|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Steve Mitchell, Project Director and Coordinator |
![]()
AbstractiVia is an open source Internet subject portal or virtual library system. As a hybrid expert and machine built collection creation and management system, it supports a primary, expert-created, first-tier collection that is augmented by a large, second-tier collection of significant Internet resources that are automatically gathered and described. iVia has been developed by and is the platform for INFOMINE, a scholarly virtual library collection of over 26,000 librarian-created and 80,000 plus machine-created records describing and linking to academic Internet resources. The software enables institutions to work cooperatively or individually to provide well-organized, virtual library collections of metadata descriptions of Internet and other resources, as well as rich full-text harvested from these resources. iVia is powerful, flexible and customizable to the needs of single or multiple institutions. It is designed to help virtual libraries scale. This article describes the results of the last four years of work on iVia as funded by the National Leadership grant program of the U.S. Institute of Museum and Library Services, the Fund for the Improvement of Post-Secondary Education (U.S. Department of Education), and the Library of the University of California, Riverside. Introduction and BackgroundiVia [1] is designed to help virtual library systems scale as the number of high quality resources on the Internet continues to rapidly grow. The labor costs required to provide both coverage of major subjects, if only in representative ways, and collection maintenance are becoming prohibitive. The large, critical mass of resources that would represent good coverage and enable fine granularity in searching, which users of Internet finding tools often expect, isn't present in most Internet virtual libraries, whether of single or multi-subject focus. At the same time, commercial virtual libraries and finding tools continue to evolve at a rate that non-commercial virtual libraries have been unable to match. iVia addresses this set of challenges in two ways. First, it joins the best features of advanced library-oriented, expert-based virtual library collection building software with the best features of advanced crawling and classification systems. Secondly, it creates a foundation that supports numerous levels of cooperative, multi-project collection building and sharing. More generally, systems like iVia may prove critical within the larger context of enabling those in the learning community, among others, to continue to reliably find what they need on the Internet. In fact, some computer scientists who specialize in search engine technologies believe that generalized engines may have significant technical limitations that a federated array of finding tools, each handling a more finite subject area and/or target audience and each relying on focused crawling and other approaches employed in iVia, would not have [20, 43]. Such a federation, designed as a Librarian's Web intended for the participation of the many libraries already engaged in virtual library collection building, may increasingly become a crucial strategy for finding useful resources on the Internet for the learning community. The hybrid, focused, streamlined, and expert-based/machine-assisted approach that iVia is designed around represents an important type of Internet resource discovery strategy. Potentially, it helps bring together and amplifies the expertise found within the abundance of high quality and useful but generally small, uncoordinated and disparate virtual library finding tools. This Librarian's Web of virtual library effort could better scale and take a more crucial place alongside the large search engines plying the open Web if tools like iVia were adopted. iVia lends itself well to usage by a potential Librarian's Web because it represents a cooperative, open source system that could serve as a catalyst for cooperation and that weaves together, benefits from and represents a unified tapestry of the approaches underlying search engines and virtual libraries. Some of the major features of the iVia system include:
Project BaseThe iVia system has been primarily developed by one of the longest running and largest of librarian-created academic virtual libraries, INFOMINE [2, 3, 4] (see Figure 1). iVia work is supported by the LOOK (Libraries of Organized Online Knowledge, formerly Fiat Lux) cooperative of virtual libraries [5]: INFOMINE, BUBL [6], the Internet Public Library [7], the Librarians' Index to the Internet [8], MeL (Michigan Electronic Library) [9] and the Virtual Reference Library (Toronto Public Library) [10]. Most of these projects are working in concert in systems planning. Cooperators currently working directly with INFOMINE or iVia in developing the collection or the software include librarians from Wake Forest University, several University of California and California State University campuses, and the Librarians' Index to the Internet. The latter has recently supported important iVia development work in the area of content management. Computer scientists and researchers from the New Zealand Digital Library (University of Waikato Computer Science Department) [11] and the Centre for Digital Library Research (Strathclyde University, U.K.) [12] contribute to the project.
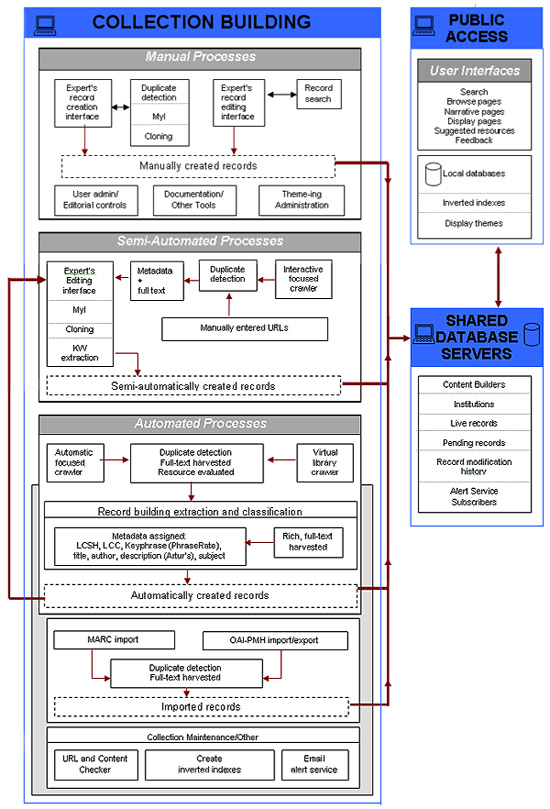
iVia In-depthiVia includes the following important systems components among others: a database of expert and machine built records; sophisticated user search, browse, and display options; focused crawlers of various types for automated and semi-automated resource identification; classifiers for automated and semi-automated metadata application (including library standard subject schema, Library of Congress Subject Headings, LCSH, and Library of Congress Classifications, LCC); advanced collection maintenance programs; a rich text identifier and a keyphrase identification and extraction system (PhraseRate); support for multiple interfaces, data views and product "brands" for cooperating virtual library projects (Theme-ing and MyI); support for OAI-PMH; means for importing records in MARC format; and a robust collection management package (see Figure 3 for an overview). Core SystemiVia's core system is a set of open source programs for building and maintaining Internet virtual libraries and allowing users great flexibility in access to content. It is scalable, stable, free, and places an emphasis on multi-project cooperation and machine-assisted strategies for finding and describing resources and sharing them. Users will find numerous means of search and browse access to information [14]. Searching for fielded as well as full-text data, using standard Boolean and proximity operators, is supported. Collection builders will find a large selection of resource discovery and content building, editing and maintenance tools at their disposal. Our content creation system is very flexible and allows a great number of expert contributors from multiple projects to develop content through any of several coordinated tracks (all meeting minimum data type and quality standards) according to the needs of the cooperating organization. The tracks vary in terms of the privileges allowed to individual content builders and the number of levels of editorial review. This allows projects of different sizes to begin production quickly using procedures similar to those with which they have experience. Included as part of the content building software are sophisticated content building interfaces (see Figure 2), focused crawlers, and smart classifiers or metadata generators.
Projects using the software can create collections of links to and metadata about Internet resources by any of the following means: manually creating metadata; using metadata automatically created by the focused crawlers and classifiers (fully automated record building); manually augmenting and refining records created by the focused crawlers and classifiers (semi-automated record building); importing metadata records from other Internet collections including other virtual libraries using OAI-PMH protocol as well as library catalogs using MARC format. iVia is written in C++, runs on Debian Linux and makes use of the MySQL and Berkeley DB database management packages, among others. Institutional Co-branding - Theme-ing and MyIScalability and sustainability for virtual libraries is not only a technological issue but a social one. Meaningful cooperation among virtual library projects reduces redundant effort and takes advantage of the large gains made possible by labor and resource sharing. Sharing the iVia record creation interface and database provides resource savings in the areas of content development, content maintenance, and systems development costs. To facilitate this, iVia supports multiple user interfaces and data views. The Theme-ing system allows cooperating projects to retain their "brand" or front-end through the design options provided. Theme-ing enables the creation of almost any interface, data retrieval option and/or results display that would be desired. See, for example, the Wake Forest University interface to INFOMINE [15]. MyI allows the selection and retrieval of specialized data and subsets of the greater iVia collections. MyI categories are descriptors assigned to resources in order to create specialized sub-collections, pathfinders, subject guides, or even informal lists of resources relevant to a particular topic, virtual library, campus or organization, librarian or instructor. These lists are created by adding MyI category names like LC-econ or UCR-ACCESS-TELNET to the resource descriptions. The records can subsequently be retrieved and displayed by iVia searches. Machine-assisted Collection DevelopmentMost virtual libraries are relatively small collections and are prone to zero-result searches. In iVia, large collections of automatically and semi-automatically created metadata, along with full-text that is extracted from the resource, are developed to provide the critical mass of content needed to help solve this problem. Greater numbers of resources also provide for a much finer level of granularity in searching—which users increasingly expect in an Internet finding tool. In our system, crawlers detect significant resources, and classifiers provide metadata representing these resources in creating a large automatically created collection that is used in INFOMINE to undergird and support, as a second-tier of resources, the expert-created first-tier collections. This results in significant labor and monetary savings in resource identification (i.e., collection development). Crawling systems iVia automatically crawls and identifies relevant Internet resources through focused crawling and topic distillation approaches [18, 43] that involve techniques known as inter-linkage analysis (also known as co-citation analysis) and text co-occurrence. Inter-linkage analysis works like a citation index by identifying the resources most linked to/from in focused subject areas or other domains [16-25, 43]. Text co-occurrence (i.e., text similarity among resources) [18, 26, 27] is used to measure the degree of similarity between the text in a potential new Internet resource and the text of a known, high-value, expert-vetted resource. These measures, of relevance and quality, provide a generally effective means for automatically identifying promising resources. As with all our crawlers, if the significance score or "vote" for a resource is high enough, record building software then comes into play. The record builder will create a record either fully automatically (to create a second-tier record) or semi-automatically and interactively with expert augmentation and refinement (to create a first-tier record). Automatic Focused Crawler Interactive Focused Crawler
Virtual Library Crawler Machine-assisted Metadata Creation—Indexing/catalogingSignificant new resources discovered by the crawlers are then processed, as mentioned, by our automatic record builder. They can either be automatically classified and completed or flagged for expert review and augmentation (with machine assistance). This process of automated metadata generation results in significant labor and monetary savings in resource description (i.e., collection indexing). We have created record building software to determine and automatically apply the following topic and other metadata: Library Standard Subject Schema - Library of Congress Classifications We use LCC, a major U.S. academic library subject schema standard, to generate a multiple-tiered subject hierarchy that is both searchable and browseable [28, 29]. The iVia LCC classifier assigns an LCC to a resource based on the set of Library of Congress Subject Headings (LCSH) associated with that resource. Other projects have explored similar territory: most are based on information retrieval techniques [18] and use additional metadata, such as the document title. Instead, we use a smaller, controlled feature set (LCSH lead terms, minus some subdivisions) and base our classifier on Support Vector Machine algorithms [30]. Absolute accuracy, the number of times the classifier is exactly correct with its first prediction, is around 58% which compares well to similar work. However, this measure does not allow for partially correct assignment. For example, 4% of its classifications were somewhat too specific and 3% somewhat too general. We have applied the LCC classifier to every Internet resource in INFOMINE and created a browsing interface for this subject schema. Training data has been limited to records from our local Library catalog [31], but we are hoping to improve performance of our model by using more comprehensive training datasets. Additional datasets made available to us include 11 million unique records from the University of California's Melvyl System [32] and 270,000 records for Internet resources contained in OCLC's FirstSearch [33]. Future research will build a keyphrase to LCC classification model for use on documents with text but no LCSH. Library Standard Subject Schema - Library of Congress Subject Headings We also assign LCSH automatically. LCSH is another major subject schema in U.S. academic libraries but, unlike LCC, is relatively flat [34, 35]. LCSH is both searchable and browseable in iVia. LCSH is important, like LCC, because it is a long term library standard and can function as a subject access bridge to facilitate seamless inter-searching of academic library online catalogs and virtual libraries (i.e., both Internet as well as library-held print resources). We have developed software that automatically assigns LCSH to resources harvested on the Internet using a practical k-nearest neighbor classifier [30]. In our approach, a new record is classified by extracting from the resource a set of keyphrases that summarize its content. The keyphrases are used to search the expert-created records for the most similar known resources, and their similarity to the new resource is measured using information retrieval techniques. The LCSH of the most similar known resources are retrieved, and the most frequently occurring are assigned to the new record. The expert-vetted INFOMINE records and the documents to which they link function as training data. Simple and practical, this approach relies on good expert-vetted data. It performs poorly though in areas where little or no such data is available. Consequently, we will augment this training data with records for Internet resources from FirstSearch and from Melvyl. Natural Language Keyphrases - PhraseRate PhraseRate [36] is a program for extracting a set of important words and phrases from a Web page as a means of describing the content of that page [37]. It is accurate and is better suited to virtual library applications than other phrase extractors to which we have compared it. PhraseRate works by extracting the words and mark-up tags from a Web page, forming phrases, then selecting the best phrases with its phrase selection algorithm. The algorithm satisfies eight requirements among which are phrase location in document, document length independence, length of phrase, repetitions, indications of author emphasis in page layout (e.g., HTML headers, capitalized words), and metadata presence. PhraseRate can execute automatically or can be used by experts to interactively guide the process at important junctures, e.g., in exercising greater selectivity as to which are the "richest" additional pages from which to extract keyphrases. Assignment of natural language keyphrases is crucial for retrieval in that more user access points per record are provided. In addition, deficiencies in the controlled subject vocabularies are partially corrected (also see Full-text Harvesting, below, in this regard). Finally, the phrases also support the iVia LCSH assignment and the description creation programs (described elsewhere in this section). Description Creation - Artur's Auto Annotator Descriptions are created by extracting text of various types which describe the resource. This text is determined based on its position in the Web resource and other document layout clues including HTML/XML structures (e.g., headings, fonts, and links which indicate author emphasized text). Important phrases, extracted using PhraseRate (see above), are also used. Description length is determined by the amount of rich text discovered on the site that is gauged to be about the site [38, 39]. Full-text Harvesting and IndexingiVia automatically downloads and indexes the full text of the front pages of each Web-based Internet resource in the collection. Full-text indexing allows users much finer granularity in searching and provides a boost for increasing the number of successful searches by supplying a large number of natural language terms to supplement both expert and machine applied metadata and to correct for shortcomings in subject schema terms. Full-text harvested from the initial pages of each site will shortly be augmented by full-text selected via an "aboutness" measure (which helps the crawler detect a resource's most descriptive pages from which to extract "rich" full-text). Machine-assisted Collection MaintenanceMaintaining a collection of Internet resources is a continuing challenge both in regard to keeping URLs current and in detecting content changes in order to ensure that resource descriptions remain accurate. Our URL and content change maintenance tool helps in both areas. URLs that remain broken over a period of three weeks are automatically detected and flagged for expert review. In the cases where URLs are re-directed, the new URLs are discovered and suggested. Content changes, measured through significant changes in word counts, are also automatically detected and flagged for expert review. New Approaches to User Information Retrieval through Browsing - PhindAmong the great number of search and browse retrieval options [14] offered to users is Phind [40]. This is open source software (from Greenstone Digital Library Software) [41] that creates a term browsing interface similar to a keyword-in-context browse index (as found in some standard academic library indexes) which enables users to quickly browse through phrases that occur in large document collections. Lexically based, Phind is an intuitive, hierarchical, topic-oriented structure for finding documents in a collection that conventional keyword indexes do not reveal. Phind is used in INFOMINE, where it is known as Megatopics [42], to browse keyphrases in all subjects. The novelty in the iVia application of Phind is that the "documents" that Phind works with are individual database records of highly refined metadata as is found in our title, keyphrase, subject and description fields. Phind can also support established subject thesauri, and future work will occur adapting and using Phind with library-standard and other subject schema. iVia SchematicThe following schematic diagram, Figure 3, provides an overview of how iVia processes and features work as a whole.
ConclusioniVia is a high-performance, open source virtual library system that offers major resource savings by automating or semi-automating many collection building and maintenance processes. It combines, in a hybrid system, many of the best features of expert-built virtual library finding tools with those of fully automated search engines. In using the system, multiple levels of cooperative involvement are supported ranging from fully amalgamated to highly federated to loosely federated to independent efforts and implementations. The iVia system provides technical solutions to many of the problems associated with virtual library scaling, and provides a foundation for librarians to bring their collection building craft, vision, discernment, experience, and standards to the learning community in a new medium and a new millennium. AcknowledgementsWe would like to thank the U.S. Institute of Museum and Library Services (IMLS), the Fund for the Improvement of Post-Secondary Education (FIPSE, U.S. Dept. of Education) and the Library of the University of California, Riverside for their generous funding and support. Thanks as well go to the University of California's California Digital Library and OCLC, Inc. for training data usage. Hearty thanks go to our librarian content builders from the University of California, Wake Forest University, California State University and University of Detroit (Mercy) for their great efforts over the years. We would also like to thank the following individuals for their efforts and support: Dr. Ian Witten, Dr. Eibe Frank and Dr. Steve Jones (Department of Computer Science, University of Waikato, New Zealand); Dr. Marek Chrobak, Dr. Dimitrios Gunopulos, and Anwar Adi (Department of Computer Science, University of California, Riverside); Dr. Ruth Jackson, Lynne Reasoner, Wendie Helms, Tano Simonian, Dana Nguyen and Nancy Douglas (Library, University of California, Riverside); Karen Schneider (Librarians' Index to the Internet); Kathy Scardellato (Virtual Reference Library, Toronto Public Library); Dennis Nicholson (Centre for Digital Library Research, Strathclyde University, U.K.); Sue Davidsen (Internet Public Library); John Tanno (Library, University of California, Davis); Martha Crawley (IMLS); and, Dr. Cassandra Courtney (FIPSE). Notes and References[1] 1. iVia, 1997-2003, "iVia Download site", Library of the University of California, Riverside. at: <http://infomine.ucr.edu/iVia/>. [2] INFOMINE, 1994-2003, Library of the University of California, Riverside, at <http://infomine.ucr.edu>. [3] S. Mitchell, et al., 2000, "INFOMINE," in The Amazing Internet Challenge, A.T. Wells, et al., eds., American Library Association, Chicago. [4] J. Mason, et. al., June 2000, INFOMINE: Promising Directions in Virtual Library Development, First Monday, 5 (6) at <http://www.firstmonday.dk/issues/issue5_6/mason/index.html>. [5] K. Schneider, "April 2002, "Fiat Lux: A Yahoo with Values and a Brain," American Libraries, 33(4) pp. 92-93, at <http://www.ala.org/alonline/netlib/il402.html>. [6] BUBL Information Service, Centre for Digital Library Research, Strathclyde University, at <http://bubl.ac.uk>. [7] Internet Public Library (IPL), University of Michigan, at <http://www.ipl.org>. [8] Librarian's Index to the Internet (LII), at <http://lii.org>. [9] MeL: Michigan Electronic Library, Michigan State Library, at <http://www.mel.org/>. [10] VRL: Virtual Reference Library, Toronto Public Library, at <http://vrl.tpl.toronto.on.ca/>. [11] New Zealand Digital Library (NZDL), University of Waikato, New Zealand, at <http://www.nzdl.org/cgi-bin/library>. [12] Centre for Digital Library Research (CDLR), University of Strathclyde, U.K., at <http://cdlr.strath.ac.uk/>. [13] Affero General Public License, at <http://www.affero.org/oagpl.html>. [14] iVia Search Options in INFOMINE, at <http://infomine.ucr.edu/help/>. Also see the advanced search page at <http://infomine.ucr.edu/cgi-bin/search>. [15] Wake Forest University uses of Theme-ing, at <http://www.wfu.edu/Library/infomine/>. [16] A. Borodin, et. al., 2001, "Finding Authorities and Hubs From Link Structures on the World Wide Web," WWW10, May 1-5, 2001, Hong Kong. at <http://www.cs.toronto.edu/~tsap/cv/../publications/www-paper.ps>. [17] S. Brin and L. Page, 1998. "The Anatomy of a Large-Scale Hypertextual Web Search Engine," Computer Networks, volume 30, numbers 1-7, pp. 107-117, and Proceedings of the Seventh International World Wide Web, April 1998, Brisbane, Australia, at <http://www7.scu.edu.au/programme/fullpapers/1921/com1921.htm>. [18] S. Chakrabarti. 2003. Mining the Web: Discovering Knowledge from Hypertext Data. Morgan Kaufmann, San Francisco. [19] S. Chakrabarti, et. al., 2002, "Accelerated Focused Crawling Through Online Relevance Feedback", WWW2002, Honolulu, Hawaii, May 2002, at <http://www2002.org/CDROM/refereed/336/> <http://www2002.org/CDROM/refereed/338/index.html>. [20] S. Chakrabarti, et. al., 2002, "The Structure Of Broad Topics On The Web" <http://arxiv.org/abs/cs.IR/0203024>, WWW2002, Honolulu, Hawaii, May 2002. at <http://www2002.org/CDROM/refereed/338>. [21] S. Chakrabarti, et. al., 1999, "Focused Crawling: A New Approach to Topic-Specific Web Resource Discovery," WWW8, The Eighth International World Wide Web Conference, Toronto, 1999, at <http://www8.org/w8-papers/5a-search-query/crawling/index.html>. [22] M. Diligenti, et. al., 2000, "Focused Crawling Using Context Graphs", Proceedings: Very Large Databases 2000, Cairo, Egypt, at <http://citeseer.nj.nec.com/diligenti00focused.html>. [23] G. W. Flake, et. al., March 2002, "Self-organization and Identification of Web Communities," Computer. 35(3) pp. 66-71, at <http://citeseer.nj.nec.com/flake02selforganization.html>. [24] L. Li, et. al. 2002, "Improvement of HITS-based Algorithms on Web Documents", WWW2002, May 7-11, 2002, Honolulu, Hawaii, May 2002, at <http://www2002.org/CDROM/refereed/643/index.html>. [25] J. Rennie and A. McCallum, 1999, "Using Reinforcement Learning to Spider the Web Efficiently," Proceedings of the Sixteenth International Conference on Machine Learning (ICML-99), at <http://citeseer.nj.nec.com/7537.html>. [26] T. H. Haveliwala, et. al., 2002, "Evaluating Strategies for Similarity Search on the Web," WWW2002, May 7-11, 2002, Honolulu, Hawaii, May 2002, at <http://www2002.org/CDROM/refereed/75/index.html>. [27] T. Hofmann, 1999, "Learning the Similarity of Documents: An Information Geometric Approach to Document Retrieval and Categorization," in Solla, Leen, and Muller, editors, Advances in Neural Information Processing Systems 12, pages 914-920, MIT Press, 1999, at <http://citeseer.nj.nec.com/hofmann00learning.html>. [28] Library of Congress Classification Outline, at <http://www.loc.gov/catdir/cpso/lcco/lcco.html>. [29] LCC browse interface in INFOMINE, at <http://infomine.ucr.edu/dbase/cache/LCC/>. [30] I. H. Witten and E. Frank, 2000. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations. San Francisco, Calif.: Morgan Kaufmann, 371 p. [31] University of California, Riverside, Library Catalog, at <http://scotty.ucr.edu/>. [32] University of California, California Digital Library, Melvyl Catalog, at <http://www.dbs.cdlib.org>. [33] OCLC Online Computer Library Center, Inc., FirstSearch, at <http://firstsearch.oclc.org/>. [34] Library of Congress Subject Headings, at <http://lcweb.loc.gov/cds/lcsh.html#lcsh20>. [35] Library of Congress Subject Headings in INFOMINE, example, at <http://infomine.ucr.edu/dbase/cache/govpub/subjects-A.html>. [36] J. B. K. Humphreys, 2002, "PhraseRate: An HTML Keyphrase Extractor", at <http://infomine.ucr.edu/projects/Keith_Humphrey/PhraseRate/phraserate.pdf>. [37] S. Jones and G. Paynter, in press, "Automatic Extraction of Document Keyphrases for Use in Digital Libraries: Evaluation and Applications," Journal of the American Society for Information Science and Technology (JASIST). [38] A. Kedzierski, 2002. Artur's Auto Annotator. Masters Thesis, Department of Computer Science, University of California, Riverside. [39] S. Jones, S. Lundy, and G. Paynter, 2002, "Interactive Document Summarisation Using Automatically Extracted Keyphrases". Hawaii International Conference on System Sciences: Digital Documents: Understanding and Communication Track, Hawaii, USA, January 7-11, 2002, IEEE-CS, pp101., at <http://www.hicss.hawaii.edu/HICSS_35/HICSSpapers/PDFdocuments/DDUAC04.pdf>. [40] G. W. Paynter, and I. H. Witten, 2001, "A Combined Phrase and Thesaurus Browser for Large Document Collections." Proceedings of the European Conference on Digital Libraries, Darmstadt, Germany, pp. 25-36; September, at <http://www.cs.waikato.ac.nz/~ihw/papers/01GP-IHW-CombinePhrase.pdf>. Also see Phind, New Zealand Digital Library, 1997-, at <http://www.nzdl.org/phind/>. [41] I. H. Witten, et al., 2000, "Greenstone: A Comprehensive Open-Source Digital Library Software System." Proceedings of the Fifth ACM International Conference on Digital Libraries, San Antonio, Texas, United States, pp 113-121, at <http://doi.acm.org/10.1145/336597.336650>. Also see Greenstone Digital Library Software, New Zealand Digital Library, et al., at <http://www.greenstone.org/english/home.html>. [42] Megatopics (iVia implementation of Phind), at <http://infomine.ucr.edu/dbase/megatopics.php>. [43] F. Menczer, submitted '03, Mapping the sematics of Web text and links, IEEE Journal on Selected Areas in Communications, at <http://dollar.biz.uiowa.edu/~fil/papers.html>. Copyright © Steve Mitchell, Margaret Mooney, Julie Mason, Gordon W. Paynter, Johannes Ruscheinski, Artur Kedzierski, and Keith Humphreys |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/january2003-mitchell
|