|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
|
|
D-Lib Magazine
|
|
J. Stephen Downie |
![]()
1. IntroductionThe Music Information Retrieval Evaluation eXchange (MIREX) [1] is a community-based formal evaluation framework coordinated and managed by the International Music Information Retrieval Systems Evaluation Laboratory (IMIRSEL) [2] at the University of Illinois at Urbana-Champaign (UIUC). IMIRSEL has been funded by both the National Science Foundation and the Andrew W. Mellon Foundation to create the necessary infrastructure for the scientific evaluation of the many different techniques being employed by researchers interested in the domains of Music Information Retrieval (MIR) and Music Digital Libraries (MDL). For the past two years MIREX participants have met under the auspices of the International Conferences on Music Information Retrieval (ISMIR). The first MIREX plenary convened 14 September 2005 in London, UK, as part of ISMIR 2005. The second plenary of MIREX 2006 was convened in Victoria, BC on 12 October 2006 as part of ISMIR 2006. Table 1 summarizes the wide variety of MIR/MDL tasks that have been formally evaluated over the past two years. Some of these tasks, such as "Audio Onset Detection," represent micro level MIR/MDL research (i.e., accurately locating the beginning of music events in audio files, necessary for indexing). Others, such as "Symbolic Melodic Similarity," represent macro level MIR/MDL research (i.e., retrieving music based upon patterns of similarity between queries and pieces within the collections). Table 1. Task Lists for MIREX 2005 and 2006
The tasks run for each MIREX were defined by community input via a set of topic-based mailing lists and Wiki pages [3]. In this sense, MIREX, is similar to the Text Retrieval Conference (TREC) [4] approach to the evaluation of text retrieval systems. Both MIREX and TREC are built upon three basic components:
2. Some ChallengesMIREX, however, does differ from TREC in one very important aspect. Unlike TREC, the datasets used in the MIREX evaluation process are not distributed freely among the participants. There are several overlapping reasons for this, including:
Since moving the data to participants is problematic, MIREX has the participants submit their algorithms to IMIRSEL for running against the collections. This scenario makes IMIRSEL personnel responsible for gathering (from various sources) and managing huge collections of music and ground-truth data (in a wide variety of formats). Responsibilities also include verifying the integrity of the test data itself [Note 1] and securing the data sets from malicious downloading. IMIRSEL is also responsible for managing the massive amounts of intermediate data that are created during the evaluation process, usually in the form of very large feature sets and similarity matrices that are common to many audio-based techniques. As Table 2 indicates, IMIRSEL has run 164 algorithms over the past two years. For IMIRSEL, the actual act of successfully running each of these algorithms has been one of its greatest challenges. During MIREX 2006, for example, the submissions employed various combinations of 10 different programming languages (e.g., Matlab, C, C++, Max-MSP, Perl, Python, Java, etc.) and execution environments (e.g., *nix, Windows, Mac, etc.). Notwithstanding constant reminders to the community to pay attention to defined input and output formats, not to dynamically link to non-existent specialized libraries, to have submissions return standard completion and error codes and to die gracefully when necessary, the vast majority of IMIRSEL personnel time has been spent debugging submitted code and verifying the validity of the output sets. Table 2. Summary data for MIREX 2005 and 2006
2. Some AdvancesMIREX 2006 marked the introduction of two important enhancements to the MIREX framework:
2.1 Friedman TestThe Friedman Test, also known as Friedman's ANOVA is a non-parametric test (i.e., does not assume normal distribution of the underlying data). Since many retrieval result sets have non-normal distributions, the Friedman Test has been used in the TREC domain for a number of years. It is used to determine whether there truly exist significant differences in system performances. For example, it helps determine whether System A with a "score" of "72" is really performing better than System B ("68") and/or System C ("65"), etc. Properly set up, it also allows for the statistically valid pair-wise comparison of each of the system results to help researchers better understand system differences. In this regard, is it much superior to the commonly misused multiple Student's t-tests. Several MIREX 2006 tasks underwent Friedman's ANOVA testing. These included "Query-by-Singing/Humming," "Audio Cover Song Identification," and "Audio Music Similarity and Retrieval." Similar to the results found in past TREC evaluations, the Friedman data for MIREX 2006 indicate that most MIR/MDL systems generally tend to perform on par with their peers (with a few outlying exceptions) and that most of the variance in the results appears across the various queries rather than between the systems themselves. 2.2 Human Evaluations and the Evalutron 6000A common complaint among MIREX 2005 participants was the lack of any human ex post facto input in evaluating the various tasks. All MIREX 2005 tasks had their ground-truth data determined a priori to the evaluation runs. This a priori system is adequate for such tasks as "Onset Detection," "Audio Key Finding" and "Audio Cover Song Identification" as the "answers" to these tasks are not really subject to human interpretation. However, MIREX 2006 participants wanted to take on two "real world" tasks ( "Audio Music Similarity and Retrieval" and "Symbolic Melodic Similarity") that required human evaluation of the results in order to best judge whether the results retrieved were truly similar in some way to each of the input queries. Since there exists no a priori data on the similarity of query music pieces to all possibly returned music pieces, an ex post facto human evaluation system was developed for MIREX by IMIRSEL called the "Evalutron 6000". After running the MIREX 2006 "Audio" and "Symbolic" similarity tasks, the top-x results ("candidates") for each query ("seeds") from each system were collated into "seed/candidate" sets with all source information removed (i.e., to make the evaluations "blind"). These "seed/candidate" sets were then mounted within the Evalutron 6000 which is a web-based relational database system that presented randomly selected "seed/candidate" lists to the evaluators and recorded their evaluation scores for each "seed/candidate" pair. Evaluators were drawn from members of the MIR/MDL with their identities not disclosed to the participants. To minimize evaluator fatigue, a system of presenting subsets of the results was devised. Table 3 presents the summary data concerning the distribution of "seed/candidate" sets among the evaluators. Table 3. Summary data for the "Audio Similarity" and "Symbolic Similarity" human evaluations
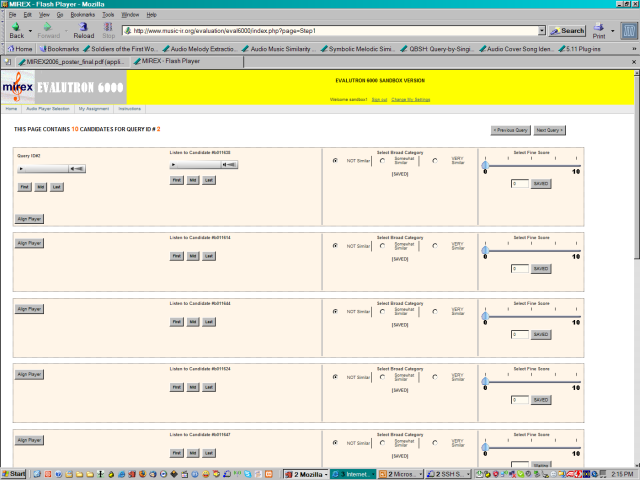
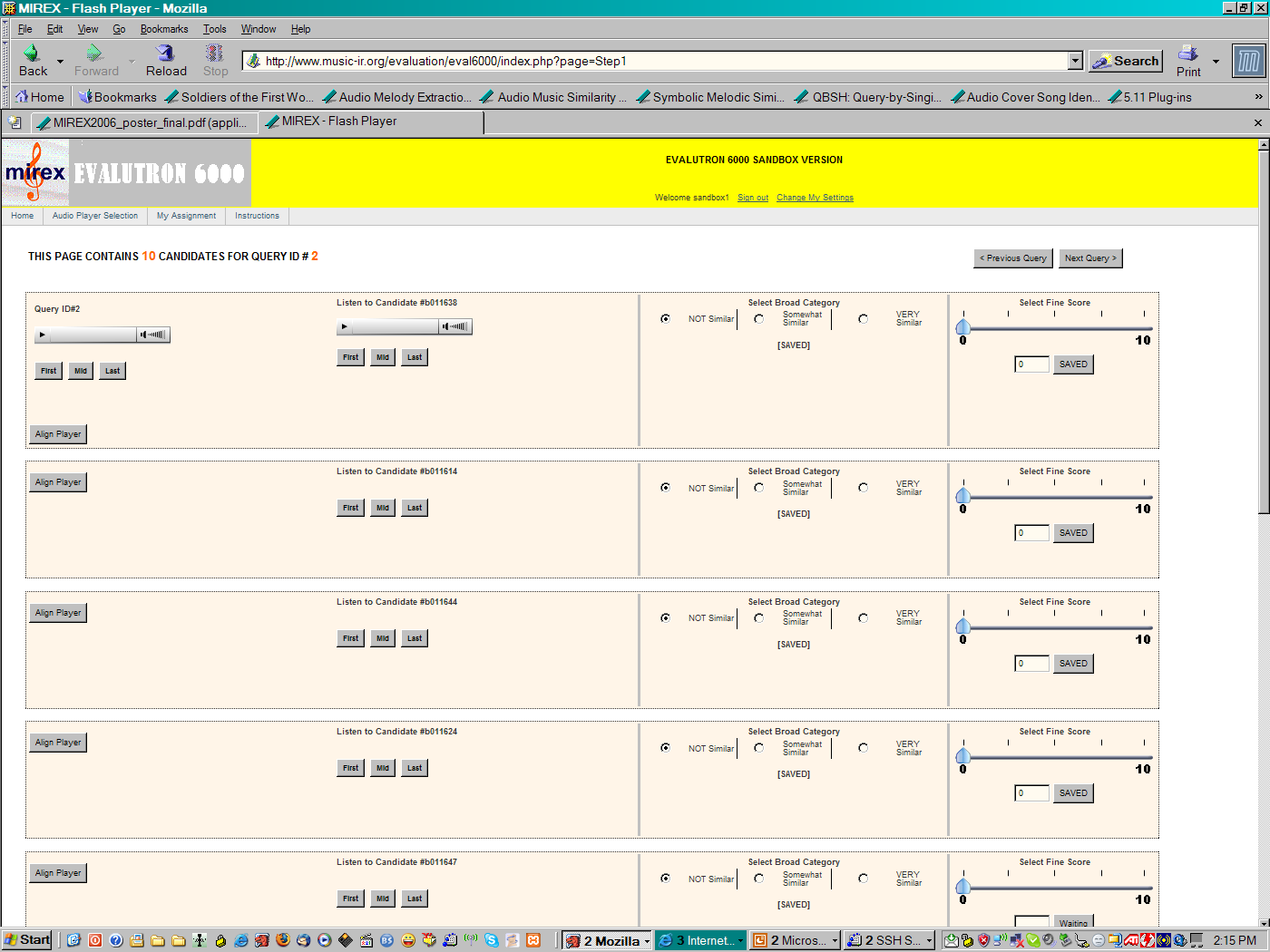
Figure 1 illustrates the Evalutron 6000 interface as seen by an evaluator for one "seed/candidate" listing. The left-most column has the "seed" embedded within an audio player that allows the evaluator to listen to the "seed" song and to start, stop and rewind it at will. The next column has an embedded audio player (with similar functionalities) for each of the "candidate" songs to be evaluated for similarity with respect to the "seed" song. The third column (second from right) takes the "Coarse" similarity score for each of the "seed/candidate" pairs. The "Coarse" scoring options include "Not Similar," "Somewhat Similar," and "Very Similar". The left-most column takes the "Fine" similarity score for the same "seed/candidate" pair recorded on a scale from 0 (not similar) to 10 (highly similar). While more formal correlation analyses are currently underway, preliminary data do indicate a strong consistency both across the different evaluators (i.e., inter-rater reliability) and strong correlations between the "Coarse" and "Fine" scores. IMIRSEL also plans on analyzing the log data associated with the evaluator interactions with the system to determine what improvements can be made to the MIREX 2007 iteration of the Evalutron 6000.
3. Future DevelopmentsIf MIREX is to grow and thrive, it is obvious that more robust mechanisms need to be put into place to alleviate the intensive commitment of labour resources MIREX places each year on the IMIRSEL team debugging code and result sets. Recent collaborations between IMIRSEL and UIUC's, Automated Learning Group (ALG) are opening up new opportunities for meeting this labour intensity challenge. IMIRSEL has worked with ALG before in the development of the Music-to-Knowledge (M2K) [5] music mining and evaluation framework. M2K is a Java-based data-flow environment built upon the foundation of ALG's modular Data-to-Knowledge (D2K) and Text-to-Knowledge (T2K) data mining systems [6]. IMIRSEL has been using M2K to help simplify the in-house running of the MIREX 2005 and 2006 evaluation tasks. Over the past several years, ALG has been developing a web service implementation of the D2K/T2K framework called D2KWS (D2K Web Services). The Tomcat/Java-based D2KWS technology has matured enough for related *2K projects to begin experimenting with independent, domain-specific (e.g., music retrieval evaluation) prototype deployments. IMIRSEL has set up an experimental D2KWS system to begin demonstration and proof-of-concept work on several "Do-It-Yourself" (DIY) MIREX evaluation frameworks [7]. 4. MIREX "DIY" Frameworks: Benefits and ChallengesA principal benefit to be realized by the creation of prototype DIY web service frameworks for MIREX is the labour shift from the IMIRSEL team back to submitters themselves. If implemented correctly, this labour shift actually provides tangible benefits to the submitters in exchange for their added effort. For example, a properly realized prototype would be available to the community 24/7/365. The time constraints imposed by constant debugging of code have made the rerunning of previous evaluation tasks difficult (which hinders meaningful comparisons across years). Also, because IMIRSEL plans on having the "DIY" system store all previous result sets, research productivity within the MIR.MDL community should improve along two fronts. First, submitters intending to participate in a given MIREX will have the ability to see how their algorithms are performing in near real-time with respect to their peer participants. Currently, the participating labs only see the "final" results sets that are made available shortly before the MIREX plenary making the de facto research cycle a year long. Second, non-participants who have novel MIR/MDL techniques will be able to submit and evaluate on their own anytime during the year to quickly determine whether or not their techniques are reaching state-of-the-art effectiveness. Notwithstanding the important benefits to be derived from the establishment of DIY MIREX services, there remain several significant challenges that need addressing. First, IMIRSEL must ensure that only results data are transmitted from the DIY system back to the participants. We are currently experimenting with several data choke/filtering schemes to make the transmission of music data impossible. Second, IMIRSEL needs to develop a permission system/policy that effectively shields the music data from malicious access attempts made by the submitted code sets. At this point, this remains an open question, so in the early days we will be opening the prototype to select external labs with which IMIRSEL has built up a high trust relationship. Third, IMIRSEL needs to make formal assessments of the computational resources that will need to be dedicated to a 24/7/365 service. These are non-trivial as, for example, the current music collections are roughly 1 terabyte in size (and growing) and the "feature sets" generated by many of the algorithms can be larger than the underlying music they represent and can take hundreds of CPU hours to compute. Third, and finally, we need to make the DIY MIREX service package easily transportable so other MIR/MDL labs can take on some of the administrative work and to make their own special collections available as standardized evaluation resources. 5. AcknowledgementsDr. Downie and his IMIRSEL team are supported by the Andrew W. Mellon Foundation and the National Science Foundation (NSF) under Grant Nos. NSF IIS-0340597 and NSF IIS- 0327371. 6. NoteNote 1: We are constantly surprised by the amount of "corrupted" data that makes its way into carefully collated music collections including damaged audio files, empty MIDI files, mislabeled file headers, etc. Since some task runs (e.g., "Audio Music Similarity and Retrieval") can take four days per algorithm to process, it is very important that the input data not cause a system crash during day three of a run. 7. References[1] Downie, J. Stephen, Kris West, Andreas Ehmann and Emmanuel Vincent (2005). The 2005 Music Information Retrieval Evaluation eXchange (MIREX 2005): Preliminary Overview. In Proceedings of the Sixth International Conference on Music Information Retrieval (ISMIR 2005), London, UK, 11-15 September 2005. Queen Mary, UK: University of London, pp. 320-323. Available: <http://ismir2005.ismir.net/proceedings/xxxx.pdf>. [2] Downie, J. Stephen, Joe Futrelle and David Tcheng (2004). The International Music Information Retrieval Systems Evaluation Laboratory: Governance, access, and security. In Fifth International Conference on Music Information Retrieval (ISMIR 2004), 10-14 October 2004, Barcelona, Spain. Barcelona, Spain: Universitat Pompeu Fabra, pp. 9-14. Available: <http://www.iua.upf.es/mtg/ismir2004/review/CRFILES/paper220-9f30cf2a39ea701625aad9ee86f6ac1f.pdf>. [3] See <http://www.music-ir.org/mirex2006/>. [4] See <http://trec.nist.gov/>. [5] See <http://music-ir.org/evaluation/m2k/>. [6] See <http://alg.ncsa.uiuc.edu/do/tools/>. [7] See <http://cluster3.lis.uiuc.edu:8080/mirexdiydemo/>. Copyright © 2006 J. Stephen Downie |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top
| Contents |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/december2006-downie
|
{kind=link}