D-Lib Magazine
June 1999
Volume 5 Number 6
ISSN 1082-9873
Personalized Information Environments
An Architecture for Customizable Access to Distributed Digital Libraries
James C. French
Department of Computer Science
University of Virginia
french@cs.virginia.eduCharles L. Viles (Corresponding Author)
School of Information and Library Science
University of North Carolina, Chapel Hill
viles@ils.unc.edu
Abstract
A Personalized Information Environment or "PIE" is a conceptual architecture that allows unified, highly customizable access to distributed information resources by providing users the tools to compose personalized collections from a palette of information resources. The architecture also provides for the efficient exchange of inter-resource meta-information like collection statistics in order to maximize retrieval effectiveness. We identify four conceptual requirements for a PIE: customizability, efficient and effective search, controlled sharability, and privacy and security. Specific technologies needed to achieve these requirements in practice include distributed object systems, resource summarization tools, and integrated security and privacy mechanisms. This paper includes the enunciation of the user-centered PIE vision, an architectural requirements specification, and an architectural description that meets the specification and supports the vision. We also describe our current implementation and research efforts conducted within the PIE framework.
In 1945, Vannevar Bush [2] first described an information environment that he felt was bordering on the unmanageable, with information users awash in research results and scholarly communication and few usable mechanisms to organize them. Bush felt that current mechanisms for dealing with information were wholly inadequate given the volume of work being produced:
Professionally our methods of transmitting and reviewing the results of research are generations old and by now are totally inadequate for their purpose. ... Those who conscientiously attempt to keep abreast of current thought, even in restricted fields, by close and continuous reading might well shy away from an examination calculated to show how much of the previous month's efforts could be produced on call. (p. 101)From this line of thought, Bush then developed his vision of the "Memex", a tool that would allow its user to note, bookmark, and otherwise organize information in whatever fashion made most sense to that user.Visionary in its scope, the Memex continues to give motivation and direction to a large amount of research in information storage and retrieval. It is abundantly clear that today the Memex might help immeasurably in stemming the increasing tide of information. While mechanisms to generate information continue to grow in number and sophistication, tools and techniques to manage, filter, and search lag behind. The level of care taken in the preparation of information for online publication varies greatly. Access to the information is often poor. Even awareness of the existence of specific data is becoming increasingly difficult. Organizational strategies provided by information publishers are publisher-centric or designed to meet the needs of a specific user group.
What is needed are tools that will enable users to create personal collections of information resources of interest to them. It will be necessary to cull tens of thousands of resources for those of specific interest; it will also be necessary to continuously monitor available resources to detect new useful sources or to decide that others are no longer of interest. Efficient search strategies are required to support the discovery of resources and to search and fuse information gleaned from those resources.
In this paper, we present our vision of a user-centered, user-organized information space called a Personalized Information Environment or PIE. In contrast to a typical Internet search of multiple information resources, where control of which resources are searched is in the search engine's hands, a PIE places the control in the user's hands. In the PIE formulation, descriptions of resources are made available to users and they decide which resources to include in a search. The process of resource selection is highly interactive and might involve sample searches and then selection or de-selection of resources from the user's current personalized collection. Regardless of the degree of interactivity, efficient and effective search is provided within whatever context the current collection of resources defines. Since users may spend considerable effort customizing their personal resource collection, it makes sense to allow sharing of the collection in constrained ways or using pre-defined policies while maintaining whatever privacy or security constraints might be placed on particular resources or users. Thus, there are four driving principles behind the PIE:
- Customizability;
- Efficient and Effective Search;
- Controlled Sharability; and
- Privacy and Security.
We believe current solutions and techniques are lacking to some degree along all four of these dimensions. The Personalized Information Environment provides a framework within which alternatives along all of these dimensions can be explored.
Personalized Information EnvironmentsA variety of forces in today's information environment combine to (1) make current modes for dealing with information inadequate and (2) suggest new modes that may provide for more effective use.
As many have noted, there is a continuous, ever-increasing flood of information of all types, quality, and formats. The technology to generate and deliver this information digitally has vastly outstripped the technology to analyze and process it. Information recipients have only coarse-grained control over the information flow -- it can be turned on and off, but it is difficult to throttle it to the desired level. For example, Larsen [19] notes the need for alternative methods for looking at search because, among other reasons, the increasing size of on-line information assures that increasing numbers of documents fit the query criteria. The result: a query that once yielded tens of hits now yields thousands.
In addition, the current multi-collection search engines are relatively crude in their capabilities, both to selectively search subsets of collections and to merge the accompanying results. Duplicate detection, while an active area of research [13], is still in its infancy.
There is, however, reason for hope. For example, we are just beginning to try to exploit the fact that users have different needs, desires, and operational modes and to recognize that relevance means different things in different situations. Given a particular task, two people may approach execution of that task in totally different ways. While designing, building, and evaluating systems that enable and facilitate such diversity is difficult, there is also a considerable opportunity to make real progress in controlling information overload.
In addition, technological capacity (i.e., memory capacity, chip densities, and network bandwidth) continues to obey Moore's law, essentially doubling every 18 to 24 months. Thus, it is restrictive to allow perceived resource limitations to constrain how we think about potential solutions.
Current Distributed Search Architectures
The particular operational scenario that we are concerned with involves information retrieval over multiple information resources, where these resources are distributed and autonomous. They provide a search interface to users, but the internal workings of the resource are not readily available. This multi-database/multi-collection search scenario is a familiar one in today's Internet/WWW environment.
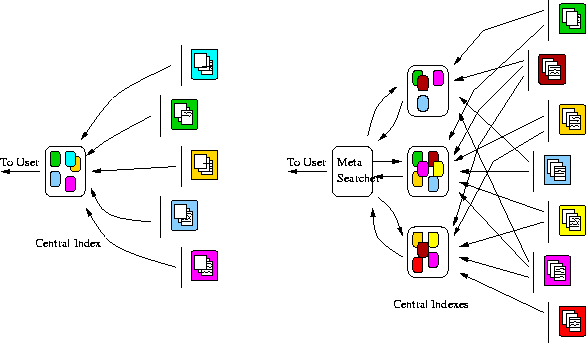
The current state-of-the-art in multi-database search can be seen in the two prevalent search architectures available today on the Web (see Figure 1). The first architecture, which we call the Centralized View, attempts to collect information about all documents in the information universe into a single, possibly replicated database. Searches are then performed on a logically single server and results with document pointers are returned to the user. This architectural view is embodied in Web Search engines like Lycos, Infoseek, Yahoo, and Excite. The Centralized View is the logical first step in trying to provide access to distributed document collections. There are many problems with the view including the following.
- Scale - Ultimately there are too many documents being produced to expect that they (or their surrogates) will reside at any single location.
- Heterogeneity/homogeneity - While data indexed by the search engines is vastly heterogeneous in content and information structure, it is essentially of a single type -- HTML web pages.
- Dynamicity - With few exceptions, search engines index only static HTML pages -- the vast amounts of data for which a web page is only an entry-point are not accessible.
- Currency - Because the centralized index is far removed from its constituent sources, many links are stale and many pages are out dated.
- Privacy/Security - Providers that have privacy or security concerns generally elect not to participate in these services.
- Property - Providers that have intellectual property concerns or who might want to be compensated for their information generally elect not to participate.
Figure 1: Two distributed search architectures. The centralized view (left) maintains a global index of documents downloaded from a large number of resources. The meta-searcher architecture searches several centralized indexes and combines results into a single list of hits.
The second view, which we call the Meta-Searcher view, is embodied in systems like MetaCrawler (http://www.metacrawler.com/). In this architecture, several Centralized search engines are encapsulated in a single common system with a common interface. The meta-searcher must take a user query, send it to each of the engines in its system, collect the results, and present them to the user in an intelligent manner.
In addition to the problems associated with the Centralized View, there are additional problems with the current generation of meta-searchers. Because the inner workings of the search engines are not readily available, intelligent merging of results that present (document, query) similarities on subtly or vastly different scales is difficult. Even if two search engines use the exact same search engine, simple collation of the results can yield sub-par results [24]. The STARTs proposal [11] for meta-data publication was one mechanism to address this problem, though work still needs to be done to verify that proposals like STARTs specify the needed information to support effective retrieval.
Another big problem with the current meta-searcher paradigm is the general lack of flexibility and customizability from the user view. Users are usually provided with a small, coarse grained set of options for performing search. For example, a meta-searcher will allow selection of the particular set of resources to search. Of course, each of these components is itself a centralized index with a very large, hetergeneous corpus, so all the central index problems mentioned previously still apply.
Personalized Information Environments
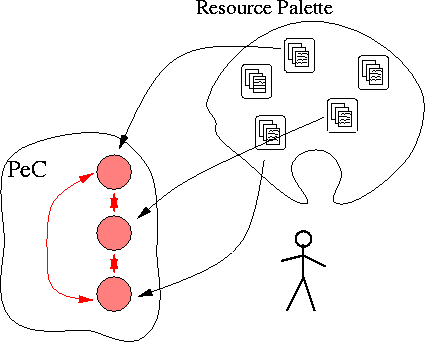
We are faced with the following situation: information overwhelms us; users differ in their personal tastes and work modes; multi-collection search is crude and prone to ineffective results; and computers, disks, memory, and networks continue their exponential increase in capacity. This confluence of factors suggests a new architecture that addresses many of the problems we have been discussing. We call this architecture a Personalized Information Environment (PIE). A PIE is a system that allows users to build their own multi-collections -- ones that are suited to their own particular needs and tasks. We call such a multi-collection a Personalized Collection (PeC).In the PIE world, users select from lists of known databases or information resources to build their own multi-collection. Once a PeC has been constructed, then the resources within the PeC must "cooperate" to ensure effective search. (We will have more to say about this cooperation shortly.) Figure 2 depicts one realization of a PeC.
Figure 2: The personalized collection (PeC). The user controls the content of the PeC by selecting from a palette of available resources.
Centralized search engines and their derivatives take a multi-dimensional, heterogeneous information world and flatten it into a single, huge information mass. Search then proceeds on the mass. The PIE allows browsing, searching, and filtering closer to the origin of the information, eschewing the centralized mass and going directly to the resource for searching. What will make a PIE tractable is the provision of powerful resource summarization tools that will allow a user to easily choose which resources should and should not be in their personal collections, combined with domain and user specific heuristics for further pruning of the search space. We believe that meta-searchers have the right philosophy in allowing users to select the indexes they search -- but this selection needs to take place closer to the information source with the system providing meaningful support in the selection process.
We now describe a set of requirements for a full-featured, working PIE, dividing these requirements up into conceptual and operational requirements.
Requirements - Towards a Working PIEThere are four central conceptual requirements that embody the Personalized Information Environment: customizability, effective search, sharability, and privacy.
- Customizability. We envision a PIE as having tools that allow users to easily design and compose PeCs. The building process is iterative. One can select a group of resources, send a query, evaluate the results and then adjust the PeC accordingly. The PIE would have auxiliary information such as topic maps or resource summaries that allow users to more intelligently select resources.
- Effective Search. Users still want effective search, so a PeC must dynamically alter its context as resources are added or removed. The main idea is that search should take place in a context derived from the contents or properties of the resources that are in the PeC at the time of the search, not in the separate local contexts of the PeC constituents.
- Sharability. PeCs should be sharable. Since there may be considerable curatorial effort expended in building a PeC, it is logical that they might be shared and re-used. The original builder might design a core PeC and then add a small number of resources for particular tasks. The PeC might be used by a number of people with interests in the same area, or who are working on the same project together. Sharing could be via reference to a single existing PeC or via copying.
- Security. Sharability also implies access control. For a variety of reasons, a PeC owner may want to control access. The owner may have paid a fee to some of the constituent resources in order to gain access, or the PeC may be related to a proprietary or otherwise sensitive task. From the searcher's point of view, protection of usage and query patterns may be important.
Any instantiation of a PIE naturally leads to some operational requirements. We identify these below.
In a PIE based world, the cross-product of many users and many PeCs demands a distributed processing approach. An information resource can be a participant in a number of PeCs and a number of PIEs. Given this possibility, a resource (or its surrogate) will be a remote participant in at least some PeCs and some PIEs. Managing the associated complexity of distributed communication and processing is therefore very important.
Distributed object systems are a natural mechanism to implement and manage a PIE. Object orientation means that communication between objects is based upon method invocation and not on lower-level primitives like send and receive. The run-time layer of the distributed object system manages the important details of object location and instantiation, method invocation, and even object migration.
2. Resource Summarization Tools
A usable PIE must provide tools that allow users to easily compose various resources into coherent PeCs. Mechanisms to tersely summarize the holdings of resources are needed so that users can aggregate these resources intelligently. The PIE can provide some default resource aggregations, or it can provide summarizations that allow the user to compose a PeC interactively. These tools must be highly interactive: it should be easy to insert and delete a resource and to have that modification quickly reflected in a subsequent search and in the collection statistics that are used for that search.
For reasons that were described above the PIE must support constrained sharability (i.e., sharing within a group) while also providing access control. The mechanism for providing these services should be flexible enough to support multiple policy types and, relative to particular PeCs or resources, changes in policy types over time.
We are now ready to describe an architecture that combines PIEs, PeCs, users, and information resources in a coherent and meaningful way. Our description is constructive, first describing how various entities fit and then building from these smaller blocks to show the overall architecture.
ArchitectureAs we mentioned previously, information resources must cooperate to ensure effective search. What is the nature of this cooperation? Clearly we cannot expect that each resource keep track of every PeC to which it belongs. There may be millions of PeCs. Yet we do need the resource to export its local context in some way so effective PeC-wide search can be conducted. The PIE architecture addresses this concern in the following way.
For each resource, there is a "front-end" called a Virtual Repository(VIRP). The main task of a VIRP is to export a common interface to PeCs and other objects that may have an interest in the resource. The VIRP is logically a single entity -- there is only one per information resource. Of course, such wrapping of heterogeneous resources is hardly new -- for example, Paepcke, et al. [21, 20] use it to provide base level interoperability between disparate resources via a "Library Service Proxy".
Personal Collections and Resource Descriptions
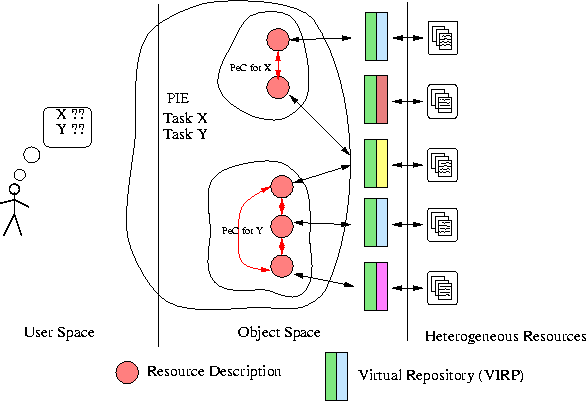
When constructing a PeC, a user selects resources or groups of resources to populate the PeC (Figure 2). For each resource, a Resource Description (RD) is created that functions as a kind of liaison between the PeC and the VIRP (Figure 3). The RD can be thought of as a summarization of the capabilities and content of the resource. It is a surrogate for the resource in both the traditional sense of providing static information about content, access, and data types, and in the non-traditional sense of providing direct dynamic access to the VIRP, and, thus, the resource itself. A Resource Description carries a live handle to the VIRP, and so holders of an RD can invoke searches on the VIRP and collect results from these searches. Resource Descriptions may come from a variety of places -- for example, our formulation of the VIRP includes methods for emitting RDs provided security constraints are met. Thus, an RD can carry information direct from the VIRP.
To create a Personal Collection, users manipulate Resource Descriptions. Possession of an RD allows the user direct access to information about the actual resource. Access to several RDs allows the construction of a search context highly specific to the collection. For example, RDs could contain statistical signatures of document content, allowing the creation of a single statistical signature for search of that collection of resources where that signature is based only on those resources in the PeC at search time. This signature is contained in the Personal Collection, not in the VIRPs, so addition or removal of RDs requires changes in the PeC, not in the resources themselves. Of course, this assumes the willingness of a resource to give up such statistical information to begin with. Some providers will be willing to give up such information, others will do so only for a fee. Random sampling of the resource is an indirect way to determine a resource's statistical properties [4].
In addition to RDs, PeCs will contain significant information related to user manipulations. Minimally, this would include desktop organization information and user annotations, but, in the case of shared PeCs, would also include access control information and anonymized PeC usage patterns.
The PIE architecture is inherently object oriented. For example, the VIRP provides a common interface to PeCs but will have resource specific implementations.
We now turn to describing three operational scenarios that fit within the PIE framework: Adhoc Search, Information Filtering, and Selective Dissemination of Information.
Operational Scenarios -- Using a PIEIn this familiar scenario, users pose a one-time query to an information system hoping to receive information that is relevant to that query. In the PIE, this activity can occur after PeC building or in concert with it. The PIE accepts the query from the user and associates it with the appropriate PeC. The PeC then sends the query to each resource through the corresponding RD. After remote execution of the query at each resource, results are sent back to the PeC for merging and presentation to the user. Accompanying these results would be query-specific collection statistics that allow the PeC to do intelligent merging of the results. Alternatively, the PeC could decouple the maintenance of collection statistics with query execution, instead undergoing separate interactions through the PVAs to maintain this information.
Another scenario is one in which a PIE user builds a PeC in order to execute a continuous or standing query, i.e., to perform information filtering. Conceptually, filtering involves placing a user profile in a stream of documents, and sending notifications to the user for those documents deemed relevant to the profile. In order to do filtering within the PIE framework, we must assume that the information resources support queries that can exclude documents that have already been seen. Date based queries of the form "Give me all documents since 'date'" would suffice; failing that, some history mechanism must be maintained. With this capability, filtering can take place. User profiles can be kept at either the VIRPs or in the individual PeCs -- there are clear consequences for each mechanism. Keeping profiles at the VIRPs means that the comparison and decision process takes place there, and that the VIRP is responsible for periodic execution of each standing query. In the presence of faults, the VIRP might also have to keep track of the last successful contact for each profile, to ensure that each profile has a chance at every inserted document. On the other hand, pushing the profile all the way back to the PeC requires the PeC to keep track of such information and to periodically execute the standing query conjunctively with the exclusion predicate mentioned previously. Effective filtering may be best enabled in this formulation because the PeC-wide context is available here, but would probably not be available in the VIRPs. No matter where the initial filtering takes place, additional filters can be implemented within the PeC.
Selective Dissemination of Information -- Looking for Users
In a very real sense, information retrieval and information filtering are duals -- information retrieval involves users finding documents, while filtering involves documents finding users [1, 6]. We now consider the PIE framework in a different context, that of a selective dissemination of information (SDI) provider, so we interpret Figure 3 in a different way. In this context, the PIE "user" is an information resource who wishes to find user profiles. User profiles are kept in a profile database, and a VIRP acts as a front-end to these databases. A PeC is then a collection of user profile databases. To complete the picture, document insertions represent queries. These queries are routed to the VIRPs whose profile databases are members of the PeC. Sets of matching profiles are returned. The PIE can then process these returns and send notifications along to users.
There are, of course, some obvious differences between the two PIE frameworks. They include the relative sizes of the information resource (document database versus profile database), the relative frequency of queries (user queries versus document insertions), and many others. Instantiations of a PIE architecture would obviously reflect these differences. The main observation is that efficient distributed searching can be used to support retrieval and SDI.
The PIE vision and architectural description provide a framework within which a variety of research questions can be addressed. These questions include (but are certainly not limited to):
Research Directions and Approaches
- What kind of methods are appropriate for identifying resources to be added or removed from the overall resource pallette? To what extent can these methods be automated?
- What specific resource attributes should be made available to the user from the resource pallette to aid in resource selection? How do we evaluate the selection process? What are the evaluation criteria?
- What are appropriate class hierarchies and base classes that encapsulate requisite functionality while providing a common interface?
- How can PeC defined collection statistics be circulated efficiently? What is the set of minimal collection statistics needed to support effective search?
- What are effective tools for PeC formulation?
- How might composite Resource Descriptions be created? To what extent can creation of such composites be automated?
Many of these questions require working testbeds in order to conduct the research. Accordingly, work must also progress in identifying and instrumenting appropriate test data and environments.
Two research areas for which we have specific approaches and operational agendas include work related to 1) distributed object systems and 2) development and evaluation of collection selection techniques. These are summarized below.
Distributed Objects and Legion
Legion [17] (http://legion.virginia.edu/) is a meta-system project begun at the University of Virginia to address many of the software problems encountered when building distributed and parallel applications in a wide area environment. These problems include scalability, heterogeneity, resource access, security and many others. Legion provides a solid, object-oriented conceptual base upon which solutions to the above problems can be built.
There are three aspects of Legion that are of particular interest to our work. The first is the presence of a language-based mechanism and implementation to express communication patterns in persistent, distributed objects. The second is the ability to express parallel computation at the language level and support for parallel execution in the run-time system. Finally, an integrated, flexible security model and implementation allows the expression of multiple policies in a relatively straightfoward fashion.
Through the Mentat Programming Language(MPL) [16] and its associated compiler, Legion provides an easy mechanism to support inter-object communication and parallelism. Through data-flow analysis, the MPL compiler automatically detects data dependencies between objects and ensures that these data dependencies are honored even when objects are physically distributed throughout the Legion system. Objects with no data dependencies are allowed to compute in parallel and asynchronously.
A general description of the Legion security model is provided here; more detail is available in Wulf, et al. [28]. The Legion system will run in many administrative domains, in heterogeneous environments, and on top of host operating systems. Furthermore, Legion applications will have fundamentally different security requirements, so prescribing a particular level of security is doomed to failure. The Legion security philosophy is thus to provide a general mechanism for doing message level security through encryption and decryption, and for object level security using an object-provided security function called MayI. The Legion run-time system guarantees that MayI will be called on every method invocation on an object. Default MayI's will be provided, but by allowing objects to provide their own implementation, security ultimately resides in the object's domain. Implementations of various security policies are being provided using this general mechanism.
The use of the Legion system is a natural mechanism by which to realize many of our goals. It is a distributed object system designed to enable distributed computations -- this is a necessary attribute in any working implementation. Just as important, Legion's MayI based security model is well-suited for PeC sharing among trusted parties. The implementation of MayI is configurable on a per object basis, allowing degrees of security and sharing. For example, a MayI might appeal to a trusted third party to determine whether the invoking party is allowed to share the PeC upon which the method has been invoked. Finally, because Legion's non-blocking, dataflow-based computation model is specifically designed and well suited for parallel computation, a Legion-based implementation for searching will automatically benefit through parallel search of document collections.
From PIE architectural standpoint, VIRPs and PeCs might be Legion Objects that export an interface that encapsulates the required inter-object communication patterns. As long as a PeC or PIE has the location independent name of a VIRP, then the particular location of the VIRP is immaterial and it can be shared among many PeCs and PIEs.
We are in the process of implementing the PIE architecture using Legion as infrastructure and data from the Networked Computer Science Technical Reference Library (http://www.ncstrl.org/). The current implementation supports interactive creation of Personal Collections using simple and composite Resource Descriptions. The VIRP implementation speaks NCSTRL's native access protocol, Dienst, and does significant caching of data in order to speed search. Both VIRPs and PeCs are Legion objects -- thus they are persistent, relocatable, and can support sharing and controlled access.
The process of choosing which information resources should be consulted when a query has been posed has been called text database discovery [14], collection selection [5], and database selection [9]. In the PIE, selection happens at two levels. When users create a personal collection, they explicitly include and exclude information collections as they manipulate resource descriptions, so at this level they are performing selection. This process may still yield a large number of remaining resources -- so many that simple broadcast of queries to all resources in the remaining collection might be ill-advised from a network utilization standpoint. The problem at this level then becomes determining which of the remaining resources should be consulted and in what order. This second level is the one that has received attention in the literature, with the assumption that the resource/collection/database with the most "good" or "relevant" material should be consulted first.
Our work on the selection problem has concentrated thus far on the second level, where the assumption is that some potentially large set of resources has been identified as likely to contain relevant information. One of the problems with early efforts on the selection problem was the lack of agreement on evaluation metrics and test environments, making direct comparison of techniques essentially impossible. We have spent a good deal of effort developing common testbeds within which various selection algorithms might be compared fairly and unambiguously [9]. One point of disagreement in the literature is on what the appropriate "best" or "ideal" method would yield. Regardless of the "ideal" method, our follow-on work indicates that there is still significant improvement possible and desirable [7].
We have also been considering domain specific methods to further prune the search space once a personal collection has been developed [8]. For example, many of the searches on the NCSTRL collection are author restricted. Thus if an NCSTRL site exports its author list in a Resource Description, a PeC holding that RD could easily determine whether sending an author-restricted query to that site would be fruitful by simply checking the author list in the RD. This capability has been implemented in the prototype NCSTRL PIE.
Related WorkThe PIE is both a vision of user-centric, customizable access to distributed information and a framework for research. In this section, we take a narrower view and focus on work most related to our current research agenda, recognizing that there are large bodies of work (in, e.g., human/computer interaction, information organization) that are highly related to the larger vision of the PIE, but which are not immediately related to our current research agenda.
Existing Web-based search engines like Infoseek (http://www.infoseek.com/) and Excite (http://www.excite.com/) build centralized, static databases. They offer pre-computed sub-indexes devoted to various popular subjects. Some of these services (www.yahoo.com) allow personalized views of their indexes through registration of a user-profile. Control of the specific data sources from which these indexes are built is generally not possible. We envision a system with greater user control over which individual data streams are examined and their relative importance.
The Harvest project provided tools to gather, extract, index, and organize distributed information. The main focus was on efficiency, not effectiveness. Harvest was not designed for, and does not support, the kind of personalized, dynamic configurability that we propose.
The information retrieval community has begun to look at problems associated with merging results from searches on separate document collections, the problem [26, 27, 5]. Some approaches rely on prior knowledge of a searcher's interest in a particular collection while others rely on complete knowledge of collection statistics. Both approaches have merit.
As we have noted previously, collection selection has been examined in both the information retrieval community [5, 27, 9] and in the database community [15, 14], with information retrieval originated research concentrating on effectiveness issues and DB originated research looking at efficiency. We view collection selection as at least a two-phase process. In the first phase, the user actively participates in the choice of resources to include, with the system providing descriptive information to help in the process. In the second phase, the system provides more explicit guidance about what resources should be contacted and in what order.
Our own work [24, 23, 25, 10] and recent work by Callan [3] suggest that the use of collection statistics derived from a portion of a document collection is sufficient to give good retrieval effectiveness in both search and filtering environments.
We will build on these findings to explore the best mechanism to communicate collection statistics in the the highly configurable personalized environment we envision.
The use of distributed object technology is not new. The Stanford Digital Library Project uses CORBA [21, 20]. In addition to our familiarity with Legion [17], our choice of this system is based upon our needs for 1) persistent objects; 2) flexible and configurable security and access control policies; and 3) high performance computation for simulations and some PIE algorithms.
The work of Schatz [22] and others at the Illinois Digital Library Initiative is highly relevant to the PIE. Schatz's Interspace describes a world of connected information units where each unit is highly tuned to a particular community or set of individuals. The community is responsible for the maintenance and evolution of the unit. Shared PeCs fit very well into this vision.
The STARTS initiative out of the Stanford Digital Library project was an effort to design a standard protocol by which information resources provide meta-data about their holdings. An important part of the proposed protocol, from our perspective, is the inclusion of a mechanism for returning statistical information about the information resource along with query results [12].
The IRISWeb project [18] and some commercial software (e.g., Ultraseek Server) take a significant step towards providing a user-specified collection of resources. These systems allow a user to provide a web page of seed URLs and a crawl distance from that page. These URLs and the crawl distance define a virtual collection that is the connected graph composed of the original URLs and all pages N links away or less. Harvesting software then downloads and indexes these pages and provides a relevance-feedback based search interface to the collection.
ConclusionsWe have defined a user-centric vision of access to information called the Personalized Information Environment or PIE. The key concepts in the PIE include 1) customizability; 2) effective, efficient search; 3) controlled sharability; and 4) privacy and security.
Our architecture for the PIE includes Virtual Repositories to act as front-ends to arbitrary information resources, Resource Descriptions to act as surrogates or summaries of the contents of information resources, and Personal Collections of user-created and maintained collections of related resources.
Acknowledgements
This work is supported by the Defense Advanced Research Project Agency under contract N66001-97-C-8542.Bibliography
- 1
- N. Belkin and W. B. Croft.
Information Filtering and Information Retrieval: Two Sides of the Same Coin.
Communications of the ACM, 35(12):29-38, 1992.- 2
- V. Bush.
As We May Think.
Atlantic Monthly, 176(1):101-108, 1945.- 3
- J. Callan.
Document Filtering with Inference Networks.
In Proceedings of the 19th Conference on Research and Development in Information Retrieval, Zurich, Switzerland, 1996.- 4
- J. Callan, M. Connell, and A. Du.
Automatic Discovery of Language Models for Text Databases.
To appear in: Proceedings of SIGMOD'99, Philadelphia, PA, 1999.- 5
- J. P. Callan, Z. Lu, and W. B. Croft.
Searching Distributed Collections with Inference Networks.
In Proceedings of the 18th International Conference on Research and Development in Information Retrieval, pages 21-29, Seattle, WA, 1995.- 6
- J. C. French.
DIRE: An Approach to Improving Informal Scientific Communication.
Information and Decision Technologies, 19:527-541, 1994.- 7
- J. C. French, A. Powell, J. Callan, C. L. Viles, T. Emmitt, K. J. Prey, and Y. Mu.
Comparing the Performance of Database Selection Algorithms.
Technical Report CS-99-03, Department of Computer Science, University of Virginia, 1999.- 8
- J. C. French, A. Powell, and W. R. Creighton.
Efficient Searching in Distributed Digital Libraries.
In Proceedings of the Third ACM Conference on Digital Libraries, pages 283-284, Pittsburgh, PA, June 1998.- 9
- J. C. French, A. Powell, C. L. Viles, T. Emmitt, and K. Prey.
Evaluating Database Selection Techniques: A Testbed and Experiment.
In Proceedings of the 21st Conference on Research and Development in Information Retrieval, Melbourne, Australia, 1998.- 10
- J. C. French and C. L. Viles.
Ensuring Retrieval Effectiveness in Distributed Digital Libraries.
Journal of Visual Communication and Image Representation, 7(1):61-73, 1996.- 11
- L. Gravano, C.-C. H. Chang, A. Paepcke, and H. Garcia-Molina.
STARTS: Stanford Proposal for Internet Meta-Searching.
In Proceedings of the 1997 International Conference on the Management of Data (SIGMOD '97), 1997.- 12
- L. Gravano, C.-C. K. Chang, H. Garcia-Molina, and A. Paepcke.
STARTS: Stanford Proposal for Internet Meta-Searching.
In Proceedings of the 1997 ACM SIGMOD International Conference on Management of DATA, 1997.
To appear.- 13
- L. Gravano, H. Garcia-Molina, and N. Shivakumar.
dSCAM: Finding Document Copies Across Multiple Databases.
In Proceedings of the 4th International Conference on Parallel and Distributed Information Systems, Miami, FL, December 1996.- 14
- L. Gravano, H. Garcia-Molina, and A. Tomasic.
GlOSS: Text-source discovery over the internet.
ACM Transactions on Database Systems, To appear, 1999.- 15
- L. Gravano, H. Garcia-Molina, and A. Tomasic.
The Effectiveness of GlOSS for the Text Database Discovery Problem.
In SIGMOD94, pages 126-137, Minneapolis, MN, May 1994.- 16
- A. S. Grimshaw.
Mentat 2.5 Programming Language Reference Manual.
Technical Report CS-94-05, Department of Computer Science, University of Virginia, February 17 1994.- 17
- A. S. Grimshaw and W. A. Wulf.
The Legion Vision of a Worldwide Virtual Computer.
Communications of the ACM, 40(1):39-45, January 1997.- 18
- R. G. Sumner, Jr., K. Yang, and B. J. Dempsey.
An Interactive WWW Search Engine for User-Defined Collections.
In Proceedings of the Third ACM Conference on Digital Libraries, pages 307-308, Pittsburgh, PA, June 1998.- 19
- R. Larsen.
Relaxing Assumptions ...Stretching the Vision: A Modest View of Some Technical Issues.
D-Lib Magazine, April 1997.
< http://www.dlib.org/dlib/april97/04contents.html >.- 20
- A. Paepcke, M. A. W. Baldonado, C.-C. K. Chang, S. Cousins, and H. Garcia-Molina.
Using Distributed Objects to Build the Stanford Digital Library Infobus.
IEEE Computer, 32(2):80-87, February 1999.- 21
- A. Paepcke, S. B. Cousins, H. Garcia-Molina, S. W. Hassan, S. P. Ketchpel, M. Roscheisen, and T. Winograd.
Using Distributed Objects for Digital Library Interoperability.
IEEE Computer, 29(5):61-68, May 1996.- 22
- B. R. Schatz.
Building the Interspace: The Illinois Digital Library Project.
Communications of the ACM, 38(4), 1995.- 23
- C. L. Viles.
Maintaining Retrieval Effectiveness in Distributed, Dynamic Information Retrieval Systems.
PhD thesis, University of Virginia, 1996.- 24
- C. L. Viles and J. C. French.
Dissemination of Collection Wide Information in a Distributed Information Retrieval System.
In Proceedings of the 18th International Conference on Research and Development in Information Retrieval, pages 12-20, Seattle, WA, July 1995.- 25
- C. L. Viles and J. C. French.
On the Update of Term Weights in Dynamic Information Retrieval Systems.
In Proceedings of the 4th International Conference on Knowledge and Information Management, pages 167-174, Baltimore, MD, November 1995.- 26
- E. Voorhees.
The TREC-5 Database Merging Track.
In Proceedings of the Fifth Text Retrieval Conference (TREC-5), Gaithersburg, MD, November 1996.- 27
- E. Voorhees, N. K. Gupta, and B. Johnson-Laird.
Learning Collection Fusion Strategies.
In Proceedings of the 18th International Conference on Research and Development in Information Retrieval, pages 172-179, Seattle, WA, 1995.- 28
- W. A. Wulf, C. Wang, and D. Kienzle.
A new model of security for distributed systems.
Technical Report CS-95-34, Department of Computer Science, University of Virginia, May 1995.
Copyright © 1999 James C. French and Charles L. Viles
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous story | Next story
Home | E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/june99-french