 |
D-Lib Magazine
January/February 2011
Volume 17, Number 1/2
Table of Contents
Supporting Science through the Interoperability of Data and Articles
IJsbrand Jan Aalbersberg
Elsevier, S&T Journals, Content Innovation, The Netherlands
ij.j.aalbersberg@elsevier.com
Ove Kähler
Elsevier, S&T Journals, Content Innovation, The Netherlands
o.kahler@elsevier.com
doi:10.1045/january2011-aalbersberg
Printer-friendly Version
Abstract
Whereas it is established practice to publish relevant findings of a research project in a scientific article, there are no standards yet as to whether and how to make the underlying research data publicly accessible. According to the recent PARSE.Insight study of the EU, over 84% of scientists think it is useful to link underlying digital research data to peer-reviewed literature.[1] This trend is reinforced by funding bodies, who — to an increasing extent — require the grantees to deposit their raw datasets at freely accessible repositories.[2] And also the publishing industry believes that raw datasets should be made freely accessible.[3]. This article presents an overview of how Elsevier as a scientific publisher with over 2,000 journals gives context to articles that are available on their full-text platform SciVerse ScienceDirect, by linking out to externally hosted data at the article level, at the entity level, and in a deeply integrated way. With this overview, Elsevier invites dataset repositories to collaborate with publishers to create an optimal interoperability between the formal scientific literature and the associated research data — improving the scientific workflow and ultimately supporting science.
Introduction
Content innovation at Elsevier is about improving the peer-reviewed scientific communication between the author and the reader. For centuries this communication has taken place based on the traditional print format — though more recently in the form of the PDF. Whereas the digital revolution brought great improvements to many processes around scholarly communication (like submission, discoverability, access, and archiving), it has had almost no impact on its content, format, and presentation, i.e., on the scientific article itself. One of the ways Elsevier aims at utilizing the new digital possibilities to add value to the scientific article is by putting it in context with external resources that are related to the article and relevant to the respective research community. This can be achieved in two ways.
-
Linking out from SciVerse ScienceDirect to external resources. Currently, there are two types of linking capabilities in place:
- dataset linking (based on the DOI of an article) and
- entity linking (based on semantic tagging of entities in an article).
- Pulling data from external resources into SciVerse ScienceDirect. A recent example of such a contextualisation is the Protein Viewer, which makes 3D images of proteins from the Protein Data Bank (PDB) available within protein-related articles on SciVerse ScienceDirect.
In the following we will detail and describe examples of these three types of "internet wiring" between scientific articles and research datasets. It thus serves as an invitation to dataset repositories to actively collaborate with publishers to provide a seamless interoperability between scientific articles and their associated datasets, which will result in an improved workflow for the scientist.
Dataset linking
Scientific research is all about collaboration and never limited to one information source only. In recent years, more and more digital repositories have been set up to host research data in the different fields. Even among information scientists, there is no consensus on the number of such repositories, but "there are clearly thousands in existence" [4]. Not to mention the amount of actual data stored in these repositories, as their individual datasets could easily amount to many terabytes of data in fields like earth and planetary sciences. [5]
It is customary on the web that if information is not sufficiently interlinked with other relevant information, it tends to be invisible and thus unused. This also applies to research data: if such data in a data repository is not connected to the relevant literature, it is invisible and then the use and re-use of the data is limited.
"Dataset linking" aims at bridging this gap that occurs when a research article is available on a publisher's full-text platform such as SciVerse ScienceDirect, while the underlying dataset is hosted on an entirely different service. It is Elsevier's objective to connect such datasets with the article in a bi-directional way: both from the article at SciVerse ScienceDirect to the research dataset and from the dataset to the research article.
Linking to a dataset
SciVerse ScienceDirect has created a generic mechanism to link from articles to datasets. It is based on using the article's DOI as the common linking pin between an article and its dataset, and it enables the dataset repository to position a link to the dataset on the SciVerse ScienceDirect article page. The associated workflow consists of the following five distinct steps:
- Author submits article to publisher.
- Author submits dataset to repository.
- At article publication, repository connects article DOI to associated dataset.
- At article rendering/presentation, repository creates a link (when available).
- SciVerse ScienceDirect user sees (and can follow) link to repository from SciVerse ScienceDirect.
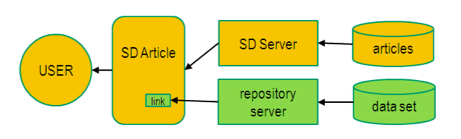 Figure 1: Dataset linking — using image-based linking.
Figure 1: Dataset linking — using image-based linking.
The linking mechanism being used between SciVerse ScienceDirect and the data repository is so-called "image-based linking" (see Figure 1). Every time a user views the HTML version of an article, an image-link request containing the article DOI is sent to the external repository, asking whether a dataset is available for that article.
- If yes, then a visible image with the hyperlink to that dataset is returned and will thus indicate to the user that the data repository holds a dataset for this article.
- If not, then the repository also returns an image, but now the image is a transparent 1x1 pixel image. As this image is not visible to the user, s/he does not see a link to any data (at that repository).
Current status of dataset linking
So far, Elsevier has established linking cooperation with two dataset repositories.
Note: in July 2010, the interoperability with PANGAEA was expanded by also embedding a Google Maps application created by PANGAEA for those articles, where such a map is available (see further below).
- CCDC. In September 2010, dataset linking was set up for CCDC (Cambridge Crystallographic Data Center) with the Cambridge Structural Database (CSD), a leading repository of small-molecule crystal structures — see Figure 2 (r).
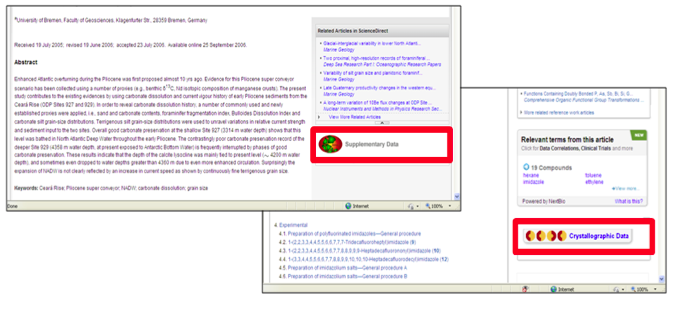 Figure 2: Dataset linking to PANGAEA (l) and CCDC (r).
Figure 2: Dataset linking to PANGAEA (l) and CCDC (r).
Entity linking
Next to dataset linking, which usually concerns linking from the article as a whole, SciVerse ScienceDirect also allows linking from "entities" — mentioned in the full text — to related datasets. "Entities" in this context are occurrences of a discipline-specific concept used by researchers to communicate and categorize the objects in their research. A concept can be of different origins:
- It can be related to a specific resource (e.g., PDB accession numbers for entries in the Protein Data Bank).
- It can be an agreed communication standard independent from a specific resource (e.g., species names in biology).
Linking from entities in an article on SciVerse ScienceDirect to external resources (e.g., the Protein Data Bank or a biodiversity database) requires two distinct steps:
- Identify the entities in the article.
- Create the actual links in the HTML.
Step 1: Identify the entities in the article
Entity identification can be done either manually (by the author) or automatically (through text-mining).
- A manual mark-up will have higher accuracy (as authors know exactly what entities to refer to), but lower recall (as authors will overlook entities in their article or because they are simply not aware of our mark-up guidelines). Author mark-up has an additional advantage in that an author is also capable of distinguishing between the key entities in the article, and e.g., those that are merely serving as examples.
- The text-mining approach will have higher recall (because all instances of correctly spelled entities will be recognized and marked-up), but (potentially) lower precision (because ambiguities will not be taken into account). On the other hand, text-mining — especially when done while rendering the article — has the advantage that it can be re-done when new insights and entity databases have become available.
Step 2: Creating the actual links in the HTML
Once a user opens an article page on SciVerse ScienceDirect, the marked-up entities are rendered as hyperlinks pointing at the defined target resource (see Figure 3). A necessary condition is that the URL structure of the target database caters for entity-related URLs — which is unfortunately not yet the case with all domain-specific databases.
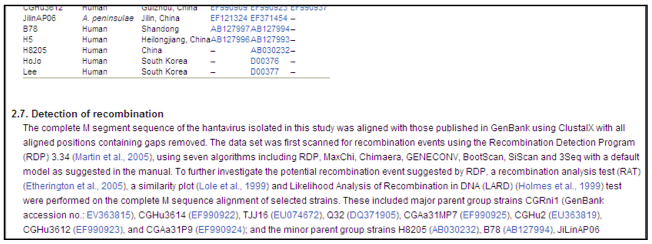 Figure 3: Article on SciVerse ScienceDirect, where entities (in this case: Genbank Accession numbers) appear as hyperlinks in a table as well as in the text.
Figure 3: Article on SciVerse ScienceDirect, where entities (in this case: Genbank Accession numbers) appear as hyperlinks in a table as well as in the text.
More specifically, the URL of the dataset associated to the entity has to be constructible from an entity-type specific URL base (determined by the entity mark-up) plus an entity-specific modifier. For example, for all protein identifiers from PDB (Protein Data Bank), the shared URL base is "http://www.rcsb.org/pdb/explore.do?structureId=", while the marked-up protein entity (e.g., "2KAF") has to be affixed to it as modifier.
Current status of entity linking
Currently, Elsevier asks authors to mark-up occurrences of a variety of entities — including the following (to learn more about the target resource, click on the linked resource name):
| Name of target resource |
Description of target resource |
Example of entity structure |
| GenBank |
Databases at the National Center for Biotechnical Information at the National Library of Medicine |
BA123456 |
| PDB |
Worldwide Protein Data Bank |
1TUP |
| CCDC |
Cambridge Crystallographic Data Centre |
AI631510 |
| MINT |
Molecular INTeractions Database |
6166710 |
| UniProt |
Universal Protein Resource Knowledgebase |
Q9H0H5 |
In addition to using manual identification of entities by authors, SciVerse ScienceDirect recently also integrated two entity-linking tools that rely exclusively on text-mining: Reflect [6, 7] and NextBio [8, 9] (see Figure 4).
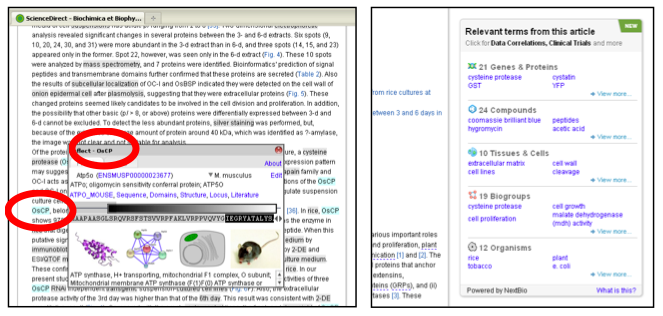 Figure 4: Entity links as created through text mining, using Reflect (l) and NextBio (r).
Figure 4: Entity links as created through text mining, using Reflect (l) and NextBio (r).
Application-based dataset linking
So far, all solutions described to connect an original research article with underlying datasets (as deposited at external data repositories) consist of creating links from the article to the dataset. However, it would be much more user-friendly if the scientist could see within the article itself what to find in the data repository, or even already see the data inside the article: this would require fewer clicks and would keep the context of the article in place. Elsevier offers this possibility in its SciVerse ScienceDirect platform through the capability of applications (see Figure 5).
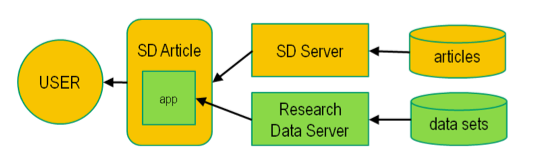 Figure 5: Application-based dataset linking.
Figure 5: Application-based dataset linking.
This capability opens a window in the HTML article page, which can be used by an application to present article-specific data that is extracted in real time from an external dataset repository. Also here we can have two different situations:
- The application is created and run by the external dataset repository. For example, for a wide collection of Earth and Ocean Sciences journals, articles that have their data deposited at PANGAEA are enriched with a map using Google Maps. The map displayed shows all datasets that are associated with this article and deposited at PANGAEA (see Figure 6). [10] Furthermore, both the map as a whole and the individual data points on the map provide links to the datasets deposited.
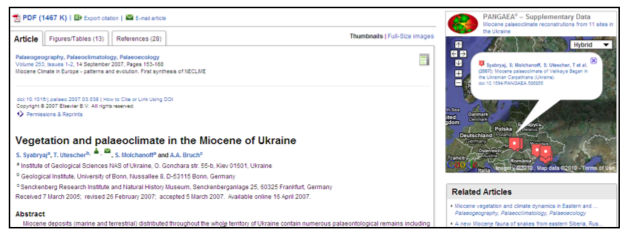 Figure 6: Article on SciVerse ScienceDirect with a Google Maps application created by PANGAEA. Also the data used to construct the map comes from PANGAEA.
Figure 6: Article on SciVerse ScienceDirect with a Google Maps application created by PANGAEA. Also the data used to construct the map comes from PANGAEA.
- The application is created and run by a party other than the external dataset repository. For example, for the Journal of Molecular Biology, articles that have PDB (Protein Data Bank) protein identifiers are enriched with a 3D Protein Viewer (see Figure 7). [11] Using this viewer (run and developed by Elsevier, with data fetched from PDB in real time), scientists are able to investigate the proteins, through rotation, zoom, and e.g., surface selection. For those who want even more information on the proteins, the Protein Viewer also links to the full protein dataset at PDB.
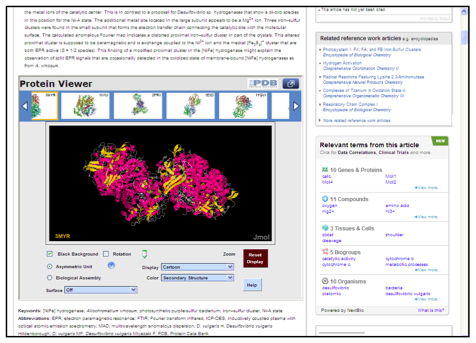 Figure 7: Article on SciVerse ScienceDirect with a Protein Viewer application created by Elsevier. The data is pulled in real time from PDB.
Figure 7: Article on SciVerse ScienceDirect with a Protein Viewer application created by Elsevier. The data is pulled in real time from PDB.
Conclusion
As it has been established by e.g., the PARSE.Insight study, the preservation and therefore deposition of research datasets is of crucial importance to the progress of science. However, preservation and deposition by itself is not sufficient. Research data that cannot be found through, or is not connected to, the associated and peer-reviewed research articles is factually not part of the "official" research information that a researcher can use in his research.
Fortunately, publishers like Elsevier now provide the means to connect research articles with datasets deposited at external data repositories. Obviously, this also requires that such data repositories provide the means to get connected with (i.e., to and from) articles at publisher sites. Organisations like DataCite do play an important role in getting the latter accomplished, by being a single point of contact for publishers and creating a single mechanism to interlink between publishers and data repositories.
The approach of providing links between research articles and datasets can be expanded even further by providing the scientist with access to (an outline of) the data inside the associated research article — with the appropriate links to the external datasets. Also for this, there are a multitude of possibilities, as shown by SciVerse ScienceDirect applications like the PDB Protein Viewer or the PANGAEA Google Maps. The future of intense and seamless interoperability between publishers and data repositories lies wide open in front of us — and Elsevier invites all parties interested in that future to collaborate!
References
[1] http://www.parse-insight.eu/
[2] E.g., http://grants.nih.gov/grants/policy/data_sharing/
[3] http://www.alpsp.org/ForceDownload.asp?id=129
[4] Laura Haak Marcial, Bradley M. Hemminger (2010): Scientific Data Repositories on the Web: An Initial Survey. JASIST 61 (10) 2029-2048. doi:10.1002/asi.21339
[5] Scott Weidman, Thomas Arrison (eds.) (2010): Steps Toward Large-Scale Data Integration in the Sciences: Summary of a Workshop.
[6] http://www.elsevier.com/wps/find/authored_newsitem.cws_home/companynews05_01186
[7] http://www.reflect.ws/
[8] http://www.elsevier.com/wps/find/authored_newsitem.cws_home/companynews05_01249
[9] http://www.nextbio.com/
[10] http://www.elsevier.com/wps/find/authored_newsitem.cws_home/companynews05_01616
[11] http://www.elsevier.com/wps/find/authored_newsitem.cws_home/companynews05_01720
About the Authors
 |
IJsbrand Jan Aalbersberg is VP Content Innovation at Elsevier S&T Journals. Prior to that, he worked in a variety of positions in Elsevier to bridge the gap between publishing and technology. IJsbrand Jan has a PhD in Theoretical Computer Science, and before moving to Elsevier, worked as a research scientist at Philips Research.
|
 |
Ove Kähler is Content Innovation Manager at Elsevier S&T Journals. Prior to that, he was responsible for Scopus content. Before joining Elsevier, Ove worked at Springer and Dow Jones. Ove holds an MBA from Nyenrode University (The Netherlands) and an M.A. from University of Mainz (Germany).
|
|