|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Jeroen Bekaert Lyudmila Balakireva Patrick Hochstenbach Herbert Van de Sompel |
![]()
AbstractThis paper focuses on the use of NISO OpenURL and MPEG-21 Digital Item Processing (DIP) to disseminate complex objects and their contained assets, in a repository architecture designed for the Research Library of the Los Alamos National Laboratory. In the architecture, the MPEG-21 Digital Item Declaration Language (DIDL) is used as the XML-based format to represent complex digital objects. Through an ingestion process, these objects are stored in a multitude of autonomous OAI-PMH repositories. An OAI-PMH compliant Repository Index keeps track of the creation and location of all those repositories, whereas an Identifier Resolver keeps track of the location of individual complex objects and contained assets. An MPEG-21 DIP Engine and an OpenURL Resolver facilitate the delivery of various disseminations of the stored objects. While these aspects of the architecture are described in the context of the LANL library, the paper will also briefly touch on their more general applicability. 1. IntroductionWhen compared to most academic and research libraries, the Research Library of the Los Alamos National Laboratory (LANL) follows a rather unique strategy with respect to providing access to digital scholarly information. The general trend in digital library services is to have users access externally hosted materials through third party services, federated through a locally hosted Web Portal. In order to be self-supporting with respect to mission-critical scholarly information, the LANL library acquires or licenses a vast collection of digital scholarly assets, hosts those assets locally, and makes them accessible through locally developed user services. The locally hosted assets include secondary data feeds from ISI, BIOSIS, Inspec, and primary information feeds from major scholarly publishers such as Elsevier, Wiley, IOP, APS, etc. At the time of writing, the collection of locally hosted assets amounts to approximately 5 Terabytes of raw materials. In addition to that, the LANL library is actively investigating the deployment of Institutional Repository capabilities to host locally created materials such as technical reports, datasets, videotaped presentations, etc. Also, research is underway to augment the locally hosted collection with materials gathered by focused Web crawling and to include logs detailing the usage of repository assets in the repository as assets in their own right [1,2]. Hosting, archiving and making accessible such a vast and heterogeneous collection of scholarly assets in a consistent and sustainable manner is a challenge that touches on many areas of Digital Library practice and research, including the identification of assets, the expression of relationships between assets, the representation of assets by means of complex object models, and methods to ingest and access stored assets. Over the last year, the Digital Library Research and Prototyping Team of the LANL Research Library has worked on the design of a LANL Repository architecture aimed at ingesting, storing, and making accessible to downstream applications an ever growing heterogeneous digital collection. Also, a working prototype of the design has been implemented. While no claims are being made that the LANL Repository design or implementation are of a nature that merits a comparison with—say—the deliverables of the DSpace [3] or Fedora [4,5] projects, the authors do feel that the architecture has the following interesting properties that should be attractive for repository-related projects beyond the realm of the LANL Research Library:
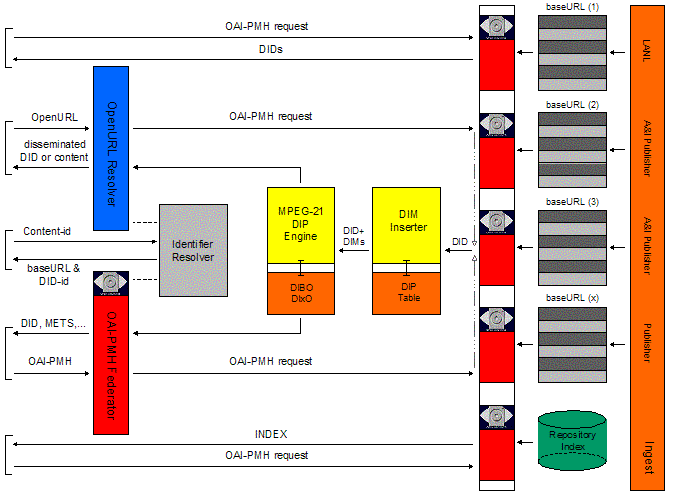
Figure 1 introduces the major components of the LANL Repository architecture. As can be seen, the LANL Repository hosts a multitude of autonomous OAI-PMH [7] repositories, each of which stores complex digital objects represented using the MPEG-21 DIDL [8] format. The Repository Index keeps track of the creation of such autonomous OAI-PMH repositories as well as of their location. The Repository Index is exposed as an OAI-PMH repository in its own right. The OAI-PMH Federator exposes the whole LANL Repository as a single OAI-PMH repository. It interacts with other components of the architecture mainly using the OAI-PMH. The OAI-PMH Federator hides the complexity of the environment to downstream harvesters, and becomes their single point of access to harvest from the LANL Repository. The aforementioned components of the LANL Repository architecture are only briefly discussed in Section 3. They will be described in detail in a forthcoming paper that focuses on aspects (2), (3) and (4) above. This paper elaborates on properties (2), (5), (6), and (7) of the LANL Repository architecture by describing its use of MPEG-21 DIP [9] and NISO OpenURL [10] for the dynamic dissemination of the stored complex objects and their contained assets. To that end, Section 4 describes the Identifier Resolver, which contains identifiers of stored content, as well as the location of the OAI-PMH repository in which the content resides. The Identifier Resolver is populated through OAI-PMH harvesting and can be queried in a variety of ways, including the Handle protocol [11]. The DIP Engine, which works according to MPEG-21 principles, is introduced in the environment to facilitate the delivery of various disseminations of stored content. A high-level insight in the operation of the DIP Engine is provided in Section 5. Section 5 also describes the OpenURL Resolver, which provides a front-end to the LANL Repository from which various disseminations of individual assets contained in the LANL Repository can be obtained using requests compliant with the forthcoming NISO OpenURL Standard.
2. Ingestion into the LANL repositoryIn many cases the delivered assets to be hosted in the LANL Repository are 'complex' in the sense that they consist of multiple individual datastreams that form a single logical unit. For example, a scholarly article may be delivered as a bundle that consists of metadata describing the article, the article itself in PDF and ASCII format, and the references made in the article expressed in XML. The complex nature of the assets led to an investigation regarding existing approaches to represent complex digital objects using XML wrappers, which resulted in the selection of the MPEG-21 Digital Item Declaration Language (DIDL) [8] as the sole way to store digital assets in the LANL Repository. DIDL introduces a set of abstract concepts that, together, form a well-defined data model for complex digital objects [note 1]. Based on those abstract concepts, DIDL defines a W3C XML Schema that provides broad flexibility and extensibility for the actual representation of compliant complex digital objects [note 2]. The DIDL data model recognizes the following entities, each of which has a corresponding XML element in the DIDL XML Schema:
Digital assets to be hosted by the LANL Repository can, in principle, be obtained in a variety of ways including FTP, OAI-PMH harvesting, Web crawling and delivery on physical media. A prototype ingestion process has been developed that turns each obtained asset into an autonomous XML document that wraps the datastream(s) of which the asset consists. Such an XML document is named a Digital Item Declaration (DID); all LANL DIDs are compliant with the MPEG-21 DIDL specification. As such, for example, the different datastreams of the previously mentioned scholarly article will be contained in a single DID, which will physically contain and/or reference the various datastreams that make up the complex object. The DID also contains information added by the ingestion process, for example, aimed at expressing relationships between contained datastreams, the media type of datastreams, etc. The actual use of DIDL in the LANL Repository, and the LANL DIDL profile is described in detail in [6] [note 3]. Appendix A shows an actual DID. For the purpose of this paper, the use of identifiers in LANL DIDs is important. Two types of identifiers are distinguished. The manner in which they are conveyed in DIDs has been revised to some extent when compared to our previous D-Lib paper [6]:
3. The multi-faceted use of the OAI-PMH in the LANL RepositoryOnce a delivered asset has been turned into a DID by the ingestion process, the DID is stored in an OAI-PMH repository. Data assets at LANL are typically received in large batches, since secondary or primary publishers that account for the bulk of the data to be stored in the LANL Repository deliver weekly or annual feeds. In those cases, an autonomous OAI-PMH repository is created per delivered batch. The OAI-PMH identifier used by these repositories is the DID-identifier, and the OAI-PMH datestamp is the datetime of creation or update of a DID. As those repositories only contain DIDs, the only supported metadataPrefix is DIDL. As a result, many autonomous OAI-PMH repositories exist in the LANL Repository. A special component, the Repository Index, keeps track of the creation and location of these autonomous OAI-PMH repositories. The Repository Index is itself an OAI-PMH repository. Through interaction with the Repository Index and the autonomous OAI-PMH repositories, harvesters working on behalf of downstream applications can selectively gather DIDs from the LANL Repository that were added or updated since the previous harvest, and—in good OAI-PMH Service Provider tradition—do something meaningful with them. In order to relieve downstream harvesters from the burden of having to interact with all autonomous OAI-PMH repositories, and having to understand other details of the LANL Repository architecture, the OAI-PMH Federator is introduced. The OAI-PMH Federator exposes the whole LANL Repository as a single OAI-PMH repository. The OAI-PMH Federator becomes the single point of access to the LANL Repository for harvesters—each of which is internal to LANL—hiding the complexity of the LANL Repository environment from them. As a result, the applications on whose behalves the harvesters operate can permanently remain in sync with the LANL Repository situation using a uniform technique—OAI-PMH harvesting. The multi-faceted use of the OAI-PMH in the LANL Repository, as briefly summarized in this Section, will be explained in detail in a forthcoming paper. 4. A special Service Provider: the Identifier ResolverHarvesters work on behalf of Service Providers, collect DIDs from the LANL Repository, and build services with the collected information. As a result, identifiers contained in the harvested DIDs become available in applications such as search engines. As mentioned before, these identifiers can either be DID-identifiers identifying DIDs or DID entities, or Content-identifiers identifying content contained in DIDs. Obviously it is essential that, when such identifiers show up in downstream applications, the corresponding content can be retrieved from the LANL Repository. For this purpose the Identifier Resolver is introduced to the environment. The Identifier Resolver is a special-purpose Service Provider that collects the information it requires from the LANL Repository through recurrent OAI-PMH harvesting. From the harvested information, it only uses the DID-identifiers, the Content-identifiers, and the baseURL of the OAI-PMH repository in which these occur. The Identifier Resolver consists of two modules, reflecting the nature of the contained identifiers:
Tables[ 1] and [2] illustrate the content of the Identifier Resolver. As can be seen, all identifiers are expressed using the proposed 'info' URI scheme [14] [note 6]. In Table 1, 'info:lanl-repo/i/58f202ac' and 'info:lanl-repo/i/002035b2' are DID-identifiers, of DIDs located in the OAI-PMH repository with baseURL "BaseURL(3)" and "BaseURL(6)", respectively. As these are DID-identifiers, the value of the OAI-PMH identifiers of the DIDs in these repositories is equal to the value of the DID-identifiers. In Table 2, Content-identifiers 'info:lanl-repo/apsmeta/123456', 'info:lanl-repo/aps/1202252' and 'info:lanl-repo/biosis/abcdef' identify content contained in the DIDs with DID-identifier 'info:lanl-repo/i/58f202ac' and 'info:lanl-repo/i/002035b2', respectively. Within these DIDs, the Items with which these Content-identifiers are associated have XML IDs '445998', '899952', and '444940', respectively. Appendix A shows the DID with DID-identifier 'info:lanl-repo/i/58f202ac'.
The Identifier Resolver is accessible to applications in a number of ways, including the Handle protocol, a SOAP-based [15] access mechanism, and a C library. Through consultation of the Identifier Resolver, an application can use the OAI-PMH to retrieve the DID with a specified DID-identifier, or the DID in which content with a specified Content-identifier resides. This works as follows:
Because Content-identifiers can always be mapped to DID-identifiers through the Identifier Resolver, only DID-identifiers will be used for the discussions in the remainder of this paper. In addition to the information shown in Table 2, the Identifier Resolver also keeps track of the location of assets for which information providers delivered updated versions. For DIDs, only a single version will ever correspond with a given DID-identifier. However, when an update for content contained in a DID is delivered, typically a new DID is created and stored in another OAI-PMH repository as was the original DID. As a result, the location information for that content changes, and this is reflected in the Identifier Resolver by updating the content of the location information for the Content-identifier involved and saving previously existing information in a history section. 5. Disseminating assets from the LANL RepositoryAs was described, downstream applications obtain DIDs from the LANL Repository through OAI-PMH harvesting. These applications will reference DIDs, DID entities, or more commonly, assets contained in DIDs to allow agents that use the applications to retrieve the referenced entities from the LANL Repository. In order to facilitate the retrieval of various —dynamically generated—disseminations of stored assets, a solution has been designed that is based on the MPEG-21 DIP specification, and on the NISO OpenURL. Various aspects of the solution, of which an initial implementation has been developed, are described in this section. 5.1 Associating Services with DID Entities: MPEG-21 Digital Item MethodsMPEG-21 Digital Item Processing (DIP) specifies an architecture pertaining to the dissemination of DIDs. This MPEG-21 Part, that remains to be standardized, introduces the concept of a Digital Item Method (DIM), as a means to associate services with a DID and/or its entities. It is worthwhile mentioning that the MPEG-21 DIM concept is closely related to Fedora's "behavior" concept [4,5]. A DIM is physically contained in the same DID as the entity of the DIDL data model with which it is associated. In the current, pre-standard, practice a DIM is typically accommodated in a Component entity of the DID, which must contain at least 2 other DID entities:
A DIM is associated with an entity of a DID using the dip:objectType/dip:Argument technique, explained in detail in [6]:
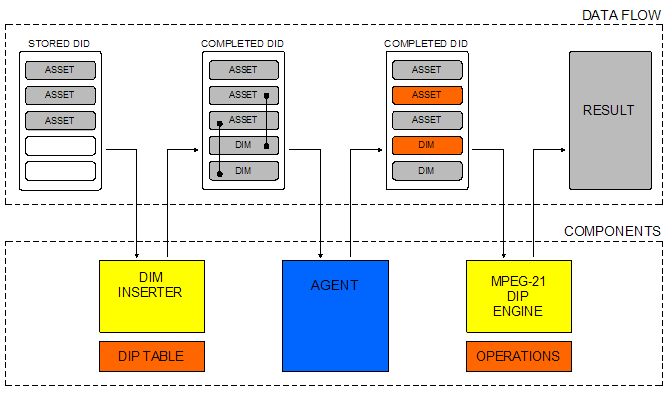
This is illustrated in the DID shown in Appendix A, in which a service is associated with a Component through the value 'urn:uuid:8f64eabf-1dd2-11b2-a3f1-0800209a5b6b'. That value is used as the content of both the dip:ObjectType element of the Component, and the dip:Argument element of the DIM. The DIP specification allows entities to have more than one dip:ObjectType. Also, a DIM can bind to more than one entity by using multiple dip:Argument elements, each of which connects via the dip:ObjectType to the entities. It is worthwhile mentioning that changes have been made to the DIP specification since the publication of our previous D-Lib paper [6]. Processing methods in DIDs are now recognizable by their use of the reserved dip:Arguments element. The notion of a special Item—the Processing Item—reserved to contain processing methods is no longer supported. 5.2 Dynamically Associating Services with DID entities in the LANL Repository: the Placeholders and the DIP TableAs explained in [6], the authors felt a general level of discomfort with statically embedding DIMs in DIDs stored in the LANL Repository. Therefore, it was decided to embed Placeholders for DIMs instead of actual DIMs in stored DIDs. When the dissemination of a stored DID is requested, the DIM Inserter module dynamically adds DIMs to that DID in a process that is based on the values of the Placeholders contained in the DID. The result is a Completed DID, which contains assets and associated methods. Placeholders can be attached at the Container, Item and Component level of a DID. At the Container level, the Placeholder conveys to which 'family' the DID belongs. For example, the Placeholder value 'container:ai' shown in Table 3 is used to convey that a DID only contains metadata. This 'family' information is closely related to the ingestion process. At the Component level, the Placeholder specifies the digital format of the contained datastream. Awaiting the emergence of global unique identifiers for digital formats, values are currently used as shown in the second entry of Table 3. These values convey the media type of a datastream as well as a broad classification of the nature of its format. The latter is based on an ontology under development by the Digital Format Registry project [17]. The exact nature of Item-level Placeholders is a matter of ongoing research. Placeholder values are conveyed in DIDs via a diph:PlaceHolder element from a self-defined XML Namespace. The actual insertion of DIMs in a DID is achieved through a look-up in a special-purpose registry—the DIP Table. The DIP Table lists all services that can be associated with DID entities from the LANL Repository. In the DIP Table, each service has a Service Identifier. Also, for each service, the DIP Table contains a Placeholder value—as used in the DIDs—with which the service is associated. For example, the first entry of [Table 3] shows that the service with Service Identifier 'info:lanl-repo/service/table_of_contents' is associated with all DID entities that have 'container:ai' or 'container:aps' as a Placeholder value. For each service, the DIP Table also lists a pointer to the DIM code that actually implements it.
The dynamic insertion of DIMs in a DID, as performed by the DIM Inserter module of the LANL Repository, is explained by means of the following example. It is also illustrated in the left part of [Figure 2]. Consider a DID, which has a Component-level Placeholder with a value of 'component:content-stream:text:structured-text:mark-up-language:xml#application/marc+xml'. A look-up of this Placeholder value in the DIP Table reveals that a service with Service Identifier 'info:lanl-repo/service/marc_2_mods', and a pointer to DIM code 'gov.lanl.library.dip.marctomods' are associated with it. This service must be added to the DID. This requires:
In order to embed all relevant DIMs into a DID upon dissemination, the process as explained above is repeated for every Placeholder entry found in the DID. The DID of Appendix A actually illustrates the result of the above actions applied for Placeholder values 'container:aps' and 'component:content-stream:text:structured-text:mark-up-language:xml#application/marc+xml'.
5.3 Using an MPEG-21 DIP Engine to process service requests for DIDsMPEG-21 DIP introduces a component, named a DIP Engine, that is capable of processing DIDs upon request of an agent. A DIP Engine is able to respond to service requests in which the following information is conveyed:
The actual functioning of the LANL DIP Engine is illustrated in Figure 2. Upon receipt of a service request, the DIP Engine will extract the identified DID entity, and DIM. As was mentioned, DIMs are expressed using a language that normatively includes ECMAScript. This ECMAScript does not actually contain all the code required for the implementation of the service request. Rather, the ECMAScript is used by the DIP Engine to bootstrap the process of implementing the service request and to actually coordinate it. To that end, the ECMAScript contains calls to so-called Digital Item Operations. Two types of Digital Item Operations are distinguished in MPEG-21 DIP:
An MPEG-21 DIP Engine is typically thought of as a client-side software component that operates on a user terminal. At LANL, a server-side prototype implementation of a DIP Engine has been developed. It currently supports only a few of the DIBOs defined by MPEG-21. But various DIxOs have been coded that implement services that are relevant for and specific to the nature of the collection stored in the LANL Repository. As a matter of fact, all services listed in Table 3 are implemented using DIxOs. Also, Java-based templates have been developed to facilitate the straightforward creation of more DIxOs. For example, one template can be used as the basis for all DIxOs that use XSL transforms, another for DIxOs that need to call external applications, and yet another for the interaction with Web Services. 5.4 Using NISO OpenURL to convey service requestsThrough OAI-PMH harvesting, downstream applications obtain DIDs and use contained assets in their services. For example, a search engine might extract all textual information from harvested DIDs and make it available for searching by end-users. In this case, brief search results will point back to the corresponding asset stored in the LANL Repository. Obviously, in such pointers the DID-identifiers, their associated XML IDs, and the Content-identifiers will play a crucial role. Also, as was shown, the proposed solution allows for the definition of several services aimed at delivering various disseminations of content. Hence, requests to retrieve content should also be able to convey which actual dissemination of the identified content is requested. This, as a matter of fact, is equivalent to conveying the Service Identifier, as shown in Table 3, of the service that implements the required dissemination. Since many downstream applications are Web-based, the discussion will assume that requesting disseminations from the LANL Repository is an HTTP-based process. It turns out that the forthcoming NISO OpenURL Standard [10] provides a perfect framework to convey such dissemination requests. The initial OpenURL specification [18] was specifically introduced for the purpose of reference linking, and was targeted at facilitating the provision of context-sensitive reference links for popular types of scholarly works such as journal articles and books [19]. Hereby, identifiers and metadata describing the work are conveyed using a controlled-vocabulary HTTP GET request to a user-specific linking server, which uses its knowledge base and the incoming information to provide a user with appropriate services pertaining to the work. A generalization of the essential components of the initial OpenURL solution [20] inspired the nature of the forthcoming NISO OpenURL Standard, which provides a generic framework for the delivery of context-sensitive services pertaining to whichever type of resource referenced in a networked environment. To that end, the OpenURL Standard introduces the notion of a ContextObject, which is an information construct that contains descriptions of various entities involved in the process of providing context-sensitive services. The entities are shown in Table 4.
Each entity of the ContextObject can be described by means of identifiers, by means of metadata, and/or by means of private data. A ContextObject can be represented in many ways, and currently, a Key/Encoded-Value (KEV) representation and an XML representation have been defined. A representation of a ContextObject can be transported to a networked system named a Resolver, in order to request services pertaining to the Referent described in it. To decide upon the nature of such services, the Resolver may take entities other than the Referent into account. The network transport can occur using various network protocols, and currently transport over HTTP and HTTPS have been defined. From the above, two mappings follow easily:
An OpenURL Resolver is introduced in the LANL Repository to which all dissemination requests originating from downstream applications will be targeted. Using examples provided earlier in this paper (Tables 1-3), the HTTP transport of the OpenURL Standard, and its KEV representation of the ContextObject, the following are valid OpenURLs to convey dissemination requests to this OpenURL Resolver:
Content-identifiers can also be used in OpenURL requests. However, as Content-identifiers can always be mapped to a corresponding DID-identifier (see Section 4), only DID-identifiers are considered here. Currently, the Referent and ServiceType are the only entities of the ContextObject that are used in OpenURL requests. But, NISO OpenURL allows expressing other entities that can be taken into account when responding to dissemination requests. Conveying Requester information may be of particular interest, as this would allow adapting the actual dissemination to the agent requesting it. Requester information could convey identity, and this would allow responding differently to the same service request for the same asset depending on whether the requesting agent is human or machine. Or different humans could receive different disseminations based on recorded preferences. But the NISO OpenURL specification is purposely very generic and extensible, and would also support conveying the characteristics of a user's terminal, and/or the user's location via the Requester entity. Such information could be passed on to the DIP Engine and could be taken into account in the delivery of an actual dissemination. As a matter of fact, the expressiveness of NISO OpenURL seems to resonate nicely with the nature of the MPEG-21 Digital Item Adaptation (DIA) [21] effort that focuses on transforming assets for delivery by taking into account characteristics of the requesting terminal, network conditions and other contextual information. 5.5 Putting MPEG-21 DID, MPEG-21 DIP, NISO OpenURL, and the OAI-PMH togetherThis section provides a walkthrough of the processes involved in responding to the two OpenURL requests shown above. The Table of Contents request involves the following steps:
With regard to the MARCXML to MODS request, the process involved in responding to this OpenURL request is similar to the one described above, with these nuances:
6. ConclusionThis paper has described aspects of the LANL Repository architecture pertaining to the dissemination of complex objects or their contained assets. In this architecture, NISO OpenURL is used to encode dissemination requests. This takes the actual use of OpenURL to a new level. Indeed, OpenURL has so far only been used to deliver services that were calculated based on metadata that describes a referenced resource. In the proposed solution, the services are based on the resource itself. As NISO OpenURL is generic and extensible, it offers a flexible framework for the expression of contextual dissemination requests. Although the authors have only scratched the surface of the use of NISO OpenURL in the proposed solution, it seems fair to state that it resonates nicely with MPEG-21 DIP, and potentially MPEG-21 DIA. NISO OpenURL is also attractive in another sense. One of the core assumptions made in the OpenURL Framework is the existence of a multitude of OpenURL Resolvers, each of which can have its own behavior when responding to OpenURL requests. Typically this behavior is based on the nature and/or preferences of a community on whose behalf a Resolver operates. The natively distributed and protocol-based nature of the proposed architecture allows us to speculate on its deployment in a Web context. What was described as the LANL Repository now becomes a federation of OAI-PMH repositories distributed across the Web. In such a federation, components such as the Repository Index, the Identifier Resolver and the OAI-PMH Federator can play roles that are very similar to those described in the context of the LANL Repository. One can easily imagine the existence of an OpenURL Resolver per institution in the federation. As is the case in the OpenURL Framework that has successfully been deployed for reference linking in the scholarly community, users would direct dissemination requests to the OpenURL Resolver of their institution. The institutional Resolver would respond to such requests by obtaining a stored complex object from the appropriate OAI-PMH repository in the federation. And, in a process similar to the one performed by the described DIM Inserter, locally defined services could be attached to the object. Actually, assuming the existence of globally unique identifiers for digital formats, the addition of such services based on digital format is not even difficult to imagine. The result is a framework in which each institution of the federation can implement different preferences with respect to the nature of the dissemination of the same content. AcknowledgementsThe authors would like to thank their colleagues Henry Jerez, Xiaoming Liu, and Thorsten Schwander from the LANL Digital Library Research and Prototyping team for their contributions to the reported work, and the LANL library director, Rick Luce, for his ongoing support. Jeroen Bekaert also wishes to thank the Fund for Scientific Research (Flanders, Belgium) for his PhD scholarship.
References
Notes
Appendix A: A DID containing DIMs associated with a DID entity
Copyright © 2004 Jeroen Bekaert, Lyudmila Balakireva, Patrick Hochstenbach and Herbert Van de Sompel |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/february2004-bekaert
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||