D-Lib Magazine
July/August 1998
ISSN 1082-9873
Metadata: The Right Approach
An Integrated Model for Descriptive and Rights Metadata in E-commerce
Godfrey Rust
Data Definitions
London, England
godfreyrust@dds.netkonect.co.uk

This paper was adapted by the author from The Fire and the Rose, © Godfrey Rust, a paper produced for the meeting of the EDItEUR metadata working groups in New York in June 1998 [http://www.bic.org.uk/bic/rights.html].
Contents
The INDECS project Creations
Rights and Agreements
Parties
Rights metadata
The dependence of Rights metadata on Descriptive metadata
"Wide-area" agreements
The DOI and metadataA vocabulary for descriptive metadata
Identifiers
Classes
Events
Extents
Contributors
Components
Versions
References
Granularity
Party attributes and linksA vocabulary for rights metadata
Agreements
Agreements linked to Creations
The dependence of Descriptive metadata on Rights metadata
Authoritative descriptive metadata
Authoritative rights metadata
The development framework
The Dublin Core
If you've ever completed a large and difficult jigsaw puzzle, you'll be familiar with that particular moment of grateful revelation when you find that two sections you've been working on separately actually fit together. The overall picture becomes coherent, and the task at last seems achievable.
Something like this seems to be happening in the puzzle of "content metadata". Two communities -- rights owners on one hand, libraries and cataloguers on the other -- are staring at their unfolding data models and systems, knowing that somehow together they make up a whole picture. This paper aims to show how and where they fit.
Historically, metadata -- "data about data" -- has been largely treated as an afterthought in the commercial world, even among rights owners. Descriptive metadata has often been regarded as the proper province of libraries, a battlefield of competing systems of tags and classification and an invaluable tool for the discovery of resources, while "business" metadata lurked, ugly but necessary, in distribution systems and EDI message formats. Rights metadata, whatever it may be, may seem to have barely existed in a coherent form at all.
E-commerce changes all this. Suddenly, metadata matters for creators and rights owners, even if they are not always sure what it is. E-commerce offers the opportunity to integrate the functions of discovery, access, licensing and accounting into single point-and-click actions in which metadata is a critical agent, a glue which holds the pieces together. It is becoming a gateway, a shop window, a potential distribution channel, a means of protection and, critically, the route along which income will flow. E-commerce in rights will generate global networks of metadata every bit as vital as the networks of optical fibre -- and with the same requirements for security and unbroken connectivity.
What is sought in e-commerce by owners, producers, and users alike is a situation where rights administration can be fully automated: requests can be framed, offers made, licences granted, and payments transacted without costly manual intervention by anyone except the end user (and not always then). Sometimes intervention in the form of negotiation or authorisation is desired by the rights owner, but even this process needs to be as highly automated as possible. The sheer volume and complexity of future rights trading in the digital environment will mean that any but the most sporadic level of human intervention will be prohibitively expensive. Standardised metadata is an essential component.
All this has led to a major outbreak of metadata-related activity by the rights owning communities. This paper looks at metadata developments from this standpoint -- hence the "right" approach -- but does so recognising that in the digital world many Chinese walls that appear to separate the bibliographic and commercial communities are going to collapse.
Just as the creators and rights holders are the sources of the content for the bibliographic world, so it seems inevitable they will become the principal source of core metadata in the web environment, and that metadata will be generated simultaneously and at source to meet the requirements of discovery, access, protection, and reward. It will be prudent for us to reflect on the implications of this before embarking too energetically on the next generation of metadata standardisation to suit our own piece of the puzzle.
The Rights-holder communities
There are currently four major active communities of rights-holders directly confronting these questions: the DOI community, at present based in the book and electronic publishing sector; the IFPI community of record companies; the ISAN community embracing producers, users, and rights owners of audiovisuals; and the CISAC community of collecting societies for composers and publishers of music, but also extending into other areas of authors' rights, including literary, visual, and plastic arts.
Each of these communities has its own large-scale projects (respectively DOI, MUSE, ISAN, and CIS) which address metadata issues.
- DOI (Digital Object Identifier) is an umbrella term for a set of related initiatives centred on a persistent digital identifier (the DOI), a technology (Handle by the Corporation for National Research Initiatives [CNRI]), and an organisation (the International DOI Foundation). Although started by the book and electronic publishing community, it is attracting wider membership. Metadata definition has become a major issue for the DOI.
- MUSE is an EC-funded initiative of the record industry scheduled to announce (around October 1998) a secure means of encoding and protecting identifiers within digital audio. It is linked to the ISRC (International Standard Recording Code), and the project includes the specification of ISRC-related metadata.
- ISAN (International Standard Audiovisual Number) is backed by the film industry and collecting societies and is currently in draft in ISO TC46 sc9. It will be the backbone of several industry databases and related metadata sets.
- The CIS (Common Information System) plan is a copyright society-led international standardisation programme based on the integration of identifiers and related metadata to support efficient licensing and royalty distribution. It is based on an international "party" identifier (the CAE/IP number) and has introduced the ISWC (proposed International Standard Work Code in ISO TC46 sc9) for identifying abstract works.
There are related rights-driven projects in the graphic, photographic, and performers' communities. E-commerce means that metadata solutions from each of these sectors (and others) require a high level of interoperability. As the trading environment becomes common, traditional genre distinctions between creation-types become meaningless and commercially destructive.
In this paper, I refer to "DOI metadata" as shorthand for "metadata enabling the description and rights ownership of digitally-traded creations".
The INDECS project
A 12-month EC-funded project, INDECS [1] (Interoperability of Data in E-Commerce Systems), is scheduled (subject to contract) to start in October to find a number of practical solutions for matters of common interest by drawing together the relevant work of these separate projects. The trade associations of almost all the major rights sectors are participating.
The challenge for DOI and the INDECS project is to create a genre-neutral framework among rights-holders for electronic IPR trading so that companies which at present are record companies, film companies, book and music publishers can trade their creations in a coherent single marketplace.
What follows is an examination of some fundamental dependency relationships in rights and descriptive metadata and how these may be worked out in practice.
This paper examines three propositions which support the need for radical integration of metadata and rights management concerns for disparate and heterogeneous materials, and sets out a possible framework for an integrated approach. It draws on models developed in the CIS plan and the DOI Rights Metadata group, and work on the ISRC, ISAN, and ISWC standards and proposals.
The three propositions are:
- DOI metadata must support all types of creation.
- The secure transaction of requests and offers data depends on maintaining an integrated structure for documenting rights ownership agreements.
- All elements of descriptive metadata (except titles) may also be elements of agreements.
The main consequences of these propositions are:
- A cross-sector vocabulary is essential.
- Non-confidential terms of rights ownership agreements must be generally accessible in a standard form. (In its purest form, the e-commerce network must be able to automatically determine the current owner of any right in any creation for any territory.)
- All descriptive metadata values (except titles) must be stored as unique, coded values.
If correct, the implications of these propositions on the behaviour, and future inter-dependency, of the rights-owning and bibliographic [2] communities are considerable.
Creations
The generic term creation was coined within the CIS plan to denote a product of human imagination and/or endeavour by one or more Parties in which Rights may exist. The term has the advantage that it does not carry much baggage. It is free of the connotations or legal encumbrances of the narrower term work and it has not been hitherto employed in any specific sector. It is now employed as a basic term in the vocabularies of CIS, DOI and in the IMPRIMATUR business model.
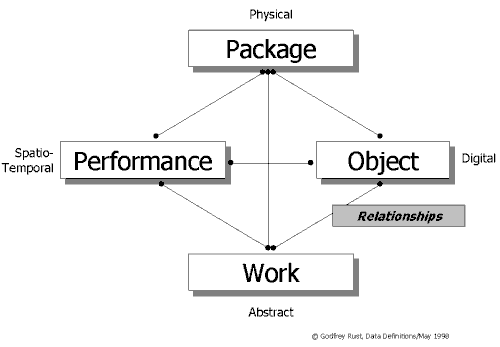
Creations appear to come in four main structural types:
Structural type
Medium (material)
Examples
Means of identification
Package
Physical (atoms)
Book, CD, video, photograph, painting
Printed text or barcodes (e.g., UPC/EAN, ISBN, ISSN, ISMN)
Object
Digital (bits)
Text, picture, audio, av file
Digitally encoded (e.g., ISRC, ISAN [3], DOI )
Performance
Spatio-temporal (actions)
Live performance of work, broadcast of recording
In metadata only
Work
Abstract (concepts, ideas)
Musical composition, literary work
In metadata only (e.g., ISWC, ISAN [3])
Each structural type of creation may be manifested in any other. So, for example, the song A Day In the Life was written by John Lennon and Paul McCartney (creating an abstract work) and performed by the Beatles (creating a performance). The performance was recorded and later remastered by George Martin (creating an object), and the recording included in an CD released by EMI (creating a package). The same principles apply in audiovisual, visual, text and other primary types. The generic structural relationships are modelled in Diagram 1.
Diagram 1. Creation Structural Types: Descriptive DataAnother way of saying this is that creations can be said to be nested within each other: this also applies to creation of the same type (such as acts in a play or movements in a symphony). In the example of A Day In The Life, a work is nested in a performance nested in an object nested in a package.
The phenomenon of nesting is the norm for most works, not the exception -- for example, every sound recording manifests at least one corresponding composition, and every printed edition manifests at least one corresponding "underlying" literary work. When one creation is traded, a complex network of them may in fact be traded. A single multimedia creation may nest hundreds of audiovisual works, graphics, texts, audio recordings and all their underlying abstract compositions and works: often thousands of distinct creations with attendant rights owners.
Of course, there is nothing new about these relationships in themselves, but e-commerce creates the ability for each component creation to be individually discovered, identified, offered, acquired and for the resulting transaction to be accounted to source.
The implications for scalability are ominous. We already know that the variety of ways in which creations can be used, adapted or combined with readily available electronic tools in an environment which will be accessible in time to billions of users makes the issues of secure protection and billing of utmost importance.
However, under the analysis being carried out within the communities identified above and by those who are developing technology and languages for rights-based e-commerce, it is becoming clear that "functional" metadata is also a critical component. It is metadata (including identifiers) which defines a creation and its relationship to other creations and to the parties who created and variously own it; without a coherent metadata infrastructure e-commerce cannot properly flow. Securing the metadata network is every bit as important as securing the content, and there is little doubt which poses the greater problem.
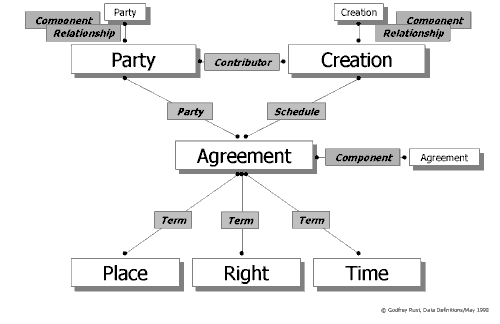
Rights and Agreements
Creations are made by people who may then assign Rights in them to other people or companies through Agreements.
A right is defined in CIS as the authority originating in law or by international convention for a Party to do or to authorise another Party to do a defined act to a Creation.
An agreement is a written or unwritten accord between Parties which determines Rights or entitlements in relation to Creations for a given Place and Time. These relationships are shown graphically in Diagram 2, which models the fundamental entity relationships that underlie an integrated model. Agreements embrace everything from a copyright act at one extreme to the terms of a single download transaction at the other.
Diagram 2. Primary Entity Relationships: Integrated Data ModelParties
Generically, people and companies may be called Parties (a simpler form of the CIS term Interested Party). They require unique structured identifiers because names, though helpful for discovery, are inadequate on their own for secure identification (which John Williams is it?) and dangerous as a basis for automated e-commerce transactions because they are not unique. Metadata for people and companies has to be integrated at the primary level of parties because either type may be parties to the same Agreements.
Because parties may make creations and own rights of any kind, party metadata must be adaptable to all creation types. John Lennon created words, music, performances, recordings, audiovisual works, books, drawings, and photographs and owned and traded rights in all of them.
Ownership and exploitation of rights in different creation-types is now the norm. Most the major players in the different sectors deal in text, pictures, sound recordings, photographs, graphics, and audiovisuals: the differences between them are of proportion, not type. If there will be no essential operational difference between an e-publisher and an e-record company or e-film company -- and it seems that there won't -- then the metadata framework has to embrace all their requirements. Just as an entertainment retailer uses the same EPOS systems for all types of package, e-commerce must accommodate all types of creation. It should also be considered that, in operational if not commercial terms, there may be little or no difference between the digital transactions of an e-publisher and an e-library.
Rights metadata
Every transaction involving creations can be described as a grant (or refusal) of rights, even where the rights are in the public domain. These transactions can be described in the same terms for physical packages such as books and sound carriers as for digital objects or abstract works, although the grant of rights may be accompanied by different consequences for different structures.
For example, grant of rights in a package will normally result in some kind of sale or reproduction. If it is in an object there may be the copying or manipulation of a digital file. In an abstract work, it will ultimately result in the making of one or more new creations of other types such as a new performance, recording and sound carrier manifesting a song.
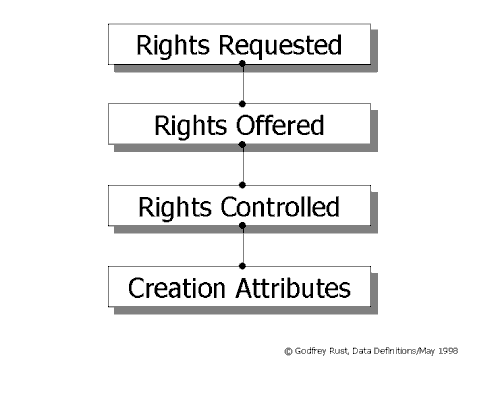
What is commonly called Rights metadata may be expressed in three distinct categories which may be named as follows:
Requests
The specified use(s) to which a party wishes to put a creation(s) ("Rights Requested")
Offers
The terms under which a creation(s) may be put to specified use(s) ("Rights Offered")
Agreements
The terms of a completed transaction ("Rights Controlled")
To date, the DOI working group has focussed exclusively on the first and second of these, where the principle concern is the business-to-end-user relationship. The CIS Plan has dealt exclusively with the third element, where the main object is the structured documentation of rights ownership as it has been passed in creator-to-business or business-to-business agreements.
In fact, all three are inextricably linked in a chain of "metadata dependencies", set out simply in Diagram 3:
Diagram 3. Metadata Dependences: Integrated Data ModelThese three forms are intimately related. The terms of the Rights Requested will depend on the terms of Rights Offered. When a consumer finds a packet of tea in a hypermarket, he knows it is for sale and for what price. In a more exclusive shop and for a more valuable object, he may negotiate a deal, but not for his day-to-day commodities. E-commerce will be, in general, a virtual hypermarket dealing in high-volume day-to-day commodities. Automated e-commerce requires that, as far as possible, Requests are made in conformity with structured, well-advertised multiple-choice Offers.
The terms of the Rights Offered (and by whom) will in turn depend upon the Rights Controlled (and by whom). Creations can only be offered if the trader has access to the necessary rights. Early DOI assumptions tended to pre-suppose that the object being traded generally has unitary and static rights. As already shown, this is a misconception.
For example, a publisher may offer under certain terms and conditions downloads of all of his biographies of musicians with attached photographs, music, and audiovisual samples. To do this, he will depend on his own licences from the providers of the visual, audio, and audiovisual clips and their underlying abstract works.
The validity of those licences will change if any "nested" rights change hands, and here is the rub for Rights metadata. Because creations can be nested and modified at an unprecedented level, and because online availability is continuous, not a series of time-limited events like publishing books or selling records, dynamic and structured maintenance of rights ownership is essential if the currency and validity of offers is to be maintained.
Of course in a web environment, the end-user may be enabled to conduct business directly and automatically with the sources who control the original clips and works at the same time as downloading the biographies: this is one of the aims of the DOI system. But the metadata requirements are exactly the same. Rights metadata must be maintained and linked dynamically to all of its related content.
The sheer scale of this, in the longer-term, is the major issue. E-commerce or e-library development to date has largely focussed on managing the possible complexities of individual transactions involving individual creations, but these are nursery school building blocks compared to the constructions lying ahead.
We should consider that a typical creation such as a text, picture, or sound recording put into an e-commerce environment in the year 2000, may within a decade have tens of thousands of continuing "licences" or "agreements" for use in a network stretching out through many generations as rights are passed on in adapted and incorporated creations. These will not be subject to the same physical constraints of time and place as current "physical" licences for reproduction in the form of books or recordings.
A single, even partial, change to rights ownership in the original creation needs to be communicated through this chain to preserve the currency of permissions and royalty flow. There are many options for doing this, but they all depend, among other things, on the security of the metadata network.
This is already managed successfully on a limited, local scale within individual collecting society systems. The CIS plan includes the development of an international agreements system documenting dynamically the ownership of musical works. The CISAC experience at a local society level provides both a model and a warning. The registration of a single change of ownership in a work may impact on thousands of existing complex licences and alter the distribution routing. In situations where the metadata is well-structured, such a comprehensive change can be effected by a single metadata input at the correct point.
On the other hand, where the metadata is not built on structured descriptions and agreements, a single change of ownership becomes expensive to administer effectively, and its impact on licensing arrangements can be a nightmare to track. The CISAC community is well acquainted with these difficulties, for in many systems, the function of maintaining copyright ownership is not yet fully integrated with that of licensing or distribution, resulting in wasteful parallel maintenance of data and inaccuracies in both functions. Many systems are simply unable to reflect the full complexity of rights involved in issues like music commissioned for broadcast or the sampling of sound recordings, which is now endemic within the pop and dance industries. Yet these complexities, regarded in the past as exceptional, are now becoming the everyday pattern in digital environments.
The data structure of the three Rights categories are closely related: Requests and Offers are both potential Agreements, so we can expect a single structure to serve all three. The current CIS Agreements model does not embrace the trading issues comprehensively enough (it was designed only to provide a structured framework for documenting ownership) but provides a sound logical basis that has been proved to work in local environments.
The dependence of Rights metadata on Descriptive metadata
We will come back in more detail to the structure of agreements data, but now we must take the rights "chain" one step further and find that the terms of the Agreements are in turn dependent on the described attributes of the Creation(s) which are being traded.
For example, if an Offer relates to the genre of music biographies in a particular publisher's catalogue, the Agreement chain must refer to the appropriate genre classification. The attribute values for "biography" and "music" must therefore be interpretable to the Rights metadata set. This requires a unique value for each, common to both Descriptive and Rights metadata systems, to be held as an attribute of the creation. We may refer to this as the class attribute values being "operable" in agreements.
This phenomenon also embraces the events and extents in a creation's metadata. Dates of creation or publication, and the dimensions of the creation itself, are frequently operable in agreements to determine copyright ownership or status, and price to be paid.
We already know, of course, that a creation's identifiers (such as ISBN, ISRC, UPC, or SICI) are operable in agreement-based transactions: indeed, an electronic agreement is ineffective unless it is linked explicitly to one or more unique structured identifiers.
How far does this principle go? Analysis appears to show that there is no class, event, or extent which may not at some time be an operable value in a request, offer, or agreement. In particular, we find that modes, formats, derivations, classifications, dimensions, creation and publication dates, contributors, and their roles are all common determining factors in determining the control and flow of rights in creations.
For example, a licencing scheme offered by an agency for JPEG downloads of any wildlife photographs by a specific photographer taken after the commencement of his exclusive agency agreement on January 1, 1996, may depend on structured descriptive metadata values for at least six of those attributes, or links, if it were to be maintained automatically, before any consideration is given to the purposes to which the picture may be put. Further examples are given in the section a vocabulary for Rights metadata below.
We can summarise this chain by saying you have to make a Request in the terms of the Offer, to frame an Offer in terms of the rights that are Controlled, and to frame the rights that are Controlled in terms of the creations that give rise to those rights. Those terms must be compatible throughout the chain.
Of course, in many cases, the terms of Rights Offered and Controlled will be simple and may simply be implied. A web retail transaction is such a case. Either the seller controls all the relevant rights, or he will deal with the accounting process in his own back office with whatever systems he employs.
And of course not all descriptive attributes are always operable in agreements -- but all are sometimes operable. Because of the persistent availability of objects and the volatility of rights in the electronic environment, it cannot be known at the time of description which elements may be relied upon at what point. The only secure and efficient approach is to structure all of it.
"Wide-area" agreements
Where blanket or statutory provisions are in force (what we might call "wide-area" agreements), tracking of permission or royalty liability for either party is problematic in the current environment. But in the electronic dimension, it assumes a quite new order of magnitude.
Rights management is especially vulnerable to change at national or global level. Examples of the byzantine complexity of administering the impact of structural changes in copyright provisions (which in our terminology are new agreements) have occurred regularly in Europe in recent times. For example, the extension of the term of copyright protection to 70 years, and the extension of statutory rights to performers for the public performance of sound recordings were both well beyond the scope of the UK music industry's existing administrative capability, principally because of inadequately structured metadata.
Both measures have required substantial and somewhat frantic systems development and data restructuring, the latter triggering a wholesale gradual reappraisal of the metadata infrastructure surrounding sound recordings in the UK. In both cases, the new "agreements" will be administered in a less than satisfactory way for some time to come because of this legacy. And even with the excellent progress that has now been made, the failure of the record industry to allocate ISRC and capture its metadata at its proper source (the recording studio) is a further metadata tragedy awaiting its costly time on stage.
As digital media causes copyright frameworks to be rewritten on both sides of the Atlantic, we can expect measures of similar and greater impact at regular intervals affecting any and all creation types: yet such changes can be relatively simple to implement if metadata is held in the right way in the right place to begin with.
The DOI and metadata
The disturbing but inescapable consequence is that it is not only desirable but essential for all elements of descriptive metadata, except for titles, to be expressed at the outset as structured and standardised values [4] to preserve the integrity of the rights chain.
Within the DOI community, which embraces commercial and library interests, the integration of rights and descriptive metadata has become a matter of priority. Working groups are considering both the standardised metadata requirements and the structure of a rights transaction language and how the two will work together. The INDECS project will be the context for some of this work, especially on standardised metadata.
The "agreement" model being developed by the DOI working group has to be able to accommodate any type or combination of creative content. It would be short-sighted in the extreme to attempt to structure core metadata to meet only a limited number of known or projected e-commerce models. How the descriptive elements of this model may be expressed is elaborated in the vocabulary sections below.
What is required is that the establishment of a creation description (for example, the registration of details of a new article or audio recording) or of change of rights control (for example, notification of the acquisition of a work or a catalogue of works) can be done in a standardised and fully structured way. Unless the chain is well maintained at source, all downstream transactions will be jeopardised, for in the web environment the CIS principle of "do it once, do it right" is seen at its ultimate. A single occurrence of a creation on the web, and its supporting metadata, can be the source for all uses.
One of the tools to support this development is the RDF (Resource Description Framework). RDF provides a means of structuring metadata for anything, and it can be expressed in XML. Its value depends on there being structured vocabularies for specific metadata provinces, but it does not provide these vocabularies. These are left to the market to sort out: an integrated DOI metadata vocabulary driven by rights-owner consensus will save a lot of lost time, effort, and business.
These vocabularies will certainly draw on existing standards and authorities, both formal and de facto. Although formal metadata standards hardly exist within ISO, they are appearing through the "back door" in the form of mandatory supporting data for identifier standards such as ISRC, ISAN and ISWC. A major function of the INDECS project will be to ensure the harmonisation of these standards within a single framework.
The framework for the vocabulary which follows is a starting point for DOI and INDECS development. It is elaborated from work done on the CIS common system model and can accommodate existing relevant ISO, EDI and de facto standards. References to Dublin Core are made for comparative purposes. A brief review of the implications of Dublin Core for rights management appears in the conclusion.
In this vocabulary, all Descriptive metadata attributes for creations are structured in four generic groups to describe the attributes of all creation types:
Attribute
Definition
Examples
Identifier
A title or code which designates the creation
ISO identifier (ISBN, ISRC, etc.), proprietary identifier, title, subtitle, series title
Class
A classification of the creation
Primary type, structure, mode, genre, form, subject, data type, sound type, context, derivation
Event
An event in the history of the creation
Created, composed, produced, first published
Extent
A dimension of the creation
Size, duration, speed, resolution
With the exception of titles, all the values within these attributes are expressible as unique codes from appropriate schemes or standards and can therefore become operable within structured agreements.
In addition to this, the vocabulary requires four sets of structured links or relationships, one involving creations and parties and three involving only creations:
Link
Definition
Examples
Contributor
A party playing a role in the making of a creation
Composer, author, performer, artist, dancer, editor, director, photographer, producer, printer, compiler, engineer
Component
A creation which is contained or manifested within another creation
Aria in opera, sample in recording, track on album, poem in anthology, illustration in book, article in journal, audiovisual clip on CDROM
Version
A creation derived from another creation of the same type
Arrangement, adaptation, translation, different technical format, paperback edition, remix, film edit
Reference
A creation whose content refers explicitly to the content of another creation
Abstract, review, annotation, advertisement, blurb
As with attributes, links are fully structured with standard coded values.
Identifiers
Identifiers include titles and structured codes such as ISBN, ISRC, ISWC, UPC, and DOI. A generic vocabulary is needed for title types, as different creation types are accessed and reported within the same systems.
This attribute can be described with these elements:
<IDENTIFIER TYPE>
<IDENTIFIER VALUE>
<IDENTIFIER SEQUENCE>The Identifier Type may come from standard coded vocabularies of title types (Original Title, Series Title, Subtitle, Translated Title, etc.) and code types (ISBN, ISRC, ISWC, DOI, UPC, Publisher Catalogue Number, etc.).
The Identifier Value used for titles is the only item of metadata in this model which is held as non-standardised text rather than a standardised unique value from an authority table.
The Identifier Sequence may be used to establish priority in the case of multiple identifiers of the same type.
Note that there is ultimately no high-level logical distinction between a title and an identifier. Is "Symphony No.3" or "Opus 45" a title or a structured identifier?
A creation may have any number of identifiers.
This attribute group corresponds to two of the Dublin Core elements, Title and Identifier.
Classes include any category attributed to a creation.
This attribute can be described with these elements:
<CLASS TYPE>
<CLASS VALUE>with options for sub-types according to the class.
A framework of generic Class Types can be applied to all creation types. Where possible existing schemes and standards will be drawn from, critically those already operational in relation to identifier standards employed in e-commerce. The only proviso is that they must provide for a unique set of structured values or codes within each class.
Two Class Types are fundamental to the operation of many laws and agreements, and they determine the applicability, or otherwise, of other specific classes or class values to a given creation. These are the derivation (original or version) and the primary type, the highest level of classification.
An agreed set of primary types (for example, sound recording, book, serial, sound carrier, photograph, musical work, audiovisual work, video, literary work, etc.) with their definitions is the single most critical classification exercise to be done.
A primary type falls within a matrix of structural types and modes, though there may be more than one primary type within each intersection. The main criterion for identifying a new primary type in any intersection is that it has its own identification system. The matrix begins to look something like this:
Structural type
Mode
Audiovisual Audio Visual Package
Video (UPC/EAN) Sound carrier (UPC/EAN) Book (ISBN)
Serial (ISSN)
Painting
Sheet music (ISMN)Object
AV recording (ISAN)
SoftwareSound recording (ISRC) Text file
Graphic file
PhotographPerformance
AV performance Audio performance Work
AV work (ISAN)
Dramatico-Musical workMusical work (ISWC)
Literary workWhile cross-sector standard values for the highest-level generic categories are essential, the development of value tables within these for specific creation types is open-ended and can be carried out, as now, within specific sectors operating within the appropriate standardisation framework such as ISO. Many existing classification schemes can be embraced (ISO language codes are an obvious example) but with this proviso: competitive, incompatible classification systems for the same creation primary types are not tenable in rights-based e-commerce. "Cross-walks" for variant codes for directly equivalent values are second-best but manageable.
Some class types will apply to all primary types, but with variable value sets (e.g., form, context, subject).
Some classes will be specific to certain primary types, structural types, or modes (e.g., sound type, picture type, data type, musical genre, literary genre, audiovisual genre, language).
Non-exclusive classes such as subject, language, genre, or context may have any number of class values for one creation.
This attribute group incorporates four of the Dublin Core elements: Type, Format, Subject, and Language.
Events include any event of significance in the making and first publication or distribution of a creation.
This attribute can be described with these elements:
<EVENT TYPE>
<EVENT TIME>
<EVENT PLACE>Event Types typically include creation/composition/compilation and first publication/release.
Event Times may be expressed as a single date/time or a start-finish range and encompass HHMMSS as well as CCYYMMDD (the time, for example, of broadcast of a news bulletin or of a take of a specific recording being sometimes significant).
Places require unique identifiers within a hierarchical framework. Examples of this are already in use, and the ISO territory codes provide a top-level framework. As with other issues of metadata standardisation, the required process is one of extending the widely-used principle of authority files to the next logical step of expressing authorities as unique identifiers.
This attribute group incorporates one of the Dublin Core elements: Date.
Extents include any measurement of a creation.
This attribute can be described with these elements:
<EXTENT TYPE>
<EXTENT MEASURE>
<EXTENT VALUE>Extent Types include measures of duration, physical size, and numbers of components.
Extent Measures indicate the measurement scheme (such as HH/MM/SS, inches, megabytes, no of tracks).
The Extent Value is a numeric value structured according to the measure.
There is no corresponding Dublin Core element for this attribute group.
Contributors
A contribution is the role played by a party in the making of a creation.
This relationship can be described with these elements:
<CREATION-ID>
<CONTRIBUTOR PARTY-ID>
<CONTRIBUTOR ROLE>
<CONTRIBUTOR STATUS>
<CONTRIBUTOR SEQUENCE>Contributor Role indicates the role played in the creative process. One party may fulfil many roles and vice versa.
Contributor Status indicates a standardised distinction in level of contribution (e.g., featured/non-featured).
Contributor Sequence may be used to establish priority in reporting (although this may normally be established by default rules).
A creation may have any number of contributors.
This link group incorporates two of the Dublin Core elements: Creator and Contributor. For certain creation types Publisher may be included as a contributor role, but normally the Publisher element is a component of Rights metadata.
A component is a creation nested or manifested in another (the term "manifestation" is only used where the relationship is between creations of different types).
This relationship can be described with these elements:
<HOST CREATION-ID>
<CONTENT LOCATION>
<COMPONENT CREATION-ID>
<CONTENT LOCATION>
<CONTENT EXTENT>
<CONTENT REALISATION>Content Host Location indicates where in the host the component appears (e.g., on page 45, a bitmap reference, side/track on a cassette).
Content Component Location indicates, in the case of excerpts of one creation being used in another, where in the component it appears.
Content Extent indicates how much of the component creation has been incorporated.
Content Realisation indicates any transformation process which is a function of the relationship.
In a component relationship, precedence between host (or composite) and component may be on either part (a creation may be extracted from another, or may be compiled from a set of components) and is not necessarily possible to determine. Their making may be simultaneous or overlapping.
A single creation may have any number of component relationships. The issue of granularity is dealt with below.
This link group incorporates one of the Dublin Core elements: Relation, and possibly that of Source. As described in DC, a Source relationship embraces elements of both manifestations and versions.
A version is a creation recognised as primarily an adaptation of another. (This recognition may be acknowledged at the outset by its creator or publisher, or established by legal process when someone sues.)
This relationship can be described with these elements:
<CREATION-ID 1>
<CREATION-ID 2>
<VERSION TYPE>Version Types have different values (e.g., edition, arrangement, format, adaptation, translation) according to primary type.
In a version relationship, precedence of source over version is not necessarily recognisable (for example, simultaneous release of hardback and paperback, CD and cassette or Word and Wordperfect documents).
The issue of version granularity is dealt with below.
A single creation may have any number of version relationships.
This link group possibly corresponds to one of the Dublin Core elements: Source. (See note in previous section.)
A reference is a creation related by its content or purpose to another creation. Reviews, biographies, abstracts, promotional blurbs, advertisements, and samplers are all examples of references.
This relationship can be described with these elements:
<CREATION-ID 1>
<CREATION-ID 2>
<REFERENCE TYPE>Note that a creation which is also a reference (such as an abstract or an annotation) is fully a creation in its own right, with its own attributes, links and related rights.
Reference Types may be a relatively simple and high level set, as the forms of the related creations (for example, novel and book review) will establish the precise function of the relationship.
A single creation may have any number of reference relationships.
There is no directly corresponding Dublin Core element for this link group, although the Description element deals with limited examples of References.
Creations may be identified at any level of granularity. The principle of functional granularity states that entities only need to be identified when they need to be identified. Granularity is a separate issue for versions and components.
Version granularity is an increasing problem, especially with digital production and modification of documents. The key lies in the structured metadata. A new version must be recognised if a new attribute or contributor is present, but not because of a change in relationships with other creations or agreements.
Component granularity is similar. Where a component is a distinct element, such as an aria in an opera or chapter in a book, with its own identifiers, classes, extents (and possibly events), then separate identification is logically simple, although different technical solutions are required for different primary types. The SICI code is an effective example of this principle.
However, components are often less easily differentiated, such as a five-second sample of a recording or a stanza quoted from a poem. Here there are two alternatives for dealing with granularity.
One option is for the excerpt to be dealt with by a Component Link (as described under Components above) between the original and the new host creation, where the location and quantity of material used will be described as shown in <CONTENT LOCATION> and <CONTENT MEASURE>. For example, where a paragraph from one article is quoted in another.
The other option is to treat the excerpt as a new creation in its own right and furnish it with identifiers and other attributes. The criterion here is a functional one: is this same excerpt used rarely or repeatedly? If repeatedly, it will be helpful for discovery (though generally irrelevant for rights administration) to establish a separately titled creation. If rarely, don't waste your time.
The unique identification of parties is fundamental to the unique identification of creations, especially in the area of abstract works.
Differing commercial pressures have resulted in uneven development of structured identifiers. While the book industry has been efficient with its creation identifiers (ISBN, ISSN, SICI, et al.), it has neglected to devise any serious structured identifiers for its parties -- principally authors and publishers.
On the other hand, the composer and publisher community has for more than two decades had an efficient party identifier: the CAE (Compositeur, Auteur, Editeur) number, now being developed into the broader IP (Interested Party) number, is the backbone of its collective administration. Yet only in the last two years has it begun to apply a structured identifier (the ISWC) to its repertoire.
The commercial consequences for both industries of these blind spots in their infrastructure may be guessed at -- certainly for the music industry there has been substantial and avoidable inefficiency -- but continuing neglect is unthinkable in e-commerce. There is a basis for a constructive integration of these two approaches, as we will also see later in the area of Rights metadata.
Party attributes and links mirror those of creations almost precisely. Parties have identifiers (substituting names for titles), classes, and events, the structure of which are the same as for creations, and in some cases (e.g., musical genres, places), the supporting value tables are identical. However, as parties undergo continuous change in space and time they do not have fixed extents.
Parties appear to have four major primary classes (people, personae, corporate entities and corporate trading names).
Parties have the equivalent of component (group member, affiliate company) and reference (father, husband, sister, personal assistant) relationships with other parties, although unlike creations these links can also have <START TIME><END TIME> elements.
In place of versions they have personae (for people) and corporate trading names (for companies). More extensive analysis of party metadata is not required for the purpose of this paper.
We have already seen that Requests, Offers and Agreements are all different conditions of the same thing. Without addressing all elements of the structure and relationship of agreements, which is a matter beyond the current scope, this section considers the general framework and some of the metadata elements which agreements must contain. The analysis draws on the CIS Agreements model and on the work being done in the DOI Rights Metadata group.
The rights chain normally starts with a primary "agreement", determined by law, whereby the creator(s) own 100% of all rights and entitlements for all creations for all places and times. Thereafter, different rights and entitlements are assigned in part or whole through a chain of agreements valid for specific places and times.
Some chains may remain very simple. Others, such as music sub-publishing networks, become very complex, with dozens of agreements distributing rights to different parties, but all agreements can be expressed in a unified model. Such a structure is operated successfully in a number of copyright societies, and the CIS Plan has now agreed on a generic Agreements data model which it plans to implement within the CISAC network.
Note that an "agreement" here is a defined technical term and does not necessarily correspond to a specific contract, which may on analysis include several distinct agreements.
Any agreement may contain basic elements along these lines:
<AGREEMENT TYPE>
<AGREEMENT CLASS>
<PARTY-ID>
<PARTY ROLE>
<PARTY SHARE>
<CREATION TYPE>
<CREATION CLASS>
<RIGHT>
<ENTITLEMENT>
<PLACE>
<START TIME>
<END TIME>Agreement Types will embrace a range of primary types such as exclusive creator assignment, non-exclusive assignment, sub-publishing. Requests and Offers probably belong at this level.
Agreement Classes will include genre-specific forms.
The Party-ID, Role and Share identify the party, his role in the agreement (not his commercial role in the market) and his share in benefits arising from this agreement.
The Creation Type(s) identifies the primary type(s) of creation covered by this agreement.
The Creation Class(es) identify any other restrictions in scope such as by Genre, Form, Sound/Picture/Data Type or Context.
The Right(s) are those assigned or offered or requested, and values will vary according to Creation Type and Place.
Entitlements determine the specific limited actions and uses with the given right(s) permitted by the agreement. Where the agreement involves consumer end-users, the range of Entitlements will be extensive, and will adapt or combine with other creations including all variants of the entitlement to use. Many of these entitlements will have attached price values (or zero values).
Place will normally refer to ISO Territories or their composites, although end-user entitlements may operate at a lower level of granularity of place.
Start and End Times identify the term of the agreement.
An agreement is ineffective unless associated with one or more specific creations. This may be done by Creation Type but more often by a link to a specific Creation-ID, or a group of Creation-IDs. This may, in turn, be mediated by links to other agreements; to class, extent or event attributes of the creations (e.g., "all creations of type w, format x, publication date prior to y and size z)"; or to contributor ("all creations by writer a"), component (e.g., "this creation and all its components"), version (e.g., "this creation and all its derivatives") or reference (e.g., "this creation and all reference creations under common ownership") links.
Common agreements where creation attributes are relied upon include those which govern a creator's output for a specific period (such as an exclusive songwriter or author's agreement); when the creation Event Type becomes operable in rights metadata to determine whether a specific creation is covered; where term of copyright is concerned then either the Creation Event Type (for example, under current US Law) or the Party Event Type date of death (under the Berne Convention) will be operable; and where quantity of content used impacts on price, the Creation Extent attribute will be operable in Rights metadata.
This high-level review of Agreements has shown that all four Creation attribute groups and all four Creation link types may be relied upon at some point or other for electronic Rights management.
The structuring and definition of the final Entitlements ("business rules") within the agreement chain is the ultimate requirement: work on solutions for this is being carried out in a number of contexts, including DOI/EDItEUR working groups. Its successful integration with the Agreement and Descriptive metadata infrastructure described above becomes DOI's holy grail.
The Agreement incorporates two Dublin Core elements: Publisher and (partly) Rights.
The dependence of Descriptive metadata on Rights metadata
We have seen how in e-commerce, rights metadata is dependent on descriptive metadata. Finally, we can see how the reverse is true.
Many agreements allow a user to modify an acquired creation (for example, by abridgement, expansion, substitution of new text, incorporation, or other customisation) and then making that material available to others. A new version has therefore been created which requires its own descriptive metadata to be generated, including the generation of new version, component, reference, and contributor links, to support the continuing commerce chain.
How will this be done? In an automated, protected environment, this requires that the rights transaction is able to generate automatically a new descriptive metadata set through the interaction of the agreement terms with the original creation metadata. This can only happen (and it will be required on a massive scale) if rights and descriptive metadata terminology is integrated and standardised.
The implications of the three propositions and the framework above are clearly not trivial, and they are considered below in three sections: Authoritative metadata, the development framework and The Dublin Core.
Authoritative descriptive metadata
The integrated model raises the question of responsibility for creating and maintaining metadata. If metadata must become stable and reliable, it must be authorised, and that leads us back to the fundamental principle of the CIS plan, namely, that data should be created once, correctly, at source: "Do it once, do it right".
As resources become available virtually, it becomes as important that the core metadata itself is not tampered with as it is that the object itself is protected. Persistence is now not only a necessary characteristic of identifiers but also of the structured metadata that attends them.
Structured resource descriptions for creations or agreements should only be created or amended by the parties who make them, or by their authorised agents. This principle is followed already in the allocation of standard identifiers such as ISBN, ISRC, and ISWC. This does not, of course, exclude the work of libraries or other bibliographic agencies; indeed, the expertise of these groups is finding itself a new market in providing services for content providers and rights owners. This is likely to be a growing trend as the dynamics of the Web change the focus of activity from re-generating metadata many times to the development of ever-more sophisticated discovery, access, and protection techniques.
This leads us also to the conclusion that, ideally, standardised descriptive metadata should be embedded into objects for its own protection. This runs counter to some of the current MPEG thinking. There are good reasons for being wary of any enforcement of such proposals, but in any case standards and tools for the creation and linking of standardised descriptive metadata to web-based creations is a priority.
It also leads us to the possibility of metadata registration authorities, such as the numbering agencies, taking wider responsibilities.
It is likely there will be a revolution in the process by which rights ownership is asserted. At present, copyright societies are among the few places where electronic documentation of rights ownership agreements is maintained, and integrated with commercial transaction processing.
There appears to be no alternative to the development of an infrastructure for registering and maintaining creation ownership claims actively in the web (or through agencies with dynamic interaction with web licensing networks). In many sectors, the role of formal ownership registration authorities is either primitive or largely non-existent. The notable exception is the music sector of CISAC, whose societies operate extensive registration systems, accompanied by procedures for dispute resolution. These are being globalised through the CIS Plan.
It may appear that ISBN and ISRC agencies provide such a registration service. In fact, they record only the identity of the publisher at the time (and sometimes not even that) -- which is no more than a clue to the possible underlying rights holders, of which we have seen there may be many, and is fixed at a given point in time.
Many rights owners themselves, including music publishers, book publishers or record companies, are not yet equipped to manage their own property electronically and are only now embarking on the process of translating their contractual archives into an operational technical environment. In one way this is unfortunate, as rights owners are only now scrambling to prepare themselves for an environment which is already among us. In another way, though, it is convenient, as there are communities perhaps more prepared to recognise and embrace standardised solutions.
Some testing of integrated licensing and registration systems is currently taking place (for example, within the IMPRIMATUR project). There will be a range of solutions, and the market will provide agencies (existing and new) willing to undertake the work, but comprehensive common metadata standards are sine qua non.
There is urgency about this task, but there should not be hurry. Half-baked solutions will give us serious indigestion.
Each sector's rights owners have their own strong and weak points. The book/electronic publishing sector is strong on creation identifiers and familiar with complex concepts of metadata description, but weak on party identifiers and has no structure for describing or registering agreements. In CISAC, those roles are reversed. With the completion of the MUSE project later this year, IFPI will become a significant player in copy management; and the ISRC and ISAN standards beg all of the rights metadata questions.
Though the problems are formidable, the pace of web development means that solutions are now technically attainable. XML (Extensible Markup Language) and RDF (Resource Description Framework) can provide a technical infrastructure; Xerox's DPRL or others can provide a basis for the verbs and syntax of a standard rights language; and existing ISO, EDI and CIS standards can provide some of the attribute values for the vocabulary.
Further registration authorities and tools for certain Party, Creation and Agreement data will be needed.
CISAC provides the basic model for Rights Control metadata. The DOI sector may wish to concentrate on Rights Offered and Requested, and on vocabulary for the book/print/text creation types. IFPI, ISAN, and other sector initiatives may provide their own subsets.
The INDECS project (assuming its formal adoption next month), in which the four major communities are active, and with strong links to ISO TC46 and MPEG, will provide a cross-sector framework for this work in the short-term. The DOI Foundation itself may be an appropriate umbrella body in the future.
We may also consider that perhaps the main function of the DOI itself may not be, as originally envisaged, to link user to content -- which is a relatively trivial task -- but to provide the glue to link together creation, party, and agreement metadata.
The model that rights owners may be wise to follow in this process is that of MPEG, where the technology industry has tenaciously embraced a highly-regimented, rolling standardisation programme, the results of which are fundamental to the success of each new generation of products. Metadata standardisation now requires the same technical rigour and commercial commitment.
However, in the meantime the bibliographic world, working on what it has always seen its own part of the jigsaw puzzle, is actively addressing many of these issues in an almost parallel universe. The question remains as to how in practical terms the two worlds, rights and bibliographic, can connect, and what may be the consequences of a prolonged delay in doing so.
The Dublin Core initiative (http://purl.oclc.org/metadata/dublin_core/) is currently the focal point for object-related bibliographic metadata development. How does it relate to the initiatives described above?
As a basis for descriptive metadata for rights owners, Dublin Core has four principal difficulties. First, as a core data set, it is compromised. Its weaknesses have been highlighted elsewhere (for example, David Martin Beyond Dublin Core), and are touched on in the comparison above. The difficulties include:
- Extents (including duration, size or number of components) are not recognised.
- Locations are not recognised in relation to events (Dates).
- There is insufficient flexibility in time (neither date ranges or granular measurement in HHMMSS).
- Creators
and Contributors are arbitrarily separated (less importantly, so are Titles and Identifiers), and there is no core provision for specifying their role or status.- A Description, such as an abstract or even an annotation, is treated as a descriptive element instead of a logically separate creation of its own with attributes and rights of its own.
- A Publisher is treated as a descriptive rather than a rights element.
- It fails to take proper account of the significance and structure of the entity-to-entity links which undergird the metadata network. The elements of Source and Relation inadequately describe creation relationships.
- As it does not deal adequately with "nesting" or manifestations of creations, it is likely to commonly lead to the attribution of element values at the wrong level.
- Its definitions lack precision.
There are significant question-marks over the majority of the fifteen elements. Their grouping into three overall categories (Content, Intellectual Property, and Instantiation) doesn't really help. Why, for example, is a Title an attribute of Content and an Identifier an attribute of Instantiation? One creation may have different titles in different contexts. At each stage in its progress, Dublin Core leaves open more doors for exceptions and anomalies.
Secondly, its attributes, terminology, and examples are derived principally from text-based creations. This may be the reason for some of the difficulties already noted, and make it likely to appear largely irrelevant to owners and publishers of audio, audiovisual, and abstract works, despite the fact that a cross-sector vocabulary is now essential.
Thirdly, Dublin Core's structure is neither tight enough to satisfy the requirements of a rights-based system (which as we have seen needs a fully structured framework) nor loose enough to be able to accommodate such a structure being imposed from another source. It recognises the principles of adopting standard value sets (notably in the Canberra Qualifiers) but does not apply the principle extensively or ruthlessly enough [5]. Free text has to be driven out of core digital metadata, and this is too low on its agenda [6].
Finally -- and this is the main difficulty with Dublin Core for rights owners -- it views rights metadata as an extra (15th) element or set of elements, not recognising that, in fact, it embraces 13 of the other 14 elements (Titles being the only exception). If this paper is correct in its propositions, then rights metadata will have to rewrite half of Dublin Core or else ignore it entirely.
Does any of this matter? After all, wasn't Dublin Core developed as a metadata set for the limited purposes of supporting discovery? What harm is there if rights owners go ahead and develop their own set to meet their own requirements?
Here's the rub: unfortunately it does. In the web environment, there is no logic in having one core metadata set for discovery and one for rights management: they are, at heart, one and the same. If Dublin Core is to become a standard, what will it be a standard for? For core metadata? If there is to be a formal standard, the argument of this paper suggests that it must take account of both the rights and descriptive requirements. Is Dublin Core, then, for core metadata for discovery purposes only? When it has almost a 100% overlap with the requirement for rights management?
Dublin Core's stated ambition includes the following:
It would encourage authors and publishers to provide metadata simultaneously with their data. It would allow the developers of authoring tools for network publishing to include templates for this information directly in their software, making it even easier for the information providers to supply it. The metadata created by the information providers would serve as a basis for more detailed cataloguing or description when warranted by specific communities. In addition, it would ensure a common core set of elements that could be understood across communities, even if more specific information was required within a particular interest group. Because of the inadequacy of current search engines to provide relevant search results given the huge number of Internet resources being searched, fielded searching could be provided to allow for more precision if metadata were available for them.
Simply add the phrase "and rights management" after the word "description" in the third sentence and this requirement is as broad as it could be.
The prize here is a worthwhile one. We are at a watershed. The web environment with its once-for-all means of access provides us with the opportunity to eliminate duplication and fragmentation of core metadata; and at this moment, there are no legacy metadata standards to shackle the information community. We have the opportunity to go in with our eyes open with standards that are constructed to make the best of the characteristics of the new digital medium.
Dublin Core is a solution born out of the practices of a non-digital age. Applying it extensively in an environment where rights and descriptions are intimately inter-dependent may be very costly. We will not only have a new circus of competing versions like that which has followed the development of AACR, MARC, and other "standards" (this may have already begun with Dublin Core), but we will be asking rights owners (who at present are rarely able to provide one clean set of metadata into the community) to generate at least two -- one for rights management, and one for a specific sector of the "discovery business"; and we will provide huge confusion for developers who will be confronted with two partly incompatable metadata "standards".
There are those who will argue that the Dublin Core compromise is the best that we can hope for. To quote from the proceedings themselves:
Early in the course of the workshop it became evident that no single data element set whether limited or unlimited would satisfy the widely divergent and highly specific needs of the various stakeholders.
This is defeatism of the highest order and akin to stating that no single word-processing package could meet the widely divergent and highly specific needs of every document writer. Perhaps too much attention has, understandably, been given to the various applications to which metadata is put, and not enough to its fundamental nature and structure. Computers do not like muddled thinking: there is very little difference now between the requirements of metadata analysis and those of computer programming. Dublin Core is a horse designed by a committee, and we cannot afford such transport on superhighways.
I make these closing remarks reluctantly, for I applaud the aims of the Dublin Core initiative and the efforts that many have put into it. Rights owners will concede that it has taken them far too long to begin to get their house in order. Dublin Core has seemed to be the only metadata game in town, and that is precisely why it is dangerous. Of course, this conclusion will be regarded by some as contentious, and by others as irrelevant or unrealistic. The former I encourage to make a case for continued support and standardisation of a flawed Dublin Core in the light of the propositions I have set out in this paper, or else engage with the DOI and rights owner communities in its revision to meet the real requirements of digital commerce in its fullest sense. The latter I can only remind that the structure of the information world is changing in ways more fundamental than we have known before, and those who promote strategic solutions nowadays must have a wide field of vision.
Notes
[1] INDECS partners include the record industry (IFPI), the book/electronic publishing industry (represented through EDItEUR), IFRRO and CISAC societies for literary, audiovisual, music and visual works (ALCS, BILD-KUNST, CEDAR, MCPS/PRS, KOPIOSTO, CAL and SACD), and the Anglo-American multi-media database provider MUZE. Affiliated groups include the international trade bodies, the DOI Foundation, STM, FEP, IPA (book/publishing industry), ICMP (music publishers), AEPO (performers), IFRRO, CISAC, and it is supported by the US Copyright Office. It will have close links with ISO TC46, W3C and WIPO.
[2] I use the term bibliographic in this paper in its broadest sense, to embrace discographic and other activities concerned with the professional cataloguing and description of creations of any kind.
[3] The ISAN (International Standard Audiovisual Number) appears to identify both the audiovisual work and the related object, assuming a one-to-one relationship.
[4] It will be rightly objected that this principle cannot possibly apply to annotations, abstracts and other text descriptions, but in the analysis which follows it will be seen that these things are not technically metadata at all but creations in their own right with their own (explicit or implicit) rights and descriptive metadata sets, and reference links to the creations to which they relate.
[5] Of course not all metadata elements can be expressed as standardised, coded values today (although many can), but the Dublin Core has the opportunity to set out the requirement. Nor do I suggest that core metadata is presented as coded values, but that it is created with the use of coded authority tables.
[6] Free text metadata can and will flourish around a standardised core, but free text searching has a different function. The structured search platforms which Dublin Core aims to serve will be successful in proportion to the precision with which the core metadata itself is structured.
Copyright © 1998 Godfrey Rust
Top | Magazine
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editorhdl:cnri.dlib/july98-rust