|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
September/October 2012
Volume 18, Number 9/10
Fulltext Geocoding Versus Spatial Metadata for Large Text Archives: Towards a Geographically Enriched Wikipedia
Kalev H. Leetaru
University of Illinois
Kalev.leetaru5@gmail.com
doi:10.1045/september2012-leetaru
Abstract
The rise of "born geographic" information and the increasing creation and mediation of information in a spatial context has given rise to a demand for extracting and indexing the spatial information in large textual archives. Spatial indexing of archives has traditionally been a manual process, with human editors reading and assigning country-level metadata indicating the major spatial focus of a document. The demand for subnational saturation indexing of all geographic mentions in a document, coupled with the need to scale to archives totaling hundreds of billions of pages or those accessioning hundreds of millions of new items a day requires automated approaches. Fulltext geocoding refers to the process of using software algorithms to parse through a document, identify textual mentions of locations, and using databases of places and their approximate locations known as gazetteers, to convert those mentions into mappable geographic coordinates. The basic workflow of a fulltext geocoding system is presented, together with an overview of the GNS and GNIS gazetteers that lie at the heart of nearly every global geocoding system. Finally, a case study comparing manually-specified geographic indexing terms versus fulltext geocoding on the English-language edition of Wikipedia demonstrates the significant advantages of automated approaches, including finding that previous studies of Wikipedia's spatial focus using its human-provided spatial metadata have erroneously identified Europe as its focal point because of bias in the underlying metdata.
The Importance of Space
The concepts of space and time are perhaps the most fundamental organizing dimensions of large archives, forming the root structure around which all other categories are situated. (Bellomi & Bonato, 2005) Space, in particular, is an integral part of human communication: every piece of information is created in a location, intended for an audience in the same or other locations, and may discuss yet other locations. Daily communication about the world revolves around space: the global news media, for example, mentions a location every 200-300 words, more than any other information type. (Leetaru, 2011) Even access to information is mediated heavily by space, with over a quarter of web searches containing geographic terms and 13% of all web searches being primarily geographic in nature. (Gan et al, 2008)
Yet, despite its prominent role in organizing the world's information streams, space has traditionally been exposed in document archives only through the lens of human-assigned metadata such as a document's author or publisher location, or geographic indexing terms like the Library of Congress Subject Headings. In the case of author or publisher location, the metadata doesn't reflect the actual spatial focus of the work, while in the case of geographic indexing terms, they usually capture only the most prominent focal locations, and usually only at the country level. A subject entry for agriculture in the "United States", for example, does little to assist a searcher looking for information on historical agricultural trends in a particular region of Arizona. Indexing terms also focus only on the primary subjects of a work and thus are unlikely to mention an isolated paragraph buried deep in a book on the US cotton industry comparing growing conditions in Texas to those in Cameroon. The alterative of manually compiling a list of every city and landmark in the region of interest into a massive Boolean keyword search potentially reaching thousands or tens of thousands of terms is simply intractable.
As information increasingly becomes produced and accessed at the level of individual messages rather than as holistic documents, (Leetaru & Olcott, 2012) users are increasingly attempting to access this information at more and more precise geospatial resolutions. For example, with the rise of mobile devices and location-aware information systems, a growing percentage of information is being born "geographically native" with precise coordinates indicating its origins. From geotagged tweets to Facebook and Foursquare "check-ins," users are becoming accustomed to seeing, accessing, and searching information in space. Just as Google Maps brought geospatial representation to the masses, the rise of geographically native information sources has led to an increasing demand for being able to access the geospatial information in legacy collections and formats in the same fashion. This demand is driving a revolution of sorts in the area of "fulltext geocoding," in which software tools are being used to geographically enrich large text archives, automatically identifying, disambiguating, and converting geographic references in textual documents into precise geographic coordinates for mapping and searching.
Current Approaches
The traditional approach of using trained human editors to read each document (or sometimes just its title or abstract) and manually assign geographic tags simply isn't scalable to the size and velocity of modern archives, which may contain hundreds of billions of pages with millions of new pages added each day. In addition, manual geographic tags can only index the primary focal points of a document: it simply isn't feasible for a human indexer to index every single mention of a location across a 600-page book. Automated software algorithms are therefore replacing human indexers as the primary mechanism for geographic indexing of large text archives.
The most common approach, used by toolkits such as General Architecture for Text Engineering (GATE), is to simply perform a keyword search for the names of countries, their capitals, and major cities. While very easy to implement and fast to run, this approach is problematic for a variety of reasons. One of the greatest limits is that many documents, especially news articles, assume their intended readers share common background knowledge about locations. A local newspaper in Champaign, Illinois, for example, when referencing the neighboring city of Urbana, simply mentions "Urbana", rather than "Urbana, Illinois, United States of America." Thus, searches for country names or even the names of administrative divisions like US states, will miss many mentions entirely. Garbin & Mani (2005) found that 68% of mentions of US cities did not include the state name or other contextual information in the vicinity. Even when a match is found, the resulting geographic index permits only country-level searches, while users are increasingly interested in subnational information. Finally, not all country names are unambiguous: "Georgian authorities" could refer to either the US state or the country in Europe.
Thus, the emerging area of fulltext geocoding, also known as "geoparsing", or "Geographic Information Retrieval" (GIR) was born. At its core, fulltext geocoding involves scanning a body of text to identify potential geographic references and then using an external knowledgebase, called a "gazetteer," and document context to disambiguate and convert the references to a geospatial form. (Hill, 2006) Disambiguation is a critical component of geocoding, determining which of the 41 locations on Earth named "Cairo" a given mention refers to and ultimately translating that textual reference into an approximate latitude and longitude for mapping and analysis. GIR actually refers to the entire pipeline of extracting geographic referents from text, indexing them into a spatial index, and allowing spatial search of a corpus using the spatial information. This paper will focus only on the first stage, translating text into geography. Most geocoding systems focus on precise location mentions like "Cairo", though there is emerging work on regional descriptions like "the south eastern portion of the country" or vague mentions like "three days hike north of the river's mouth".
There are a number of commercial tools available for fulltext geocoding. MetaCarta is perhaps the best-known and is widely used by the US Government and companies, but is focused primarily on contemporary geographies and is extremely expensive. Yahoo!'s Placemaker service is a hosted API platform that offers free processing, but is limited to documents less than 50K in length. (Placemaker) While Yahoo! currently states there are no formal limits on the number and speed at which documents may be processed, it does restrict usage to a "reasonable volume," (Yahoo!) meaning it is unlikely that it would permit geocoding of millions of pages of material. In addition, most systems are black boxes, meaning they can't be modified or expanded over time to address specific nuances of the underlying data collection or to improve their accuracy.
Building a Fulltext Geocoder: The Basic Algorithm
This section outlines the workflow and core elements of a fulltext geocoder and presents an efficient scalable algorithm for fulltext geocoding that will be applied to the full four million entries in the English-language Wikipedia.
Identifying Potential Candidates
The first stage of a fulltext geocoder is to parse the document text to identify words and phrases that may potentially be geographic references. The most basic approach is to extract all capitalized phrases preceded by a "trigger word" like "in" or "near." (Morton-Owens, 2012) Locations are traditionally capitalized, so this simplifies trying to identify the start and end of a potential location mention, but trigger words may generate many false positives such as "in God" or "near Death" and trigger words are not as common in certain types of writing styles. For example, social media postings often lack trigger words and in many cases may be in all lower case. Document titles may be in all capital letters, further confusing this method, while many names contain lower-case components such as "de la" or "el." A more sophisticated approach, used by most systems, (Lieberman & Samet, 2011) is to apply Part of Speech Tagging (Brill, 1992) to identify groups of nouns, known as "noun phrases." This has the benefit of identifying names that are not capitalized, but requires significantly more processing time due to the complexity of speech tagging. Many location names also include common words that are adjectives, verbs, pronouns and other parts of speech as part of the name, such as "Matsayit Nu Run I Man" in Thailand, which can cause the tagger to split the name into pieces. In addition, documents written by non-native English speakers or that have been translated can cause errors in the speech tagging process. Finally, part of speech taggers are only available for a small number of languages, restricting this approach to major languages like English and Spanish.
In contrast, the algorithm used in this study does the opposite: instead of extracting potential geographic names from the text, it eliminates all of the text that cannot be a location. To do this, several standard Linux spell-checker dictionaries were combined to generate a list of all common English words. These were compared against the geographic gazetteers (described in more detail later in this section) to remove all words that are also a location name or part of a location name. The end result is a list of non-geographic words. The source document text is first compared against this list and all matching words are converted to a period so that a sentence like "in Canada yesterday we went to the store" becomes ". Canada . . . . . .".
Some common English words can also appear as part of a location, such as the word "run." To address these, a list of all words that appeared in the English dictionaries and also in one or more geographic names was used to compile a list of ambiguous words. The English edition of Wikipedia was then searched to compile a list of all matches of each word and to calculate what percentage of those appearances were capitalized versus lowercase. This is stored in a probability table that is used in the next stage.
Checking Candidates for Potential Matches
Once the list of potential geographic names is compiled, the next step is to search those for unambiguous references like certain country names and capital and major cities. Mentions of nationalities like "French" are treated as mentions of the corresponding country with the sole exceptions of "Indian", which is often used to refer to indigenous populations around the world, and "English", which is used more often to refer to the language than to the British people. For ambiguous references like "Washington" (which could be either the US state or the capital of the country) or "Georgia" (which could be the US state or country in Europe), the system records both possibilities as matches and then returns at the end of the geocoding process to determine if any cities were found from one of the possible matches and removes the matches if not. If an article mentions Georgia and then subsequently also references Atlanta, the system will save the match to the US state and discard the country match.
If a candidate is not found to be a country, capital, or major city, it is then checked to see if there is any location worldwide with that name. If there is any location by that name, the candidate is saved as a possible match and forwarded to the next stage. If no match is found, the system uses the probability lookup table from earlier to examine the first and last words of the candidate. The word with the highest percentage of its appearances in Wikipedia being in lowercase is dropped off the candidate and it is retried. To demonstrate how this process works, when presented with the candidate "New York City Police Station", the system finds no match and then compares the first word, "new" and last word "station" and finds that "station" appears in Wikipedia in lowercase more often than uppercase. It then drops station to generate the new candidate phrase "New York City Police". This, too, fails to match, so "new" is compared against "police", with police being dropped, yielding a new candidate of "New York City", which ultimately matches.
The system also compiles a list of person names in the text using a separate algorithm and drops location candidates that are also person names. This prevents a mention of "Paris Hilton" from matching Paris, but does allow "the Hilton hotel in Paris" to match. Finally, a manually-compiled "blacklist" is used to drop out locations with high false positive rates. For example, while a mention of "God" could indeed refer to the city in Ethiopia, or "Hell" to the city in the United States, the overwhelming majority of appearances of these names are not in reference to a location on Earth and so the manual blacklist allows these common false positives to be removed. Similarly, some countries have locations that are also named after famous people or organizations, such as Castro, Cuba, or Duma, Russia, which are also placed into the blacklist.
Gazetteers: GNS and GNIS
In order to identify whether a given candidate may be a location on earth, a database is needed that records a list of the names of all known places on earth and their approximate locations, known as a "gazetteer". A number of country-specific gazetteers provide high resolution coverage of their land areas. The Australian Government provides a database of 322,000 locations in Australia, (Australia Search) while Canada's government offers a similar database of 350,000 locations. (Canada) Global gazetteers pool together all available geographic information on the world into a single database. The Getty Thesaurus of Geographic Names (Getty) contains over 1 million entries on around 900,000 distinct places on earth, including historic names back to at least Roman times. The Alexandria Digital Library Project (ADL) gazetteer has 5.9 million names in its database. (Alexandria) The GeoNames.org website pools together as many country gazetteers as possible to offer a database of around eight million placenames.
Yet, perhaps the two most famous gazetteers, which actually form the core of most others, are the United States National Geospatial-Intelligence Agency's GEOnet Names Server (GNS) (NGA) and the United States Geological Survey's Geographic Names Information System (GNIS). (BGN) Each entry includes the name of the feature, its "type" (city, mountain, river, etc.), its higher order administrative division (such as US state), and the centroid latitude and longitude of the location in order to place it approximately on a map. The GNS catalog includes only locations outside of the United States and its territories and contains 8,558,755 entries describing a total of 5,394,250 geographic features in 5,057,418 distinct locations (unique latitude/longitude pairs). Some places have multiple local alternative or historical names, such as "Peking" (Beijing) or "White Russia" (Belorussia), and GNS records these as references to its contemporary formal name, together with alternative transliterations of names from non-Latin languages. More than half of the catalog is devoted to human population centers like cities, towns, and villages, with 4,556,986 populated place entries describing a total of 2,814,515 distinct features in 2,703,352 locations. GNS includes a special gazetteer covering Antarctica, but many of those locations are named after famous persons and would thus result in a high false positive rate and since few geocoding tasks involve processing names from Antarctica, it has not been included in this study.
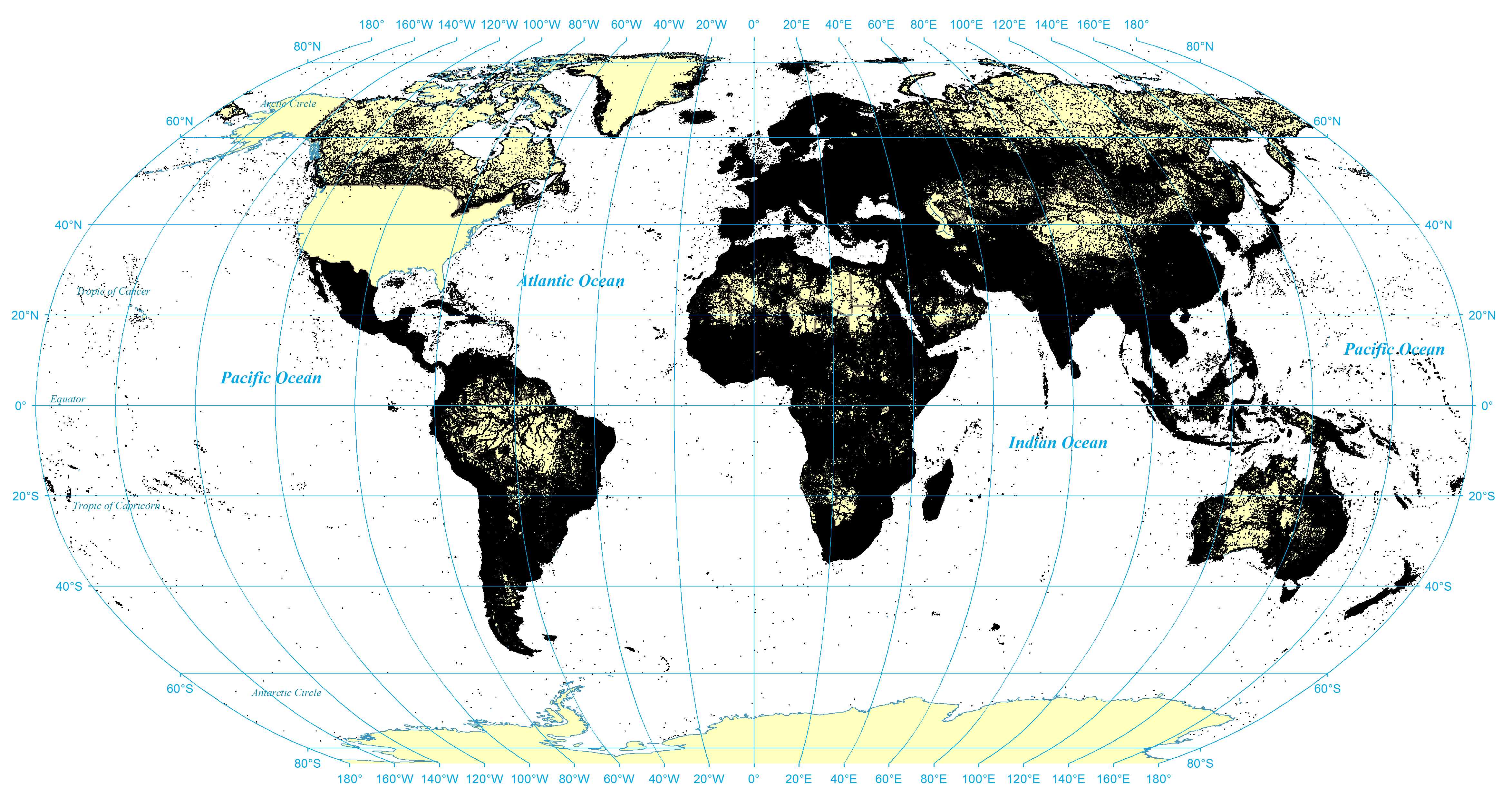
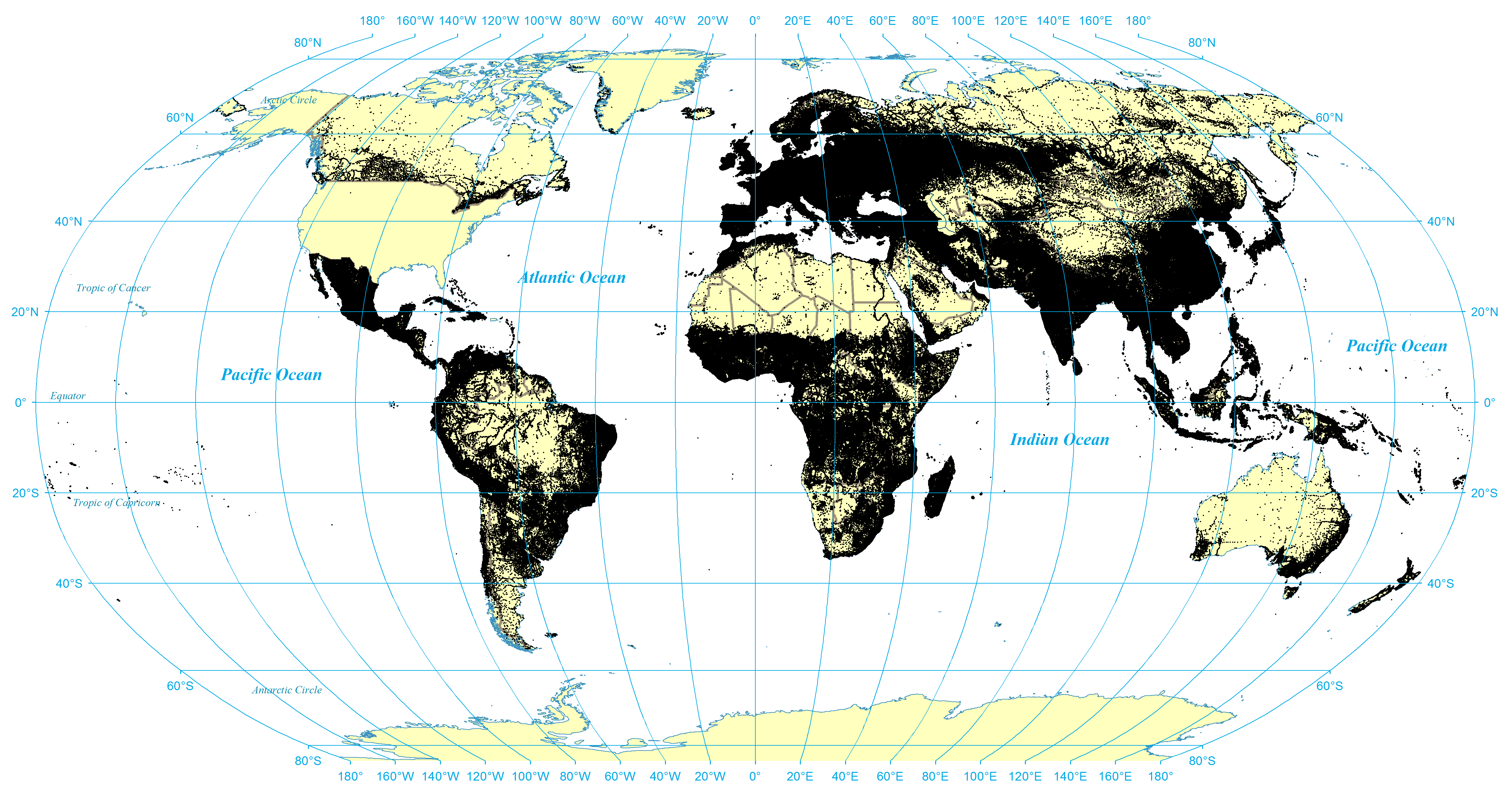
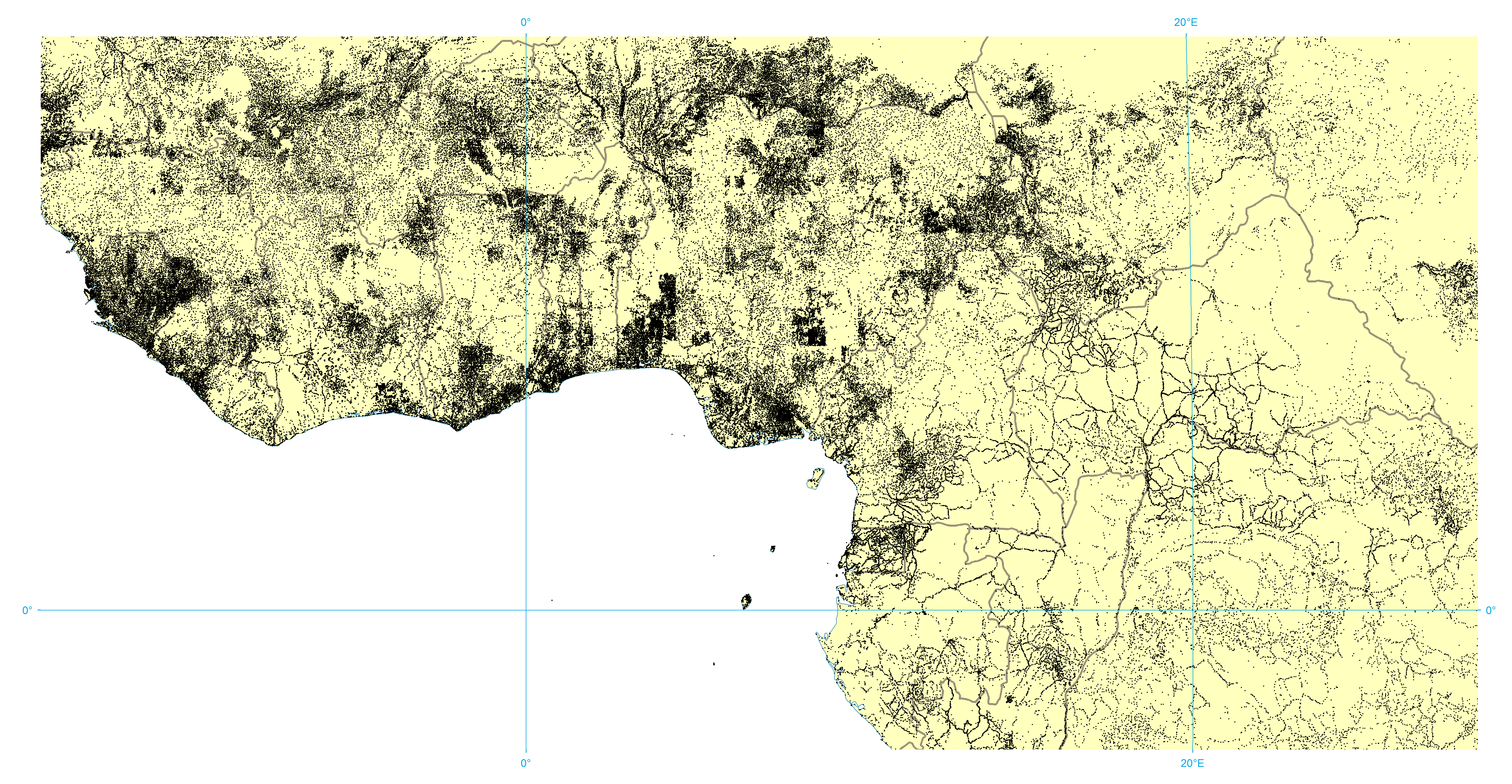
Figure 1 shows the distribution of the entirety of GNS' coverage of the world, while Figure 2 shows the distribution of populated places recorded in GNS. Given the high density of places recorded for many countries, large areas of the map appear largely as a black blob. Figure 3 therefore shows a zoom-in of a corner of Western Africa, centered on Nigeria, showing the fine level of detail contained in the gazetteer and the different geospatial layouts of human civilization.

Figure. 1: All geographic locations recorded in the GNS gazetteer
View a higher resolution version of this figure here.
{kind=link}

Figure 2: All populated place locations recorded in the GNS gazetteer
View a higher resolution version of this figure here.
{kind=link}

Figure 3: Zoom up of GNS populated place locations in Western Africa, centered on Nigeria
View a higher resolution version of this figure here.
{kind=link}
GNS uses the FIPS10-4 standard for representing all countries with a two-digit "country code." This standard was formally withdrawn in 2008, but is now maintained by NGA for use in the GNS gazetteer. (Geopolitical) Despite being maintained by the United States Government, it tends to err on the side of geographic resolution in the case of disputed territory, granting, for example, Taiwan its own country code, despite its being claimed by China. While it does encode historical country and landmark names, GNS does not archive historical country or administrative affiliations for landmarks in cases of subdivided countries or changes in administrative boundaries. For example, in 2007 Chile subdivided the Los Lagos Region (roughly equivalent to a US state) to create the new Los Rios division and created the Arica y Parinacota Region from the Tarapaca region. (FIPS #13, 2008) All existing features in those regions were reassigned to their new administrative division entries in the GNS gazetteer, but no record was made of their previous assignments. Similarly, when Kosovo split off from Serbia in 2008, a new country entry was created and the former Serbian landmarks contained within the boundaries of the new Kosovo had their country codes simply reassigned.
Thus, at any given moment GNS reflects a mapping of the world into contemporary political boundaries, with historical placenames mapping into their present-day country and administrative affiliations. Thankfully, city and landmark names change far more rarely than country and administrative divisions (the names of most cities in Kosovo stayed the same as when they were part of Serbia, for example), so geocoding historical material will still place an extracted city at its proper location on the map, but will simply affiliate it with its current country, rather than the country it was part of at the time. This is one of the greatest challenges facing geocoding systems at the present: the lack of extensive historical gazetteers that also capture changing affiliations over time. The Getty gazetteer captures major cities over time, but only for a small number of historical locations.
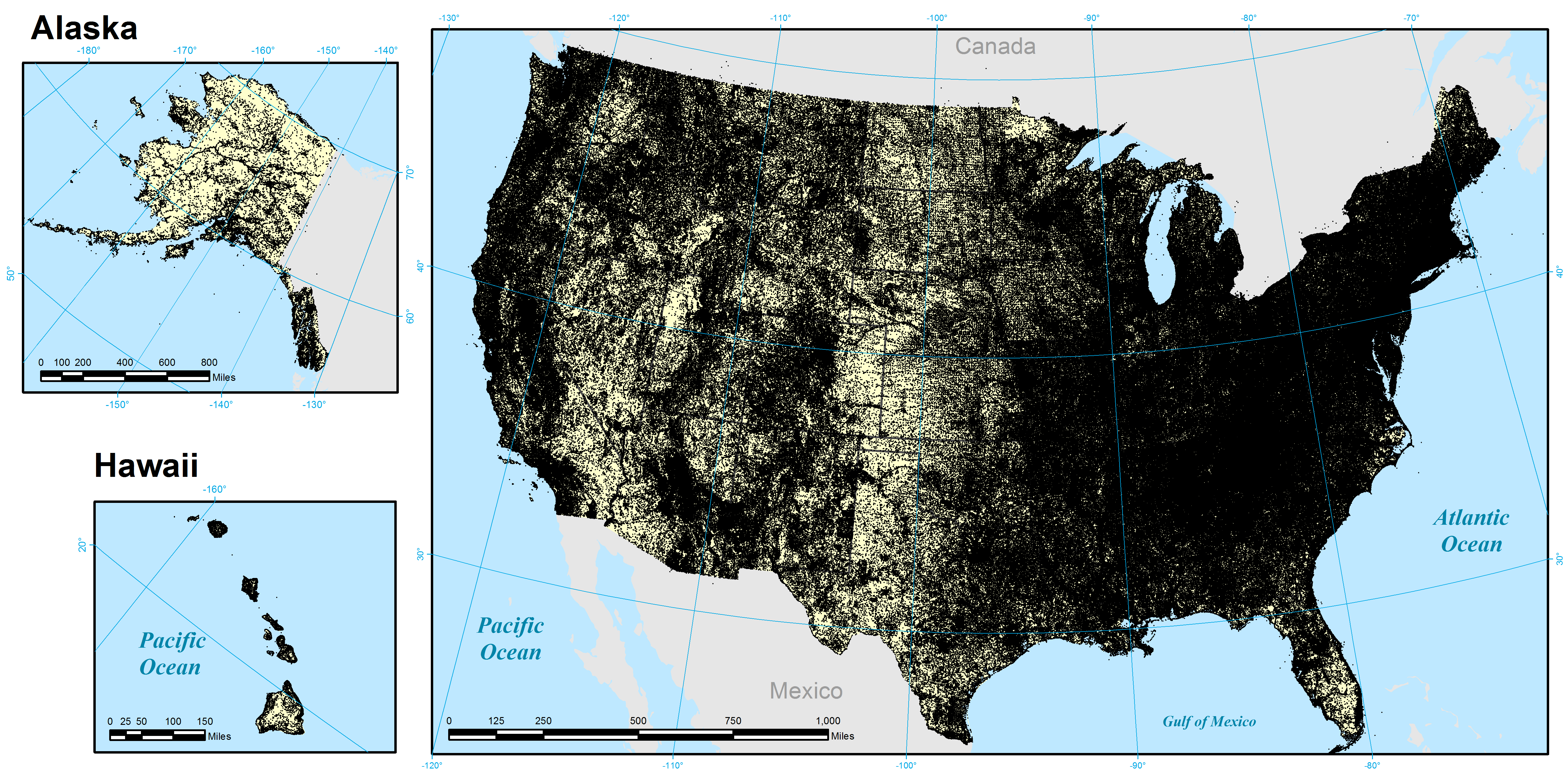
GNIS is the complement to GNS and focuses exclusively on the United States. It catalogs 2,221,269 geographic features in 2,079,751 distinct locations (latitude/longitude pairs). Unlike GNS there is a one-to-one match between names and features, as it does not provide alternate or historical names. Compared with GNS, just 9% of its catalog is devoted to populated places: 198,980 places in 192,897 locations. This can be seen in the figures below, illustrating strong coverage of features like lakes, streams, and hills, and the relative concentration of the nation's population in the East and the way in which population centers tend to follow rivers, railroads, trails, and other major transportation networks.

Figure 4: All geographic locations recorded in the GNIS gazetteer
View a higher resolution version of this figure here.
{kind=link}

Figure 5: All populated place locations recorded in the GNIS gazetteer
View a higher resolution version of this figure here.
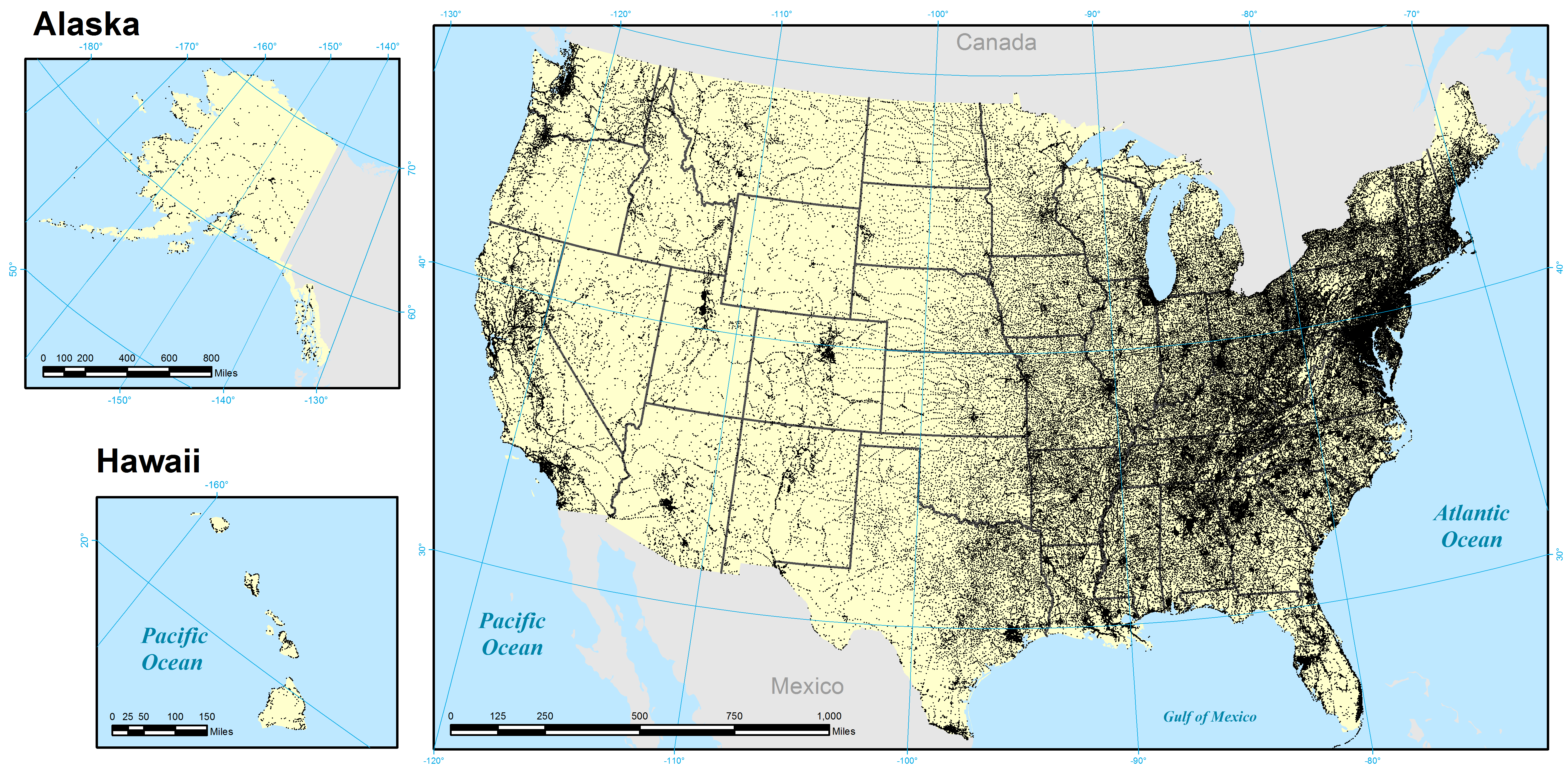{kind=link}
The longest entry in either gazetteer is a college in the West Bank, which has the Romanized (transliterated) name of "Kulliyat al Mihan at Tibbiyah al Musa`idah wa Ma`had al I`lam al `Asri Tilifizyun al Quds at Tarbawi". The longest entry in the GNIS gazetteer is also a school, the "Coastal Carolina University Thomas W and Robin W Edwards College of Humanities and Fine Arts". US placenames are on average nearly double the length of their foreign counterparts at 2.8 words and 19.2 characters, compared with 1.7 words and 11.2 characters for the rest of the world. Shorter names pose greater challenges for geocoding as they are more likely to yield false positives or multiple locations with the same name. One reason for the longer names in the US is likely due to the greater number of precise locations, to the building level in many cases. While this can yield very high-resolution geocodings, it can also have unintended consequences. For example, GNS contains an entry for the "National Democratic Party" in Egypt that records the location of its headquarters. It is unlikely, however, that a user would expect all mentions of that political party in Egyptian news to resolve to the location of its headquarters.
Both gazetteers are updated on a regular basis. GNS stores only the last modified date for each feature, with its highest update periods being December 1993 and January 1994 at 650,000 features each and averaging around 130,000 updates a month in early 2012. GNIS stores both creation and modification dates for each feature. The vast majority (around 46%) of GNIS's features were added between 1979 and 1981. It has been averaging around 4,200 new features a month through May 2012. The last modified field reflects dates only back to 2005 and only 15% of features have a value for this field, reflecting a steady increase in updates, with around 180,000 features updated in 2011. Not all updates or additions contain valid data, however. In its May 14, 2012 release, GNS added 1,196,921 entries from 71 countries that did not contain Roman transliterations, making them unusable for English geocoding tasks.
Disambiguating and Confirming Candidates
The final stage in the geocoding pipeline is the disambiguation and confirmation of the candidates from the earlier stages. Language is highly ambiguous; words can have very different meanings depending on context. Geographic coordinates on the other hand are unambiguous: a set of coordinates and the necessary projection information uniquely defines a single location in space. Thus, this stage must leverage linguistic context to disambiguate textual references into their unambiguous geographic representations. For example, a reference to "Urbana" could refer to a city in Venezuela, or to one of 11 cities in the United States. If, however, the rest of the article mentions Chicago, Springfield, and Decatur, it is likely that the reference is to Urbana, Illinois, in the United States. In this way, the disambiguation process looks at the other geographic mentions in a document to help resolve a potential candidate.
There are numerous approaches used for disambiguation. One of the most common is to check whether the country or administrative division containing that landmark also appears in the text. If not, it is unlikely that the mention refers to that location (other than capital and major cities, which were already processed earlier). If there are multiple possible matches for a landmark and each of those countries or administrative divisions are mentioned in the text, the one closest to the mention is usually used. When there are multiple possible matches in a country (such as multiple landmarks with the same name and no disambiguating information in the source text, like "Urbana, United States"), most geocoding algorithms employ a ranking algorithm that scores each entry in the gazetteer by its geographic type. Capitals and large cities usually receive a very high score, followed by administrative divisions, province-level cities, small cities, villages, settlements, etc. Thus, if there are multiple entries with the same name in a country, the largest one is picked under the assumption that larger cities are more likely to be referenced without contextual information, while smaller ones will include additional information. One study found that by using only closest-country and place importance ranking, it was able to achieve almost 76% accuracy, suggesting that even the simplest of techniques can work well. (Pouliquen et al, 2006) The geocoding system used here uses these two techniques as its primary disambiguation mechanism.
Various other approaches have been explored in the literature for increasing this accuracy level. Garbin & Mani (2005) treat disambiguation as a classification problem and train a machine learning algorithm to essentially "categorize" the text as containing that location reference or not. Such algorithms have enormous computational requirements and must be trained on a per-feature basis, making them intractable for large-scale geocoding. Buscaldi & Rosso (2008) test a similar approach using a geographically-enriched version of WordNet and also explore centroid ranking. Centroid ranking, which is also used by studies like Pouliquen et al (2006), perform an initial pass through the text to identify unambiguous country names and capital and major cities like other geocoders. They then arrange these points in space and for each ambiguous candidate location, they choose the match closest to the centroid of the previous known points, based on the assumption that a text will likely reference multiple locations near each other, rather than scattered across the world. However, a text which does refer to locations in multiple countries can skew this approach. Moreover, in many cases the ambiguous location in question is the only one in the text (especially for smaller news articles), rendering this approach inapplicable. Few of these approaches have been tested at scale on real collections so their computational tractability on large collections is unknown. However, perhaps the greatest limitation is that most of these extended approaches yield at best a 1% or less accuracy boost over the basic closest-country and feature-ranking approach, at significantly greater cost. (Pouliquen et al, 2006)
One of the factors having the greatest impact on the disambiguation process is the number of locations in a country that share the same name (for example, the 11 cities named Urbana in the United States). The more locations in a country that share the same name, the more critical the disambiguation process is to identifying the correct location and the greater the chance it may pick the wrong one. After all, if each location on earth had a unique name that was not shared with any other location on earth, there would be no need for the disambiguation process. Figure 6 shows the percentage of all locations in a country that share their name with one or more other locations in that country. The country with the highest overlap is Cuba, with 48.4%, compared with the Paracel Islands with just 1%, and Vatican City with 0% overlap. By comparison, the United States has a 40% overlap while the United Kingdom has a 9.7% overlap. The average for all countries is 31% and when all locations worldwide are pooled together, 33% of locations share their name with another location somewhere else in the world. Northern Africa and the Middle East have fairly low levels of name duplication, while North and South America and South-Eastern Asia have higher-than normal concentrations of name duplication, suggesting a higher level of potential error in geocoding locations there.

Figure 6: Percent of locations in each country that share their name with one or more other locations in that same country
View a higher resolution version of this figure here.
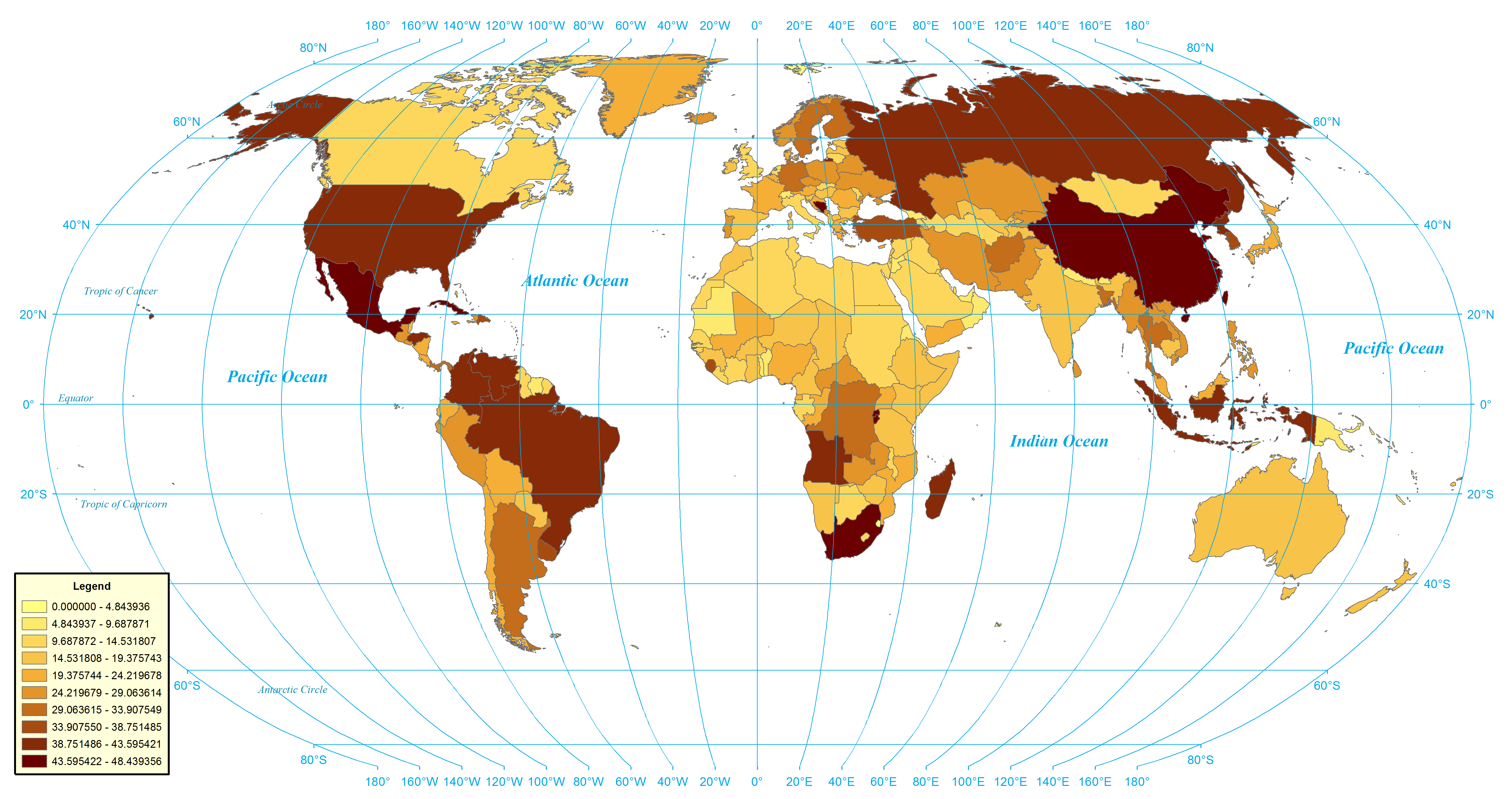{kind=link}
Common Sources of Error
There are many common sources of error in fulltext geocoding. The first revolves around differences in how names are spelled. For example foreign names often have a nearly infinite number of ways they can be transliterated into English. Arabic transliterations in particular are rife with dashes, apostrophes, and spaces removed or transposed due to a lack of standard rules for their conversion into the Latin character set. Muammar Gaddafi's name is perhaps the most famous in this regard, with more than 100 documented transliterations of his family name alone. (Ball & Bryan-Low, 2011) Spaces and punctuation in names cause a number of matching complications beyond transliteration. Cape Town, South Africa is routinely misspelled as Capetown, while Masambolahun, Liberia is often reported as "Masam Bolahun" even in the African press. To address this, most geocoding systems, including the system here, remove all non-letters from the candidate name before searching for a match in the gazetteers. Both Cape Town and Capetown will therefore match to the Cape Town entry. However, this introduces an increased level of false positives. Multiple short words like "So Do" will be collapsed together to match Sodo, Finland, resulting in a false positive. To prevent this, if the candidate is only two words in length and the combined merged candidate will be 4 characters or less, the candidate is left as-is.
Many locations around the world share their names with common English words. GNS includes 22 locations with the Romanized name of just the letter "A", including 7 cities in Denmark, Sweden, Norway, and Japan. Many other common words like "the" and "to" are also used as location names. After extensive manual review of the results of the geocoding system over time, it was determined that nearly every match of a landmark with a name three characters or shorter was a false positive, so these are now automatically excluded, dropping 32,736 names from GNS and 1,189 names from GNIS. While this will undoubtedly exclude some legitimate matches, despite a manual review of a sample from several hundred million pages of geocoded documents, not a single false negative due to this filter has yet been found.
Over the course of reviewing the results of geocoding hundreds of millions of pages, a number of common false positives have been identified that have been added to a manual blacklist. For example, a common name variant of a city in Chad is "Al Gore", which matches the former US Vice President. Even more confusingly, there is a "Castro" in Cuba and a neighborhood called "Fidel Castro" in Colombia. These are added to the blacklist to prevent them from generating false positives. Some cities like Maryland, Jamaica and Australia, Cuba are difficult to detect and for the time being these will result in false positives, but given their extreme rarity in the global discourse, the incidents of those false positives are extremely low, and a human reading the source text quickly would likely make the same mistake.
Finally, an automated process was used to expand the blacklist with the most common false positives. A complete list of all of the unique place names from GNS and GNIS was compiled and Wikipedia was searched to determine how often each name appeared and what percentage of those appearances were capitalized versus lower-case. The Moby Words II dictionary (Ward, 1993) of 354,984 English words was used to drop names that were not also common English words. This yielded a list of 22,311 names that were manually reviewed and added to the blacklist, including locations like Cling, Germany, and Murmur, Nigeria.
The World According to Wikipedia
Wikipedia, as the largest open encyclopedia of world history, makes an ideal test bed for exploring the application of fulltext geocoding system. In particular, Wikipedia supports the concept of manually-applied "geotags" in which contributors mark up a document with latitude and longitude coordinates, allowing a comparison of manual and automated geographic indexing of a large text collection. There have been several previous studies of the geography of Wikipedia. Strotgen & Gertz (2010) is one of the few studies to have used a complete fulltext geocoding, applying the commercial MetaCarta product to the small set of "featured" Wikipedia pages, but did not attempt to analyze the larger corpus. Morton-Owens (2012) used a limited set of trigger words to identify candidate phrases and used exact matches against the GeoNames gazetteer to identify the largest city worldwide by that name, but did not utilize context in disambiguating locations: the largest city match was used as-is.
Most studies have relied only on the user-provided geographic tags, such as a 2011 study that coupled manually-specified geographic references with yearly "event" listings to create an animation of world history. (100 Seconds) Other studies like TraceMedia/Oxford Internet Institute's Mapping Wikipedia Project (Tracemedia) have created extensive maps coupling the hand geotags with language, edit history, and other information to visualize key dimensions of Wikipedia spatially. Services like DBpedia offer customized extracts of Wikipedia's geotags for download, enabling quick integration of spatial indexing into studies of the site.
Extracting Manual Geotags
There is significant variety in the specification of geotags in Wikipedia. DBpedia's list of geographic coordinates extracted from Wikipedia was originally to be used as the source of the geotag information, but upon further analysis, it was determined that DBpedia extracts only one type of geotag and records only the first match in the document. Thus, DBpedia's record for Ankara records only a single coordinate, while the Wikipedia entry actually contains three. Instead, after a further search of available databases and open source programs for extracting Wikipedia's geotags, it was decided to simply write a simple script to ensure that all of the various tags and their variants were included and that all matches in each document were recorded. Through a combination of random manual review and pattern-based searches for coordinate-like numbers, a core set of coordinate tags were found including "|latitude", "|latd", "|lat_deg", "|lat_degrees", "{Coord" and "{coord", in both decimal and Degrees Minutes Seconds (DMS) formats, with a wide variety of attribute tags under each. Since these instructions must be processed by the wiki software for display, they must be in English, regardless of the language of the entry's text.
To explore this, the complete list of all manually-specified geographic coordinates were extracted from all 40 language-specific editions of Wikipedia having 100,000 or more entries. The majority of geotags appear in the English edition of Wikipedia, totaling 1,155,661 mentions of 741,419 distinct coordinates across 583,415 entries, seen in Figure 7. The article with the most geotags is the "List of Nike missile locations" (Nike) with 1,078 hand-entered geotags. The large number of points scattered throughout the oceans and in largely unpopulated areas stems from the significant presence of invalid coordinates. This "background noise" is made up of typographical errors, swapped latitude/longitudes, wrong directional signs (North/South, East/West), and even coordinates from other planets. There is no standardized way to specify that a coordinate is located on the Moon, the Sun, Mars, or another planet, so Wikipedia's extensive coverage of prominent features of other planets and stars cannot be easily filtered out and appear in the resulting output.
As might be expected, each language edition of Wikipedia emphasizes different areas of the world of greatest relation to that language. The TraceMedia/Oxford Internet Institute's Mapping Wikipedia Project (Tracemedia) maps the differences among the various language editions of Wikipedia. Figure 8 shows the result of combining all of the geotags from across all 40 language editions of Wikipedia having more than 100,000 entries. This increases the total number of geotags to 2,600,194 mentions of 1,264,841 distinct locations across 1,381,899 entries. Despite increasing the total universe to a combined 35 million entries, the total number of geotags increased by just 2.5 times and the number of distinct points increased by just 1.7 times, demonstrating that the majority of Wikipedia's hand-tagged geographic information is centered in its English edition. In total, less than 4% of all pages in the 40 largest editions of Wikipedia contain even a single geotag, illustrating the extremely low prevalence of enhanced metadata like geospatial information in large document collections.

Figure 7: Geotagged coordinates in English Wikipedia
View a higher resolution version of this figure here.
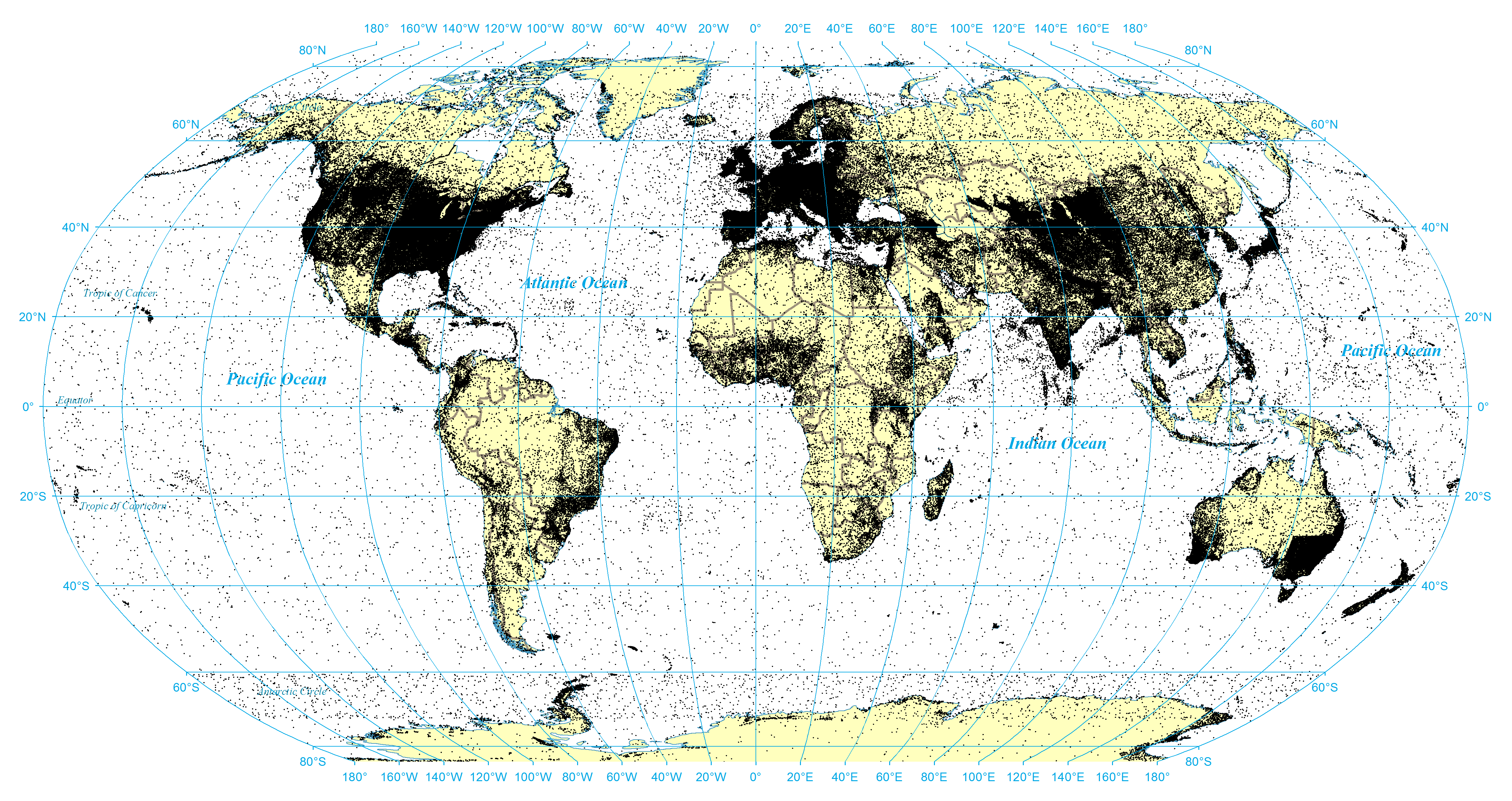{kind=link}

Figure 8: Geotagged coordinates in top 40 Wikipedia editions with more than 100,000 articles
View a higher resolution version of this figure here.
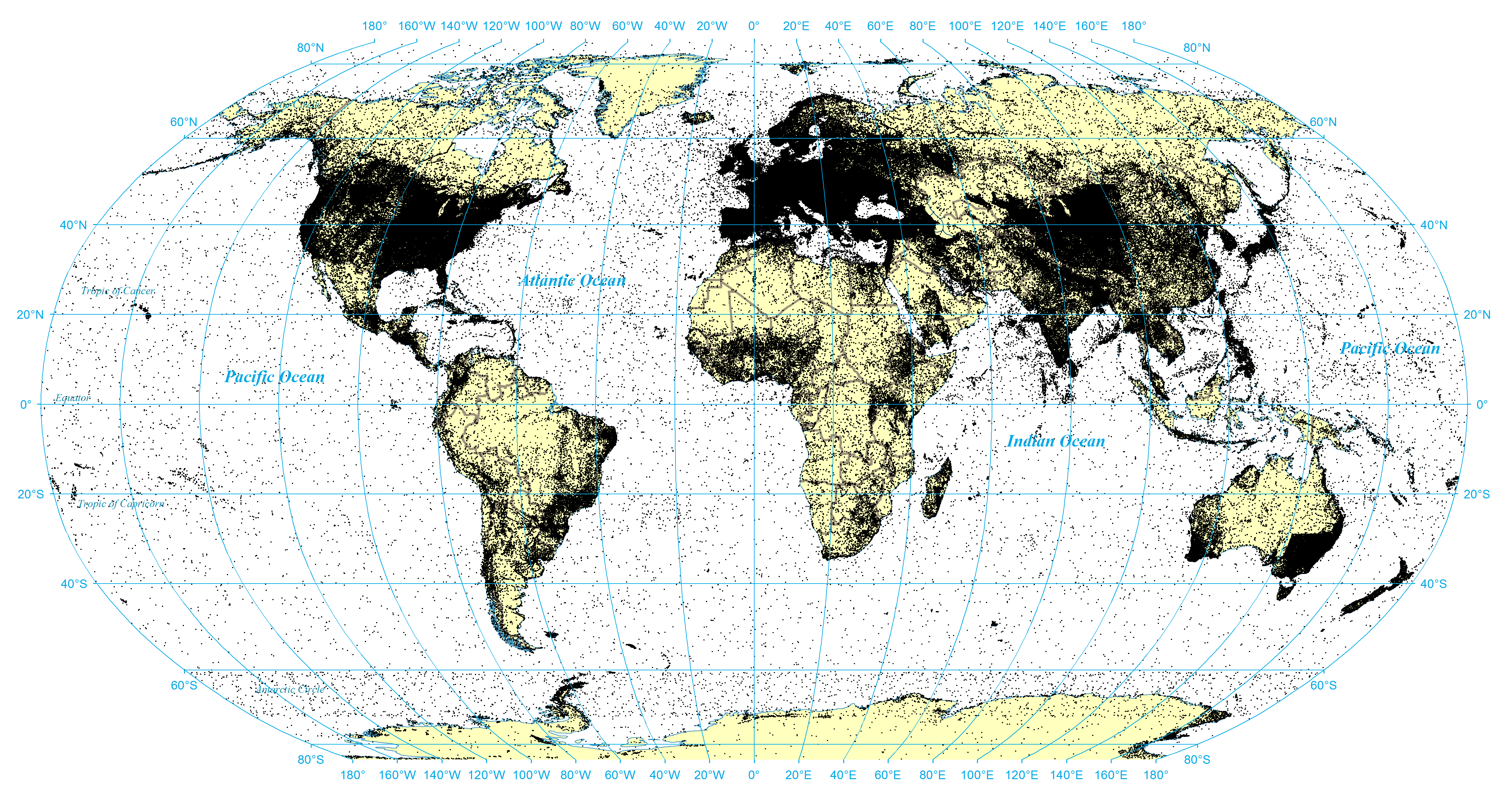{kind=link}
FullText Geocoding
In contrast, Figure 9 shows the result of processing Wikipedia's four million English-language entries using the fulltext geocoding algorithm described in this paper. Each entry was preprocessed to remove all non-geographic words, all potential geographic words capitalized, and the resulting list of capitalized candidates processed. Country names and capital and major cities were recognized, and the list of remaining candidates was compared against the GNS and GNIS gazetteers. Candidates were processed in the order they appeared in the text and disambiguated by selecting the highest-ranking candidate from the country of the closest mention of a known or previously disambiguated location. In the case that none of the countries of a candidate's potential matches appeared in the text, it was discarded. GNS and GNIS entries were ranked in order of country capitals, administrative division capitals, independent political entities, islands, administrative divisions, populated places, and finally all other landmarks. A manual review of several randomly-selected articles showed accuracy on par with current systems with no systematic obvious false positives or false negatives.
The expanded geographic coverage afforded by fulltext geocoding is immediately apparent in the map below, resulting in 80,674,980 mentions of 2,760,704 distinct locations across 4,298,589 entries. Excluding redirect pages, this accounts for 59% of all entries in the English Wikipedia XML export, more than 15 times the number of entries containing just hand-coded geographic information. This represents 30 times more geographic mentions as in the hand geotags from all 40 of the largest Wikipedia editions combined, referencing twice as many unique locations. Black points represent manually-specified points or points in which both manual and fulltext geocoding resulted in a match, while red indicates locations found only through fulltext geocoding. It is clear that both fully saturate areas like the United States and Europe, but the vastly greater coverage of fulltext geocoding is readily apparent.
")
Figure 9: Comparison of geotagged coordinates with fulltext geocoding coordinates (black are points covered by hand tagged or both / red are points covered only by fulltext geocoding)
View a higher resolution version of this figure here.
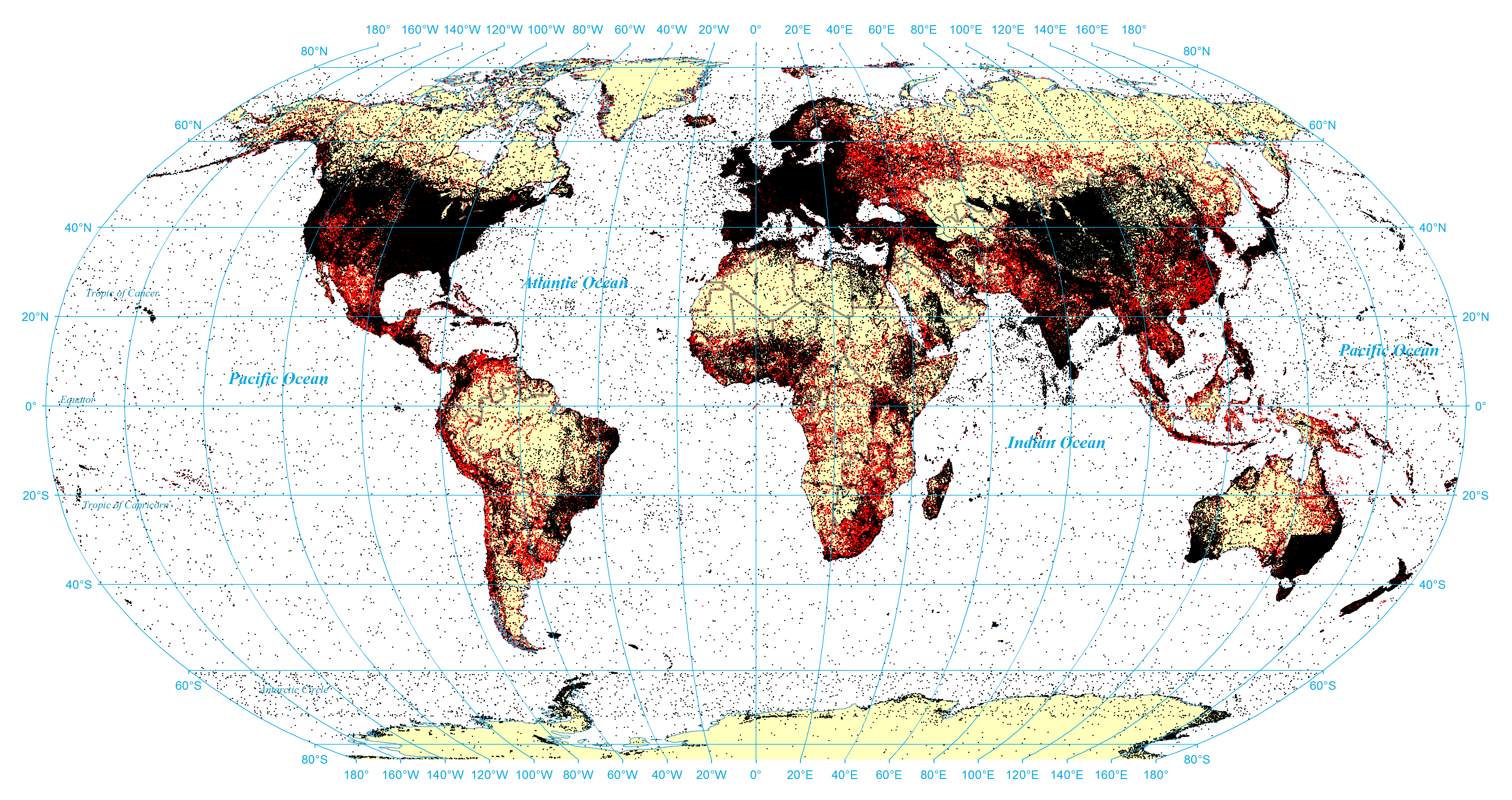{kind=link}
Density Comparison
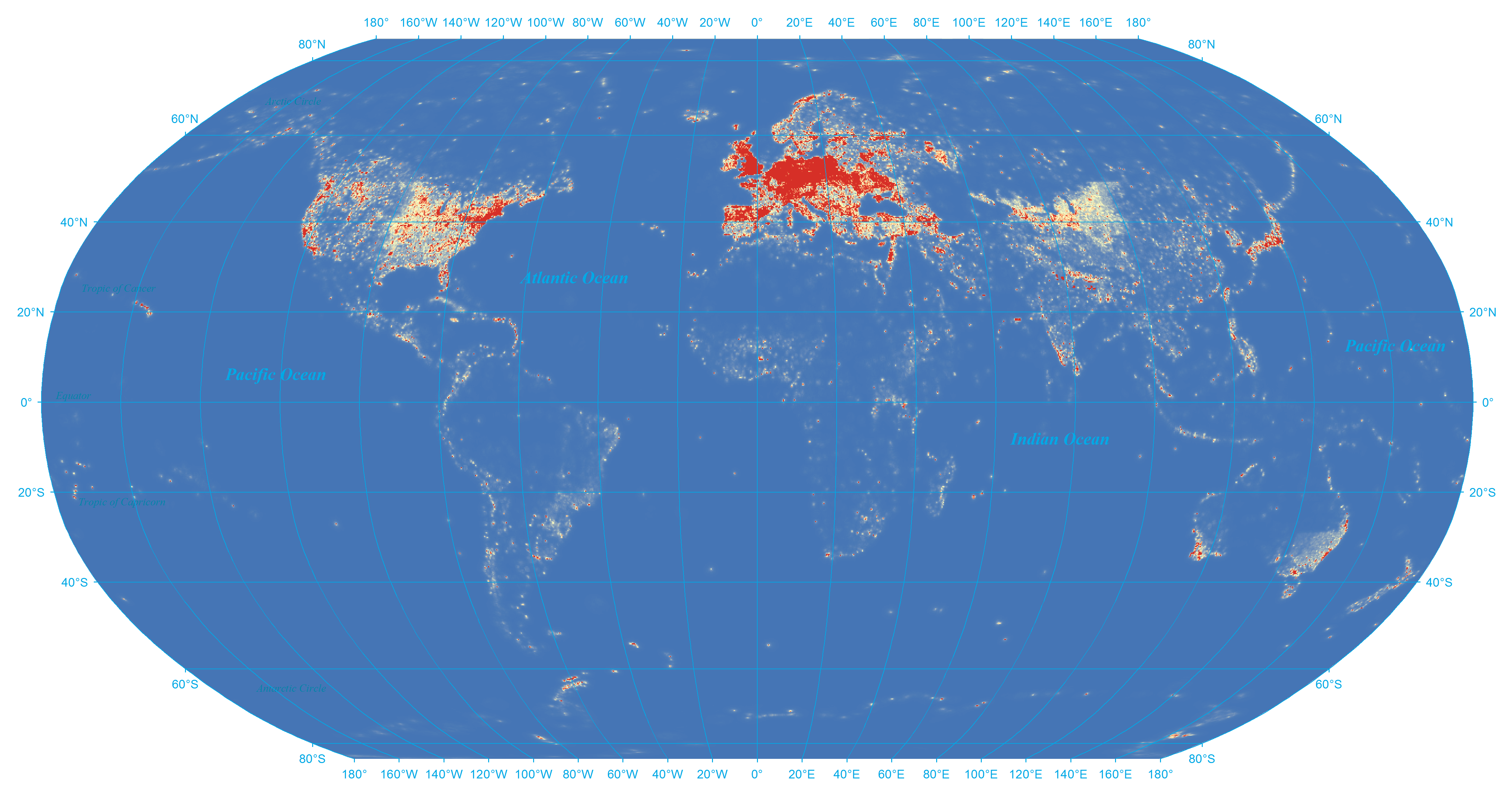
The maps above show only the distinct locations mentioned in Wikipedia, but a dot on the map could indicate a single mention of that location across the entirety of Wikipedia or thousands of references. This is especially problematic in areas like the United States and Europe, where the number of unique locations mentioned is so high it results in essentially a solid black shape. A better comparison of the two datasets revolves around the focus of those mentions: are there particular areas that receive a higher number of mentions than others? Morton-Owens (2012) and others have argued that Wikipedia is heavily skewed towards the United States and Europe. The following two visualizations therefore examine the density of coverage, identifying areas with higher-than-normal numbers of mentions. Figure 10 displays the focus of Wikipedia's manually-specified geotags and demonstrates why previous studies have asserted that it overemphasizes Europe and the Eastern coast of the United States. This map makes it clear that these areas contain the highest density of Wikipedia's manually-specified geographic information. Europe is perhaps the greatest outlier, with the core areas of Europe all significantly over-emphasized.
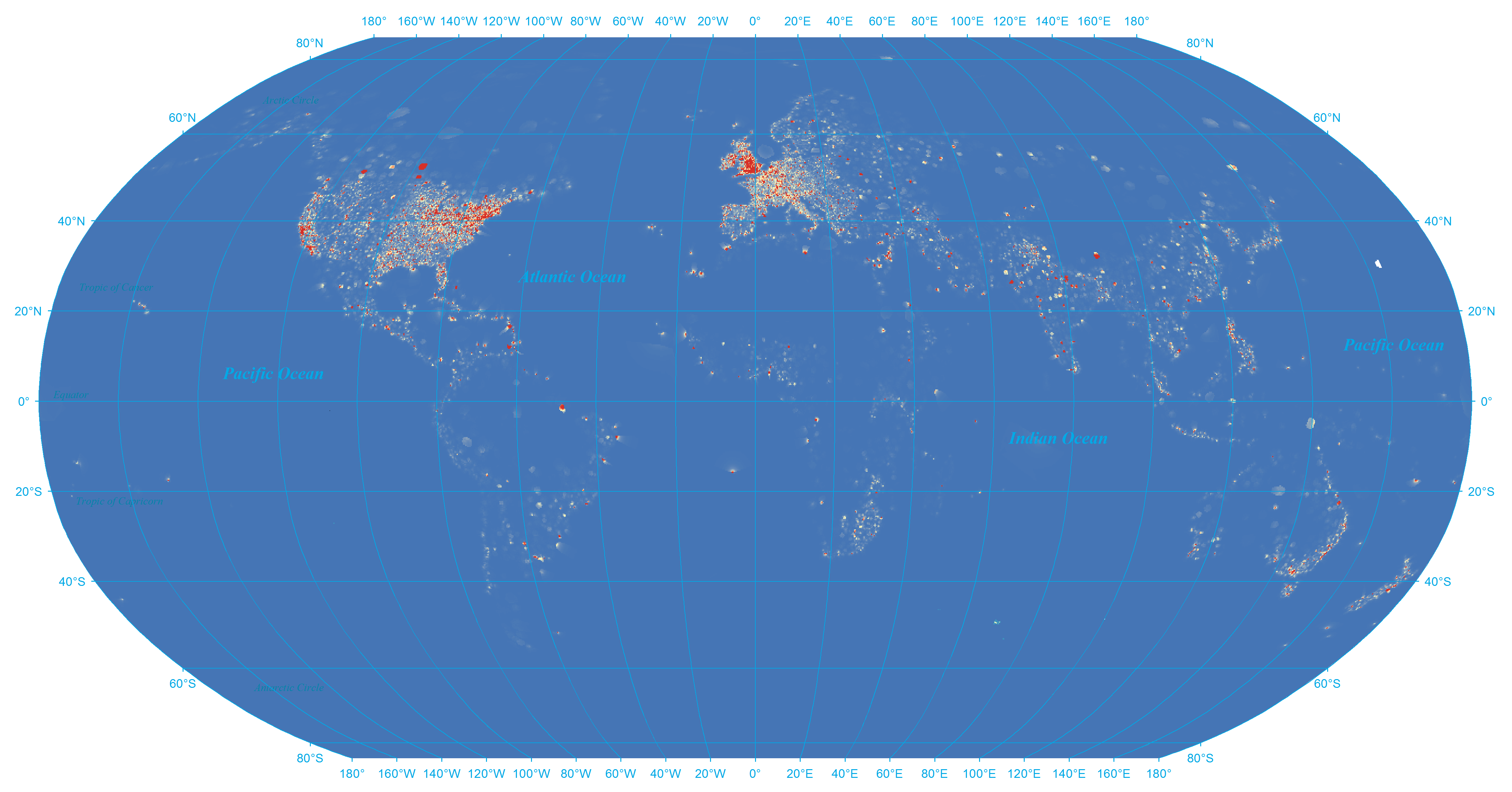
Yet, Figure 11 shows the same analysis for the fulltext geocoding results. Here Europe is still represented, but it appears to more closely track population density and major cities across the world. Of particular interest, far fewer areas are highlighted in this map, indicating that the majority of geographic mentions in the contents of Wikipedia's entries are distributed evenly across the world, compared with a primary emphasis on Europe and the Eastern United States of its hand-tagged data. This suggests that in the case of Wikipedia, the manually-specified geographic metadata that is currently used to study Wikipedia's view of space is heavily biased and not representative of Wikipedia's actual geographic emphasis.

Figure 10: Density heat map of hand-tagged locations
View a higher resolution version of this figure here.
{kind=link}

Figure 11: Density heat map of fulltext geocoding results
View a higher resolution version of this figure here.
{kind=link}
Mapping Wikipedia's View of World History
Perhaps the greatest benefit of fulltext geocoding is that by identifying geographic references inline in the article text, they can be associated with other textual elements such as date references. In the case of the SGI Wikipedia Project, each location mention was paired with its closest date mention, and any pair of locations mentioned together in an article with respect to the same year was considered "linked". The average "tone" of all articles mentioning that city/year pair was then computed and used to color each location and connecting line (bright red for very negative to bright green for very positive), generating a sequence of maps visualizing world history 1800-2012 according to Wikipedia. The resulting animation can be viewed here.

Figure 12: World history according to Wikipedia
Finally, to allow interactive exploration of Wikipedia through a spatial interface, a Google Earth file was created for Libya (Google Earth is limited in the number of points it can handle and Libya was one of the few countries with a small enough set of points), which can be viewed here. All mentions across all of Wikipedia's four million pages to any location in Libya with respect to the last 200 years is included in this file, allowing visitors to use the Google Earth time slider to select a period in time and see all mentions of that time in Libya's history. Clicking on a point allows the visitor to jump directly to the Wikipedia page containing that mention, offering a spatio-temporal interface for browsing Wikipedia.

Figure 13: Google Earth interface to interactively explore Wikipedia's coverage of Libya 1800-2012
Conclusions
Spatial information is playing an increasing role in the access and mediation of information, driving interest in methods capable of extracting spatial information from the textual contents of large document archives. Automated approaches, even using fairly basic algorithms, can achieve upwards of 76% accuracy when recognizing, disambiguating, and converting to mappable coordinates the references to individual cities and landmarks buried deep within the text of a document. The workflow of a typical geocoding system involves identifying potential candidates from the text, checking those candidates for potential matches in a gazetteer, and disambiguating and confirming those candidates. The GNS and GNIS gazetteers that form the basis of most geocoding systems offer fairly extensive coverage across the world, though name duplication, in which multiple locations in a country share the same name, varies significantly across the world, creating regional variations in the accuracy of the disambiguation process. Previous studies of Wikipedia's spatial coverage have largely relied on editorially-assigned spatial metadata tags, finding that Wikipedia overemphasizes Europe and the United States. However, when applying fulltext geocoding to map all locations mentioned in Wikipedia, rather than just those a human editor manually tagged, Wikipedia is found to actually have relatively even coverage across the world, with far less emphasis on Europe and the United States. This points to the limitations of using metadata to study and understand collections and suggests that as new content-based data mining approaches are used to revisit collections previously accessed only through metadata, they may challenge previous findings. Finally, the ability to leverage fulltext geocoding to offer new spatial visualization, interaction, and search capabilities for large document collections offers a powerful new modality for understanding and using information.
Acknowledgements
The author wishes to thank Silicon Graphics International (SGI) for providing access to one of their UV2000 supercomputers to support this project, and Eric Shook of the CyberInfrastructure and Geospatial Information Laboratory at the University of Illinois for the creation of the two heat maps based on the CyberGIS software infrastructure supported in part by the National Science Foundation under Grant No. OCI-1047916.
References
[1] A history of the world in 100 seconds.
[2] Alexandria Digital Library Project.
[3] Ball, Deborah & Bryan-Low, Cassell. (2011, April 19). Arabic Names Spell Trouble for Banks. The Wall Street Journal.
[4] Bellomi, Francesco & Bonato, Roberto. Network Analysis for Wikipedia. Proceedings of Wikimania, 2005.
[6] Brill, Eric. (1992). A simple rule-based part of speech tagger. Proceedings of the Workshop on Speech and Natural Language. pp. 112—116.
[7] Buscaldi, Davide & Rosso, Paolo. (2008). Map-based vs. knowledge-based toponym disambiguation. Proceedings of the 2nd International Workshop on Geographic Information Retrieval (GIR 2008), 19—22.
[8] FIPS Publication Change Notice #13, 4 February 2008, United States National Geospatial-Intelligency Agency.
[9] Gan, Qingqing; Attenberg, Josh; Markowetz, Alexander; Suel, Torsten. (2008). Analysis of geographic queries in a search engine log. In the WWW'08 Workshop on Location and the Web, pages 49—56. ACM Press.
[10] Garbin, Eric & Mani, Inderjeet. (2005). Disambiguating toponyms in news. Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT 2005), 363—370.
[11] Geographical Names of Canada.
[12] National Geospatial-Intelligence Agency, Geopolitical Codes.
[13] Getty Thesaurus of Geographic Names, About the TGN.
[14] Hill, Linda. (2006). Georeferencing: The Geographic Associations of Information. Cambridge, MA: The MIT Press.
[15] Leetaru, Kalev & Olcott, Anthony. (2012). Gaps and ways to improve how populations and social groups can be monitored via journalistic and social media to detect fragility. In LTG Flynn, M. et al; "National Security Challenges: Insights from Social, Neurobiological, and Complexity Sciences". Multilayer Assessment Program, Office of the Secretary of Defense, July 2012.
[16] Leetaru, Kalev. (2011). Culturomics 2.0: Forecasting large-scale human behavior using global news media tone in time and space. First Monday. 16(9).
[17] Lieberman, Michael & Samet, Hanan. (2011). Multifaceted toponym recognition for streaming news. Proceedings of the 34th international ACM SIGIR conference on Research and development in Information. 843—852.
[18] List of Nike missile locations.
[19] Morton-Owens, Emily. (2012). A tool for extracting and indexing spatio-temporal information from biographical articles in Wikipedia. Master of Science Department of Computer Science New York University.
[20] NGA GEOnet Names Server (GNS).
[21] Gazetteer of Australia Place Name Search.
[23] Pouliquen, Bruno; Kimler, Marco; Steinberger, Ralf; Ignat, Camelia; Oellinger, Tamar; Blackler, Ken; Fluart, Flavio; Zaghouani, Wajdi; Widiger, Anna; Forslund, Ann-Charlotte; Best, Clive. (2006). Geocoding Multilingual Texts: Recognition, Disambiguation and Visualisation. Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC'2006). Genoa, Italy, 24 — 26 May 2006.
[24] Strotgen, Jannik & Gertz, Michael. (2010). TimeTrails: A System for Exploring Spatio-Temporal Information in Documents. Proceedings of the VLDB Endowment. 3(2), 1569—1572.
[25] TraceMedia, Mapping Wikipedia.
[26] Ward, Grady. (1993). Moby Words II.
[27] Yahoo! APIs Terms of Use.
About the Author
 |
Kalev H. Leetaru holds a Josie B. Houchens Fellowship at the University of Illinois Graduate School of Library and Information Science and is Former Assistant Director for Text and Digital Media Analytics and Former Senior Research Scientist at the Institute for Computing in the Humanities, Arts, and Social Science and Former Center Affiliate of the National Center for Supercomputing Applications. His work centers on the application of high performance computing and "big data" to grand challenge problems. He holds three US patents and more than 50 University Invention Disclosures and has been an invited speaker, panelist, and discussant at venues including the Library of Congress, Harvard, Columbia, Stanford, and UC Berkeley, while his work has been profiled in venues as diverse as Nature, the New York Times, BBC, Discovery Channel, The Atlantic, Fortune Magazine, The Economist, Columbia Journalism Review, MSNBC, Que Leer and media outlets in more than 100 countries. His 2011 "Culturomics 2.0" study was one of just five science discoveries featured in The Economist's The World in 2012 review of the most significant developments of 2011. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |