An Architecture for Information
in Digital Libraries
William Y. Arms
Christophe Blanchi
Edward A. Overly
Corporation for National Research Initiatives
Reston, Virginia
{warms, cblanchi, eoverly}@cnri.reston.va.us
D-Lib Magazine, February 1997
ISSN 1082-9873

Contents
1. Background
Flexible organization of information is one of the key design challenges in any digital library. For the
past year, we have been working with members of the National Digital Library Project (NDLP) at the
Library of Congress to build an experimental system to organize and store library collections. This is a
report on the work. In particular, we describe how a few technical building blocks are used to organize the
material in collections, such as the NDLP's, and how these methods fit into a general distributed computing
framework.
The technical building blocks are part of a framework that evolved as part of the
Computer Science Technical Reports Project (CSTR)
[1]. This framework is
described in the paper, "A Framework
for Distributed Digital Object Services", by Robert Kahn and Robert Wilensky
(1995)[2]. The main building blocks are: "digital objects", which are
used to manage digital material in a networked environment; "handles", which identify digital objects and
other network resources; and "repositories", in which digital objects are stored. These concepts are
amplified in "Key Concepts in the Architecture of the Digital Library", by William Y. Arms (1995)
[3].
In summer 1995, after earlier experimental development, work began on the implementation of a full
digital library system based on this framework. In addition to Kahn/Wilensky [2] and Arms [3], several
working papers further elaborate on the design concepts. A paper by Carl Lagoze and David Ely,
"Implementation
Issues in an Open Architectural Framework for Digital Object Services"
[4],
delves into some of the repository concepts. The initial
repository implementation was based on a paper by Carl Lagoze, Robert
McGrath, Ed Overly and Nancy Yeager, "A Design for Inter-Operable Secure
Object Stores (ISOS)"
[5]. Work on the handle system, which began in 1992, is described in
a
series of papers that can be found on the Handle Home Page
[6].
The National Digital Library Program (NDLP) at the Library of Congress is a large scale project to
convert historic collections to digital form and make them widely available over the Internet. The program
is described in two articles by Caroline R. Arms, "Historical Collections for the National Digital Library"
[7]. The NDLP itself draws on experience gained through the earlier
American Memory Program
[8].
Based on this work, we have built a pilot system that demonstrates how digital objects can be
used to organize complex materials, such as those found in the NDLP. The pilot was demonstrated to
members of the library in July 1996. The pilot system includes the handle system for identifying digital
objects, a pilot repository to store them, and two user interfaces: one designed for librarians to manage
digital objects in the repository, the other for library patrons to access the materials stored in the repository.
Materials from the NDLP's Coolidge Consumerism compilation have been deposited into the pilot
repository. They include a variety of photographs and texts, converted to digital form. The pilot
demonstrates the use of handles for identifying such material, the use of meta-objects for
managing sets of digital objects, and the choice of metadata. We are now implementing an enhanced
prototype system for completion in early 1997.
2. Overview of the Digital Library System
2.1 The structure of information and sets of digital objects
This section gives an overview of the concepts as background to the more detailed explanation in
Section 3 and the technical information in Section 5.
The purpose of the information architecture is to represent the riches and variety of library information,
using the building blocks of the digital library system. From a computing view, the digital library is built up
from simple components, notably digital objects. A digital object is a way of structuring
information in digital form, some of which may be metadata, and includes a unique identifier,
called a handle. (Digital objects and handles are described in more detail in Section 4.) However,
the information in the digital library is far from simple. A single work may have many parts, a complex
internal structure, and one or more arbitrary relationships to other works. To represent the complexity of
information in
the digital library, several digital objects may be grouped together. This is called a set of digital
objects. All digital objects have the same basic form, but the structure of a set of digital objects
depends upon the information it represents.
The different types of material in a digital library, information can be divided into categories,
e.g.: text with SGML mark-up, World Wide Web objects, computer programs, or digitized radio programs.
Within each category, rules and conventions describe how to organize the information as sets of digital
objects. For example, specific rules will describe how to represent a digitized radio program. For each
category, the rules describe the digital objects that are used to represent material in the library, how each is
represented, how they are grouped as a set of digital objects, the internal structure of each digital object, the
associated metadata, and the conventions for naming the digital objects.
A user interface that is aware of the rules and conventions applying to certain categories of information
is able to interpret the structure of the set of digital objects. Complex information can be presented without
the user having any knowledge of the complexity. Since the user interface recognizes how material is
represented, it can provide unsophisticated users with flexible access to rich and complicated information.
2.2 Components of the computer system
The digital library framework permits many different computer systems to coexist. The key
components are shown in the figure below. They run on a variety of computer systems connected by a
computer network, such as the Internet.
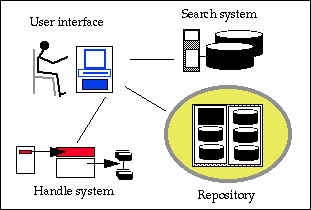
Major system components
To demonstrate this framework, we implemented a pilot system. A more comprehensive
prototype will be completed early in 1997.
- User interfaces
- Both the pilot and the prototype have two user interfaces: one for the users of the library, the other for
the librarians and system administrators who manage the collections. Each user interface is in two parts. A
standard Internet browser is used for the actual interactions with the user. This can be Netscape
Navigator, Microsoft's Internet Explorer, or the Grail browser developed by our colleagues at CNRI. The
browser connects to client services, which provide intermediary functions between the browser
and the other parts of the system. The client services allow the user to decide where to search and what to
retrieve; they interpret information structured as digital objects; they negotiate terms and conditions,
manage relationships between digital objects, remember the state of the
interaction, and convert among the protocols used by the various parts of the system.
- Repository
- Repositories store and manage digital objects and other information. A large digital library may have
many repositories of various types, including modern repositories, legacy databases, and Web servers.
Section 4 of this report describes the pilot repository that we have implemented and enhancements planned
for the prototype. The interface to this repository is called the repository
access protocol (RAP). Features of RAP are explicit recognition of rights and
permissions that need to be satisfied before a client can access a digital
object, support for a very general range of disseminations of digital objects,
and an open architecture with well defined interfaces.
- Handle system
- Handles are general purpose identifiers that can be used to identify Internet resources, such as digital
objects, over long periods of time and to manage materials stored in any repository or database. CNRI's
handle system is a computer system that provides a distributed directory service for identifiers
(handles) for Internet resources. When used with the repository, the handle system receives
as input a handle for a digital object and returns the identifier of the
repository where the object is stored.
- Search system
- The design of the digital library system assumes that there will be many indexes and catalogs that can
be searched to discover information before retrieving it from a repository. These indexes may be
independently managed and support a wide range of protocols. The pilot system is independent of any
search system; the prototype is being linked to CIIR's InQuery system, which is already in use at the Library
of Congress.
2.3 An example of how these components support a user's query
To understand the function of these system components, here is an example of how they allow a user to
carry out a simple query. Suppose that a user is looking for a digitized
photograph showing both President Calvin Coolidge and President Herbert Hoover. The interaction could
pass through the following stages.
The first stage is to search for digitized photographs that fit the required criteria. The client
services provide the user's browser with a form for searching. The
user fills in the form with a search query, asking for photographs of Coolidge and Hoover. The completed
form is sent to the client services. The client services translate the query into the formats and protocols
required by the search system. For example, the search system may use Z39.50. The client services
conduct a Z39.50 session with the search system and obtain a list of the digital objects that satisfy the
query. Each digital object is identified by its handle.
The next stage is for the user to select a digitized photograph to view. The client services
present the user's browser with the list of digital objects found through the search system (currently as an
html page with links to click). The user selects the required photograph.
The third stage is retrieval of the digitized photograph. The client services send the handle of
the chosen photograph to the handle system, which returns the address of the repository. The client services
pass the handle to the repository, using the RAP protocol. Several versions of the photograph may be
stored in the repository as a set of digital objects, identified by the handle. The client services select one,
perhaps a small thumbnail, and requests it from the repository. All RAP transactions pass through an
explicit terms and conditions step. Checking the terms and conditions associated with this digital object
may need negotiation between the client services and the repository, or direct interaction with the user.
Finally, the digitized photograph that was chosen is delivered from the repository, via the client
services, to the user's browser and displayed on the screen.
3. The Information Architecture
3.1 Outline of the Information Architecture
The structure of information in a digital library
Interactions, such as the query described above, require that information in a digital library be
organized effectively. Within the library, information is stored as basic units of digital information, e.g., a
digitized map, a section of text, a Web page, a scanned photograph, etc. In digital form, each basic unit is a
sequence of bits, but users often want to refer to material at a higher level of abstraction than the individual
item. Common English terms, such as a "report", a "computer program", or an "opera" can refer to many
items that are variants of each other. They may have different formats, minor differences of content,
different usage restrictions, and so on, but for some purposes users are willing to consider them as
equivalent.
The issues to be addressed in structuring information include the following.
- Digital materials are frequently related to other materials by relationships such as part/whole,
sequence, etc. For example, a digitized text may consist of pages, chapters, front matter, an index,
illustrations, and so on. In the World Wide Web, a typical item may include several pages of text, with
embedded images, and links to other information. A single computer program is assembled from many
files, both source and binary, with complex rules of inclusion. Materials belong to collections. These may
be collections in the traditional, custodial sense; they may be the on-line groupings provided by a publisher;
or
they may be the pages maintained by a Webmaster.
- The same item may be stored in several digital formats. Sometimes, these formats are exactly
equivalent and it is possible to convert from one to the other (e.g., an uncompressed image and the same
image stored with a loss-less compression). At other times, the different formats contain different
information (e.g., differing representations of a page of text in SGML and PostScript formats).
- Because digital objects are easy to change, different versions are created continually. (Some
organizations change their Web home page several times per month.) Versions may differ by a single bit or
may be very different. When existing material is converted to digital form, the same physical item may be
converted several times. For example, a scanned photograph may have a high resolution archival version, a
medium quality version, and a thumbnail.
- Each element of digital information may have different rights and permissions associated with
it.
- The manner in which the user wishes to access material may depend upon the characteristics of
computer systems and networks, and the size of the material. For example, a user connected to the
digital library over a high speed network may have a different pattern of work from the same user when
using a dial-up line.
The information architecture described here provides a general approach to organizing the material
within the digital library in such a manner that computer programs can understand the structure of the
material and carry out the interactions that the user wishes.
Basic principles
The information architecture is motivated by the following basic principles:
- Users and their applications programs must be given flexibility. Since users explore material in almost
every conceivable manner, the organization of information should not be biased by expectations about how
users will approach the material, their level of expertise, or the sequence in which items will be accessed.
- Collections must be straightforward to manage. In digital libraries, as in all libraries, comparatively
small professional staffs manage very large collections of material. The architecture must allow the staff to
concentrate on curatorial aspects, and free them from routine tasks wherever possible.
- The information architecture must reflect the economic, social, and legal frameworks developing in the
information infrastructure. In particular it must recognize that information is valuable, subject to terms and
conditions, and is transmitted over insecure networks that cross national boundaries. These considerations
are a driving force behind the technical framework
([2] and
[3]) which underlies the architecture.
Data types, structural metadata, and meta-objects
The information architecture is based on three simple concepts: data types, structural metadata, and
meta-objects. A data type describes technical properties of data, such as format, or method of
processing. Structural metadata is metadata that describes the types, versions, relationships and
other characteristics of digital materials. A meta-object is an object that provides references to a
set of digital objects. In its simplest form, a meta-object is a list of handles of other digital objects. For
example, a poetry anthology might be represented by one digital object per poem. A meta-object for the
anthology is a digital object that lists all the poems. An important example of a meta-object is a digital
object that lists all converted versions of a specific physical item.
As part of the pilot system, with colleagues at the Library of Congress, we developed specifications of
structural metadata and meta-objects for two categories of material, scanned photographs and digitized
texts. For the prototype we plan to extend these specifications to other categories of material.
In developing these rules for each category of material, certain guidelines were applied to all categories.
- All data is given an explicit data type
Each item of data has an associated data type. The type specifies that the data has a certain format (e.g.,
the data is in the JPEG format), should be processed in a specific way (e.g., a computer program is written
in the C programming language), or has a specific organization (e.g, a section of text has been marked up
with SGML tags).
- All metadata is encoded explicitly
All metadata that is needed to manage the collection or to provide access is coded explicitly. In
particular, no semantic information is included in any name that is not encoded separately as metadata.
(This can be contrasted with computer file systems, where semantic information is often embedded in file
names, such as ".txt" indicating a text file.)
- Handles are given to individual items of intellectual property
Whenever an item of information might be used on its own, it is given its own handle and made into a
separate digital object. By having its own handle, an item may be accessed independently. This provides
maximum long-term control and flexibility. For example, if a digitized text contains illustrations that could
potentially be used independently, each illustration is made into a separate digital object with its own
handle.
- Meta-objects are used to aggregate digital objects
In a digital library, the full metadata about a single piece of information may exist in several places
within a repository and also in external catalogs, indexes, or finding aids. Maintaining links to all the
metadata is a huge task, and therefore the architecture does not require them. Much is gained from having a
meta-object for each item that provides links to all versions of the item and to all structural metadata.
External bibliographic records can then refer to the meta-object and not need to know details of a set of
digital objects.
- Handles are used to identify items listed in meta-objects
A meta-object contains a list. We use handles to identify the items of these lists. This provides a robust,
flexible structure that allows subsequent reorganization of the collection with minimal effort.
The interpretation of these rules is often a matter of judgment, with a trade-off between a powerful
representation of information, which is flexible in use but laborious to manage, and a simpler
representation. Ultimately such decisions can not be dictated by the architecture or the system designers.
They must be made by the curators who are knowledgeable about the material and responsible for managing
it. The system provides straightforward methods for curators to decide how best to manage collections.
3.2 An Example of the Use of Meta-objects
Scanned photographs in the NDLP collections
Scanned photographs are a simple category of material that illustrates the general principles of how to
use meta-objects. In the National Digital Library Program, most of the photographs to be scanned are
single items, but there are numerous interesting cases to consider, including sets of photographs, and large
photographs and posters that are scanned in sections.
With colleagues from the Library of Congress, we have developed guidelines for representing each
scanned photograph as a set of digital objects linked through a meta-object.
Digital objects for a scanned photograph
When a typical photograph is scanned, three or more versions are produced. In NDLP terminology,
they are called a low resolution "thumbnail", an intermediate resolution "access" image, and a high
resolution "reference" image. Separate digital objects are created for each individual version. They each
contain metadata specific to the version and the data bits for the image. To describe the photograph and its
digitized versions, a meta-object is created. It contains metadata that is common to all versions of the
photograph and handles for the three separate versions. Thus the scanned photograph is represented by a
set of four digital objects.
- Digital objects for individual versions
- The digital object for each individual version of a scanned photograph has the following
information:
- Key metadata. Key metadata is metadata contained in the digital object that is used to manage
the object in a networked environment. It includes the handle, and the rights and permissions associated
with the digital object.
- Structural metadata. This includes other metadata associated with the specific version. It
includes fields for description, owner, handle of meta-object, data size, data type (e.g., "jpg"), version
number, description, date deposited, use (e.g., "thumbnail"), and the date of last revision.
- Image data. This is the image data.
- Meta-object
- The digital object for the meta-object has the following information:
- Key metadata. The key metadata is metadata contained in the digital object that is used to
manage the object in a networked environment. It includes the handle, and the rights and permissions
associated with the digital object.
- Structural metadata. This is metadata that applies to the original photograph and to all the
versions. It includes a description, the owner, the number of versions, the date deposited, the use
("meta-object"), and the date of last revision. If bibliographic information were to be included, it would be
added
to this part of the meta-object.
- Data about each version. For each of the three scanned versions (e.g., the thumbnail), there is
a package of information including the handle of the version, and the relationship among the versions.
The usual manner of access to the photograph is to begin with the meta-object and from there to select
one of the individual versions. However, to permit a user to go directly to a specific version, some
information is duplicated across objects. In particular, the rights and permissions are an integral part of
every digital object.
Handles for scanned photographs
At a early stage of processing a collection, the NDLP's procedure is to give a control identifier
to each item that is digitized, converted, or otherwise prepared for the library. For example, a scanned
image of a photograph from the Coolidge Consumerism compilation has the identifier: 3a16116r.jpg.
This control identifier is an example of a semantic name. The form of the identifier conveys
information about the item. For example, "r.jpg" indicates an image intended for reference, in the jpeg
format. This is convenient for processing, but, for long term identification, semantic names are fraught with
danger and violate one of the guidelines given above. Therefore, in the digital library system, we encode
such semantic information explicitly as metadata, which is stored in digital objects, and replace the control
identifiers by handles, which provide a unique, persistent, location independent name for each item. An
example of a handle is:
This particular example is the handle of the meta-object that lists the various versions of the original
object. The following terminology is used in describing handles:
- "loc.ndlp.amrlp" is the naming authority
- "3a16116" is a locally unique string
For convenience in processing, the scanned versions of the same photograph are distinguished by
sequence numbers. For example, the two following handles refer to different versions of the same
photograph. (For example, the first handle might refer to the reference version, the second to a small
thumbnail.)
loc.ndlp.amrlp/3a16116.1
loc.ndlp.amrlp/3a16116.2
Using the string "3a16116" from the control identifier as part of the handle is for mnemonic
convenience only. Any string could be used and totally different strings could be used for the separate
versions. However, this convention is convenient for managing the collection. The following diagram
shows the use of the meta-object:
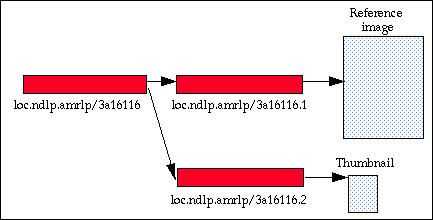
A meta-object used to identify two version of a scanned photograph
The handle to the meta-object, "loc.ndlp.amrlp/3a16116", permanently identifies the set of scanned
images made from this single photograph. The scanned photograph can be referenced by this handle, for
example, in MARC records, shelf lists, external bibliographies, and any other place where a name is needed
that can be relied on for the long term.
Depositing a scanned photograph
To deposit a scanned photograph in the repository is partly a professional task carried out by library
staff and partly automated. The beginning point is a set of files received from the contractor doing the
scanning, each with a control identifier. The following tasks require professional attention:
- Selection of the material that will be made into each digital object.
- Specification of the metadata for those fields that require judgment.
The actual creation and depositing of the set of digital objects in the repository and the registration of
handles in the handle system is carried out by a computer program. The following operations are carried
out automatically:
- Creation of the meta-object and the links to other digital objects.
- Depositing the digital objects in the repository.
- Registering the handles in the handle system.
Access to a scanned photograph
Deposit of a set of digital objects is one basic operation on the set of digital objects that represent a
single scanned photograph. Other basic operations concern access. These are discussed in more detail in
the later section on repositories. For the scanned photograph category, the access conventions are:
- Bibliographic entries in search systems refer to the scanned photograph by the handle of the meta-
object.
- If a user requests a summary of the photograph, the "thumbnail" image is provided.
- If the user requests access to the photograph without specifying which version, the "access" image is
provided.
4. The Next Steps
Our work with the NDLP concentrates on digital library materials that are converted from physical
formats, such as photographs and printed articles. The pilot system demonstrates how the framework can
be used to represent several categories of material and the prototype will extend to all categories in the
NDLP collections.
The architecture, however, is designed to be more general. Digital objects can store static or dynamic
information; they can be archived for perpetuity or have a transitory existence. Access to a digital object in
a repository may require the execution of a program of arbitrary complexity. Repositories, themselves, may
be within mobile agents. In our future work, we aim to extend the richness and variety of information in the
digital library architecture by continuing to build upon the simple building blocks of digital objects,
handles, and repositories.
Continue to Section 5. Technical Information
Go to Section 6. References
Go to Section 7. Acknowledgments
Approved for release, February 14, 1997.
Copyright © 1997 Corporation for National Research Initiatives



hdl:cnri.dlib/february97-arms