|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Johan Bollen, Michael L. Nelson, Giridhar Manepalli, Giridhar Nandigam, and
Suchitra Manepalli |
![]()
AbstractSince its inception in 1995, D-Lib Magazine's articles, reviews, and editorials have documented the rapid evolution in the digital library (DL) community. To quantify the longitudinal evolution of novel ideas and concepts in this community, we mined the contents of D-Lib Magazine. For each year since 1995, we analyzed how terms co-occurred. These patterns of term co-occurrence reveal not only which terms have been used more or less frequently over the past 10 years, but also the context in which they occurred. This contextual information allows us to more precisely examine the manifold aspects of trends and evolutions in DLs. 1. Introduction1.1 Problem StatementD-Lib Magazine is "an electronic publication with a primary focus on digital library research and development, including but not limited to new technologies, applications, and contextual social and economic issues" and its primary goal is "timely and efficient information exchange for the digital library community" (Wilson, 2004). As such, D-Lib Magazine has evolved into the primary venue for "awareness"-type publications within the DL community. This is evidenced from its publication style: announcements and articles about novel, theoretical and practical research results are published comparatively quickly after acceptance and submission. D-Lib Magazine is published 11 months a year and contains about 5 articles per edition in conjunction with numerous reviews and conference reports. The back issues of D-Lib Magazine represent an essential sample of trends and evolutions in the DL community. However, the determination of what has constituted or constitutes a genuine trend or evolution in the DL community, and what has conversely been found to be a fad or hype, remains a highly subjective affair. Using the D-Lib Magazine corpus, we performed a quantitative trend analysis of D-Lib Magazine's text content for the past ten years. We identified shifting patterns of how words co-occur in documents over time and use these patterns to pinpoint some trends in the community. 1.2 General ApproachOur analysis is based on the assumption that the frequency of term or word usage in a document collection serves as an indication of how important that term and the corresponding notion is to the community at the time of publication. However, words in isolation do not fully express the views and perspectives of a community. To better evaluate the context of the occurrence of terms, we examined their co-occurrence with other terms. In that sense, we determine that when two terms frequently co-occur in, for example, the same sentence, they are related. The more frequently they co-occur compared to how often they each occur individually the stronger we will assume their relationship to be. The resulting networks of term relationships can then be examined for each publication year and sequenced to determine how the context of a particular term changed over time. 2. Methodology2.1 Data CollectionAll issues of D-Lib Magazine are available on the web in HTML. We wrote a crawler which harvested each article in a particular year, converted it to plain text (removing all HTML source code) and stored the result in a directory according to the year in which it was published. All full D-Lib articles were harvested including briefs, editorials, and conference reports on the basis of the documents listed in the author index. A total of 675 text documents were downloaded and saved. The number of unique articles for each year was distributed as shown in Table 1.
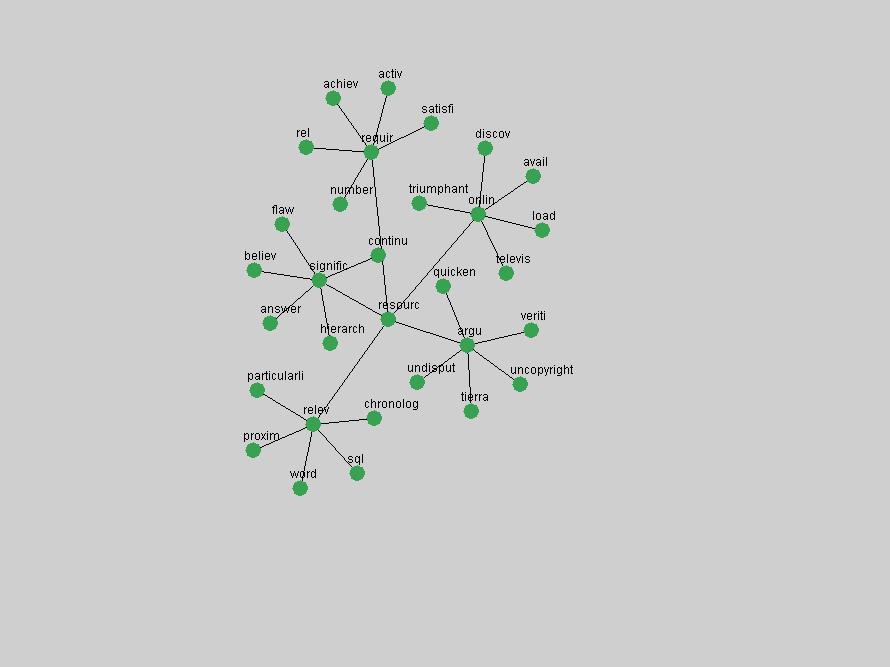
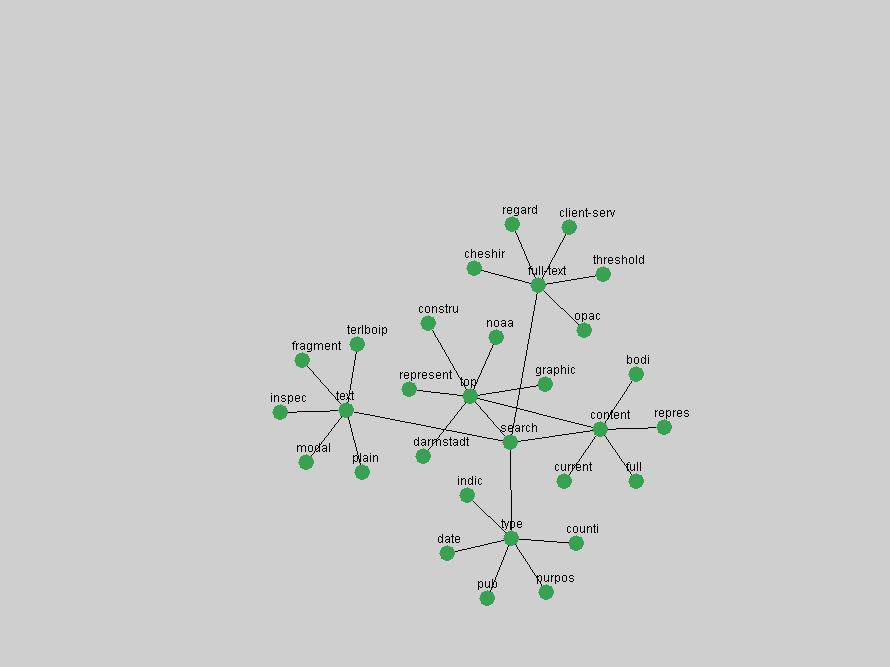
Table 1 : Number of unique articles published each year 2.2 Data PruningFor each year of D-Lib Magazine's publication, we concatenated all articles and separated their content into individual terms. We then removed stopwords (e.g. "the", "a", "I", "we", etc.). Proper names were retained since they provide essential information on which persons are most strongly associated with a particular term or concepts. All extracted terms were stemmed, meaning they were reduced to their root form by removing all changeable endings (Porter, 1980). For example, "operation", "operating" and "operator" can all be reduced to the common root "operat". This procedure allows the grouping of related terms regardless of their linguistic position or context. No amount of data pruning can remove all irrelevant and spurious terms extracted from a corpus such as D-Lib Magazine. We decided to err on the side of caution and accept a higher rate of false positives in exchange for capturing as wide a variety of terms as possible. 2.3 Term association networksFrom the list of terms extracted from each year's articles we then generated term associations. We did so on the assumption that terms occurring within close proximity, e.g. same sentence or sequence of words, are related. Since sentence boundaries are difficult to automatically and consistently detect, we applied a 8 term window to the resulting text whose position was shifted down the text, one word after the other. This window did not cover the transitions between concatenated articles. A term co-occurrence was defined as any two words jointly occurring within that sliding window of 8 words. Term co-occurrence frequency data was generated for each year and used to determine term association data on the basis that often co-occurring terms are more related than those that do not co-occur. We thus defined the association weight A for each pair of term (ti,tj) as follows:
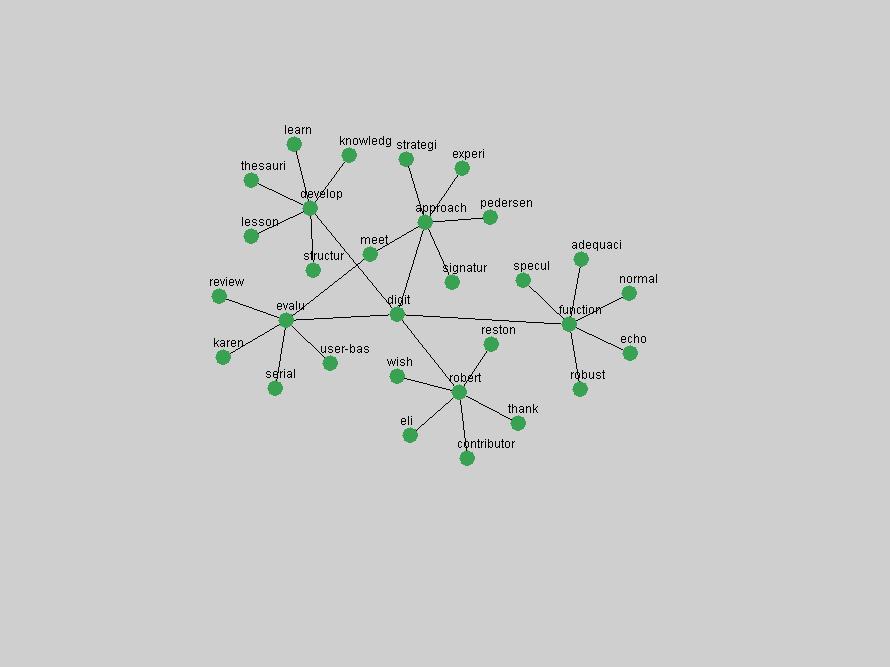
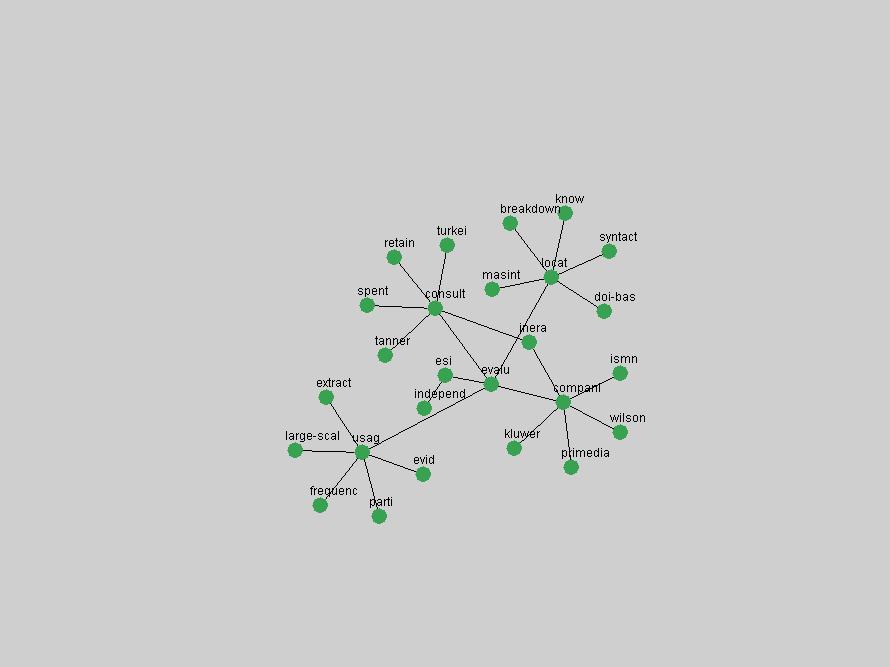
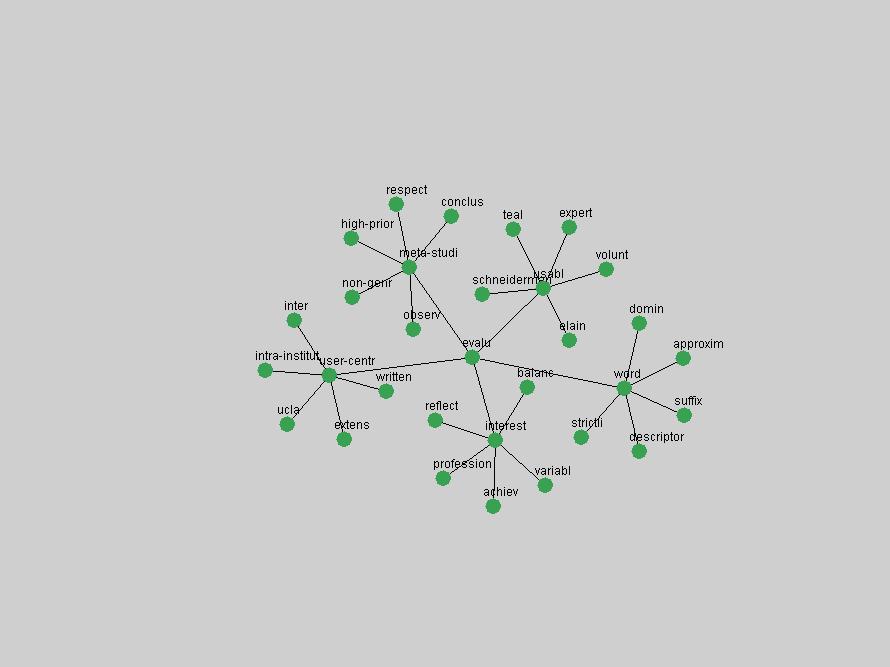
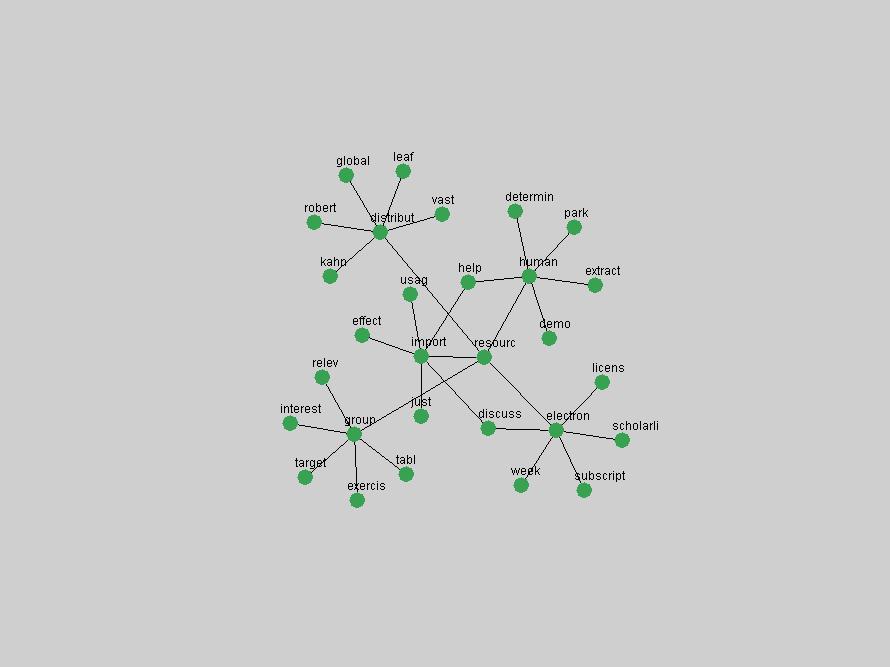
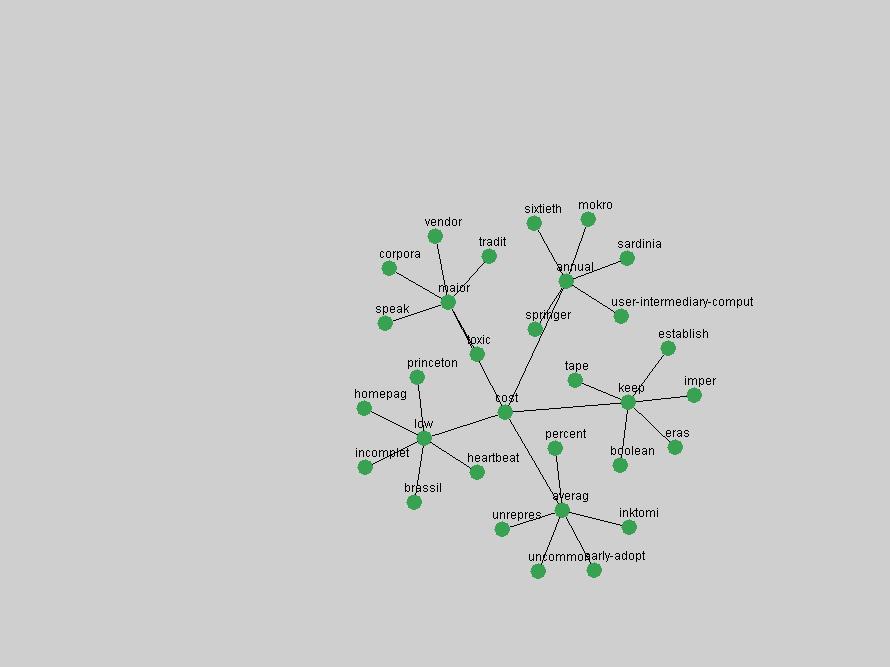
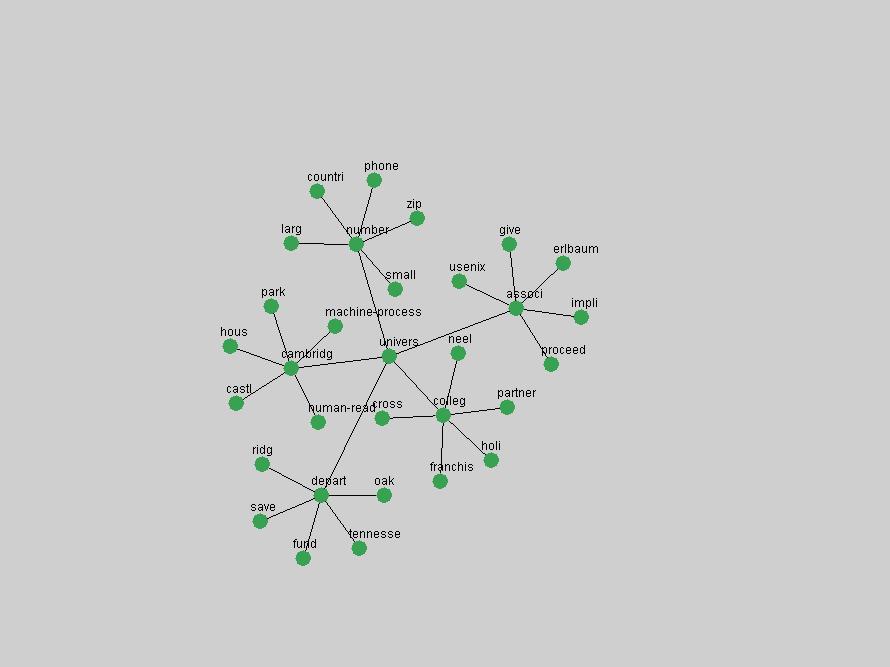
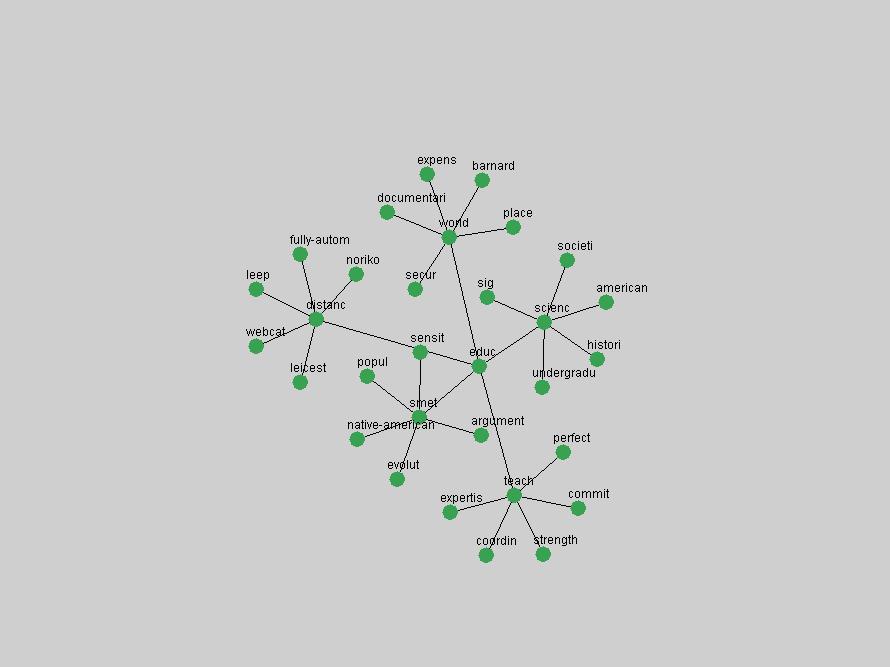
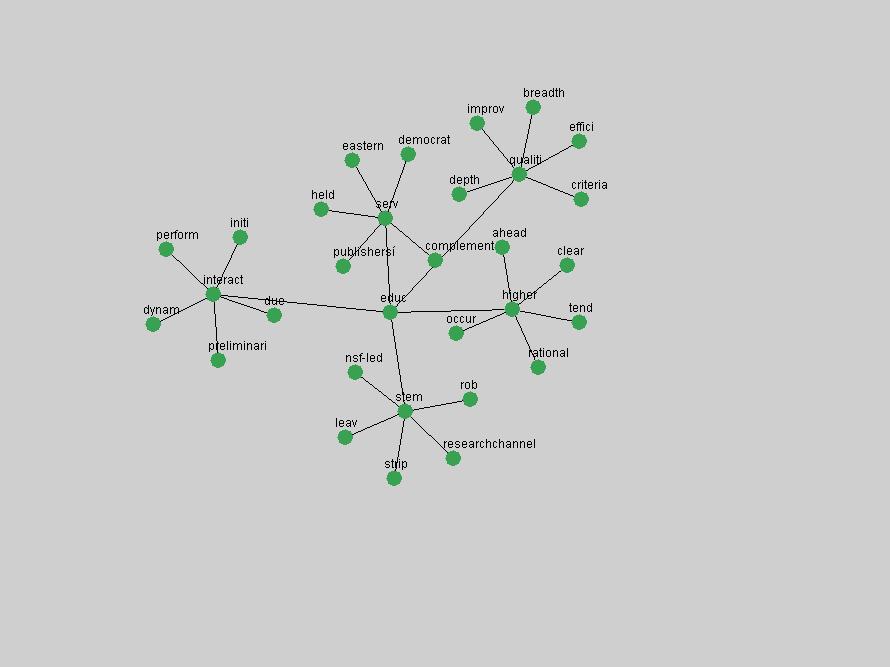
where P(ti & tj) represent the probability that the terms will co-occur (normalized co-occurrence frequency), and P(ti) and P(tj) represent respectively the probability that the terms will occur independently of each other (normalized occurrence frequency). This metric of term association is also known as Jaccard similarity and can be understood as calculating the ratio between the number of times the terms co-occur over the number of times they occur independently of each other. If the frequency of co-occurrence approaches the independent occurrence of a pair of terms, A(ti,tj) approaches 1, i.e. they always co-occur. If they never co-occur, regardless of how often they occur independently, A(ti,tj) approaches 0. When applied to D-Lib Magazine's publications, we can generate a network of term associations for each year. We assume that each term indicates a particular topic or concept of interest, and that these yearly networks represent how these topics related to each other. Using the term association data we can therefore not only determine which terms were used, but the context in which they were used. 2.4 Term selectionWhen studying the "zeitgeist" of a community two types of conceptual entities seem to matter most:
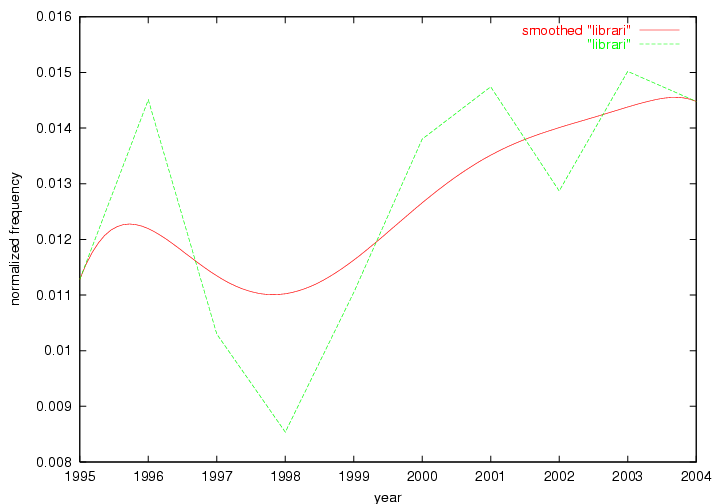
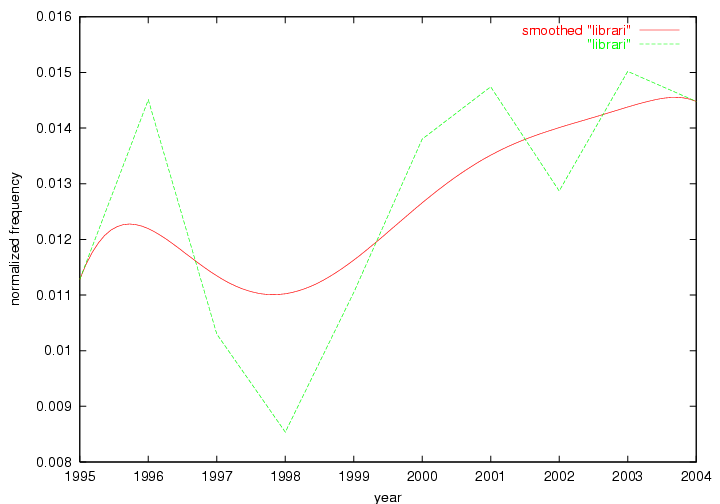
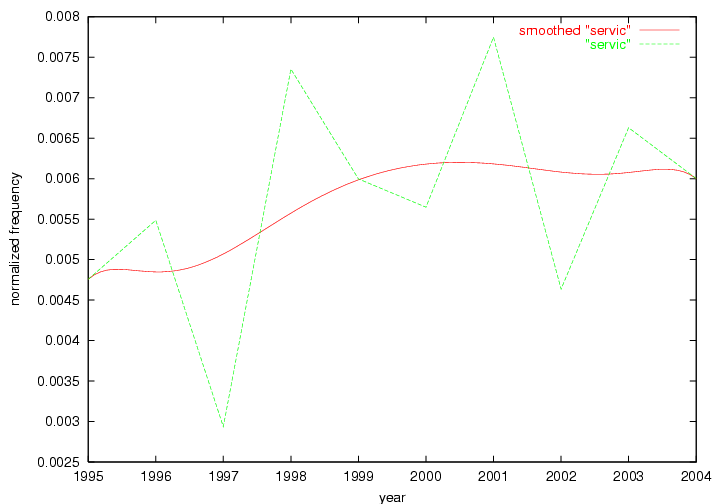
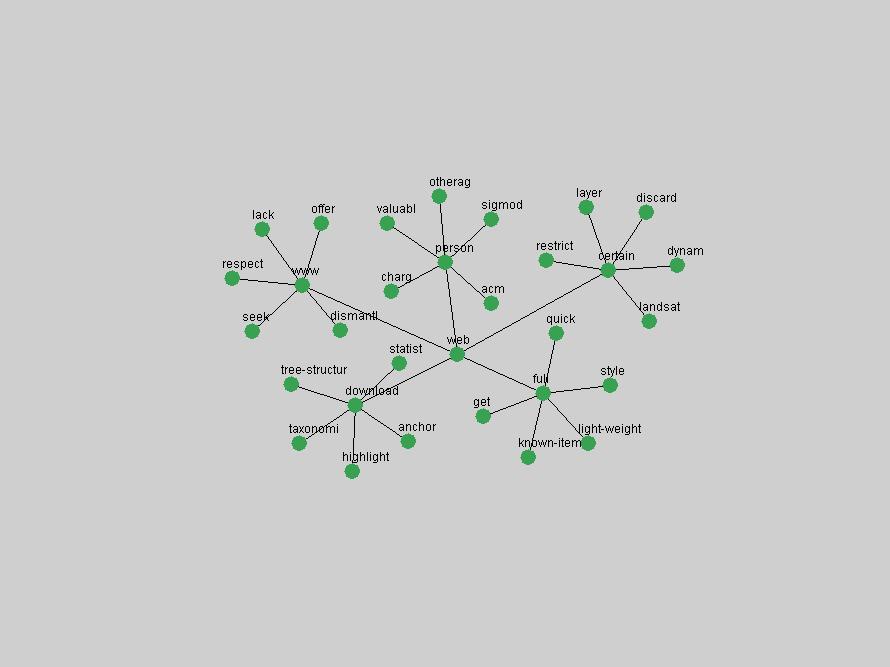
We adopted two different approaches to associate a set of terms with "central concepts" and "innovations". First, frequency tables were generated for each year in which D-Lib was published including 2004 (all issues) and 1995 (six issues starting with July of that year). The frequency of each term was normalized by dividing it by the total of all term occurrences in that year. Those terms that appeared in the top 10 ranked terms for each of the recorded years were adopted as indicators of "central concepts". Second, terms were selected from the frequency tables for each year by ranking each term by the values of their absolute changes in frequency from one consecutive year to another. In other words, the 10 terms that underwent the largest, positive changes in their occurrence frequency from one year to another were adopted as "innovations" within the community. These terms were selected and the evolution of their frequency examined over the 10 years of D-Lib publication. 3 Results3.1 Central ConceptsThe set of terms associated with "central concepts", as listed in Table 2, demonstrates a strong focus on a limited number of concepts as evidenced by the fact that out of 100 possible terms (10 years multiplied by the top 10 most frequent terms each year) only 22 unique terms occurred. The lists of each year's most frequent terms were therefore highly stable. For example, as expected the terms "digital", "library" and "information" are among the ten most frequent terms in all 10 years D-Lib publication.
|
| Most Frequent Used Terms | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 |
| digit | librari | inform | inform | inform | librari | librari | librari | librari | librari |
| inform | inform | librari | user | librari | digit | digit | digit | digit | digit |
| librari | digit | user | librari | digit | inform | inform | inform | inform | inform |
| user | project | digit | digit | system | collect | metadata | metadata | servic | access |
| object | access | data | servic | user | search | servic | user | provid | search |
| system | user | search | system | servic | archiv | provid | develop | metadata | metadata |
| access | document | imag | resourc | access | provid | access | access | system | resourc |
| research | provid | system | access | provid | access | user | provid | user | develop |
| project | collect | access | provid | research | data | system | collect | refer | servic |
| search | system | document | search | work | system | collect | resourc | develop | data |
|
Table 2. Central concepts selected on the basis of their top 10 frequency ranking in all years (1995-2004).
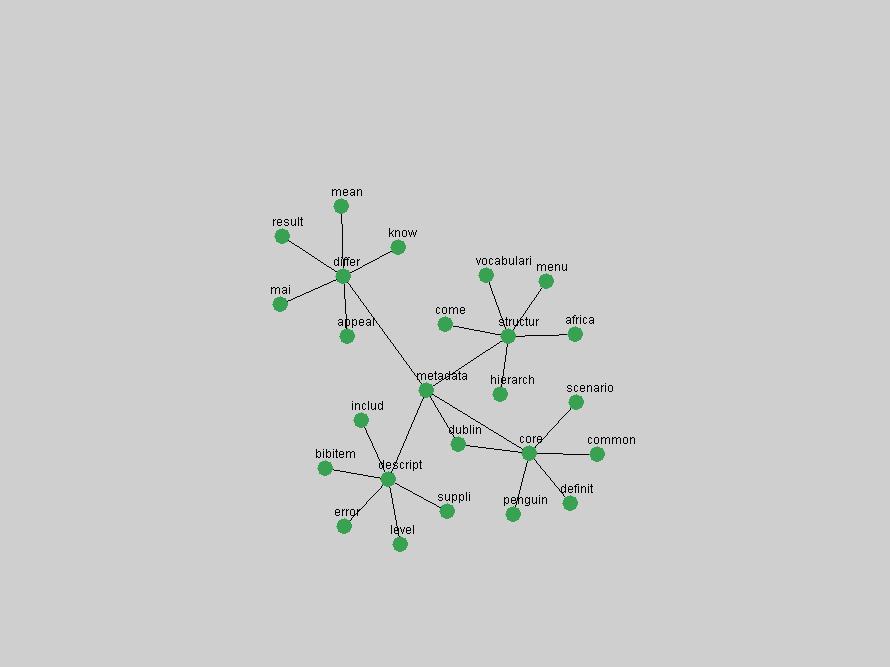
To determine how stably a term occurred in each year's list of the most frequent terms, we counted the number of years that a particular term occurred among the 10 most frequent terms. This number indicates its "centrality", i.e. how central and stable the term represented the content of D-Lib Magazine. Table 3 lists the number of times a term occurred among the 10 most frequent terms over 10 years.
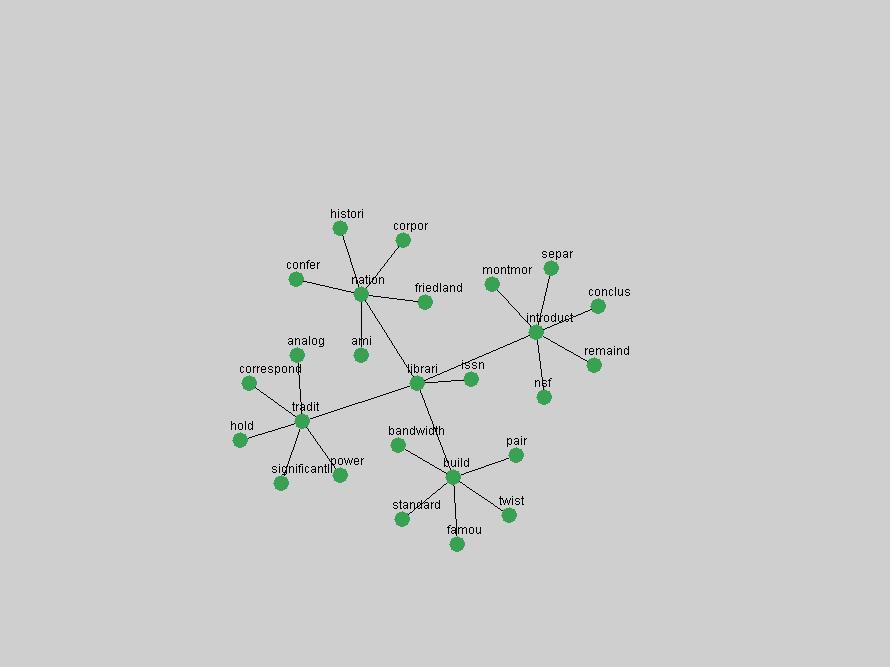
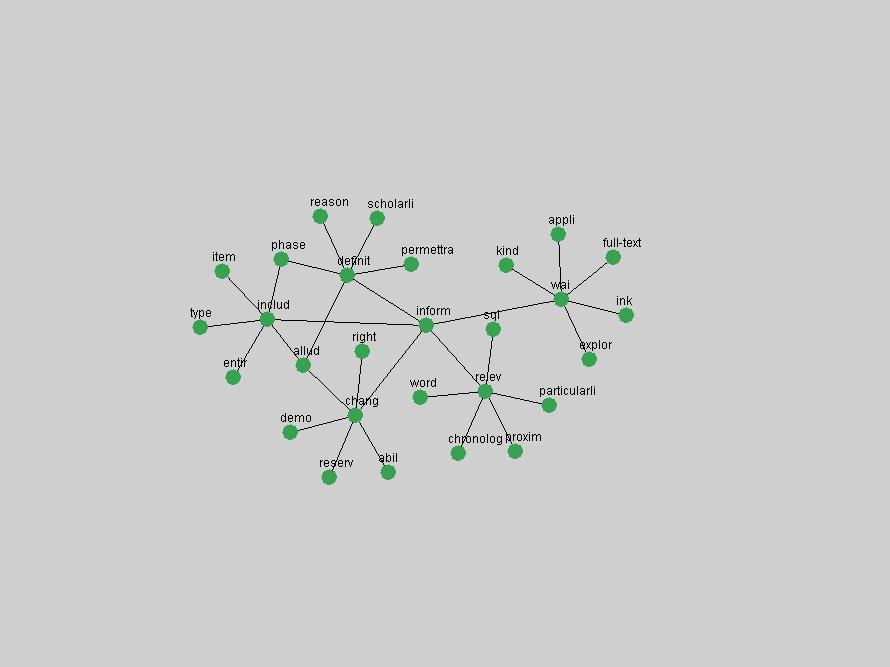
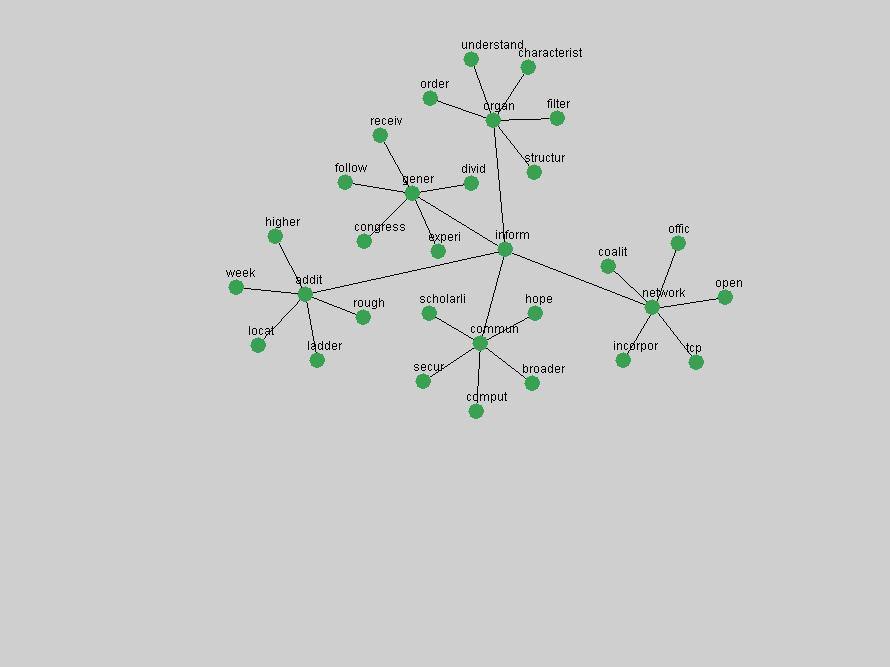
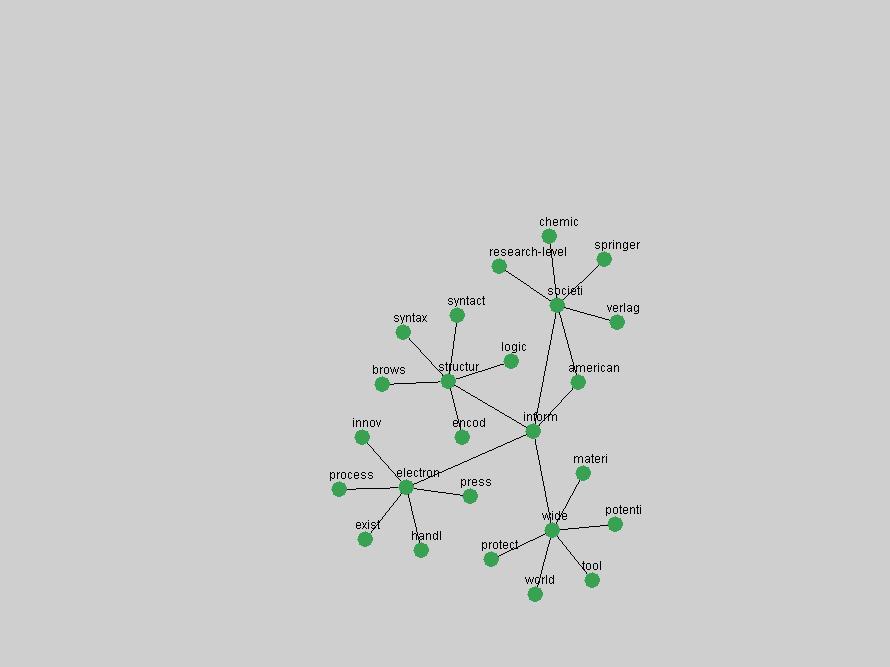
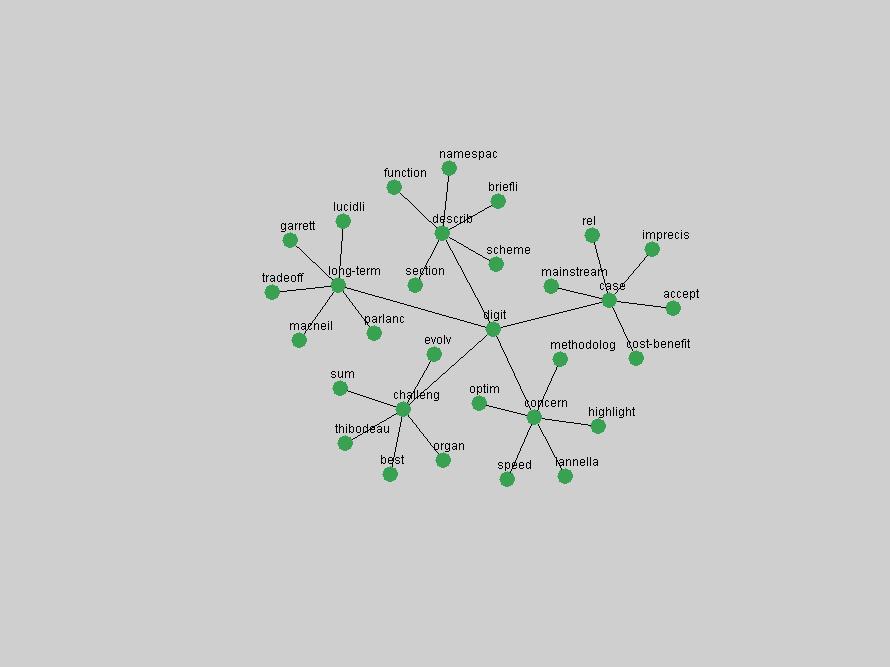
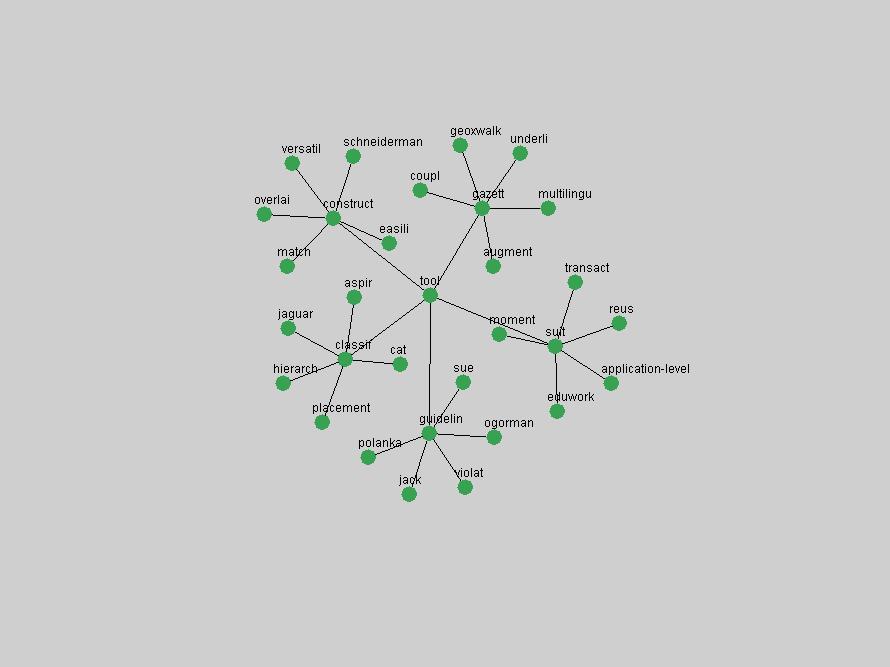
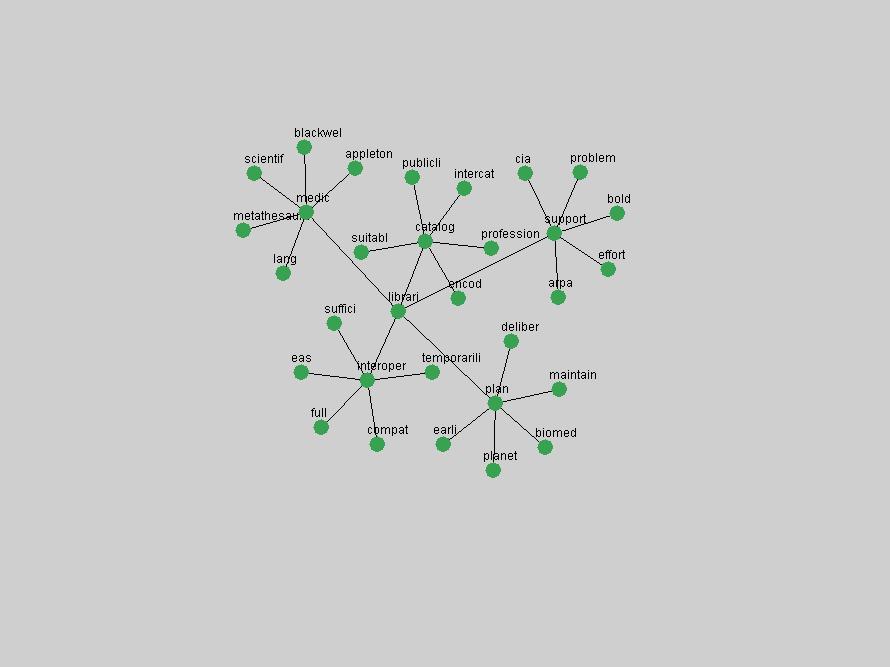
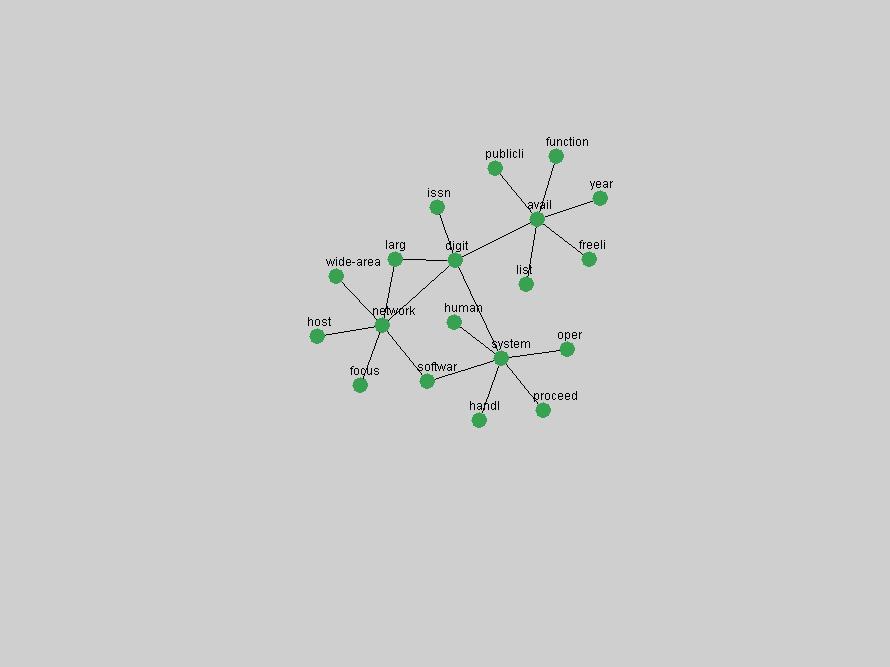
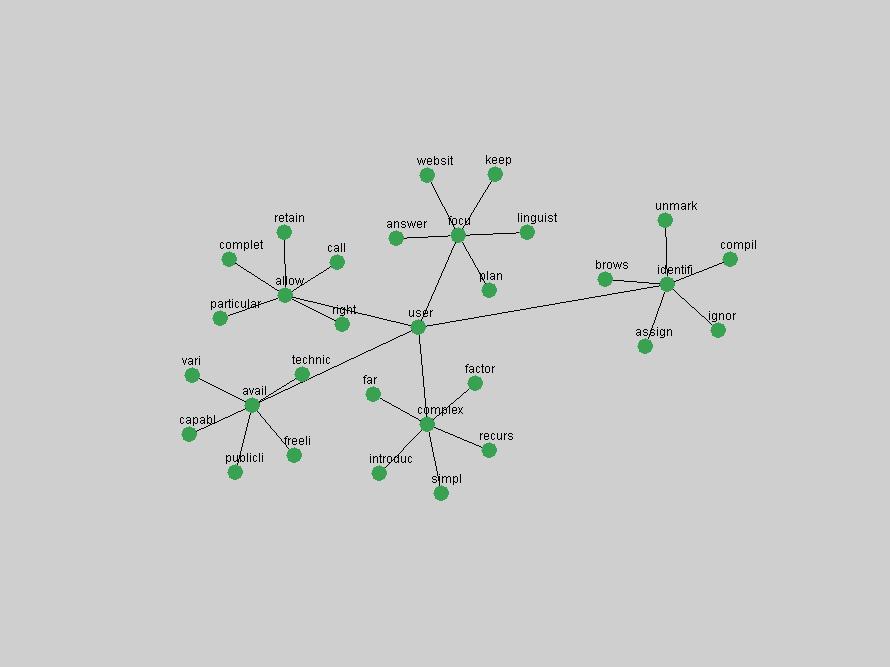
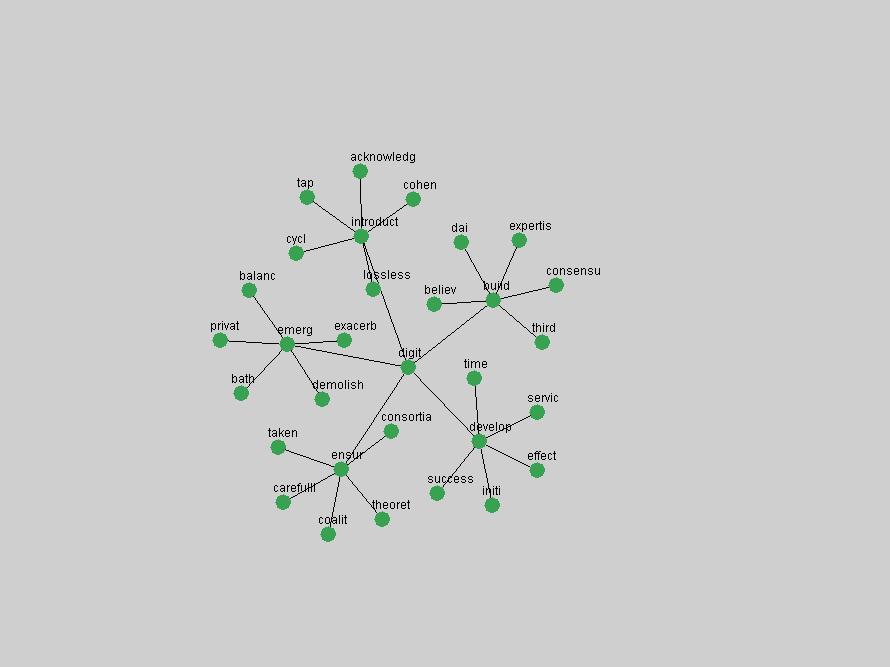
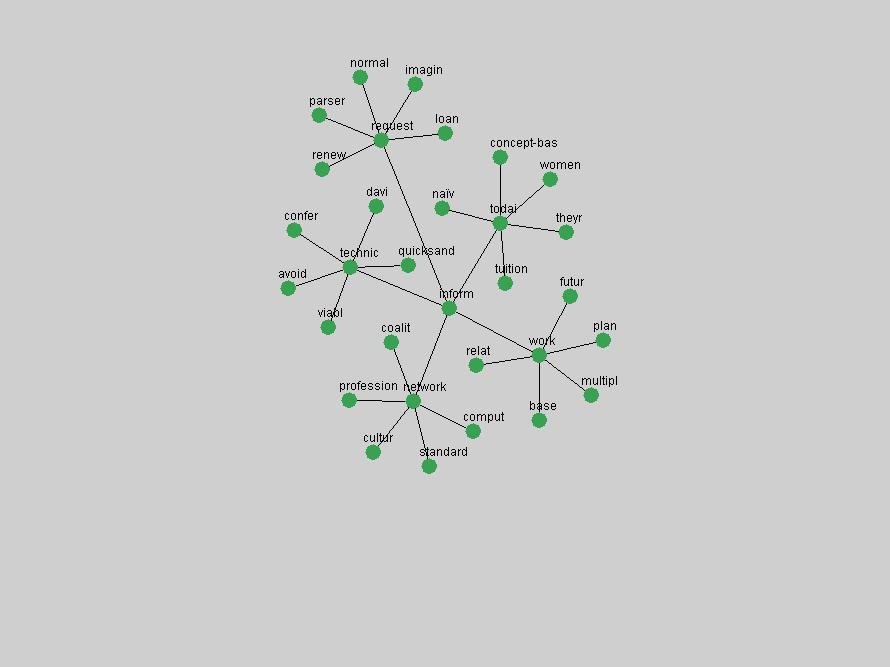
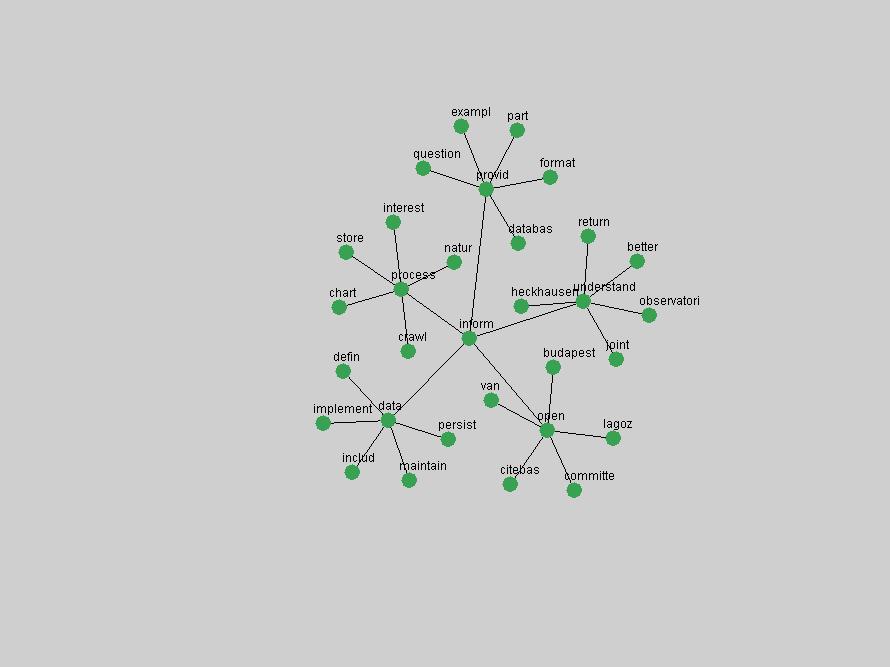
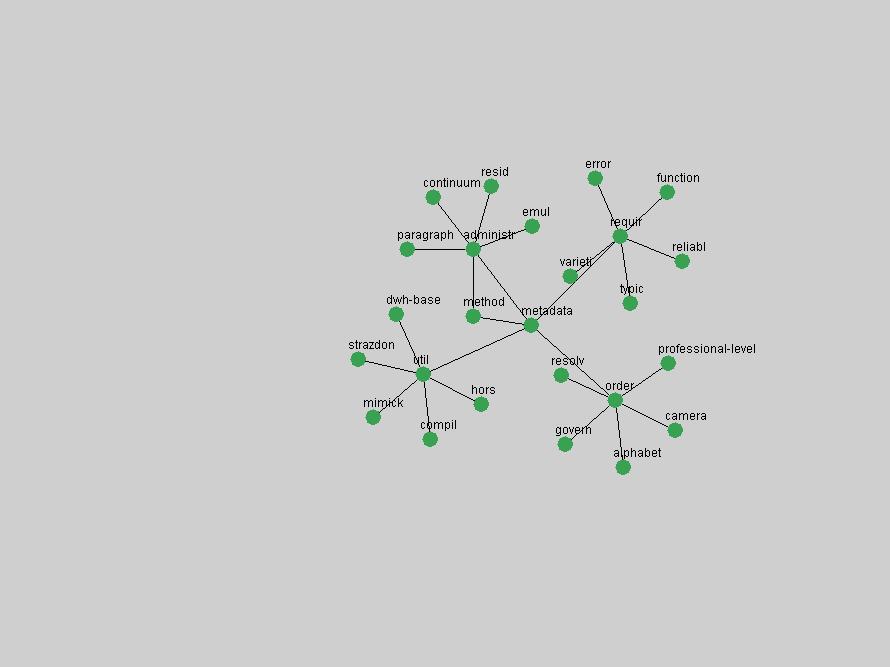
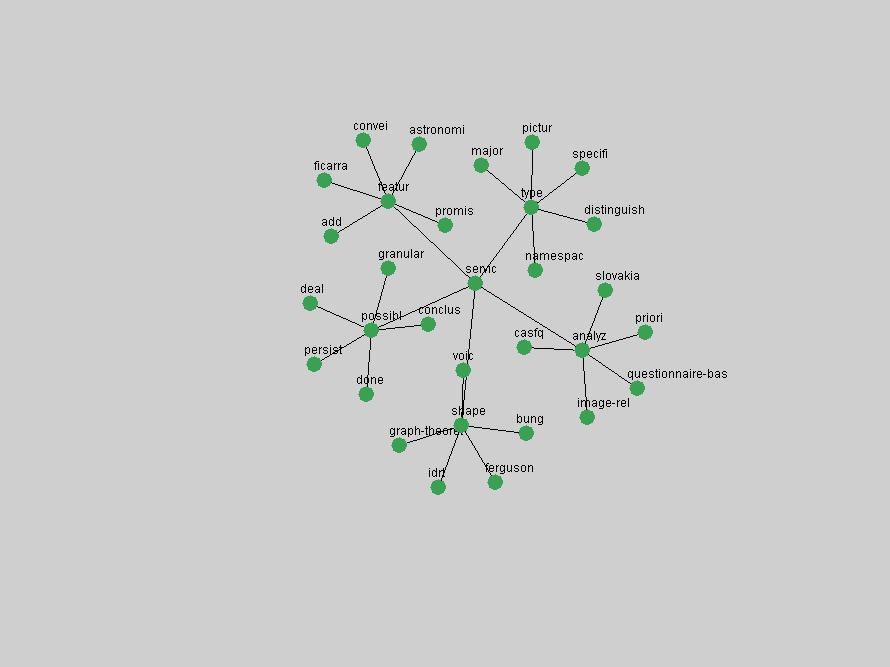
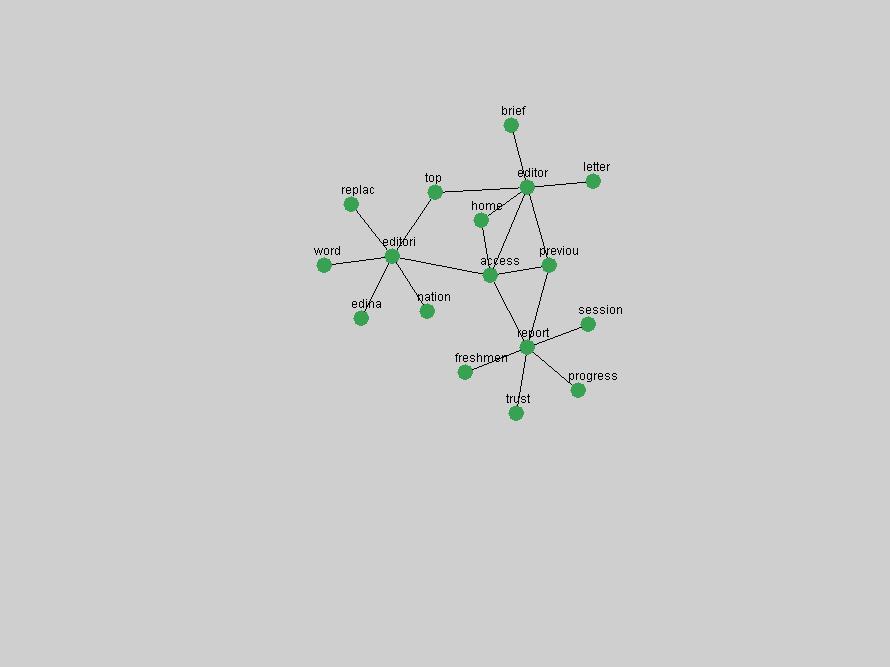
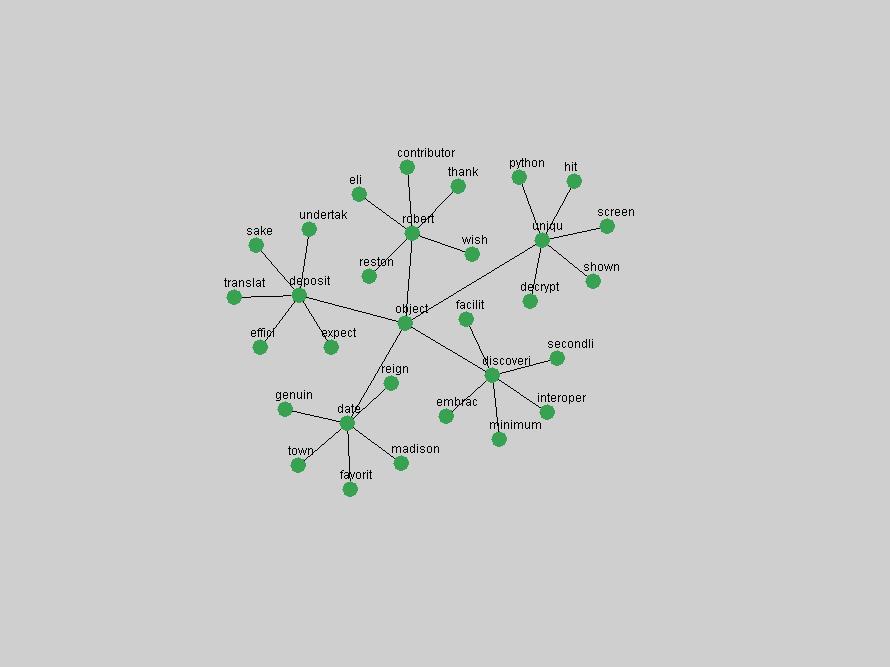
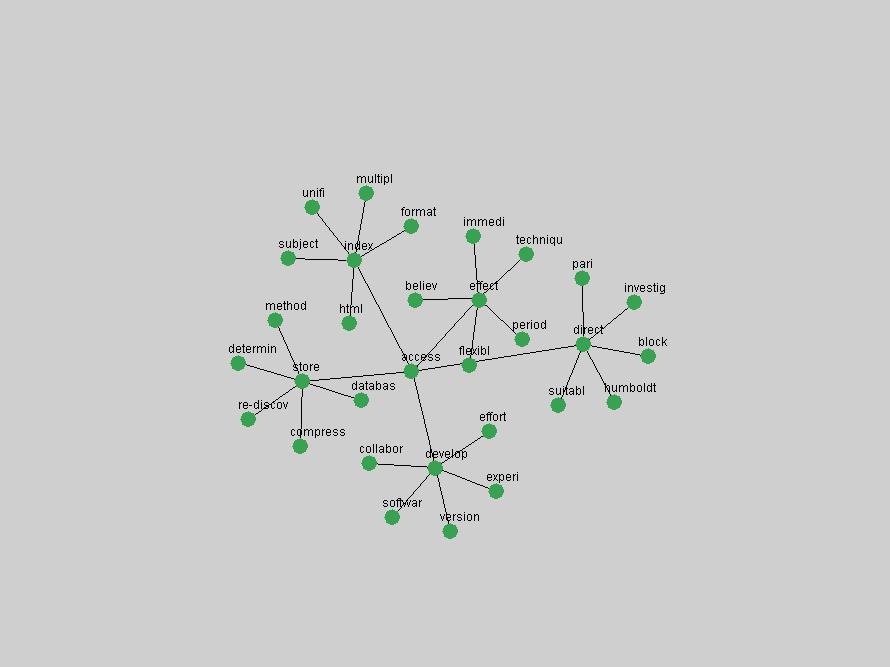
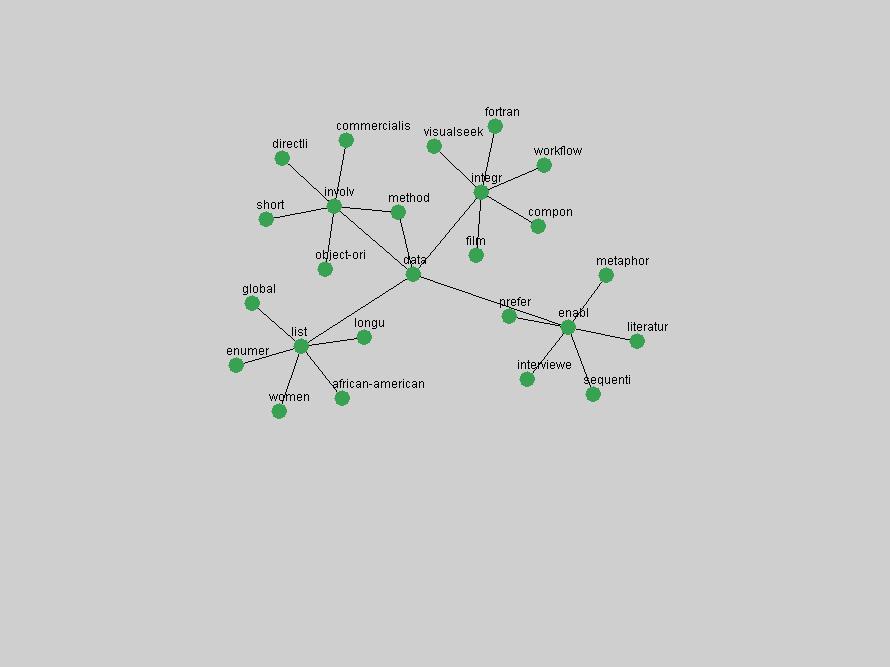
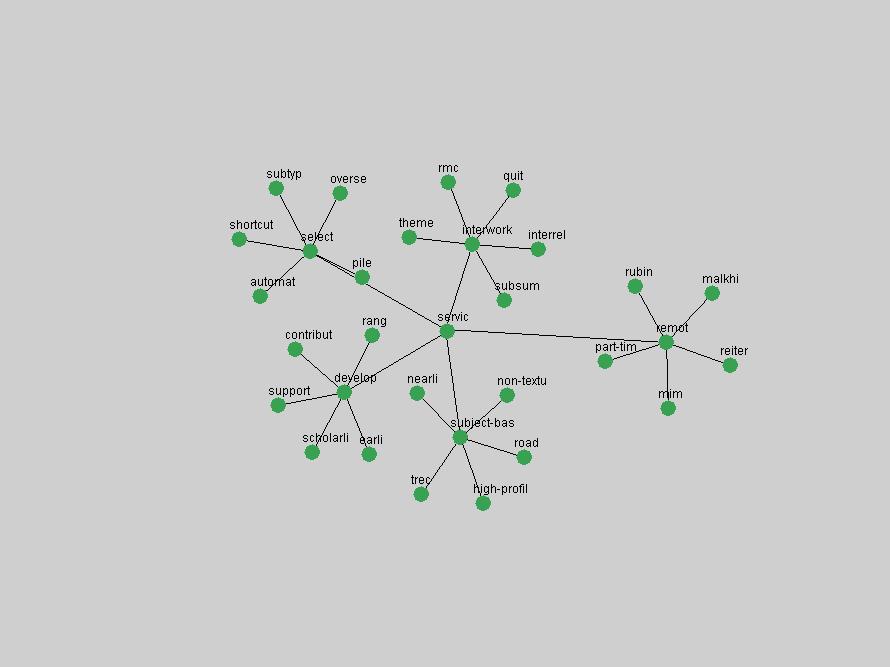
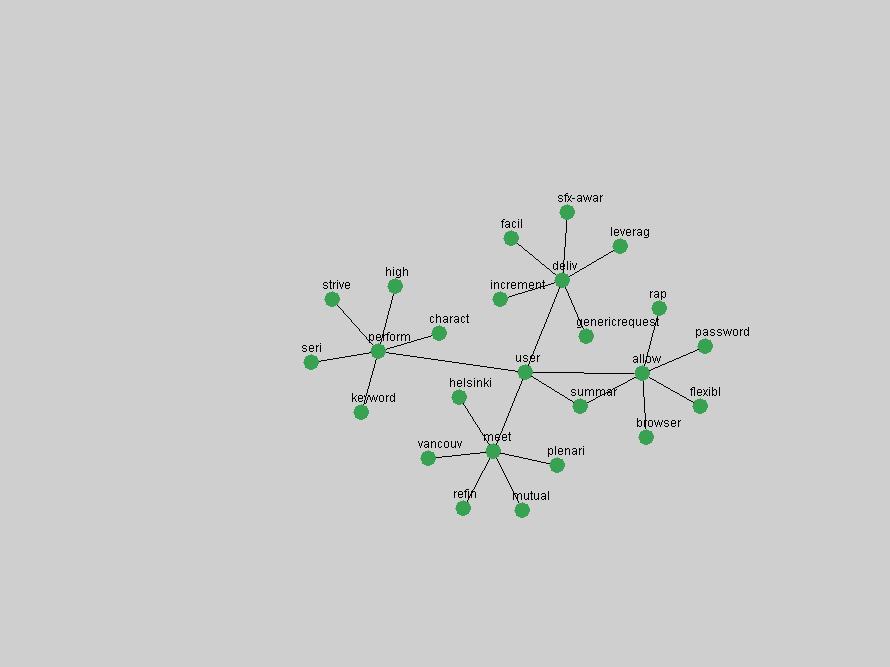
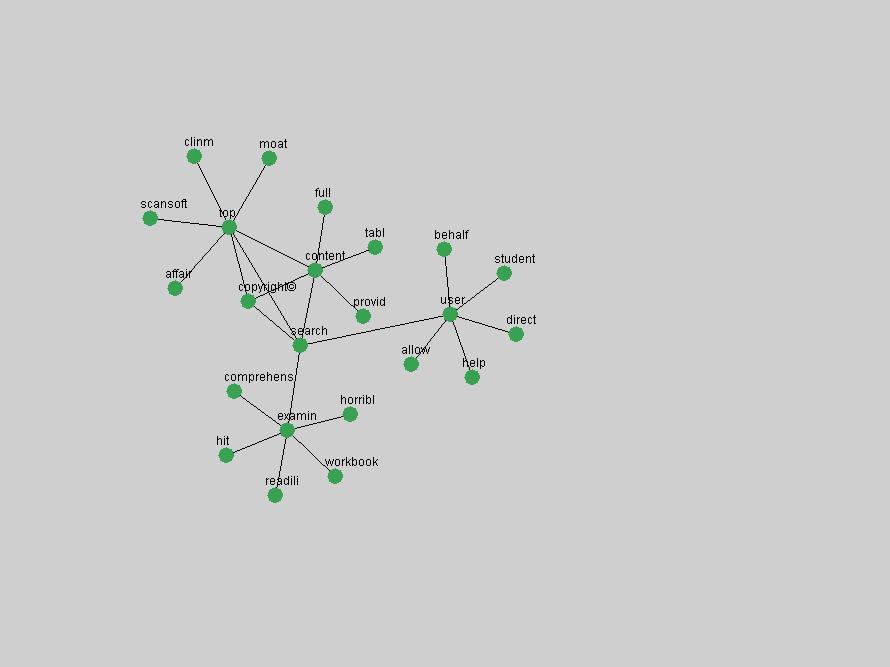
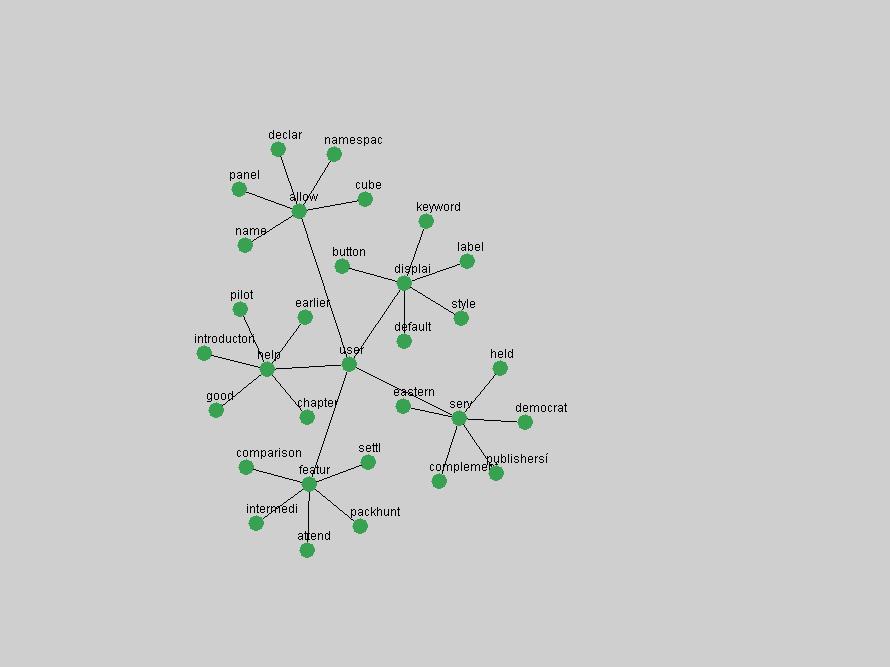
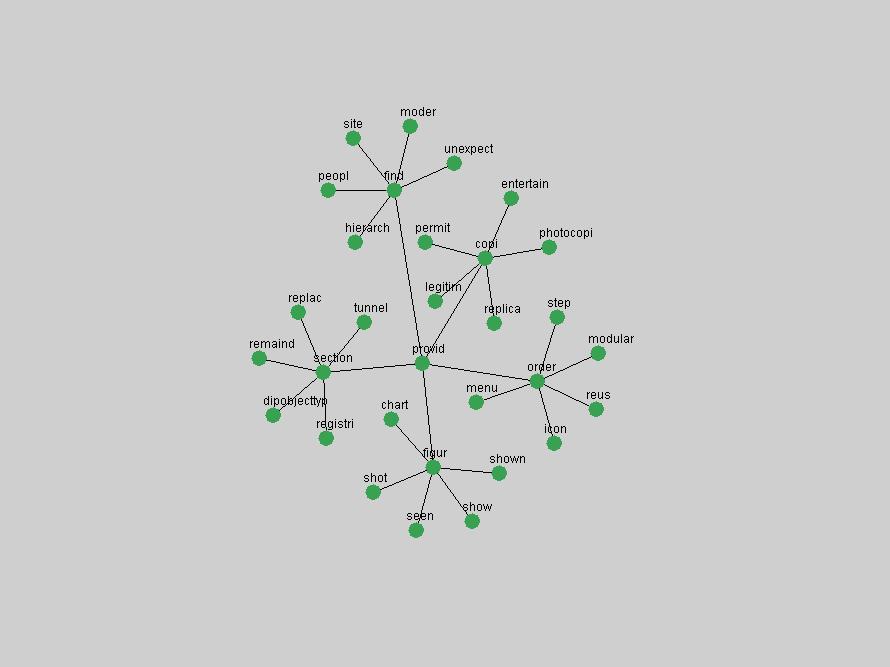
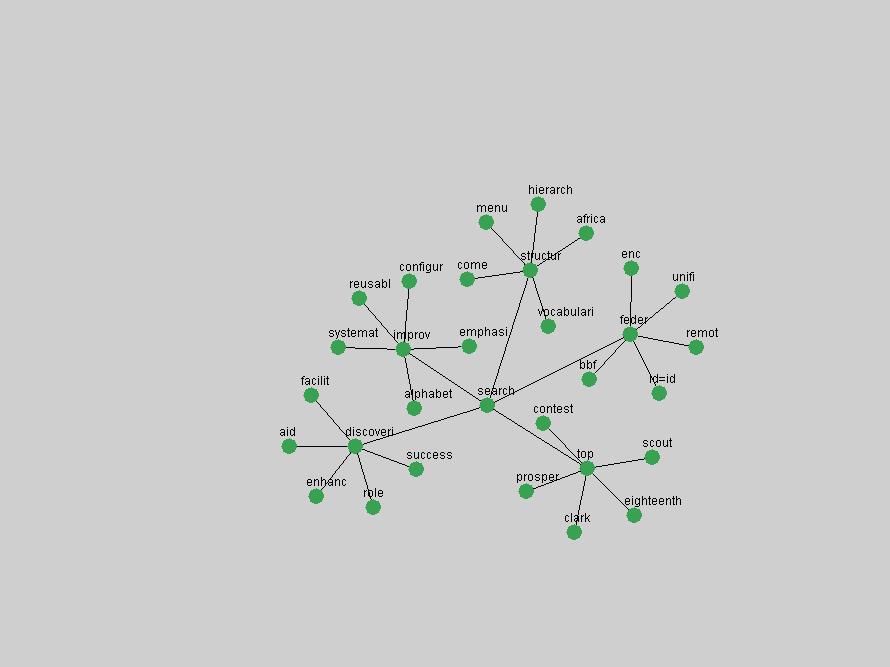
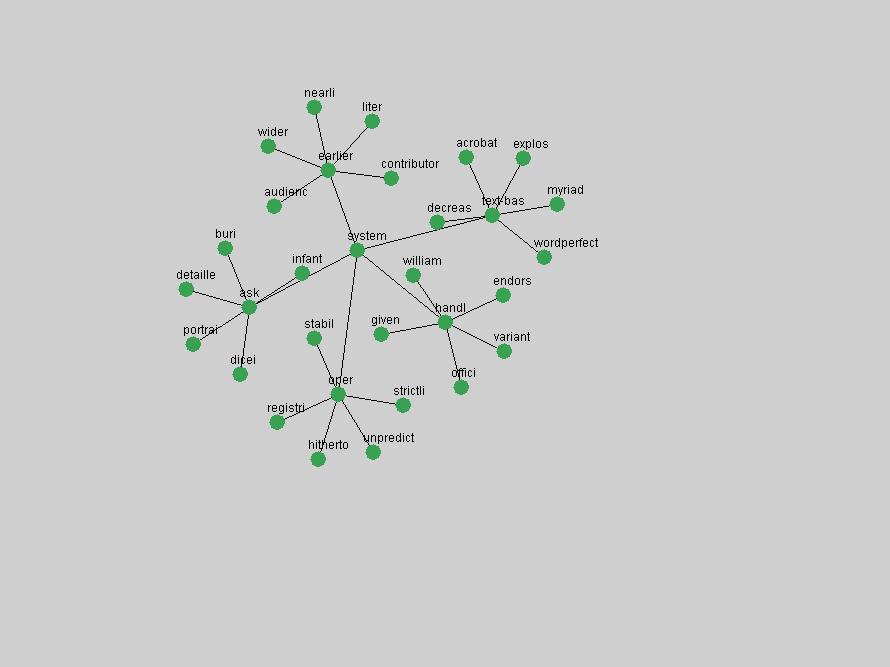
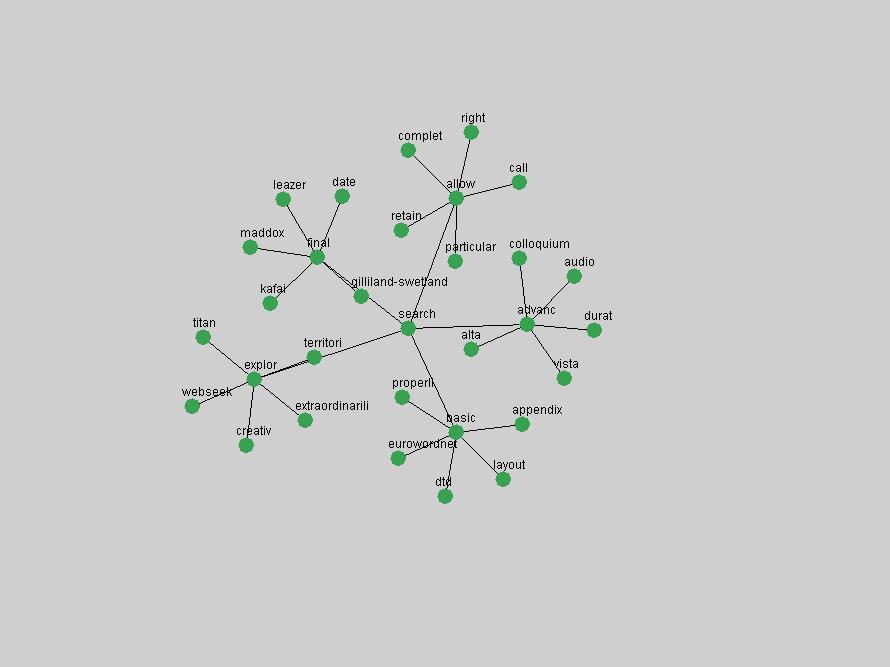
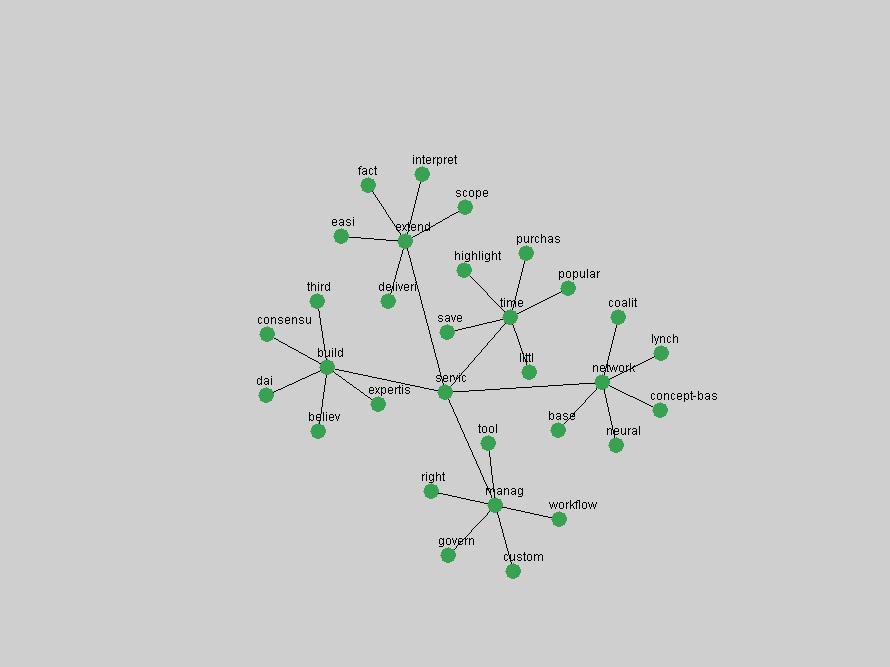
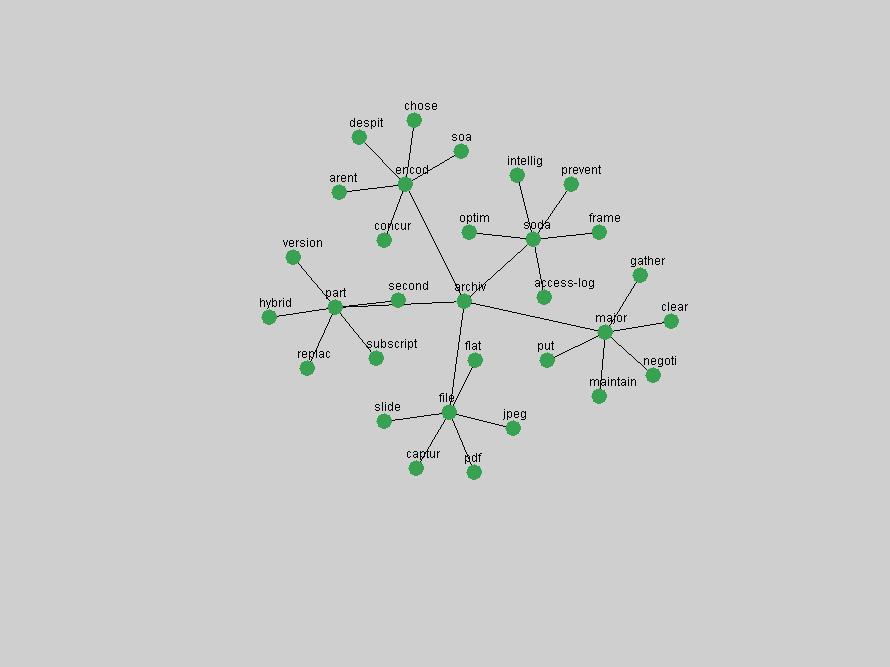
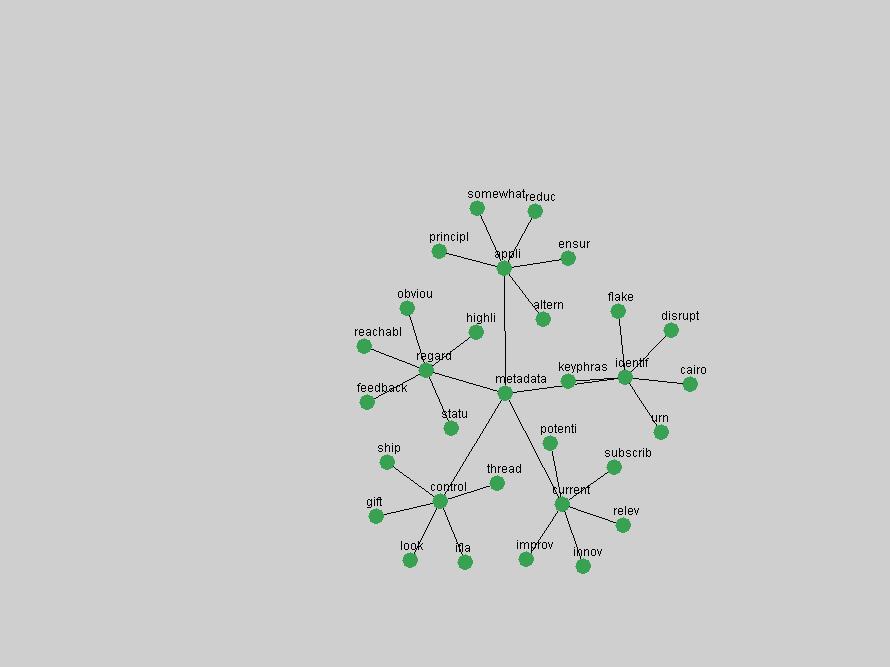
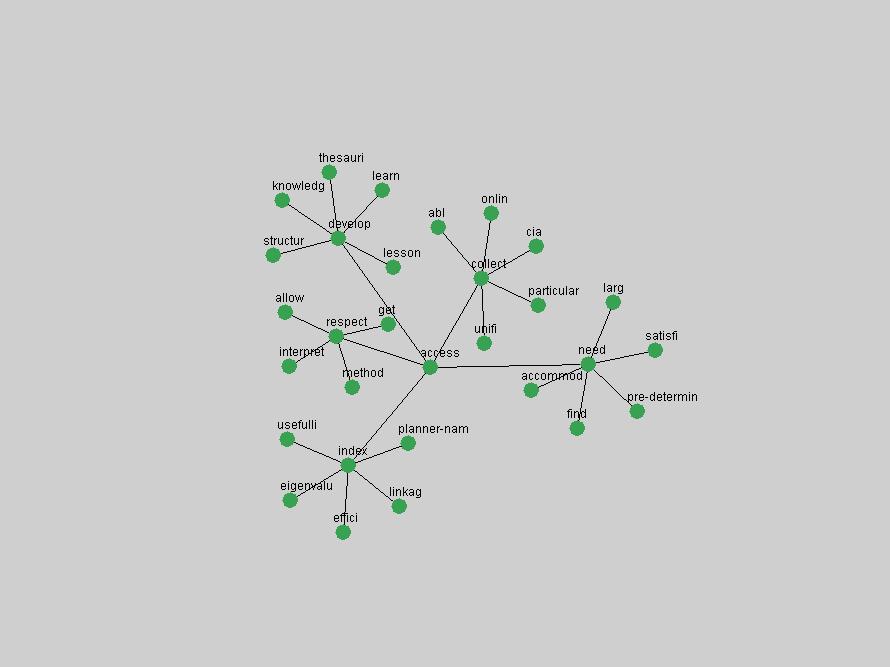
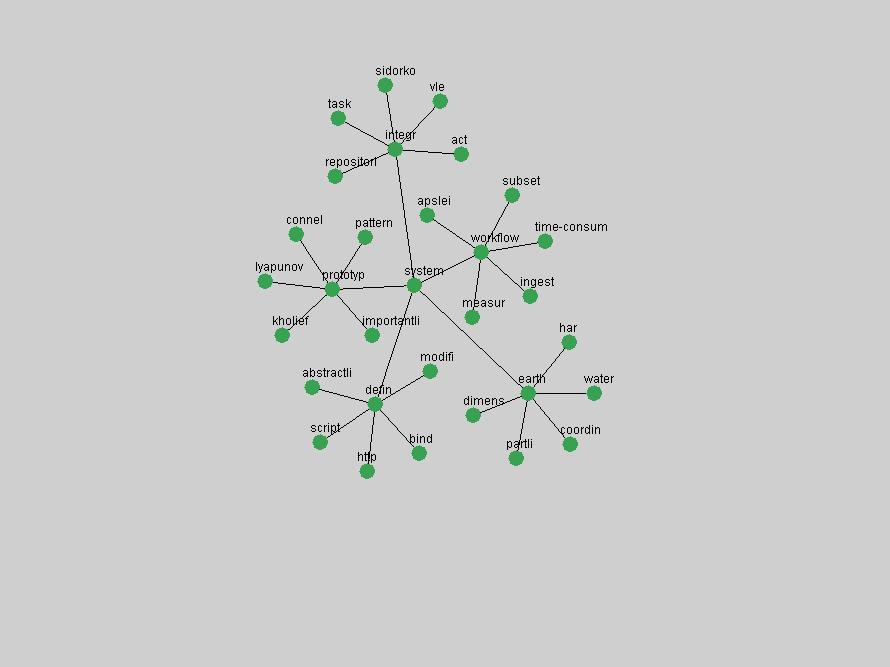
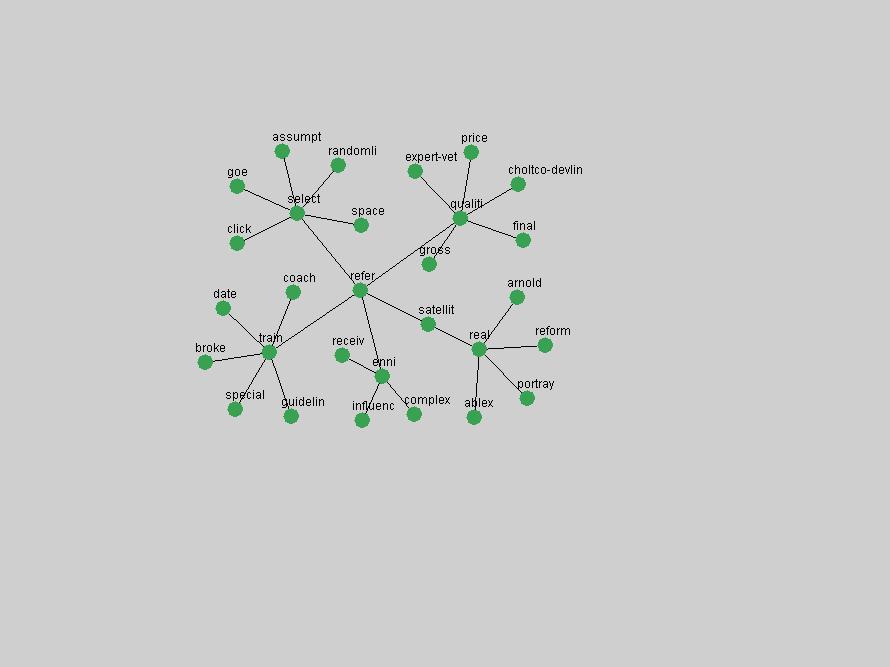
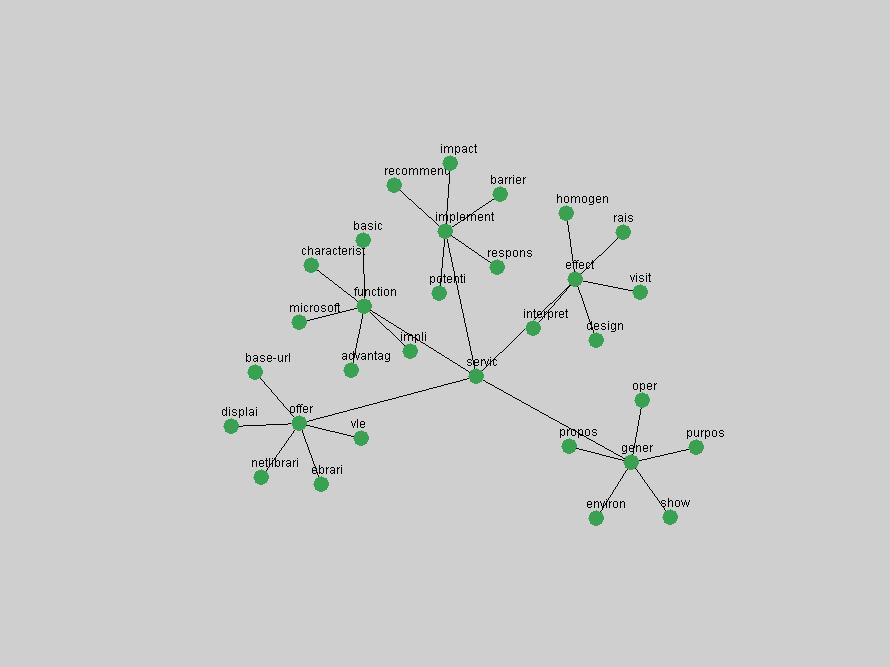
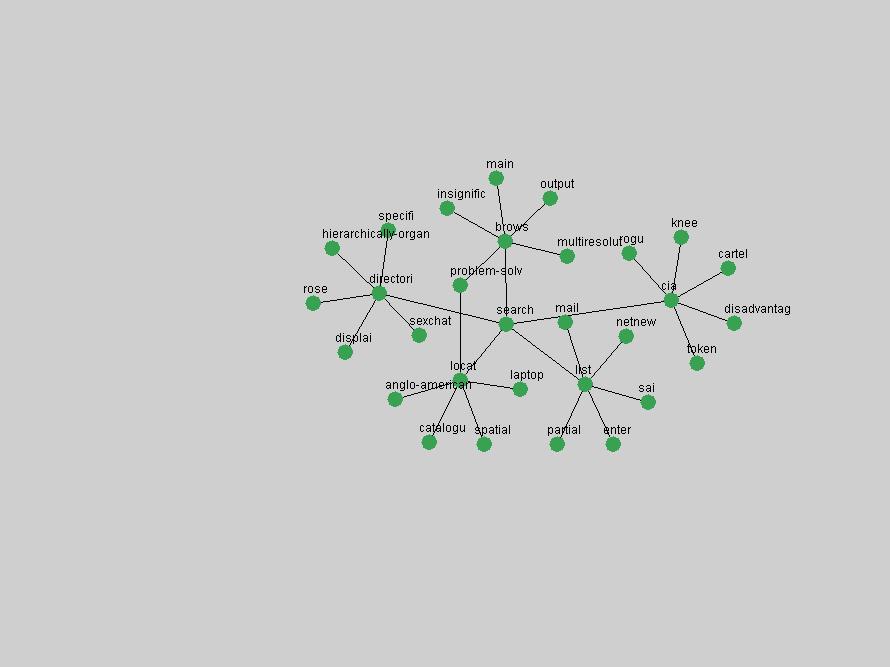
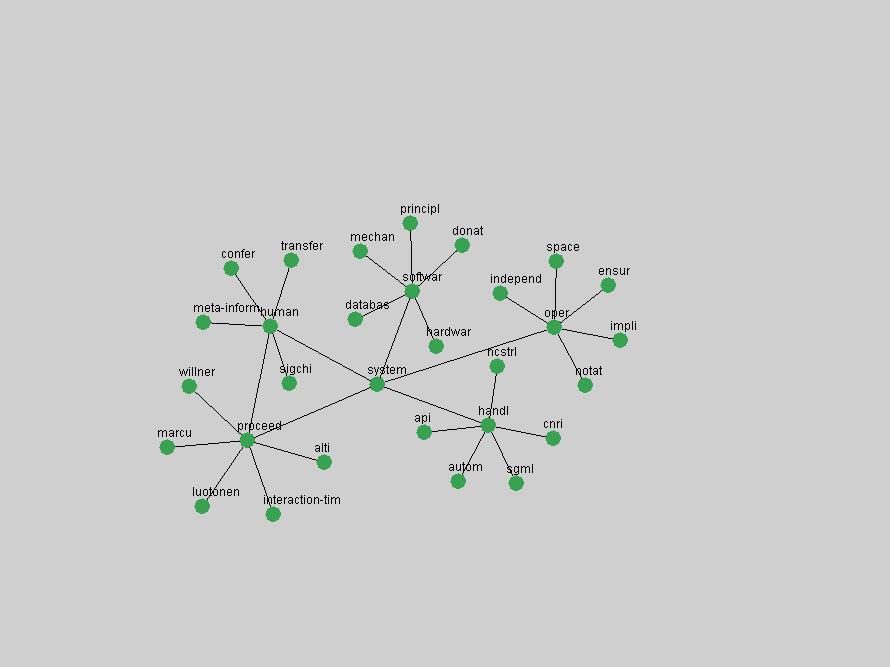
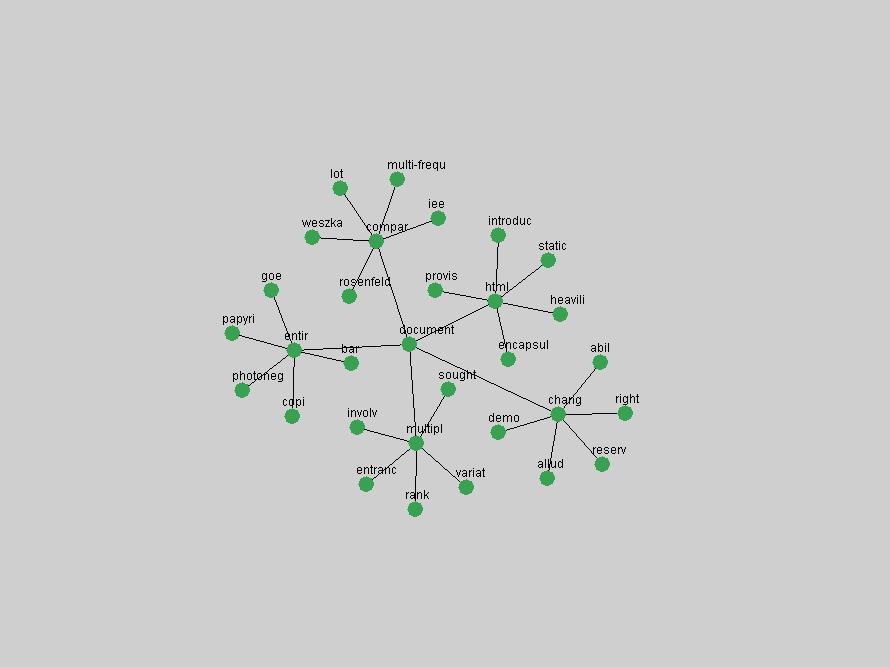
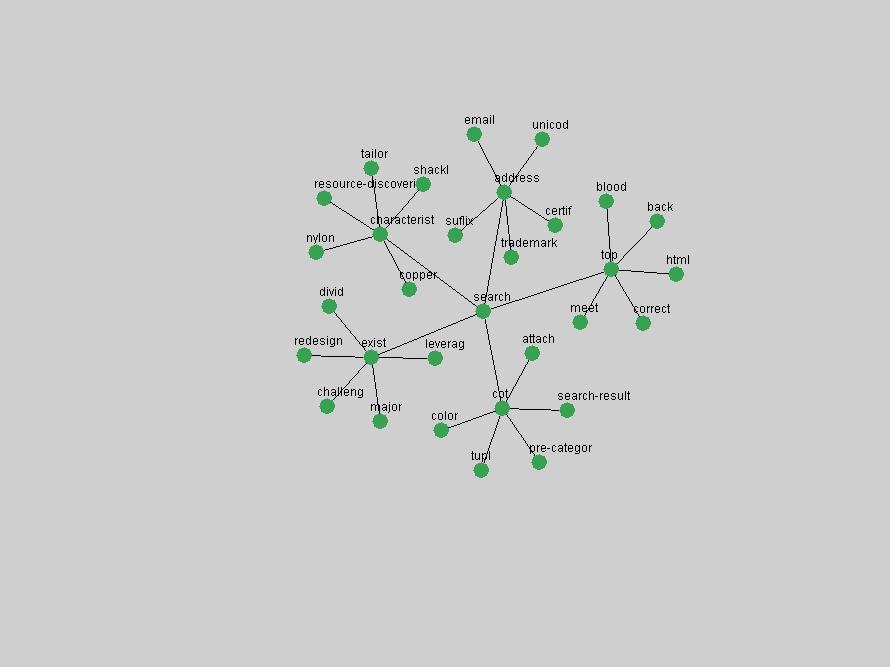
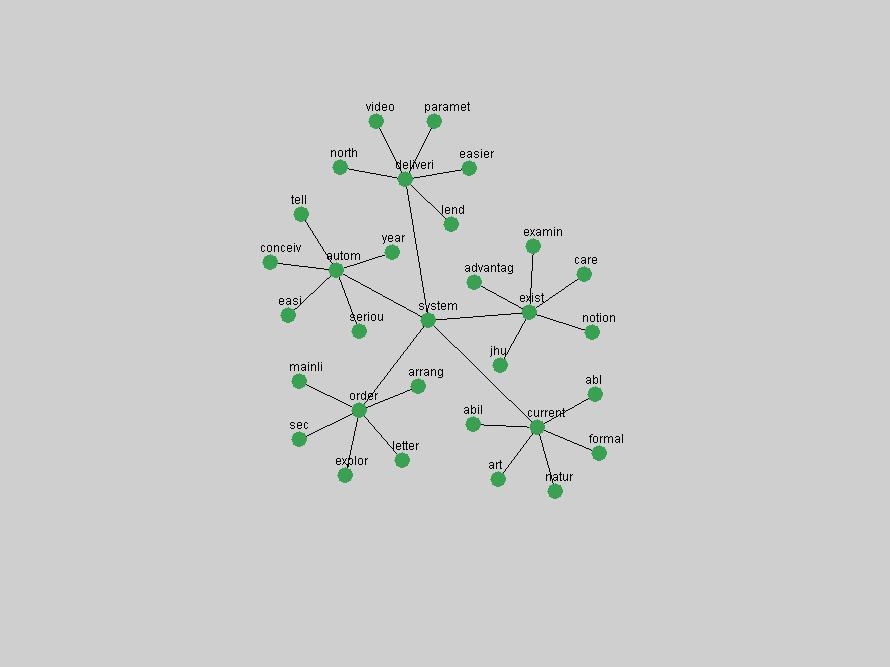
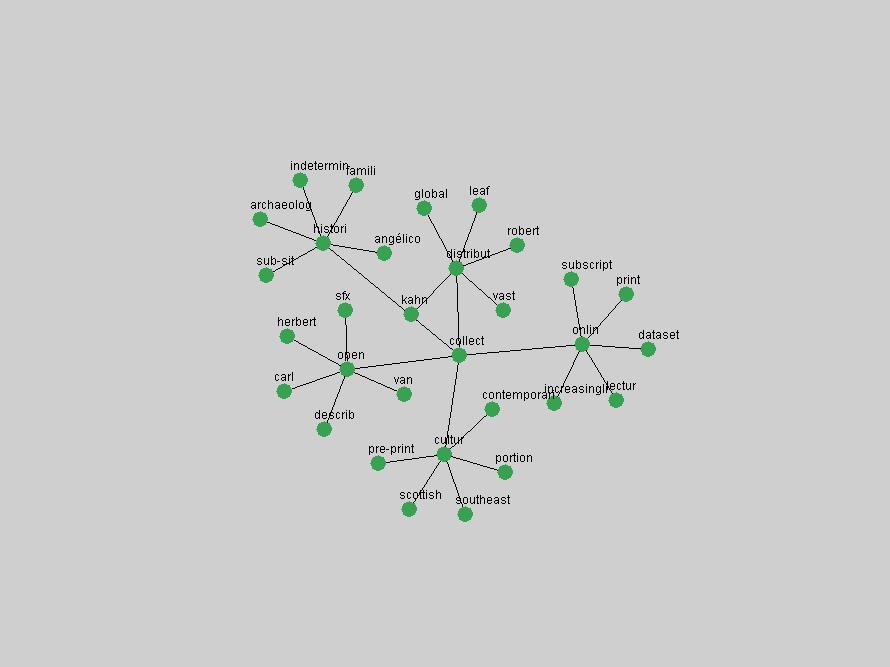
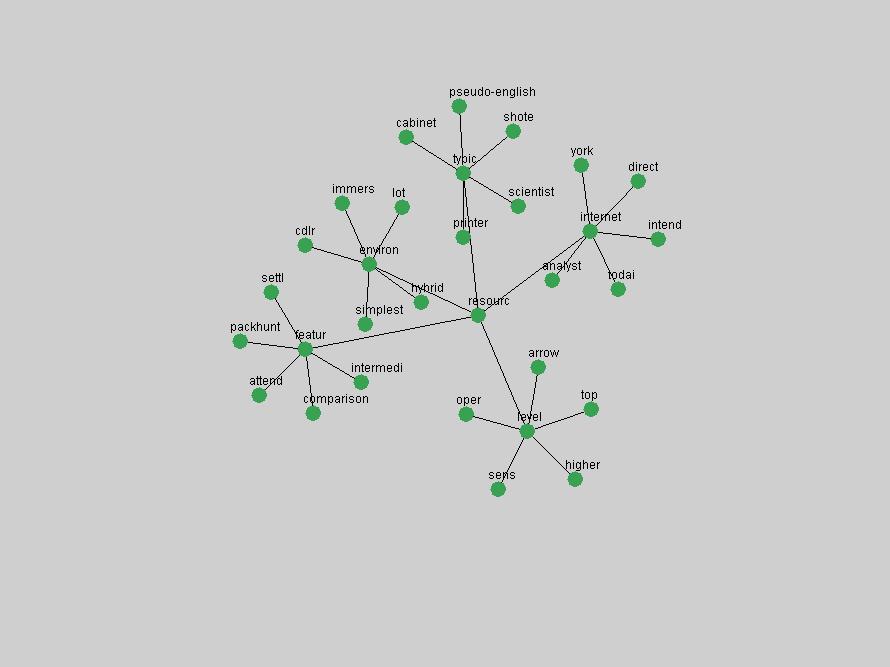
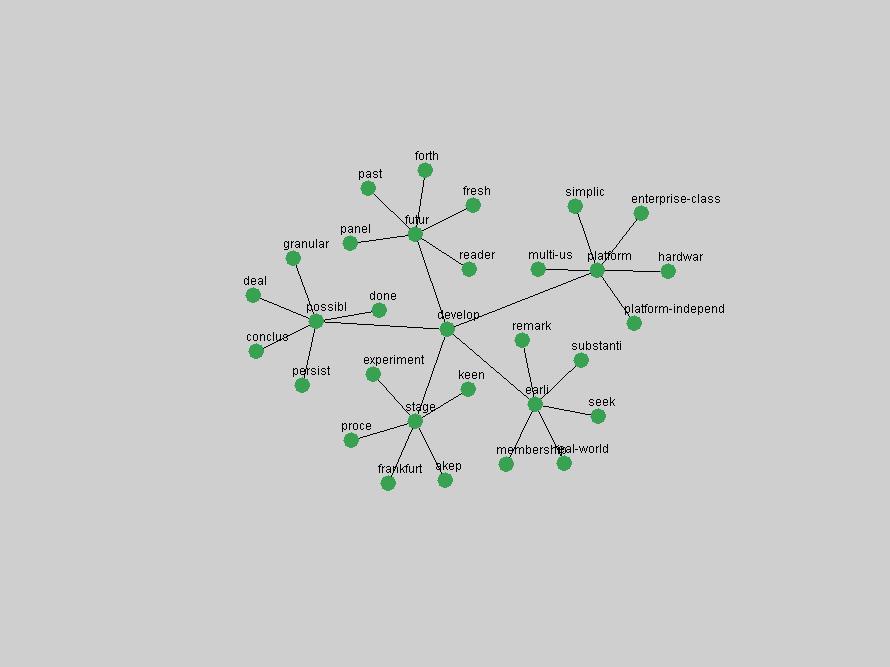
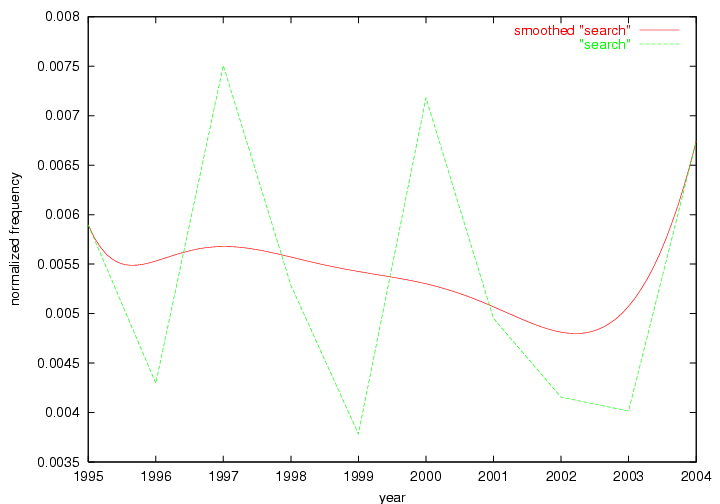
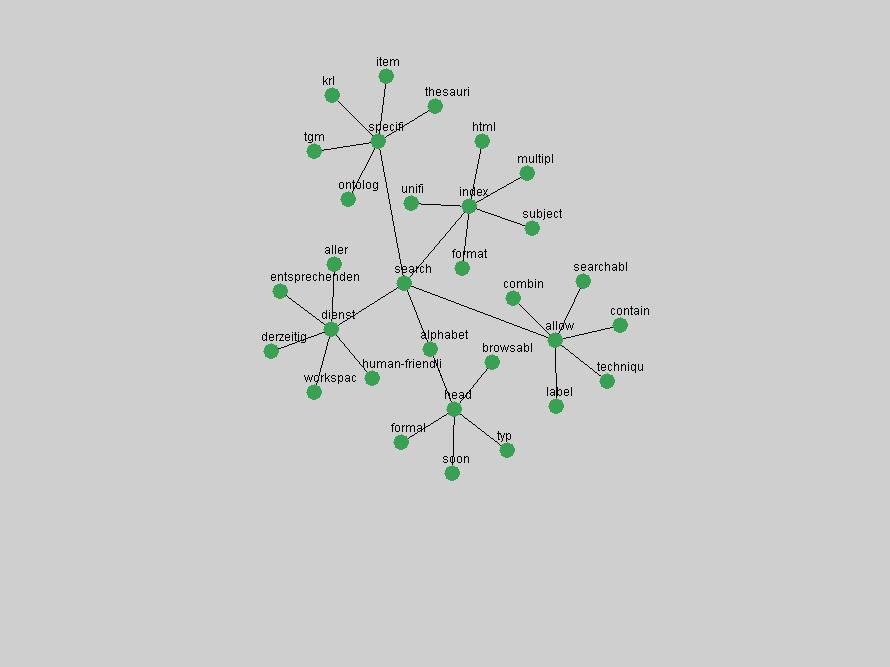
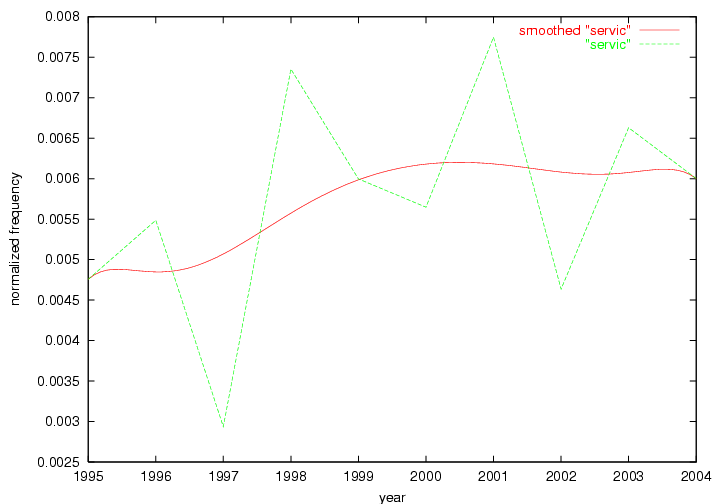
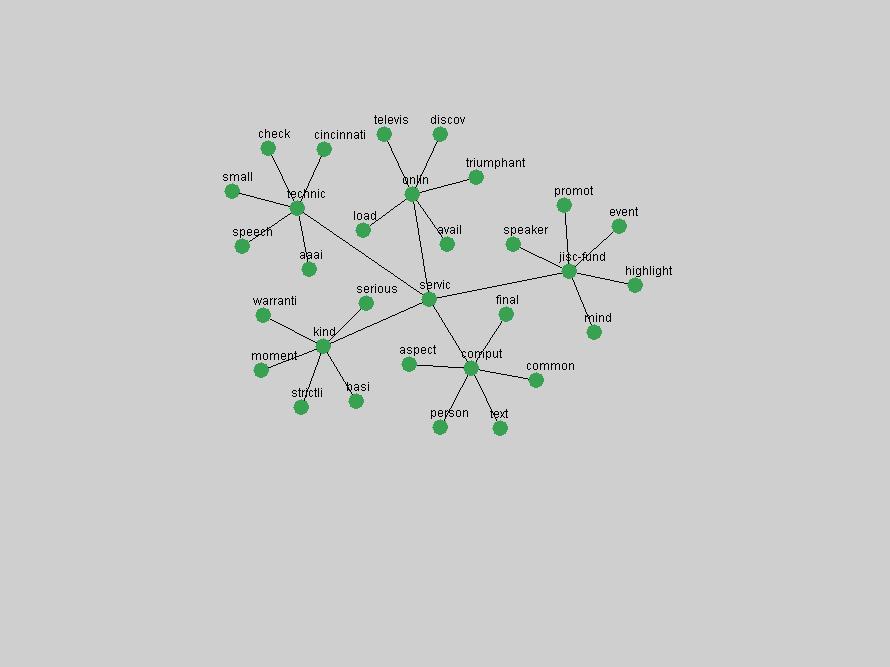
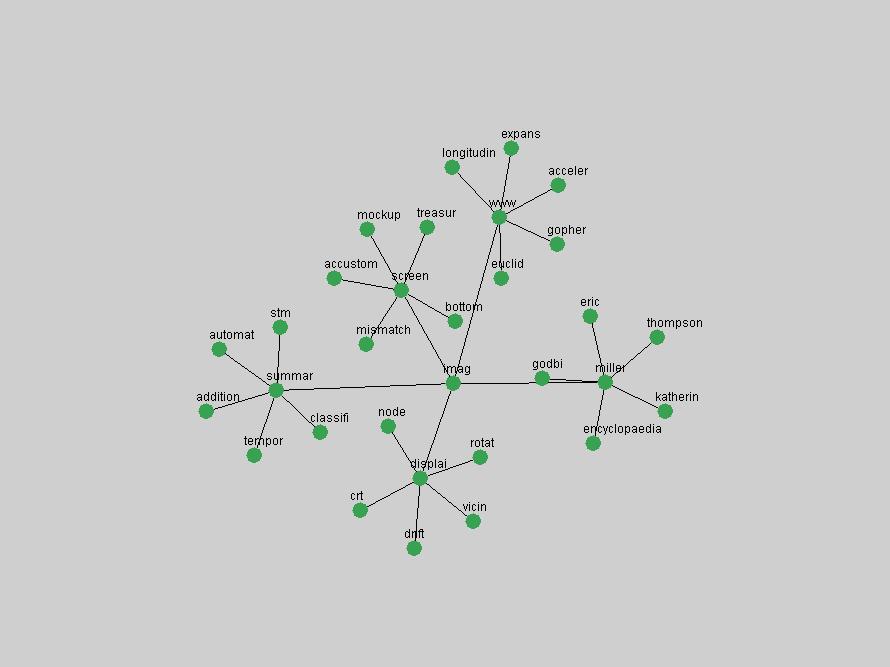
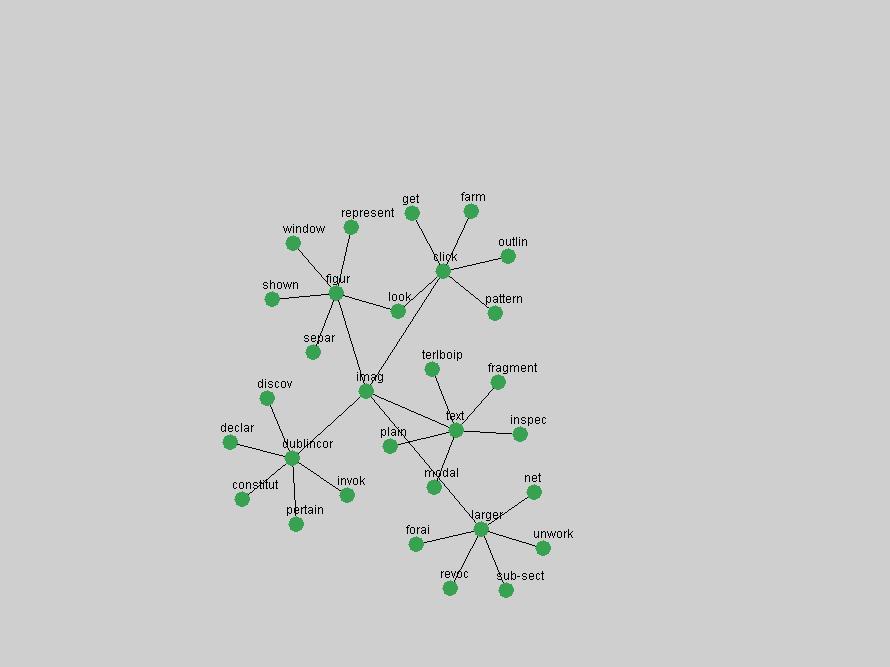
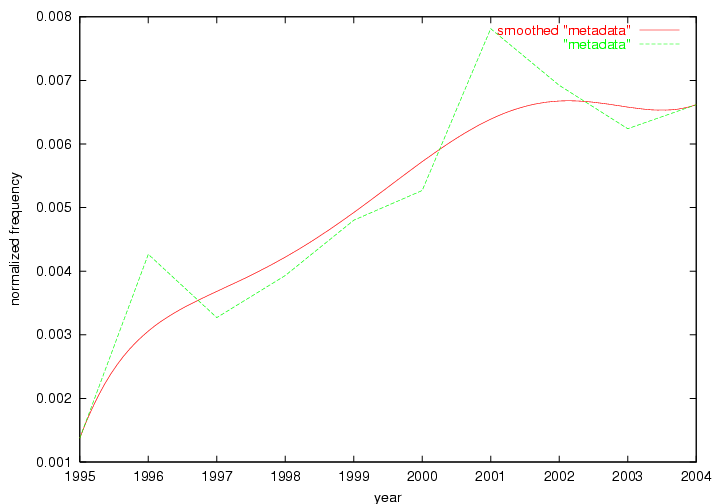
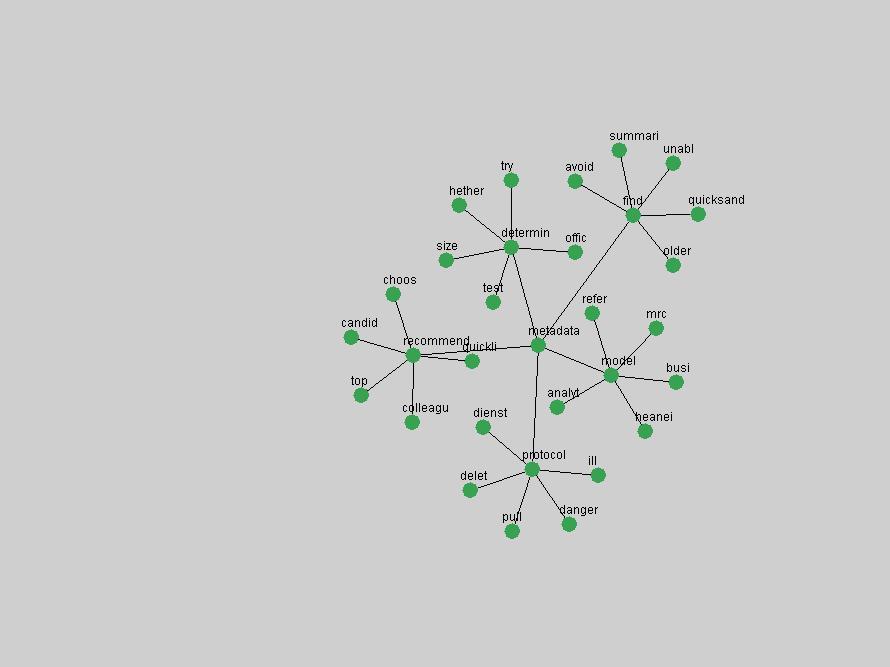
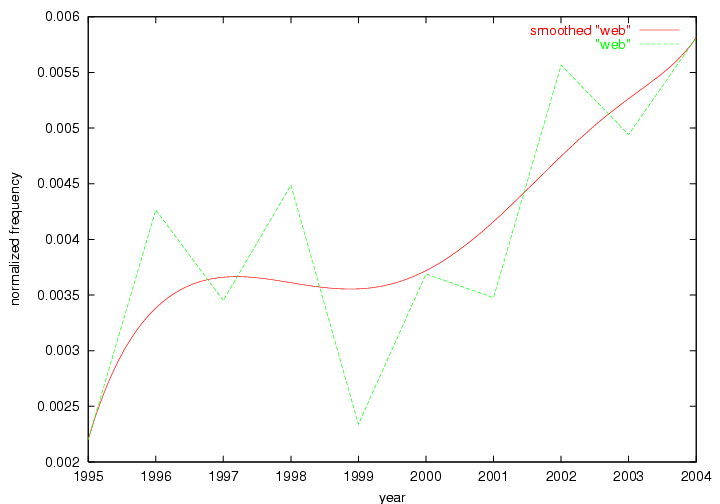
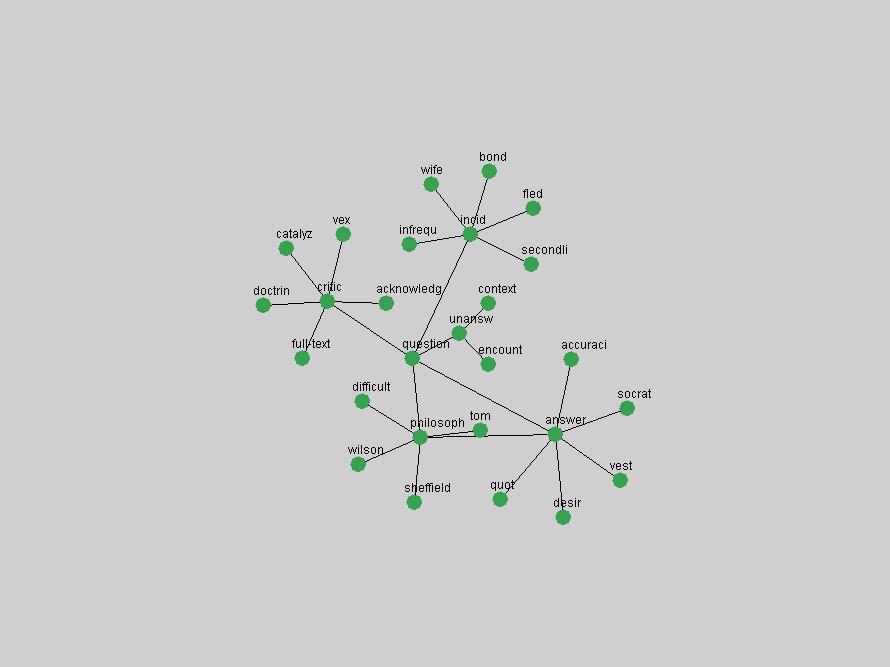
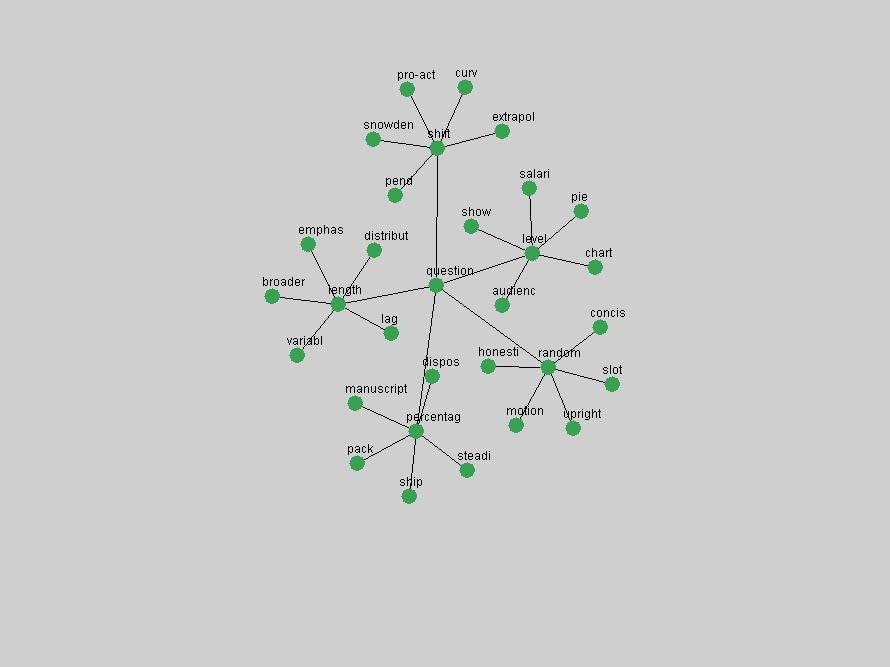
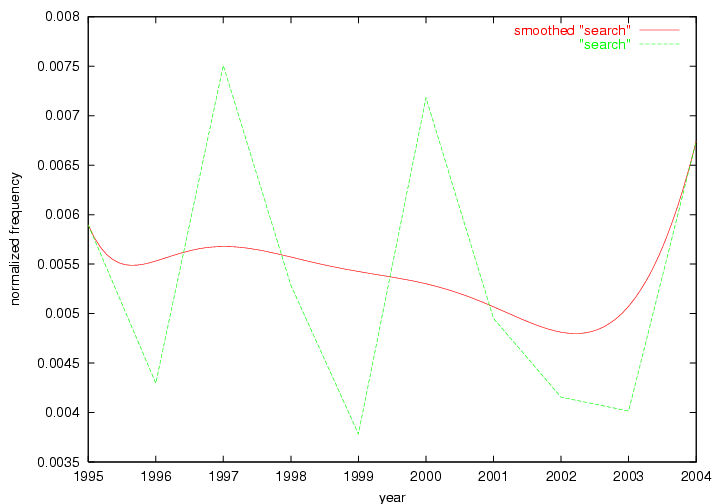
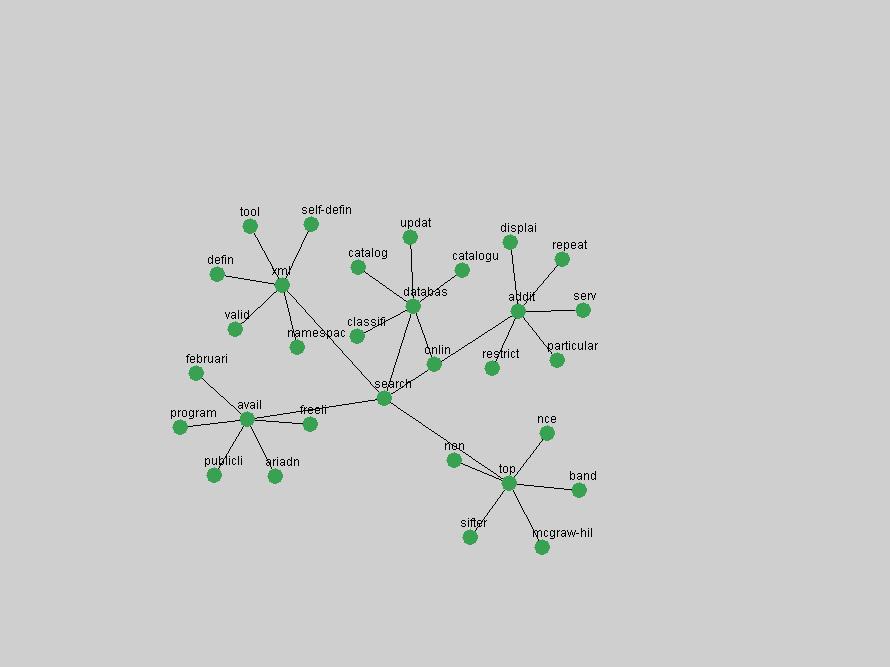
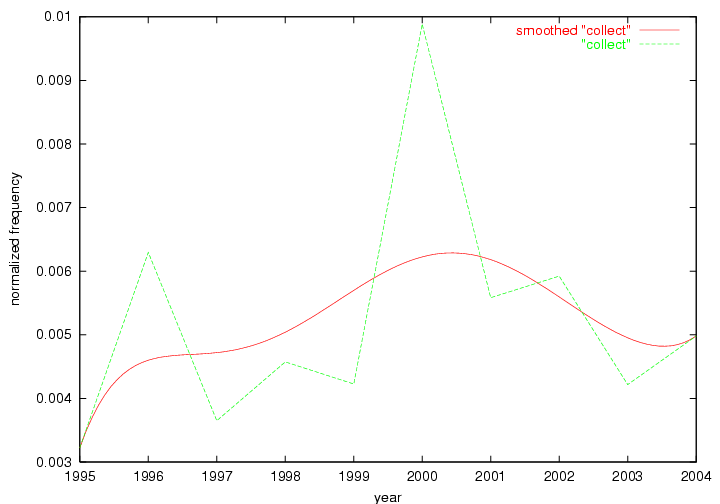
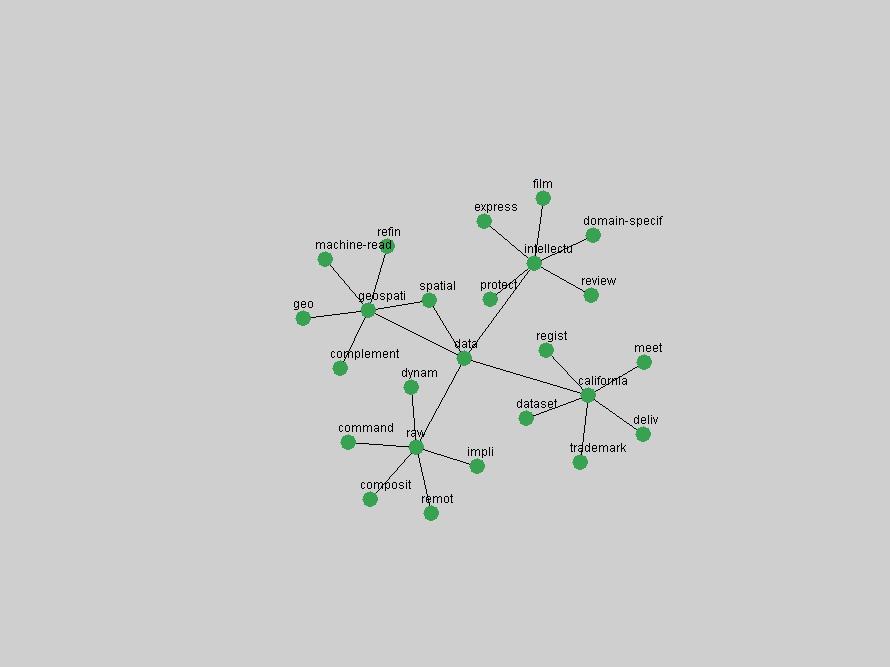
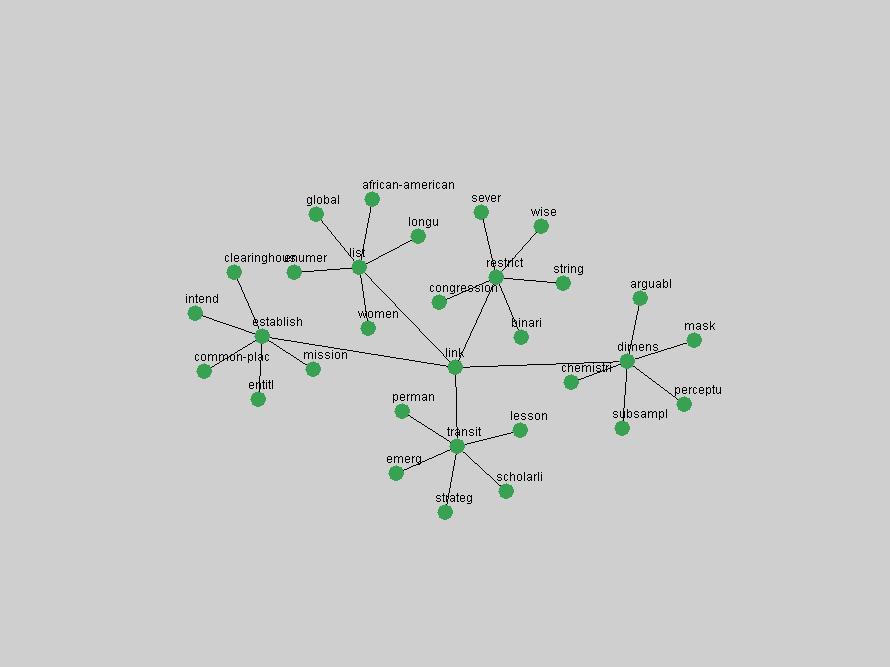
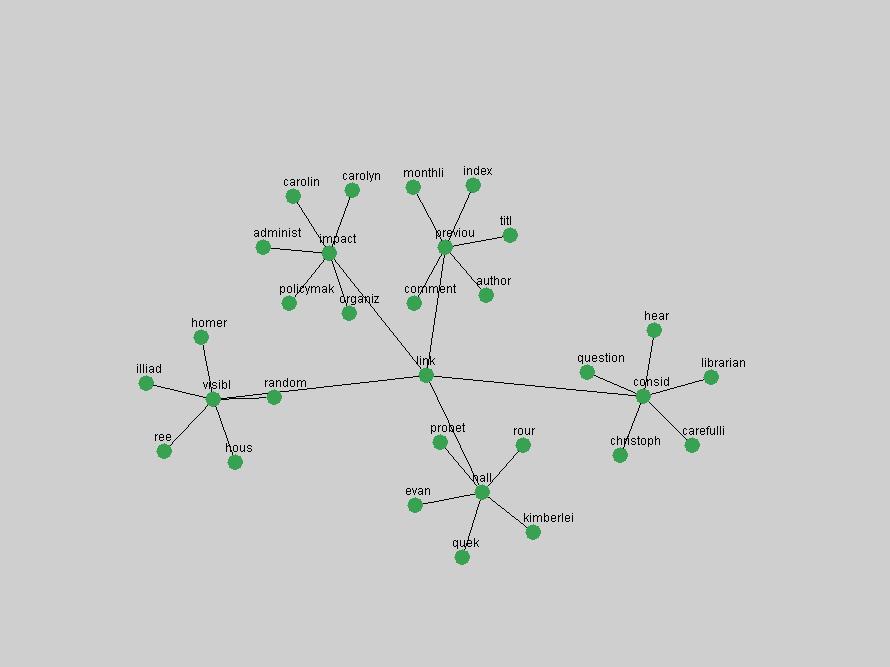
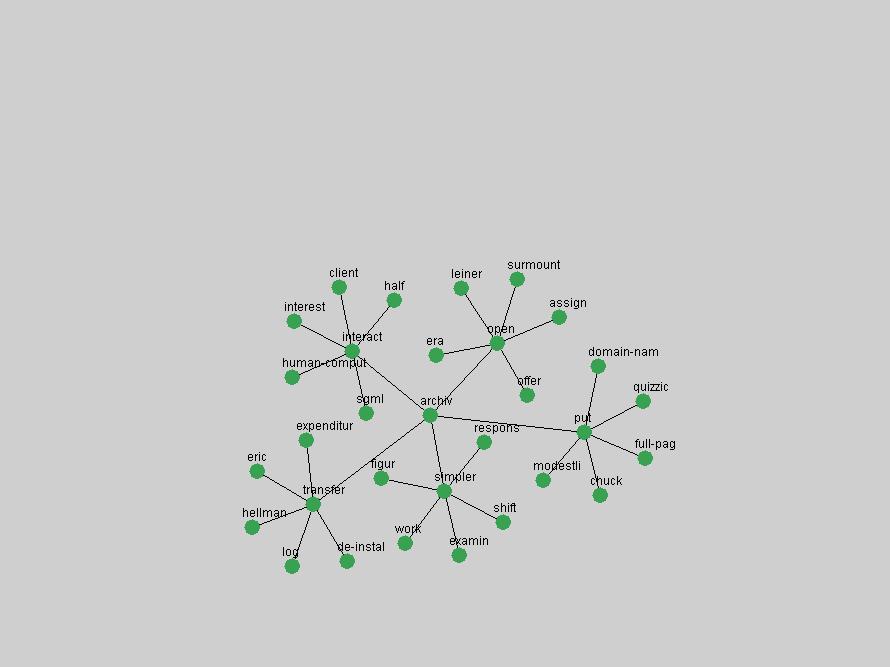
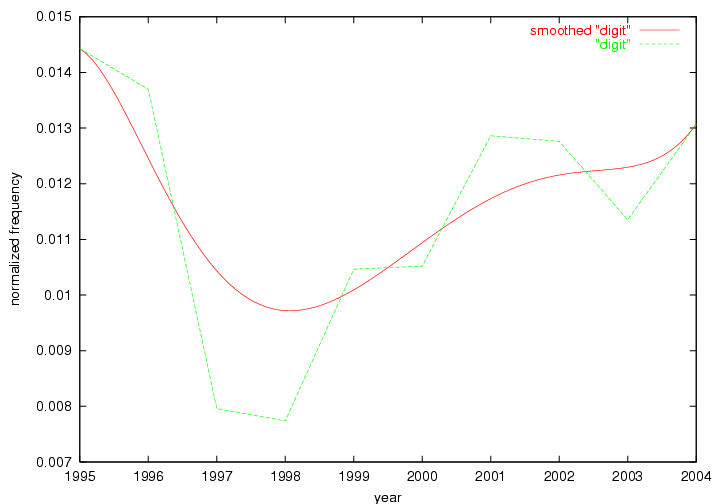
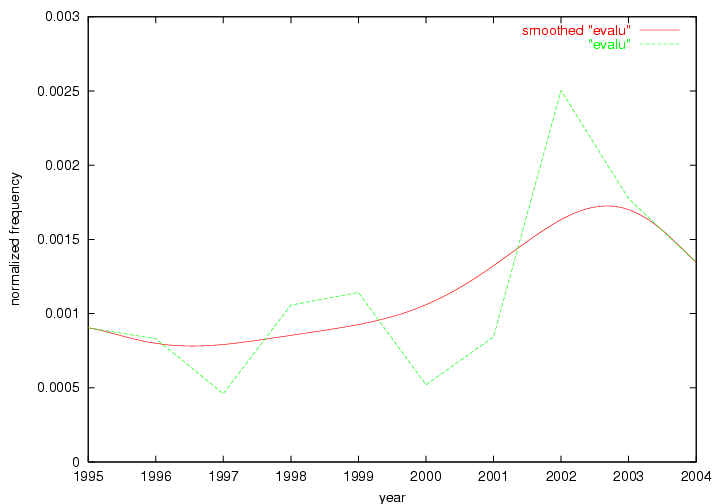
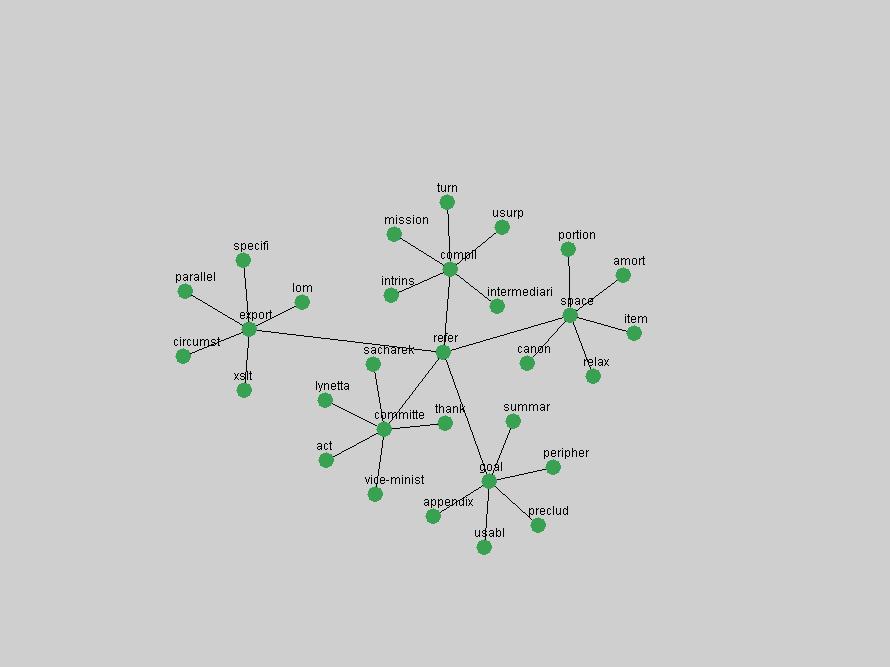
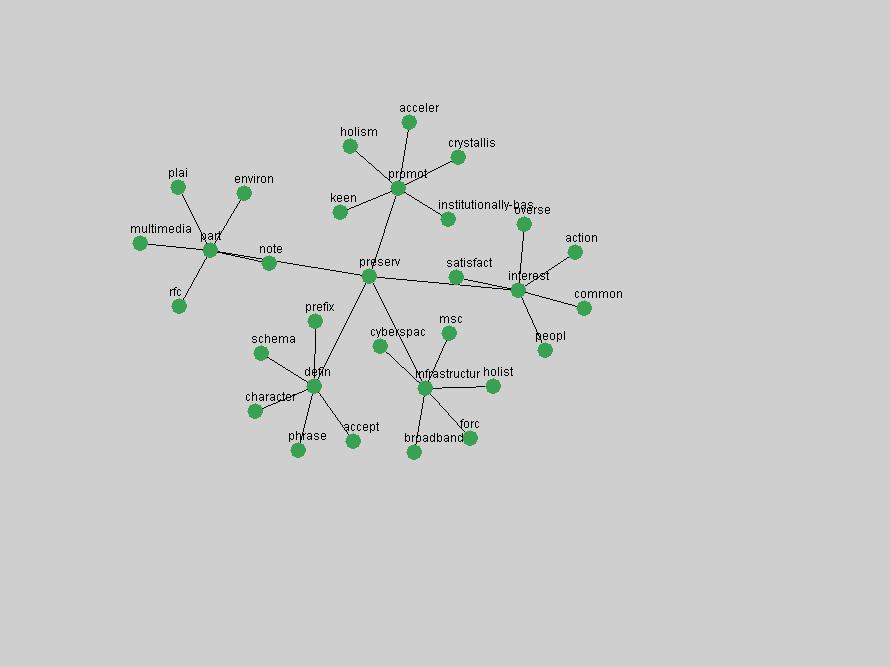
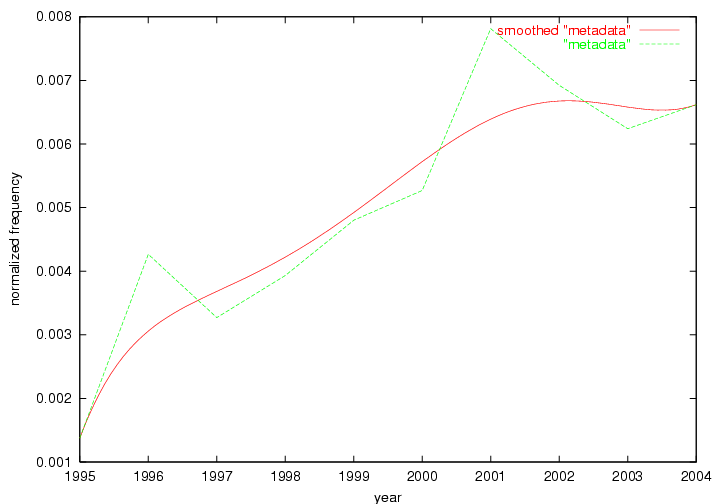
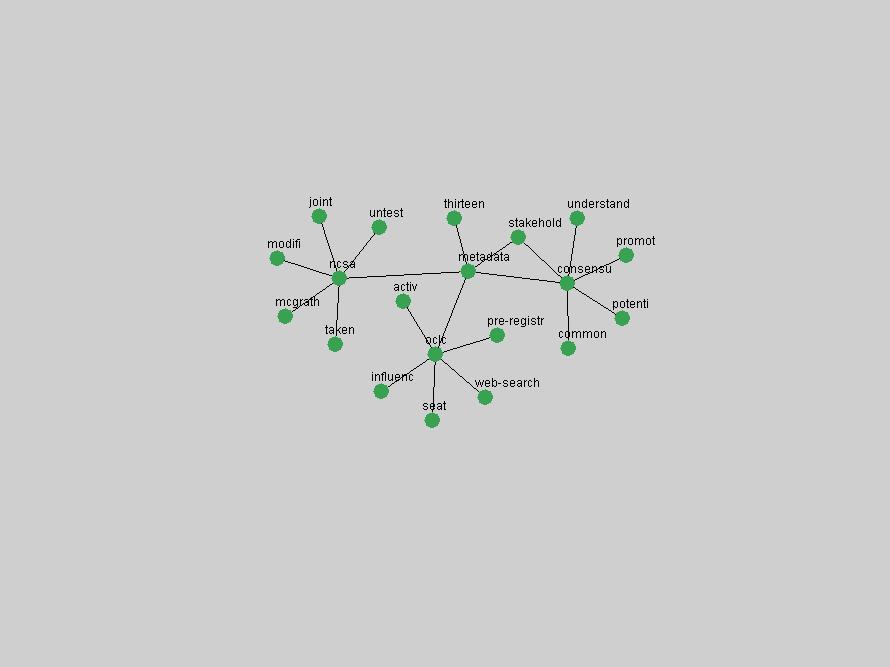
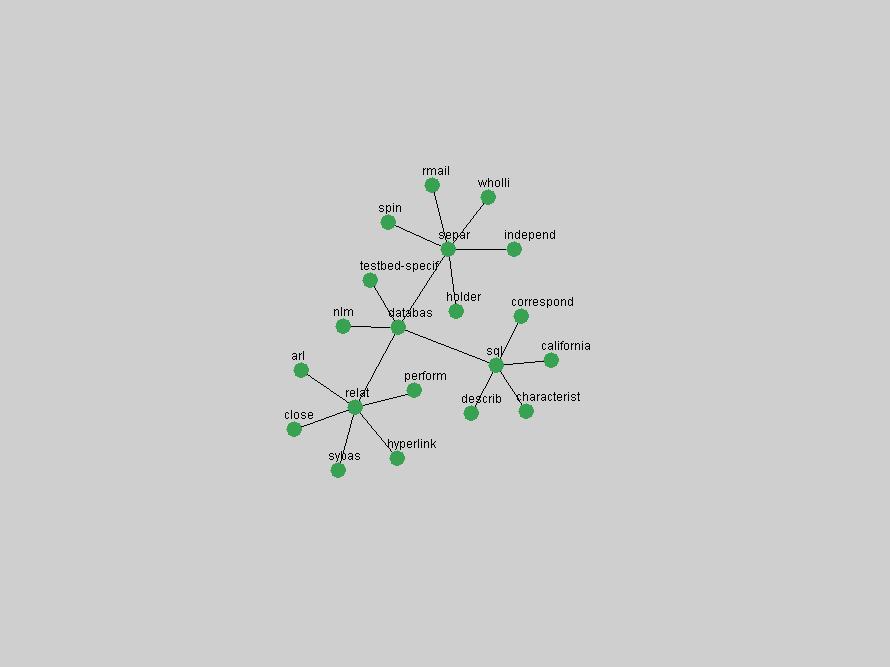
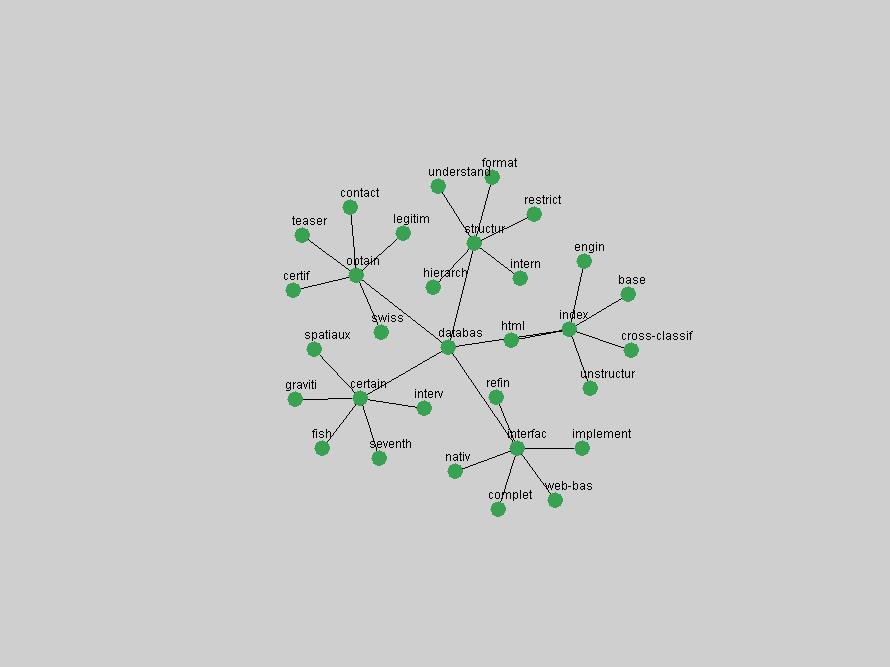
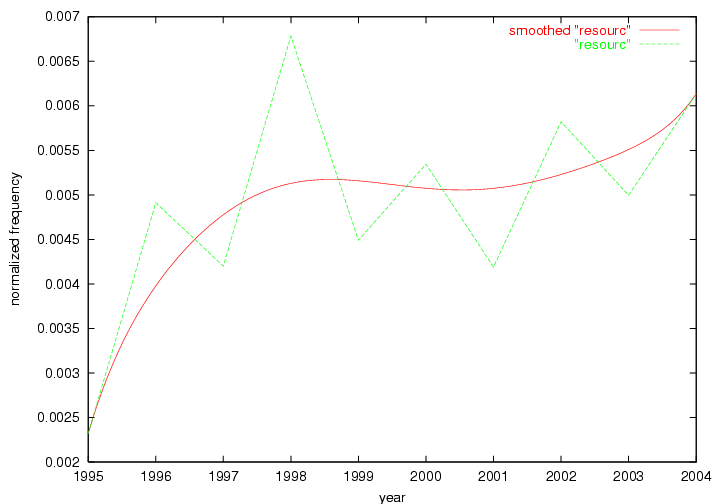
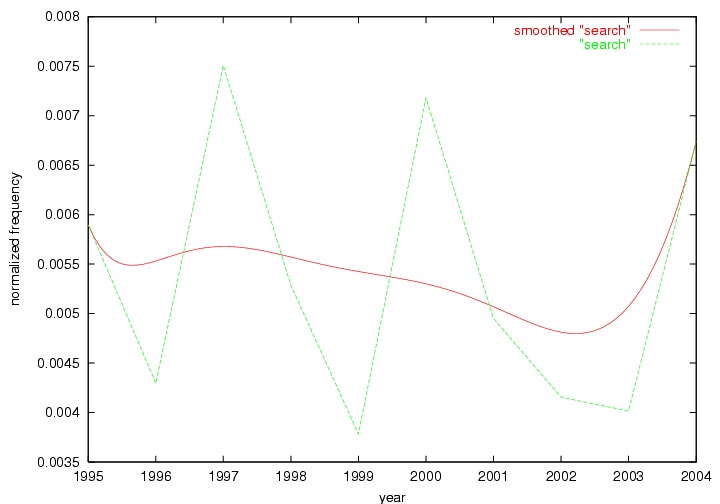
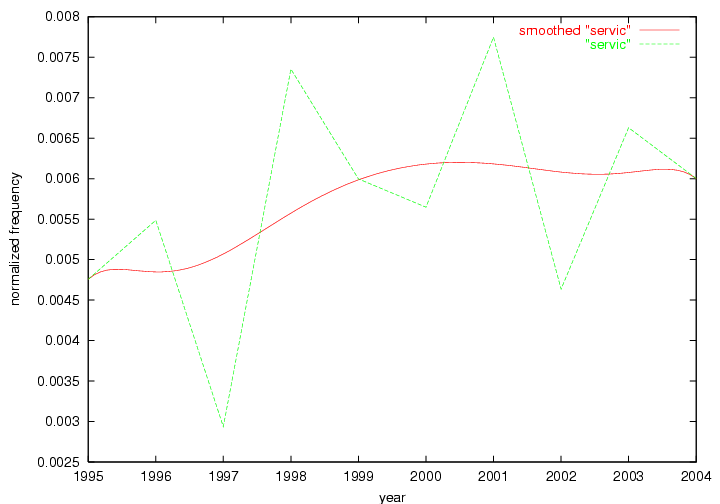
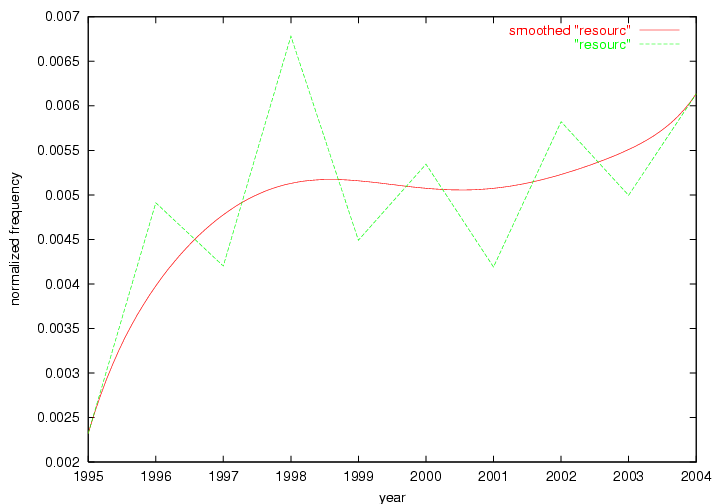
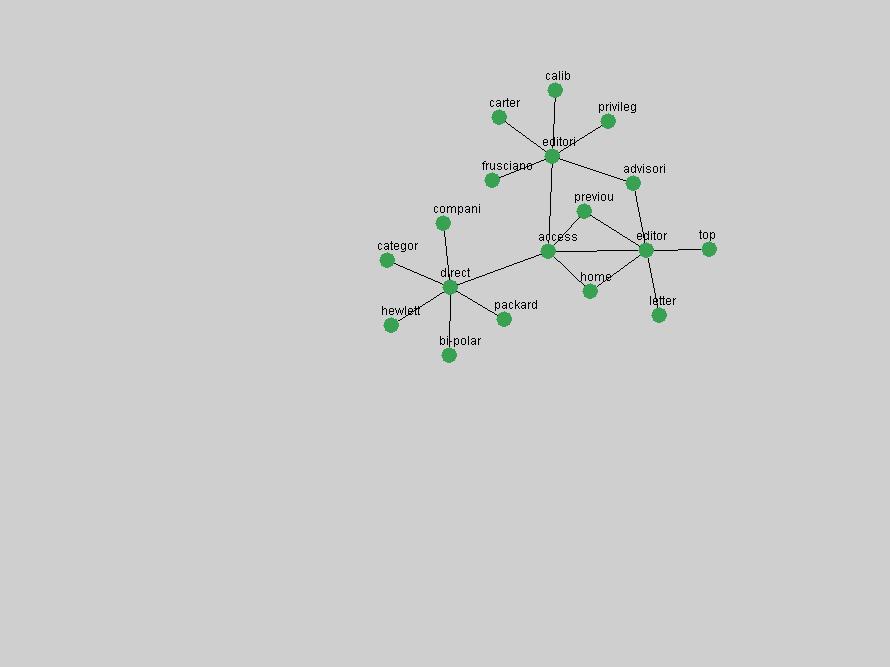
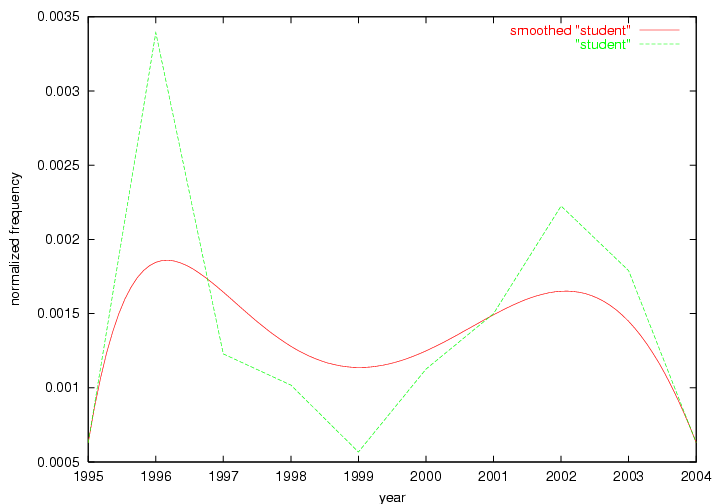
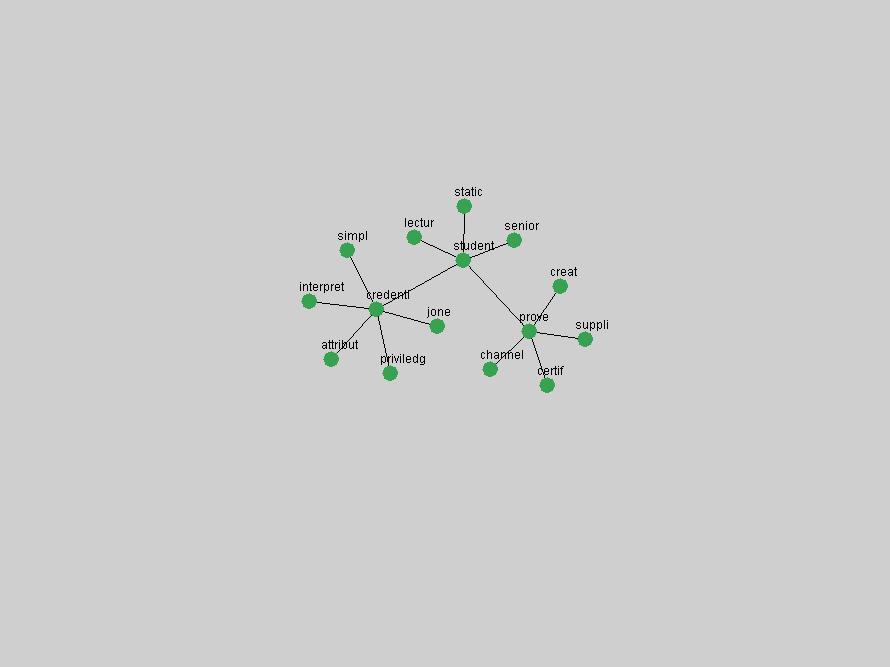
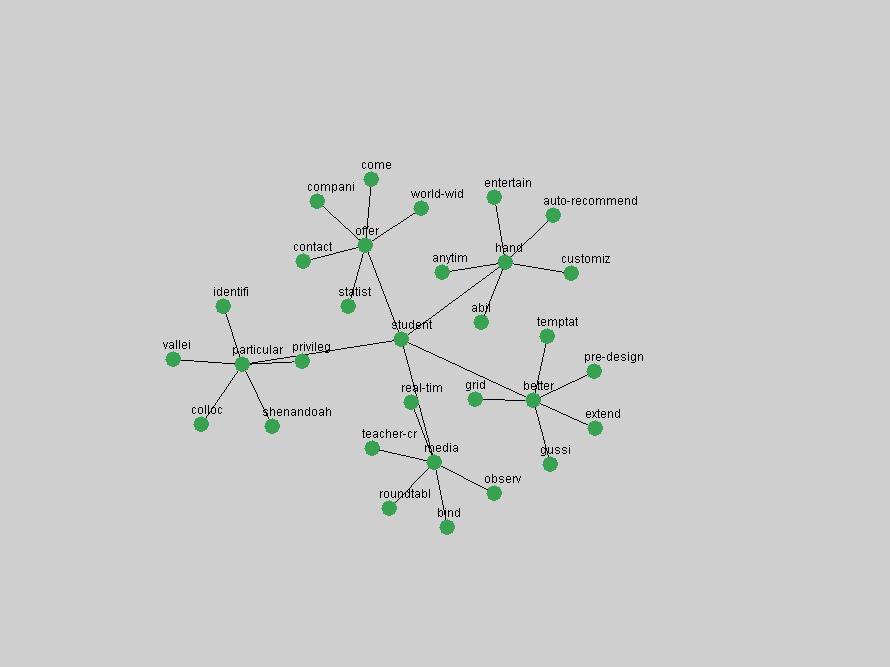
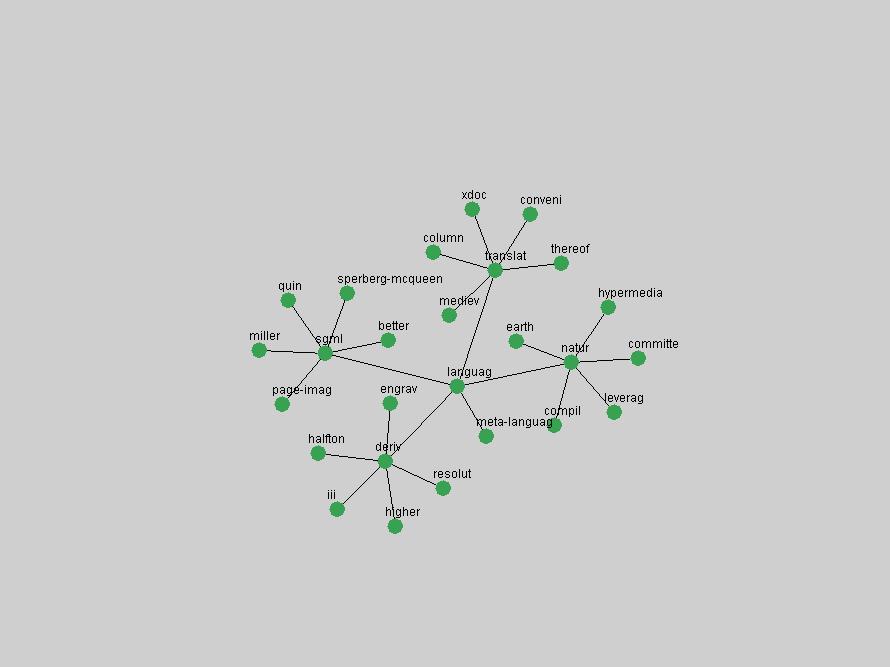
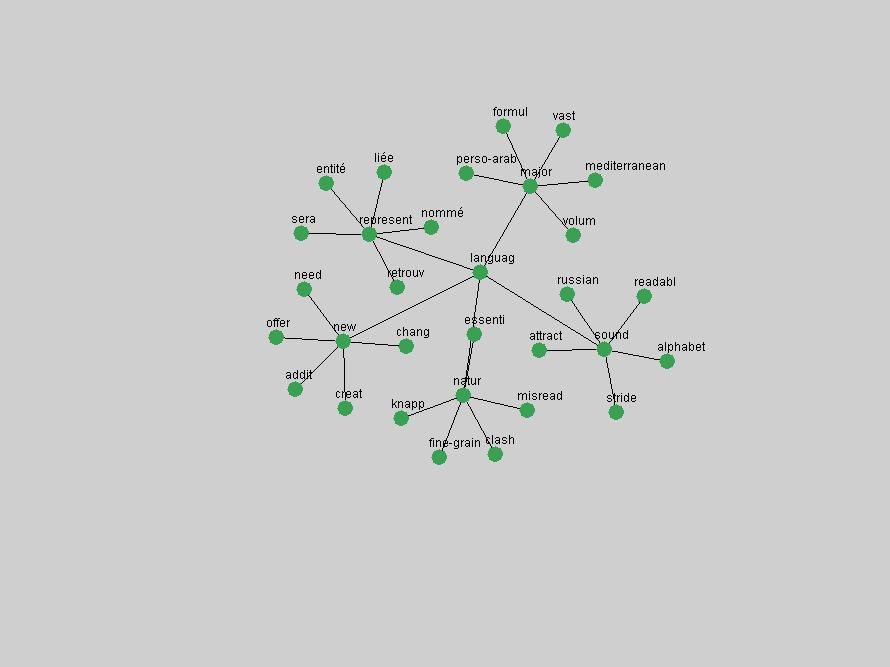
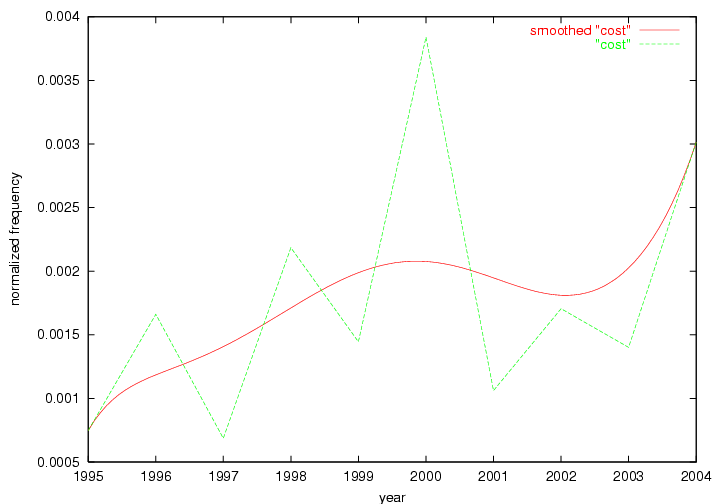
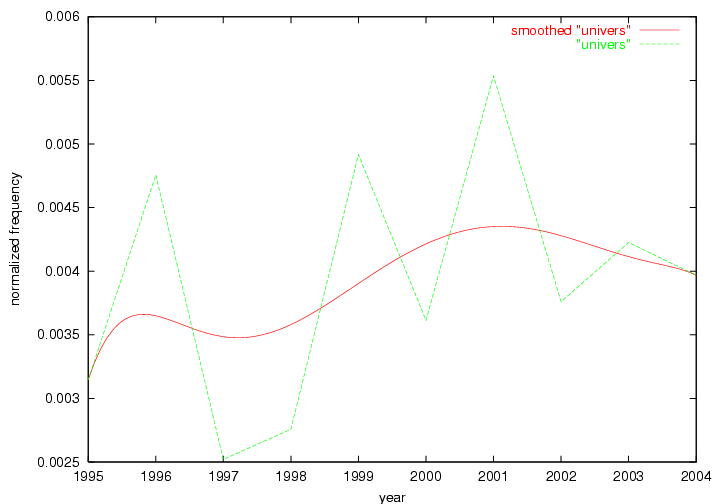
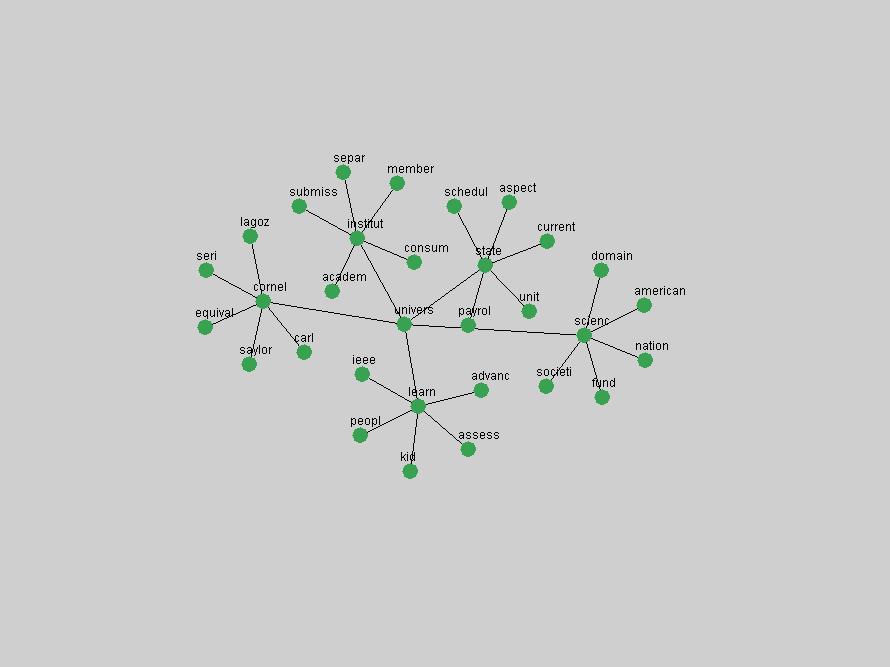
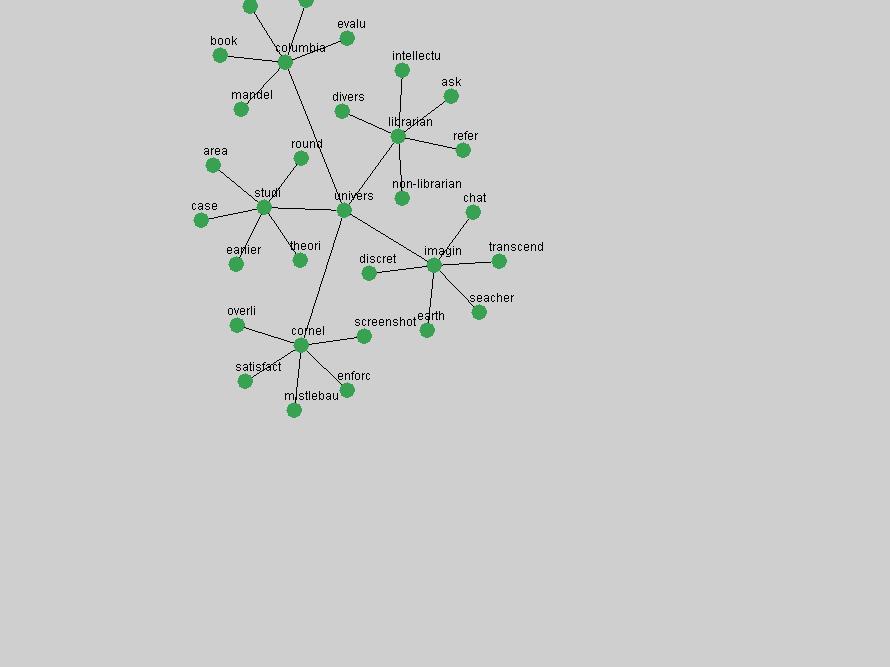
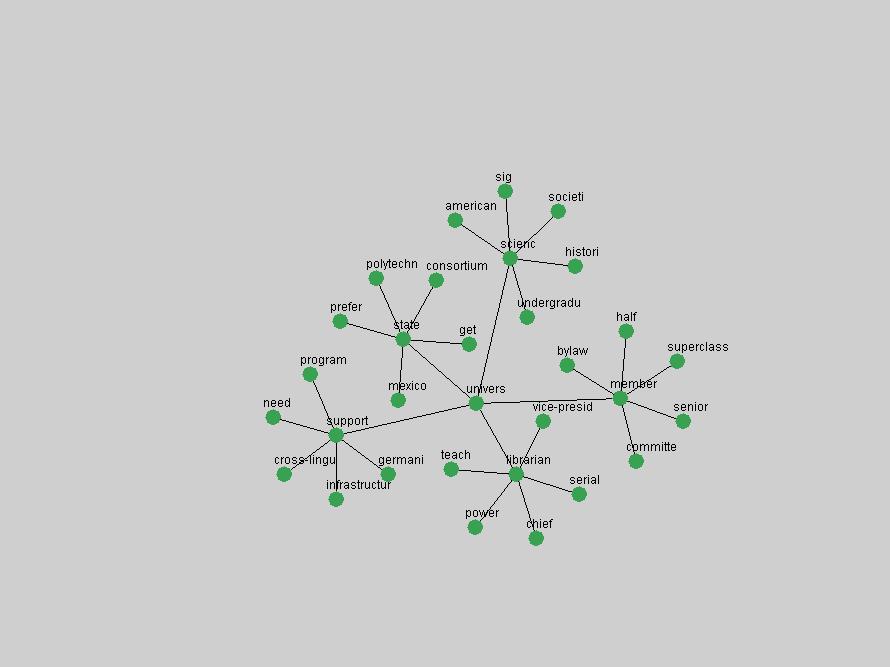
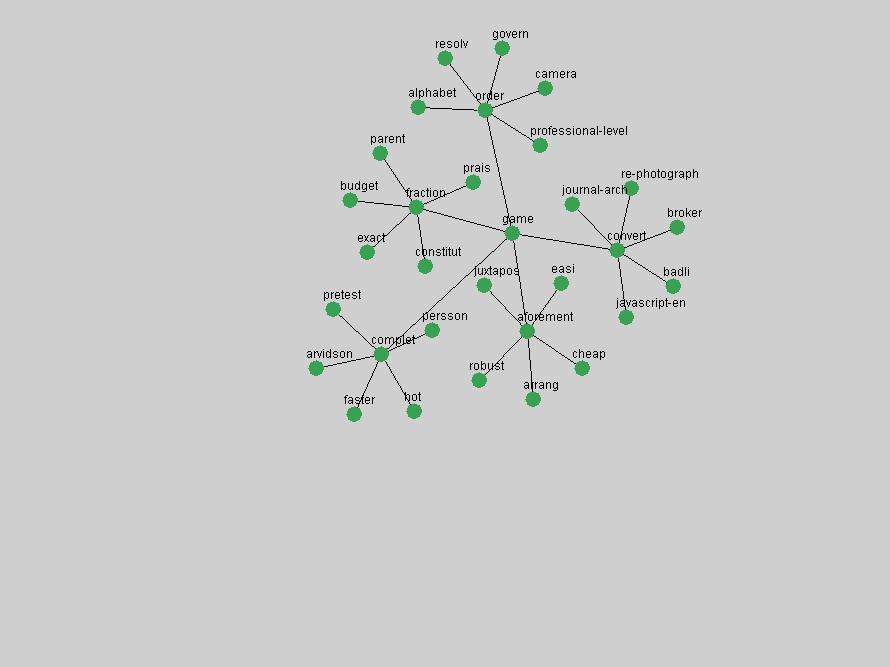
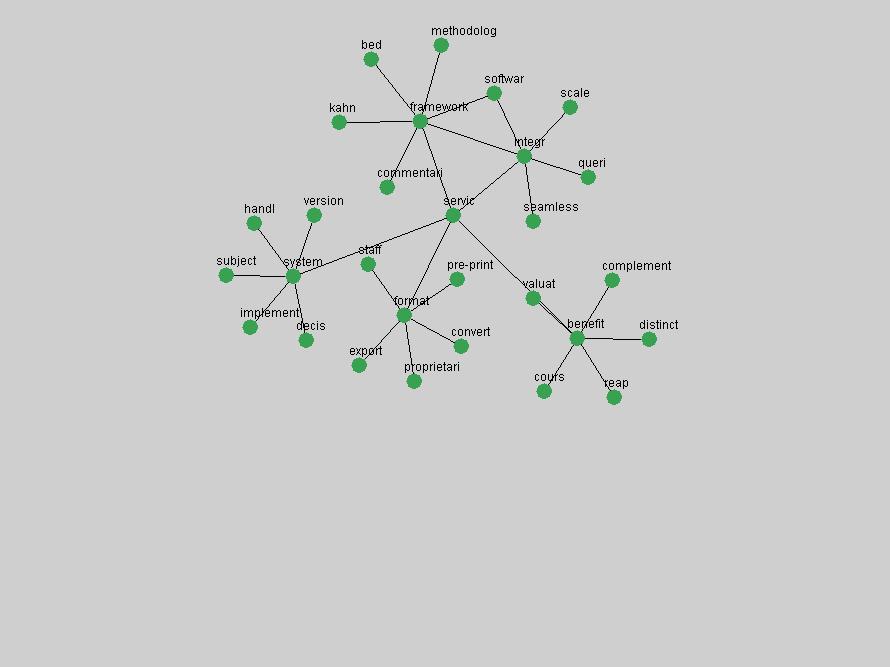
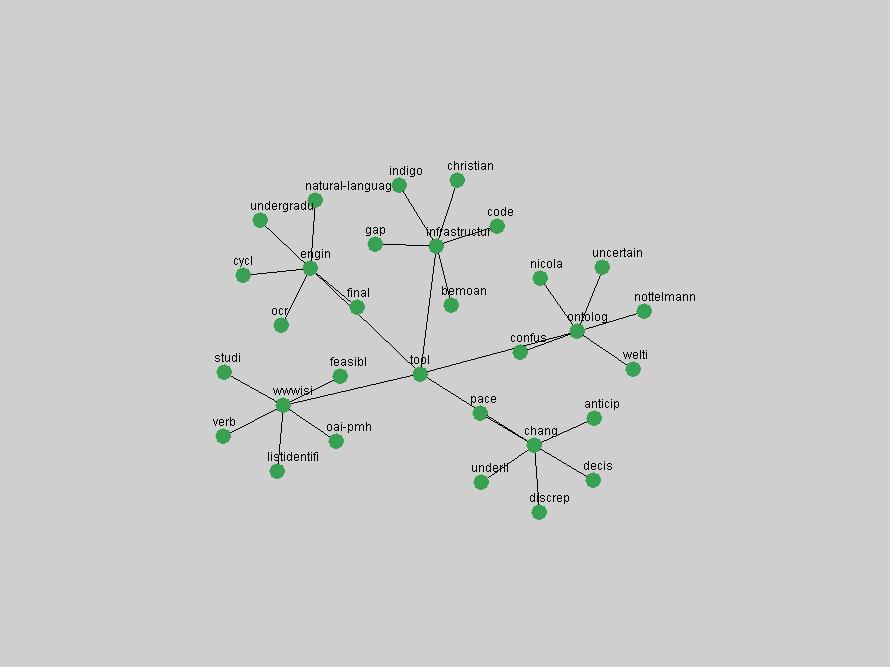
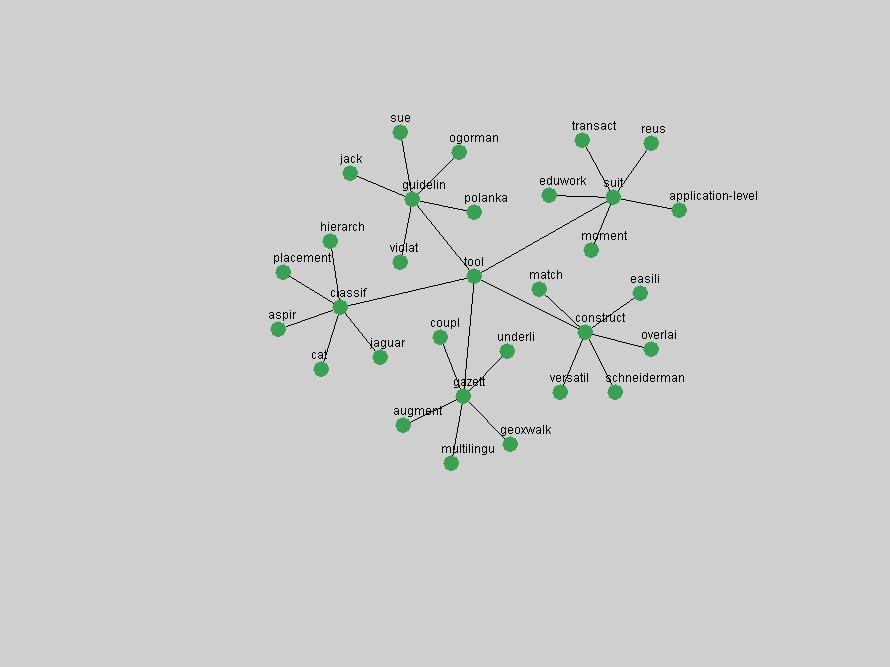
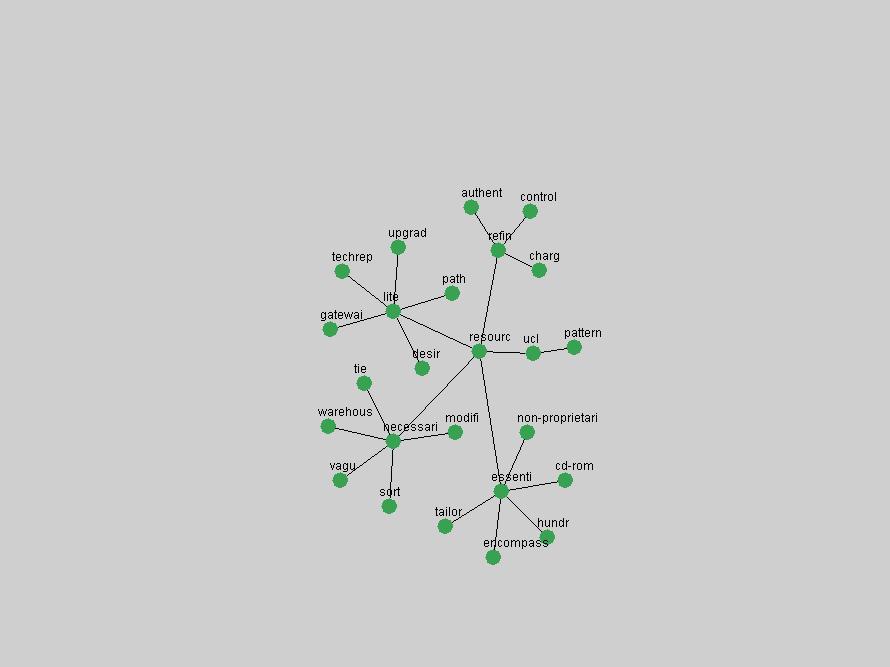
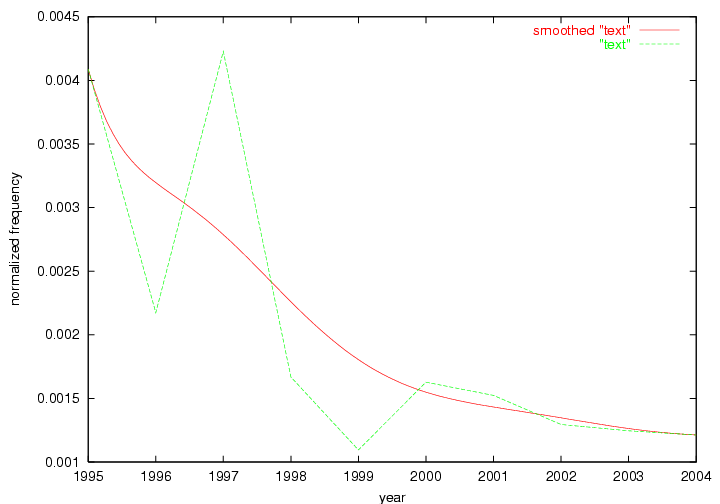
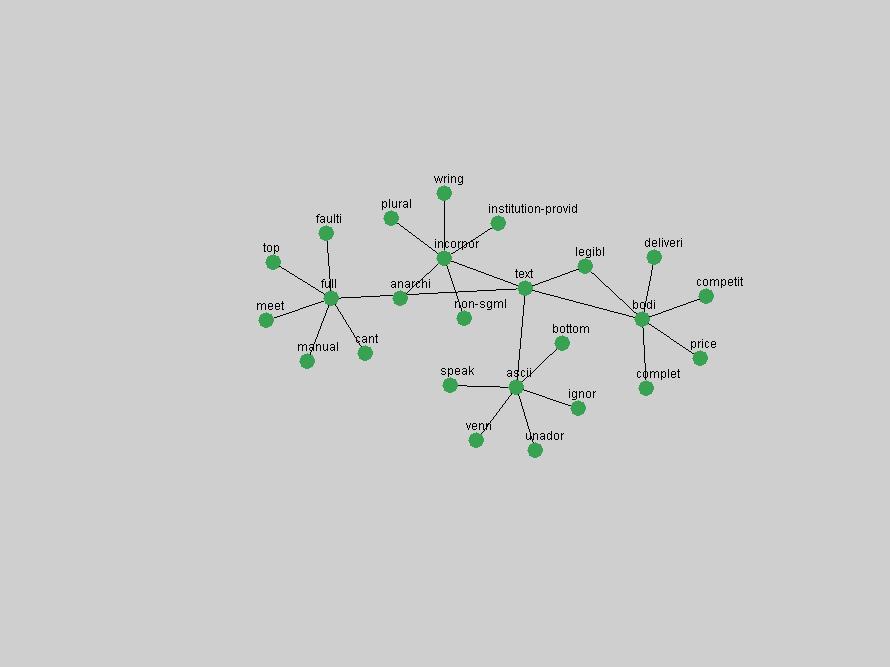
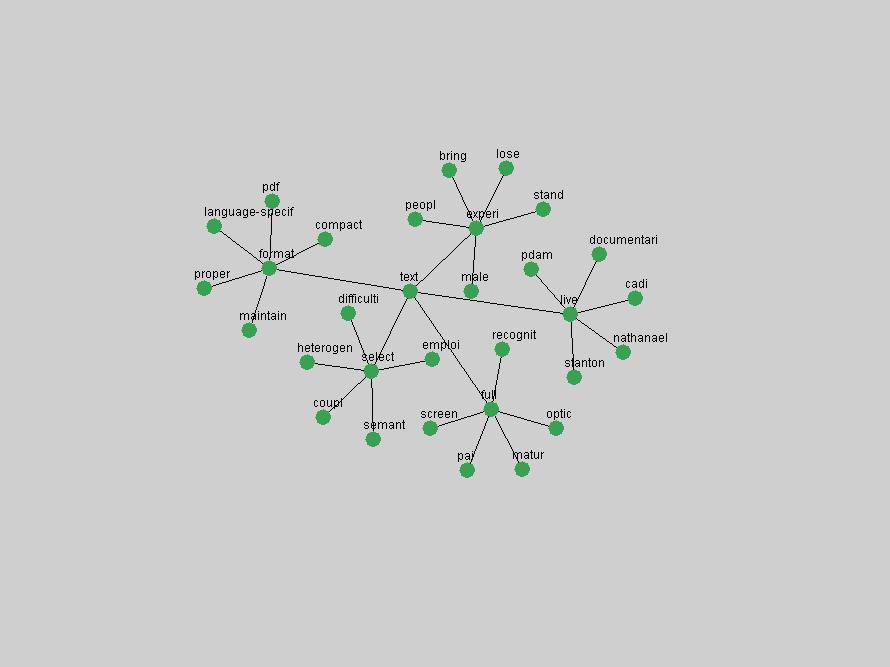
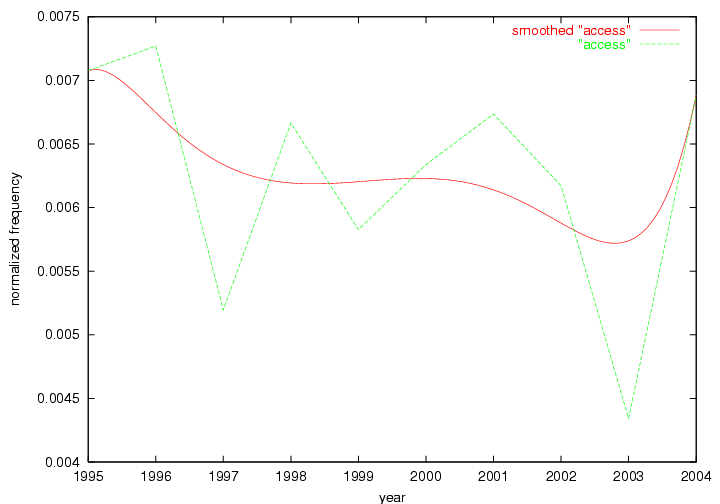
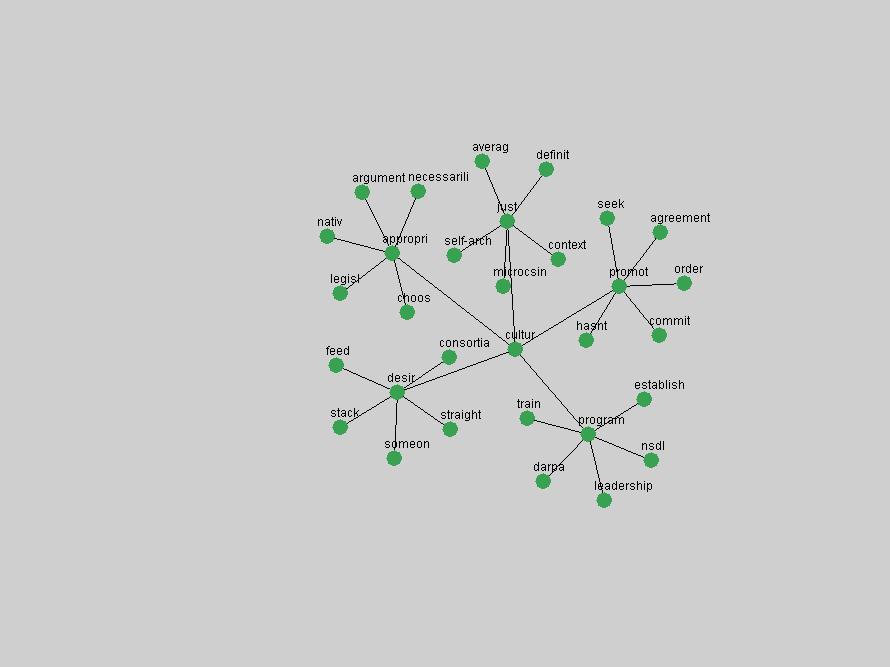
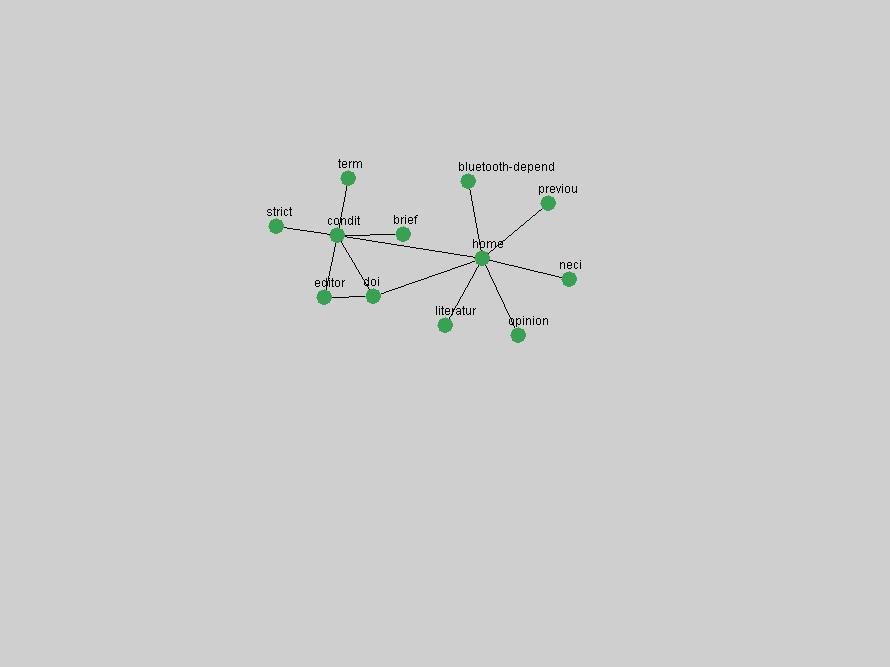
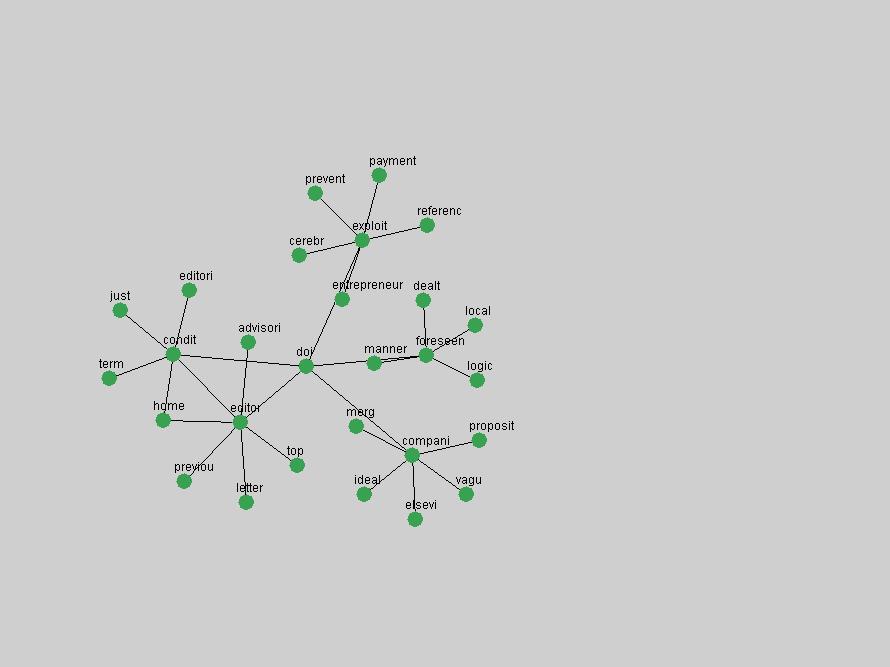
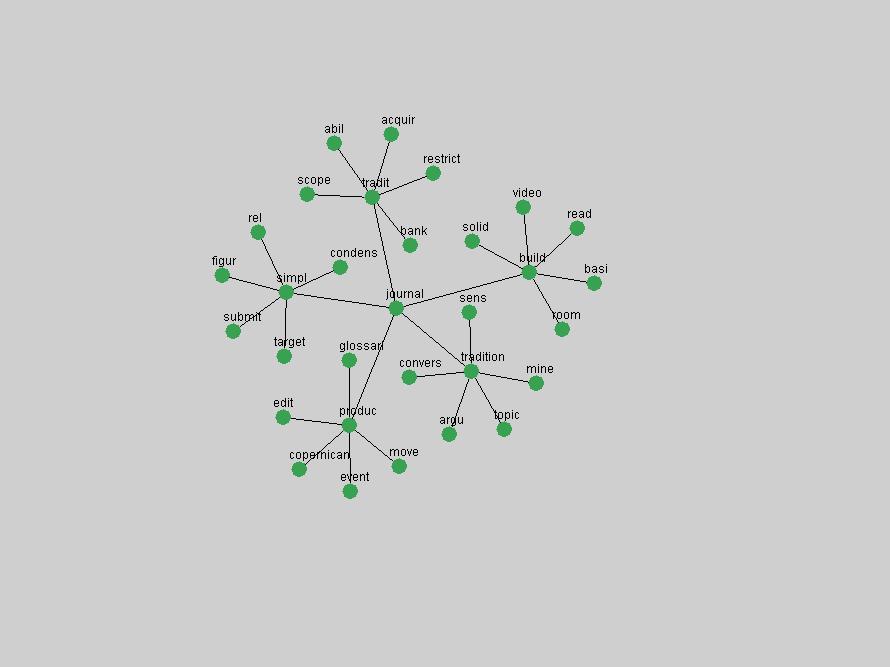
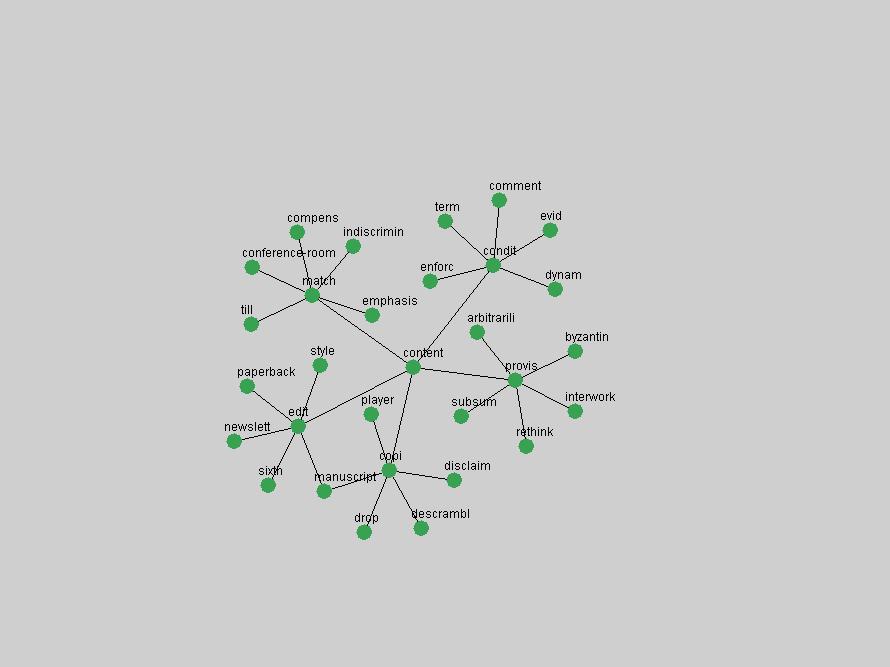
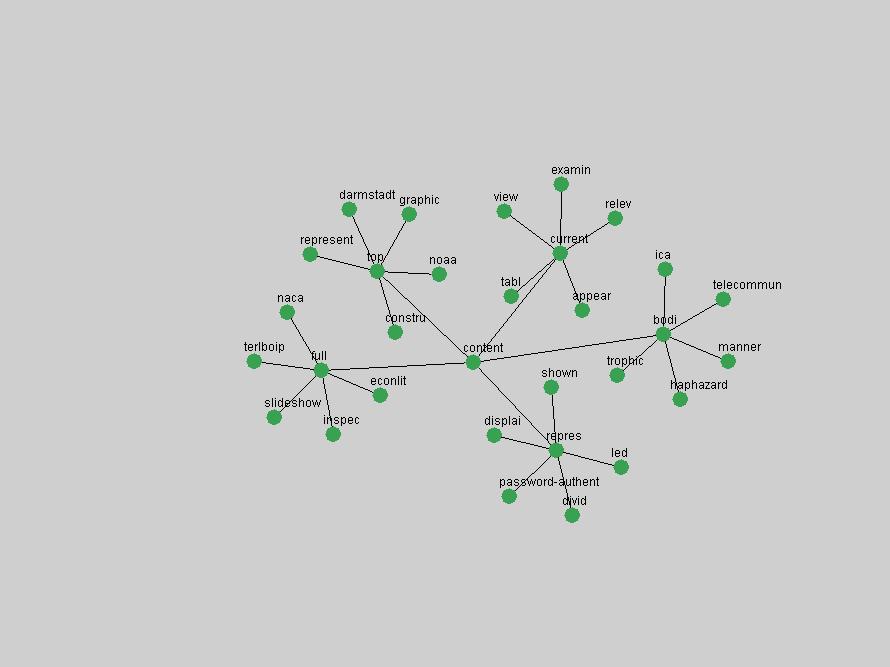
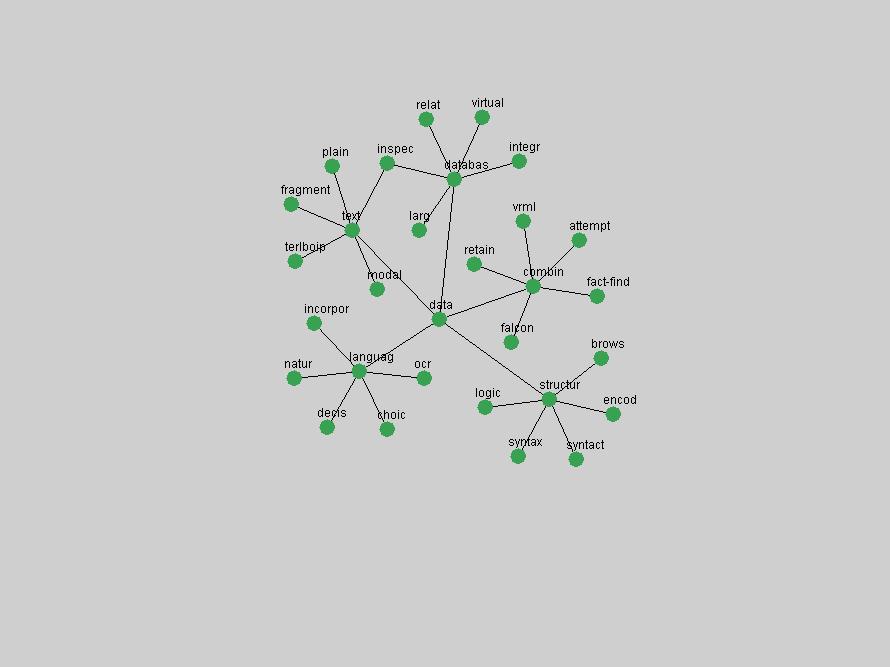
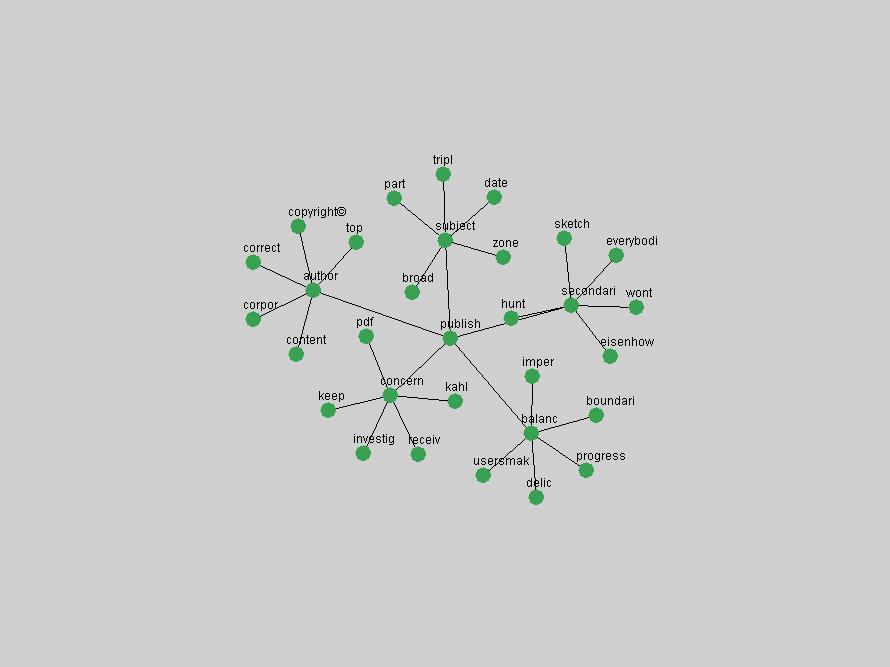
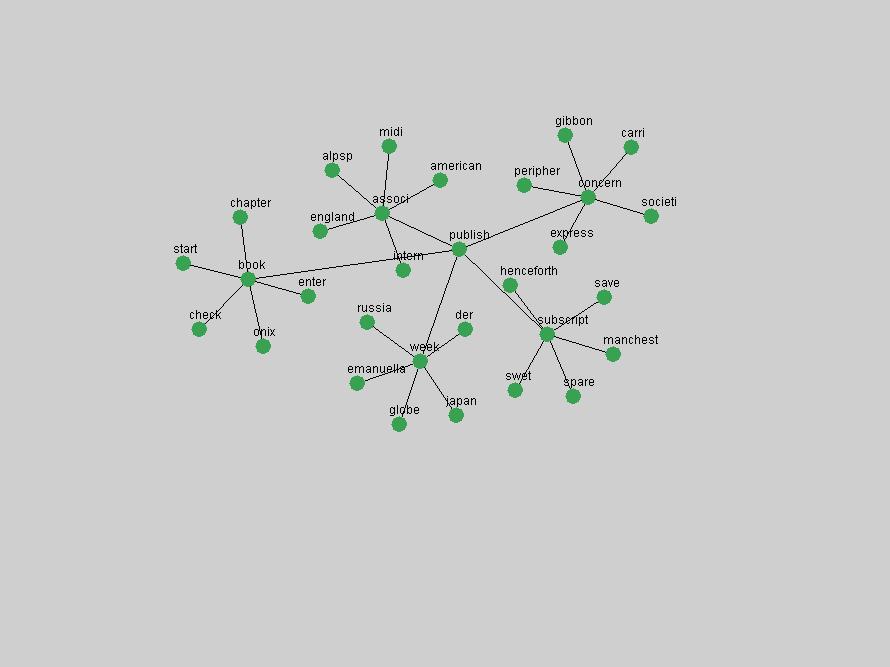
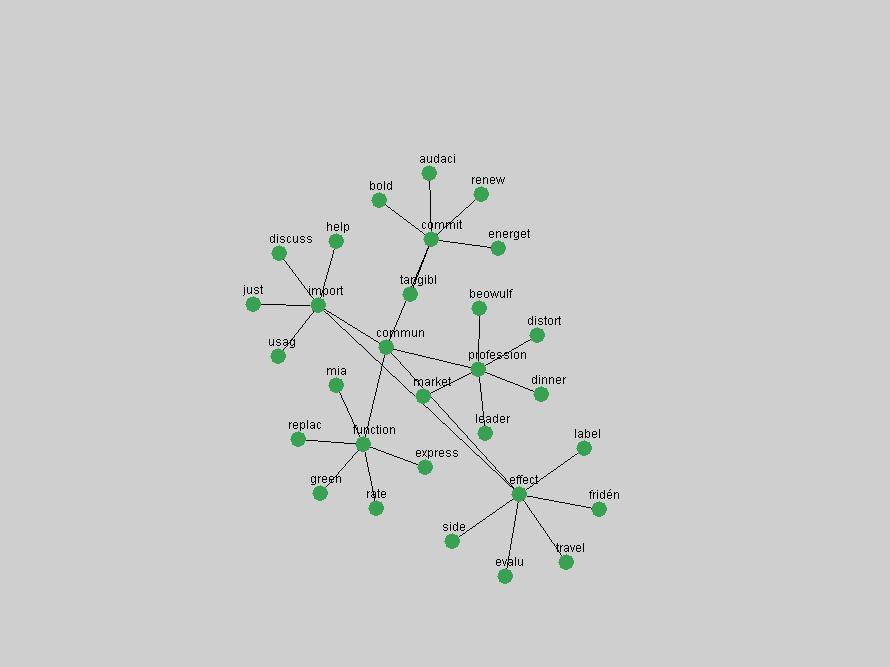
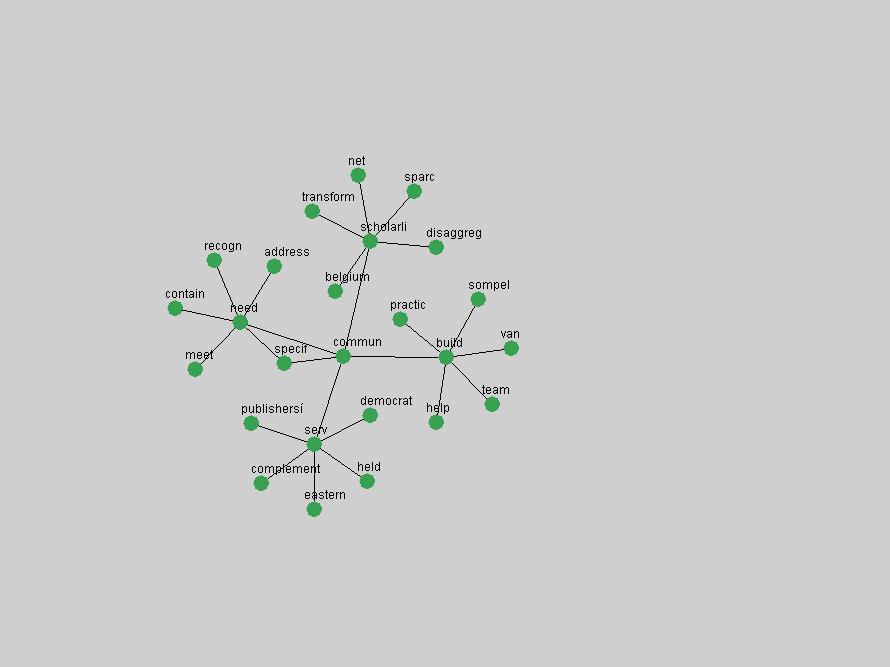
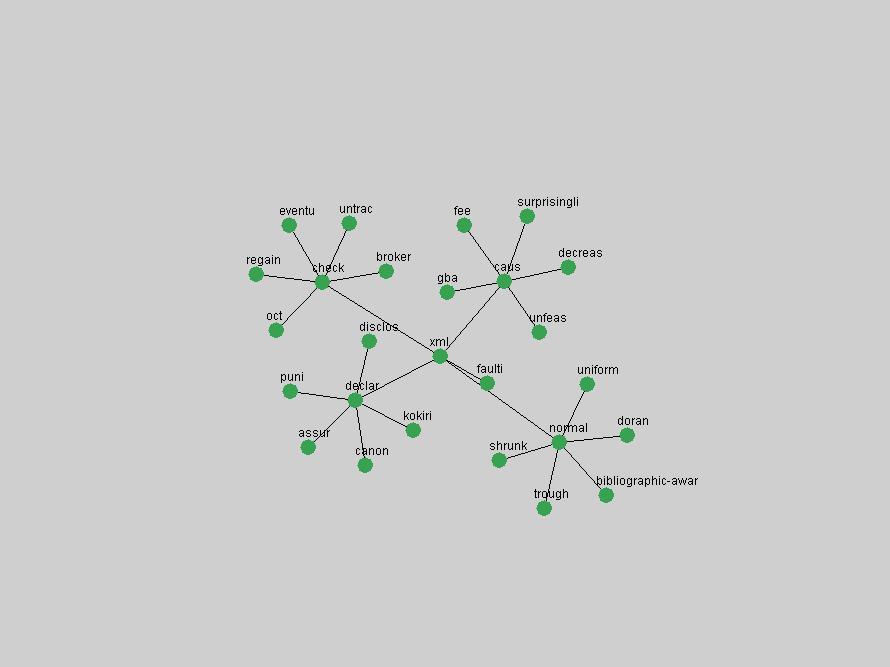
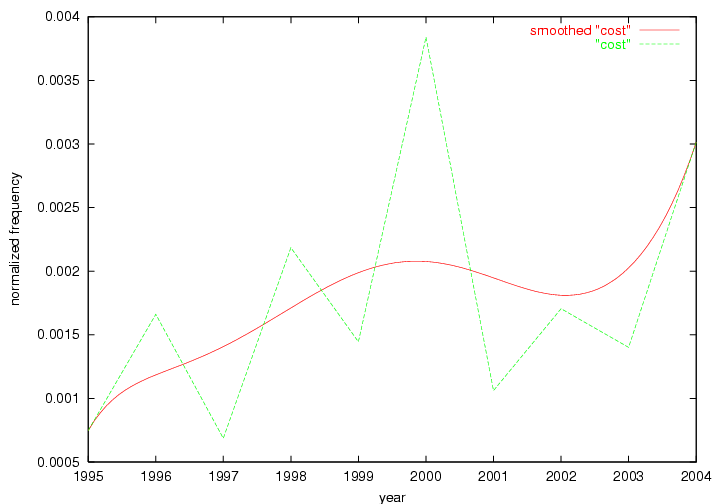
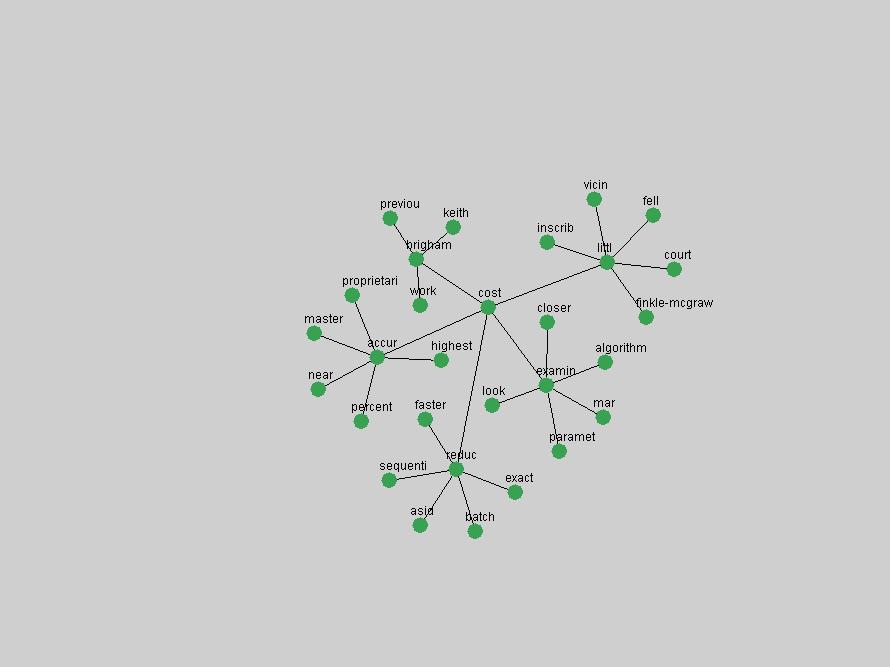
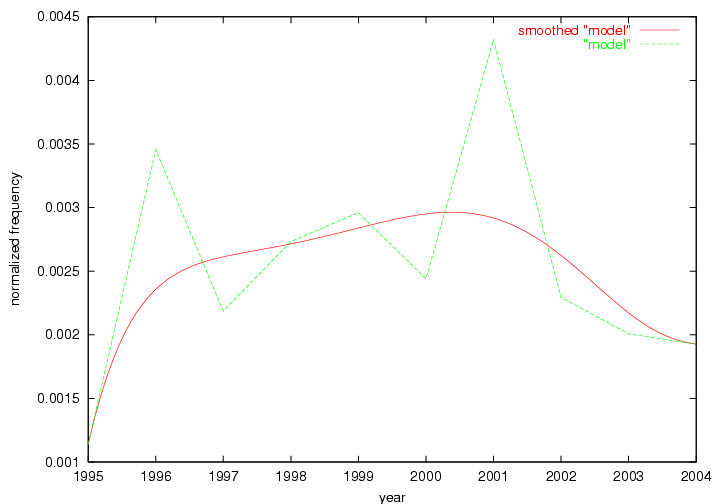
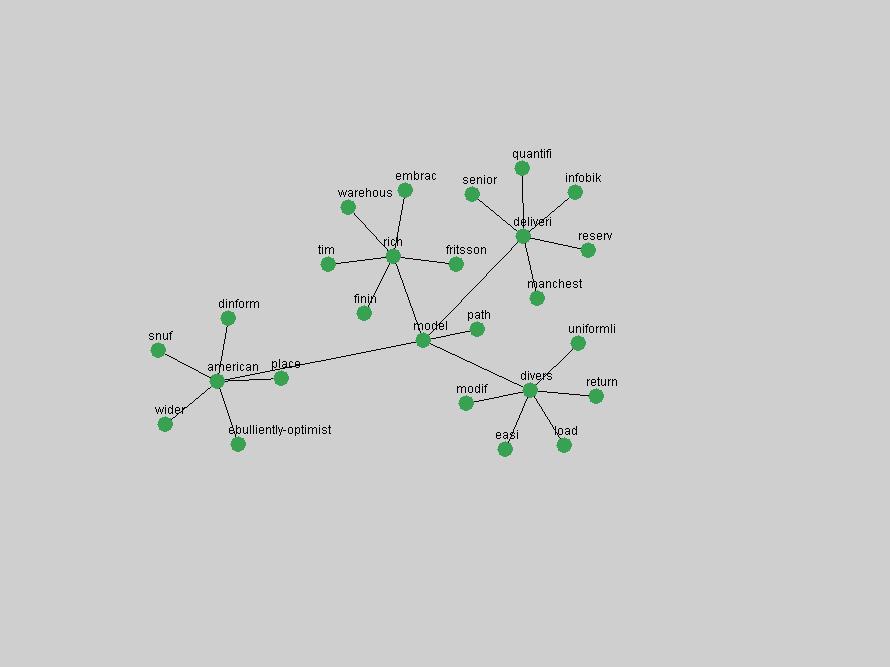
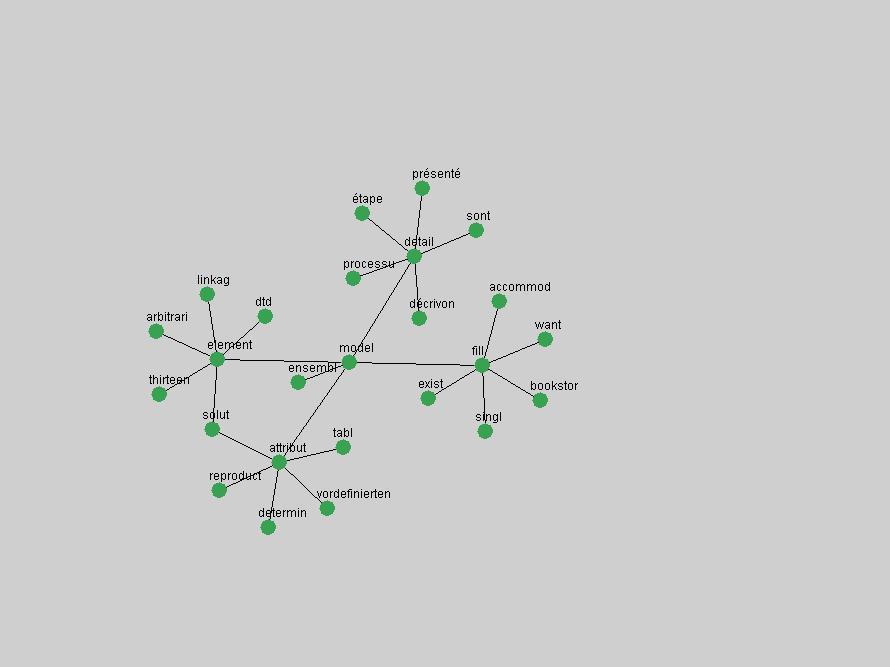
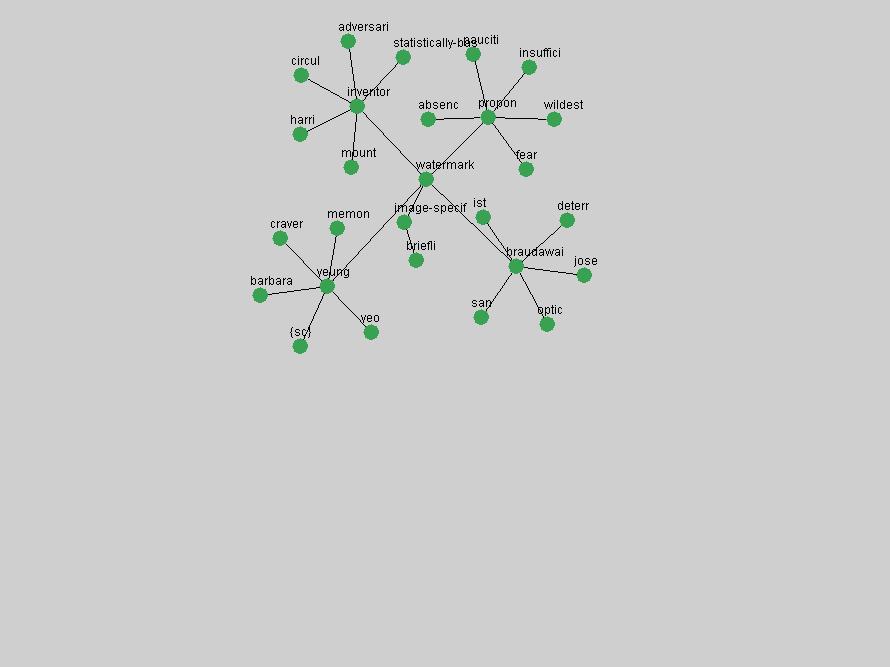
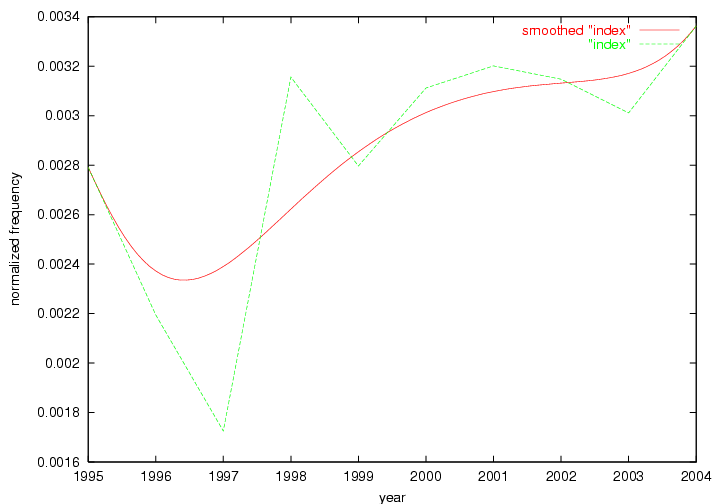
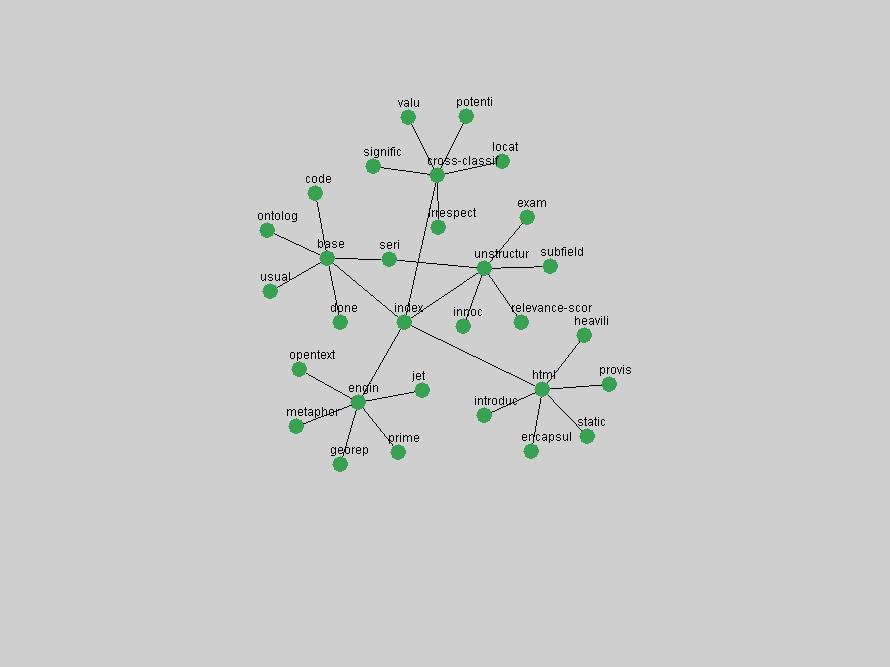
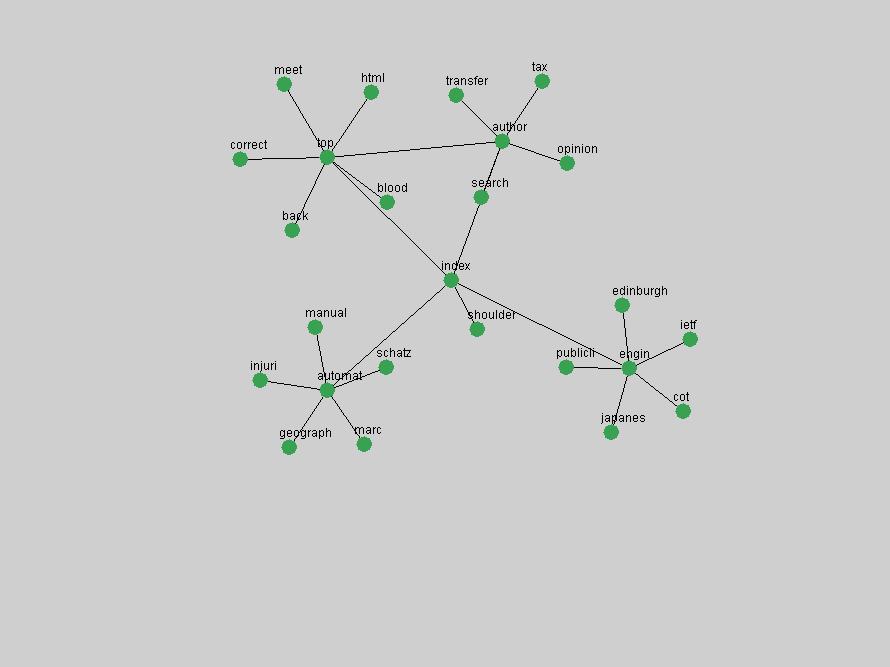
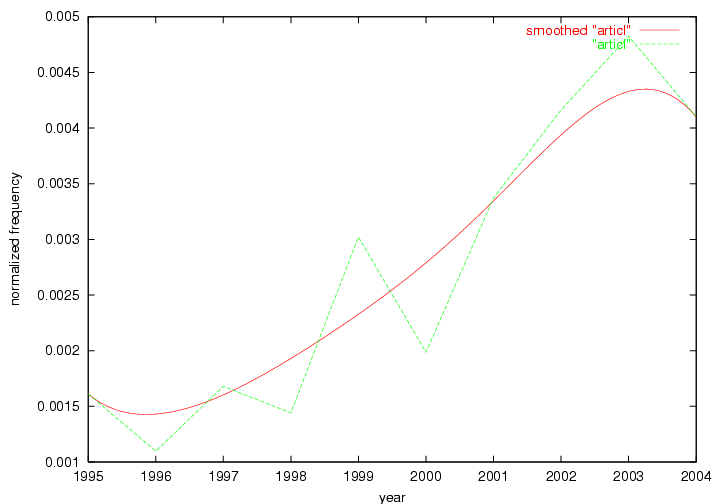
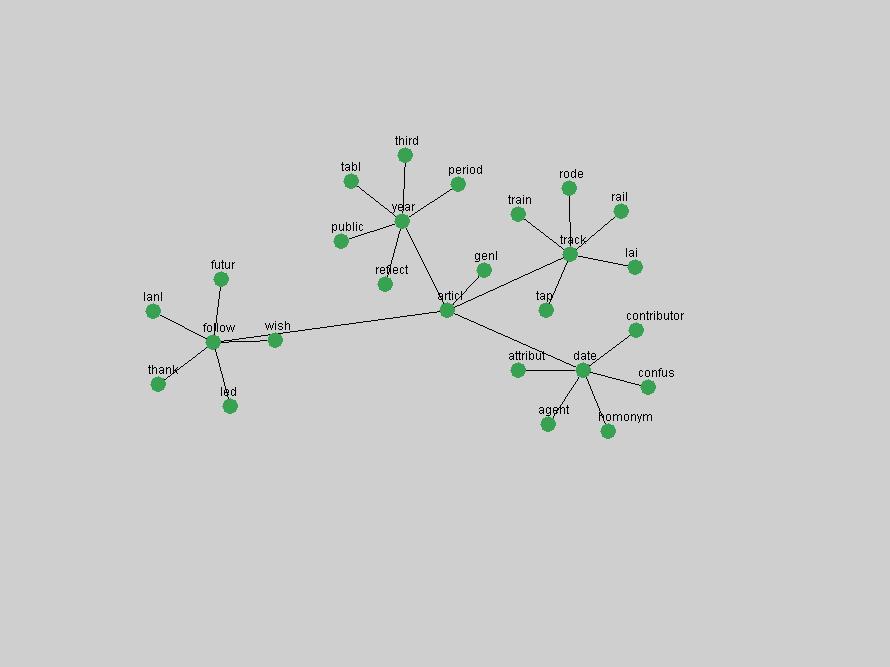
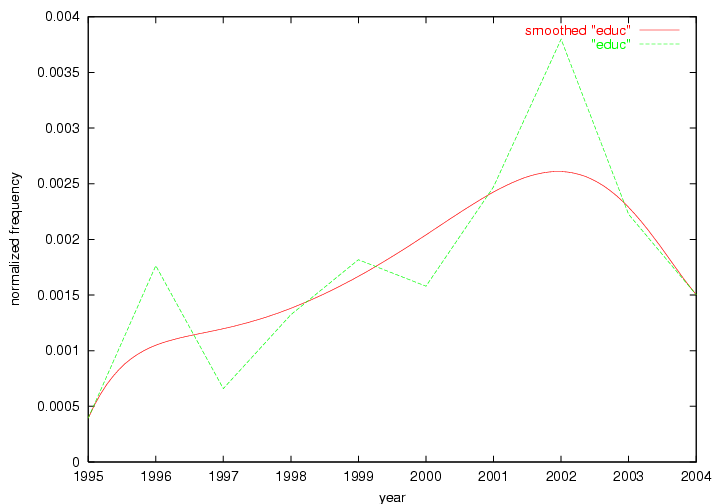
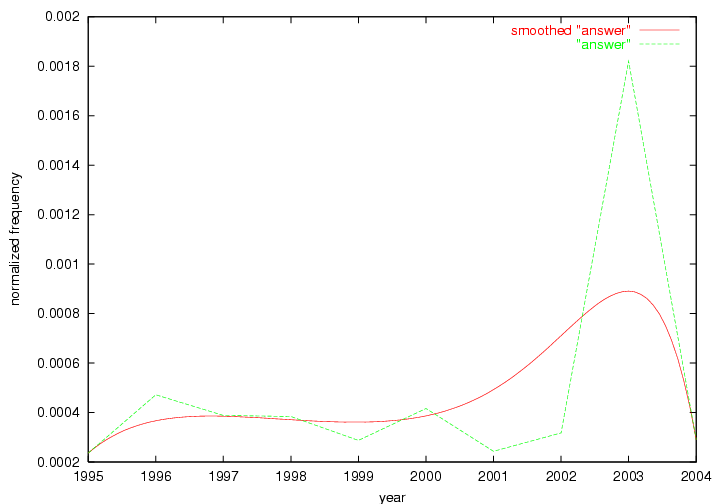
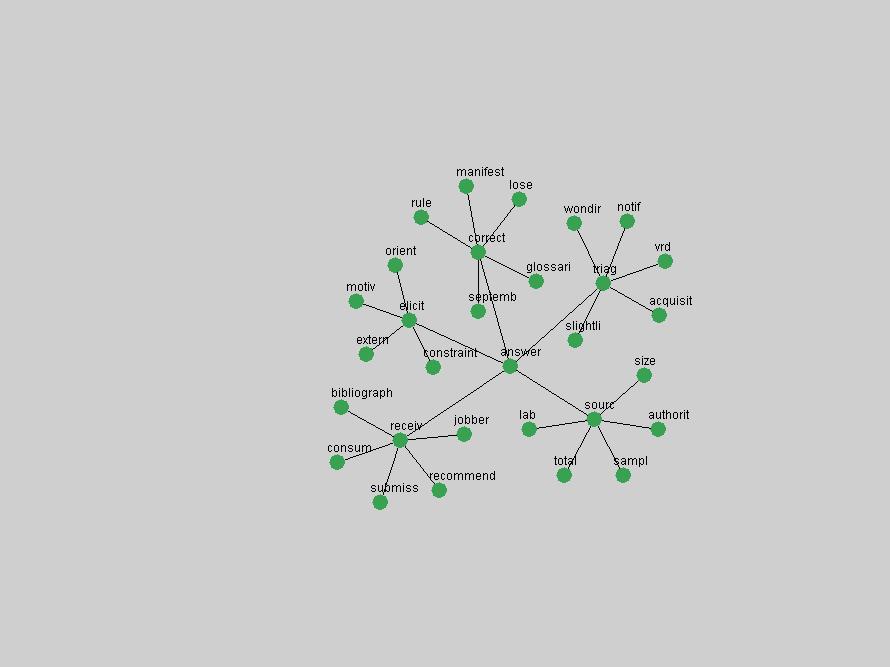
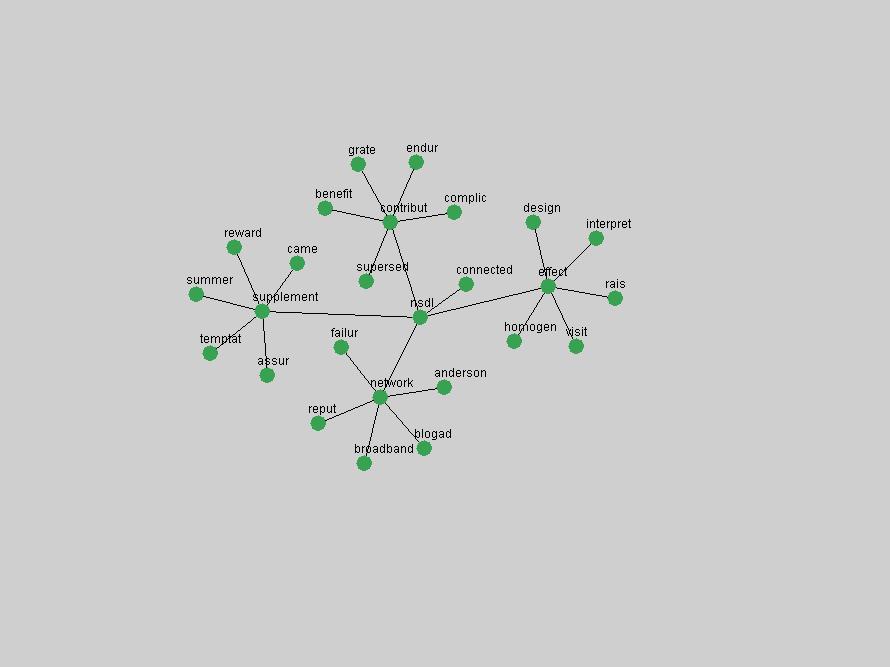
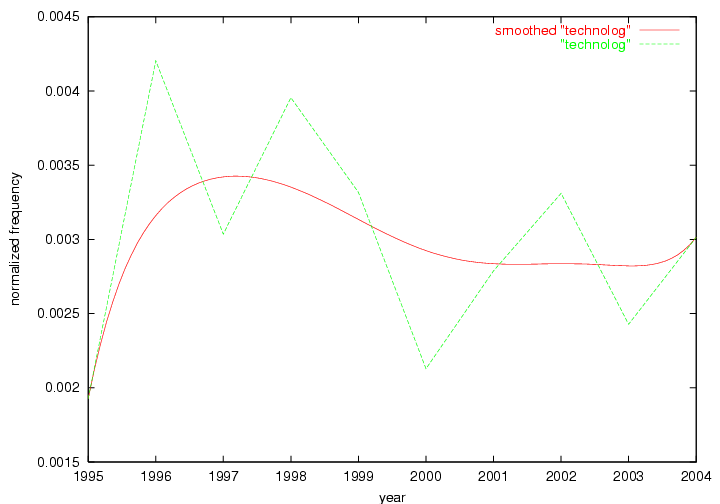
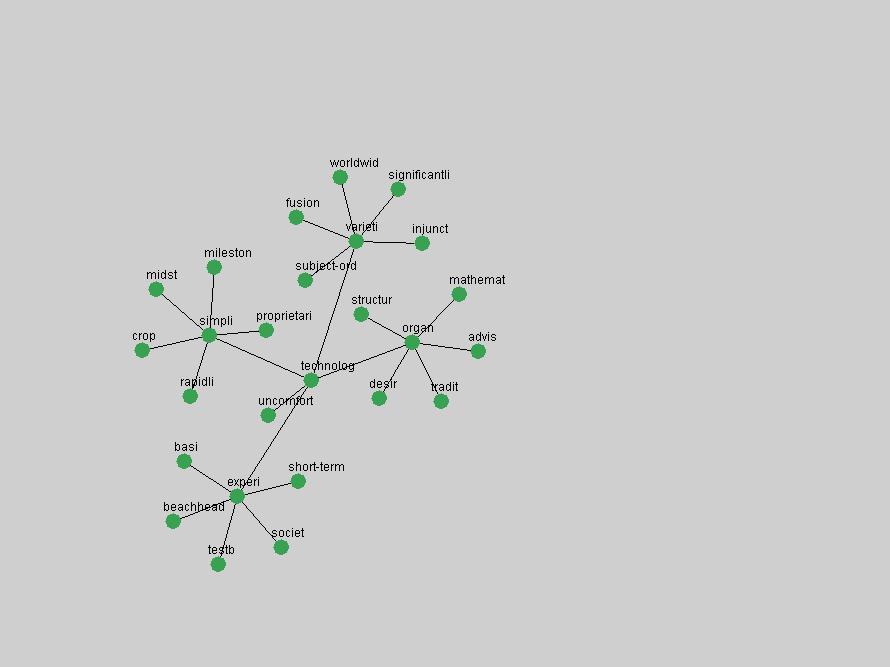
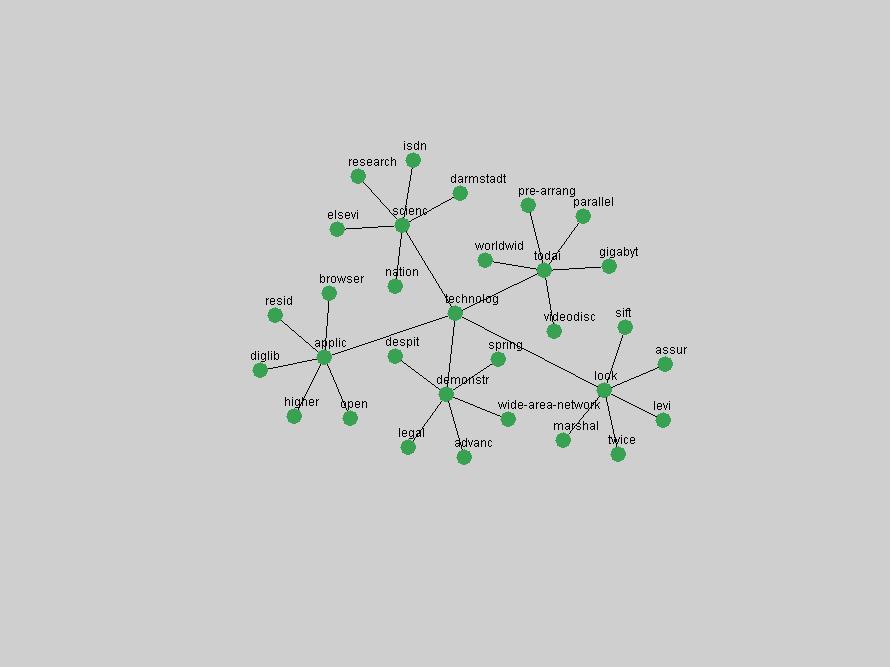
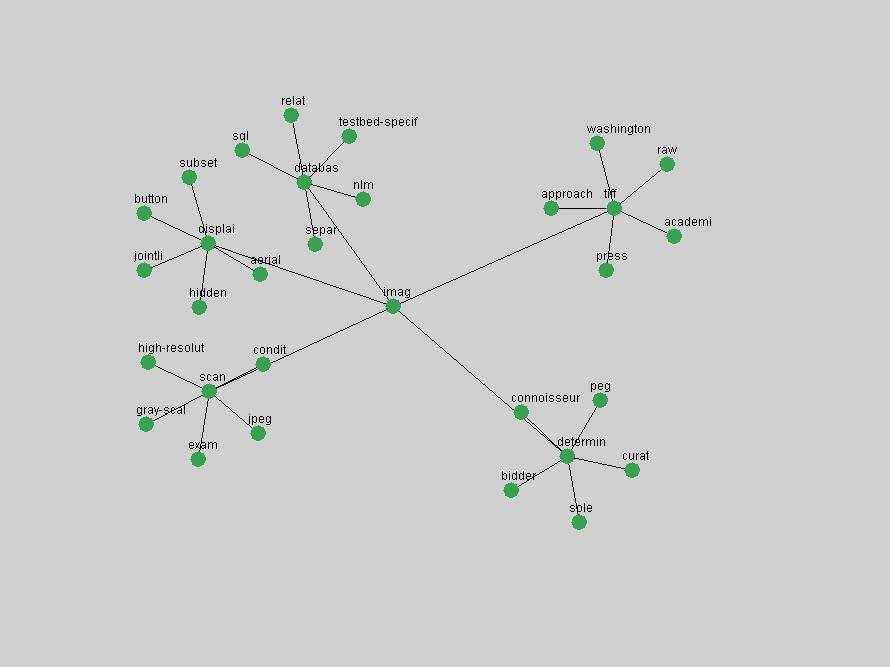
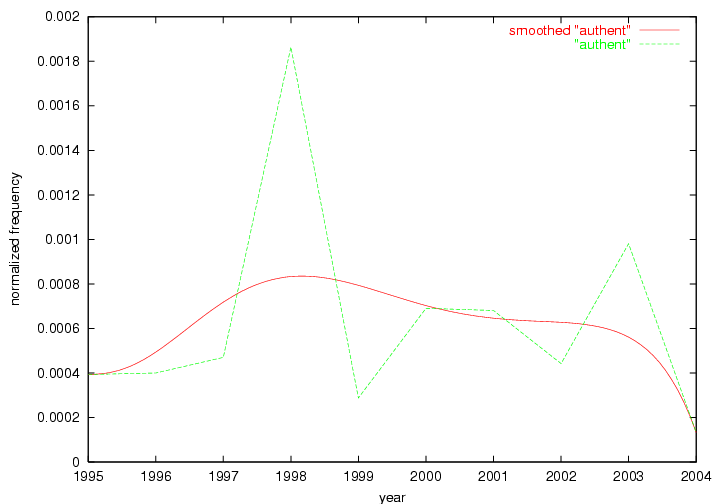
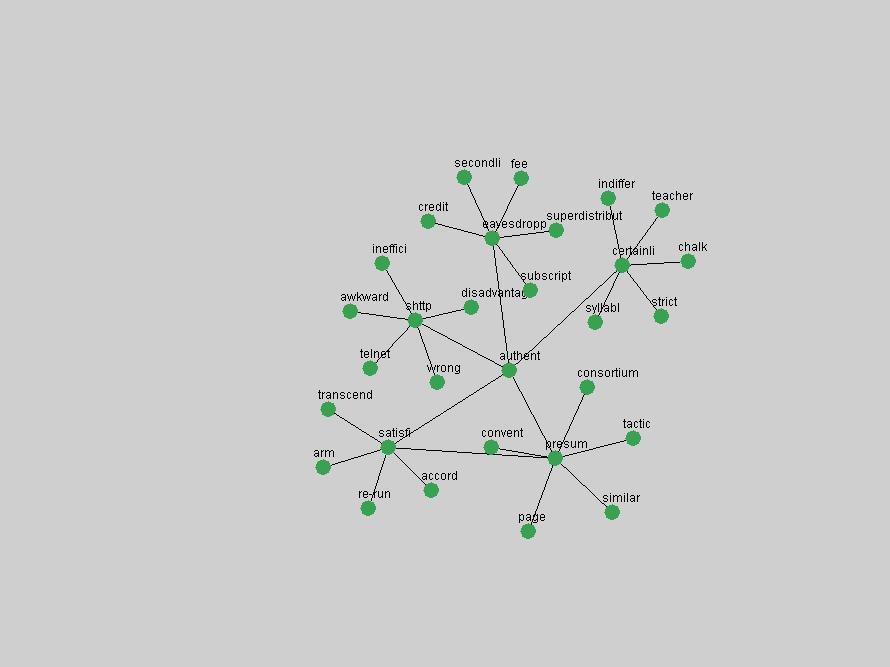
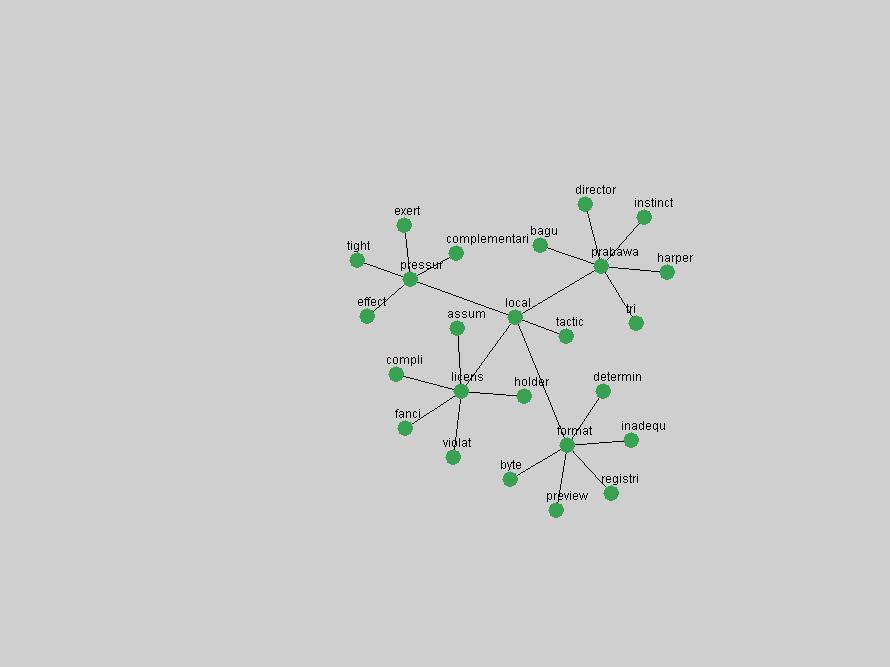
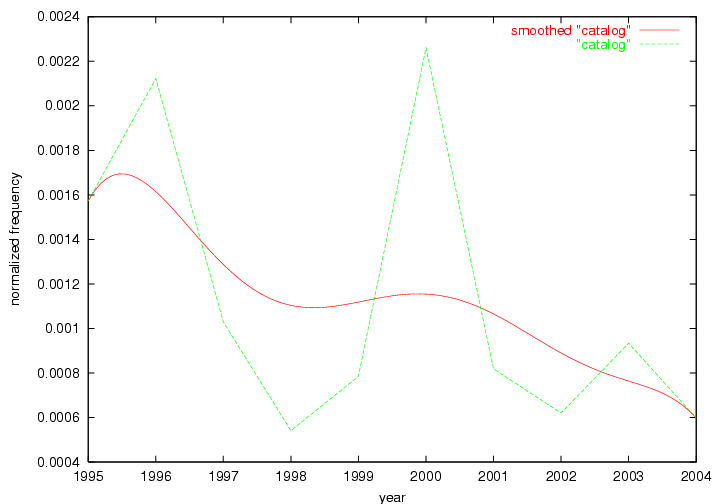
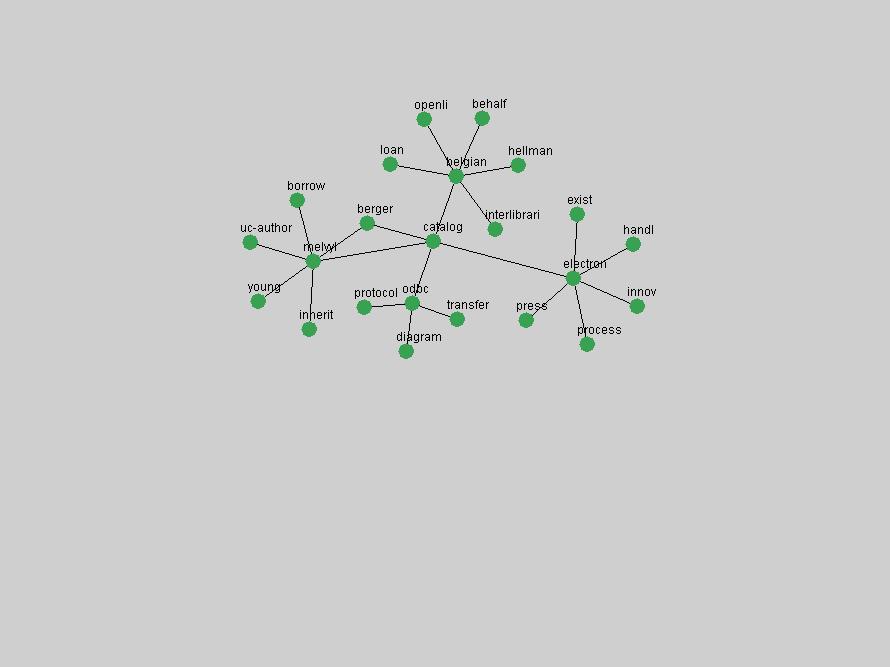
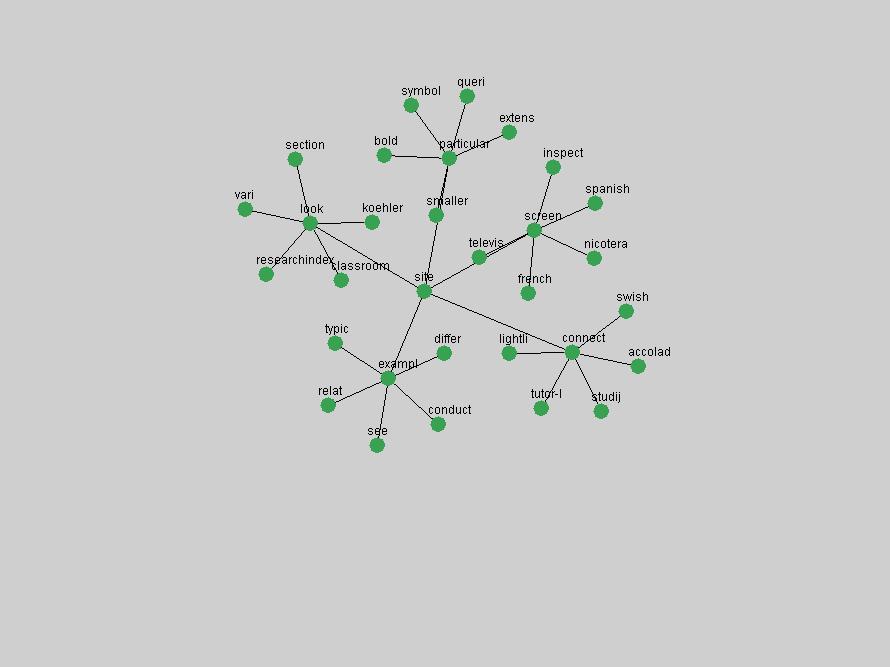
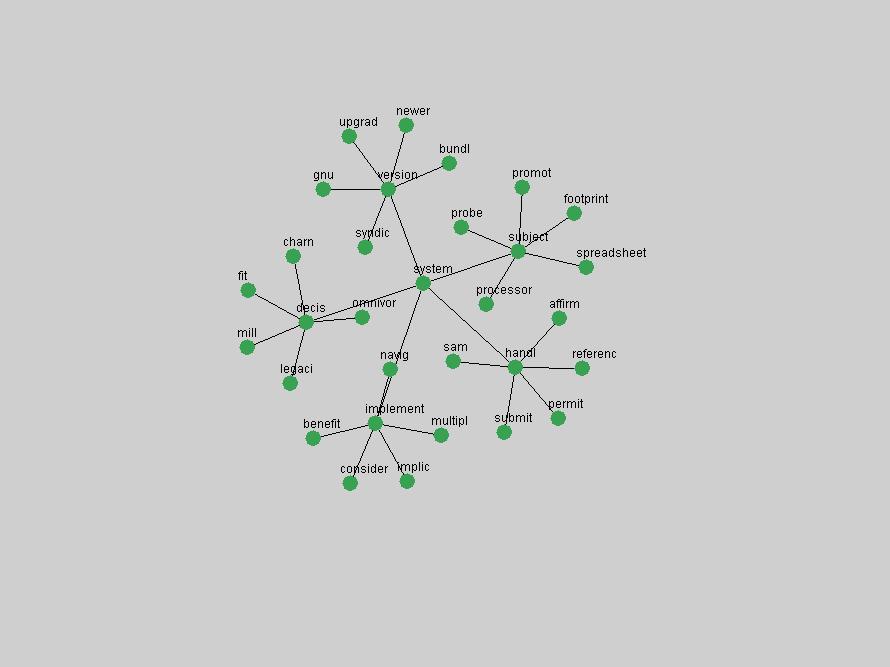
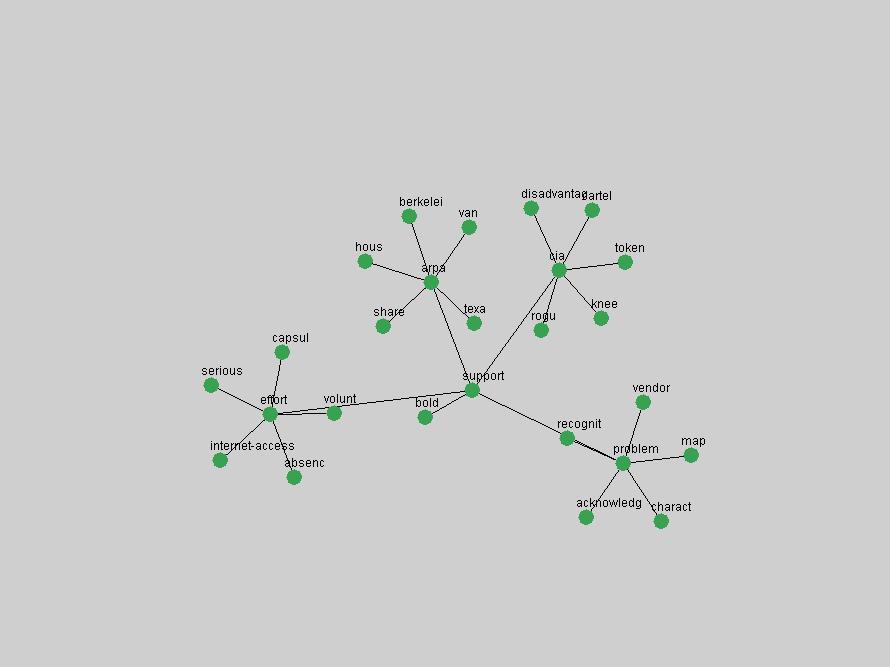
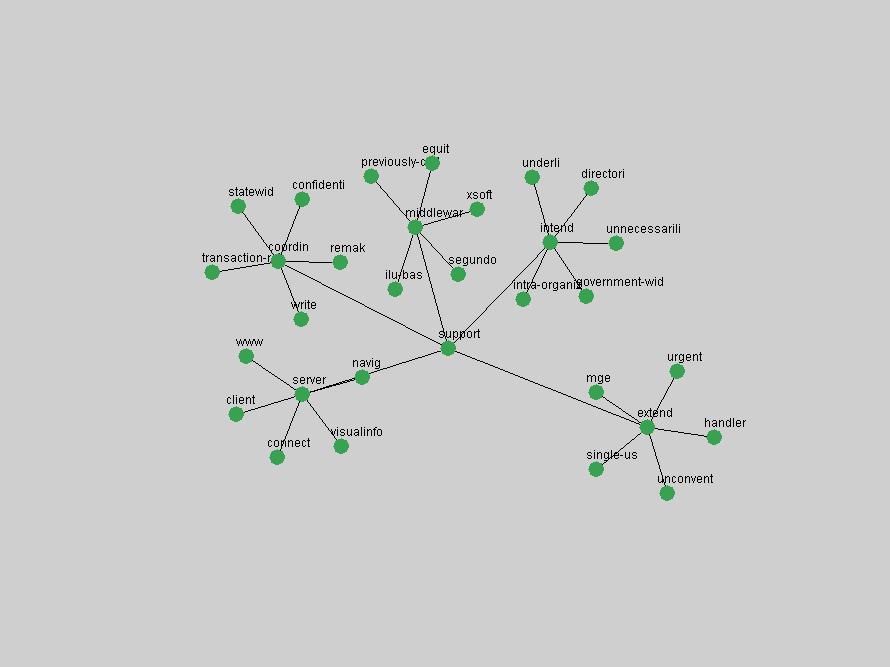
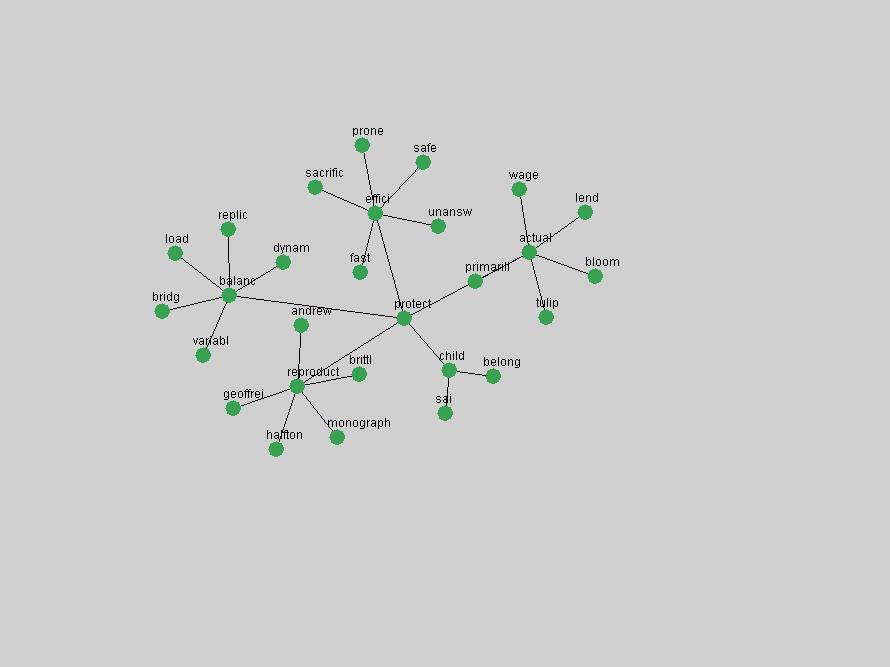
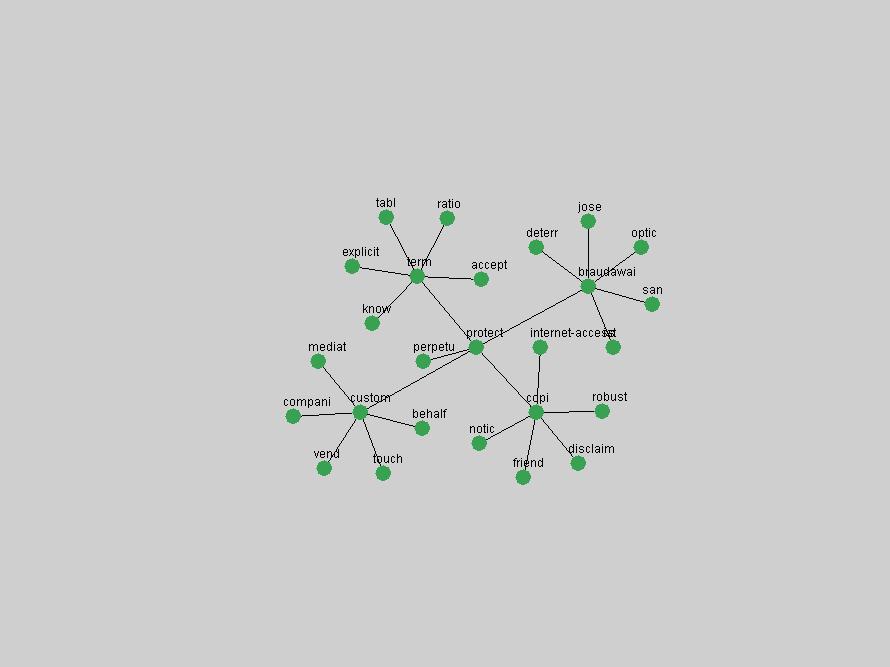
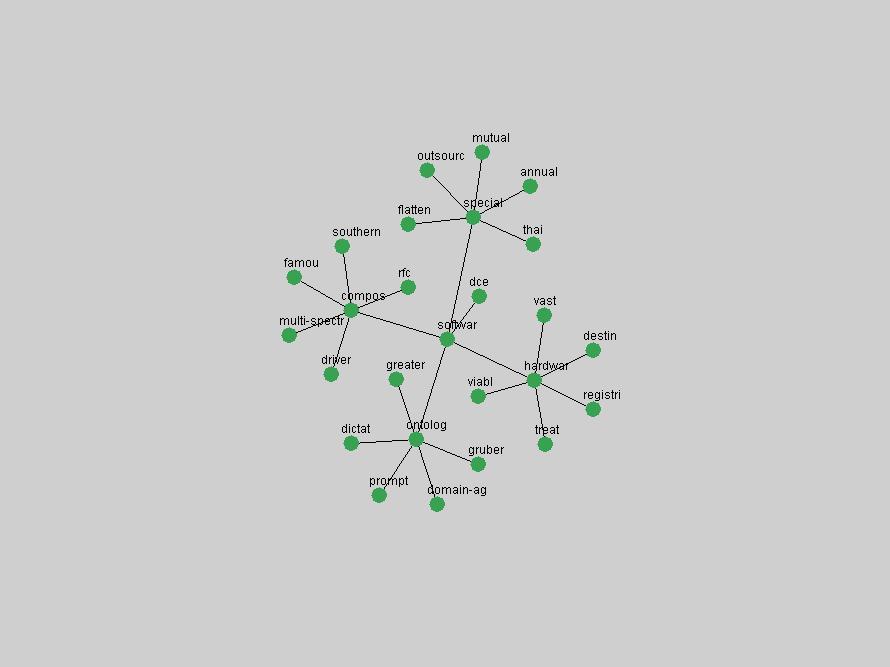
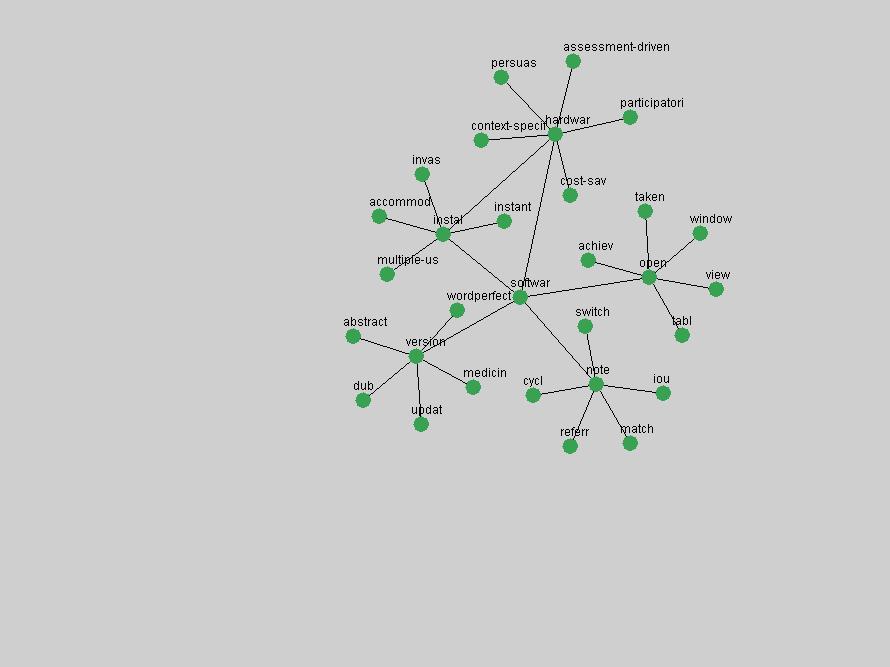
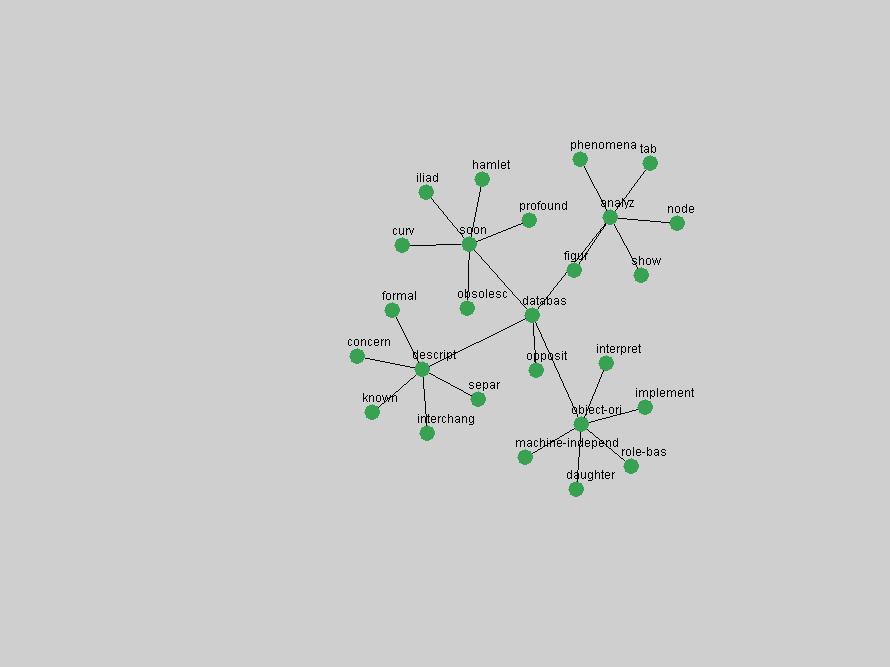
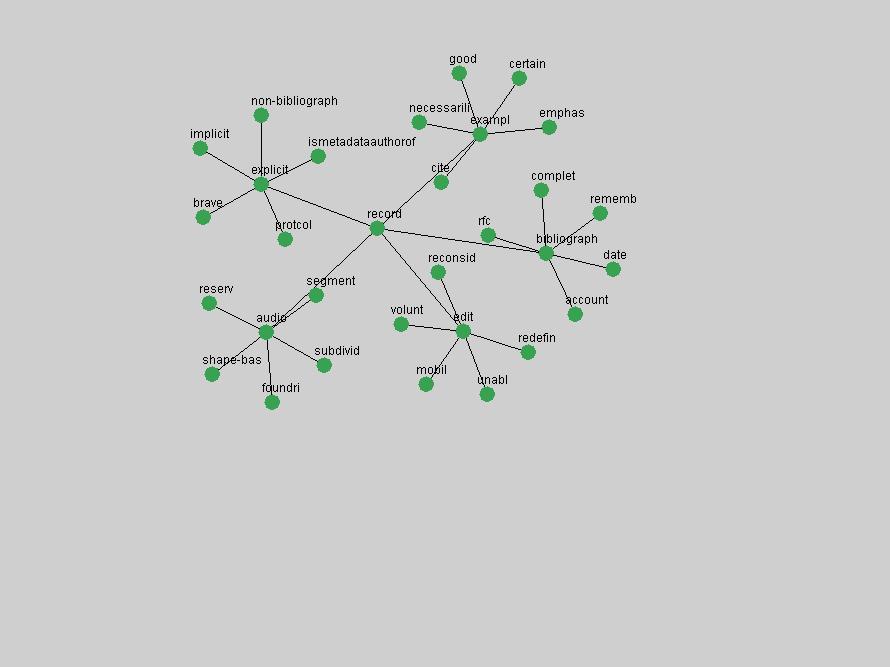
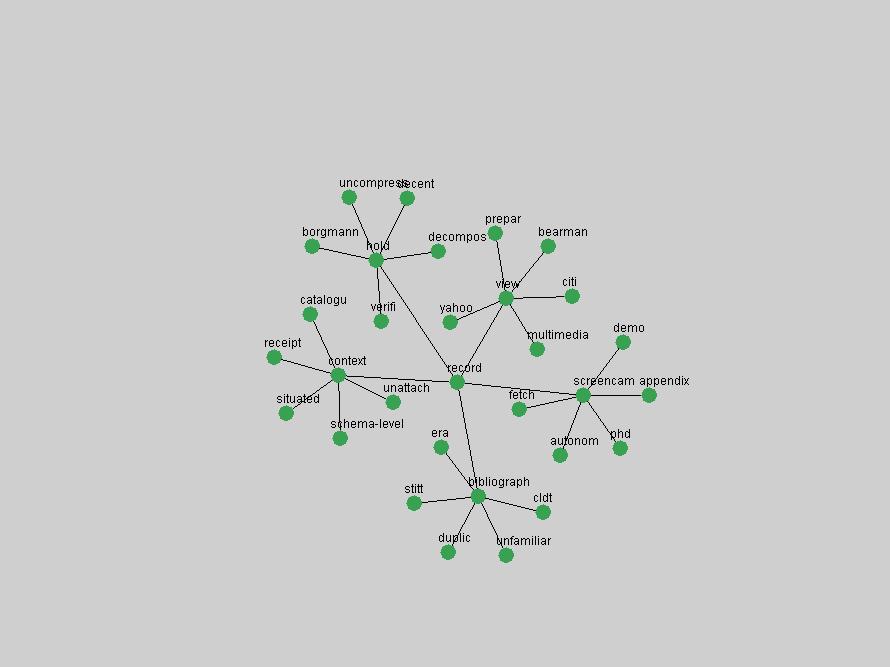
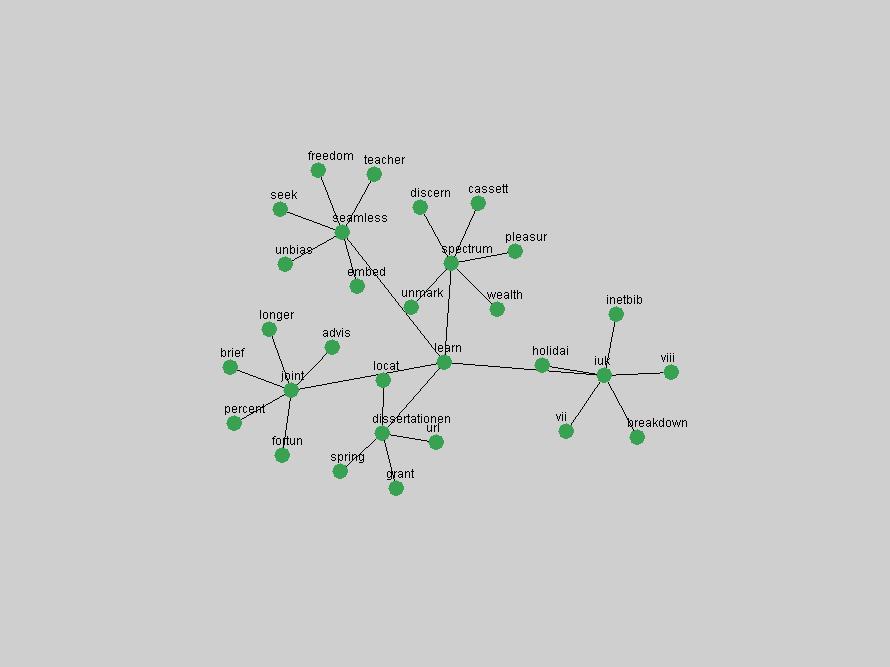
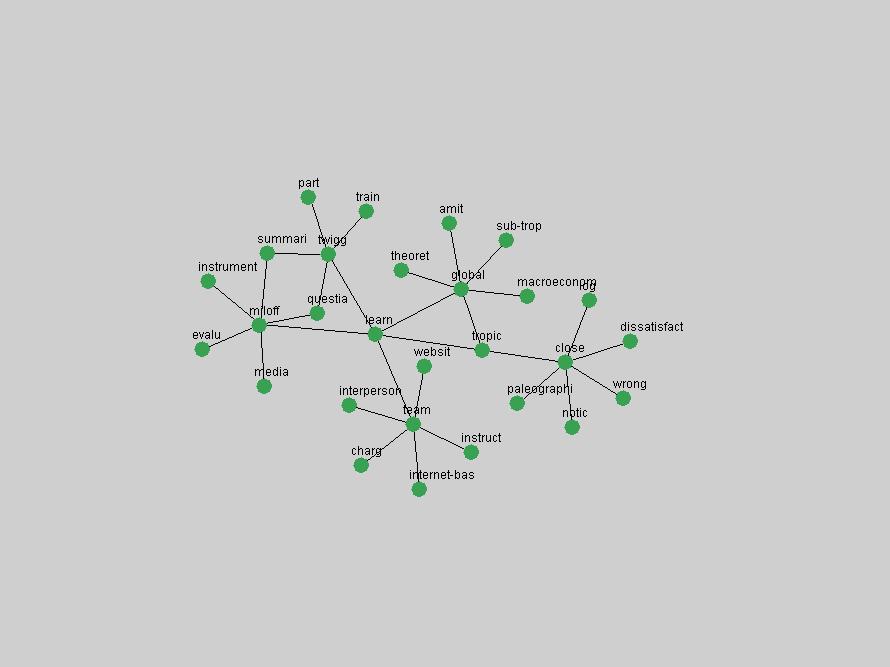
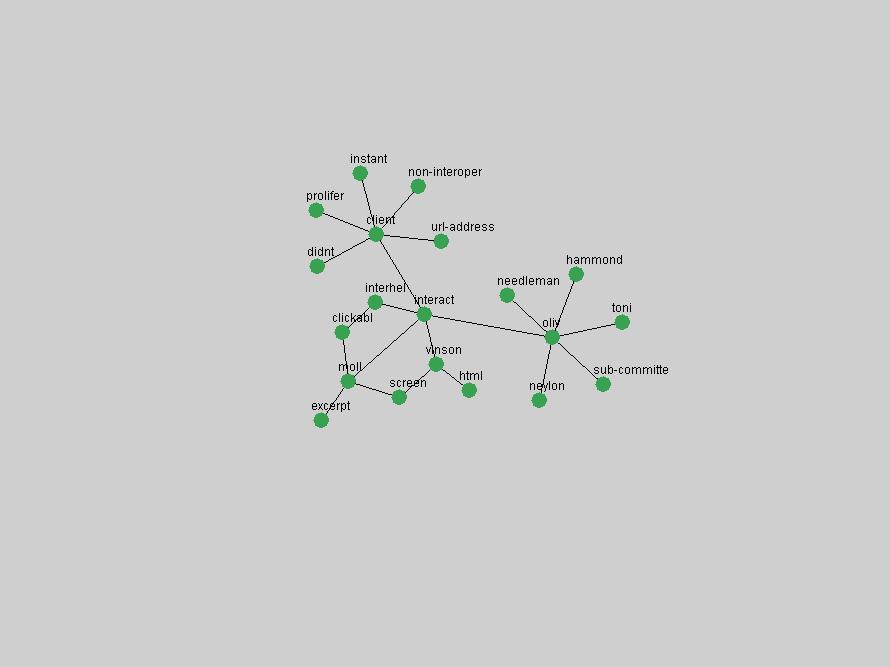
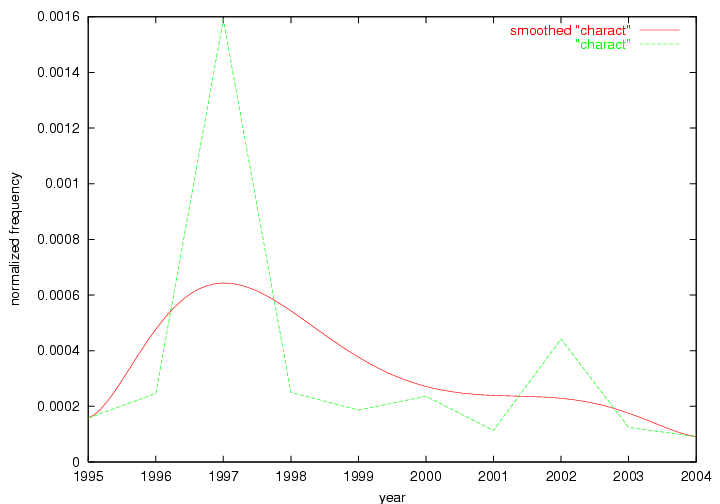
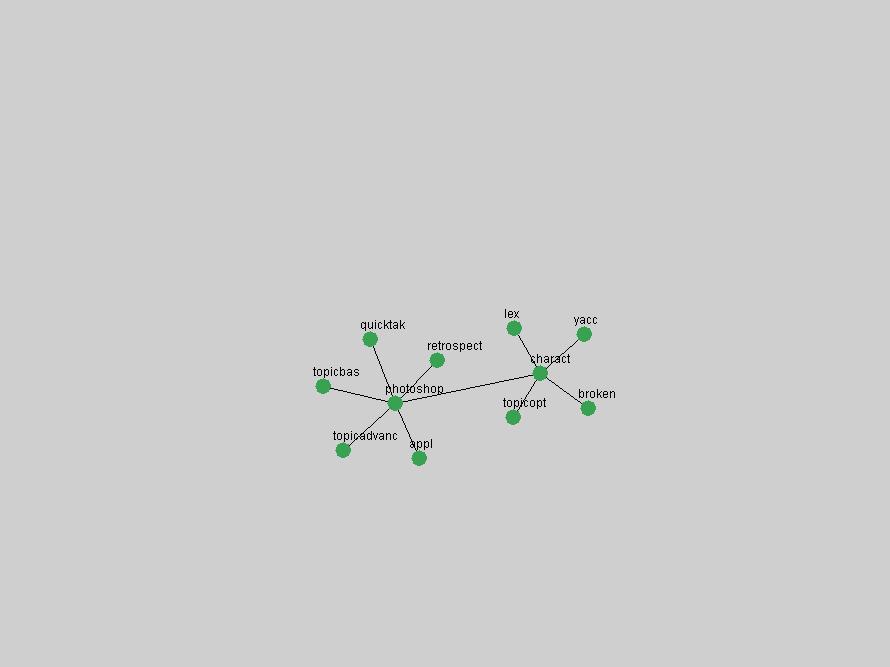
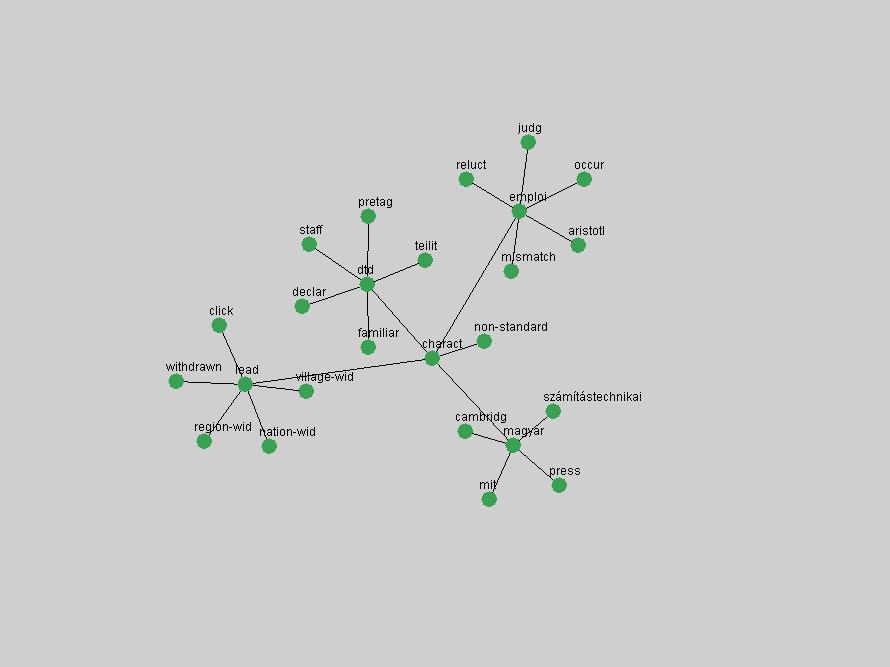
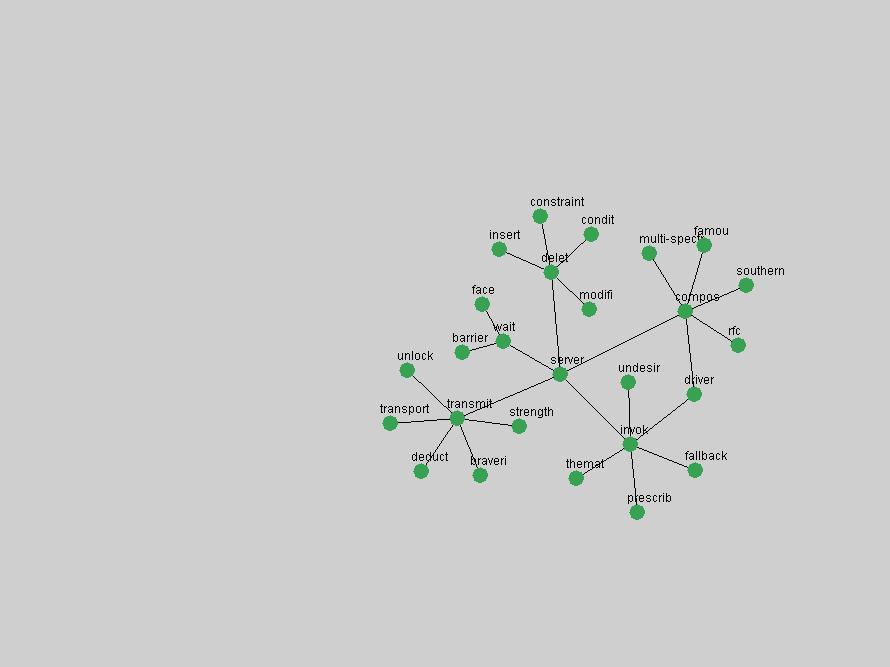
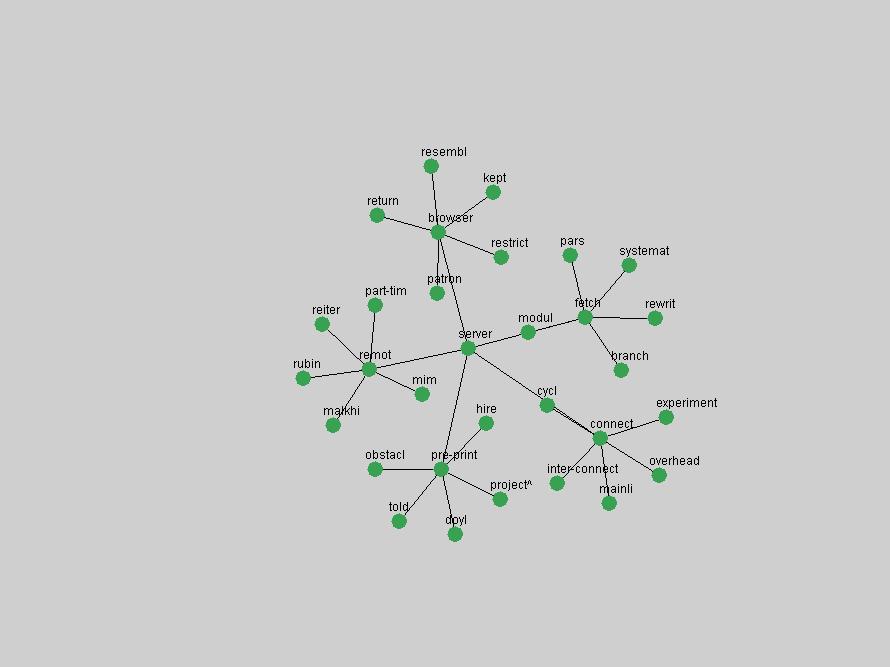
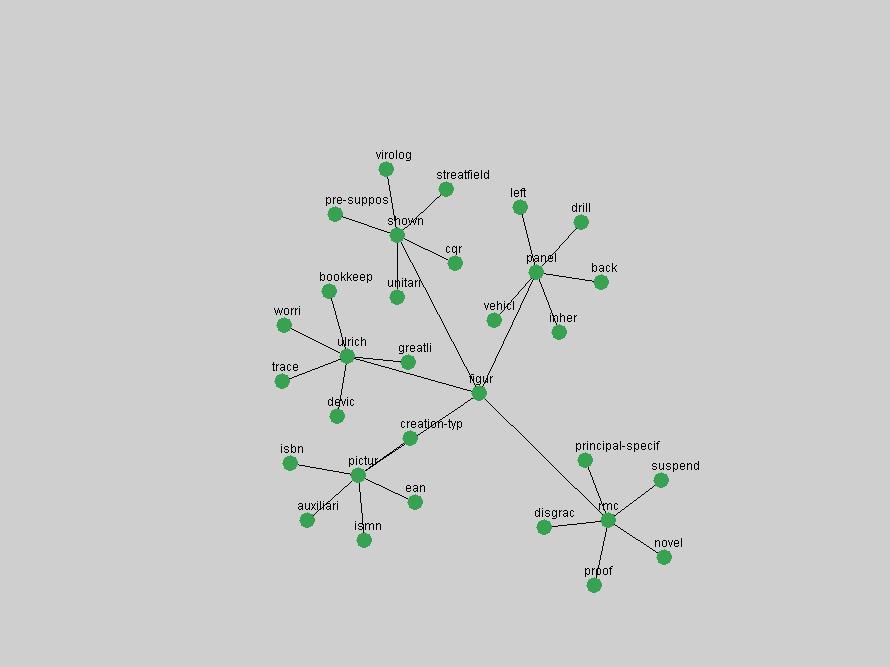
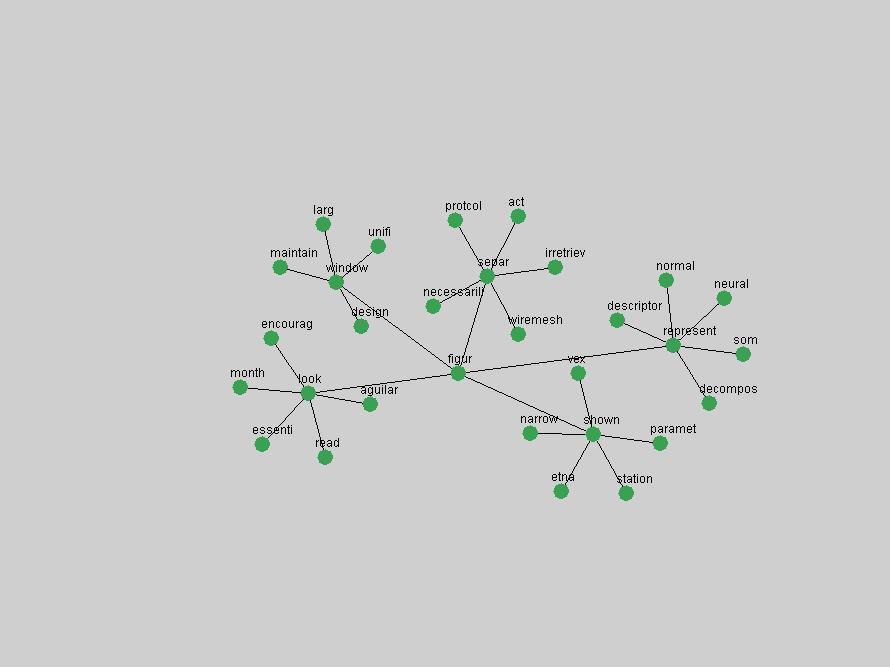
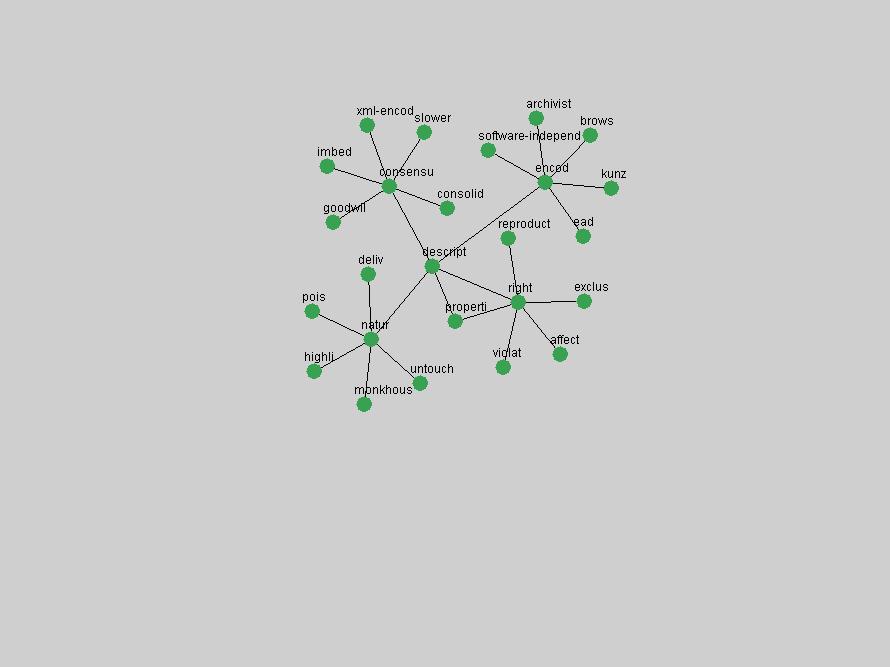
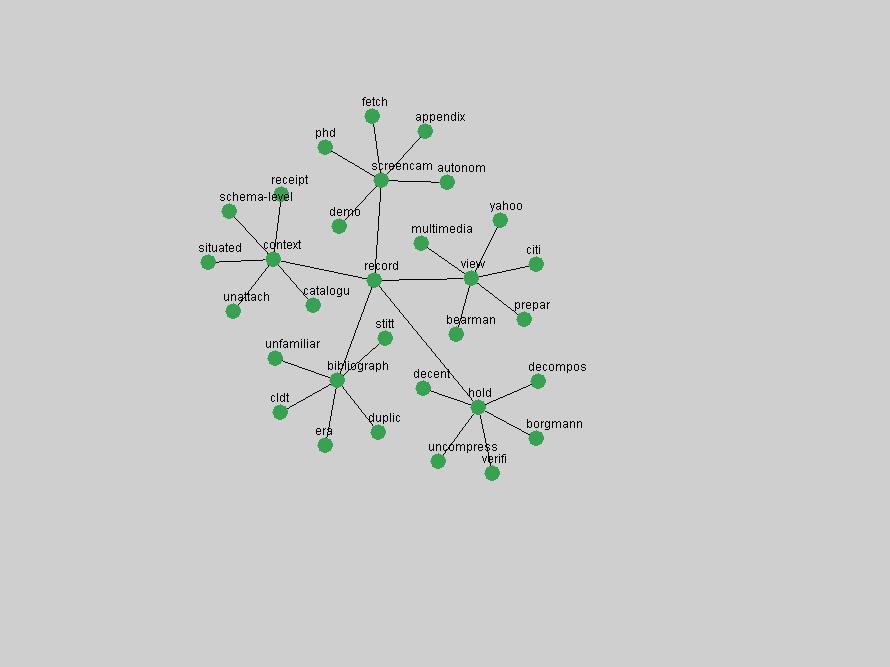
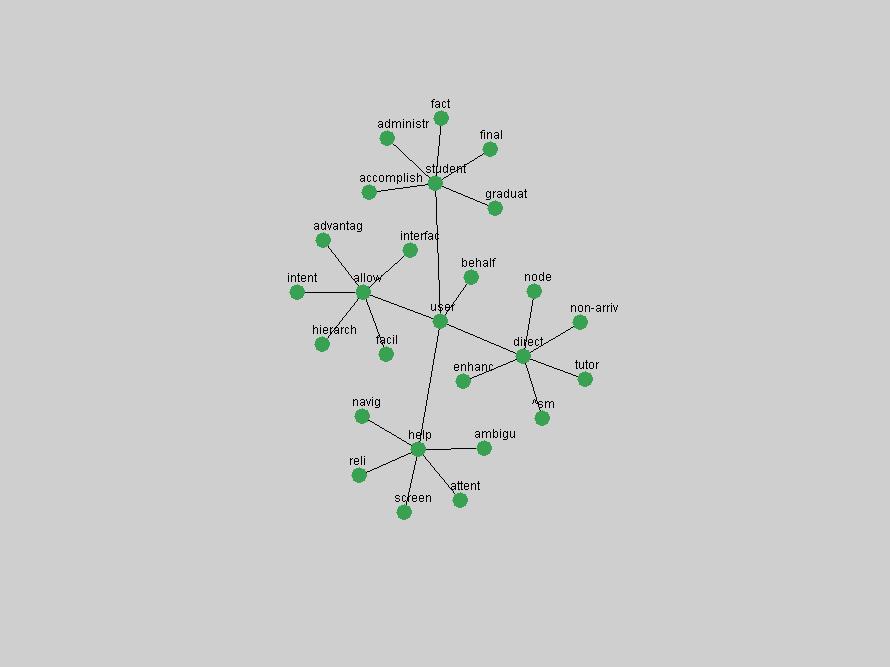
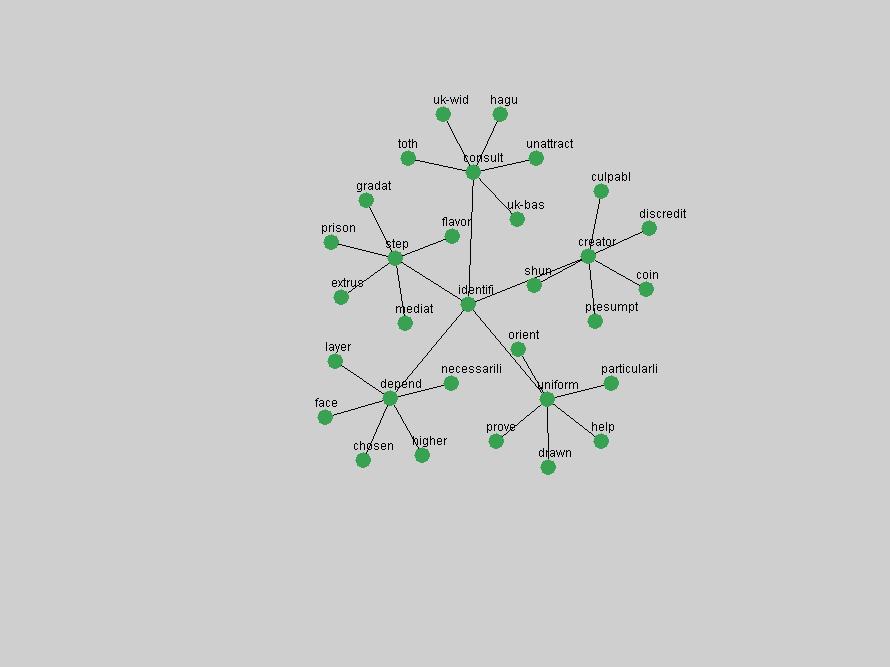
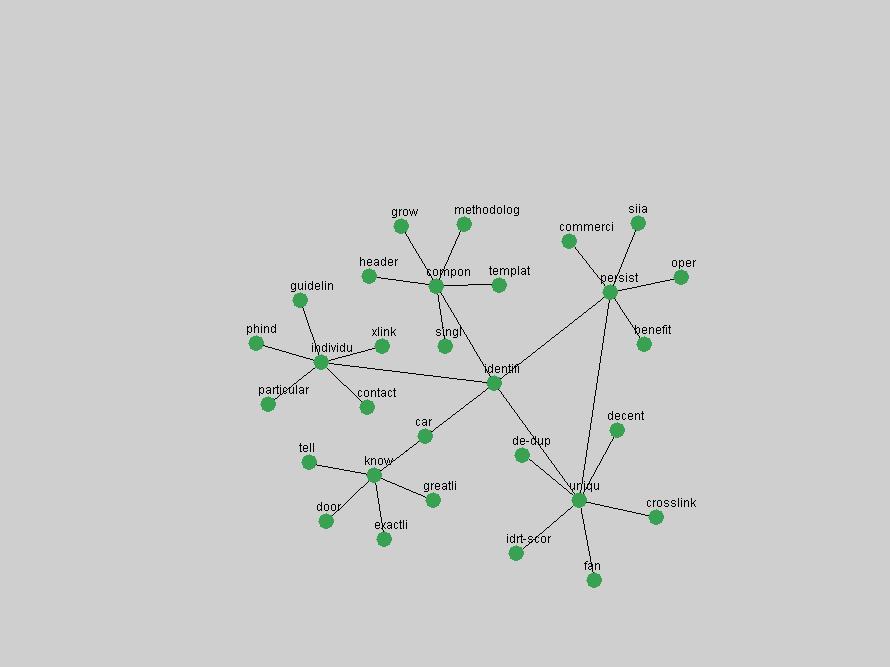
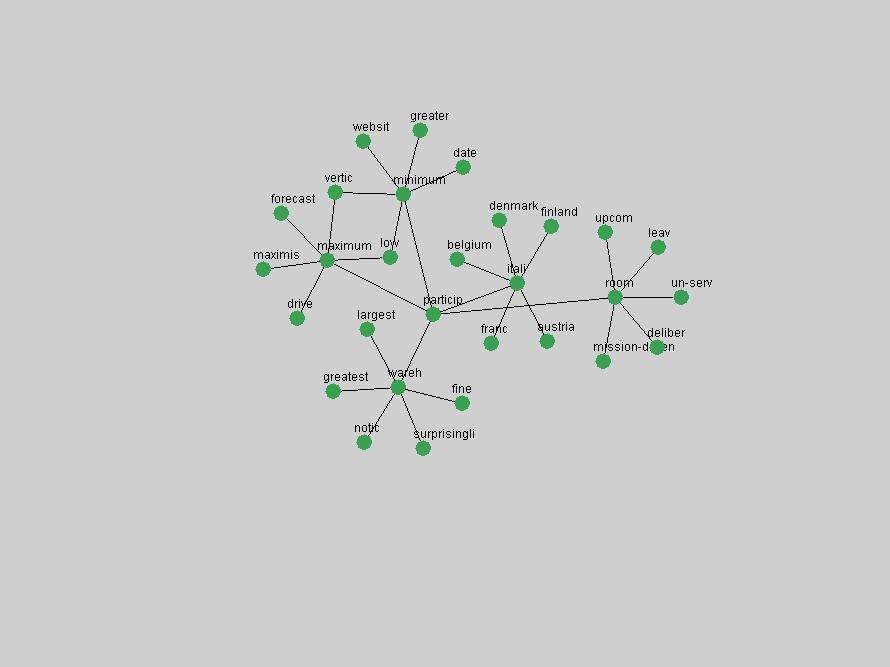
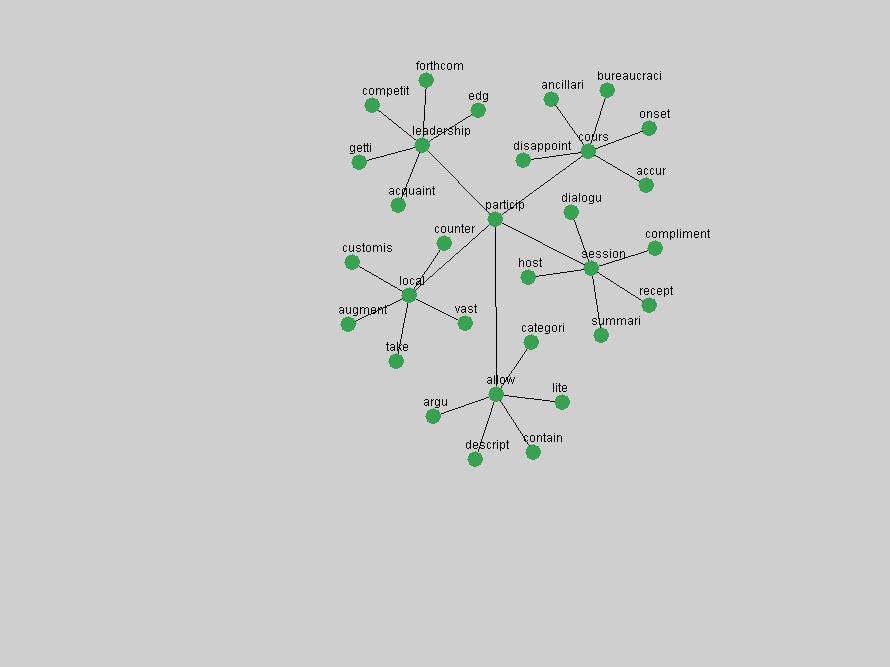
Table 3. Frequency of Terms Appearing in the Top 10 Each Year This data suggests that some of the most frequent terms are relative newcomers. The term "metadata" only started occurring among the 10 most frequent terms in 2001, but maintained a stable top position in the following 4 years. In other words, 10 years after the introduction of Dublin Core (Weibel, 1995), metadata remains a central concept within the content of D-Lib Magazine. Although the lists of the 10 most frequent terms are quite stable across the past 10 years, this stability hides the fact that these terms have undergone significant shifts in context and meaning. We invite the reader to explore the networks of associative relations that have been generated from term co-occurrences in Table 2. 3.2 InnovationsAs mentioned, we selected a set of terms which over the years have experienced the largest positive shifts in occurrence frequency from one consecutive year to another, i.e. 1995 to 1996, 1996 to 1997, etc. as indicators of "innovations" occurring in the D-Lib corpus. These sets indicate which terms have most strongly entered the discussions at D-Lib Magazine at some point in time, after which they may have continued to become a stable part of the D-Lib content or disappeared after a short initial spike in interest. Table 4 lists the strongest growing terms for each pair of years since D-Lib Magazine started production in 1995. Each term is linked to its network graphs and a graph of its normalized frequency in the 1995 to 2004 period.
|
Table 4. Terms that underwent strongest positive shifts in occurrence frequency from one consecutive year to another
|
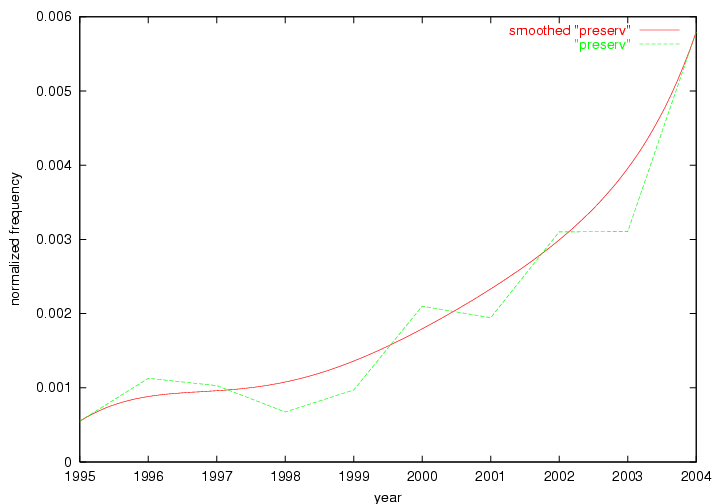
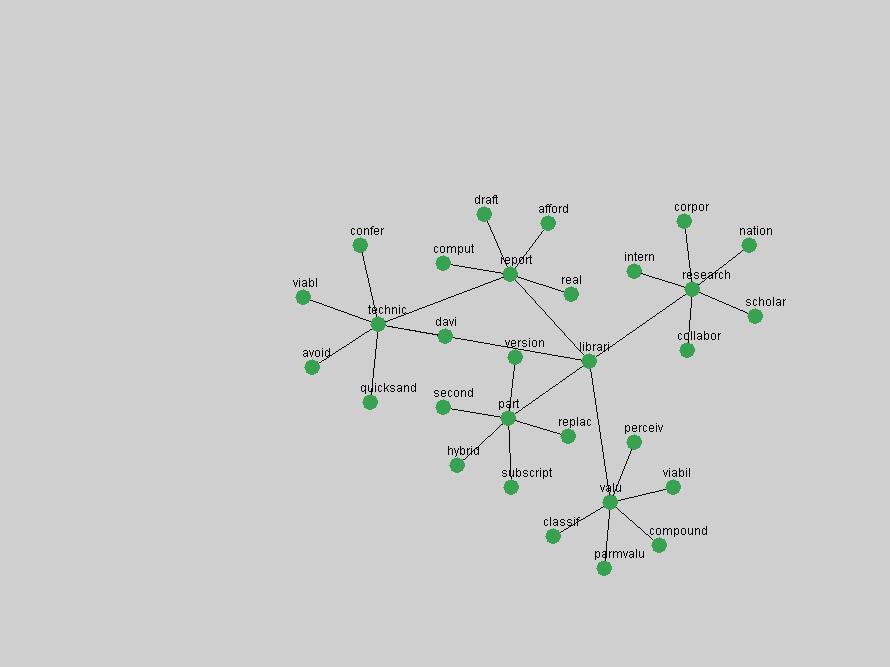
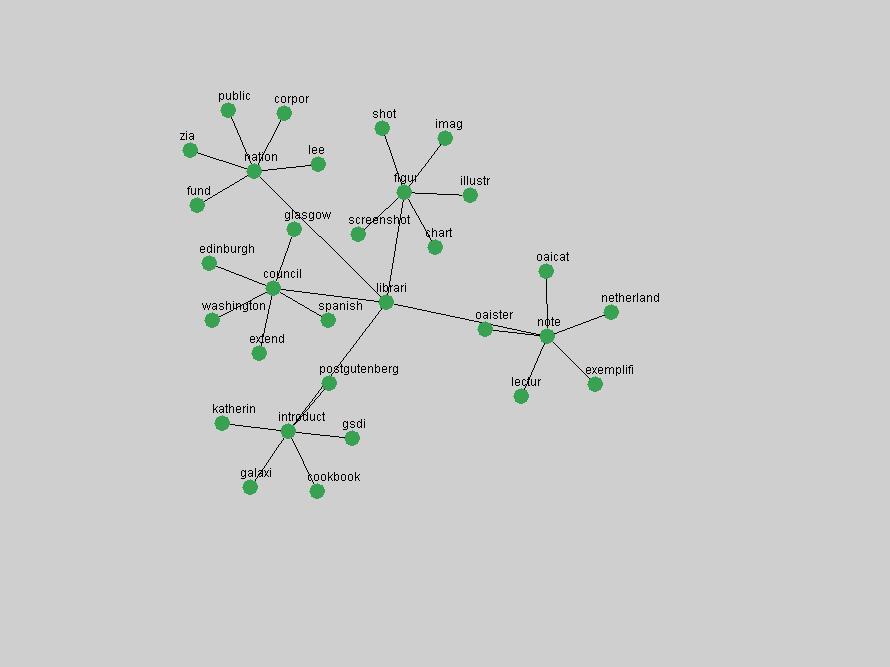
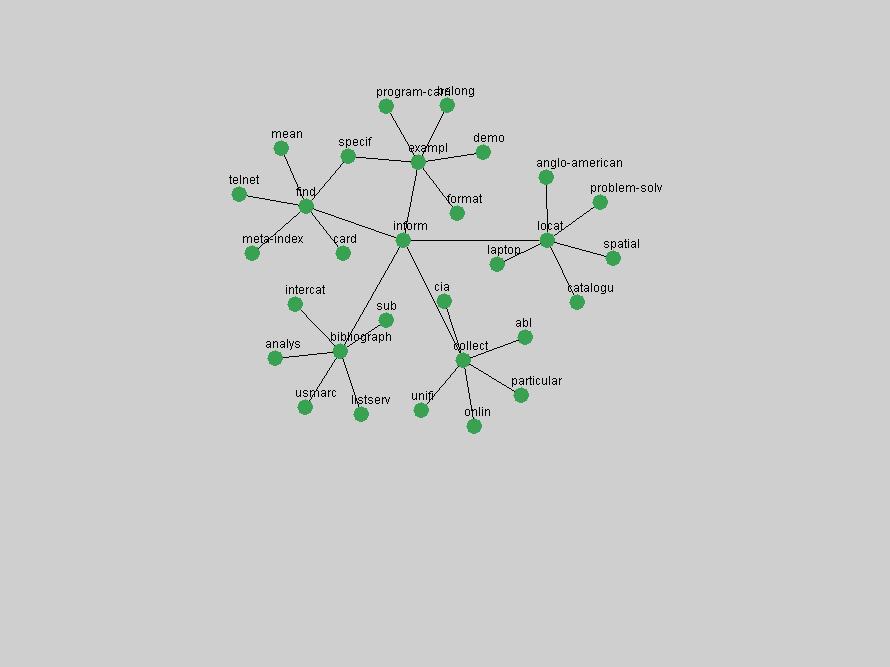
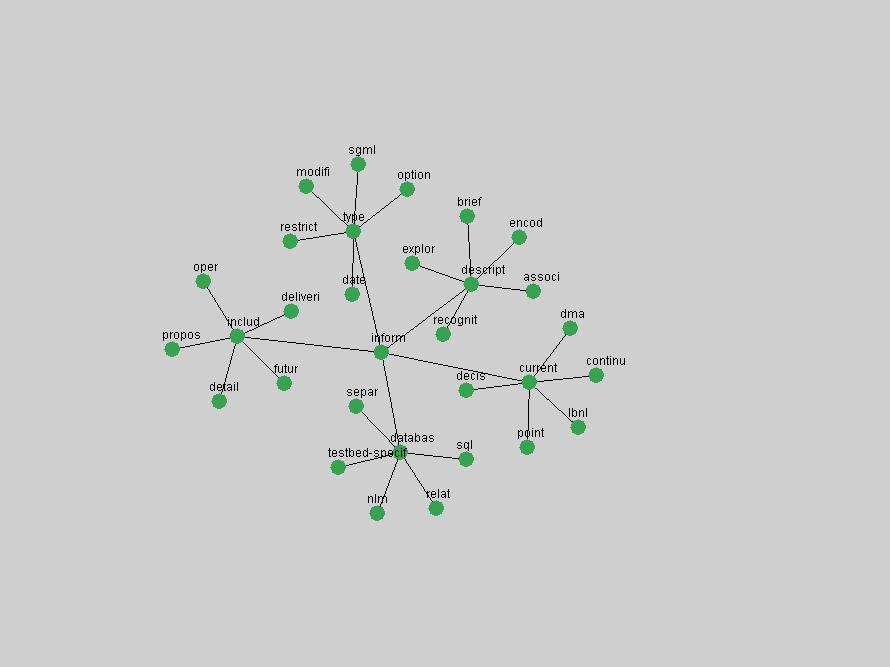
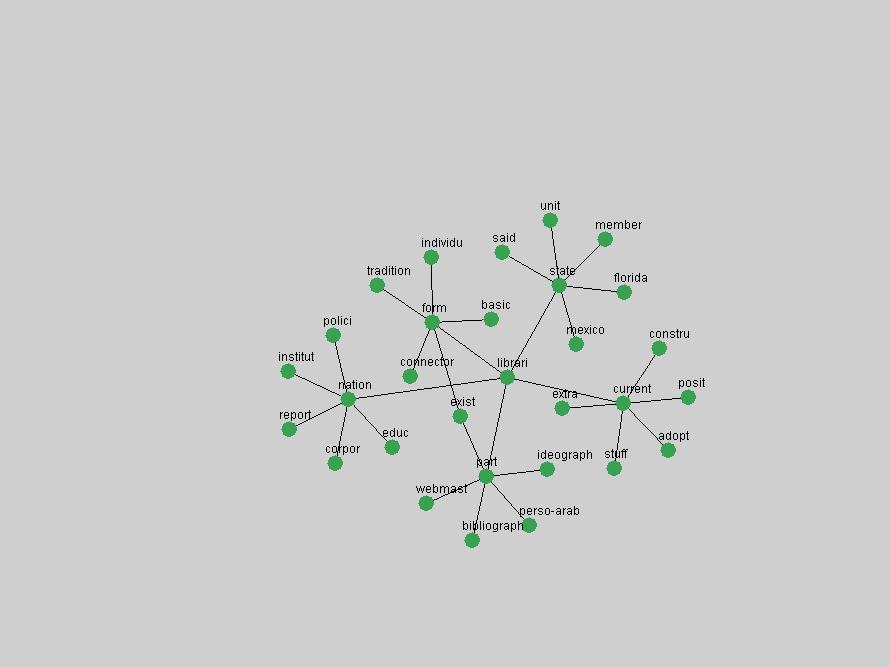
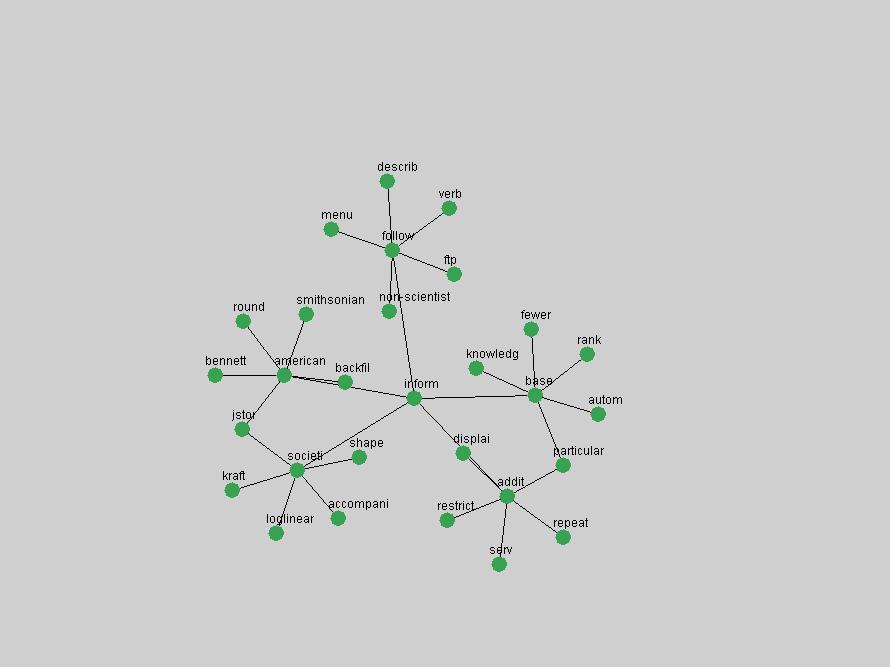
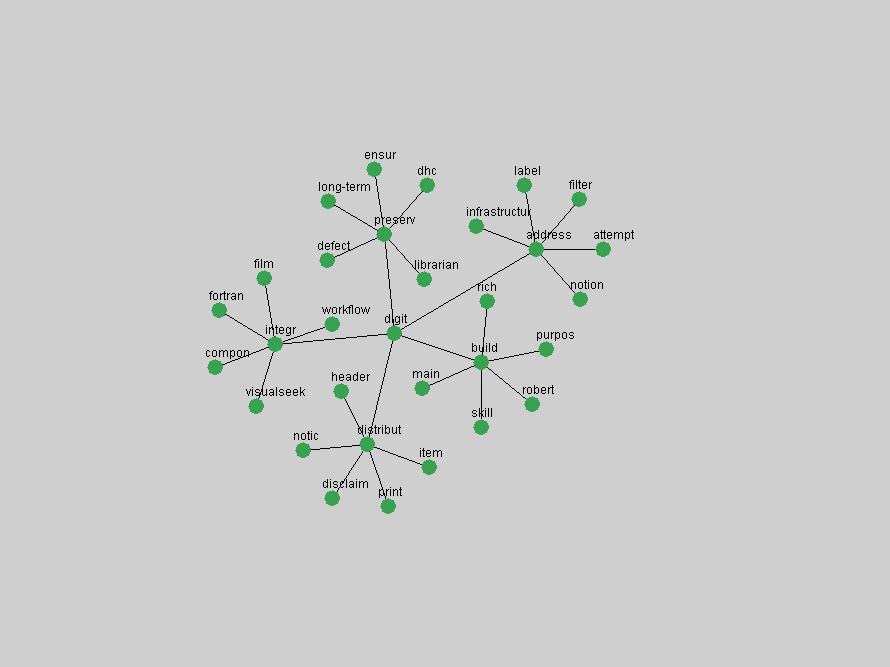
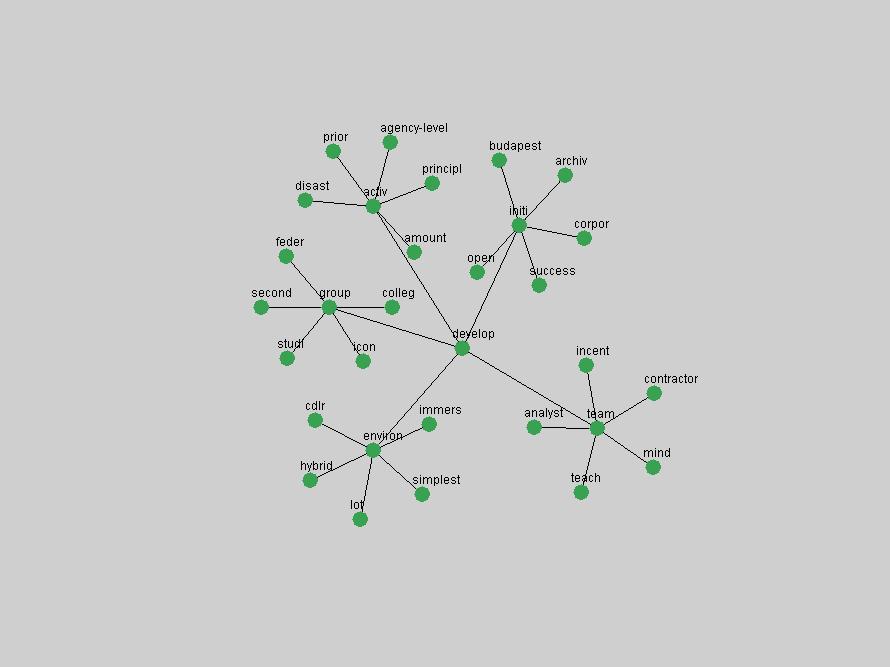
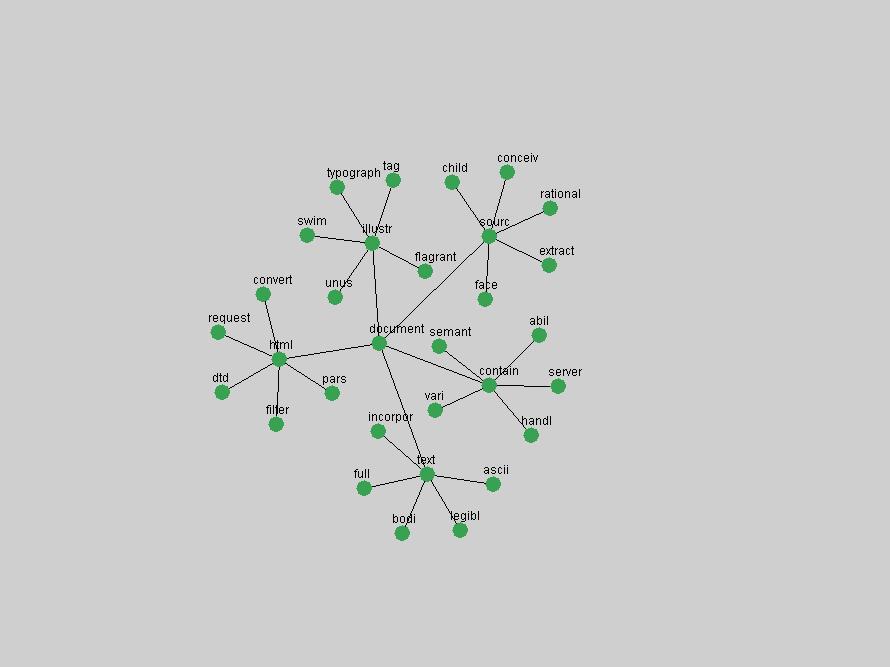
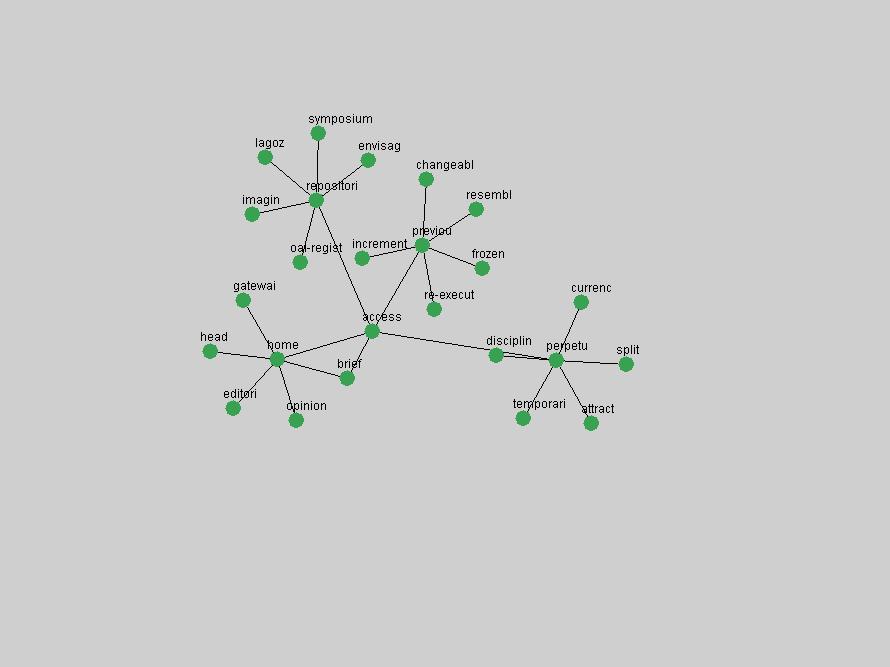
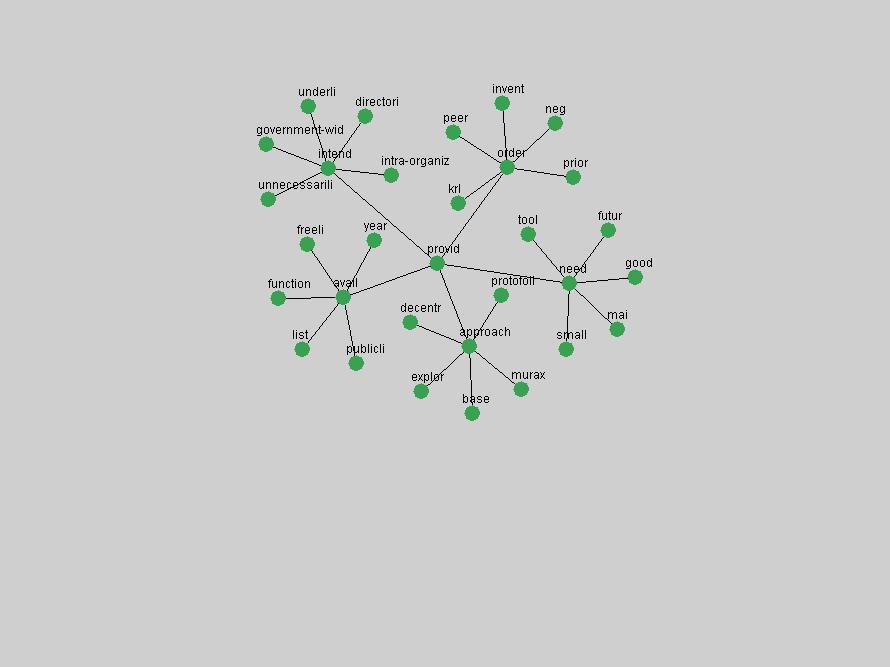
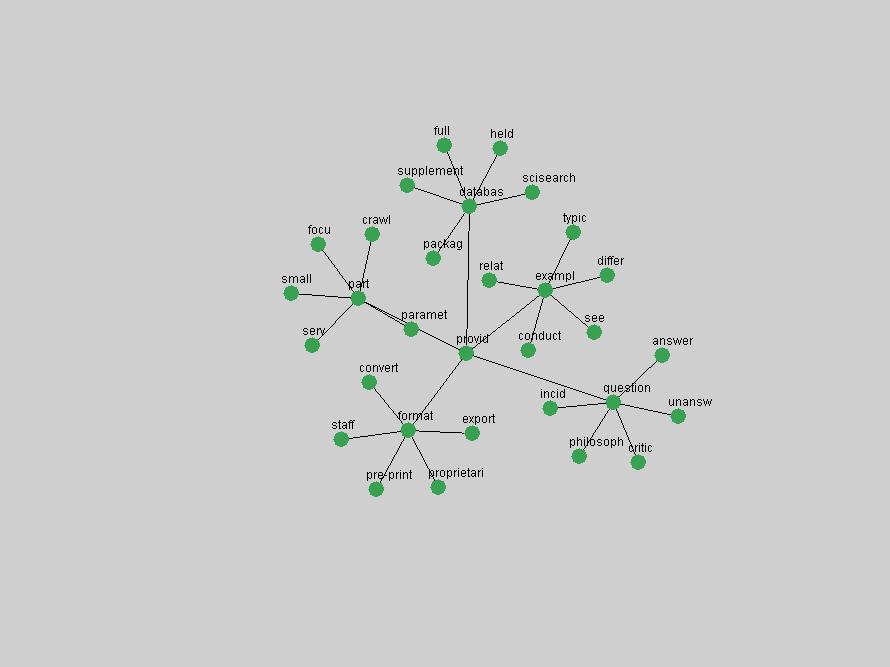
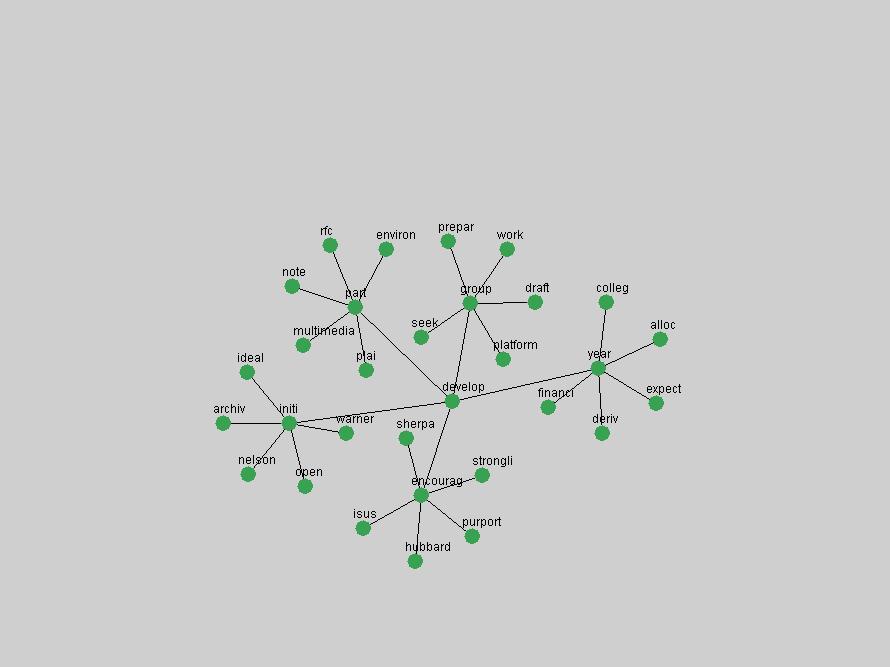
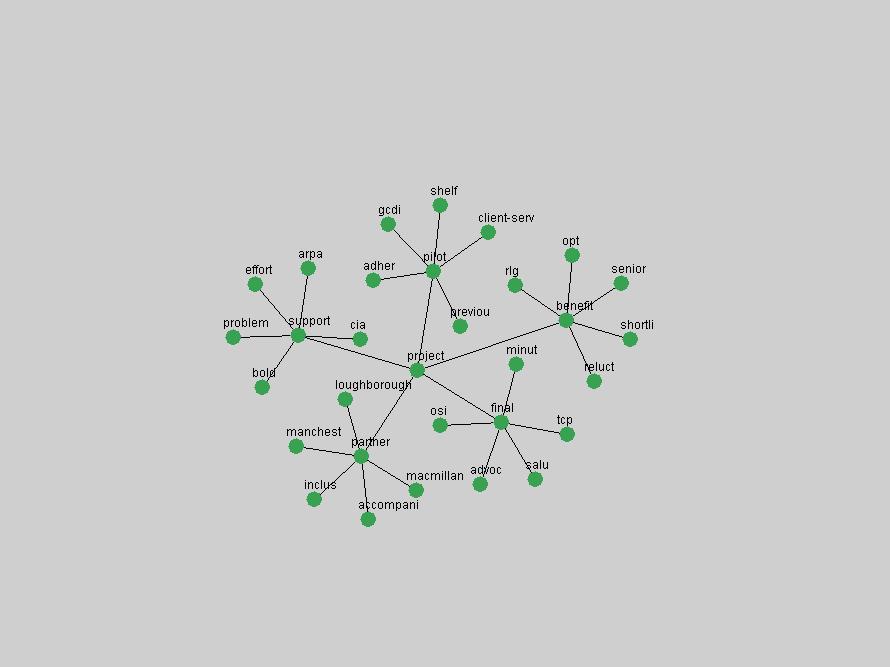
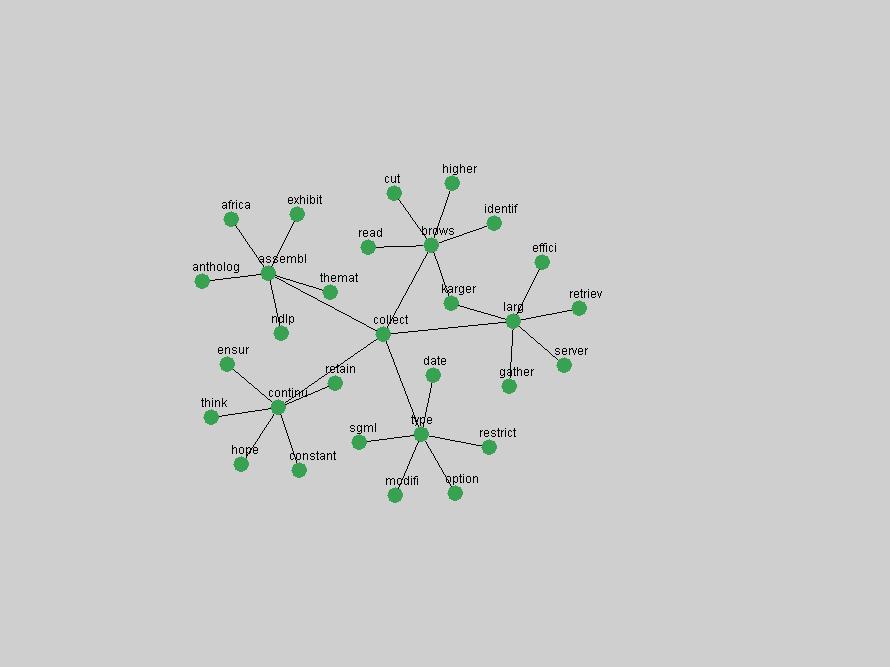
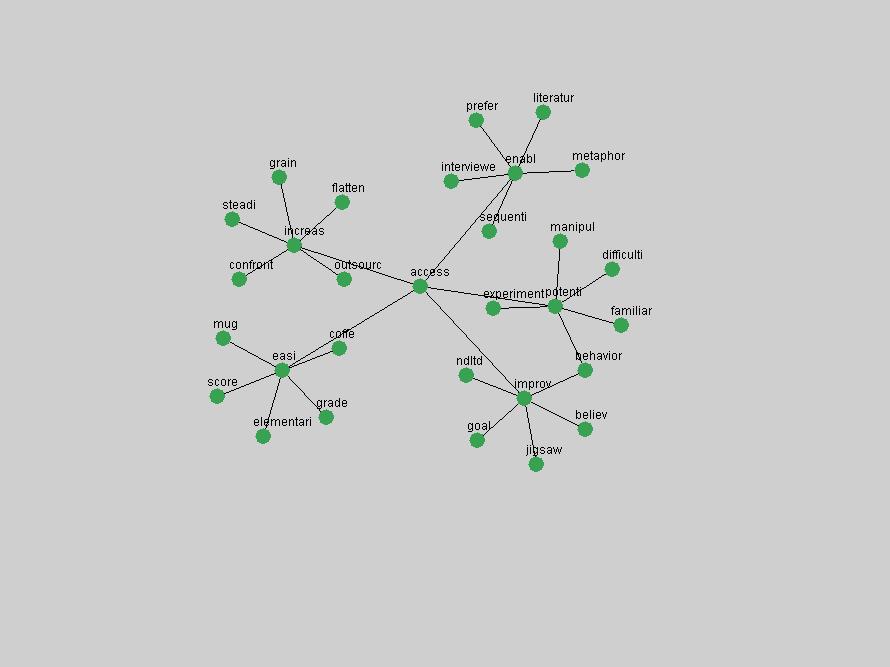
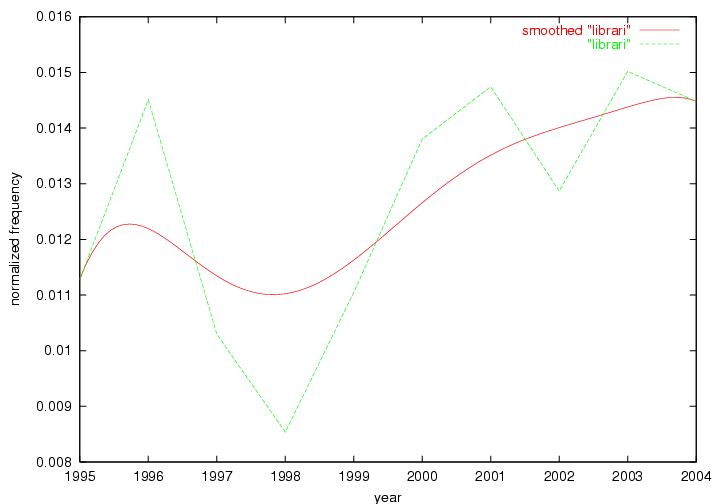
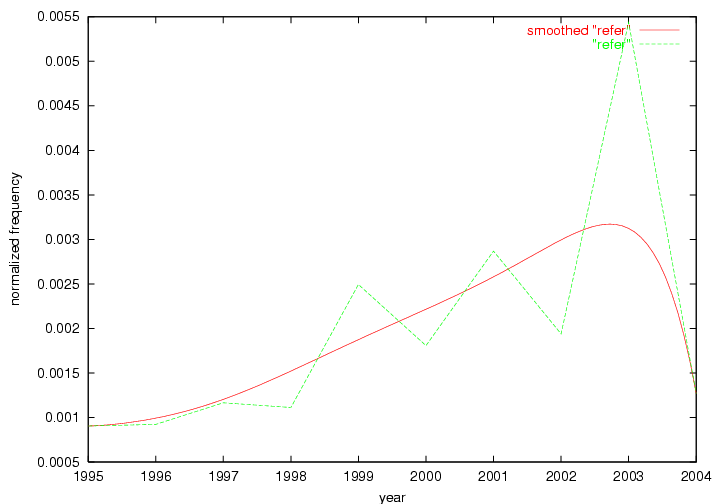
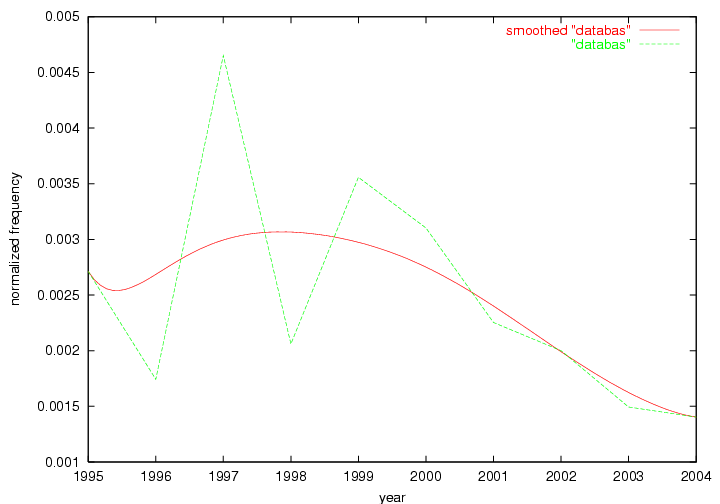
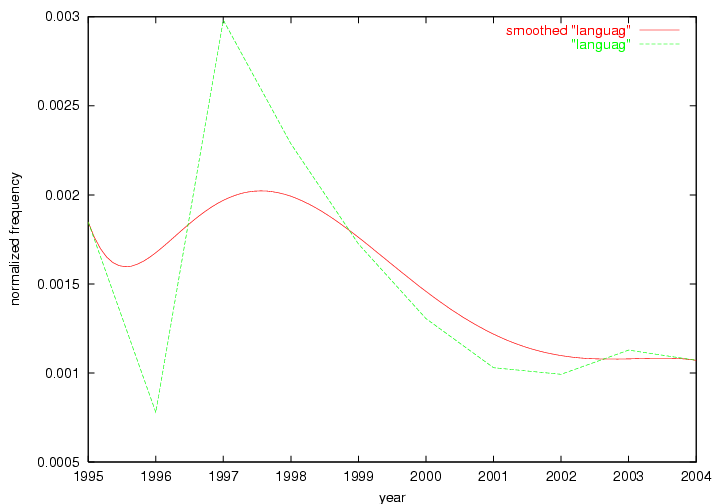
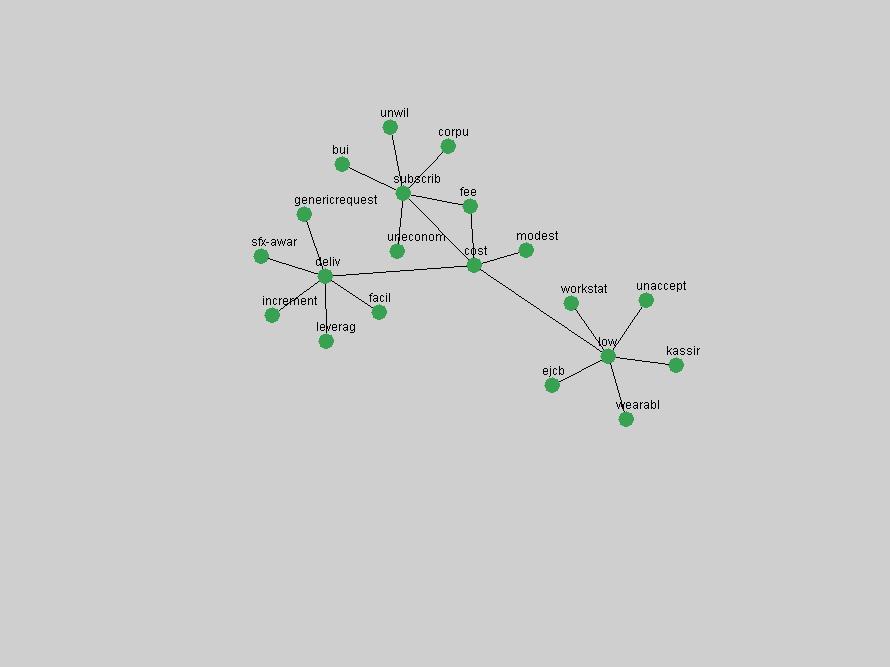
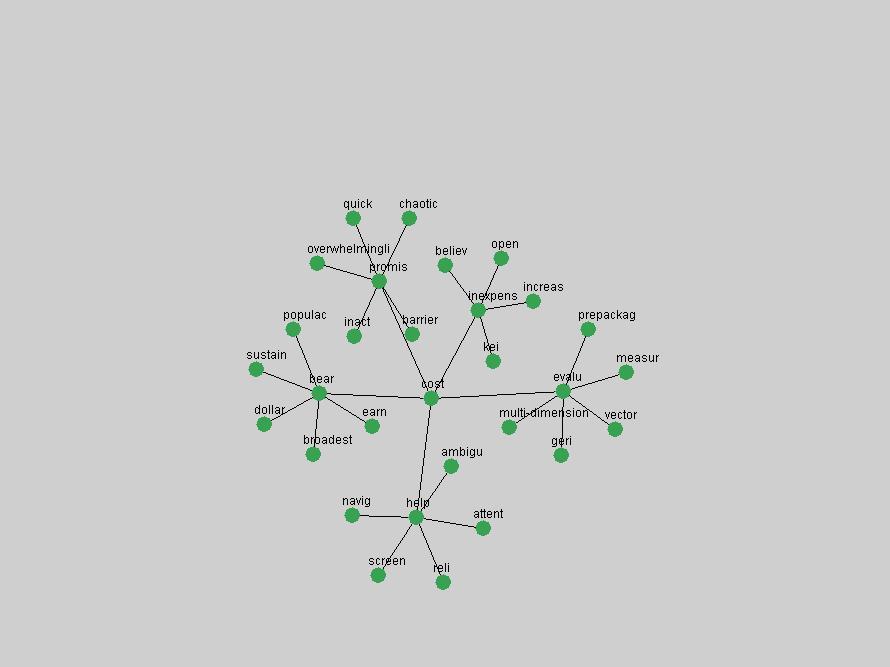
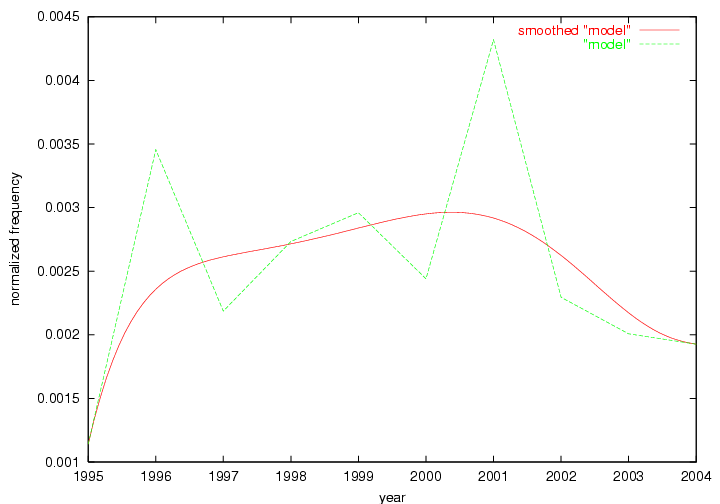
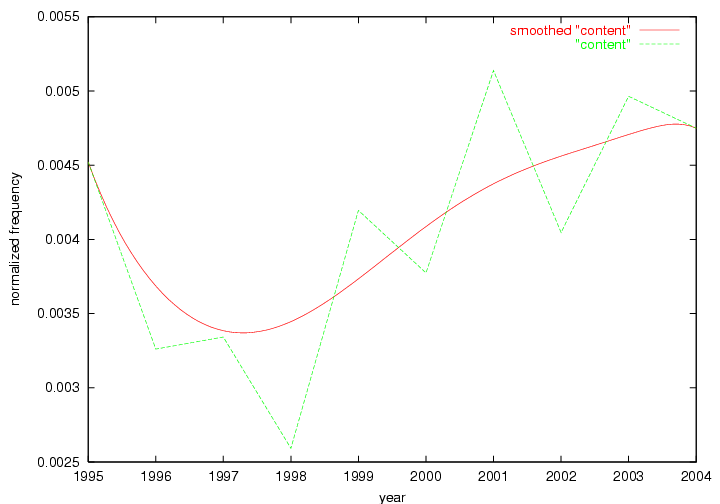
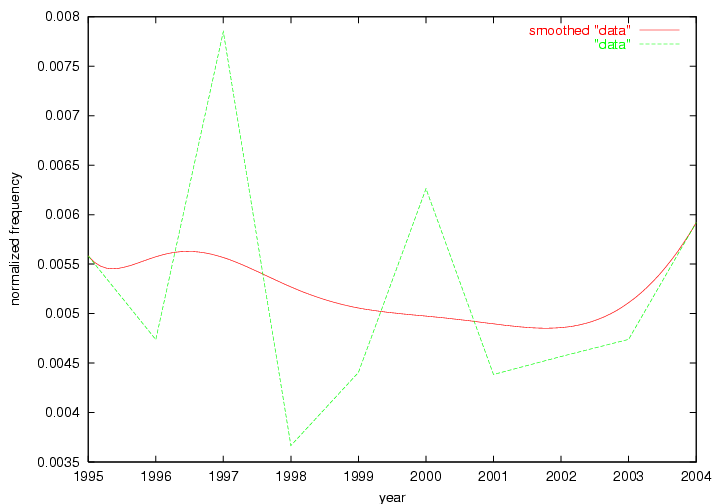
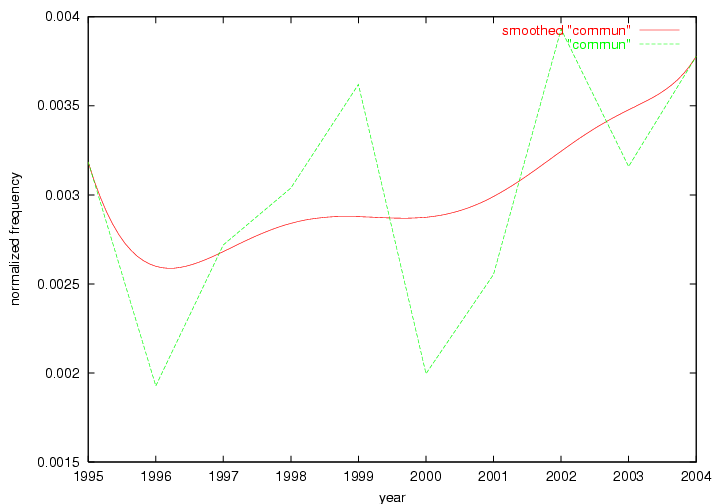
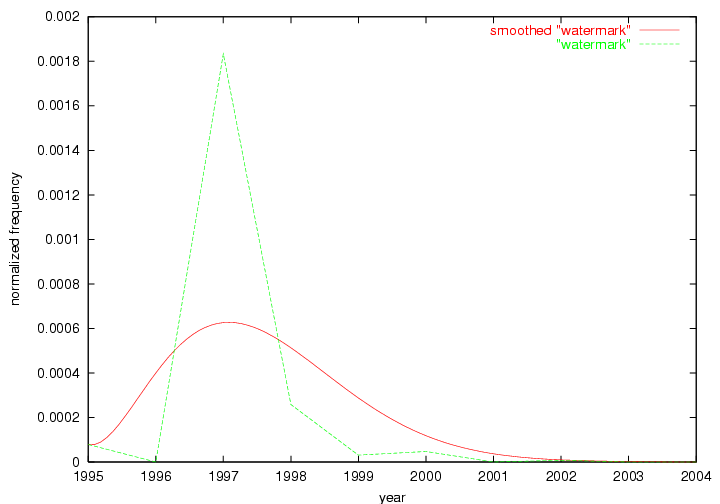
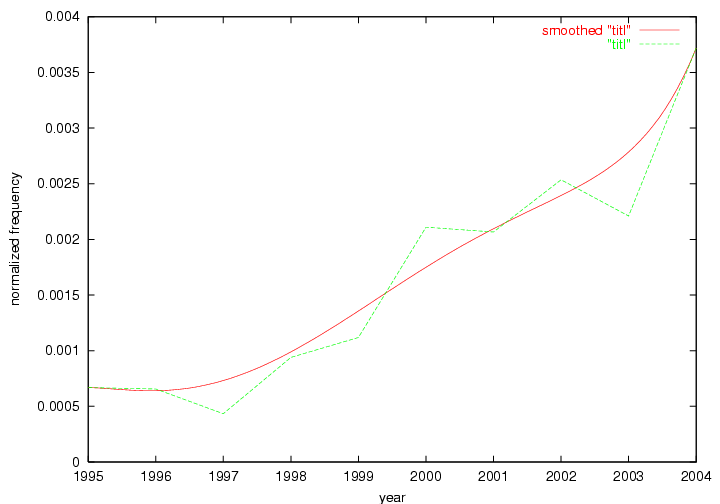
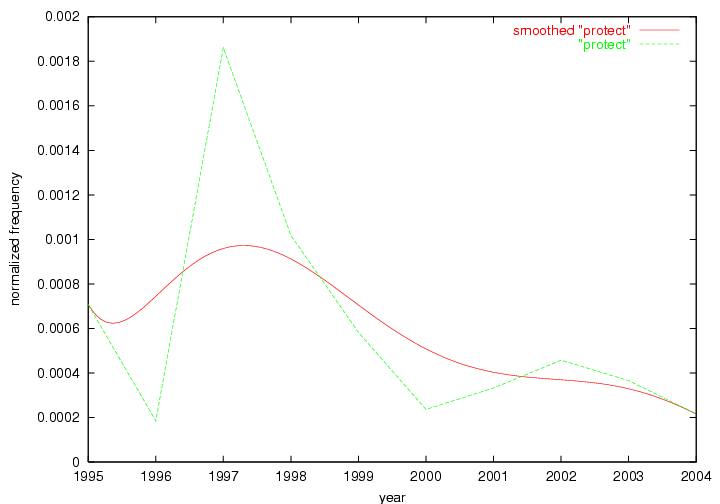
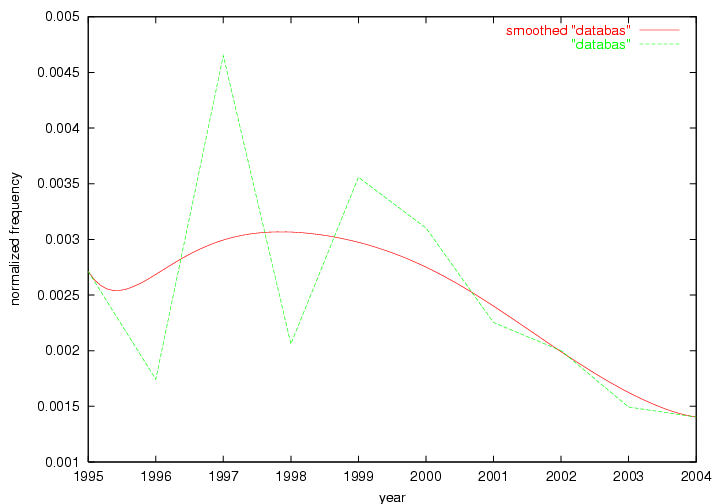
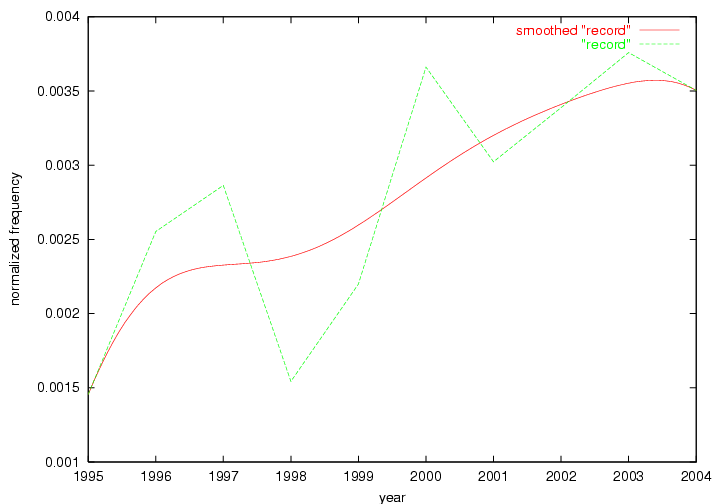
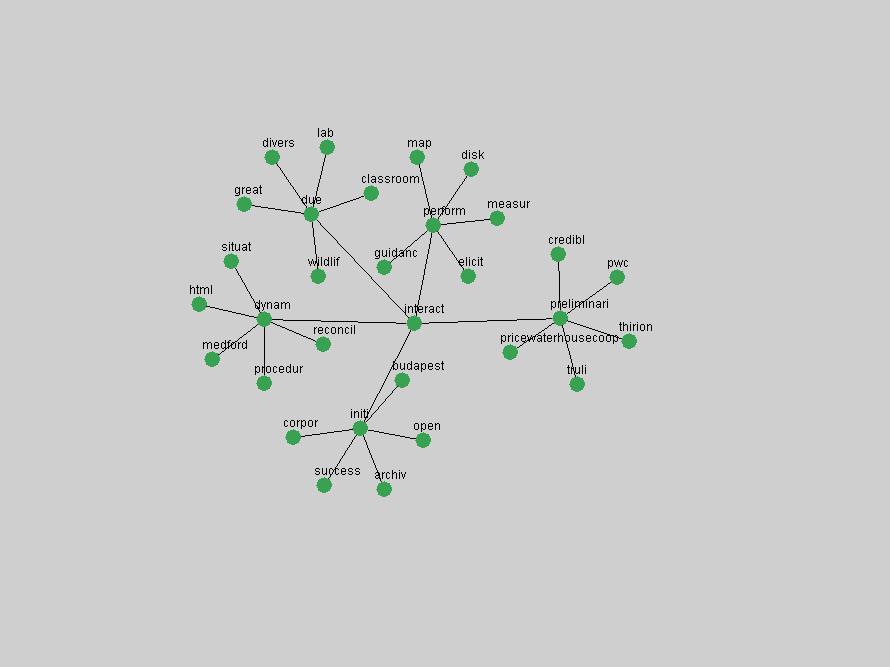
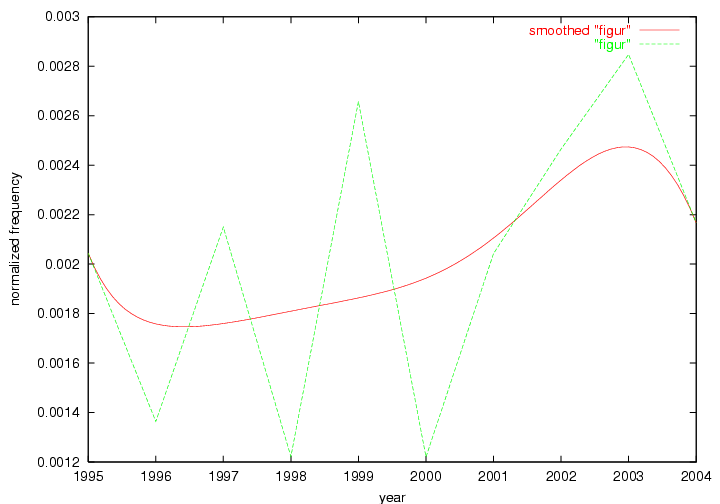
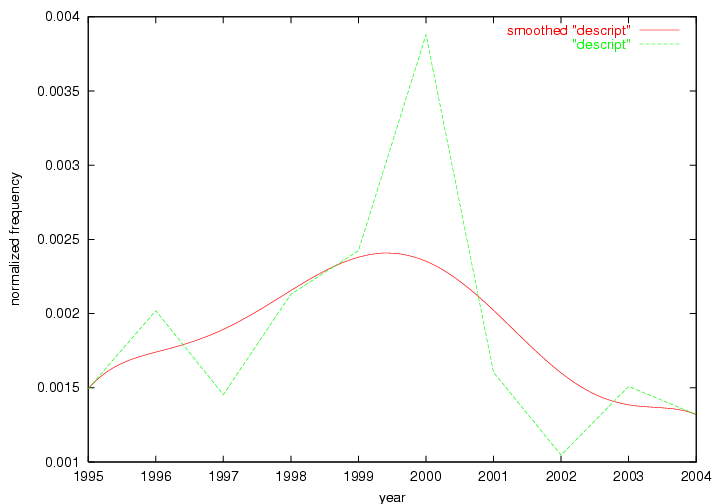
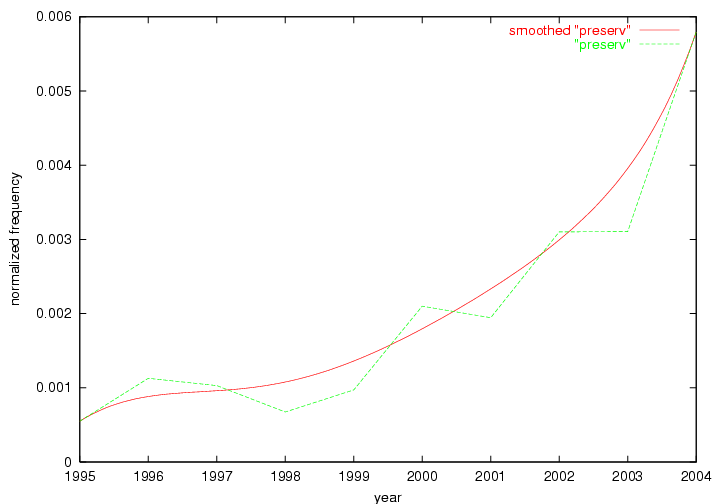
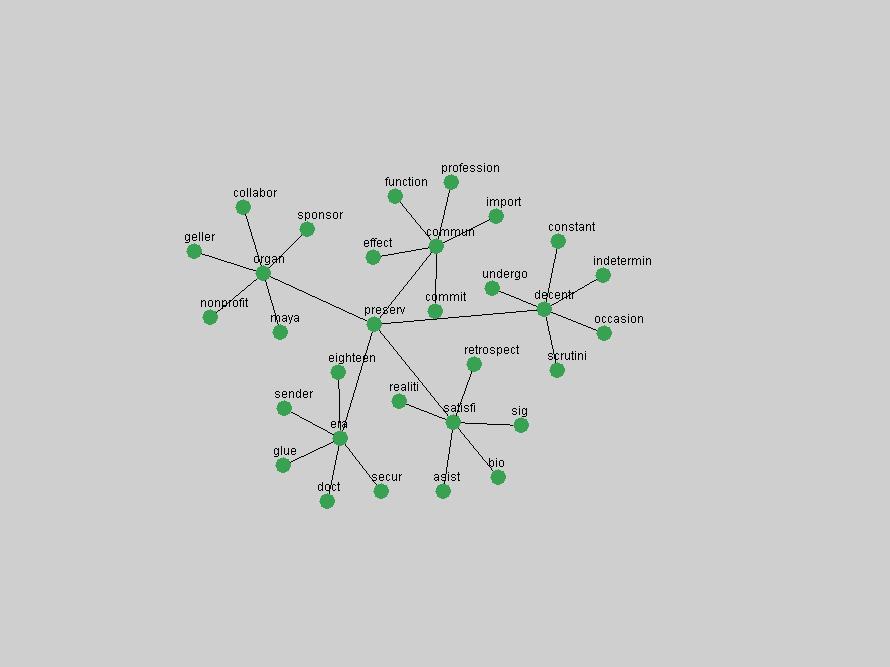
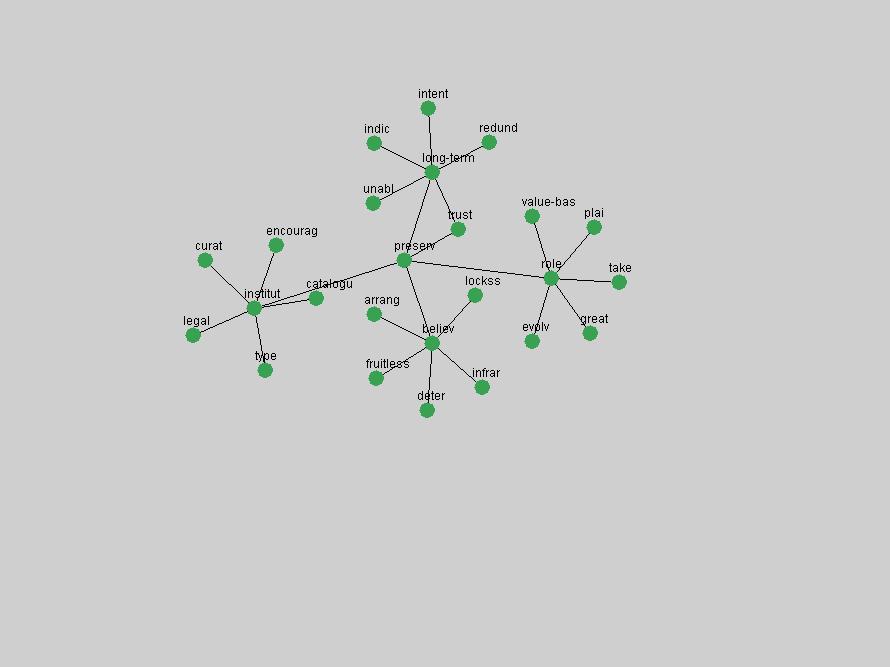
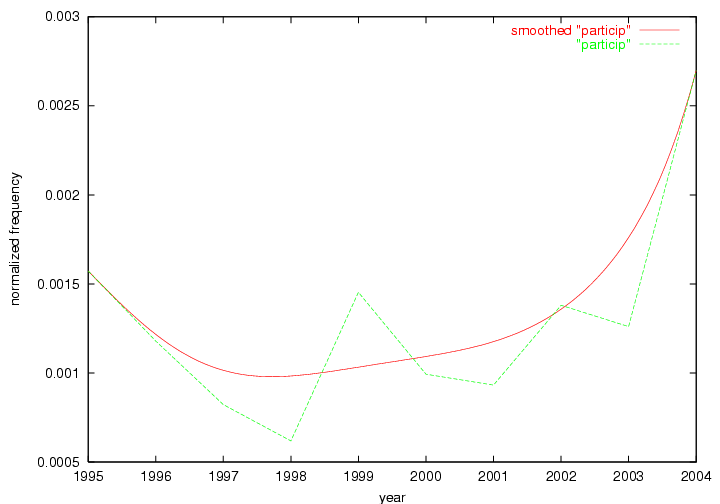
These terms strongly overlap with the stable concepts listed in Table 2. In fact, only 6 of the "central concepts" never occur in the list of "innovations": "develop", "object", "project", "provid", "research" and "work". This indicates that the "central" concepts, even though among the top most frequent terms, still experienced strong shifts in their relative frequencies from one consecutive year to the other. In fact, a term could be among the ten most frequent terms in years 1 and 2, suddenly strongly increase its frequency in year 3, and thus be registered among the group of "innovations". Other terms may silently grow in frequency over the years, never to achieve particular spikes in occurrence frequency and thus not be detected by this methodology as "innovations". Conversely, a term may not be among the most frequent in any year, but may have experienced sufficient spikes in occurrence frequency so that it can still be counted among the "innovations". Indeed, this is a short-coming of this approach. Term frequency is an intuitive but coarse indicator of a term's "importance" or "innovation" value. We are currently developing more advanced methodologies which exploit the structural, temporal features of term-term relationships to avoid these shortcomings and provide a more nuanced, detailed analysis. Table 4 nevertheless highlights a number of interesting trends associated with innovation and shifts of interest in the DL community. To elucidate these trends, we plotted the 10-year frequency evolution of all terms which experienced short spikes in their occurrence frequency. These graphs indicate how the frequency of these terms has evolved over the years, and thus how the DL community has changed its focus. A particularly interesting case is the term "preserv" (Figure 1). Its steadily increasing frequency throughout the years corresponds to our observation of it becoming a more important topic in the study of digital libraries (NDIIPP, 2002). However, it is not until 2004 that it gains enough of a positive increase to emerge as an "innovation".
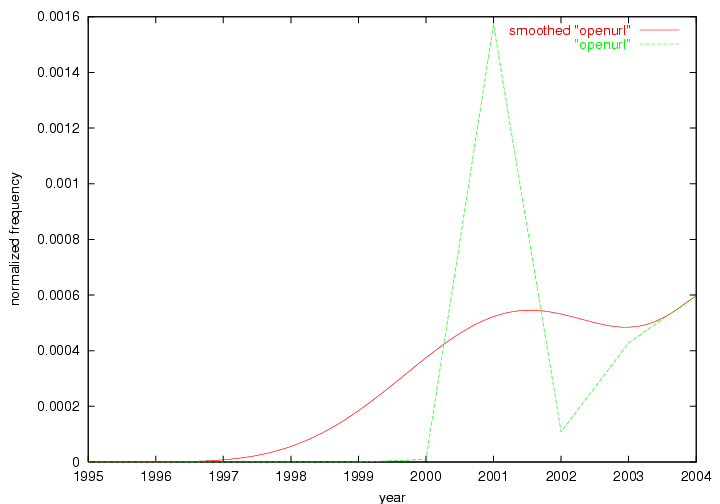
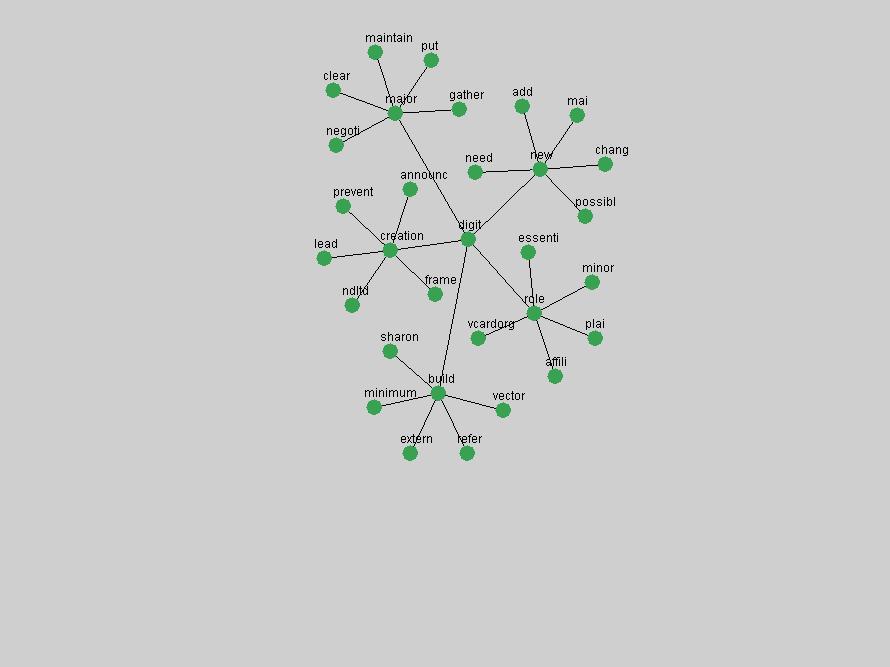
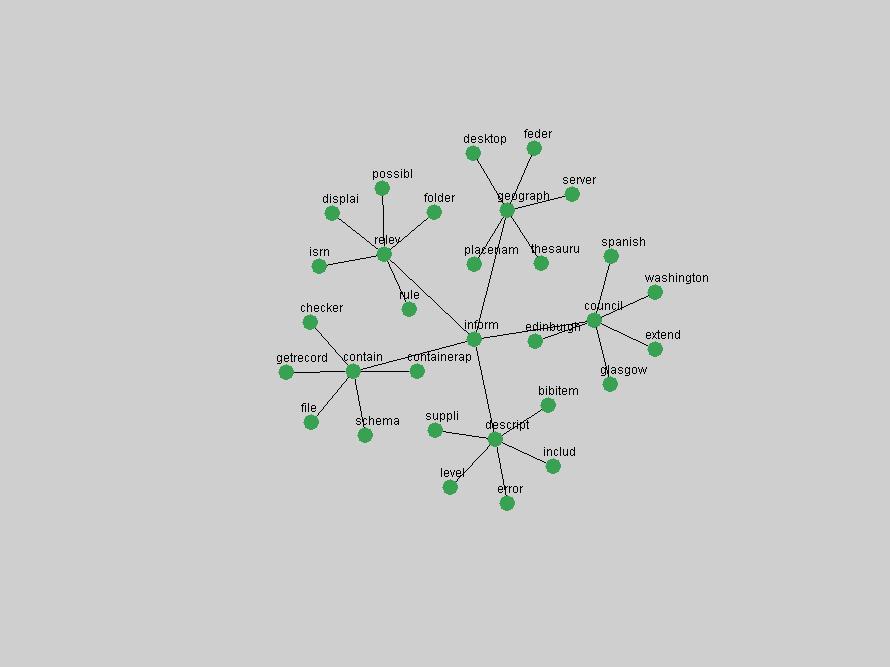
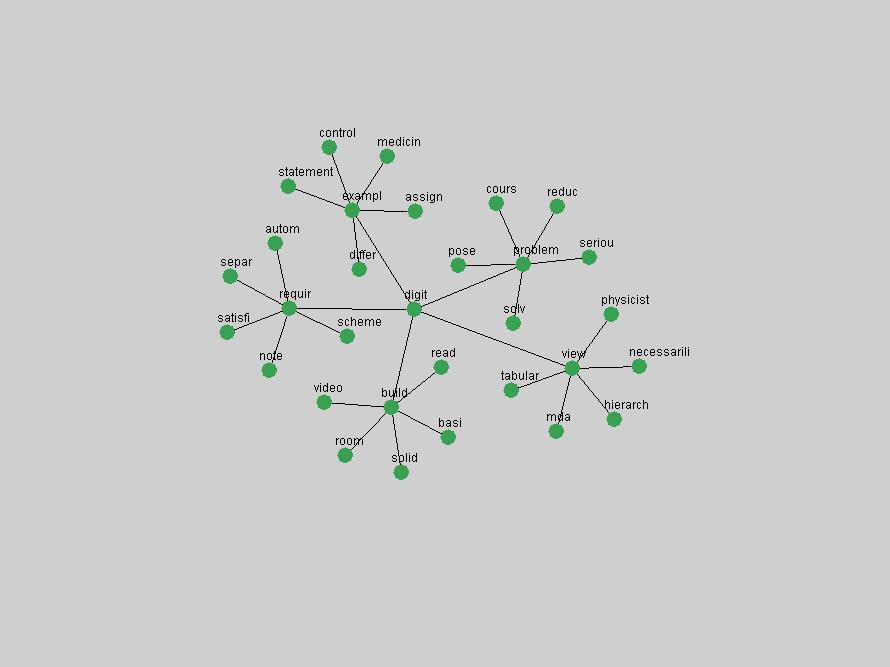
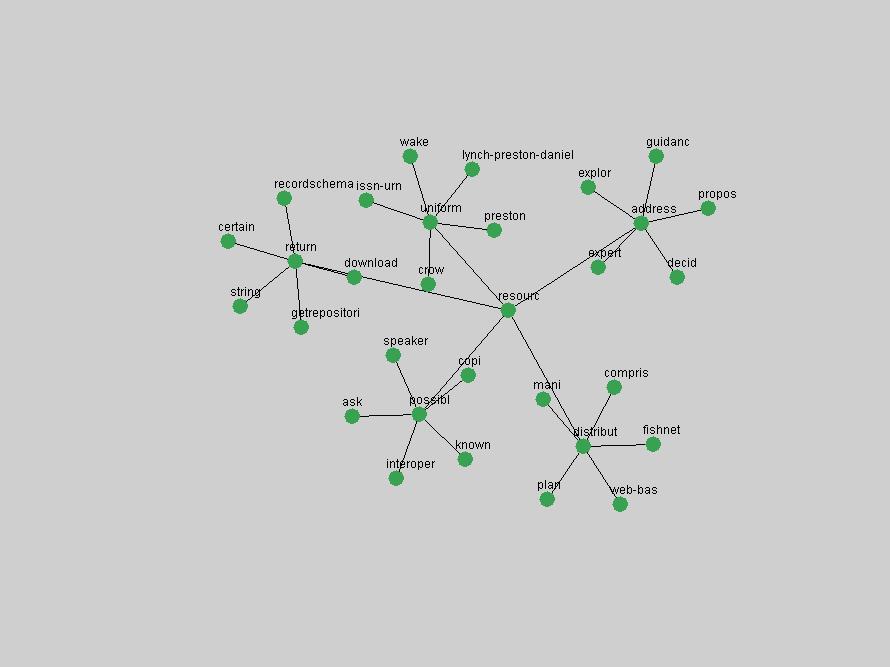
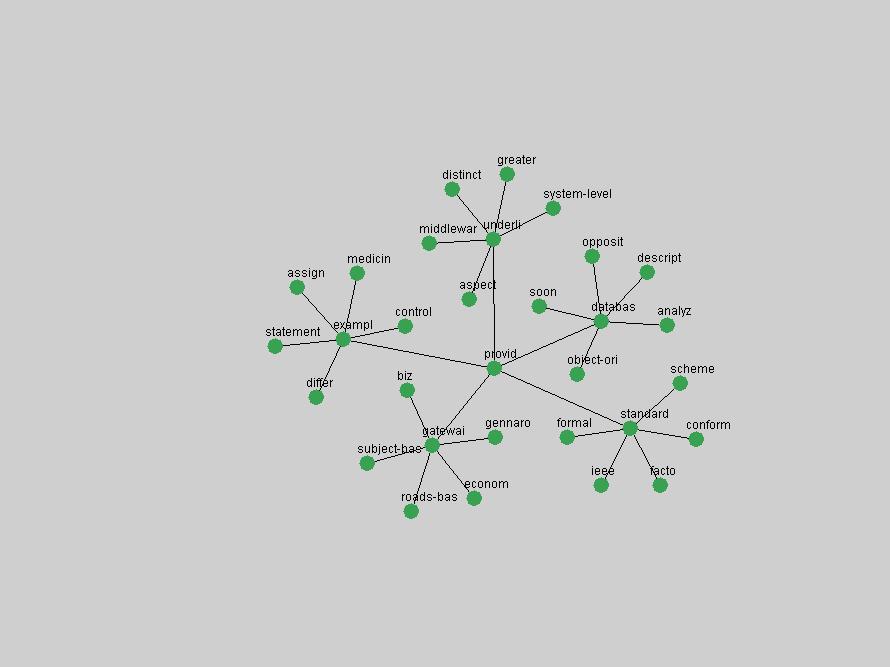
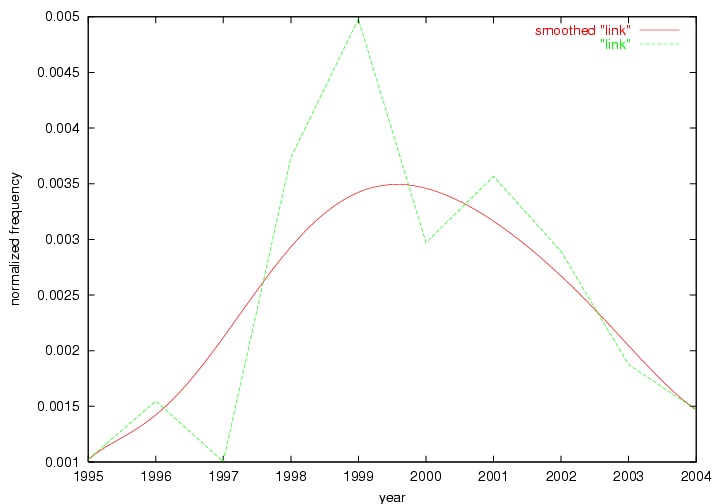
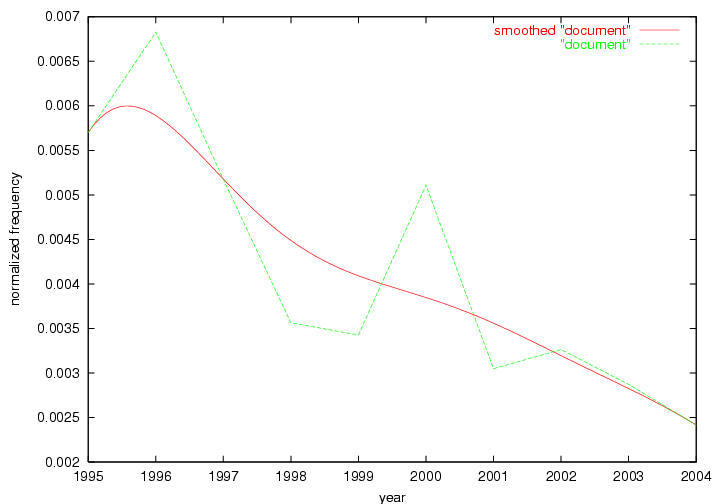
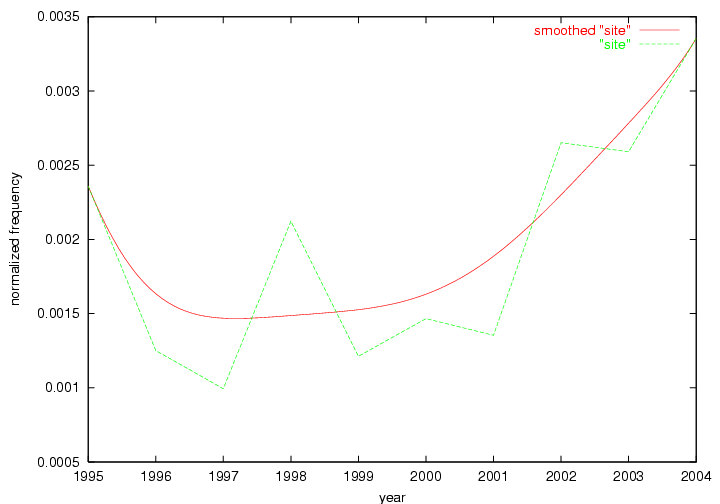
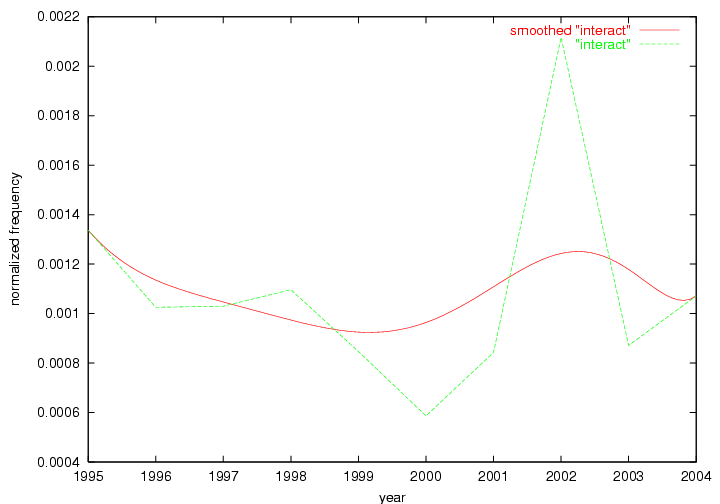
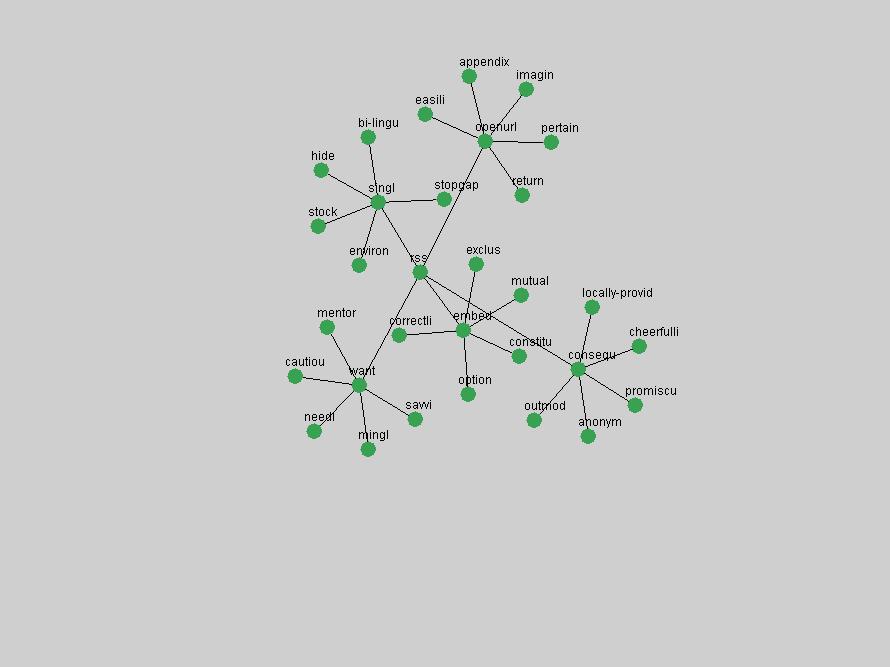
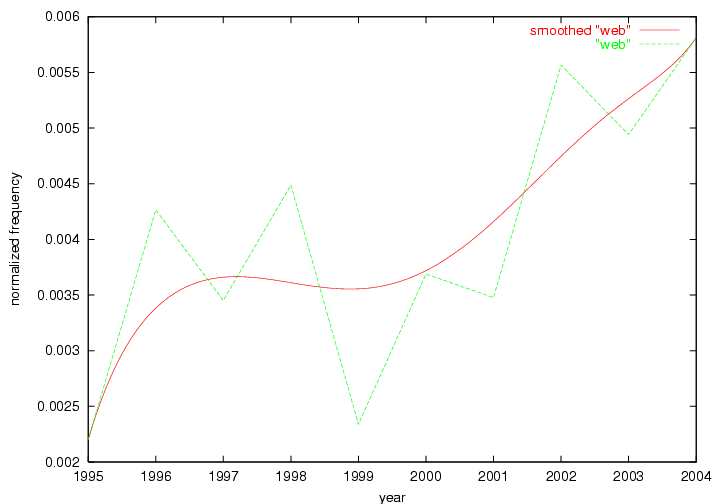
The term "openurl" (Figure 2) reveals an interesting pattern: it first appeared in 2001 when a number of seminal papers on the subject were published (Van de Sompel & Beit-Arie, 2001a; Van de Sompel & Beit-Arie, 2001b). Discussion dropped off in the corpus in 2002 but began to climb again in 2003 and 2004 as the institutional acceptance of OpenURL increased.
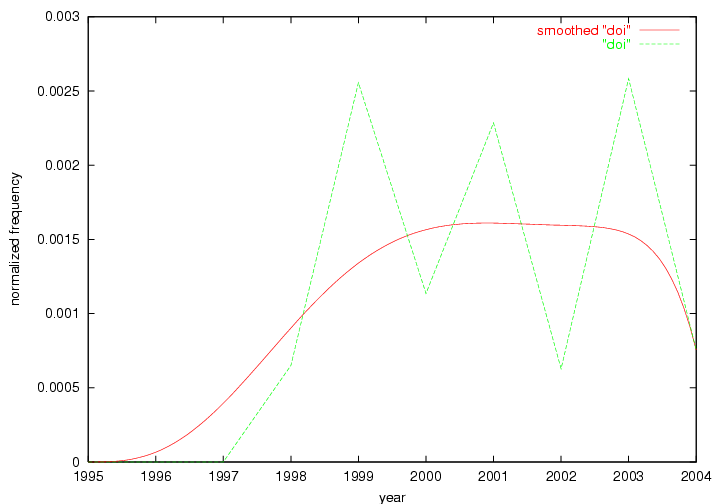
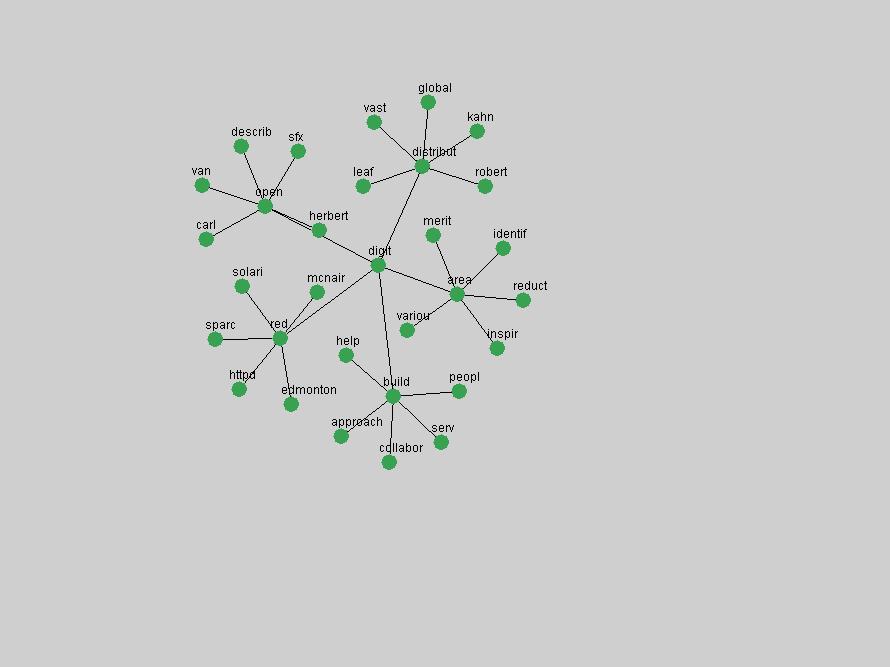
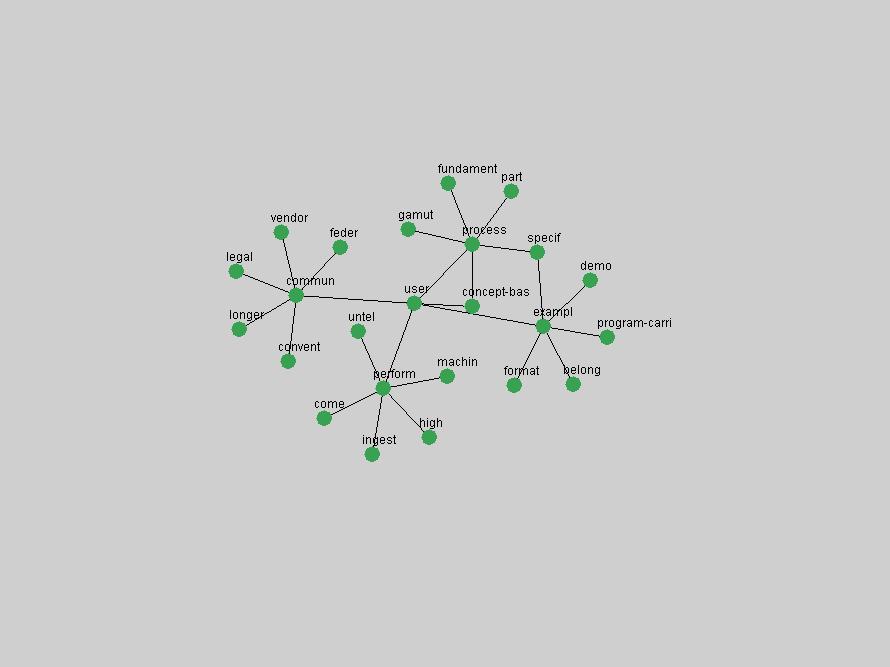
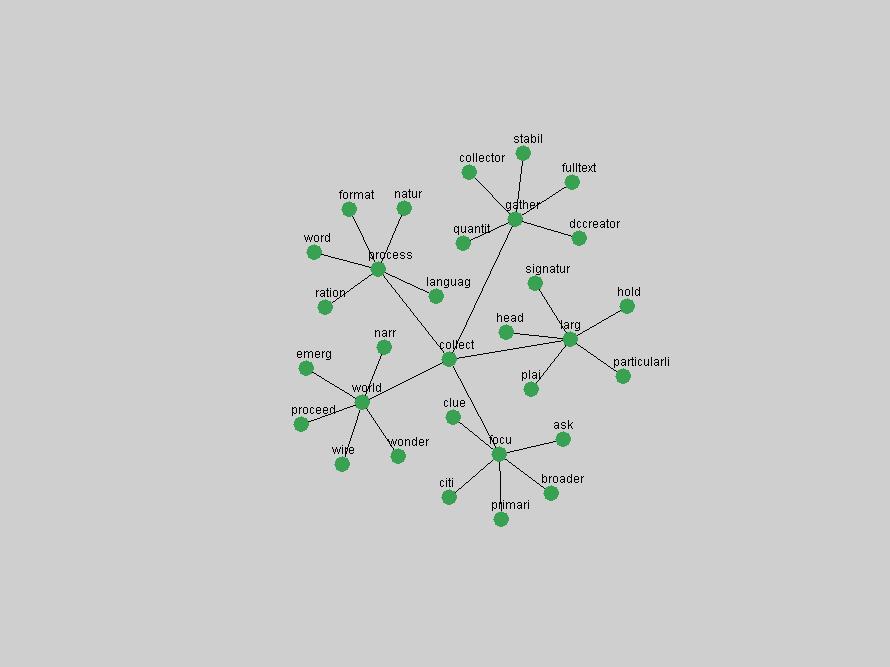
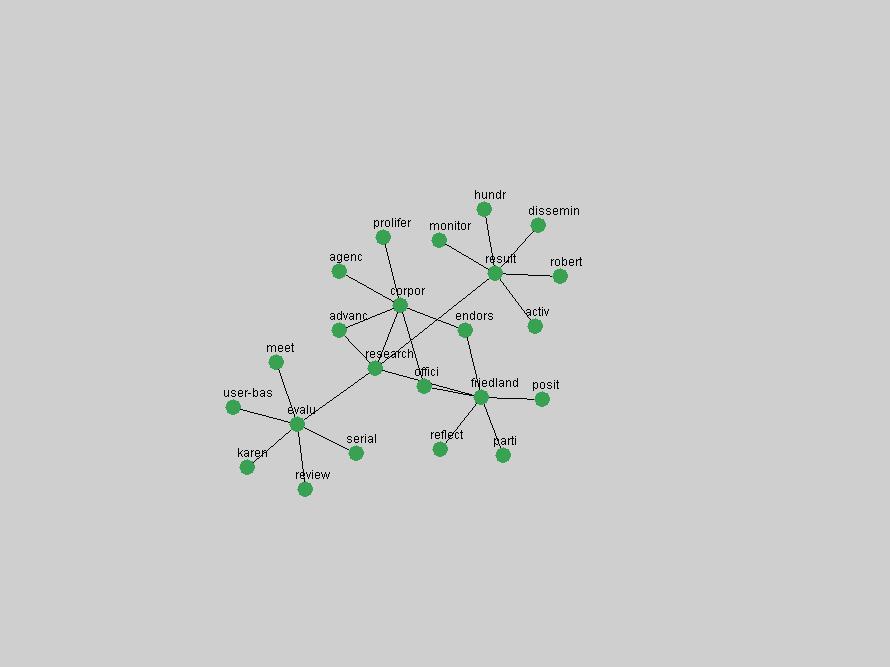
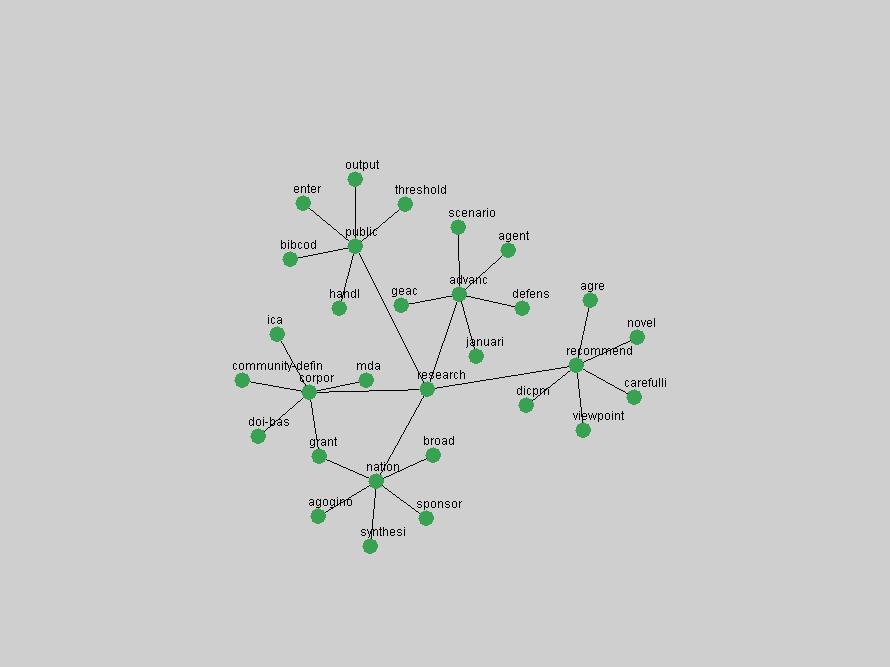
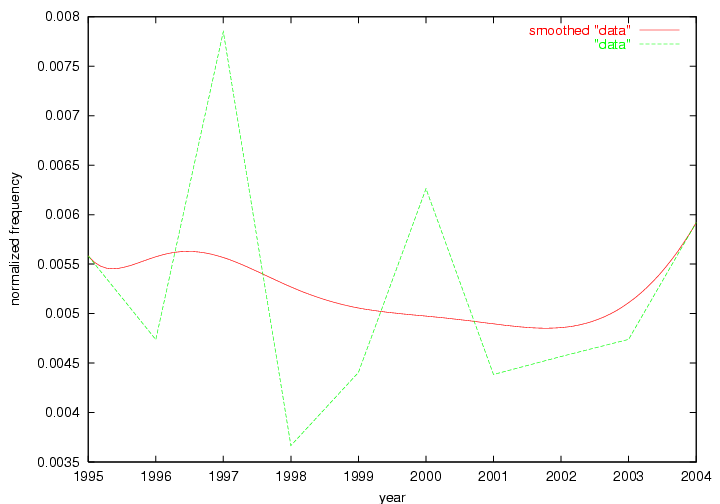
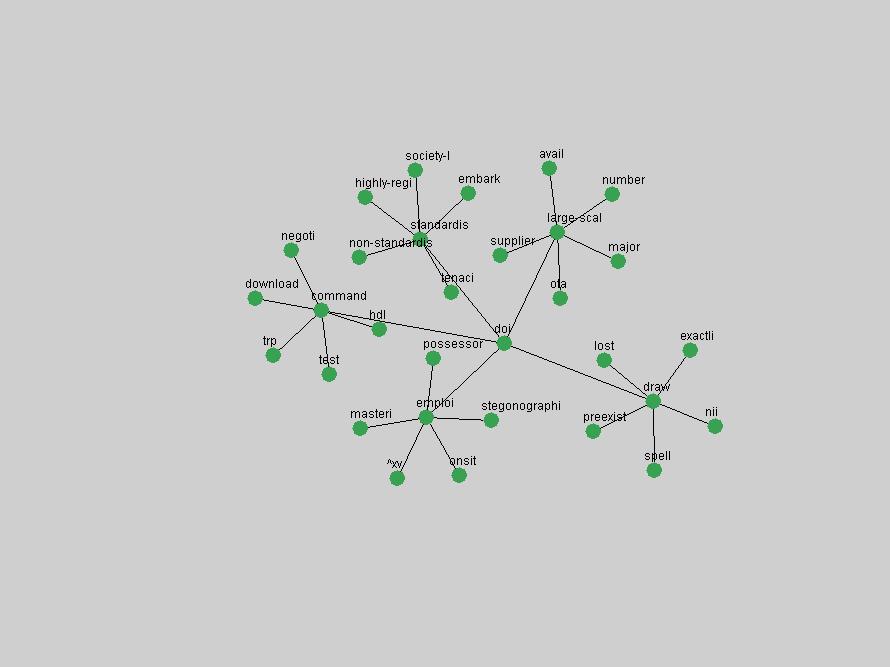
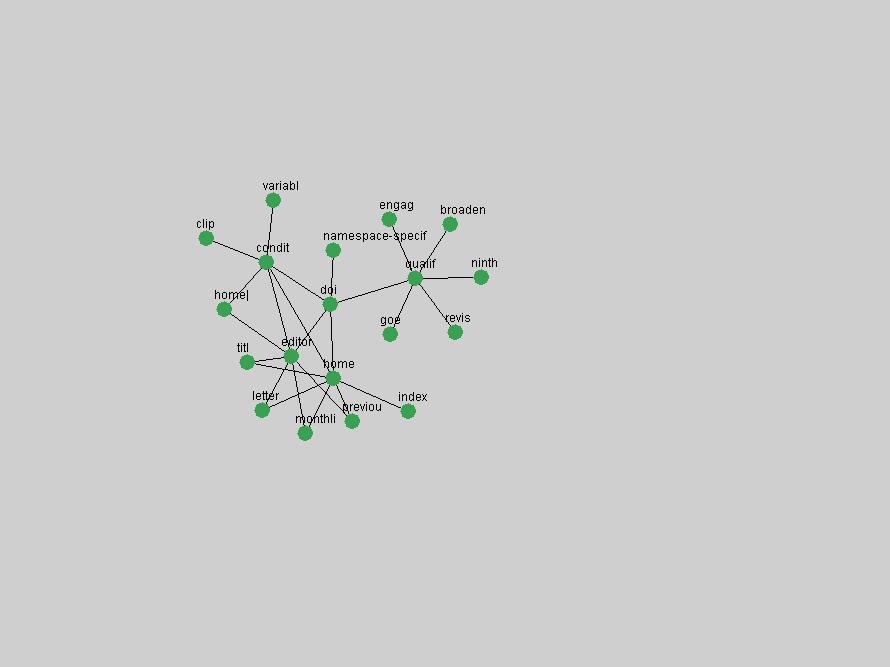
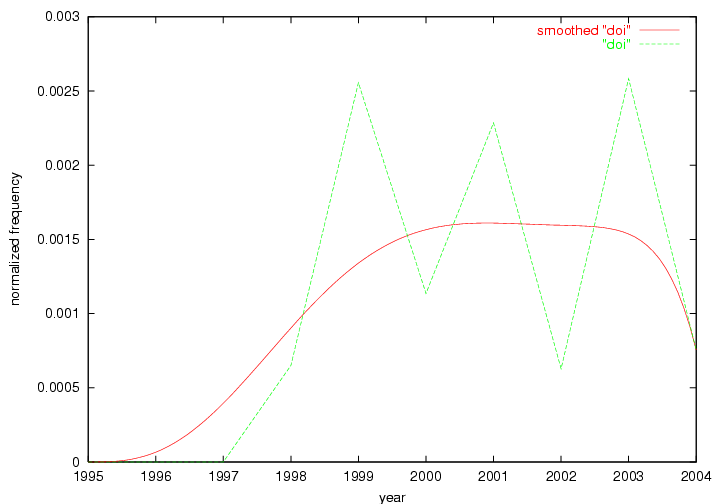
Some terms display other patterns of frequency shifts. The term "doi" (Figure 3) steadily increased in frequency from 1998 to a set of spikes in 1999, 2001 and 2003 when status and project reports were published (Paskin, 1999; Beit-Arie et al., 2001; Paskin, 2003). The aggregate pattern is one of growth and subsequent stabilization.
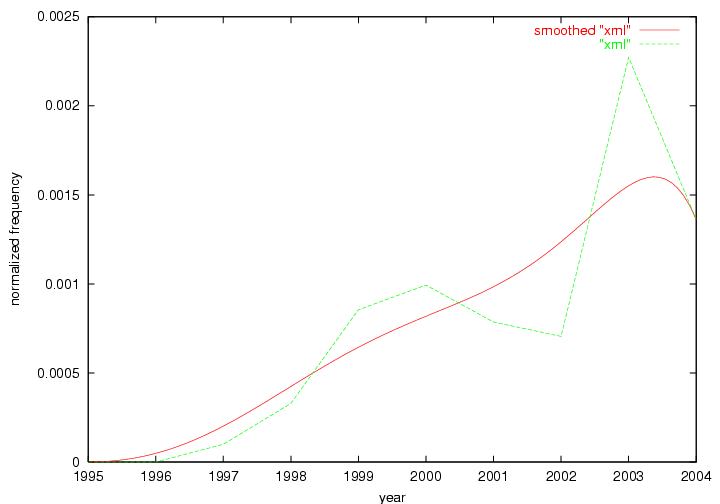
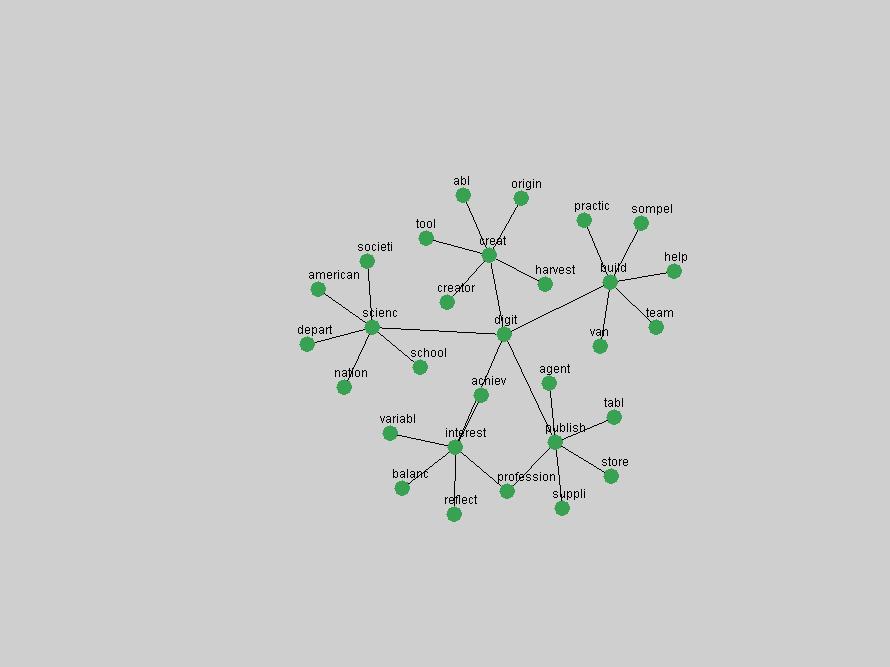
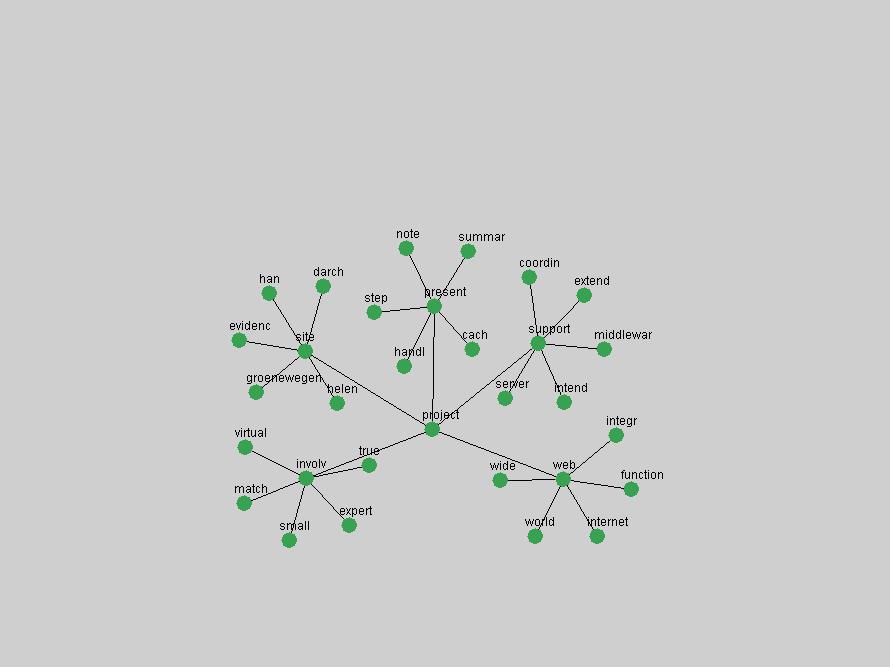
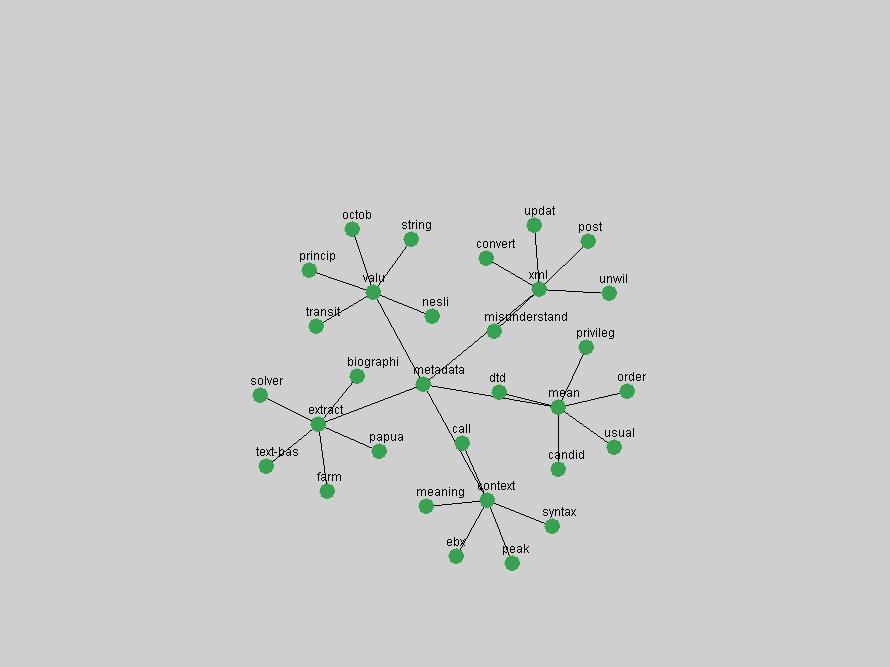
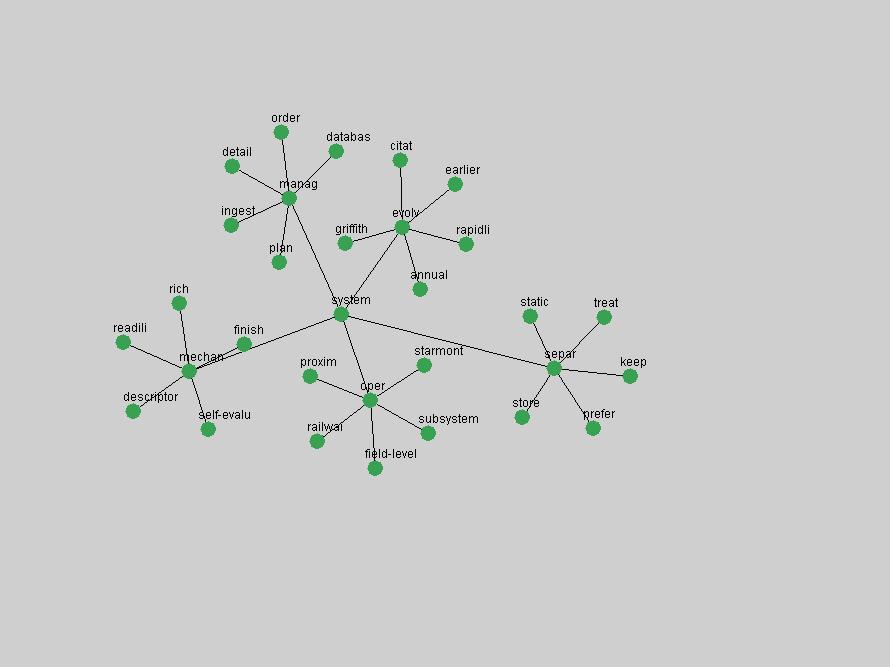
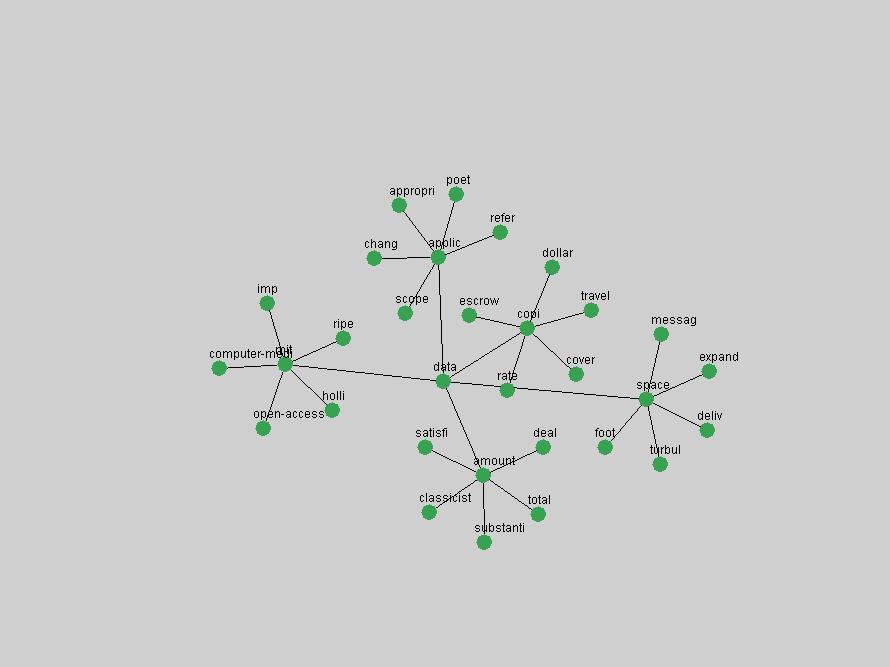
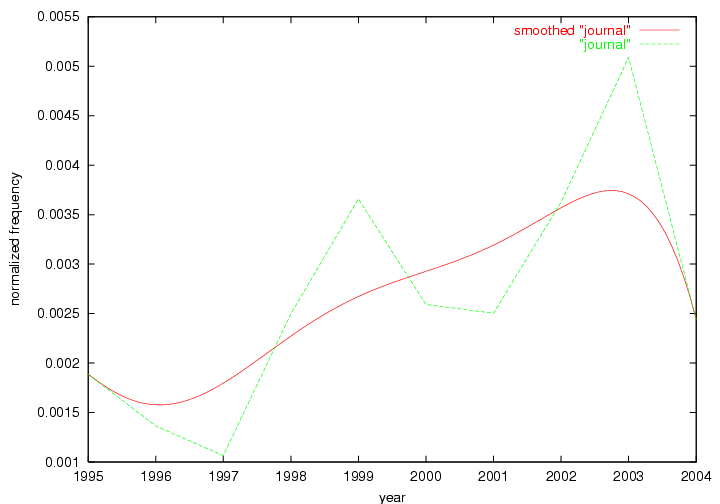
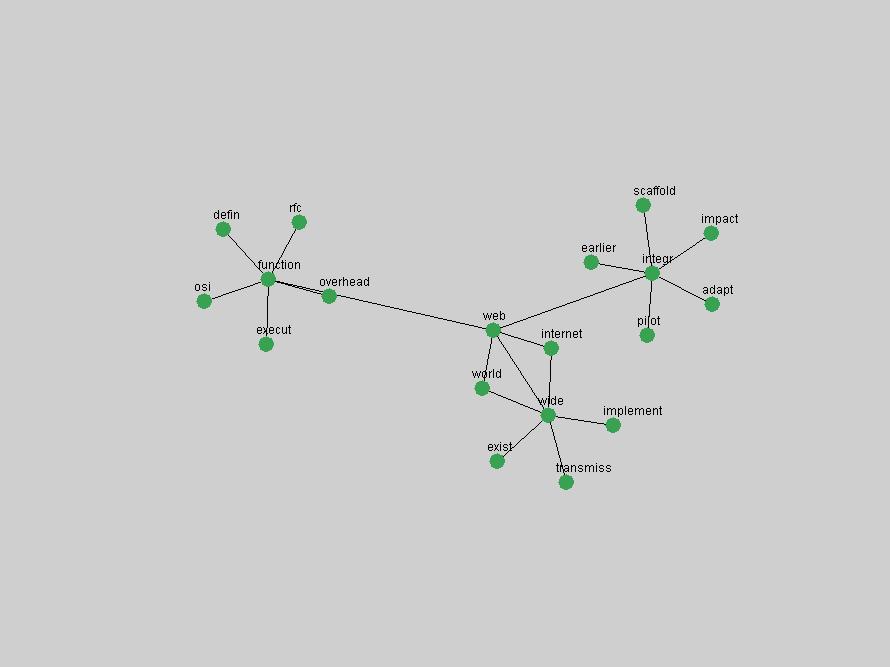
An example of a term that has increased its frequency in a steady, stable pattern of growth is "xml" (Figure 4). Starting in 1997 to 2004 it has continuously grown in frequency. Although there have been small declines and large jumps in particular years, the trend is clearly one of stable growth.
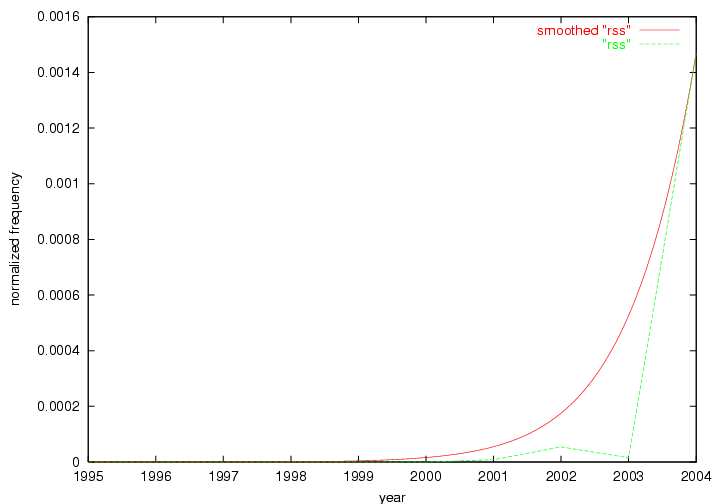
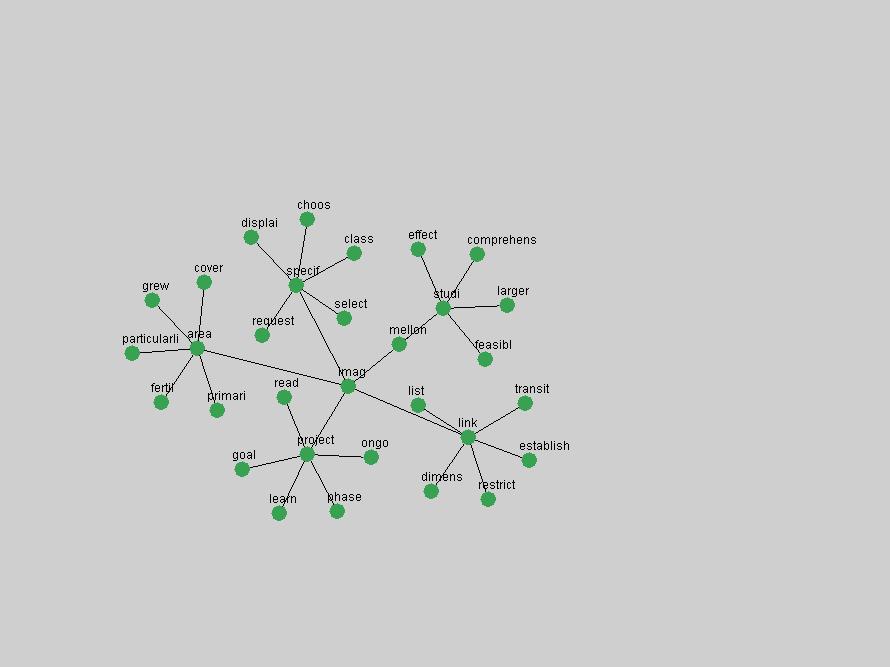
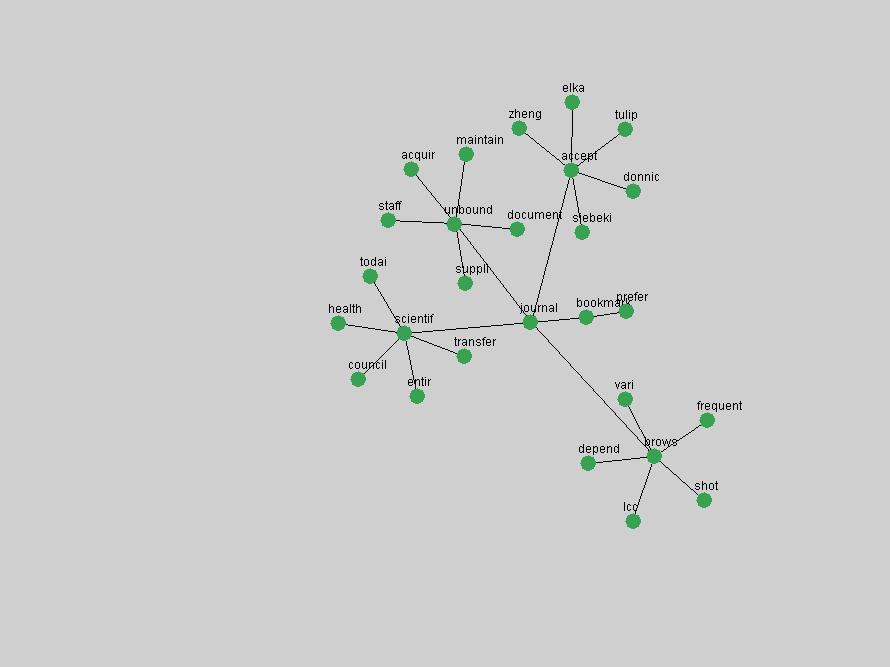
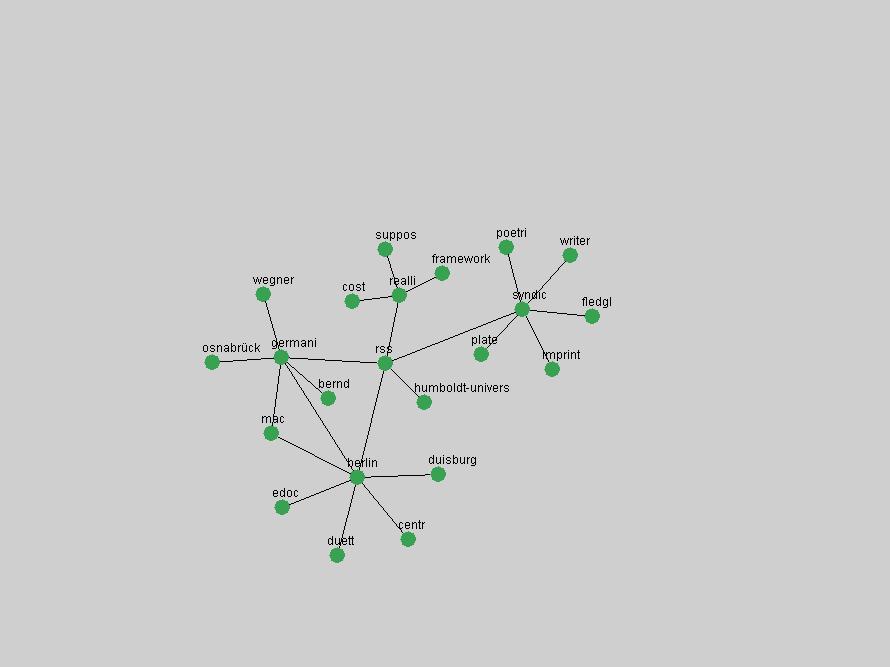
"RSS" (Figure 5) has existed in its current form since 1999 (Reagle, 2004). The frequency graph of the term, and its appearance in the "innovations" list in 2004 however indicates that it has only recently attracted the attention of the DL community.
The maturation of the NSDL community is evidenced from the evolution of the term "nsdl" (Figure 6) in D-Lib Magazine. Its appearance in the list of "innovations" is due to a spike in term frequency occurring in 2003-2004. It was first mentioned in 1998, was discussed in earnest in 2001 and has since demonstrated continued growth.
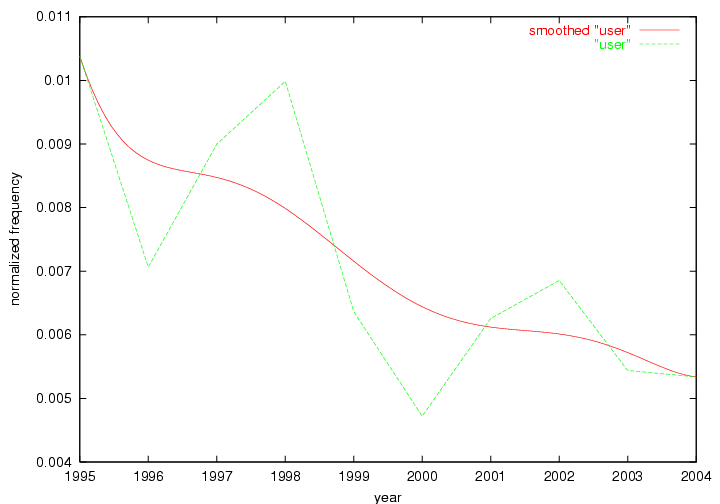
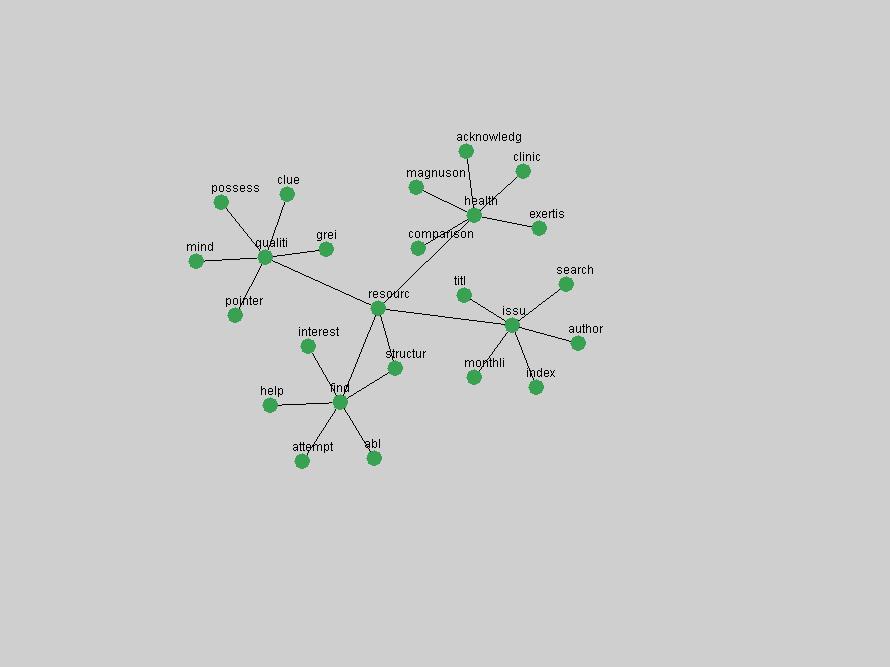
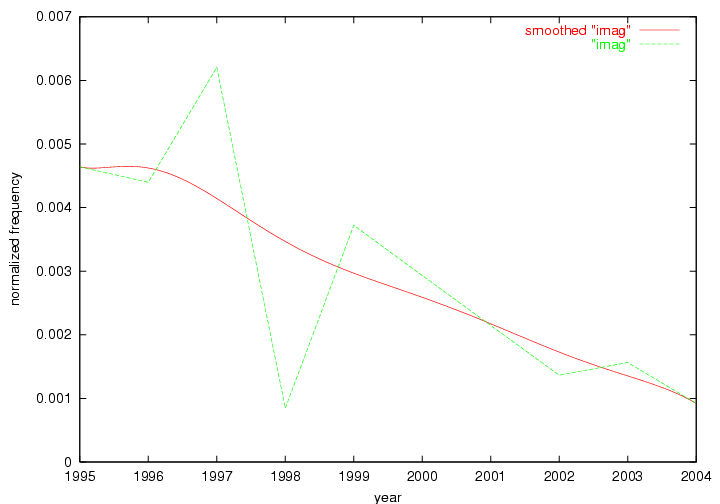
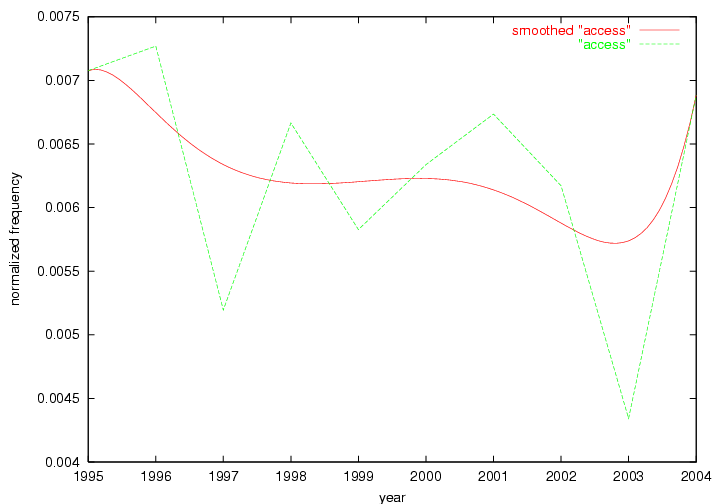
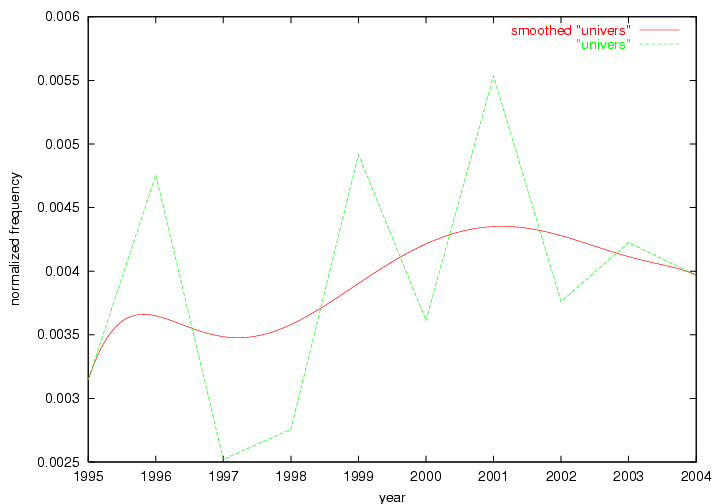
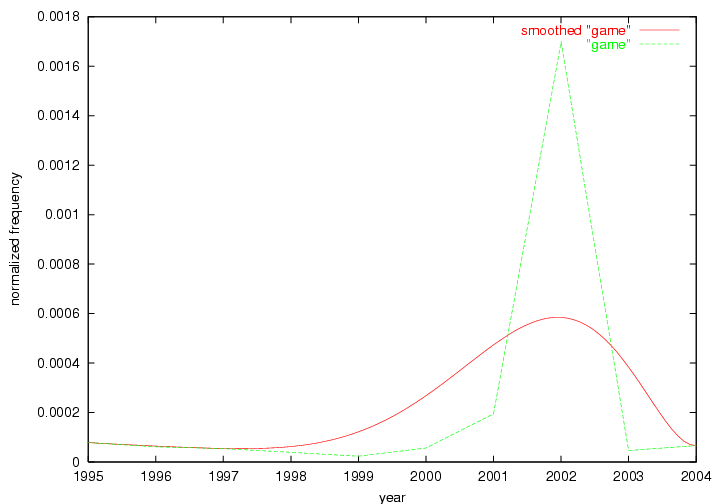
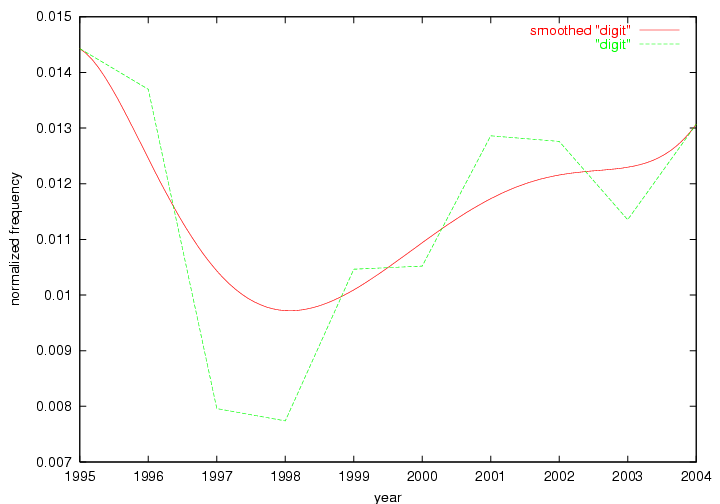
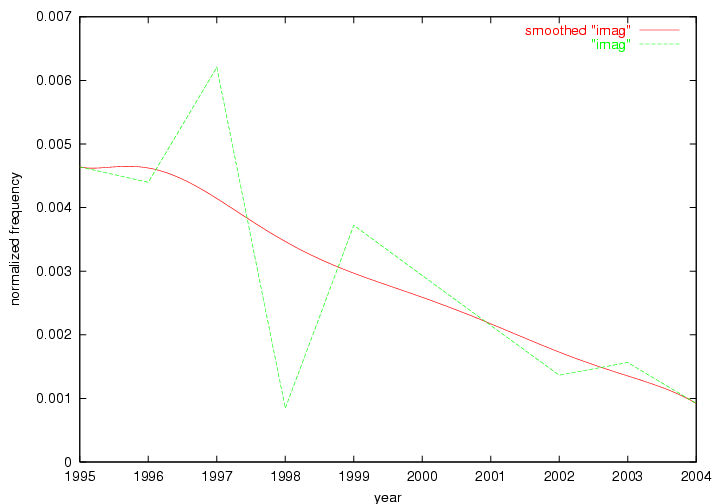
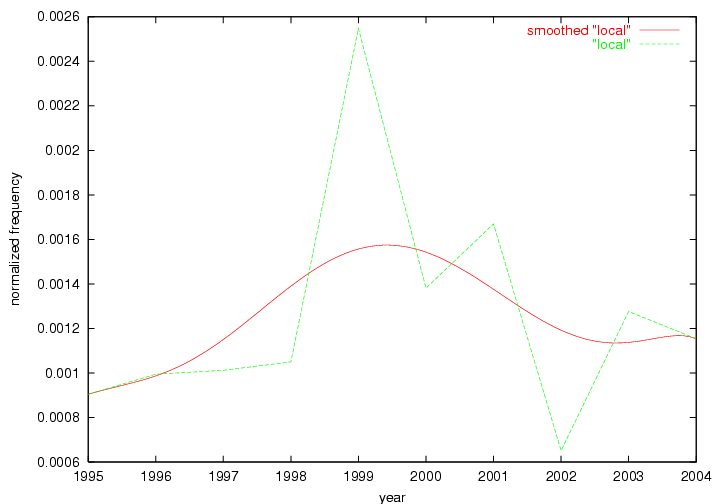
Oddly, the term "user" (Figure 7), although highly general, has experienced a gradual decline in term frequency since its spikes in 1995 and 1998. Several hypothesis could be proposed to explain this phenomenon. New terms may have supplanted "user" to denote similar concepts, or this area is receiving less attention because it is generally considered to be a "solved" problem. A similar phenomenon may be observed for the term "image" which has experienced a declining frequency over the past 10 years.
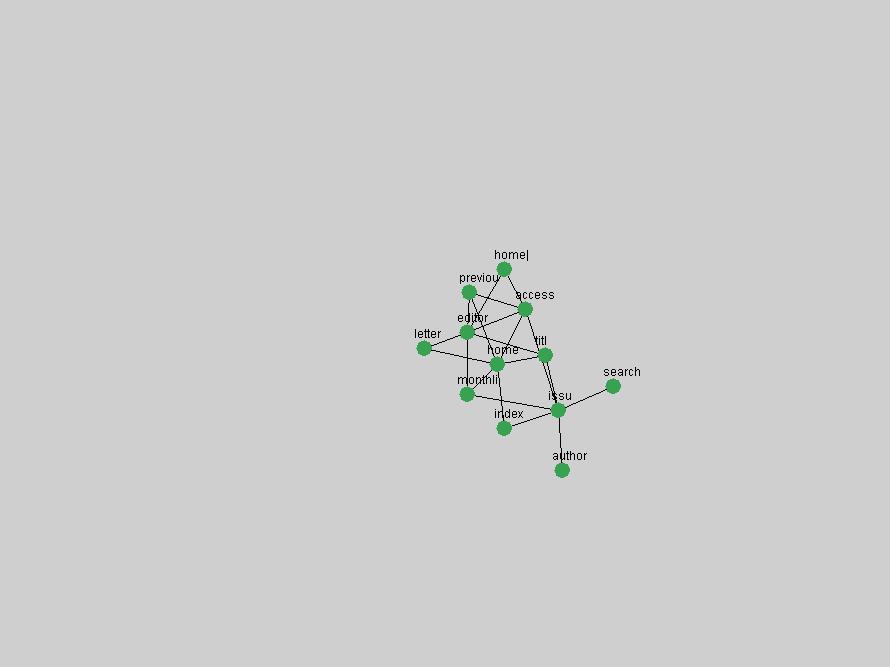
Some terms are conspicuous by their absence. The Open Archives Initiative (OAI) (Lagoze & Van de Sompel, 2003). just missed being an "innovation" in 2001, scoring as the 11th term undergoing the largest positive frequency jump from 2000. However, the multitude of terms that authors have used to describe this concept ("OAI", "OAI-PMH", "OAI-Compliant", "OAI-Compatible", etc.) limits the visibility of the concept in the frequency-based methods. 3. Conclusions and Future WorkD-Lib Magazine constitutes an attractive corpus for detecting trends: publications are characterized by a low publication latency, it is published monthly, and its focus is on summary and "awareness" types of articles. In our analysis, we have identified terms that are both of stable importance to the community and the ones that have experienced rapid positive shifts in interest. We observed that D-Lib Magazine has a strong, stable focus on a relatively small set of central concepts that were unsurprisingly represented by the terms "digital", "library" and "information". The number of unique terms associated with innovations over the past 10 years was higher but overlapped to a large degree with the list of stable "central" concepts, indicating that certain terms, such as "metadata", which have been discussed for extensive periods will steadily grow in importance to be established as a central focus of the D-Lib community. Future work will focus on expanding this methodology to avoid the limitations of frequency-based indicators. Frequency simply corresponds to how often something is mentioned, not necessarily its true underlying importance to a community. Shifts in occurrence frequency are therefore not accurate indicators of innovations and changes in interest. Nevertheless, some interesting patterns have been detected and term frequency is easily and efficiently derived from any corpus. It can therefore be used to compare and cross-validate trends in other publications. In other words, we can study trends within the texts of a particular publication, or apply the same analysis to multiple collections so that we can compare and cross-validate the observed trends for different communities. Long-time readers of D-Lib Magazine may find that the identified "central concepts" and "innovations" match their intuition and recollection of the past 10 years. However, newcomers who did not have the benefit of perusing every issue the day it originally was published may benefit from this automated analysis and summarization of the main lines of thought and evolutions within the DL community. We are working to expand the tools presented here for more general corpus summarization and exploration purposes. ReferencesBeit-Arie, O., Blake, M., Caplan, P., Flecker, D., Ingoldsby, T., Lannom, L., Mischo, W. H., Pentz, E., Rogers, S. & Van de Sompel, H. (2001). "Linking to the Appropriate Copy: Report of a DOI-Based Prototype", D-Lib Magazine 7(9). Available at: <doi:10.1045/september2001-caplan>. Kleinberg, J. "Bursty and hierarchical structure in streams." In KDD '02: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 91-101. ACM Press, 2002 Lagoze, C. & Van de Sompel, H. (2003). "The Making of the Open Archives Initiative Protocol for Metadata Harvesting", Library Hi-Tech 21(2), pp. 118-128. NDIIPP, (2002). "Preserving Our Digital Heritage: Plan for the National Digital Information Infrastructure and Preservation Program". Available at: <http://www.digitalpreservation.gov/index.php?nav=3&subnav=1>. Paskin, N. (1999). "DOI: Current Status and Outlook", D-Lib Magazine 5(5). Available at: <doi:10.1045/may99-paskin>. Paskin, N. (2003). "DOI: A 2003 Progress Report", D-Lib Magazine 9(6). Available at: <doi:10.1045/june2003-paskin>. Porter, M. (1980). "An Algorithm for Suffix Stripping", Automated Library and Information Systems, 14(3), pp. 130-137. Reagle, J. (2004). "Web RSS (Syndication) History". Available at: <http://goatee.net/2003/rss-history.html>. Van de Sompel & Beit-Arie (2001a). "Open Linking in the Scholarly Information Environment Using the OpenURL Framework", D-Lib Magazine 7(3). Available at: <doi:10.1045/march2001-vandsompel>. Van de Sompel & Beit-Arie (2001b). "Generalizing the OpenURL Framework Beyond References to Scholarly Works: The Bison-Futé Mode", D-Lib Magazine 7(7/8). Available at: <doi:10.1045/july2001-vandesompel>. Weibel, S. (1995). "Metadata: The Foundations of Resource Description", D-Lib Magazine 1(1). Available at: <doi:10.1045/july95-weibel>. Wilson, B. (2004). "About D-Lib Magazine", Available at: <http://www.dlib.org/about.html>. (On January 18, 2005, at the authors' request an incorrect reference was removed from this article.) Copyright © 2005 Johan Bollen, Michael L. Nelson, Giridhar Manepalli, Giridhar Nandigam and Suchitra Manepalli |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/january2005-bollen
|
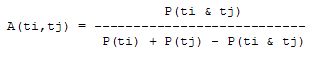

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}