Information Visualization
The Information Visualization project has for many years
been exploring the application of interactive graphics and
animation technology to the problem of visualizing and making sense of
larger information sets. This work is based on the premise that many
complex information tasks can be simplified by offloading complex
cognitive tasks onto the human perceptual system.
The Information Visualizer (IV) [Robertson
et al.] is based on a 3D Rooms metaphor to establish a
large workspace containing multiple task areas. In addition, other
novel building blocks were developed to support a new user interface
paradigm.
The IV architecture has enabled the development of a set of animated
information visualizations for hierarchical information, including the
Cone-Tree , the Perspective Wall and the Table
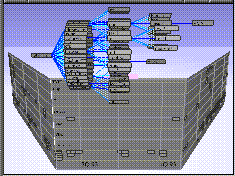
Lens. The figure below shows examples of a cone-tree
and a perspective wall.
Many of these techniques use the display uniformly,
assigning a large number of pixels to a focus area, and retaining
contextual cues in less detail. These techniques allow the display of
larger number of items than could previously be put on the screen.
For example, the top 600 nodes of the Xerox organization chart could
be seen all at the same time even though it otherwise requires an
80-page paper document.
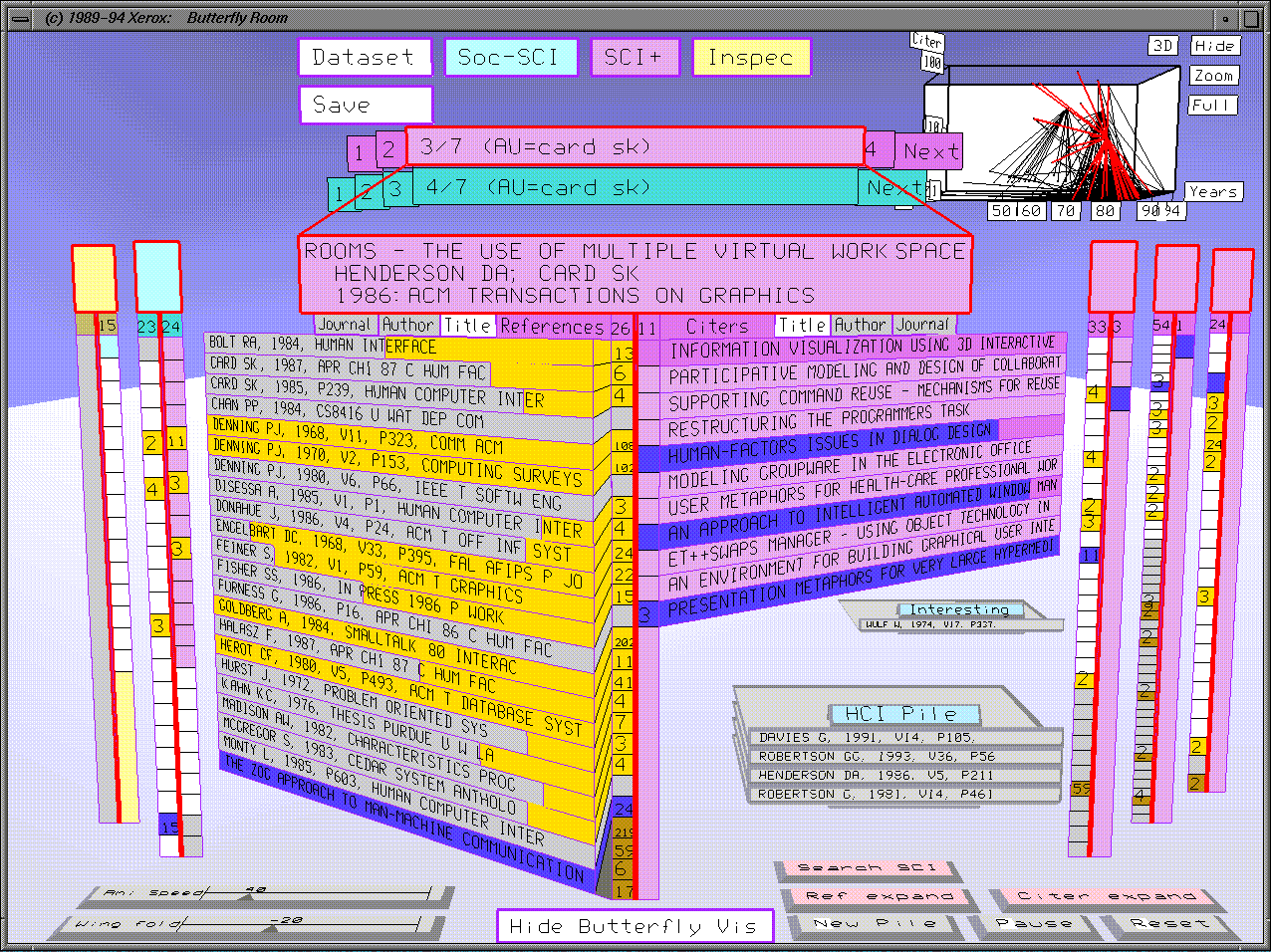
The Butterfly Citation Browser
An application of IV that is of particularly relevance to digital
libraries is Butterfly , an Information Visualizer application
for collections of scholarly papers, which have rich patterns for
visualization including people, time, place, and citation
relationships [Mackinlay et al]. Butterfly
allows the user to quickly navigate citation relationships among
scholarly papers (available from DIALOG's Science Citation databases)
by interacting with virtual 3D objects representing papers and their
citation relationships. Network information often involves slow
access that conflicts with the use of highly-interactive information
visualization. Butterfly addresses this problem, integrating search,
browsing, and access management via four techniques:
- visualization supports the assimilation of retrieved
information and integrates search and browsing activity,
- automatically-created ``link-generating'' queries assemble
bibliographic records that contain reference information into citation
graphs,
- asynchronous query processes explore the resulting graphs for the
user, and
- process controllers allow the user to manage these processes.
Experience with the Butterfly implementation has allowed the proposal
of a general information access approach, called Organic User
Interfaces for Information Access, in which a virtual landscape grows
under user control as information is accessed automatically.
 Full Size Image
Full Size Image
Analytical and Empirical Characterization of
Information-Intensive Work
Information retrieval has often been studied as if it were a
self-contained problem (e.g., library automation). Yet from the
user's point of view, information retrieval is almost always part of
some larger process of information use. Researchers at PARC are
engaged in a set of empirical and theoretical studies to characterize
information-access-intensive work in a way that leads to the design
and evaluation of digital library and related systems.
There are currently three thrusts. First is the characterization
of accessible information in terms of its cost structure [Card and Pirolli]. Information retrieval can be
thought of as just the rearrangement of this cost structure. Second,
is the application of concepts from the literature of optimal foraging
theory from biology to information access. Based on cost and benefit
parameters, this allows us to understand the ecology of various
information strategies, such as direct retrieval vs automatic
dissemination [Pirolli et al.]. Third is the
development of a theory of sensemaking
[Russell et al.], which articulates the methods by which raw
information is combined to produce new information products and
insights. All three of these components are being explored in the
context of the World Wide Web and information access.
Middleware
Middleware refers to software and systems architecture that helps knit
together the various pieces of a distributed information delivery
system, including information repositories, search and retrieval
tools, and client-side workspace tools such as visualizations.
Important emerging issues are the need to develop a network-oriented
object-oriented mechanism for system interoperability, and interfaces
that make use of this mechanism to expose the capabilities of the
underlying sub-systems.
PARC work in interface and middleware development for digital library
integration has focused on three components:
The Inter-Language Unification System (ILU)
There are currently two primary distributed object-oriented
programming paradigms available as open standards in the commercial
market, Microsoft's Distributed Component Object Model (DCOM) and OMG's Common Object Request Broker
Architecture (CORBA). While
there are many differences between the two, and debates about their
relative merits are intense, there is no question that both are
powerful enough to serve as the infrastructure on which to build
digital library systems. The Inter-Language Unification System
(ILU) is an implementation of the CORBA standard that was
developed at PARC and is distributed freely over the Internet. (See
ftp://ftp.parc.xerox.com/pub/ilu/ilu.html.)
ILU is a multi-language object interface system designed to provide
interconnection between components of a distributed system. The object
interfaces provided by ILU hide implementation distinctions between
different languages, between different address spaces, and between
operating systems. For example, ILU allows modules
written in Common Lisp, C++, and Python to be combined.
It also automatically provides networking to interconnect parts of the
system running on different machines, thereby relieving application
programmers of the need to write networking code. Finally, it can be
used to define and document interfaces between the modules of
non-distributed and distributed programs using ILU's Interface
Specification Language. Currently several of the NSF-sponsored
Digital Library Initiative projects are making use of ILU.
The Document Management Alliance (DMA)
Xerox joined with Novell in May 1994 to propose a standard framework
for distributed document repositories called Document Enabled
Networking (DEN). This
standard was both competitive and complementary with the standard
proposed by the Shamrock Document Management Coalition, so in April
1995 they were merged to produce the Document Management Alliance
(DMA), a standards group
under the auspices of the Association for Information and Image
Management (AIIM). The proposed DMA
standard specifies an object system and interfaces for
repository-based document management, including storage and retrieval
of documents of various types, version management services, catalog
information and search services, and integration of services over
multiple repositories. All objects in DMA are self-describing using
mechanisms built into the standard.
The DMA standard is currently in draft form, with a version 1 release
expected by third quarter of 1996. PARC and other Xerox
researchers are actively involved with DMA standards and development
activities. In particular, the 1996 AIIM trade show in Chicago
featured a demonstration of DMA-based interoperability between a
number of client and repository systems, one of which was developed by
Xerox researchers in Webster, New York. In addition, Xerox research
in El Segundo, California, has been involved in porting the XSoft DMA
middleware (available free to DMA members) from Win32 to Unix, and is
currently working on extending the middleware to support distributed
repositories.
The Metro Project
A DMA-related effort at PARC is the Metro research project,
which provides ILU-based interfaces and middleware that allow the
integration of multiple search services over DMA-style repositories.
The integrated services may provide quite different analyses of the
underlying repository documents (e.g., image vs. text retrieval);
Metro allows each of the services to be developed independently and
then integrates their operation and search interfaces.
The Metro implementation
allows for arbitrary distribution of the service and repository system
elements, as well as for optimizations in cases where they are
co-resident. In future, Metro functionality is intended to include
query persistence (result set updates as repository contents change).
UPrint1
Currently when books are published, a large number of them are printed
all at once and distributed to bookstores and other merchants, with
the remainder stored in warehouses. If publishers greatly
overestimate the number of books desired they must absorb the expense
of unsold books. On the other hand, print runs using standard
printing equipment are expensive unless done in bulk.
The UPrint1 project is exploring whether it is practical to
print books one at a time, at the time the customer wishes to purchase
them [Bruce et al.]. (This assumes that the
trend toward digitizing printed material will not make books obsolete,
but rather will make bookstores obsolete. Printed books will
stay around because paper has high contrast and resolution and books
don't require batteries or power cords.) This may be more practical
today than in the past due to the recent availability of high-end,
high-volume publishing systems such as the Xerox DocuTech Network
Publisher. If this effort does prove to be practical, it may
dramatically change the book publishing industry. For instance, books
would not need to go out-of-print, and could be customized when
printed to have large type, use a special kind of paper, and so on.
As another example, small-run, specialized books, such as academic
monographs, should become less expensive to produce.
The UPrint1 project makes use of an online, or virtual, bookstore.
After making a selection at the virtual bookstore, one copy is printed
for the customer, either at home if an appropriate printing device is
available, or at a print shop.
Some advantages of a virtual over a physical bookstore are: it's
contents are searchable, browsing can be done in multiple ways instead
of the static shelf arrangement of a physical bookstore, a larger
selection of books can be available, the bookstore is accessible
anytime from anywhere, and it can provide auto-recommendation from an
appropriate community of experts. On the other hand, a physical
bookstore provides a place for people to meet and talk, allows for the
reading and browsing of physical copies of the books, and often has a
coffee shop next door.
A virtual bookstore without a UPrint1 service is no different from
existing web bookstores in which users find what they want and
publishers fill their orders from a warehouse and ship the physical
books. Thus books that are out of print, or that are temporarily sold
out are unavailable without a mechanism like UPrint1. Futhermore,
UPrint1 avoid the lag time between ordering and receipt of the book.
There are many aspects to making UPrint1 a reality. Currently the
project is focusing on the question of how to entice people to visit
an online or virtual bookstore that has no physical books. One idea
is to give the visitor to a virtual bookstore a recommendation service
they can't get at a physical bookstore. As a sample scenario, imagine
you visit the bookstore and search for books on the Java programming
language. You will get many hits: how do you know which book you
should buy? If you have previously indicated some of your favorite
computer books, the system can match you with readers of similar
taste, and suggest a Java book that these readers found helpful.
Work on this aspect of the project is currently ongoing.
Summary
This article has surveyed some of the recent activities at PARC related to
digital libraries, focussing on document capture, information access and
visualization, and middleware. The set of specific projects described here
is representative of the range of ongoing activities, but is by no means an
exhaustive list of all relevant PARC projects. Missing, for example, are
significant activities in web-based authoring, high-resolution displays,
AAA (authentication, authorization, accounting), multilingual technology,
and electronic commerce-based document services. Information about some of
these can be found via the PARC home
page.
Acknowledgements
Bill Janssen, Ramana Rao, and Hinrich Schütze contributed
material to this article. Kris Halvorsen and Larry Masinter read and
commented on early drafts.
References
[Bruce et al.] R. Bruce, J. Foote,
D. Goldberg, J. Pedersen, K. Petersen, ``UPrint1,'' Xerox PARC
Internal Report 1996.
[Card and Pirolli] S. K. Card and P. Pirolli.
``The Cost-of-Knowledge Characteristic Function: Display Evaluation for
Direct-Walk Dynamic Information Visualizations,'' Proceedings of the
ACM SIGCHI Conference on Human Factors in Computing Systems, April
1994.
[Chen and Bloomberg]
F. Chen and D. Bloomberg,
``Extraction of Thematically Relevant Text from Images,''
Fifth Annual Symposium on Document Analysis and Information Retrieval,
April 15 - 17, 1996, Las Vegas, Nevada.
[Cutting et al. 91] D. Cutting, J. Pedersen,
and P.-K. Halvorsen.
``An Object-Oriented Architecture for Text Retrieval,'' Proceedings
of RIAO'91.
[Cutting et al. 92] D. Cutting, J. Kupiec,
J. Pedersen, and P. Sibun.
``A Practical Part-of-Speech Tagger,'' Proceedings of Applied
Natural Language Processing, Trento, Italy, 1992.
[Cutting et al. 92b] D. Cutting, D. Karger,
J. Pedersen, and J.W. Tukey. ``Scatter/Gather: A Cluster-based Approach
to Browsing Large Document Collections,'' Proceedings of the 15th
Annual International ACM/SIGIR Conference, 1992.
[Cutting et al. 93] D. Cutting, D. Karger, and
J. Pedersen. ``Constant Interaction-Time Scatter/Gather Browsing of
Large Document Collections,'' Proceedings of 16th Annual
International ACM/SIGIR Conference, Pittsburgh, PA, 1993.
[Kaplan and Kay] R. Kaplan and M. Kay.
``Regular Models of Phonological Rule Systems,''
Computational Linguistics, 20 (3), pp.331-378, September 1994.
[Hearst] M. A. Hearst, TileBars:
``Visualization of Term Distribution Information in Full Text
Information Access,'' Proceedings of the ACM SIGCHI Conference
on Human Factors in Computing Systems, Denver, CO, ACM, May 1995.
http://www.acm.org/sigchi/chi95/Electronic/documnts/papers/mah_bdy.htm
[Hearst and Pedersen] M. A. Hearst and J.O. Pedersen
``Re-examining the Cluster Hypothesis:
Scatter/Gather on Retrieval Results,'' Proceedings of the
19th Annual International ACM/SIGIR Conference, Zurich, 1996.
[Johnson et al]
W. Johnson, S. K. Card, H.D. Jellinek, L. Klotz, R. Rao,
``Bridging the Paper and Electronic Worlds: The Paper User Interface,''
Proceedings of INTERCHI, ACM, April 1993. pp. 507-512.
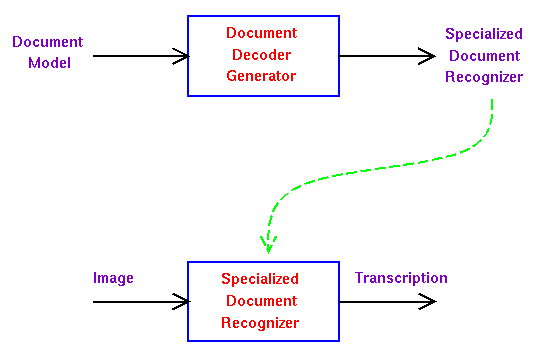
[Kopec]
G. Kopec, ``Document image decoding in the Berkeley digital
library project,'' in Document Recognition III, L. Vincent and J. Hull,
editors, Proc. SPIE vol. 2660, pp. 2--13, 1996.
[Kopec and Chou] G. Kopec and P. Chou, ``Document
image decoding using Markov source models,'' IEEE. Trans. Pattern Analysis
and Machine Intelligence, vol. 16, no. 6, June, 1994.
[Kupiec] J. Kupiec. ``MURAX: A Robust
Linguistic Approach For Question-Answering Using An On-Line
Encyclopedia,'' Proceedings of 16th Annual International ACM/SIGIR Conference,
Pittsburgh, PA, 1993.
[Kupiec] J. Kupiec, J. Pedersen, F. Chen,
``A Trainable Document Summarizer,'' Proceedings of 18th Annual
International ACM/SIGIR Conference, Pittsburgh, PA, 1995.
[Lynch and Garcia-Molina]
C. Lynch and H. Garcia-Molina,
Interoperability, Scaling, and the Digital Libraries A Report on the
May 18-19, 1995 IITA Digital Libraries Workshop Reston, VA,
August 22, 1995.
http://www-diglib.stanford.edu/diglib/pub/reports/iita-dlw/main.html
[Mackinlay et al.] J. D. Mackinlay,
R. Rao and S. K. Card. ``An Organic User Interface For
Searching Citation Links,'' Proceedings of the ACM SIGCHI Conference
on Human Factors in Computing Systems, Denver, CO, May 1995.
http://www.acm.org/sigchi/chi95/Electronic/documnts/papers/jdm_bdy.htm
[Pirolli] P. Pirolli and S. K. Card,
``Information Foraging in Information Access Environments,''
Proceedings of the ACM SIGCHI Conference
on Human Factors in Computing Systems, Denver, CO, ACM, May 1995.
http://www.acm.org/sigchi/chi95/Electronic/documnts/papers/ppp_bdy.htm
[Rao et al. 94] R. Rao, S. K. Card,
W. Johnson, L. Klotz, and R. Trigg, ``Protofoil: Storing and Finding
the Information Worker's Paper Documents in an Electronic File
Cabinet,'' Proceedings of the ACM SIGCHI Conference on Human
Factors in Computing Systems, April 1994.
[Rao et al. 95]
R. Rao, J. O. Pedersen, M. A. Hearst, et al., ``Rich Interaction in
the Digital Library,'' Communications of the ACM, 38
(4), 29-39, April 1995.
[Robertson et al.]
G. G. Robertson, S. K. Card, J. D. Mackinlay.
``Information Visualization Using 3D Interactive Animation,''
Communications of the ACM, v.36, n.4, 1993.
[Russell et al.]
Dan M. Russell, Mark J. Stefik, Peter Pirolli, Stuart K. Card. `` The
Cost Structure of Sensemaking,'' Proceedings of ACM InterCHI '93.
April 1993.
[Sahami et al.] M. Sahami, M. Hearst, and
E. Saund, ``Applying the Multiple Cause Mixture Model to Unsupervised
Text Category Assignment,'' Proceedings of the 13th International
Conference on Machine Learning, Bari (Italy), July 3-6th, 1996.
[Schütze] H. Schütze,
``Dimensions of Meaning'', Proceedings of Supercomputing,
pages 787-796, Minneapolis MN, 1992.
[Schütze et al.]
H. Schütze, D. Hull and J. O. Pedersen, ``A Comparison
of Classifiers and Document Representations for the Routing Problem,''
Proceedings of the 18th Annual International ACM/SIGIR
Conference, pages 229-237, 1995.
ftp://parcftp.xerox.com/pub/qca/sigir95.abs.html
June 5, 1996
Copyright © 1996 Xerox Corporation. Permission to copy without fee
of this material is granted provided that the copies are not made or
distributed for direct commercial advantage, this copyright notice and
the title of this publication and its date appear. To copy otherwise,
or republish, requires a fee and/or specific permission.




hdl://cnri.dlib/june96-hearst