D-Lib Magazine
July/August 2012
Volume 18, Number 7/8
Table of Contents
Automatic and Interactive Browsing Hierarchy Construction for Scientific Publication Collections
Grace Hui Yang
Georgetown University
huiyang@cs.georgetown.edu
doi:10.1045/july2012-yang
Printer-friendly Version
Abstract
Pre-constructed browsing hierarchies are often incapable of supplying the right set of terms to describe a new scientific publication collection. Even if a browsing hierarchy contains descriptive terms, they may not be organized in the same way as they are presented in the collection. Browsing hierarchies derived directly from the collection can be far more effective than pre-constructed ones. In this paper, we present a novel automatic browsing hierarchy construction algorithm which can derive browsing hierarchies that match the content of a collection of scientific publications. It also allows librarians or others who construct browsing hierarchies to interactively modify the hierarchies and, to some extent, teaches the algorithm to predict further human modifications. A user study and experimental results show that our algorithm is effective in creating hierarchies to support browsing activities for arbitrary collections.
1. Introduction
In the pre-Google days, browsing was the main method for finding information in scientific publications. Keyword search has greatly reduced the popularity of browsing [18]. It is becoming accepted that browsing is more suitable than keyword search for exploratory search tasks that involve information learning and investigation [9,15,21]; searching scientific literature is an excellent example. Another factor that will prevent the revival of browsing is that browsing lacks the ability to quickly handle an ad hoc document collection, such as a published conference proceedings, a thread of discussions in a forum, or a new collection of electronic papers, that will be explored, analyzed, and investigated by the end users.
An important arguement against relying on browsing is that most browsing hierarchies, such as Online Public Access Catalogs (OPACs), are still manually constructed, which is slow and expensive. Another arguement is that pre-constructed, static browsing hierarchies are often incapable of supplying the right set of terms to cover a new collection's content. A hierarchy and a collection either show a vocabulary mismatch between them or suffer from different granularity in their uses of languages. For example, this paper's closest match to the ACM Computing Classification System [1] is Systems and Software under Information storage and retrieval, which is too vague to present the content of this paper. Moreover, even if a catalog contains descriptive terms, it is unlikely that the terms will be organized in the same way as they are presented in the collection.
Fortunately, researchers have found that browsing hierarchies directly built from collection content are far more effective than manually pre-constructed catalogs. For example, Choi et al. reported in [3] that a table of contents (TOC) generated by an author based on the content of a book is a better match to users' information needs in related search tasks than the Library of Congress Subject Headings (LCSH). Moreover, faceted search engines, such as Flamenco [7,23,18], which either manually create specific facets to fit a collection's content or carve out the browsing hierarchy from existing taxonomies, have demonstrated their power in effective browsing collections from multiple perspectives [20]. We were therefore inspired to study how to construct browsing hierarchies from a collection of scientific papers.
In this paper1, we present a novel automatic browsing hierarchy construction algorithm, which can derive browsing hierarchies that well match the content of a given publication collection. In our browsing hierarchies, each concept connects to all documents containing it. When traversing to a concept, a user can view the documents related to this concept. The concepts are well-organized into a semantically sound browsing hierarchy which reveals the interrelationships among concepts in the collection. The hierarchy provides an effective structure from which to browse and explore the content in the papers.
Our approach is a global optimization algorithm which puts every concept at the place where it should be. We achieve this by minimizing the overall semantic distance among concepts in the browsing hierarchy and minimizing the semantic distance among concepts along a path in the hierarchy. Particularly, we estimate the pair-wise semantic distance between concepts from training data and proceed from it to organize the concepts. Besides automatic construction, the algorithm allows those constructing the browsing hierarchies to interactively modify a hierarchy and to some extent teaches the algorithm to predict further human modifications. The users therefore have no need to make every change manually, saving time and effort. We effectively combine knowledge from the collection itself and human expertise to build a semantically sound browsing hierarchy.
The remainder of the paper is organized as follows: Section 2 describes related work. Section 3 details automatic browsing hierarchy construction. Section 4 presents how to incorporate human expertise. Section 5 presents the evaluation and Section 6 concludes the paper.
2. Related Work
Prior research on automatic browsing hierarchy construction can be categorized into either of two approaches, clustering approaches and taxonomy induction approaches. The clustering-based approaches utilize existing text clustering techniques to produce document clusters, usually hierarchical document clusters, and then derive cluster labels as concept names for each cluster [4]. The hierarchical organization of the clusters is used as the browsing hierarchy, and the cluster labels are used as the concepts within the browsing hierarchy. Clustering-based approaches are a straightforward way to build hierarchical organization for a document collection. However, they often generate clusters that are difficult to interpret due to bad cluster labels and off-topic documents present in the clusters.
The taxonomy induction approaches, sometimes also known as monothetic concept hierarchy construction, first extracts the concepts from the document collection, then organizes the concepts into structures matching the concept relations present in the collection [17,11]. Our work belongs to this class of approaches.
As a classical work in monothetic concept hierarchy construction, Sanderson and Croft's subsumption approach created catalog-like browsing hierarchies based on terms' document frequencies. Particularly, documents containing concept x are a superset of documents containing concept y and x subsumes y, if P(x|y) ≥ 0.8 and P(y|x) < 1. The authors identified several design principles for browsing hierarchy construction. Example principles include: all concepts should be extracted from the documents to best reflect the topics within them; a parent concept subsumes a child concept; allowing multiple parents; and allowing multiple senses of an ambiguous word to appear in the hierarchy. However, other design considerations are less reasonable, such as allowing intransitivity of concepts. That is, the approach considered financial institute→bank→river bank correct even though financial institute is clearly not an ancestor of river bank and the concepts are inconsistent along the path. In this paper, we address the problem of path inconsistency caused by concept intransitivity and present a solution in Section 3.4.
Another line of research also belongs with the taxonomy induction approaches. It makes use of linguistic analysis and semantic information to derive the relations among concepts and build the hierarchical organization. Most research along this line focuses on extracting local relations between concept pairs [5]. Recently, more efforts have been made in building full hierarchies. For example, Kozareva and Hovy proposed to connect local concept pairs by finding the longest path in a subsumption graph [10]. Yang and Callan proposed the M E framework that modeled the semantic distance d(cx, cy) between concepts cx and cy as a weighted combination of numerous lexical and semantic features: ∑j weightj * featurej(cx,cy) and determine the hierarchical structure by minimizing overall semantic distances among concepts [22]. In this paper, we also make use of semantic distance minimization to form the browsing hierarchies, however, we model the semantic distance into a more justified mathematical form (Section 3.2).
3. Automatic Browsing Hierarchy Construction
This section presents how to automatically build browsing hierarchies. As one of the taxonomy induction approaches, we first extract concepts from a publication collection (presented in Section 3.1) and then organize the concepts into a browsing hierarchy.
A good browsing hierarchy should reflect the semantic proximity among concepts by organizing them into proper structures. Assuming that the similarity of concepts in meanings can be represented by a semantic distance, then a good browsing hierarchy should guarantee that concepts related to the similar topics have small semantic distances among themselves, and are put together. We discuss how to model semantic distance among concepts in Section 3.2.
This suggests that positioning a concept at its correct position means putting it in a correct neighborhood with correct parents, children, and siblings. Its semantic distances to its true neighbors should be small. If it is put into a wrong position, its semantic distances to the false neighbors are large. Therefore, an optimal browsing hierarchy should require minimum semantic distances among the concepts. This desirable property supplies a guideline for us to use to select the best hierarchical organization from many choices. we present an automatic greedy algorithm to build browsing hierarchies based on this property in Section 3.3.
To enforce consistency along a path from the root to a leaf in a browsing hierarchy, we propose to require all concepts on the path to be about the same topic. They need to be coherent no matter how far away two concepts are apart in this path. We present how to achieve path consistency in Section 3.4.
In Section 3.5, we analyze the computational cost of our algorithm and how it can be utilized in practice.
3.1 Concept Extraction
We aim to build a relatively complete overview for the collection, thus instead of inventing a sophisticated and very selective concept extraction algorithm, we take a simple but effective approach to exhaustively examine the terms in a document collection and keep a good portion of them as concept candidates. Moreover, when building the browsing hierarchies as in Section 3.3 and Section 3.4, the concepts will be either connected or discarded so that the selection of concepts comes along naturally. In particular, we follow the steps below to extract concepts:
- Exhaustively examine the collection and output a large set of terms, formed by nouns, noun phrases 2 and named entities 3 , that occur > 5 times in the collection.
- Submit each term in the pool to google.com as a search query. Then filter out invalid terms due to part-of-speech errors or misspelling by removing terms that occur < 4 times within the top 10 returned snippets.
- Further conflate similar terms into clusters using LSA [2] and select the most frequent terms as concepts from each term group.
The detailed procedure of forming term clusters by LSA is:
- Create a term-document matrix C. Each entry Cij in C represents the tf.idf weight [14] of term ci in document dj.
- Perform SVD for C and obtain the SVD term matrix U, singular value matrix Σ, and SVD document matrix V. The rank of C is r, which indicates the first r non-zero diagonal entries in Σ.
- Reduce the rank of C from r to k, where k is an integer much smaller than r. We empirically test different k values and choose the k value based on [19]. Basically, k is selected if it generates an "elbow value" in the summary purity scores for the series of concept clustering results. k is tested from 50 to 500 in our experiments.
- Given k, set the last (r−k) diagonal entries in Σ to zeros to obtain Σk. Calculate a truncated concept-document matrix at rank-k: Ck=UΣkVT.
- Compute the term-term matrix CkCkT, whose (m,n)th entries indicates the similarity between two terms cm and cn in the lower dimensional space. Cluster the terms based on the scores in CkCkT. Repeat steps 3, 4 and 5 to pick the best k.
- From each term clusters, choose a
term with the highest corpus frequency to keep in
the concept set C.
We select the N most frequent terms to form the concept set C. N usually ranges from 30 to 100. We assume that C contains all concepts in the browsing hierarchy; even when an important concept for the collection is missing, we will "make do" and do our best with C. This may lead to some errors, but they can be corrected by users through adding, deleting, or renaming concepts (Section 4).
3.2 Estimating Pair-wise Semantic Distance
Once the concepts are extracted, we can organize them into a browsing hierarchy. Our goal is to formulate the construction of the browsing hierarchy with restrictions that can monitor semantic correctness for the hierarchy. We start the process by defining local relations and then build the entire hierarchy based on those local relations. In this section, we demonstrate how to estimate the local relations by supervised distance learning.
The local relations, i.e., the pair-wise relations between two concepts, can be represented by a semantic distance. The semantic distance between two concepts measures how dissimilar in terms of semantics these concepts are. There are various ways to measure such semantic distance. For example, lexico-syntactic patterns such as "..., including A and B ..." can be used to identify the semantic distance (in terms of sibling relationship) between apple and pear if a text fragment "... fruits, including apple and pear ... " is found. Term context and term co-occurrence are also good measures for semantic distances and are used in our work.
Each type of measurement is considered as one feature type. We propose a general framework to model the combined effect of multiple feature functions for better prediction accuracy. There are again multiple ways to combine the features, including simple linear interpolation or Euclidean distance function. As long as the aggregated features can jointly represent a metric that well-represents the semantic distance between two concepts, any aggregation function for the features is fine to use.
In this work, we choose the Mahalanobis distance [13] to aggregate multiple feature functions and to represent the pair-wise semantic distance between two concepts. It can be formulated as
where Φ(cx, cy) represents the set of pair-wise feature functions, where each feature function is ϕk:(cx,cy) with k=1,...,|Φ|. W is a weight matrix, whose diagonal values weigh the feature functions. Note that a valid distance metric should satisfy regularities such as non-negativity and triangle inequality. We therefore constrain W to be positive semi-definite (PSD), that is, W ≥ 0, to satisfy those constraints.
The weight matrix W is the parameter that the distance function needs to learn. In order to estimate it in a supervised setting, we collected around 100 training hierarchies from WordNet [6] and ODP [16] and use the pair-wise relations within these training hierarchies to train the model. The training examples, i.e., training pair-wise relations, can also be obtained from user inputs and we will demonstrate how to collect them in Section 4.
3.3 Minimizing Overall Semantic Distance
When beginning to build a browsing hierarchy from the pair-wise relations that we learned earlier, it is important to know what defines a good browsing hierarchy. One fundamental property of a good browsing hierarchy is that concepts similar in meanings are positioned close to each other. It implies that the pair-wise semantic distances between concepts should be small in a good hierarchy. It further implies that the overall semantic distance among all the concepts in a good hierarchy should be minimized. The goal is to find an optimal browsing hierarchy ∧T such that its overall semantic distance is minimized, i.e., to find:
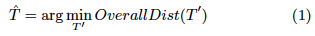
Finding optimal tree structures to satisfy certain conditions is often NP-hard [8]. To construct a browsing hierarchy within a reasonable amount of time, we take a greedy algorithm to approximate the global minimum in overall semantic distance. Our approach takes an incremental clustering approach to organize concepts into ontologies. The learning framework builds a browsing hierarchy step by step by considering the concepts one by one and placing each concept at an optimal position within the hierarchy.
When a new concept is added into the browsing hierarchy, there is an increase in the overall semantic distance of the entire browsing hierarchy because it introduces several distances, which are non-negative and did not exist previously, from itself to other nodes. However, how much this increase will be is determined by whether the new concept is inserted at the correct position. We observe that when a concept is in its correct position, it should give the least increase to the overall semantic distance in the browsing hierarchy. Thus minimizing the overall semantic distance is equivalent to searching for the best possible position for a concept.
At the nth insertion, a concept cz is tried as either a parent or a child concept to all existing nodes in the current browsing hierarchy Tn. Every insertion of concepts produces a new partial concept hierarchy. The optimal partial browsing hierarchy at each insertion step is the one that gives the least information change. At each insertion, after adding the nth concept, the best current browsing hierarchy Tn is one that introduces the least change to the overall distance from the previous browsing hierarchy Tn−1. The greedy approximation to Equation is:
Since the optimal concept set for a full browsing hierarchy is always C, the only unknown part for 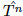 is the relations is the relations 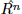 . Thus, Equation 2 can be transformed into: . Thus, Equation 2 can be transformed into:
where Sn−1 is the (n−1)th concept set, Rn−1 is the (n−1)th relation set.
By plugging in the definitions of semantic distance, the updating function becomes the minimization of the absolute difference in the information for the
ontologies with and without the nth new concept cz. The objective function that is based on minimization of overall semantic distances can be represented as:
where d(cx,cy) is the semantic distance between cx and cy.
3.4 Minimizing Path Semantic Distance
Through controlling distance scores among concepts, we can enforce path consistency in the hierarchies. For example, when the distance between financial institute and river bank is big, the path financial institute→bank→river bank will be pruned and the concepts will be repositioned.
We propose to minimize the sum of semantic distances in a path to make them as small as possible. When adding a new concept cz into an existing browsing hierarchy T, we try it at different positions in T; for each temporary position, the root-to-leaf path ∧P that contains the new concept cx is constrained by:
where Pcz is a root-to-leaf path including cz, x < y defines the order of the concepts to avoid counting the same pair of pair-wise distances twice. We interpolate both the overall semantic distance objective and the path consistency objective as follows:
where λ ∈ [0,1] is the interpolation coefficient that controls the contributions from both objectives. Through this interpolation of multiple objective functions, we incorporate path consistency into automatic browsing hierarchy construction.
3.5 Computational Cost
Suppose there are N concepts in total to be added. Among these N concepts, assume m of them are already in the browsing hierarchy. We need to put this new concept at 2m temporary positions, a dummy parent or a dummy child to an existing node. For each temporary position, when calculating semantic distances for the minimum evolution objective, the time complexity is O(m) to compute the distance between the new concept at the temporary position to all existing m nodes in the hierarchy. Note that for the pairwise distances between existing nodes in the hierarchy, their distances should already have been calculated in the previous iterations and therefore no additional computational cost remains for this iteration. For the path consistency objective, because all pairwise distances have already been calculated either in the previous iterations or in the step to calculate overall semantic distance, it does not introduce much overhead cost and its time complexity is O(1). Finally, since we grow the browsing hierarchy from scratch, m increases from 1 to N−1. Therefore the overall time complexity is O(2 * 12 + 2 * 22 + 2 * 32 + ... + 2 * (N−1)2) = O(⅓(N−1)N(2N−1)) = O(N3). Thus the big O notation for Algorithm 3.4 is O(N3).
In practice, since an ad-hoc collection contains a limited number of interesting issues that are worth looking at, the number of nodes in a browsing hierarchy is low. A browsing hierarchy's size stays within 30 to 100 nodes. The algorithm is fast enough to allow rapid learning and prediction in realtime interactions as we describe in Section 4.
4. Interactive Browsing Hierarchy Construction
Although fully automatic construction can save human effort the most in browsing hierarchy construction for a new collection of scientific publications, due to topic specification and multiple facets often present in a collection, it is desirable to offer an opportunity to incorporate human expertise at minimal cost, to construct a sensible browsing hierarchy. In this section, we study how to incorporate human expertise into the framework that we presented in Section 3.
4.1 User Interface
We provide a user interface for librarians or constructors of browsing hierarchies to enter their modifications to an automatically built one. The user inputs are used as training data to teach the algorithm to follow manual guidance and organize the browsing hierarchy in the way that the user wants.
Figure 1 shows the user interface of the browsing hierarchy construction tool. It supports editing functions, such as dragging and dropping, adding, deleting, and renaming nodes, that allow the user to intuitively modify a browsing hierarchy. Users do not need to complete all the modifications they want in a hierarchy; instead, they can enter a few modifications and click the interact button, to teach the algorithm how to organize other concepts following the patterns in the manual inputs. Specifically, when a user puts cx under cy, it indicates that the user wants a relation demonstrated by cx→ cy to be true in this browsing hierarchy. We capture the user input as manual guidance and use it as a base to adjust our supervised distance learning model to further organize other concepts.
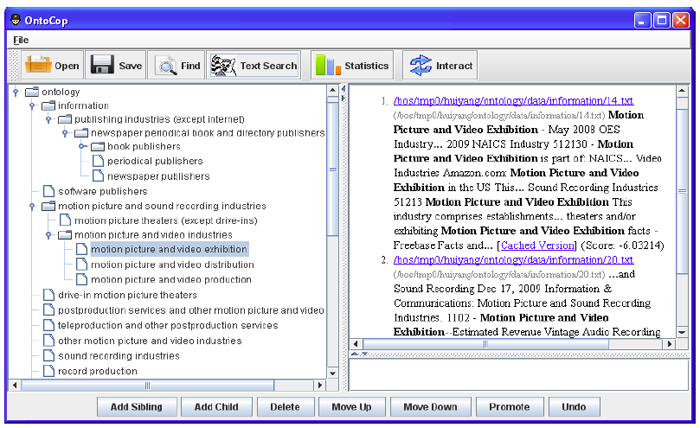 |
| Figure 1: The browsing hierarchy construction tool. The left pane displays the constructed browsing hierarchy; the right pane displays the related documents for a selected node in the hierarchy on the left. A user can add, edit, delete, rename, and drag and drop a node around in the browsing hierarchy. |
The interactive browsing hierarchy construction process is demonstrated in the following steps:
- Create an initial browsing hierarchy using the techniques presented in Section 3.
- User modifies the hierarchy with a few edits, the system collects manual guidance, the modifications, from the user.
- Based on the manual guidance, the distance learning function which represents how to measure the semantic distances among concepts in the current hierarchy is updated.
- Use the new distance function to predict the semantic distances among concepts that have not been touched by the user.
- Update the browsing hierarchy according to the new set of semantic distances. Present the new organization to the user.
- Repeat step 2 to step 5 until the user feels no more modification is necessary.
Learning and predicting distances was presented in Section 3.2. Section 4.2 focuses on how to represent hierarchies to the user and to the algorithm. How to capture manual guidance is covered in Section 4.3, and updating the browsing hierarchies in Section 4.4.
4.2 Matrix Representation for Hierarchies
The supervised distance learning algorithm is able to learn a good model which best preserves the regularity in a browsing hierarchy defined by a user. To translate hierarchies, especially changes in hierarchies, into a format that a learning algorithm can easily understand, we propose to convert a browsing hierarchy into matrices of neighboring nodes. For a given hierarchy T, the matrix representation of T is defined as:
the (x,y)th entry in the hierarchy matrix MT for hierarchy T indicates whether (or how confident) a relation r(cx,cy) for concepts cx ∈ T and cy ∈ T is true.
The relation type present in the hierarchy matrix could be any type relation between the concepts, i.e., r could be any type of relation between the concepts. For example, if the relation r is is-a, the parent-child pairs are indicated as 0, and other nodes are indicates as 1. If the relation r is sibling, within-cluster distances are defined as 0 and between-cluster distances are defined as 1.
4.3 Learning from Manual Guidance
Based on the hierarchy matrix representation, for each snapshot of a hierarchy during human-computer interaction, we can represent a hierarchy snapshot in a hierarchy matrix. This series of hierarchy matrix snapshots together demonstrate the changes to the hierarchy. We are interested in the changes introduced by user inputs.
We call the changes caused by users manual guidance, which indicates how the user wants the concepts are organized and to where the user wants the browsing hierarchy to evolve. Formally, we define manual guidance Gn as a portion (submatrix) of the current hierarchy matrix HTn that the portion is where HTn is different from the previous hierarchy matrix HTn−1. That is, given a hierarchy T, the manual guidance for the nth human-computer interaction is GTn = HTn[r;c], where r = {i : HTnij−HTn−1ij ≠ 0}, c = {j : HTnij−HTn−1ij ≠ 0}, HTn−1ij is the (i,j)th entry in HTn−1, and HTnij is the (i,j)th entry in HTn.
Note that manual guidance is part of the later matrix, not simply the matrix difference between two hierarchy matrices. It is because what matters is the later matrix that indicates where the user wants the hierarchy to develop. The manual guidance can be used to derive training examples for the supervised distance learning algorithm. In this way, the final constructed browsing hierarchy is able to incorporate human expertise. In practice, a user only provides a small amount of manual guidance in each iteration. To avoid too rapid change of the taxonomic structure based on minimal manual guidance, we continue to use background training collections, WordNet and ODP, to smooth and formulate better models with less variances.
4.4 Updating the Browsing Hierarchy
After a new semantic distance function is learned from manual guidance, we can apply it to predict the pair-wise semantic distance scores for the unmodified concepts and further update the browsing hierarchy to reflect the changes. In general, when the pair-wise distance score for a concept pair (cl, cm) is small ( < 0.5), we consider the relation between the concept pair to be true. However, how to organize the concepts whose relation is true is decided by the relation type in the distance matrix. If the relation r is "sibling", cl and cm are put into the same concept group. If r is "is-a", cm is put under cl as one of cl's children.
The construction tool presents the modified browsing hierarchy to the user. The parts of the browsing hierarchy modified by the system are highlighted as shown in Figure 2. The system then waits for the next round of manual guidance. This human-teaching-machine-learning process continues until the user is satisfied with the hierarchy.
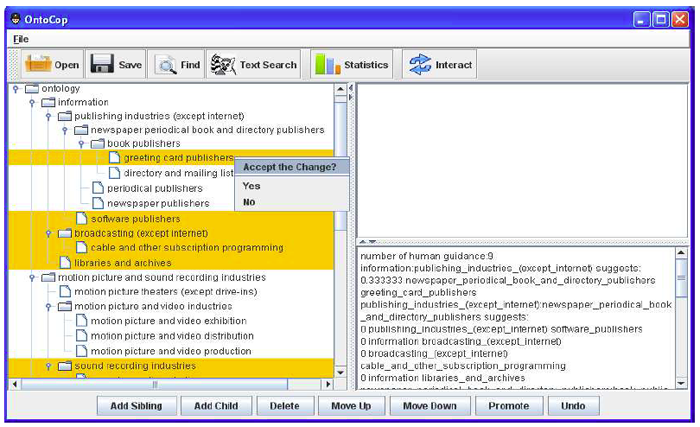 |
| Figure 2: An updated browsing hierarchy with new system suggestions highlighted. The user can select "yes" or "no" to indicate whether the new concept and the new place to put the concepts that suggested by the machine is correct or not based on his/her own judgment. |
5. Evaluation
We conducted a user study to evaluate the effectiveness of our approach.
Our goal is to evaluate browsing hierarchies that are pre-constructed, that are automatically derived from a collection of scientific publications using the techniques presented in Section 3, and that are interactively created using the techniques presented in Section 4. We first describe the study design in Section 5.2, and then report the browsing effectiveness in Section 5.3 and how well the system learns from human expertise in Section 5.4.
5.1 Datasets
The datasets we used are conference proceedings of SIGIR (ACM SIGIR Special Interest Group on Information Retrieval) 2001-2010. The SIGIR publication datasets cover broad and diverse concepts in Information Retrieval research. We use each year's SIGIR conference proceedings as a collection of papers and evaluate how well different techniques can generate browsing hierarchies for each year's collection. The relations described in the datasets is is-a.
5.2 Study Design
Twenty-nine graduate and undergraduate students from two universities participated in the study. They were all familiar with use of computers, with an undergraduate degree, and highly proficient in English. We asked the participants to use and compare the provided browsing hierarchies with the following task in mind.
Imagine you are a survey writer. You need to write a survey paper about the document collection on [dataset name] by using a browsing hierarchy designed for this collection. Use the browsing hierarchy to find all useful topics for your paper. Identify at least one document for each topic.
The user study was conducted in sessions. Each session was one hour long. The participants were first introduced to the tool for about 10 minutes so that they could get familiar with its functions. This training was then followed by another exercise task which lasted about 5 minutes. Afterwards, participants started the real tasks and worked on the datasets for 45 minutes. For each dataset, we asked the participants to compare the following three types of browsing hierarchies built for it:
- TOC: The original table of contents for browsing the publication collection provided by the conference proceedings.
- AUTO: Browsing hierarchies constructed for the dataset by the automatic algorithm presented in Section 3.
- Interactive: Browsing hierarchies constructed for the dataset by the participants through interaction with the tool, as presented in Section 4. The corresponding AUTO hierarchy was used as the initial browsing hierarchy for the interactive construction.
Once the real tasks were done, participants had 5 minutes to answer a questionnaire regarding their experience.
5.3 Browsing Effectiveness
It is believed that a good browsing hierarchy should do well at predicting the collection that it was built from [11]. To evaluate the quality of the browsing hierarchies, we use the expected mutual information measure (EMIM [12]) to measure the predictiveness of a browsing hierarchy T for a document collection D. The measure is defined as:
where P(c,v)=∑d ∈ DP(d)P(c|d)P(v|d), C is the set of concepts in T, and V is the set of non-stopwords in D.
Table 1 shows the mean predictiveness of the TOC, AUTO, and Interactive browsing hierarchies for each dataset, averaged over all participants. Comparing the three types of browsing hierarchies, we find that specific browsing hierarchies, i.e., AUTO and Interactive, greatly outperform the pre-constructed TOC browsing hierarchies. Specifically, in terms of how well to predict a document collection, AUTO is 130% and statistically significantly more effective than TOC (p-value < .001, t-test) and Interactive is 167% and statistically significantly more effective than TOC (p-value < .001, t-test). It suggests that browsing hierarchies built by our techniques are statistically significantly more effective for browsing than general browsing hierarchies.
The interactive method further demonstrates another 23% more improvement (p-value < .01, t-test) over the AUTO hierarchies in terms of predictiveness (see Table 1). It shows that by incorporating human expertise, our interactive method successfully creates much more effective browsing hierarchies than the fully automatic method.
| SIGIR Year | TOC | AUTO | Interactive |
| 2001 | 0.4×10−3 | 5.6×10−3 | 7.3×10−3 |
| 2002 | 0.5×10−3 | 7.8×10−3 | 8.3×10−3 |
| 2003 | 0.1×10−3 | 2.8×10−3 | 3.6×10−3 |
| 2004 | 0.2×10−3 | 6.4×10−3 | 6.8×10−3 |
| 2005 | 0.01×10−3 | 0.6×10−3 | 0.6×10−3 |
| 2006 | 0.2×10−3 | 3.8×10−3 | 4.7×10−3 |
| 2007 | 0.1×10−3 | 2.4×10−3 | 3.2×10−3 |
| 2008 | 0.3×10−3 | 3.5×10−3 | 4.9×10−3 |
| 2009 | 0.2×10−3 | 1.3×10−3 | 3.2×10−3 |
| 2010 | 0.4×10−3 | 4.9×10−3 | 5.6×10−3 |
| average | 0.27×10−3 | 3.9×10−3 | 4.8×10−3 |
Table 1: Predictiveness (measured in EMIM).
5.4 Accuracy of System Predictions
To evaluate how well the proposed interactive approach can learn from human expertise, we measure the accuracy of system predictions by asking the participants to judge how well the system learns from human edits through an on-the-fly direct evaluation. During every human-computer interaction cycle, the system made predictions based on a participant's edits. The parts of the browsing hierarchy modified by the system are highlighted as shown in Figure 2. The predictions were evaluated by the participant according to his/her own standard via selecting an option "yes" or "no" from the "Accept the change?" menu. Based on user evaluation, we can calculate the accuracy of system predictions as:
where r is the total number of human-computer interactions when constructing a browsing hierarchy.
Table 2 shows that the mean accuracy of the system predictions is above 0.92 for all datasets, and 0.94 on average. Note that the participants did not select "yes" for every prediction. This high accuracy indicates that the system learns well from user edits and that users accept nearly all of the predictions. It shows that our technique for incorporating human expertise in constructing browsing hierarchies is highly effective.
| Max | Min | Average |
| # of system predictions | 23 | 11 | 15.2 |
| accuracy of system predictions | 0.98 | 0.92 | 0.94 |
Table 2: Accuracy and number of system predictions for Interactive hierarchies.
6. Conclusion
Pre-constructed browsing hierarchies are often incapable of supplying the right set of terms to describe a new scientific publication collection. Browsing hierarchies derived directly from the collection could be far more effective than pre-constructed ones. In this paper, we presented a novel browsing hierarchy construction algorithm, which can not only automatically derive browsing hierarchies from a given collection of scientific publications but also interactively work with users to create even more effective browsing hierarchies. A user study and experimental results show that our algorithm is highly effective.
Our algorithm minimizes the overall semantic distances among concepts, and the path inconsistency along paths in a browsing hierarchy. The resulting hierarchies organize concepts in a scientific publication collection well. The supervised distance learning algorithm flexibly combines multiple semantic feature functions to evaluate the proximity between concepts. This flexible framework has the potential to enable other constraints to be added, and potentially to build more complex and sensible browsing hierarchies for any given document collection.
7. Notes
1 The following terminologies are used in this paper. A Collection refers to a collection of documents, in this case, a collection of scientific papers. Browsing hierarchy refers to the tree-structured hierarchical organization of topics/concepts in a collection. Concept refers to a node in the browsing hierarchy and term refers to any noun or noun phase in the collection which could potentially be a concept.
2 We used Stanford NLP Parser to get the part-of-speech (POS) tags.
3 We used BBN Identifier to obtain the named entities.
8. References
[1] ACM. ACM Computing Classification System, 1998. http://www.acm.org/about/class/1998.
[2] J. R. Bellegarda, J. W. Butzberger, Y.-L. Chow, N. B. Coccaro, and D. Naik. A novel word clustering algorithm based on latent semantic analysis. In Acoustics, Speech, and Signal Processing, 1996. ICASSP-96. 1996 IEEE International Conference on, Volume 1, pages 172-175, Washington, DC, USA, 1996. IEEE Computer Society.
[3] Y. Choi, I. Hsieh-Yee, and B. Kules. Retrieval effectiveness of table of contents and subject headings. In Proceedings of the 7th ACM/IEEE-CS joint conference on Digital libraries, JCDL '07, pages 103-104, New York, NY, USA, 2007. ACM.
[4] G. R. Cutting, D. R. Karger, J. R. Petersen, and J. W. Tukey. Scatter/Gather: A cluster-based approach to browsing large document collections. In Proceedings of the fifteenth Annual ACM Conference on Research and Development in Information Retrieval (SIGIR 1992), 1992.
[5] O. Etzioni, M. Cafarella, D. Downey, A.-M. Popescu, T. Shaked, S. Soderland, D. S. Weld, and A. Yates.
Unsupervised named-entity extraction from the web: an experimental study. In Artificial Intelligence, 165(1):91-134, June 2005.
[6] C. Fellbaum. WordNet: an electronic lexical database. MIT Press, 1998.
[7] M. Hearst, A. Elliott, J. English, R. Sinha, K. Swearingen, and K.-P. Yee. Finding the flow in web site search. Communications of the ACM, 45:42-49, September 2002.
[8] K. Kailing, H. peter Kriegel, S. Schönauer, and T. Seidl. Efficient similarity search for hierarchical data in large databases. In Extending Database Technology, pages 676-693, 2004.
[9] M. Käki. Findex: search result categories help users when document ranking fails. In Proceedings of the SIGCHI conference on Human factors in computing systems, CHI '05, pages 131-140, New York, NY, USA, 2005. ACM.
[10] Z. Kozareva and E. Hovy. A semi-supervised method to learn and construct taxonomies using the web. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, pages 1110-1118, Cambridge, MA, October 2010. Association for Computational Linguistics.
[11] K. Kummamuru, R. Lotlikar, S. Roy, K. Singal, and R. Krishnapuram. A hierarchical monothetic document clustering algorithm for summarization and browsing search results. Proceedings of the 13th conference on World Wide Web WWW 04, page 658, 2004.
[12] D. Lawrie, W. B. Croft, and A. Rosenberg. Finding topic words for hierarchical summarization. In Proceedings of the 24th Annual ACM Conference on Research and Development in Information Retrieval (SIGIR 2001), pages 349-357, 2001.
[13] P. C. Mahalanobis. On the generalised distance in statistics. In Proceedings of the National Institute of Sciences of India 2 (1): 495, 1936.
[14] C. D. Manning, P. Raghavan, and H. Schütze. Introduction to Information Retrieval. Cambridge UP, 2008.
[15] G. Marchionini. Exploratory search: from finding to understanding. Communications of the ACM, 49(4):41-46, April 2006.
[16] ODP. Open directory project, 2011. http://www.dmoz.org/.
[17] M. Sanderson and W. B. Croft. Deriving concept hierarchies from text. In Proceedings of the 22nd Annual International ACM SIGIR
Conference on Research and Development in Information Retrieval (SIGIR 1999), 1999.
[18] E. Stoica and M. A. Hearst. Automating Creation of Hierarchical Faceted Metadata Structures. In Proceedings of the Human Language Technology Conference (NAACL-HLT), 2007.
[19] R. Tibshirani, G. Walther, and T. Hastie. Estimating the number of clusters in a dataset via the gap statistic. In Technical Report 208, Department of Statistics, Stanford University, 2000.
[20] D. Tunkelang. Dynamic category sets: An approach for faceted searching. In ACM SIGIR '06 Workshop on Faceted Search. ACM, 2006.
[21] M. L. Wilson and m. schraefel. A longitudinal study of exploratory and keyword search. In Proceedings of the 8th ACM/IEEE-CS joint conference on Digital libraries, JCDL '08, pages 52-56, New York, NY, USA, 2008. ACM.
[22] H. Yang and J. Callan. A metric-based framework for automatic taxonomy induction. In Proceedings of the 47th Annual Meeting for the Association for Computational Linguistics (ACL 2009), 2009.
[23] K.-P. Yee, K. Swearingen, K. Li, and M. Hearst. Faceted metadata for image search and browsing. In Human factors in computing systems. ACM, 2003.
About the Author
 |
Grace Hui Yang is an Assistant Professor in the Department of Computer Science at Georgetown University. She received her Ph.D. and Master's
degrees in Computer Science from the School of Computer Science at Carnegie Mellon University, and Master's and Bachelor's degrees in Computer Science from at the National University of Singapore. Her research interests lie at the intersection of information retrieval, text mining, machine learning, and natural language processing, with a recent extension to human-computer interaction. Her current research includes automated and interactive ontology generation, human-guided machine learning, and text analysis and organization. Prior to this, she conducted research on question answering, near-duplicate detection, search engine training and evaluation, multimedia information retrieval, and opinion and sentiment detection.
|
|