 |
D-Lib Magazine
July/August 2015
Volume 21, Number 7/8
Table of Contents
Semantic Enrichment: a Low-barrier Infrastructure and Proposal for Alignment
Theo van Veen, Juliette Lonij and Hanna Koppelaar
Koninklijke Bibliotheek, National Library of the Netherlands
{theo.vanveen, juliette.lonij, hanna.koppelaar}@kb.nl
DOI: 10.1045/july2015-vanveen
Printer-friendly Version
Abstract
Semantic enrichment provides new possibilities for discovery and presentation of our data. At the National Library of the Netherlands research department we have created a generic infrastructure for enriching objects from our collections with, for example, links to related information. This article summarizes the main ideas behind this infrastructure and presents its implementation, with particular reference to the enrichment process of extracting named entities from textual content and linking them to resource descriptions in the Linked Data cloud. Other content providers may take a similar approach when enriching their data. We argue that such initiatives will be more beneficial for our users when infrastructures are connected and accessible with the same APIs. Alignment of data formats and identifiers, moreover, can help connect our content to others' content, e.g. through the use of a single identifier for each relevant resource across collections and institutions.
Keywords: Semantic Enrichment, Semantic Annotation, Semantic Search, Information Retrieval, Contextualization, Linked Data, Interoperability
1 Introduction
By semantic enrichment we mean adding meaning to our data by adding additional information. The nature of these enrichments can be very diverse, ranging from extracted features, like sentiment, to all kinds of related information, such as geographical coordinates. At the National Library of the Netherlands (KB) research department we currently focus on creating links between related objects from different collections, as well as links between named entities in text objects and external resource descriptions. From our point of view as a content provider, semantic enrichment can provide a lot of added value for our users in terms of discovery and presentation. When the additional information from enrichments is added to the original content at the time of indexing, it can enable spelling-independent and disambiguated search, making searching easier and the results more relevant. In the presentation of our data we can offer contextual information relating our content to objects and information from our collections, other institutions, and the wider web.
To the best of our knowledge, other initiatives are mostly focused on the details of a specific enrichment generation process, e.g. on enriching a specific dataset [2] or on a specific type of enrichment, such as linking entities to a single resource description framework [5]. At the KB, however, we are working with collections with different types of objects, different types of possible enrichments, and a multitude of — often external — sources of additional information. In order to deal with this variety, we initiated development of a simple, generic enrichment infrastructure, capable of gathering all information from all types of enrichments for all sorts of objects — and having them easily accessible for further processing steps, such as indexing.
This key aspect of our infrastructure is of particular relevance for enrichment with links to resource descriptions from the Linked Data cloud. Ideally, information about a resource appearing in a text object from our collections could be obtained via a simple request to a single service, like "return property X for object with identifier Y". This would be a realistic option if there were only one permanent source containing all descriptions of all resources, using globally unique identifiers for each resource, being used by everyone. However, the Linked Data cloud of connected resource descriptions keeps growing and evolving, so one has to deal with many different resource description frameworks, each using its own identifiers and containing different property names and values. Our enrichment infrastructure is aimed at aggregating identifiers from these sources — as far as they describe KB resources — at a single location and at providing low-barrier access to the corresponding resource descriptions in the Linked Data cloud, abstracting from different data formats, property names and values, and the complexities of SPARQL as a query language.
The remainder of this article is structured as follows. In Section 2 we will describe the enrichment infrastructure under development at the KB research department, along with new functionality that we are considering implementing. We will illustrate some details with our main current enrichment process: that of linking named entities found in our collection of Dutch historical newspapers to resource descriptions in the Linked Data cloud. The focus of the article, however, will not be on issues surrounding named entity extraction or disambiguation. Instead, in Section 3, we will discuss how collaboration with other organizations and alignment of APIs, data formats and identifiers might yield additional benefits from our efforts. Section 4 will provide a brief overview of some related work to put our activities into context.
2 The KB Research enrichment infrastructure
2.1 Overview
Data objects can be enriched by means of an enrichment infrastructure created in the KB Research environment, consisting of a so-called enrichment database and a number of services for interacting with this database, some of which can be used by external applications. The basic principle underlying this infrastructure is that enrichments are created and stored separately from the original data and do not modify them in any way. In addition, the enrichment architecture is agnostic with respect to the type of the object to be enriched and the type of enrichment to be stored. It can thus be used with multiple collections available at the KB, and with collections from other institutions as well. This section describes the enrichment database, the services, the enrichment process for linking named entities to external resource descriptions, and some of our plans for future improvements.
2.2 The enrichment database
The enrichment database contains two types of enrichment records: (1) enrichment records for content or information resources (IR) containing all kinds of links to related information, such as web sites, images and videos and (2) enrichment records for resources or non-information objects (NIR), containing links to descriptions or information about a resource from DBpedia, Freebase, VIAF, etc. The enrichments in IR records can apply to the complete object as well as to fragments of the object, like named entities in a text. For example, a newspaper article describing an event may be enriched with a link to a video about the same event, or by a link to a resource description of a person mentioned in the article. When the enrichments in an IR record point to a non-information resource, they should link to the NIR record for that resource, rather than directly to the resource description itself. The NIR enrichment records will aggregate links to descriptions or information about a specific resource. This is illustrated in Figure 1 below.
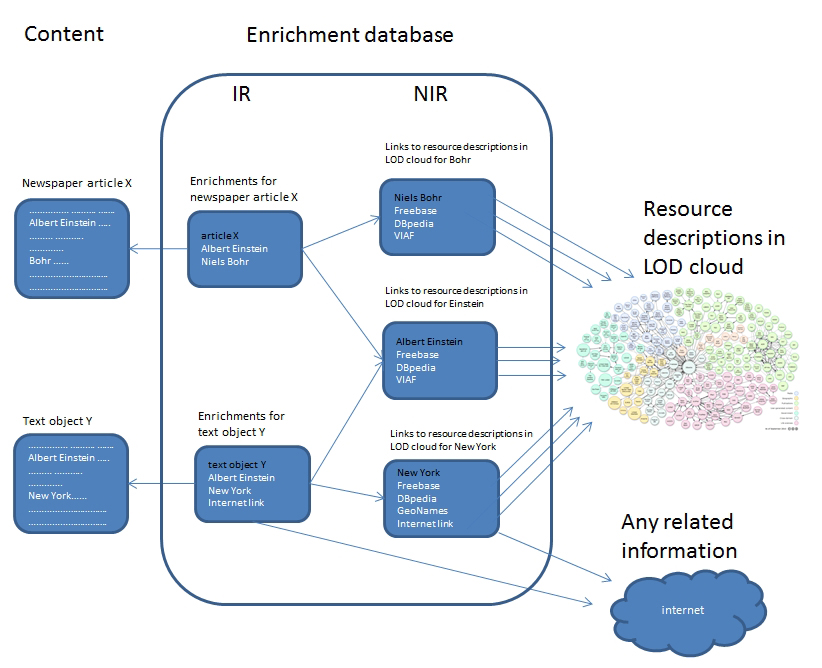
Figure 1: Enrichment database architecture
The IR enrichment record has the same identifier as the enriched object, so this identifier can also be used for retrieving the enrichments for that information resource. When an object is used for presentation or indexing, the identifier is used to check whether there is an enrichment record and, if so, the enrichments may be used for indexing and presentation purposes as well. In other words, links to IR enrichments are "just in case" links: there is no guarantee that there is an enrichment behind the link. Naturally, the chance of finding an enrichment must be large enough to justify the number of requests to the enrichment database. The key for requesting a non-information record can be any of the identifiers of any resource description that it contains, for example DBP:Albert_Einstein for DBpedia or VIAF:75121530 for VIAF, using a prefix instead of the complete URL. By allowing any of these resource identifiers as record key, we do not yet have to designate one of them as being the "authoritative" identifier. All these identifiers can be used for requesting a resource, as long as they are present in the enrichment database.
Both IR and NIR enrichment records are made up of a list of enrichments and each enrichment consists of a list of properties in the form of name-value pairs. The specific properties available will depend on the type of enrichment. For named entities, for example, the most important properties are the named entity as it occurs in the text, the "official" name of the resource that the named entity is referring to, the link to the related information or resource description, and the content type of the related information. The complete and up to date list of properties for all types of enrichments is maintained as part of the KB Research enrichment pages. The data model for enrichment records is easily extensible, and may change over time, as new types of enrichments are added. As a general rule, however, we try to keep the amount of information stored in the database to a minimum: wherever possible, only links are stored as enrichments and the actual data are retrieved "just in time", by following the link.
We use a NoSQL database, a MongoDB document database in particular, for storing the enrichment records in JSON format. The flexible data model of this type of database makes it suitable for quick experimentation and relatively frequent changes. For data exchange with external parties, a JSON enrichment record can easily be transformed into other formats, such as SKOS or JSON-LD.
2.3 The services
The usage of the enrichment database consists of retrieving enrichments, e.g. for presentation and indexing purposes, and adding, modifying and deleting enrichments. For these interactions the infrastructure contains a number of services, accessible with simple APIs, which are described below. Additional details, the current status of ongoing developments (like the latest URLs, and examples of API calls) can be found in the overview of services at KB Research. In addition to six mostly generic services, we list and describe a seventh service here, developed specifically for enriching text objects — either manually or automatically — with named entities linked to resource descriptions in DBpedia. This type of enrichment forms an important current application of the enrichment infrastructure and will be the topic of the next subsection.
- Get enrichments for an information resource
Syntax: <base_URL>?id=<object_id>
This service returns a JSON list containing all enrichments for the object with object_id as identifier. There is no restriction on the syntax of this identifier, but it should be unique. Each enrichment is a list of name-value pairs, containing such information as a URL to related information, a named entity string, a confidence level, etc.
- Get enrichments for a non-information resource
Syntax: <base_URL>?id=<resource_id>
This service returns a JSON list containing all enrichments for a non-information resource with a specific resource_id as identifier. Currently, these enrichments are links to resource descriptions and other related web pages. For supported resource description frameworks the resource identifier is a prefix for the framework combined with the framework resource identifier, for example DPB:Albert_Einstein or VIAF:75121530. If it is not from such a framework, the resource_id is supposed to be a complete URL.
- Get the value of specific properties of a non-information resource
Syntax: <base_URL>/<resource_id>?{property_name_list}
This service returns the requested property values for a specific resource. It is supposed to provide low-barrier functionality for obtaining specific information about a resource. For example the request <base_URL>/VIAF:75121530?birthDate,deathDate returns the response: {"birthDate":"1900","deathDate":"1950"}. Right now the user still has to know which properties are available in a specific framework, but we are working on abstracting from framework-specific details and providing a service that requires as little foreknowledge as possible.
- Add or delete an enrichment for an information resource
Syntax: <base_URL>?action=<add|delete>&objectId=<object_id>&subjectId=<subject_id>&<other_parameters>
With this service an enrichment for a specific object_id can be added or deleted. The parameter list contains a number of fields that are specific for the type of enrichment, like the subject_id, being the link to the related information. These are the fields that are returned when an enrichment record is requested with service (1) described above. If the IR enrichment record did not exist yet, it is created. This service requires authorization.
- Add or delete an enrichment for a non-information resource
Syntax: <base_URL>?action=<add|delete>&objectId=<object_id>&subjectId=<subject_id>&<other_parameters>
With this service an enrichment to a non-information resource can be added to or deleted from a record. As with the previous service, the parameter list contains fields that are specific for the type of enrichment, which are returned when an enrichment record is requested with service (2) described above. If the NIR enrichment record did not exist yet, it is created. This service requires authorization.
- Expanded SRU service
Syntax: <base_URL>?{SRU_parameters}, with CQL/query extension: [property=value]
This service provides a combination of conventional search based on the SRU protocol and semantic search. It uses the same API as the regular SRU service of the KB, but it differs from that service in that it takes the condition between brackets as an additional, semantic condition on a query. The condition is sent to a SPARQL endpoint (currently DBpedia) and returns the names of the objects that meet the specified condition. These names are then substituted in the CQL query sent to the SRU service of the KB. This service is still under construction: eventually, we will use the identifiers of the returned resources instead of their names. We also want to investigate how to optimize the processing of the SPARQL output as input for the conventional search, because limitations may be imposed on the query length.
- Get potential links for named entities in a text
Syntax: <base_URL>?[url=<value>][&ne=<value>][&context=<true|false>][&debug=0|1]
This service is used in the process of extracting named entities and automatically establishing the most probable link to DBpedia. It extracts the named entities in the text pointed to by the url parameter value, searches the named entities in DBpedia, and returns a JSON list of potential DBpedia links. The debug parameter is used to provide information about the reason for not finding a match. In case the named entity (parameter ne) is provided, the named entity recognition is skipped and the most probable link for that specific entity is searched for. In case context=true (not yet supported) the context of the url parameter and the contents of the DBpedia record will be taken into account by the matching algorithm. This matching algorithm is still under construction.
2.4 Enrichment process: linking named entities
To get a complete picture of the functionality of the enrichment database and the services described above, we will now consider the way in which they are used in the enrichment of digitized Dutch historical newspaper articles with named entities linked to DBpedia and other resource description frameworks in the Linked Data cloud. A simplified overview of the infrastructure, including the elements specific to the process for linking named entities, is shown in Figure 2. Some results of this particular enrichment process can be viewed at the KB Research enrichment pages.
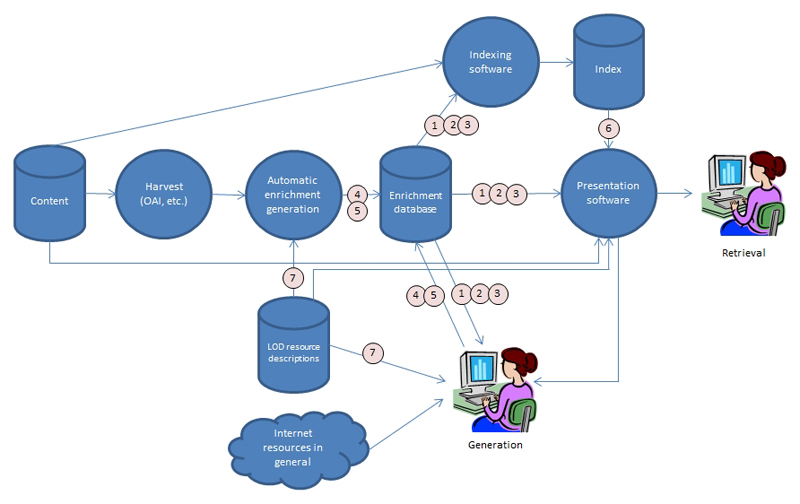
Figure 2: Overview of the enrichment infrastructure
For the automatic part of the processing, the content is harvested via OAI-PMH and forwarded to the linking service already mentioned in the previous subsection. There, named entities in the original text are extracted with the Stanford named entity recognizer, which we trained using the CoNLL-2002 corpus. Each named entity is looked up in DBpedia and, if necessary, disambiguated. These first few steps are specific for the linking of named entities: other types of enrichments require different kinds of processing.
Once a link with a certain level of probability is established, the IR enrichment record for the newspaper article containing the entity is created or updated with the recognized named entity, along with the link to the NIR enrichment record. If the NIR record did not exist, it is created with the DBpedia link and — if available in the DBpedia description — links to VIAF and Freebase. Now, this information can be added to the original content at the moment of indexing or presentation, and it can be used to help users to reformulate a query, using the services for getting enrichments and their properties, and the service for expanding conventional SRU queries with semantic conditions. These services are not only available for automatic processing, but also allow manual generation and editing of enrichments by authenticated users.
2.5 Future developments
The infrastructure is under construction in a number of areas. We want to improve existing enrichment generation processes and keep adding new ones. The application of machine learning techniques in particular should help us improve the quality of matching in different situations: automatically linking related objects across different KB collections, for example newspaper articles and radio broadcast transcriptions or press photographs related to the same event, or the use of context for disambiguation of identical names for different resources when matching named entities and DBpedia entries. In addition, links other than those to DBpedia, Freebase and VIAF will be added to the NIR records, especially links to Wikidata, replacing those to Freebase. We try to increase the throughput when automatically generating enrichments by using external processing capacity, and we are searching for solutions for unlinked named entities and dealing with user input.
Furthermore, we are working on improving the service for requesting the value of specific properties of a non-information resource and the expanded SRU service described above. An important aspect of our approach is the use of properties of resources that are not part of our own infrastructure, but of resource descriptions in the Linked Data cloud. We want to optimize the usage of these properties for presentation, indexing and adding semantic relations in conventional search. For this purpose, we need to create a machine-usable mapping of properties and their names in different resource description databases, that will allow us to request the live-updated property values "on the fly" from the various frameworks. In addition, we are considering implementing a SPARQL endpoint supporting federated queries on top of our existing infrastructure to extend the semantic search facilities.
3 Alignment with other organizations
Together, the enrichment database and the services described here form a mostly generic infrastructure that provides low-barrier facilities for enrichment generation and usage. This enrichment infrastructure is not restricted to specific collections, so it is possible to enrich data from other organizations, without any effort from that organization and without being intrusive with respect to their data or infrastructure. In this way, small organizations that do not have the necessary staff or infrastructure themselves could make use of the enrichment infrastructure of larger organizations, or share a central enrichment infrastructure. The KB Research enrichment infrastructure can potentially be used by others. For submission of enrichments, authorization is required. In a production environment we would need to apply stricter access policies.
Alignment of data formats, vocabularies, APIs and services will lower the barrier for creating clients that can access the enrichment databases of others. When the API and enrichment format are standardized, the only a priori knowledge required for access is the base-URL of the services. This is comparable to using the SRU protocol for searching metadata in remote databases. Imagine for example the presentation of bibliographic records containing links to VIAF for which one wants to present specific properties of an author. Rather than requesting the data from VIAF and transforming it to the desired output, using our service that returns the property values for a specific resource would be much simpler, because it only requires the VIAF identifier and the names of the properties to be presented. Adding a few lines of code to a web page would suffice.
Another example of where alignment may be beneficial is the way in which we combine conventional and semantic search. The average user will not easily enter a SPARQL query. For users that incidentally want to do a search that includes a semantic relation we introduced an extension of the user's query language that adds a relation in terms of "property = value". Our software transforms that relation into a SPARQL query and replaces the condition in the user's query with the result. It is trivial that it helps users in querying collections when they can rely on a simple way to express relations that is identical across different content providers. In addition, it would be possible to share a part of this service — namely the transformation of a simple relation to a list of resources that conform to this relation — with others.
The most important outcome of alignment with other organizations, however, would be using the same identifier for a resource in all types of databases, resource description frameworks, and even web sites. Suppose that we could rely on the use of, for example, the Wikidata identifier — which would be a serious candidate for this purpose — for all resources in all kinds of databases. In that case it would be easy to query those databases for a specific resource. This could also apply to the many named entities that do not occur in any resource description database at all. We would like to be able to identify such resources in a standard way that always leads to the same resource, for example by means of a national enrichment database. This helps to uniquely identify resources, not only in a single collection, but eventually also across collections.
Of course, an issue to consider here is whether existing standards could be used. The enrichments in this article are a special case of the annotations used in many environments. We chose not to use the OpenAnnotation data format for now, as only a small subset would be needed, and we believe that in our proposed infrastructure it does not contribute to a lower implementation barrier. However, collaboration with others might lead us to consider additional formats, such as OpenAnnotation, for submitting enrichments. Moreover, we believe that, given the simple API that we are proposing, a document database acting as a hub between text objects and existing triple stores is efficient, easy to use, and sufficient for our purposes. Transforming it into a triplestore with a SPARQL endpoint, on the other hand, would offer the possibility of taking part in a network of federated triple stores, without having to create an additional database on top of our infrastructure.
4 Related work
A lot of software for creating disambiguated links to DBpedia already exists, such as DBpedia Spotlight and Apache Stanbol. Since we aim at improving the results for the Dutch language, we developed this component of the linking service ourselves. This article, however, is primarily about lowering barriers for sharing and connecting infrastructures. Some interesting initiatives in this area are coming from the Australian National Data Service [1] and from the Andrew W. Mellon foundation [6]. A Europeana Foundation task force that was started recently is concerned with the issue of interoperability requirements for enrichment processes and services [3]. As the national library of the Netherlands, the KB is currently participating in the Dutch coalition Netwerk Digitaal Erfgoed, building a national infrastructure for digital heritage [4]. At this stage, developing a simple showcase, as we are doing at KB Research, can serve as input for further development of these initiatives as well.
5 Conclusion
In this article we demonstrated a way to deal with enrichments, focusing on links to related information — mostly resource descriptions in the Linked Data cloud. The main advantages of our approach are that it does not depend on or interfere with the original data, and that it has a low barrier to implement and use, as we offer a number of very simple APIs. Because of these advantages, we propose that other organizations enrich their content in the same way. We encourage aligning data formats and APIs and aim towards a more globally used identification of resources across collections, so that we can more easily access and use each other's data, offering users more relevant contextual information, as well as better discovery through semantic search.
References
[1] Australian National Data Service. (n.d.). The ANDS Data Connections Strategy.
[2] Bontcheva, K., Kieniewicz, J., Andrews, S., & Wallis, M. (2015). Semantic Enrichment and Search: A Case Study on Environmental Science Literature. D-Lib Magazine, 21(1/2). http://doi.org/10.1045/january2015-bontcheva
[3] Europeana Foundation. (2015). Evaluation and enrichments.
[4] Netwerk Digitaal Erfgoed. (2015). Nationale strategie digitaal erfgoed.
[5] Odijk, D., Meij, E., & de Rijke, M. (2013). Feeding the Second Screen: Semantic Linking based on Subtitles. In Open research Areas in Information Retrieval (OAIR 2013). Lisbon.
[6] The Andrew W. Mellon Foundation. (2014). Workshop on Reconciliation of Linked Open Data.
[7] Van Veen, T., & Koppelaar, M. (2014). Doing More with Named Entities. In Ł. Bolikowski, et al. (Eds.), Theory and Practice of Digital Libraries — TPDL 2013 Selected Workshops (pp. 163-168). Springer International Publishing. http://doi.org/10.1007/978-3-319-08425-1
About the Authors
 |
Theo van Veen has been a member of the research and development department of the Koninklijke Bibliotheek, National Library of the Netherlands since 1998. He got his degree in physics at the Technical University Delft in 1979 and started in 1988 in library automation at the University Library in Utrecht. He has been involved in several projects related to the European Library and Europeana, both hosted at the Koninklijke Bibliotheek. His research interest is currently focussed on the combination of text enrichment, named entities, linked data and service integration.
|
 |
Juliette Lonij is research software engineer at the Koninklijke Bibliotheek, National Library of the Netherlands. She studied philosophy and mathematics at the University of Amsterdam, receiving her master's degree with distinction in 2005. Prior to joining the National Library in 2014 she worked as a software developer and consultant for a number of internet agencies and various clients in the cultural sector.
|
|
Hanna Koppelaar works as a software developer at the National Library of the Netherlands. She has worked in several academic institutions and has been at the National Library since 2001. She holds an MA in History and a BSc in Mathematics.
|
|