of the text.
Good support for users is a vital part of any metadata production system. In a Dublin Core –based system there is an even more vital need for user guides, since there are no cataloguing rules such as the International Standard for Bibliographic Description (ISBD), well known to all librarians. This problem has been recognised by the Dublin Core community, which is as of this writing finalising a user guide for the basic, unqualified Dublin Core. Draft version 5.0 of the text is available at
http://linnea.helsinki.fi/meta/UserGuide5.html. The final version, when published, will be made available via the Dublin Core homepage.When the Nordic metadata project was launched there were no drafts of a global user guide – the group which is writing the guide was established in the 5th Dublin Core Workshop in Helsinki (
http://renki.lib.helsinki.fi/meta/DC5.html). For this reason Preben Hansen wrote a set of user guides for the project. There were three user guidelines documents: a short and an extended version of the Dublin Core metadata user guidelines, and a general help for the metadata template itself. During May 1997 – February 1998 these files were accessed more than 2500 times, which indicates the users' need for assistance (and the fact that our metadata templates were used actively).In addition to complete guide there were also individual help texts for each Dublin Core element. For nine elements there was just a single text file, but six essential elements (Title, Creator, Subject, Language, Identifier and Type) had both a short and normal help text file. These files were accessed more than 4200 times during the test period (for full details see
http://www.sics.se/~preben/DC/reports/DC_access.html).During the project it has become obvious that the user guides need to be nationalised. This means not only translation from English to local languages, but also modification of elements which are country-specific. A prime example of this is Subject; Nordic countries use different subject headings lists and classification systems, and there is a need to take this into account in the template and national help texts.
Unfortunately there has been no time to translate the user documentation. There is also another reason for this: contrary to the global user guide under construction, our guide – like our metadata template – supports usage of Dublin Core qualifiers. As these are not fully stable yet, changes are possible. Most of the changes will force us to change the metadata template and also user guides. If there were six versions of the guides (English and all Nordic languages) the burden of keeping everything up to date would have been tremendous.
The full evaluation report written by Preben Hansen is included in this report as Annex 3. This chapter contains only a summary of the results, written by Juha Hakala.
Due to lack of time and resources the evaluation covers only the metadata template. We intend to evaluate the other tools in the proposed Nordic metadata II –project.
One of the main things with an evaluation and usability study is to detect errors and requirements from the intended users, as well as to measure the satisfaction with software design.
User guides have been accessed approximately 10.000 times during the project. Unfortunately, only 21 people completed our questionnaire. Two of them had an expert knowledge of Dublin Core, nine said that they had medium knowledge of Dublin Core, and the others classified themselves as novices. The small number of respondents (especially in the expert category) must be kept in mind when the results are evaluated.
In general the respondents understood very well the meaning of the Dublin Core elements (4.42/5). This could be explained by an integration of a satisfactory level of explanation in the user guide documents, an emerging knowledge the respondents had about Dublin Core, and a design that takes this in account. The Dublin Core elements are well understood, and this is encouraging, since it strongly indicates that one of the central design goals of the format has been reached: the Dublin Core seems to be simple enough even for novices. Of course these novices were interested in metadata and motivated to learn; we do not know yet what will happen when 5000 Danish State officials start providing Dublin Core metadata because they are ordered to do so.
The respondents were quite satisfied (3.10/5) with the functionality of the template. Satisfaction with the overall design of the template was a bit higher (3.68/5). It should be kept in mind that the current version of the template is much improved from the one that was available during the test period. The fourth version of the template, coupled with the URN generator, would perhaps get a better evaluation in both cases. It is noteworthy that the novices liked the template better than the other users – metadata professionals are demanding, since they have expectations based on the systems they are used to.
For the future there are two remarks that can be made: people categorised as medium knowledgeable had low score for a) the functionality of the metadata tool including the resulting metadata description page (Question 1); and b) the overall design of the template (Question 2). Some of the reasons can be seen in the analysis of open-ended question in Annex 3, section 3. Since this group constitutes of almost 50 % of all respondents, it is important to take this into account.
Users had a high satisfaction both with the support they got from the user guides (4.11/5), and with the interaction between the template and the user guides (4.28/5).
To sum up, the user guides provide in their current form good support for metadata providers. However, there is a need to customise the documents according to national needs by translating them, and adding sections that are needed to fulfil domestic needs. There is also a need for a more detailed look at the design of the template. The evaluation has detected some important factors that need to be taken into consideration, such as the meaning of symbols, the length of the template, complexity versus simplicity, and intuitiveness.
All tools and documentation created in the Nordic metadata project have been made available in English. Moreover, the tools have nothing "Nordic" in them, except that all classifications and subject headings lists widely used in Nordic countries have been embedded into our template (but it is easy to remove them from it). The reason for remaining as international as possible was that we wanted to serve not only Scandinavian countries, but the global Dublin Core user community. As the metadata has been created by users from 28 countries and visited by people from 60 countries, we have been quite successful in this.
Because the tools are international, there is a need to make national versions of them. Activities in this area include:
A more interesting question is: how have the Nordic countries introduced metadata in general and the Nordic metadata project’s results in particular in their library IT activities in general? Although metadata as a hobby works to some extent - thousands of metadata records supplied during the project prove this - Dublin Core will not be a success until it is embedded into the daily routines.
This chapter contains a more detailed description of the state of the art in Denmark and Finland. The process of making the Dublin Core a routine is well under way in other Nordic countries as well, though Norway and Iceland have perhaps been a little slower to start these activities. However, in Norway there is a Norwegian version of the Dublin Core and work on the Icelandic translation is well under way.
In Sweden there are a number of important initiatives using the Dublin Core and modifications of our metadata tools. These include SAFARI (
http://safari.hsv.se/metadata/safari.pl?lang=sv) and the Royal Library's Swedish Web guide for libraries, Svesök (http://www.svesok.kb.se/).This chapter was written by Susanne Thorborg from the Danish Library Centre, with some additions and modifications by Juha Hakala.
In 1996 The Danish Library Centre launched a project, InDoReg (Internet Document Registration; see
http://purl.dk/rapport/html.uk/) to clarify some fundamental questions concerning bibliographic control of Danish Internet Documents. It focused among other things on the registration method and use of metadata.The ultimate target was that the document registration should be made in DanBib (the joint union catalogue for the complete Danish library system; see
http://www.dbc.dk/english/engdanbi.html) alongside the national bibliography. Consequently, the starting-point was that the Internet publications should be catalogued according to the Danish cataloguing rules (based on AACR2) and in danMARC format, thus maintaining the traditions for processing information from the other materials in DanBib.The proposed registration method seeks to cover the special needs of Internet publications in terms of description and format. The problems of describing static and dynamic publications vary, but it is obvious that self-registration by authors/publishers using metadata is a necessary supplement if very large amounts of information are to be registered.
For this purpose the DBC has built a modified version of the Nordic metadata project metadata template to satisfy Danish requirements. The template is available in two versions: long (
http://purl.dk/metadata/meta_lang.htm) and short (http://purl.dk/metadata/meta_kort.htm). The help text (http://purl.dk/metadata/help.htm) is common to both templates.In addition to the DBC, the national library has built another metadata template based on our metadata template. The national library's template is available at
http://www.pligtaflevering.dk/anmeld/anmeld.pl. This template is intended for authors and publishers sending electronic legal deposit materials to the library. According to the Danish Act on legal deposit (http://www.pligtaflevering.dk/lovstof/loven.htm), the publishers are required to send a description of all works they think should be deposited. The library uses this description for deciding whether the publication is worth inclusion in the national bibliography.In order to support the creation of MARC records from the generated DC-metadata produced by the document owners, a DC->danMARC2 crosswalk has been prepared for the DC->MARC converter (see
http://linnea.helsinki.fi/meta/dcdancr.html). In the Royal library, DC data is uploaded into a dedicated database.To ensure the constant validity of addresses (URLs), a PURL server has been established by DBC. This solution was chosen in early 1997 in order to cover immediate needs, but use of URN's will of course be considered in the future.
Denmark is the first country to require that a large group of authors – public employees - provide Dublin Core -like metadata. The specification was published as a book "Netpublikationer: Statens standard for elektronisk publicering" (Net publications: State standard for electronic publishing ).
By requiring a) publication of all public documents on the Internet and b) making metadata obligatory Denmark is setting an interesting example for other Nordic countries. As of this writing at least Finland has followed this example: there is a requirement to add Dublin Core metadata into public documents published by state and local officials. As of yet there is no requirement to publish all public materials on the Web, but in practice this is already happening.
The Danish standard was published in June 1997. Although the elements were aligned with the Dublin Core (with a number of local additions) the syntax never was; there is a need to revise the Netpublikationer to make it interoperate better with the Dublin Core.
An interesting aspect of the Danish initiative is the need to educate thousands of state officials to provide metadata. As far as we know, this will be the first such training effort on a national scale.
In Finland, Dublin Core usage has a vital role in the project EVA (
http://renki.helsinki.fi/eva/english.html), which develops methods for the acquisition and archiving of electronic network publications. There is also a close link between EVA and the revision of the Finnish Act on legal deposit, which is currently under way. The new law, which will cover electronic publications, exists as a proposal of the working group nominated by the Ministry of Education, but as of this writing it seems that the law will not come into force before the year 2000.The proposal for the new law recommends that the library should be allowed to harvest freely available network documents with automated means, store these documents and make them available via a full-text database. The more metadata there is in these documents, the better. The identification of documents is especially of vital importance, since without an ID it will be impossible to de-duplicate the archived documents, and also searching them will be much easier if the documents have been identified with an URN. Although it will take a while before the proposed law comes into force, we have already started URN delivery with a domestic version of the Nordic metadata project’s URN generator.
The proposal suggests also that the library should allow publishers of freely available Web documents to voluntarily deposit them. Alas, the experience from Norway indicates that much of this material may sometimes be of poor quality. Therefore, the national library will not allow direct deposit of these documents, but will require authors to provide a description of the resource. This description will be done with a metadata template, which produces Dublin Core data, with some local elements added. These additions will follow the BIBLINK recommendations (see
http://hosted.ukoln.ac.uk/biblink) when possible. The template will naturally be based on the current Finnish version of the metadata template, available at http://linnea.helsinki.fi/cgi-bin/nm.pl.Network documents protected by user ID and password or other technical means must be deposited by the publisher. The proposal does not require the publisher to provide metadata about the document. Actually the law only says that the publisher is obliged to deposit the publications, but does not define how this is to be done. This will be specified in a separate guide. At the moment the easiest way of organising the delivery is that the publisher sends the material to the library over the Internet. The publisher may of course embed metadata into the document itself, but due to diversity of document formats this option will never be available for all documents. However, due to the recommendation of embedding Dublin Core metadata in public documents, there will be a large number of publications in the Finnish Web which carry their own descriptions in them.
To sum up, the development and use of Dublin Core tools are more relevant to Finland now than than they were in 1996. Important political decisions which guarantee the popularity of Dublin Core have been made, but in order to enable users to provide high quality metadata we need to develop good tools and user guidance. The first Nordic metadata project has built a solid basis from which it will be easy to continue work.
All public project information like reports, user guides etc. has been made available during the project in the Web via the project homepage, URL
http://linnea.helsinki.fi/meta/. The documents were written in English and published in HTML format to maximise the usability of the information in the global Dublin Core community. Documentation of our software tools is also written in English, in order to make the tools easy to implement.According to the server statistics, the project homepage is on the average visited more than 1000 times per month. Many other project pages are quite popular as well - for instance, the Finnish Dublin Core specification was visited 350 times between 20 January and 20 March, 1998.
Internal communication within the project has primarily taken place via an email list (
nordic-metadata@helsinki.fi). In addition to this, five project meetings were held (Stockholm, Copenhagen, Reykjavik, Helsinki and Trondheim). The meetings were usually held in connection with other meetings to save travel costs. For instance, the Helsinki project meeting was arranged the next day after the Dublin Core metadata workshop.Our aim has been to avoid spending resources on project management, and concentrate on practical tasks such as tool development and information dissemination. Due to the active participation of all project partners this has been possible.
Documentation is divided below into documents and project presentations. Due to widespread interest in the project, there have been a lot of activities in both areas. A lot more time was spent on information dissemination than was originally planned, due to demands from our colleagues working in other metadata projects. The work put into articles and lectures, has not been done in vain - the Nordic metadata project is well known among metadata specialists all over the world.
Hakala, Juha [ed.]. The 5th Dublin Core Metadata Workshop, Helsinki, Finland, October 6-8, 1997. Project presentations. Available at:
http://renki.lib.helsinki.fi/meta/projects.htmlHakala, Juha. Dublin Core in 1997. Available at:
http://linnea.helsinki.fi/meta/dcnord.htmlHakala, Juha: Dublin Core Metadata Element Set and it's applications. Available at:
http://linnea.helsinki.fi/meta/present.htmlHakala, Juha: Dublin Core/FINMARC/GILS Crosswalk. Available at:
http://linnea.helsinki.fi/meta/dcficross.htmlHakala, Juha: Internet-resurssien kuvailun ja haun uudet välineet. Tietolinja 1/1998. Available at:
http://renki.lib.helsinki.fi/tietolinja/0198/metadata.htmlHansen, Preben: Information Retrieval and Metadata - Digital Library Activities at SICS. Available at:
http://www-ercim.inria.fr/publication/Ercim_News/enw27/hansen.htmlHansen, Preben: Nordic Metadata creation tool. General help. Available at:
http://www.sics.se/~preben/DC/DC_temp_help.htmlHansen, Preben: User guidelines for Dublin Core creation. Available at:
http://www.sics.se/~preben/DC/DC_guide.htmlHansen, Preben: User guidelines for DC metadata creation. Short version. Available at:
http://www.sics.se/~preben/DC/DC_guide_short.htmlKoch, Traugott: Metadata: References to collections, articles, technical documents. Available at:
http://www.ub2.lu.se/tk/metadata/metadata-general.htmlKoch, Traugott, Husby, Ole and Hakala, Juha (1996). Warwick framework and Dublin core set provide a comprehensive infrastructure for network resource description. Report from the Metadata Workshop II, Warwick,UK, April 1-3, 1996. Available at:
http://www.ub2.lu.se/tk/warwick.htmlLundberg, Sigfrid: Towards the creation of metadata "aware" robot based search services. Available at:
http://www.ub.lu.se/~siglun/anglo-nordic/Project plan. Available at:
http://linnea.helsinki.fi/meta/projplan.htmlThorborg, Susanne: Dublin Core -> DANMARC crosswalk. Available at
http://linnea.helsinki.fi/meta/dcdancr.htmlSome project team members have not provided a list of their presentations, so the list below is only partial.
Hakala, Juha: The Nordic Metadata Project. Presentation in the National metadata workshop arranged by the National Library of Australia, March 6, 1997.
Hakala, Juha: The Nordic Metadata Project. Presentation in the 63rd IFLA General conference August 31 - September 5 1997. Copenhagen, Denmark. Available at:
http://linnea.helsinki.fi/meta/IFLA97pr.htmlHakala, Juha: The Nordic Metadata Project. Presentation in the 5th Dublin Core Metadata Workshop, October 6-8 1997.
Hakala, Juha: The Nordic Metadata Project. Presentation in the Fagreferentkonferansen, March 10-11 1998. Available at:
http://renki.lib.helsinki.fi/meta/nm2/index.htmHakala, Juha: The Nordic Metadata Project. Presentation in Metadatakonferens 4 maj 1998. Available at:
http://renki.lib.helsinki.fi/meta/nm3/index.htm (revised version of the Fagreferentkonferansen –presentation)Husby, Ole: Metadata. Presentation at the ELAG meeting, Gdansk, June 1997. Available at:
http://www.bibsys.no/elag97/metadata.htmlHusby, Ole: The Nordic Metadata Project. DC to MARC conversion. Presentation at the DC-5 workshop, Helsinki, Finland. Slides available at:
http://renki.helsinki.fi/meta/bibsys/index.htmKoch, Traugott: 98-05-15 Univ. of Michigan, Univ. Library and Inst. of Information
EXPERIENCES FROM THE NORDIC METADATA PROJECT.
Koch, Traugott: 98-05-14 Michigan Library Consortium, Lansing, Michigan, USA
Special program: "Metadata and the Dublin Core: Harnessing the Internet Through Bibliographic Control" KEYNOTE SPEAKER.
Koch, Traugott: 98-04-17 International Metadata Day at the WWW 7 Conference, Brisbane, Australia
Presentation and demonstration: METADATA IN EUROPE/SCANDINAVIA
Koch, Traugott: 98-03-04/05 3. InetBib-Tagung, Köln
Conducting the Tutorial: INFORMATIONEN IM WEB ANBIETEN UND WIEDERFINDEN (TUTORIAL FUER FORTGESCHRITTENE PRAKTIKERINNEN)
Program with abstracts
Koch, Traugott: 98-03-03 AKI Stuttgart, Hochschule fuer Bibliotheks- und Informationswesen
Vortrag: MIT ROBOTSOFTWARE UND METADATEN AUF DEM WEG ZUR DIGITALEN BIBLIOTHEK. INFRASTRUKTURPROJEKTE UND STANDARDENTWICKLUNGEN ZUR UNTERSTUETZUNG DER SUCHE IM INTERNET
Announcement and abstract
Koch, Traugott: 98-03-02 MAID, Muenchen, Fachhochschulbibliothek Muenchen
Vortrag: MIT ROBOTSOFTWARE UND METADATEN AUF DEM WEG ZUR DIGITALEN BIBLIOTHEK. INFRASTRUKTURPROJEKTE UND STANDARDENTWICKLUNGEN ZUR UNTERSTUETZUNG DER SUCHE IM INTERNET
Koch, Traugott: 97-10-13/15 Workshop: "MetaData: Qualifying Web Objects", IuK-Kommission
der wissenschaftlichen Fachgesellschaften, Universität Osnabrück, Deutschland.
Presentation and demonstration: METADATA CREATION AND USAGE. APPROACHES AND TOOLS DEVELOPED BY THE NORDIC METADATA PROJECT AND THE EU PROJECT DESIRE
Koch, Traugott: 97-10-09 Nordic Metadata Information Day, Helsinki, Finland.
Presentation and demonstration
Koch, Traugott: 97-10-05/08 DC-5, 5th Dublin Core Metadata Workshop, Helsinki, Finland.
Presentation and demonstration: NORDIC METADATA PROJECT, DUBLIN CORE METADATA CREATOR.
Koch, Traugott: 97-08-29 IFLA Satellite Meeting "Integrated libraries - the Nordic approach", Helsinki. Session on the Library as a Virtual Research and Educational Environment.
Presentation and demonstration: INFRASTRUCTURE AND STANDARDIZATION: IMPROVING RESOURCE DISCOVERY AND RETRIEVAL IN THE ELECTRONIC RESEARCH LIBRARY.
Koch, Traugott: 97-06-29/07-01 NORDUnet '97, 16. NORDUnet conference, Information Services Session, Reykjavik, Iceland.
Presentation: A VIRTUAL LIBRARY MODEL OF DESIRE.
Koch, Traugott: 97-06-05/07 Vilnius University, Lithuania.
Conducting INTERNET WORKSHOP for Lithuanian research libraries, Part 2, advanced level (3 days)
Koch, Traugott: 97-05-20 Deutscher Bibliothekskongress/Bibliotheca. Forum fuer Formal- und Sacherschliessung, Dortmund.
Vortrag und Demonstration: METADATEN UND DUBLIN CORE: Wird das Fahrrad neu erfunden?
Koch, Traugott: 97-05-15 19. Online-Tagung der Deutschen Gesellschaft fuer Dokumentation: "Die Zukunft der Recherche", INFOBASE, Frankfurt/Main. Session: "Digitale Bibliotheksdienste"
Vortrag: VERBESSERUNG DER RECHERCHEMÖGLICHKEITEN IM INTERNET.INTERNATIONALER ÜBERBLICK.
Koch, Traugott: 97-03-19/22 Vilnius University, Lithuania.
Conducting INTERNET WORKSHOP (4 days) for Lithuanian research libraries.
Koch, Traugott: 97-03-03/05 DC-4, 4. Dublin Core Metadata Workshop, Canberra, Australia.
Presentation and demonstration: NORDIC METADATA PROJECT, DUBLIN CORE METADATA CREATOR (with Juha Hakala).
Koch, Traugott: 97-02-24 NOVA Information Gateway conference (Nordic Forestry, Veterinary
and Agricultural University), Frederiksberg, Denmark.
Presentation and discussions: PRESENTATION OF EELS, DESIRE AND NORDIC METADATA PROJECTS.
Koch, Traugott: 97-01-31 "Ressourcekatalogisering og Metadataregistrering - en temadag", Copenhagen, Danmarks Biblioteksskole.
Foeredrag og demonstration: "FORBEDRE DIGITALE DOKUMENTERS SOEGBARHED. NORDIC METADATA PROJECT OG DESIRE".
Koch, Traugott: 96-12-15/17 Workshop "Metadaten und Strukturierung elektronischer Information", Gemeinsame IuK-Initiative Deutscher wissenschaftlicher Fachgesellschaften, Göttingen.
Vortrag und Demonstration: METADATEN UND DUBLIN CORE. EINFUEHRUNG. Vortrag: "NORDIC METADATA PROJECT". Vortrag: EU PROJECT DESIRE.
Koch, Traugott: 96-10-10 NNC Workshop "Nordic Library Projects in the Networking and Digital Library area", Lund
DESIRE: DEVELOPMENT OF A EUROPEAN SERVICE FOR INFORMATION ON RESEARCH AND EDUCATION.
Metadata information day. Lund, October 11, 1996. Access to workshop materials at:
Nordic Metadata Workshop. Helsinki, October 9, 1997. Access to workshop materials at:
Day, Michael: Mapping between metadata formats. Available at: http://www.ukoln.ac.uk/metadata/interoperability/
Dublin Core Homepage. Available at: http://purl.oclc.org/metadata/dublin_core
Knight, Jon & Hamilton, Martin: Dublin Core Standard Resource Types. Available at:
http://www.roads.lut.ac.uk/Metadata/DC-ObjectTypes.htmlMetadata resources. A bibliography provided by IFLA. Available at:
http://www.nlc-bnc.ca/ifla/II/metadata.htmMetadata workshop I. Homepage. Available at: http://purl.oclc.org/oclc/rsch/metadataI
Metadata workshop II. Homepage. Available at: http://purl.oclc.org/oclc/rsch/metadataII
Metadata workshop III (Workshop on Metadata for Networked Images). Homepage. Available at:
http://purl.oclc.org/metadata/imageMetadata workshop IV (3.-5. March 1997). Homepage. Available at: http://www.dstc.edu.au/DC4/
Metadata Workshop V. (Helsinki, 6.-8 October 1997). Homepage. Available at:
http://linnea.helsinki.fi/meta/DC5.htmlA review of metadata: a survey of current resource description formats. DESIRE RE-1004. Available at: http://www.ukoln.ac.uk/metadata/desire/overview/
Description of Dublin Core elements. Available at
http://purl.oclc.org/metadata/dublin_core_elementsHakala, Juha: Dublin Core in 1997: a report from Dublin Core metadata workshops 4 & 5. Available at:
http://renki.lib.helsinki.fi/meta/dcnord.htmlKoch, Traugott [et al.]: Warwick framework and Dublin core set provide a comprehensive infrastructure for network resource description. NORDINFO-Nytt vol. 19 (1996) no. 2 s. 40-48. Available at:
http://www.ub2.lu.se/tk/warwick.htmlMiller, Eric: An Introduction to the Resource Description Framework. D-Lib Magazine, May 1998. Available at:
http://www.dlib.org/dlib/may98/miller/05miller.htmlNetpublikationer: Statens standard for elektronisk publicering. [s.l], Forskningsministeriet, 1997. Available also in electronic form at
http://www.fsk.dk/fsk/publ/online-pub/ (in Danish; with an abstract in English).Syntactic Considerations for the Dublin Core. Available at
http://purl.oclc.org/metadata/dublin_core/syntax.htmlWeibel, Stu and Hakala, Juha: DC-5: The Helsinki Metadata Workshop: A Report on the Workshop and Subsequent Developments. D-Lib Magazine, February 1998. Available at:
http://www.dlib.org/dlib/february98/02weibel.html
1. Title
Label: "Title"
The name given to the resource, usually by the Creator or Publisher.
2. Author or Creator
Label: "Creator"
The person or organization primarily responsible for creating the intellectual content of the resource. For example, authors in the case of written documents, artists, photographers, or illustrators in the case of visual resources.
3. Subject and Keywords
Label: "Subject"
The topic of the resource. Typically, subject will be expressed as keywords or phrases that describe the subject or content of the resource. The use of controlled vocabularies and formal classification schemes is encouraged.
4. Description
Label: "Description"
A textual description of the content of the resource, including abstracts in the case of document-like objects or content descriptions in the case of visual resources.
5. Publisher
Label: "Publisher"
The entity responsible for making the resource available in its present form, such as a publishing house, a university department, or a corporate entity.
6. Other Contributor
Label: "Contributor"
A person or organization not specified in a Creator element who has made significant intellectual contributions to the resource but whose contribution is secondary to any person or organization specified in a Creator element (for example, editor, transcriber, and illustrator).
7. Date
Label: "Date"
A date associated with the creation or availability of the resource. Such a date is not to be confused with one belonging in the Coverage element, which would be associated with the resource only insofar as the intellectual content is somehow about that date. Recommended best practice is defined in a profile of ISO 8601 [Date and Time Formats (based on ISO8601), W3C Technical Note,
http://www.w3.org/TR/NOTE-datetime] that includes (among others) dates of the forms YYYY and YYYY-MM-DD. In this scheme, for example, the date 1994-11-05 corresponds to November 5, 1994.8. Resource Type
Label: "Type"
The category of the resource, such as home page, novel, poem, working paper, technical report, essay, dictionary. For the sake of interoperability, Type should be selected from an enumerated list that is currently under development in the workshop series.
9. Format
Label: "Format"
The data format of the resource, used to identify the software and possibly hardware that might be needed to display or operate the resource. For the sake of interoperability, Format should be selected from an enumerated list that is currently under development in the workshop series.
10. Resource Identifier
Label: "Identifier"
A string or number used to uniquely identify the resource. Examples for networked resources include URLs and URNs (when implemented). Other globally-unique identifiers, such as International Standard Book Numbers (ISBN) or other formal names are also candidates for this element.
11. Source
Label: "Source"
Information about a second resource from which the present resource is derived. While it is generally recommended that elements contain information about the present resource only, this element may contain a date, creator, format, identifier, or other metadata for the second resource when it is considered important for discovery of the present resource; recommended best practice is to use the Relation element instead. For example, it is possible to use a Source date of 1603 in a description of a 1996 film adaptation of a Shakespearean play, but it is preferred instead to use Relation "IsBasedOn" with a reference to a separate resource whose description contains a Date of 1603. Source is not applicable if the present resource is in its original form.
12. Language
Label: "Language"
The language of the intellectual content of the resource. Where practical, the content of this field should coincide with RFC 1766 [Tags for the Identification of Languages,
http://ds.internic.net/rfc/rfc1766.txt ]; examples include en, de, es, fi, fr, ja, th, and zh.13. Relation
Label: "Relation"
An identifier of a second resource and its relationship to the present resource. This element permits links between related resources and resource descriptions to be indicated. Examples include an edition of a work (IsVersionOf), a translation of a work (IsBasedOn), a chapter of a book (IsPartOf), and a mechanical transformation of a dataset into an image (IsFormatOf). For the sake of interoperability, relationships should be selected from an enumerated list that is currently under development in the workshop series.
14. Coverage
Label: "Coverage"
The spatial or temporal characteristics of the intellectual content of the resource. Spatial coverage refers to a physical region (e.g., celestial sector); use coordinates (e.g., longitude and latitude) or place names that are from a controlled list or are fully spelled out. Temporal coverage refers to what the resource is about rather than when it was created or made available (the latter belonging in the Date element); use the same date/time format (often a range) [Date and Time Formats (based on ISO8601), W3C Technical Note,
http://www.w3.org/TR/NOTE-datetime] as recommended for the Date element or time periods that are from a controlled list or are fully spelled out.15. Rights Management
Label: "Rights"
A rights management statement, an identifier that links to a rights management statement, or an identifier that links to a service providing information about rights management for the resource.
The following proposes a core set of qualifiers for the Dublin Core element set. It attempts to find a middle ground between the "minimalists" (those wanting a minimum of DC qualifiers and substructure if any) and the "structuralists" (those wanting more precision in refinement of the elements for searching).
The document has been updated as a result of discussions at DC5 in Helsinki in October 1997. It may be replaced in the near future by the report of the DC5 Subelement Working Group, which discussed the type qualifier. This document also includes information on the scheme qualifier. The concept of a registry was discussed at DC4, which would need to be established and would maintain any qualifier list.
This document deals only with the qualifiers "scheme" and "type". A scheme qualifier is used to interpret the value in the content and is generally based on external standards. A type qualifier refines the definition of the data element itself.
Two principles were agreed upon at the DC4 meeting in Canberra relating to the type qualifier (also known as Dublin Core subelement):
If a Dublin Core subelement does not meet these principles, then an extensibility mechanism may be used (i.e., indicate the extensible element set from which the qualifier came). In this case the metadata would not be regarded as falling within the Dublin Core list of elements.
Further principles for subelements were established at DC5, which will be reported in the Subelement Working Group report. There was little discussion about scheme qualifiers, so that information in this document is preliminary.
Following is a list of qualifiers ("core qualifiers") which is an intermediate approach between the minimalist approach of using no or few qualifiers and the more complex approach in
Dublin Core Qualifiers by Jon Knight and Martin Hamilton. The latter document has been heavily used, but the number of qualifiers is considerably lessened here.Definitions are taken from the Weibel/Kunze/Lagoze RFC
Dublin Core Metadata Element Set: Reference Description (as updated 2 October 1997). All qualifiers are optional. The default for "scheme" is nothing (it is not controlled by any standard). The default for "type" is the definition of the element iteself. If the default is used, no qualifier is given.
1. Title
The name given to the resource by the CREATOR or PUBLISHER.
SCHEME
: not necessaryTYPE
:2. Author or Creator
The person(s) or organization(s) primarily responsible for the intellectual content of the resource. For example, authors in the case of written documents, artists, photographers, or illustrators in the case of visual resources.
SCHEME
:
TYPE:
Note that qualifiers listed in the Knight/Hamilton document extend the element rather than refine it (e.g., postal, phone, fax, affiliation, etc.). Only address is included here because it has been used frequently in current metadata projects. Email may be considered an alternative way of specifying the author. If other qualifiers are needed (e.g. affiliation), they should be used as local extensions.
3. Subject and Keywords
The topic of the resource. Typically, subject will be expressed as keywords or phrases that describe the subject or content of the resource. The use of controlled vocabularies and formal classification schemas is encouraged.
SCHEME
:
The above are the most frequently used. The scheme could point to the controlled list maintained by the Library of Congress in the
4. Description
A textual description of the content of the resource, including abstracts in the case of document-like objects or content descriptions in the case of visual resources.
SCHEME
:
TYPE: not necessary
5. Publisher
The entity responsible for making the resource available in its present form, such as a publishing house, a university department, or a corporate entity.
SCHEME
: not necessaryTYPE
:6. Other Contributor
A person or organization not specified in a creator element who has made significant intellectual contributions to the resource but whose contribution is secondary to any person or organization specified in a creator element (for example, editor, transcriber, and illustrator).
SCHEME
:
TYPE:
At DC4 it was decided that role was not needed. It has thus not been included here. If needed, it could be included as a local extension. (At the Library of Congress, we have found that names are all searched in the same index and there is no need to further specify role in the work. We ceased to indicate this in bibliographic records a long time ago.)
7. Date
Date associated with the creation or availability of the resource.
NOTE that this definition was changed at DC5. The date can be a single date or a range of dates.
SCHEME
:
TYPE: Note that the names of the subelements have not been agreed upon. The Date Working Group continues to work on these. There was some controversy at the end of DC5 as to whether the first two type subelements should be combined. It was also uncertain whether to include the last three subelements.
8. Resource Type
The category of the resource, such as home page, novel, poem, working paper, technical report, essay, dictionary. For the sake of interoperability, type should be selected from an enumerated list that is under development in the workshop series at the time of publication of this document. See
http://sunsite.berkeley.edu/Metadata/types.h tml for current thinking on the application of this element.SCHEME
: not necessary, but an enumerated list of types is.9. Format
The data format of the resource, used to identify the software and possibly hardware that might be needed to display or operate the resource. For the sake of interoperability, format should be selected from an enumerated list that is under development in the workshop series at the time of publication of this document.
SCHEME
:
TYPE: not necessary
10. Resource Identifier
String or number used to uniquely identify the resource. Examples for networked resources include URLs and URNs (when implemented). Other globally-unique identifiers,such as International Standard Book Numbers (ISBN) or other formal names would also be candidates for this element in the case of off-line resources.
SCHEME
:
TYPE: Not necessary
11. Source
A string or number used to uniquely identify the work from which this resource was derived, if applicable. For example, a PDF version of a novel might have a source element containing an ISBN number for the physical book from which the PDF version was derived.
SCHEME
:
TYPE: not necessary
12. Language
Language(s) of the intellectual content of the resource. Where practical, the content of this field should coincide with RFC 1766. See:
http://ds.internic.net/rfc/rfc1766.txtSCHEME
:
TYPE: Not necessary
Note that the current ISO 639 (to become ISO 639-1 when ISO 639-2 3-character code is approved), which is used in RFC 1766, covers only about 140 languages as compared with the newly developed standard ISO 639-2, which includes about 400 languages. (For instance, ISO 639-1 does not distinguish ancient languages from modern languages.) Many agencies will need the larger more extensive list that ISO 639-2 provides. ISO 639-2 was approved in 1997; approval of the Final Draft International Standard is forthcoming followed by publication by ISO. Note that ISO 639-2 includes a bibliographic set (ISO 639-2/B) and a terminologic set (ISO 639-2/T); the bibliographic set is preferred for metadata because of its widespread use in bibliographic agencies. The new standard is closer to Z39.53 than to ISO 639-1.
13. Relation
Relationship to other resources. The intent of specifying this element is to provide a means to express relationships among resources that have formal relationships to others, but exist as discrete resources themselves. For example, images in a document, chapters in a book, or items in a collection. A formal specification of RELATION is currently under development. Users and developers should understand that use of this element should be currently considered experimental.
SCHEME
:
TYPE: This element is considered to be developing rapidly within the context of collection-level descriptions. Subelements may be defined at a later date. The following Relation categories were enumerated at DC5; these should not be considered formal subelement names:
14. Coverage
The spatial and/or temporal characteristics of the resource. Formal specification of coverage is currently under development. Users and developers should understand that use of this element is currently considered to be experimental.
SCHEME
: To be determined by Coverage Working GroupTYPE
: The following were determined by the Coverage Working Group. More information is in http://www.sdc.ucsb.edu/~mary/coverage. htm15. Rights Management
A link to a copyright notice, to a rights-management statement, or to a service that would provide information about terms of access to the resource. Formal specification of rights is currently under development. Users and developers should understand that use of this element is currently considered to be experimental.
SCHEME
:
TYPE: Not necessary; subelements are implementation specific.
Preben Hansen
SICS
This document describe the evaluation and usability study of the Nordic Metadata creation tool and Template and User Guidelines. The document have the following structure:
Introduction: Introduction presents the working task as well as the goal of this study.
Section 1: Quantitative data presents the quantitative data collected in the questionnaire.
Section 2: Qualitative data presents the questions posed to the users as follow-up question to the main questions.
Section 3: Results and conclusions, tries to make some notes on what the problem are and what should be regarded in the redesign of the template and the user guidelines.
Our working requirements for the template and the user guidelines were that they should:
The goal with this study was to investigate:
in order to make suggestions for enhancements for our DC metadata creation tools and documentations.
The evaluation set-up
The design of the evaluation was as follows: First, we decided to make a first preliminary evaluation of the template on a small group of users to verify our questions, to test our approach, and so that misstakes could be avoided in the real evaluation. 8 persons made the test on a mock-up pages of the first version of the metadata template. This guided us to design our questions and areas to be evaluated.
When the preliminary study was done, we started to design the present study. The study contain both quantitative and qualitative data collection methods. One of the reasons for this is that they could be combined. We used both log statistics to measure accesses on the user guidelines, and questionnaires measuring user satisfaction and user preferences. In the questionnaires we used the Likert scale ratings (quantitative) from 1 to 5, where 3 is measured as "somewhat". Each question is followed by a comment field, were the user can make open-ended comments (qualitative).
In the final stage, the questionnaire contained of 5 questions with open-ended fields of comments. Furthermore, there were 2 questions referring to the users preferences such as occupation and metadata knowledge. Finally, there are 3 open-ended fields for comments.
The data were collected during the project period, May 1997 to February 1998.
|
NOVICES |
9 |
|
MEDIUM KNOWLEDGE |
10 |
|
EXPERT KNOWLEDGE |
2 |
|
N = 21 |
|
ACADEMIC (Staff/Researcher |
6 |
29 % |
|
INDUSTRY |
3 |
14 % |
|
INFORMATION SPECIALIST/LIBRARIAN |
6 |
29 % |
|
GOVERNMENT |
1 |
4 % |
|
PRIVATE |
5 |
24 % |
|
|
|
|
|
N=21 |
100% |
|
QUESTION 1 : What do you think of the FUNCTIONALITY that the Nordic DC Metadata creation tool provide (including the resulting metadata description page)? |
1 |
2 |
3 |
4 |
5 |
N |
Mean |
|
ALL USERS |
6 |
2 |
3 |
3 |
7 |
21 |
3.10 |
|
NOVICES |
3 |
1 |
1 |
0 |
4 |
9 |
3.44 |
|
MEDIUM KNOWLEDGE |
3 |
1 |
2 |
1 |
3 |
10 |
3.00 |
|
EXPERT KNOWLEDGE |
0 |
0 |
0 |
2 |
0 |
2 |
4.00 |
|
QUESTION 2 : What did you think of the overall DESIGN of the DC Metadata template? |
1 |
2 |
3 |
4 |
5 |
N |
Mean |
|
ALL USERS |
4 |
1 |
2 |
5 |
9 |
21 |
3.68 |
|
NOVICES |
2 |
0 |
0 |
1 |
6 |
9 |
4.33 |
|
MEDIUM KNOWLEDGE |
2 |
1 |
2 |
3 |
2 |
10 |
3.22 |
|
EXPERT KNOWLEDGE |
0 |
0 |
0 |
1 |
1 |
2 |
5.00 |
|
QUESTION 3 : Did you understand the MEANING of the elements? |
1 |
2 |
3 |
4 |
5 |
N |
Mean |
|
ALL USERS |
0 |
1 |
1 |
7 |
11 |
20 |
4.42 |
|
NOVICES |
0 |
1 |
0 |
4 |
4 |
9 |
4.22 |
|
MEDIUM KNOWLEDGE |
0 |
0 |
1 |
3 |
6 |
10 |
4.55 |
|
EXPERT KNOWLEDGE |
0 |
0 |
0 |
0 |
1 |
1 |
5.00 |
|
QUESTION 4 : Did the User Guidelines provided enough SUPPORT to complete your DC metadata description task? |
1 |
2 |
3 |
4 |
5 |
N |
Mean |
|
ALL USERS |
1 |
1 |
2 |
6 |
10 |
20 |
4.16 |
|
NOVICES |
0 |
1 |
1 |
3 |
4 |
9 |
4.11 |
|
MEDIUM KNOWLEDGE |
1 |
0 |
1 |
3 |
5 |
10 |
4.11 |
|
EXPERT KNOWLEDGE |
0 |
0 |
0 |
0 |
1 |
1 |
5.00 |
|
QUESTION 5 : Are you satisfied with how the template and user guidelines interacted? |
1 |
2 |
3 |
4 |
5 |
N |
Mean |
|
ALL USERS |
1 |
1 |
2 |
2 |
13 |
19 |
4.28 |
|
NOVICES |
0 |
1 |
0 |
2 |
5 |
8 |
4.38 |
|
MEDIUM KNOWLEDGE |
1 |
0 |
2 |
0 |
7 |
10 |
4.11 |
|
EXPERT KNOWLEDGE |
0 |
0 |
0 |
0 |
1 |
1 |
5.00 |
In close connection to every question there was a open-enden comment field for the user to make comments to a follow-up question. They were :
|
Follow-up to QUESTION 1: Which parts did you have any problems with? |
|
Follow-up to QUESTION 2: Which parts was unclear or created problems to understand? |
|
Follow-up to QUESTION 3: Which element caused you any trouble to understand or need more explanation? |
|
Follow-up to QUESTION 4: What kind of support do YOU need to better use the DC metadata creation tool? |
|
Follow-up to QUESTION 5 : What other kind of support do you need? |
|
Additional QUESTION 6 : Are there other facilities you would like to be added to the DC Metadata creation tool and the User Guidelines ? |
|
Additional QUESTION 7: Other comments about DC Metadata creation tool? |
The important results of these open-ended comments will be presented in section 3 : The results below.
One of the main things with an evaluation and usability study is to detect errors and requirements factors from the intended users, as well as to measure the satisfaction with software design.
The evaluation resulted in some valuable information about the design of the template and the user guidelines. 21 users answered the questionnaire and these results should be regarded as indications of what needs to be changed, altered or enhanced. The result tells us which parts that needs more work. The redesign should be iterative as long as this project and task remain.
Users (all users) had a medium levels of satisfaction with the functionality (mean 3.10/5).
The subjects did not have anu problems with the meaning and semantics of the DC elements (4.42/5).
This could be explained by an integration of a satisfactory level of explanation in the user guide documents, a emerging knowledge among users about Dublin Core, and a design that take this in account.
Users had a high satisfaction with both the support they got from the user guides (mean 4.11/5), and the with the interaction between the template and the user guides (mean 4.28/5).
For the future there are 2 remarks to be made: subject categorised as medium knowledgable had a significant lower score than the other groups for a) the functionality of the metadata tool including the resulting metadata description page (Q1, mean 3.00/5)); and b) the overall design of the template (Q2, mean 3.22/5).
Some of the reasons could be seen in the analysis of open-ended question in section 3. Since this group almost constitute 50% of the subjects, it is important to take this into account.
In our study we see that 9 users were novices and 10 users with medium knowledge of DC metadata. Only 2 user said that she had expert knowledge.
Concerning the users occupation we recorded that there were 3 major user groups: academic, information specialists/librarians and private users (with 29, 29 and 24% resp.). 14% of the user came from the industry. Surprisingly, there were a high level of private users and a surprisingly low level of information specialists/librarian users answering the questionnaire than expected. Most of the follow-up comments were made to questions 1, 2 and 4, which focused on the issues on functionality and design of the template.
Q1.
Concerning the question of the functionality within the DC metadata creation tool, there was a mean value of 3.10. Novices had a mean of 3.44 and those with medium knowledge had a lower mean of 3.00, which means that those with medium knowledge were less satisfied with the functionality that novices.
Problems reported in the the open-ended comments to the question:
Q2.
The second question concerned the overall design of the DC metadata template. The mean value was 3.68. Again, novices had a high mean value (4.33) and users with medium knowledge scored for a value of 3.22.
Problems reported:
Q3.
The third question asked the user about the understanding of the meaning of the elements. The question had a general very high value, 4.42, which means that the user had a high level of understanding.Those with medium metadata knowledge had a slightly higher knowledge about the meaning (4.55) than those who were novices (4.22)
Problems reported:
Q4.
The next question asked the user if they found that the user guidelines provided enough instructions and support. At the general level there were a high satisfaction with the user guidelines. At the metadata knowledge level, both the novices and those with medium knowledge had a mean value of 4.11
Problems reported:
Q5.
The last question asked the user if they were satisfied with the interaction between the template and the user guidelines. At the general level, the user showed a high satisfaction (mean value 4.28). The novices had slightly higher satisfaction (4.38) than those users with medium metadata knowledge (4.11).
No special problems were reported.
Finally, Q6 and Q7 made it possible for the user to make general comments. The following important comments were made :
The evaluation of the DC metadata template and creation tool and the user guidelines resulted in a set of requirements that should be considered or implications for the iterative redesign of the tools. As technology changes, the tools and user guidelines need to follow. As humans understanding and learning changes this should also be reflected in the tool and user guidelines.
There is a need to a more detailed look at the design of the template. The evaluation have detected some important factors that need to be taken into concideration, such as
among others.
Last Updated : 1998-05-12
Preben Hansen | preben@sics.se
This is a help page for the Nordic libraries' URN creator provided by the
"Nordic Metadata Project". The syntax of the produced URN's is authorized by the IETF URN WG and the numbering schemes are assigned by the Finnish and Swedish National Libraries.Correct URN's can be acquired using the
Dublin Core metadata template for individual documents or by getting up to 10 URN's from the separate URN creation page. However, the URN's can be used independently from DublinCore and the metadata template.
Version 1.0
3.3.1998
URN's - or Uniform Resource Names - make the identification of Internet documents possible. URN identifiers are persistent and unique: The URN given to a document will never change, if the intellectual content remains the same. A "used" URN will never be given to an another document. URN's can be utilized in Internet information retrieval in many different ways. A URN resolution service will enable users to resolve URN's into URL's or metadata related to the document.
The infrastructure for global URN resolution is not yet in place, nor are the browsers adapted to interoperate with URN resolution services, which may utilise hitherto unknown protocols. Establishment of the URN resolution infrastructure will quite likely require a few years.
All URNs have the following syntax (phrases enclosed in quotes are REQUIRED):
<URN> ::= "URN:" <NID> ":" <NSS>
String "urn:" in the beginning of the URN makes it possible to locate and index URN from anywhere within a document. However, it is better to place the URN not into the text part of the document, but for instance in a HTML document into the META tag of the HEAD.
NID stands for Namespace Identifier. It is a code that identifies the ID system used as URN and facilitates syntactic interpretation of the NSS, Namespace Specific String. In the URN's delivered by the national libraries through this creation tool the NID is NBN, for National Bibliography Number.
NSS is the actual code that persistently and uniquely identifies the document. The syntax of the namespace specific string may be basically anything. In a URN the NBN will always begin with country code and hyphen, followed by additional information. In Finland letters "fe", year (YY) and a number incremented with steps of one is used. An example: fi-fe976238.
An example of a complete Finnish URN: URN:NBN:fi-fe976238
A Swedish example: URN:NBN:se-d199811234
More information about URN's is available from the home page of the URN Working Group; see
http://www.ietf.org/html.charters/urn-charter.htmlURN's based on the NBN's are created by software. The URN generator is available at
The application is capable of delivering URN's for all Nordic countries. A user must first choose a country. the default value is set by the country code of the user's work station's Internet name; e.g. for .fi the default is Finland. Next, the user can choose the number of URN's delivered (max = 10).
The practices according to which URN's are delivered do vary a little from one country to another, but the following principles do generally apply everywhere:
URN:ISBN:<ISBN-number>
URN:ISSN:<ISSN-number>
As a main rule, regular publishers should use URN's in compliance with their profession's established identification systems (e.g. ISBN, BICI, ISSN, SICI). As an alternative to URN these publishers may use DOI (Digital Object Identifier, see
http://www.doi.org/).When you have received an URN, you must paste it into the identified document. Otherwise Web indexing applications like Alta Vista or Nordic Web Index will not be able to utilise the URN's. Indexing will yield reliable results if the URN is placed into the META tag of a HTML document. For best performance it is possible to use the Dublin Core metadata Element Set (see
http://purl.oclc.org/metadata/dublin_core/). When the Identifier tag of the Dublin Core is used, the syntax is the following:<META NAME="DC.Identifier" SCHEME="URN" CONTENT="URN code">
Example:
<META NAME="DC.Identifier" SCHEME="URN" CONTENT="URN:NBN:se-d199811234">, or
<META NAME="DC.Identifier" SCHEME="URN" CONTENT="URN:NBN:fi-fe976242">
If you have many versions of the same document in different formats, they all need an URN. To enable users to find the original (source) version, you should put it's URN into the metadata of derived records. Use Dublin Core Source tag for the source ID. Example:
Creating Dublin Core metadata manually is a complex task. The job can be made a lot easier with a metadata template, which automatizes creation of DC syntax. Such a template, developed in the Nordic Metadata Project, is available at
http://www.lub.lu.se/cgi-bin/nmdc.pl .Your document will have both a unique persistent URN as an identification and one or several URL's as (possibly temporal) location's. You should still use both when citing your document.
The browsers are at the moment not capable to find the document when you put the URN into the Location: box. This is because an international URN resolution infrastructure is not in place yet. If you include the URN into the body text of your document, most major search services will be able to retrieve the document in one or the other way, mostly among other hits. Included into the HTML Head's META tag, the URN will be found only by the very few search services which index such a META tag at the moment. To be future proof and to be found in Nordic Indexes we recommend strongly to provide the URN in the META tag of your document as well.
In the future the Nordic Web Index (NWI) system's national full-text and metadata databases (see for instance Swemeta at
http://nwi.ub2.lu.se/?lang=en will offer you the full and correct searchability of all URN's used in WWW documents published in the respective countries. In those databases you will always be able to look up URN's from these countries. The robots collecting information for those databases will normally find your document after it is published on the net. If you use our DC Metadata creator you can be sure that your document and all metadata connected to it, incl. the URN, will be indexed correctly a few days later.When URN's are used on a broader scale, you can expect most search services to be able to find your URN. The URN's we are providing now are authorized and will always be valid. The final step in this development will be that URN's replace the URL's when you are looking for a document and will click on them and put them into "Location" boxes as you do now with URL's. The big difference will be, that URN's will always give you the right document independent of its actual location. In some cases this will be accomplished using WWW archives like the Swedish Kulturarw3 and the Finnish EVA.
Here we intend to publish answers to frequently asked questions.
Since the release of the newest version (Five months between Dec 2, 1997 and May 3, 1998) the template has been visited 7421 times by 3554 distinct hosts, an average of 49 per day. The visitors are from 64 domains/countries. The number of visits has been increasing during Spring, from about 1100 to about 1900 visits per month.
Domain report visitors (Dec 2, 1997 - May 3, 1998)
Printing all domains, sorted by amount of traffic.
Printing all requested subdomains with at least 0.5% of the traffic.
#reqs : %bytes : domain
------- -------- ------
1805 : 23.62% : [unresolved numerical addresses]
883 : 12.64% : .se (Sweden)
( 69): ( 1.04%): lub.lu.se
( 125): ( 1.90%): ub2.lu.se
598 : 7.62% : .com (Commercial (mainly USA))
465 : 6.75% : .no (Norway)
470 : 6.59% : .fi (Finland)
492 : 6.50% : .au (Australia)
457 : 6.45% : .edu (USA Educational)
431 : 5.82% : .net (Network)
356 : 4.76% : .de (Germany)
342 : 4.72% : .dk (Denmark)
134 : 1.75% : .org (Non-Profit Making Organisations)
134 : 1.58% : .es (Spain)
103 : 1.43% : .uk (United Kingdom)
103 : 1.37% : .ca (Canada)
96 : 1.09% : .fr (France)
81 : 0.99% : .gov (USA Government)
57 : 0.85% : .nl (Netherlands)
42 : 0.64% : .ch (Switzerland)
41 : 0.56% : .jp (Japan)
45 : 0.55% : .it (Italy)
30 : 0.44% : [unknown]
23 : 0.35% : .nz (New Zealand)
29 : 0.35% : .su (Former USSR)
21 : 0.29% : .us (United States)
12 : 0.18% : .be (Belgium)
11 : 0.15% : .ie (Ireland)
12 : 0.14% : .my (Malaysia)
13 : 0.12% : .pt (Portugal)
9 : 0.12% : .at (Austria)
9 : 0.12% : .kr (South Korea)
8 : 0.11% : .hk (Hong Kong)
8 : 0.09% : .th (Thailand)
6 : 0.09% : .il (Israel)
6 : 0.09% : .is (Iceland)
6 : 0.09% : .ru (Russian Federation)
7 : 0.09% : .gr (Greece)
5 : 0.08% : .ar (Argentina)
5 : 0.06% : .ee (Estonia)
7 : 0.06% : .cz (Czech Republic)
5 : 0.06% : .mil (USA Military)
5 : 0.06% : .sg (Singapore)
3 : 0.05% : .ae (United Arab Emirates)
3 : 0.05% : .int (International)
4 : 0.05% : .br (Brazil)
3 : 0.05% : .in (India)
3 : 0.05% : .lu (Luxembourg)
4 : 0.05% : .uy (Uruguay)
2 : 0.03% : .ve (Venezuela)
2 : 0.03% : .pl (Poland)
3 : 0.03% : .lv (Latvia)
3 : 0.03% : .za (South Africa)
3 : 0.03% : .mx (Mexico)
2 : 0.03% : .np (Nepal)
1 : 0.02% : .fo (Faroe Islands)
1 : 0.02% : .pk (Pakistan)
1 : 0.02% : .si (Slovenia)
1 : 0.02% : .cy (Cyprus)
1 : 0.02% : .eg (Egypt)
1 : 0.02% : .hu (Hungary)
1 : 0.02% : .na (Namibia)
1 : 0.02% : .sk (Slovak Republic)
1 : 0.02% : .id (Indonesia)
3 : 0.02% : .tw (Taiwan)
1 : : .cn (China)
1 : : .jm (Jamaica)
----------
One out of 4-5 visits results in the production of a metadata output file, 10 per day, 3 files per host. The producers are
from 28 different domains/countries.
Domain report producers (Dec 2, 1997 - March 17, 1998)
Printing all domains, sorted by amount of traffic.
Printing all requested subdomains with at least 0.5% of the traffic.
#reqs : %bytes : domain
------- -------- ------
266 : 28.87% : [unresolved numerical addresses]
136 : 11.49% : .se (Sweden)
( 10): ( 0.52%): lub.lu.se
( 17): ( 2.42%): ub2.lu.se
136 : 11.06% : .no (Norway)
63 : 9.18% : .fr (France)
63 : 6.80% : .edu (USA Educational)
57 : 5.32% : .fi (Finland)
38 : 4.61% : .net (Network)
45 : 4.54% : .au (Australia)
53 : 4.26% : .de (Germany)
26 : 2.77% : .dk (Denmark)
31 : 2.72% : .com (Commercial (mainly USA))
23 : 2.09% : .nl (Netherlands)
17 : 1.50% : .su (Former USSR)
8 : 0.73% : .uk (United Kingdom)
8 : 0.60% : [unknown]
12 : 0.58% : .org (Non-Profit Making Organisations)
5 : 0.48% : .gov (USA Government)
5 : 0.39% : .es (Spain)
6 : 0.39% : .ch (Switzerland)
6 : 0.38% : .jp (Japan)
3 : 0.34% : .mil (USA Military)
2 : 0.22% : .nz (New Zealand)
3 : 0.16% : .ca (Canada)
1 : 0.12% : .ar (Argentina)
1 : 0.12% : .hk (Hong Kong)
2 : 0.08% : .pt (Portugal)
1 : 0.07% : .na (Namibia)
1 : 0.06% : .it (Italy)
1 : 0.05% : .is (Iceland)
-------
A random month (April) this Spring shows 406 completed usages of the template, which means delivery of the resulting DC code. The users that month come from 22 major domains/countries around the world, besides the Nordic countries and Europe: Australia/New Zealand, USA, Canada, India and the .com, .net and .org domains. Predominating user communities seem to be libraries, National libraries, universities and governmental agencies and individuals without obvious connection.
*About 40% of the users come from Nordic country sites.
*According to Alta Vista and HotBot about 75 sites are citing/pointing to our DC metadata creator template (both services together know according to recent studies only about half of the worlds web pages, and representation of minor language areas is worse than the average).
As one of the tasks carried out for the
"Nordic Metadata Project" , NetLab is collecting metadata usage data from HTML pages published in the Nordic countries.140 071 WWW-pages use META tags(=8,1%). 39 481 or 28 % of those carry "meaningful" metadata (=2,3 % of all pages) and are collected in the Danmeta database. 569 WWW-pages (=1,4 % of 39 481 total pages with meaningful metadata) are using any Dublin Core META tag.
403 324 WWW-pages use META tags(=21%, compared to 10% in April 1997). 151 874 or 37 % of those carry "meaningful" metadata (= 7,5 % of all pages) and are collected in the Swemeta database. More than 1 500 WWW-pages (about 1 % of 150 000 total pages with meaningful metadata) are using any Dublin Core META tag.
104 428 pages carry "meaningful" metadata (=6 % of all pages) and are collected in the Danmeta database. 815 WWW-pages (=0,8 % of the pages with meaningful metadata) are using any Dublin Core META tag.
Link to the "Nordic Metadata Project" home page.
Traugott Koch (Traugott.Koch@ub2.lu.se)
"Lund University Electronic Library", Development Dept. NetLab
Created: 1997-10-01
Last update: 1998-05-08
URL: http://www.ub2.lu.se/metadata/Nordic-MDusage.html
(C) Copyright
Juha Hakala
Automation Unit of Finnish Research Libraries
Helsinki University Library
juha.hakala@helsinki.fi
Changes:
Version 1.2:245 $b specification, 001 generation for ISO2709 from DC Resource Identifier data, specification of 021 $c usage, handling of duplicate Resource Identifier tags with the same Scheme information.
Version 1.3: Specification of URN conversion.
This document relies heavily on the Dublin Core/MARC/GILS crosswalk document developed by the Library of Congress (see
http://lcweb.loc.gov/marc/dccross.html).The following is a crosswalk between the fifteen elements in the
Dublin Core Element Set on the one hand and both FINMARC bibliographic data elements and GILS attributes on the other. The crosswalk may be used in conversion of metadata from some other syntax into MARC. For conversion of MARC into Dublin Core, many fields would be mapped into a single Dublin Core element; this is not entirely covered in this document.In the Dublin Core to FINMARC mapping, in some cases there are two mappings provided. The first is a simple mapping and is used if the Dublin Core elements are used without qualifiers. The second is for a more complex description for which the elements have qualifiers. There could be a mixture, but if the particular element is unqualified, then the simple mapping for that element should be used. Certain defaults have been assumed as to definitions and qualifiers; if this changes the list will need to be adjusted. This list has been made consistent with the GILS/MARC mapping where possible. Where applicable, subfields are given.
Earlier metadata workshops supported the notion of defining qualifiers and subelements for elements when more complex descriptions are needed, but the list of qualifiers is not entirely agreed upon. When the list of qualifiers becomes standardized it will be necessary to modify this document and add to it as appropriate. Only the most obvious qualifiers have been included now. The crosswalk will be modified after qualifiers have become more standardized.
FINMARC fields are listed with field number, then in parentheses field name/subfield name (if both are the same, no subfield name is included). If the value of the indicator is not provided, use a blank (H'20'). The label is a shortened form of the element name. GILS attribute names for each Dublin Core element are also given. Definitions are taken from Dublin Core Metadata Element Set: Reference Description (see
http://purl.org/metadata/dublin_core_elements).It is possible that conversion produces several instances of the same field. This is OK for e.g. 700, 710 and 720, but only one 100 tag is allowed.
Title
The name given to the resource by the CREATOR or PUBLISHER.
FINMARC
:If the element is repeated in the DC record, all titles after the first: 245$r (Parallel Title/Title proper) If there is a string " : " or ": " in the data, it should be generated into " $b ".
GILS
:Author or Creator
The person(s) or organization(s) primarily responsible for the intellectual content of the resource. For example, authors in the case of written documents, artists, photographers, or illustrators in the case of visual resources. Qualifier possible: type.
FINMARC
:If the Author element is repeated in the DC record, the data from repeats should go either to 700$a and $h or 710$a (see contributor tag for details) or 720$a and $h, depending on the type values.
GILS
:Subject and Keywords
The topic of the resource, or keywords or phrases that describe the subject or content of the resource. The intent of the specification of this element is to promote the use of controlled vocabularies and keywords. This element might well include scheme-qualified classification data (for example, Library of Congress Classification Numbers or Dewey Decimal numbers) or scheme-qualified controlled vocabularies (such as MEdical Subject Headings or Art and Architecture Thesaurus descriptors) as well. Qualifier possible: scheme.
FINMARC
:GILS
:Description
A textual description of the content of the resource, including abstracts in the case of document-like objects or content descriptions in the case of visual resources. Future metadata collections might well include computational content description (spectral analysis of a visual resource, for example) that may not be embeddable in current network systems. In such a case this field might contain a link to such a description rather than the description itself.
FINMARC
:GILS
:Publisher
The entity responsible for making the resource available in its present form, such as a publisher, a university department, or a corporate entity. The intent of specifying this field is to identify the entity that provides access to the resource.
FINMARC
:GILS
Other Contributors
Person(s) or organization(s) in addition to those specified in the CREATOR element who have made significant intellectual contributions to the resource but whose contribution is secondary to the individuals or entities specifed in the CREATOR element (for example, editors, transcribers, illustrators, and convenors). Qualifier possible: type.
FINMARC
:GILS
Date
The date the resource was made available in its present form. The recommended best practice is an 8 digit number in the form YYYYMMDD as defined by ANSI X3.30-1985. In this scheme, the date element for the day this is written would be 19961203, or December 3, 1996. Many other schema are possible, but if used, they should be identified in an unambiguous manner. Qualifier possible: type
FINMARC
:GILS
Resource Type
The category of the resource, such as home page, novel, poem, working paper, technical report, essay, dictionary. It is expected that RESOURCE TYPE will be chosen from an enumerated list of types. A preliminary set of such types can be found at the following URL: http://www.roads.lut.ac.uk/Metadata/DC-ObjectTypes.html.
FINMARC
:GILS
Format
The data representation of the resource, such as text/html, ASCII, Postscript file, executable application, or JPEG image. The intent of specifying this element is to provide information necessary to allow people or machines to make decisions about the usability of the encoded data (what hardware and software might be required to display or execute it, for example). As with RESOURCE TYPE, FORMAT will be assigned from enumerated lists such as registered Internet Media Types (MIME types). In principal, formats can include physical media such as books, serials, or other non-electronic media.
FINMARC
:If MARBI accepts a proposed modification of USMARC, this tag may be later replaced by:
GILS:
Resource Identifier
String or number used to uniquely identify the resource. Examples for networked resources include URLs and URNs (the latter will hopefully replace the former as an identifier in the long run). Other globally-unique identifiers,such as International Standard Book Numbers (ISBN) or other formal names would also be candidates for this element. Qualifier possible: scheme.
FINMARC
:When generating exchange records, the ID's based on the following systems should be converted also to the 001 tag: NBN, ISBN, ISRC, ISMN and ISRN.
If the converter has means of checking validity of ISBN and other established codes, and finds that the ID is not correct, the conversion is done to subfield $c in respective tag.
If NBN, ISBN, ISRC, ISMN or ISRN data is repeated in the DC record, all occurrences after the first one are ignored.
URN's are always based on other identifiers like NBN's or ISBN's. It is possible to extract the basic ID from URN string. For URN's based on NBN's, this is done by stripping string "URN:NBN:fi-" from the beginning of the URN; the rest may be placed into 015$a.
GILS:
Source
The work, either print or electronic, from which this resource is derived, if applicable. For example, an html encoding of a Shakespearean sonnet might identify the paper version of the sonnet from which the electronic version was transcribed.
FINMARC
:GILS:
Language
Language of the intellectual content of the resource. Where practical, the content of this field should coincide with the Z39.53 three character codes for written languages. Qualifier possible: scheme.
FINMARC
:GILS:
A three-character language code standard is currently under development as: ISO 639-2 (not yet available electronically)
Relation
Relationship to other resources. The intent of specifying this element is to provide a means to express relationships among resources that have formal relationships to others, but exist as discrete resources themselves. For example, images in a document, chapters in a book, or items in a collection. A formal specification of RELATION is currently under development. Users and developers should understand that use of this element should be currently considered experimental. Possible qualifiers: scheme, type.
FINMARC
:GILS:
Coverage
The spatial locations and temporal durations characteristic of the resource. Formal specification of COVERAGE is currently under development. Users and developers should understand that use of this element should be currently considered experimental. Possible qualifier: type.
FINMARC
:GILS
:Rights Management
The content of this element is intended to be a link (a URL or other suitable URI as appropriate) to a copyright notice, a rights-management statement, or perhaps a server that would provide such information in a dynamic way. The intent of specifying this field is to allow providers a means to associate terms and conditions or copyright statements with a resource or collection of resources. No assumptions should be made by users if such a field is empty or not present. Qualifiers possible: URL, URN. Nota bene: not available in the Nordic Metadata template yet (will be added shortly).
FINMARC
:
GILS:
In addition to the variable length fields listed in the mapping, a FINMARC record will also include a Leader and field 008 (Fixed-Length Data Elements). Certain character positions in each of these fixed length fields of a FINMARC record will need to be coded, although most will generate default values.
Leader:
a fixed field comprising the first 24 character positions (00-23) of each record that provides information for the processing of the record. The following positions should be generated:Character Position 06: Type of record
008 Fixed Length Data Elements:
Forty character positions (00-39) containing positionally-defined data elements that provide coded information about the record as a whole or about special bibliographic aspects of the item being cataloged. For records originating as Dublin Core, the following character positions are used:A mapping between the elements in the Dublin Core and FINMARC fields is necessary so that conversions between various syntaxes can occur accurately. Once Dublin Core style metadata is widely provided, it might interact with MARC records in various ways such as the following:
Enhancement of simple resource description record.
A cataloging agency may wish to extract the metadata provided in Dublin Core style (presumably in HTML or SGML) and convert the data elements to MARC fields, resulting in a skeletal record. That record might then be enhanced as needed to add additional information generally provided in the particular catalog.Searching across syntaxes and databases.
Libraries have large systems with valuable information in MARC bibliographic records (which may also be called metadata). Over the past few years with the expansion of electronic resource over the Internet, other syntaxes have also been considered for providing metadata. The Library of Congress has worked with a group of SGML experts to create a Document-Type Definition (DTD) for MARC, so that conversions can be made between SGML and MARC in a standardized way. It will be important for systems to be able to search metadata in different syntaxes and databases and have commonality in the definition and use of elements.