| Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Lin
Fang |
![]()
AbstractThis article describes two approaches for searching heterogeneous resources, which are explained as they are used in two corresponding existing systems—RIRS (Resource Integration Retrieval System) and HRUSP (Heterogeneous Resource Union Search Platform). On analyzing the existing systems, a possible framework—the MUSP (Multimetadata-Based Union Search Platform) is presented. 1. BackgroundLibraries now face a dilemma. On one hand, libraries subscribe to many types of database retrieval systems that are produced by various providers. The libraries build their data and information systems independently. This results in highly heterogeneous and distributed systems at the technical level (e.g., different operating systems and user interfaces) and at the conceptual level (e.g., the same objects are named using different terms). On the other hand, end users want to access all these heterogeneous data via a union interface, without having to know the structure of each information system or the different retrieval methods used by the systems. Libraries must achieve a harmony between information providers and users. In order to bridge the gap between the service providers and the users, it would seem that all source databases would need to be rebuilt according to a uniform data structure and query language, but this seems impossible. Fortunately, however, libraries and information and technology providers are now making an effort to find a middle course that meets the requirements of both data providers and users. They are doing this through resource integration. 2. Resource IntegrationThere are three approaches for integrating distributed information of different types into one union system, and these three ways coexist within many library services. In this article, the first and second approaches (bibliographic control and a database navigation system) are introduced briefly, while the third approach (union search platform) will be described and analyzed in more detail. 2.1 Bibliographic ControlBibliographic control is used to integrate data produced by other information institutions into the library automation system, that is to say, the MARC 856 field can contain a URL that links to relevant information such as the electronic full text and so on. This method is based upon the cataloging system. See, for example, Figure 1 and Figure 2 below:
In the MARC record shown in Figure 1, the URL for "Library Journal" is located in the 856 field.
When the user clicks on the URL link, he or she gains access to the electronic version of this journal. 2.2 Database Navigation SystemDatabases can also be integrated according to subjects, media types, providers or even the alphabet. With the database navigation method, a new database is built and a simple search capability is provided. However, the search result or link does not return the full text of an article to the user but instead provides access to the interface of the particular database or to the homepage of an electronic journal. In the context of a library, this is the navigation system for those databases and electronic journals that have been purchased by the library. See Figure 3.
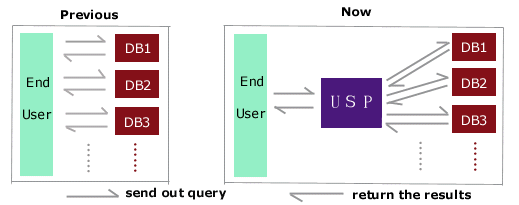
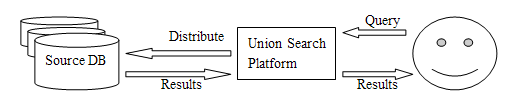
2.3 Union Search Platform (USP)One substantive approach to metasearch (search across heterogeneous data) is to create a new application that integrates multiple search requests into a union search platform. That is, this application delivers a user's query to those heterogeneous databases, deals with search results and merges results sets before returning them to the user. To the user, the various databases are transparent. The user does not need to know the different automated retrieval methods applied to the different databases. What the user sees is a single, simple search interface. This approach is illustrated in Figure 4.
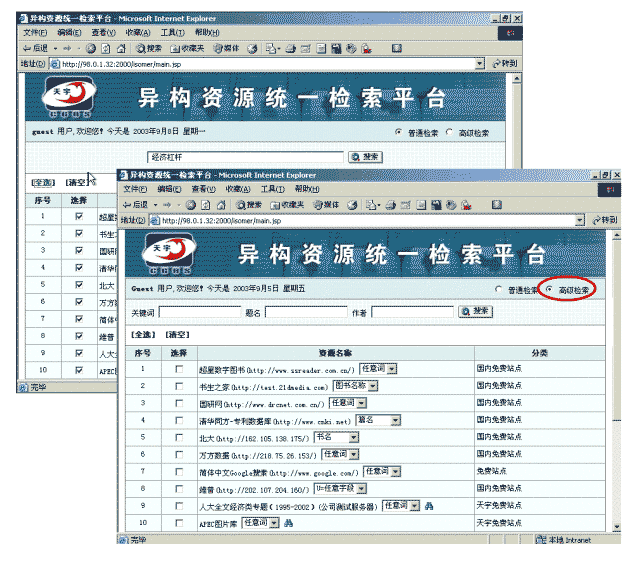
There are two possible ways to meet the requirements for this approach. The first is the core-metadata-based method, and the second is the web-based method. 2.3.1 Core-Metadata-Based MethodIn the core-metadata-based method, or database-based method, the metadata records of all the available heterogeneous databases are imported into a new database. The user's search is then performed on this new database. The full text of a document from a source database can be imported into the destination database as well (if authorized), or alternatively a hyperlink to the full text may be provided in lieu of the full text. Because of the diverse types of metadata (e.g., MARC, DC, EAD, VRA, GILS, CDWA, SMDL, custom, etc.), the new database must have a core metadata set as the transform standard in order to integrate the different types of metadata forms into the union retrieval system. Such a system is being tested in our library, the Library of Central China Normal University. The system is the Resource Integration Retrieval System (RIRS), and it is now in operation. RIRS helps in understanding the core-metadata-based method. In RIRS, the databases involved include the Chinese Science & Technology Journal Database (a full-text database), the Chinese Doctor Degree Dissertation Database (an abstract database), Renda Newspapers and Periodicals Database (a full-text database), and Bibliography Database (our library's collection of MARC records). The Dublin Core Metadata Set (DC) is used as the integrated database metadata standard, and all other metadata types are mapped to DC. RIRS offers two search options: basic search and advanced search.
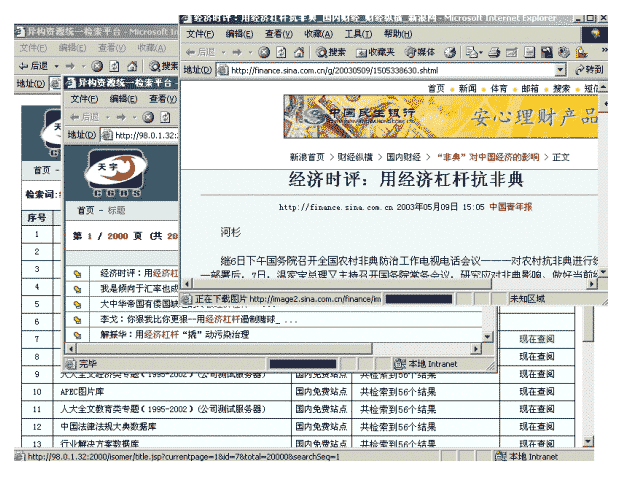
The search results page is shown in Figure 7. When the user clicks on the hyperlink, he or she can view more detailed metadata information. If the source database is a full-text database, with a corresponding browser (e.g., Acrobat Reader, CAJ Viewer, etc.), the user can read the full text online. Query refinement is available, and clustering searches (e.g., link to the same author, subject, keyword, etc.) is easy.
2.3.2 Web-Based MethodIn the web-based method, an application is employed to accept and distribute the user's query. This application plays the role of an intermediary agency. If the source database search system is web-based, it can be added into the application as an option. Unlike the method described in Section 2.3.1, the core of the web-based method is to map a user's query between multiple database search systems. The Heterogeneous Resource Union Search Platform (HRUSP), developed by Hangzhou Tellyou Information & Technology Ltd., is a model of the web-based method. Besides integrating database retrieval systems, HRUSP can integrate search engines (e.g., Google) into its platform. Theoretically, any retrieval system that supports the web-based search method—that is, B/S pattern—can be selected as a data source. It should be noted that because HRUSP is middleware, the search mechanism and speed depend on the source retrieval systems and the status of networks. HRUSP provides both simple search and advanced search, similar to RIRS. However, HRUSP's Boolean search is restricted to the use of the "and" operator. In addition, RIRS has a more flexible display than HRUSP. HRUSP only gathers results from each selected retrieval system and delivers the list of search results back to the user's Web browser. It doesn't support query refinement, but it does provide constant feedback about how many records are "hits" in each database. See Figure 8 and Figure 9.
3. Related Issues and Future WorkThe main steps that are performed by a union search platform are:
These steps lead to a series of questions that need to be addressed:
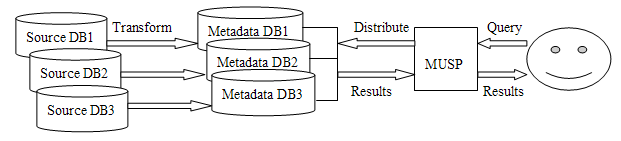
Solving these problems requires standardization. We cannot expect that all providers of retrieval systems will build their systems with the same data structures and query mechanisms. However, it is possible that these providers will build their systems conforming to some widely used standards and protocols, such as Z39.50, OpenURL, OAI, OMHP, DC, XML and so forth. To improve database interoperability, a standard interface would be a step in the right direction. 4. A Possible Eclectic Framework between RIRS and HRUSPRIRS and HRUSP represent the mainstream of integration retrieval systems in China. Each of them has its strong points and shortcomings. Based on their architectures and mechanisms, I propose an eclectic framework: Multimetadata-based Union Search Platform (MUSP). This proposal assumes that a library has purchased access to various database retrieval systems and that the metadata of each source database is open but the full text is not free. Those libraries that have been authorized to view database content in full text have been assigned an identification name or number (ID). In this case, the library and database retrieval system provider can come to an agreement for importing the metadata into a third-party application—that is, into the multimetadata-based union search platform. To view a full text, the access ID must first be verified. The differences among RIRS, HRUSP and MUSP are illustrated below in Figures 10, 11, and 12.
Some advantages of MUSP are:
5. ConclusionThis paper has proposed a framework of heterogeneous resources integration and retrieval system—MUSP. It is still a theoretical model. For accomplishing this objective many problems are waiting to be tackled. What differentiates MUSP from RIRS and HRUSP is the coexistence of multiple metadata forms in one system. But, no matter how the heterogeneous data are integrated into a union search platform (core-metadata-based, web-based or multimetadata-based), some trends are foreseeable. No doubt, more and more distributed and heterogeneous information retrieval systems will be produced. So the differences of system, syntax, semanteme and structure among these retrieval systems will continue to exist for the long term. In this environment, improving interoperability (at the technical level and at the conceptual level) becomes urgent. The benefit of interoperability is that it makes it possible for libraries to produce more effective, flexible search platforms to integrate heterogeneous resources. Bibliography[1] Li Yongwen and Zhang Xiaolin (2002). "Mechanisms for Cross-Gateway Search and Browsing," Library and Information Service, 9: 74-78. [2] Shi Weiguo (2002). "On the Intellectual Property Issues in Integration of Electronic Resource," Researches in Library Science, 6: 46-48. [3] Li Aiguo and Wang Shejiao (2003). "Tool of Academic Information Integration - SFX and Its Enlightenment," New Technology of Library and Information Service, 1: 48-50. [4] Zeng Xinhong (2003). "Research on Interoperability Among Different Library Application Based on XML and SOAP," New Technology of Library and Information Service, 2: 37-41. [5] Tsinghua Tongfang Optical Disc Co., Ltd. (2003). "The Presentation of Digital Library Development and Management Platform-TPI," Conference Materials, October. [6] Beijing National Library Digital Technology Co., Ltd. (2003). "Research and Development of Digital Library," Conference Materials, April. [7] James Powell and Edward A.Fox (1998). "Multilingual Federated Searching Across Heterogeneous Collections," D-Lib Magazine, September. Available at <doi:10.1045/september98-powell>. [8] Len Seligman, Arnon Rosenthal, A Metadata Resource to Promote Data Integration. Available at <http://www.computer.org/conferences/meta96/seligman/seligman.html>. [9] Zhejiang Tellyou Information & Technology Ltd. (2003). Products Introducing Materials, October. [10] Resource Integration Retrieval System in the Website of Central China Normal University Library. (This website is accessible only from within the the Normal University Libary.) [11] Database Navigation System in the Website of Wuhan University Library. Available at <http://202.114.65.34/dsource/show/show_new.asp>. [12] Shizhong Yinghong and Liying (2002). Basic Technology of Network in the Future - XML: Theory and Application, Huayi Press, Beijing. [13] Liu Jia (2002). Introduction to Metadata, Huayi Press, Beijing. Copyright © 2004 Lin Fang |
|
| |
|
|
Top | Contents |
|
| | |
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/march2004-fang
|