|
||
D-Lib Magazine |
|
| Christophe Blanchi Jason Petrone |
![]()
AbstractInteroperability between digital libraries depends on effective sharing of metadata. Successful sharing of metadata requires common standards for metadata exchange. Previous efforts have focused on either defining a single metadata standard, such as Dublin Core, or building digital library middleware, such as Z39.50 or Stanford's Digital Library Interoperability Protocol. In this article, we propose a distributed architecture for managing metadata and metadata schema. Instead of normalizing all metadata and schema to a single format, we have focused on building a middleware framework that tolerates heterogeneity. By providing facilities for typing and dynamic conversion of metadata, our system permits continual introduction of new forms of metadata with minimal impact on compatibility. 1 IntroductionProviding distributed, flexible search and retrieval of their collections was one of the promises of digital libraries. Although -- with various degrees of success -- many digital libraries have been developed, their ability to interoperate has always been limited. The main difficulty in interacting with digital libraries is not in the standardizing of network access across systems but lies in the inability to consistently determine the nature of the information they contain. This problem arises largely because of the lack of agreed metadata standards. Metadata commonality is necessary for clients and systems to search for, access, and exchange distributed information. Metadata, at an abstract level, describes intrinsic and extrinsic data attributes according to an arbitrary, specific, and potentially unique conceptual space. Simply restated, this means that different types of metadata describe data from different, possibly unique perspectives. Two sets of metadata are considered compatible if their conceptual spaces overlap. Metadata interoperability can therefore be described as a measure of the compatibility of two metadata sets. In practical terms, metadata interoperability represents the ability of a system to cross-walk from the conceptual space of one metadata set to the other. Types of metadata used today often lack some of the basic requirements that enable compatibility, such as standard definitions and unique identification, without which it is difficult to determine the metadata intents, what it describes, or how to process it. To make matters worse, there are nearly as many types of metadata as there are digital collections. There are two main approaches with which researchers have experimented to achieve metadata interoperability across digital library systems: the first approach is to define a common metadata standard, and the second consists of building metadata gateways to convert specific metadata corpora into another base standard for performing uniform queries. We believe it is neither realistic nor practical to seek metadata interoperability through the adoption of a single metadata standard. We are also of the opinion that incompatible metadata is unavoidable and will persist. Therefore, we believe that any solution to the problem of metadata interoperability will have to accommodate the multiplicity of incompatible metadata. 2 A State of Perpetual Metadata HeterogeneityMetadata corpora have been non-interoperable primarily because of the wide range of data genres they describe and because the metadata is created in diverse environments. Metadata must provide accurate, specific, and contextually relevant information about the data it describes. Thus new, data-specific, metadata descriptions are continuously being developed, resulting in a multiplicity of concepts and namespaces that greatly complicate metadata interoperability. Adopting one recognized metadata standard such as the Dublin Core [DC] or MARC [MARC] would result in better all around metadata interoperability, but for practical, technical, and political reasons, this approach is neither realistic nor necessarily desirable. Indeed, if a single standard were adopted, the resulting metadata would not be appropriate for describing all types of data and in effect, would not be interoperable. A one-size-fits-all standard would either not provide enough information about the described data or the metadata would be overwhelmingly difficult to generate, resulting in imprecise descriptions. Even if partial success is achieved, as is the case with Dublin Core, experience shows that its limited number of metadata elements, key to insuring interoperability, also restricts the more sophisticated metadata user. To address this issue, metadata qualifiers have been added to the Dublin Core to gain additional power of specification and substructure [BM99]. This adaptation allows for more complex metadata uses, but at the same time threatens the original goal of interoperability. 3 Dealing with Incompatible MetadataWhen used on its own, the term "metadata" references the general notion of data about data. However, this simple description is too broad. In order to avoid generating further metadata terminology confusion, below we define four additional metadata terms we will use throughout this article:
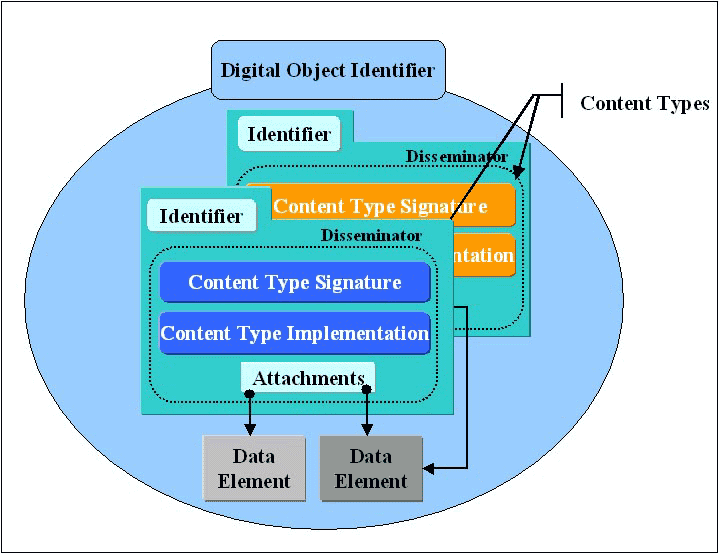
We believe that one of the most basic requirements needed to achieve broad metadata interoperability lies in the ability to describe and identify metadata schemas and their respective metadata elements. Without description, a metadata schema is an arbitrary set of terms whose purposes cannot be independently determined. Without metadata schema identification, there exists no mechanism to deduce the nature of that metadata schema or how to use it. 3.1 Metadata Schema DescriptionTo describe each metadata schema we adopted Part 3 of the ISO11179 standard. Part 3 of the standard organizes metadata elements into five general categories: identifying, definitional, relational, representational, and administrative. The specific set of attributes expressed in each of these categories provides a precise, unambiguous, description of the nature, context, and conditions of use of each metadata element within a metadata schema. The complete set of metadata element descriptions for a given metadata schema represents that schema's definition. This description enables independent parties to acquire the same understanding of the nature, context, and condition of use of each field of the metadata schema. It is important to note at this point that although we use the ISO11179 standard to describe our metadata schemas, the framework's mechanisms are not dependent on the standard to function. Indeed, another method for describing the metadata schemas could be used instead of, or in conjunction with, the standard as long as the resulting descriptions precisely and completely describe each metadata schema. To facilitate generation of metadata schema descriptions, we created a Document Type Definition (DTD) that specifies the various attributes for describing a metadata element and that encapsulates some of the rules described in Part 3 of the ISO11179 standard. Using Extensible Markup Language (XML) simplifies the metadata schema description encoding process and provides an additional level of integrity checking. The use of XML enables the independent generation of accurately encoded metadata schema definitions. 3.2 Metadata Schema IdentificationIn our approach, we uniquely identify each metadata schema and its metadata elements using the CNRI Handle System™. The Handle System is a comprehensive system for assigning, managing, and resolving persistent identifiers, known as "handles," for digital objects and other resources on the Internet. An added benefit of using a handle as a metadata identifier is that it provides a simple mechanism to associate each metadata schema identifier with a specific set of resource pointers. These pointers can be used to locate a particular metadata schema's description and services. Since the metadata schema handle can be used as an identifier, description, or service pointer, we assert that the handle represents the type of a metadata schema. 4 Digital Metadata ObjectsRecognizing the impracticality of finding a single metadata standard, we seek to achieve metadata interoperability by dynamically converting metadata based on the evolving needs of clients or systems. Our approach to metadata interoperability focuses on developing a framework geared toward making metadata instances, schema, and services into first class network objects. This involves typing, identifying, and defining metadata, and requires a framework for associating metadata with distributed services. A digital metadata object is a distributed first class object. It can describe itself, its metadata, and its metadata schema. It provides a set of services for converting its metadata into one or more different metadata schemas and can generate different representations and encoding of its metadata. Our framework allows for new metadata and metadata schema to be dynamically added and to be immediately accessible as distributed first class objects. Our framework does not provide any new methods for converting, identifying, and describing metadata and, in many respects, uses the same solutions found in currently existing middleware. Nor are we proposing any overall conceptual approach for the creation and mapping of metadata schemas, as the indecs project does for the intellectual property community. We are proposing a network architecture that is decentralized and distributes metadata and services to facilitate flexibility and extensibility. 5 Digital Object ArchitectureThe interoperable metadata framework uses CNRI's Digital Object Architecture to provide decentralized conversions of metadata as well as administration functionality. The following section provides an overview of this architecture and introduces the minimum necessary concepts required to understand the interoperable metadata framework [PB99]. The Digital Object Architecture has been an ongoing area of research at CNRI. The origins of the architecture work can be traced to R. Kahn and R. Wilensky's paper "A Framework for Distributed Digital Object Services"[KW]. Digital objects can be thought of as general purpose, uniquely identified networked information entities that protect the integrity and access rights of their respective contents. Digital objects are accessed and managed exclusively through the Repository Access Protocol (RAP). The Digital Object Architecture defines a set of services for identification, access, and management of digital objects. These services operate in a dynamic and extensible manner while respecting access policies of individual digital objects. 5.1 Digital ObjectsA digital object is the primary form of information representation within the architecture. At an abstract level, digital objects are uniquely identified network entities that can encapsulate, describe, and provide value-added access to heterogeneous typed content. Digital objects are created, managed, and accessed using the operations defined in the RAP protocol. Clients interacting with digital objects typically do not retrieve the entire digital object all at once; but only retrieve the views of the object that they have permission to request. The sets of information returned from these views are called disseminations. Digital objects achieve all their functionality through the use of two internal data structures: the data elements and the disseminators. An illustration of the structures of a digital object can be found in Figure 1.
|
|
|
|
Data elements are stored or referenced as sets of sequences of bytes within a digital object. Each digital object can have any number of uniquely identified data elements. Each data element has its own set of key metadata consisting of its data type, size, date created, and date last modified. A disseminator is a structure within a digital object used to associate a uniquely specified class of operations, also known as a Content Type, with a set of data elements from that same digital object. A digital object can have any number of uniquely identified disseminators. Zero or more data elements are associated with a disseminator's content type using a disseminator structure known as the attachments. Digital object creators use the attachments to specify which and how data elements are associated with a disseminator's content type. A digital object repository implements the RAP interface to allow for the creation, modification, deletion and access of digital objects, as well as assumes the digital object storage responsibilities. Repositories enforce the access rights policies pertaining to each digital object and provide safe environments for the generation of digital object disseminations. 5.2 Content TypesContent types provide a high level typing mechanism for describing the contents of digital objects. They are sometimes referred to as intents of use types since they can describe how a digital object creator intended for its object to be used. A content type is associated with the contents of a digital object using a disseminator described in the previous section. A content type characterizes all or part of the content of a digital object by describing a set of specific operations that can be performed on it. Each operation within a content type has a semantically relevant name, as well as a human readable description of its purpose and usage recommendations. As with any operation request, content type operations accept input parameters that are each described using a semantically meaningful name and a human readable description of their relations to the behavior of the operation. When a client issues a digital object dissemination request, the targeted content type operation receives inputs from two sources: the input parameters supplied by the requestor, and zero or more digital object data elements as specified by that disseminator's attachments. The content type operations are then run against the set of attached data elements and input parameters, and return the content type dissemination to the requestor. Although the mechanisms that enable content types to operate are completely abstracted from the client, it is important to mention that content types consist of two separate entities. The first entity, a content type signature, describes the set of operations a content type provides by defining the semantics, parameters and general expected return types for each operation. The second entity, the servlet or content type implementation, implements all the operations defined by a specific content type signature. The separation of the content type interface definition from its respective implementation allows for multiple implementations of the same content type. Content types represent a powerful and flexible mechanism for identifying, describing and referencing implementations of operations. Content types enable expression of complex types in a distributed and extensible fashion by allowing anyone with the proper authority to create new content types to express the specific functionality of their class of data. This technique of high-level data typing bears some resemblance to MIME [FB96], a standard designed to facilitate interoperability in Internet email attachments. However, there are a number of differences between MIME types and digital object content types. MIME types are concerned with expressing the particular structure within a set of bytes, while content types denote the manner in which the data is to be used. For example, an SGML file containing the script for the play Hamlet would have a MIME type of While both MIME types and content types are registered with unique identifiers, the process of registration for each differs greatly. MIME registration requires submitting for peer review a proposal to the Internet Engineering Steering Group (IESG) [FKP96] and is contingent upon IESG approval. To prevent the MIME type registry from becoming overburdened, few MIME types are adopted as standards. Unlike MIME type registration, content type registration is dynamic. Content types are registered using the Handle System so that the registry may be distributed. This allows for registration of many content types without the scalability problems of a centralized index. Using the Handle System allows content type providers to independently administer their own registries, enabling individual organizations to globally register content types with autonomy. 6 Dynamic, Extensible, and Interoperable Metadata RegistryOur interoperable metadata registry design is based on the notion that making metadata and metadata schema into first class network objects will provide a more powerful method for manipulating metadata. The following section describes how we applied the digital object architecture to implement our dynamic, extensible and interoperable metadata registry design. 6.1 Basic Design RationaleThe interoperable metadata registry implementation is based on the existing functionality of our previously implemented digital object architecture. The digital object architecture was specifically well suited for implementation of the metadata registry for the following reasons:
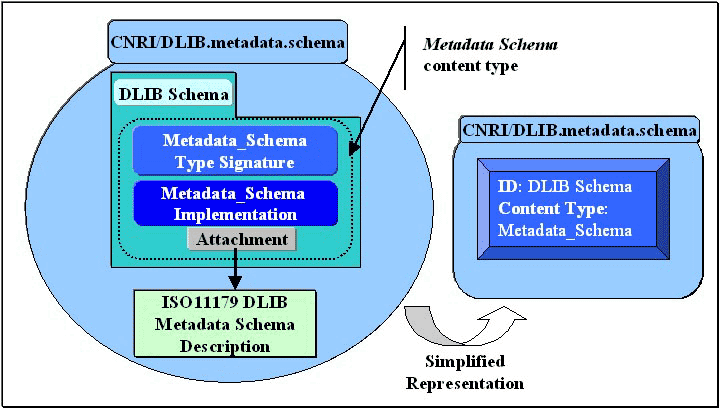
6.2 Defining a Metadata Schema Digital ObjectEncapsulating a metadata schema description and services in a digital object enables the metadata schema to become a first class network object. The resulting metadata schema digital object (Figure 2) provides standardized access to its metadata schema definition by abstracting its specific formatting and encoding. If the metadata schema was appropriately expressed according to the approach described in section two of this document, a new metadata schema digital object can be created using the following set of operations:
|
|
|
|
The Metadata_Schema content type is to be used with all metadata schema digital objects within our interoperable metadata framework. It is designed to provide two different levels of functionality:
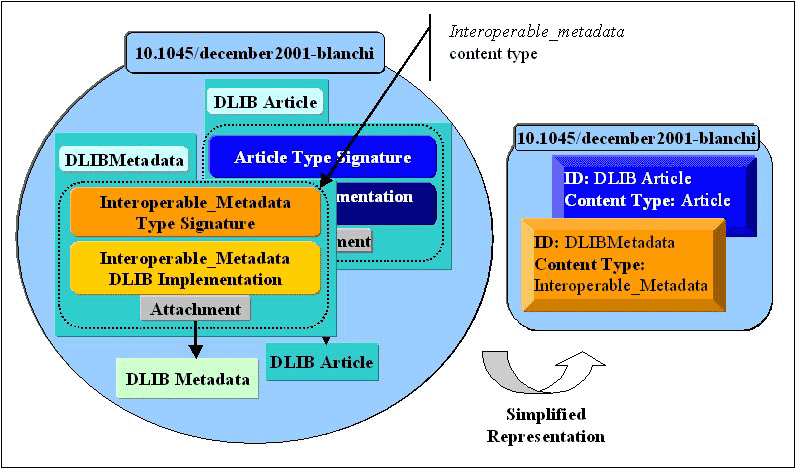
6.3 Creation of Interoperable MetadataEncapsulating metadata and its respective services in a digital object enables the metadata to become a first class network object. Operations can be run on a metadata digital object to provide access to its metadata while abstracting the specific schema, format, and encoding of the metadata. An example of a metadata digital object is illustrated in Figure 3. As previously mentioned, the inherent problem with metadata is that there are many different kinds, all serving different purposes. To describe metadata in an interoperable fashion in a digital object, it was necessary to provide a non-metadata specific interface, while still allowing a client to acquire any part of the metadata. To address this problem, we created the Interoperable_Metadata content type. This content type provides non-metadata-specific access to its attached metadata. Its functionality can be broken down into two different categories:
It is important to add that a given digital object can contain as many instances of Interoperable_Metadata content types as it contains metadata sets. Furthermore, each Interoperable_Metadata content type implementation has it own specific metadata schema. In Figure 3, for example, the Interoperable_Metadata content type has CNRI/DLIB.metadata.schema as its metadata schema, and therefore its implementation dictates that it be associated only with DLIB type metadata.
|
|
|
|
A new metadata digital object is created as follows:
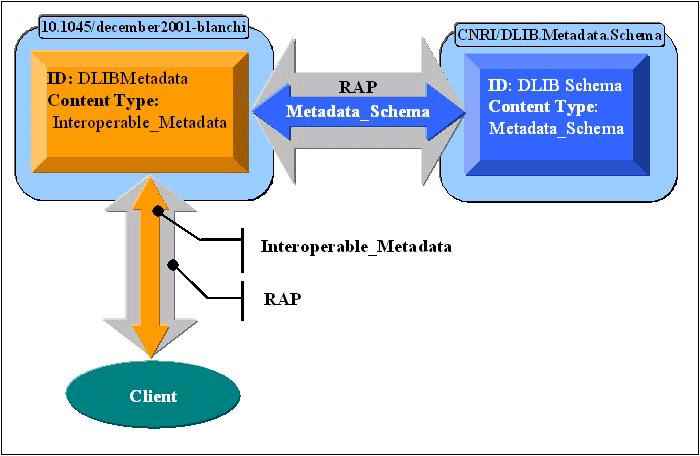
At this point the metadata creator has deposited an interoperable metadata digital object. The object can now be queried, and metadata conversion can be requested. 6.4 Dynamic metadata conversionAn intrinsic characteristic of digital objects is that they can request disseminations from each other. In addition to the quick and reliable way with which one digital object can determine its ability to interact with another based on its content types, this feature provides the basic functionality that enables dynamic metadata conversion to operate. This dynamic metadata conversion requires that both metadata and metadata schema digital objects exist concurrently, as they are both involved in the conversion process. Indeed, whereas the metadata digital object receives the original request for conversion, it delegates the actual metadata conversion to its respective metadata schema digital object. The delegation is set in the implementation of the Interoperable_Metadata content type. In the case of the 10.1045/december2001-blanchi digital object, for example, the object's content type is always to be associated with the DLIB type metadata defined by the CNRI/DLIB.Metadata.Schema metadata schema digital object. Furthermore, the 10.1045/december2001-blanchi object will delegate to CNRI/DLIB.Metadata.Schema all its metadata conversion requests. In our implementation, we designed the metadata digital object to provide a simple abstraction over the specific nature of the metadata encoding. The metadata schema digital object was given the responsibility for expressing and preserving the intrinsic characteristics of a given metadata schema and converting instances of its own metadata schema into one or more different schema.
|
|
|
|
The manner in which the interoperable metadata works is illustrated in Figure 4 and is described below:
7 ImplementationIn our prototype implementation we demonstrated how such a system facilitates the navigation of metadata registries. Building a user interface for search and query of metadata is fairly straightforward in a controlled environment where metadata schemas are relatively consistent and few in number. But in settings such as digital library federations and multi-organization archives, new schemas may be introduced regularly and will often differ in content and encoding. Our metadata registry allows distributed management of resources; when one organization adds new metadata or schemas, the changes are automatically reflected throughout the system. Users may interact with the system through a WWW gateway. The HTML representation of a metadata instance is generated by the digital object that contains the metadata instance. This shifts the responsibility of presentation to the creator of the metadata schema, and away from the metadata creator or WWW gateway. Of course, if desired, the WWW gateway creator may implement a different presentation style, and the metadata creator may choose a custom implementation of the schema object in order to provide a different presentation. The registry maintains an inverted index of the contents of all metadata objects in a search digital object. New metadata objects are registered with the search object by invoking its AddMetadata() method with the metadata object's handle as an argument. The search object will then index the metadata object. Keyword queries performed on the search object return a list of handles of metadata objects containing the keyword. When a user selects one of the listed metadata objects from a WWW browser, the gateway retrieves the metadata object's HTML rendering and returns the HTML to the user. Adding metadata based on new schemas requires no effort on the part of the WWW gateway administrators. Since the registry keeps track of metadata schemas, it is also able to provide cross-indexing between metadata instances and their schema. So when a user views a metadata instance, the user can follow links to its schema in order to learn more about the meaning and context of individual metadata fields. At the time of this writing, our implementation has registered metadata schemas for D-Lib Magazine and the University of Illinois Digital Library Initiative. 8 ConclusionThe digital object metadata registry was successfully implemented and demonstrated the feasibility and flexibility of our approach. Although the metadata schemas and metadata collections we experimented with were small, the current implementation of the system should scale reasonably well, both in its ability to handle new metadata and metadata schemas. As new metadata conversions are needed, new metadata schema conversion modules can be dynamically added to the infrastructure without requiring updates to any of the digital objects containing metadata. This framework could provide an attractive solution to collections in need of metadata migration. At the moment, creating metadata schema content type implementations requires development of software modules. Although this approach works well, efforts should be made to provide a non-programmatic solution for expressing conversions across metadata schema. Indeed, simple mappings across metadata schema could be expressed using simple equivalencies or mappings expressed in XML. This approach would make the task of adding new conversions as easy as attaching a single XML document to a general metadata schema conversion content type. Given the wide range of metadata schema that could reside within the metadata registry, it is very likely that, in many cases, the conversion from one metadata schema to another will not be supported. Experiments with dynamic graph searches through the set of metadata schema conversions could be used to dynamically determine a path of conversion sequences to produce the desired metadata conversion. The graph search would be easy to build, given that the source-target metadata schema conversion is easily expressible using a source and target metadata schema ID. The ability to create new metadata conversions using a sequence of pre-existing metadata conversions will accentuate the need for metadata conversion accuracy metrics. Finally, the use of dynamic interoperability determination using digital object content type identifiers, as well as the chaining of digital objects, provides a flexible framework that could be useful in other aspects of information integration. AcknowledgementSupport for the work described in this article came from funding by the Defense Advanced Research Project Agency (DARPA) on behalf of the Digital Libraries Initiative under Grant No. N66001-98-1-8908. 9 References[BM99] D. Bearman, E. Miller, G. Rust, J. Trant and S. Weibel, "A Common Model to Support Interoperable Metadata", D-Lib Magazine, January 1999; <http://www.dlib.org/dlib/january99/bearman/01bearman.html>. [DC] Dublin Core Metadata Initiative. Available at <http://dublincore.org/>. [KW] R. Kahn and R. Wilensky, A Framework for Distributed Digital Object Services, 1995. Available at <http://www.cnri.reston.va.us/k-w.html>. [FB96] N. Freed and N. Borenstein. Multipurpose internet mail extensions (MIME) part two: Media types. Request for Comments 2046, Internet Engineering Task Force, November 1996. [FKP96] N. Freed, J. Klensin, and J. Postel. Multipurpose internet mail extensions (MIME) part four: Registration procedures. Request for Comments 2048, Internet Engineering Task Force, November 1996. [MARC] Library of Congress Network Development and MARC Standards Office. MARC Standards. Available at <http://www.loc.gov/marc>. [PB99] S. Payette, C. Blanchi, C. Lagoze and E. Overly "Interoperability for Digital Objects and Repositories", D-Lib Magazine, May 1999. Available at <http://www.dlib.org/dlib/may99/payette/05payette.html>. [SDLIP] A. Paepcke, R. Brandriff, G. Janee, R. Larson, B. Ludaescher, S. Melnik, and S. Raghavan, "Search Middleware and the Simple Digital Library Interoperability Protocol" D-Lib Magazine March 2000. Available at <http://www.dlib.org/dlib/march00/paepcke/03paepcke.html>. [Z39] The Library of Congress Network Development & MARC Standards Office. International Standard, ISO 23950: "Information Retrieval (Z39.50): Application Service Definition and Protocol Specification" and ANSI/NISO Z39.50. Available at <http://www.loc.gov/z3950/agency/>. Copyright 2001 Corporation for National Research Initiatives |
|
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/december2001-blanchi
|