|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Michael Ashenfelder |
![]()
IntroductionBetween 2008 and 2009 the Library of Congress added approximately 100 TB of data to its digital collections, transferred from universities, publishers, web archivists and other organizations. The data comprised a broad range of content from photos to video, from books and periodicals to websites. Most of the data was transferred over the Internet rather than by hardware media, and for good reason: 650 GB of data shipped on a drive can take weeks from the time the content owner sends it to the time it is finally loaded onto a Library server. The same quantity takes just hours to transfer over the network. While network data transfer has not completely replaced shipping data on hardware storage media to the Library, it is gradually becoming the preferred method. The Library's transfer process is relatively simple and quick, and it utilizes open-source software. This article describes the Library's network data-transfer process. Transferring data on physical mediaThe Library currently receives most digital collections from its National Digital Information Infrastructure and Preservation Program (NDIIPP1) partners, and the number of partners that submit their collections over the network is increasing. For some NDIIPP partners, their preference for shipping drives is not so much a matter of efficiency as habit. Content from the National Digital Newspaper Program2, for example, is still shipped to the Library on external hard drives, mainly because the workflow was designed for drive transfers, it is ongoing and it has been solidly in place for several years. A network-transfer system would be desirable for the program, but the transition from one workflow system to another would take a significant effort. There are advantages and disadvantages to shipping hardware media to the Library. The primary advantage is that the process for hardware-based data transfer is well understood and established. Drives arrive at the Library, get plugged into a workstation, and the data is verified and transferred to its destination. However, there are several potential disadvantages:
The Library estimates that it takes about one month for a drive to make the round-trip from the sender to the Library and back. If a drive fails, the data must be re-shipped on a new drive, which adds weeks to the process. The same amount of data can be transferred over the network to the Library in hours, and if something goes wrong, the problem can be discovered and fixed in a relatively short time. The networkUntil a few years ago, transferring digital content to the Library over the Internet was impractical, because the size of shipments exceeded the capacity of most Internet connections to complete the transaction in a reasonable amount of time. Also, large transfers can monopolize an Internet connection at the sender or receiver's end. That changed when the Library linked to the Internet 2's high-performance network. Not only does the Library now move large data sets over Internet 2, the lessons and techniques the Library has learned over the past few years enable it to optimize and speed up transfers over the commercial "commodity" Internet as well. Network data transfer has fewer "moving parts," so it has fewer potential points of failure. The largest investment is in the initial time for setup and deployment, which varies depending on the condition of the institution's existing network, the availability of resources, the level of staff technological knowledge and the potential expense for materials. Once the initial setup work is finished and the architecture stabilized, the transfer itself is simple. The network data-transfer process comes down to these two steps:
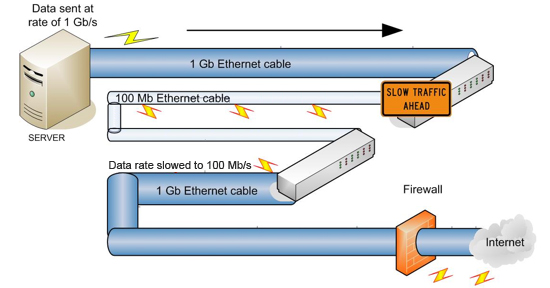
How the sender makes the data available to the Library for download and what the Library does with the data once it is downloaded are both workflow issues that are beyond the scope of this article. The main setup element for network data transfer is optimizing the transfer environment. This requires making all the network components more efficient, from the data server to the cables over which the data will travel to the firewalls through which the data will pass on its way out onto the Internet. Data transfer rates will be limited by the lowest bandwidth connection between the source and the destination. The Internet 2 network may have the potential for a 500-Mb-per-second transfer rate (about 5 GB of data per day), but that rate will never be achieved if any cabling or connection along the way is too small. It is important to ensure that the throughput is consistent. If data is sent at a given initial rate from the source to the Internet connection, the network through which it travels should ideally support data movement at the same rate. In Figure 1, the data is sent at approximately 1 Gb/s, and the first stretch of network cable – a 1 Gb Ethernet cable – supports that rate. But the next stretch of cable only supports a lesser rate, 100 Mb/s rate of transfer – 10% of the initial rate – and the transfer slows by 90%.
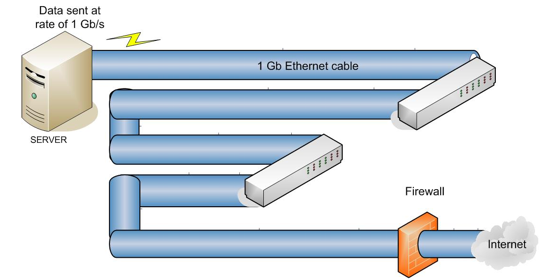
Further on, the network expands back to a 1 Gb Ethernet cable, but the transfer rate cannot increase at this point. Once the transfer rate is slowed to 100 Mb/s, it can never get back to the initial 1 Gb/s speed. Figure 2 shows a more evenly distributed cable network that would support a consistent data transfer rate.
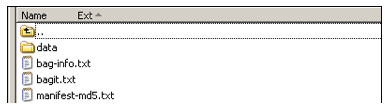
Over the commodity Internet, the Library achieves transfer rates ranging from 5 to 15Mb/s. Over the Internet 2 broadband network3 the Library achieves transfer rates 20 to 30 times faster, ranging from 100 to 500 Mb/s. To put this in perspective, at 100 Mb/s the Library can transfer approximately 1 TB per day, which means that – depending on network traffic, routing and the reliability of the senders' server – the Library could potentially download up to 5 TB per day. The Library has also found that transfers from the US to other countries behave in the same way, though the Library has not yet tested any high-volume international transfers, only FTP transfers of small data sets. The different high-bandwidth connections and hops from "here" to "there," broadband-network node to broadband-network node, seem to sort themselves out. Network transfer tools and parallelizationFor security and simplicity, the Library prefers to download data from the sender rather than have the sender upload it to us. Also, with the "pull" option the Library can download data from wherever the sender has it stored, when it is convenient or when there is space available, or when network traffic is lighter. If the sender wants to "push" the data, the transaction must be scheduled and a recipient must be standing by ready to receive it. The Library is mid-way through the development of a trusted-client application and a web application to support secure push transfers in the future. The Library tested a range of transfer tools and protocols, and it currently favors HTTP, rsync4, FTP and SSH. The features that are most attractive to the Library in a transfer tool are the ability to re-start a transfer in mid-file (in the event of a transfer disruption) and the option to parallelize transfer streams. Parallelization, one of the essential elements for optimized network transfer, maximizes the transfer process by splitting data into multiple concurrent streams [also referred to as threads]. There are no set limits on how many streams into which the data can be split. The Library usually begins with 15 to 20 streams, and if the data-transfer administrator has time, she will restart and increase the streams to find the optimum threshold; there doesn't appear to be an advantage to increasing the streams past the threshold. Also, more streams create more online activity and more bandwidth usage, so we must take care to avoid strain on the institution's shared network usage. Each file request from the Library's server needs a response from the sender's server before the Library can begin to download the file, and with so many exchanges happening at one time it is possible to spend too much time "handshaking." The network could get saturated with requests and begin to bog down, which is another reason to not have too many parallel streams running. The Library created a tool that enables parallelization: the "parallelretriever.py" script5. It requires Python and supports transfers over FTP (using curl), HTTP (using wget) and rsync (using rsync). The "parallelretriever.py" script defaults to one stream and can be easily modified to change the number of streams. Several elements affect the transfer rate, including the size and number of the files and where they are located. It is important to make sure that one stream doesn't contain all big files and another stream contains all small files, or the small-file stream will finish quickly and the large-file stream will be tied up for awhile. To ensure even file distribution, the Library recommends setting the number of streams to a prime number such as 7, 11, 13, 17, 19, 23 and so on. BagIt and BagsThe second essential element for optimized network data transfer at the Library is the bag, a simplified and standardized means of packaging content for transfer. Anyone can create a bag by grouping their data into a single directory, running checksums on the files and creating a few metadata text files to accompany the data. It is important to remember that a bag, as the Library presents here, applies to the container used for transfer and not the content itself. While a bag can also be used as a packaging unit for storage, that topic is outside the scope of this article. The Library of Congress and the California Digital Library jointly developed the BagIt6 specification based on the concept of "bag it and tag it," where digital content is packed into a directory "container" (the bag) along with a machine-readable manifest text (the tag) to help automate the content's receipt, storage and retrieval. There is no software to install. A bag representation consists of a base directory, or folder, as shown in Figure 3.
At the root level, each bag contains at least a manifest file, a "bagit.txt" file and a subdirectory that holds the actual content files. It can also contain other optional files, such as the "bag-info.txt" metadata file shown in Figure 4 and described below.
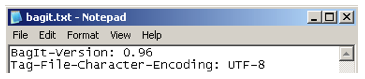
The "bagit.txt" file acts as a seal of approval, declaring that this is indeed a bag. This file is essential for establishing bag credibility for when others write bag-related code. The "bagit.txt" file should consist of two lines (see Figure 5):
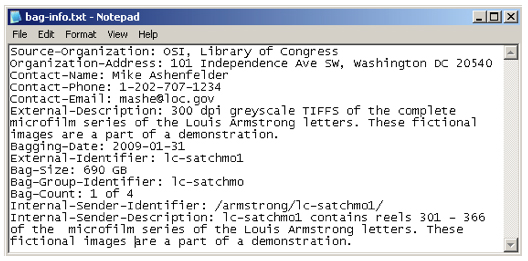
An optional file, titled "bag-info.txt," contains a small bit of administrative metadata about the contents of the bag, such as contact information for the content owner and a brief description of the content (see Figure 6).
In other optional files, users can add extra metadata about the content, such as a detailed description of the bag contents, PREMIS metadata, and so on. The Library recommends that these files be stored in the data directory in order to keep the bag root directory uncluttered. The manifest is a simple text-file that functions as a packing slip. It consists of two elements:
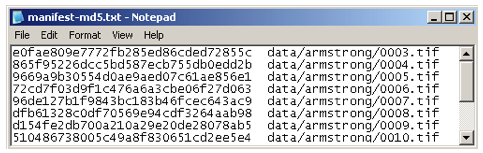
The manifest answers the question, "What's in the bag?" by listing the contents and – to ensure that the contents arrive intact – their accompanying checksums. The name of the manifest file includes the checksum algorithm that was used to create it – as in "manifest-algorithm.txt" – in order to take the guesswork out of the verifying the checksum. For example, "manifest-md5.txt" declares that the manifest was created with the MD5 checksum and "manifest-sha1.txt" declares that it was created with the SHA1 checksum algorithm. The filename in Figure 7 indicates that the MD5 checksum was used to create the manifest.
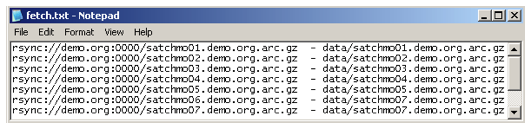
The checksums are used to verify that the files declared to be in the data directory (also called the payload) are intact once the Library receives the bag. There is no set way to organize the file hierarchy in the data directory. That is up to the content owner. Also, a bag can be any size, though the Library recommends keeping it at or below 650 GB, roughly the size of a standard external drive. Holey bagA bag may be downloaded empty, with a list of files to be fetched. A bag in this state is called a "holey" bag...a bag with content "holes" to be filled in. The URLs of the files to be fetched are listed in a text file called "fetch.txt." A holey bag can be more practical than a completed bag because with a holey bag the sender's files do not all need to reside in the same directory. The "fetch.txt" file, working with the "parallelretriever.py" script, downloads the files from their different locations and aggregates them into the bag's data directory. Figure 8 shows the contents of a holey bag.
The "fetch.txt" file contains three elements:
The "parallelretriever.py" script consults the "fetch.txt" file, follows the URLs and downloads the files to the local data directory. Again, you can set the number of parallel streams in the "parallelretriever.py" script. Once the download is finished, a checksum is run on the manifest. If the manifest does not completely verify, the Library contacts the sender to resend the file(s) in question. The Library has another script called "fetch-it-with-http-ranges.sh" that will download single large files in parallel multiple chunks. It leverages the support in HTTP 1.1 for downloading byte ranges. However, that doesn't work with rsync, FTP or old HTTP servers, because those protocols don't support the ability to transfer ranges of a file. A holey bag becomes a completed bag after all of the URL-identified objects are downloaded and the manifest is verified. In order to conduct a transfer session, the institution from which the data will be downloaded must stage its data on a server accessible to the protocol being used. For example, if the Library uses the rsync protocol for the transfer, the sender's data must be staged on an rsync server; if the Library uses the HTTP protocol the sender's data must be staged on an HTTP server. A user account must also be set up so that the Library has permission to access that data. The sender also should let the Library know in advance how much data will be transferred so that the Library can prepare the appropriate amount of space to receive it. If the manifest verifies, the Library emails a receipt to the content owner. The notification email declares the transfer status in the subject field, including the unique identifier for the bag. The Library sends a status notification for each bag. Here is a sample Subject heading from a notification email: "[lcxfer] "gov2020" received and verified." Most of the Library's collections for its NDIIPP partners follow this procedure. Some differ slightly. The Library has simplified the bagging process with a graphic-interface tool called Bagger. Enter data into the Bagger form, browse to your data and Bagger will bag your content. The Library's bagging and data-transfer software is open source and hosted on SourceForge. Go to sourceforge.com and search for "Library of Congress". eDepositThe eDeposit initiative is investigating processes for the receipt of electronic journals, with the goal of providing services that can be used for future electronic copyright deposits, subject to appropriate rules and regulations. The project currently uses a manual process that is essentially identical to those employed by NDIPP. With eDeposit, the sender uses a web-based deposit service to transfer content to LC. The sender logs in and, once the sender's credentials are verified and authorized, she creates a bag to transfer to the Library. In the web-based Deposit system, the sender fills out a manifest with the details of the transfer: sender name, transferring institution name, contact information, sender-created bag id (optional), date of transfer, agreement or project under which transfer is taking place, and a bag description (optional). The sender submits the bag through the web-based transfer system. Upon submitting the bag, the Library transfer system assigns a permanent identifier to the bag transfer and provides that identifier to the sender. This identifier can be used to monitor the status of a bag throughout the transfer transaction. SummaryNetwork transfer is a simple and inexpensive solution, and it is becoming preferred at the Library of Congress over other hardware-based methods. The process is currently manual and relies on UNIX commands, but the Library is automating the system. Transferring data over the network eliminates the need for shipping drives in parcels, saving money on shipping charges and hardware purchases. The time that it takes to get data from the sender to the receiver over the network is a small fraction of what it would take to ship drives. Digital bags simplify the conceptual "container" for data transfer. Construction of a bag is relatively simple, reducing the container to a directory that contains all the files and a text manifest file that lists the contents. Checksums are used to verify that the contents transferred intact. Differences in institutional data models do not matter; everything fits neatly into a bag. Notes1. National Digital Information Infrastructure and Preservation Program, <http://www.digitalpreservation.gov>. 2. The National Digital Newspaper Program, <http://www.loc.gov/ndnp/index.html>. 3. Internet 2, <http://www.internet2.edu/>. 4. RSYNC, <http://rsync.samba.org/>. 5. The Library of Congress Transfer Tools, <http://sourceforge.net/projects/loc-xferutils/>. 6. BagIt, <http://www.digitalpreservation.gov/partners/resources/tools/index.html#b>. |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/july2009-ashenfelder
|