|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Shirley Hyatt and Jeffrey A. Young |
![]()
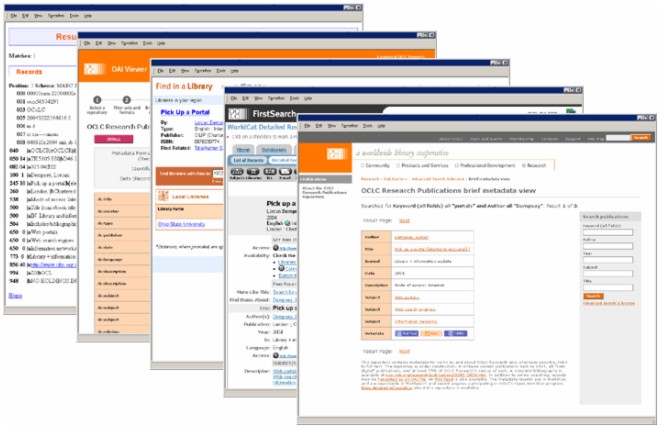
IntroductionConducting research on behalf of the library community has, for 27 years, been part of the mission of OCLC, and we believe that if research is worth doing, it's worth telling people about. Making our research outcomes known is integral to our mission, and we do this both by writing about it and by demonstrating it. Accordingly, in September 2003, OCLC's Office of Research set about to create a repository of its staff's publications. The goal of the repository was to maximize the visibility, usage, and impact of OCLC's research output. A secondary goal was to make the publication section of the OCLC Research web site more nimble. (This portion of the site had previously been one long straggle of citations, not particularly searchable in a helpful manner.) A third, de facto, goal was to demonstrate OCLC Research technologies. The publications repository achieved all of these goals. The site was launched in June 2004, and by November 2004 it included metadata for all OCLC Research's 900+ publications and full text for half of them. The project was completed with .25 FTE, which included project management, cataloging labor, copyright permissions handling, scanning, archiving, and one-time development time. The OCLC Research repository primarily uses lightweight, no- or low cost, easy-to-implement technologies [Note]. It doesn't take a rocket scientist to implement this sort of repository; indeed, we challenged a developer to implement a new repository from scratch, to discover how long it would take now that we'd completed development of the components. It took him just 1 hour. The purpose of this article is to describe the repository and provide links to additional information about the technical components used. Content of the RepositoryThe OCLC Research repository contains works produced, sponsored, or submitted by OCLC Research. In general, the works are research-oriented and are in the subject area of library and information science. Many items describe OCLC Research projects, activities, and programs and were originally published by OCLC, while others are from peer-reviewed scholarly journals. The repository contains MARC metadata about publications and, whenever available and permitted, a link to the full digital text of items described. Though the repository will always be under construction in the sense that our authors will continue to publish, the repository is presently up-to-date. Access to the Content (or, Good Bang for the Buck)The records in the repository are available for browser-based searching on the OCLC Research Web site [1]. The records are available for automated searching via the SRW/U (Search Retrieve Web Service / Search Retrieve URL) interface [2]. The metadata records are available from an Open Archives Initiative (OAI) v2.0 repository; and we encourage harvesting them [3]. The MARC records are in WorldCat [4], and are searchable in FirstSearch [5] and search engines participating in OCLC's Open WorldCat Program [6]. Full text of articles are linked from the metadata record wherever permitted by the copyright holder. The repository also has an RSS [7] feed and supports Open URLs [8].
|
|
|
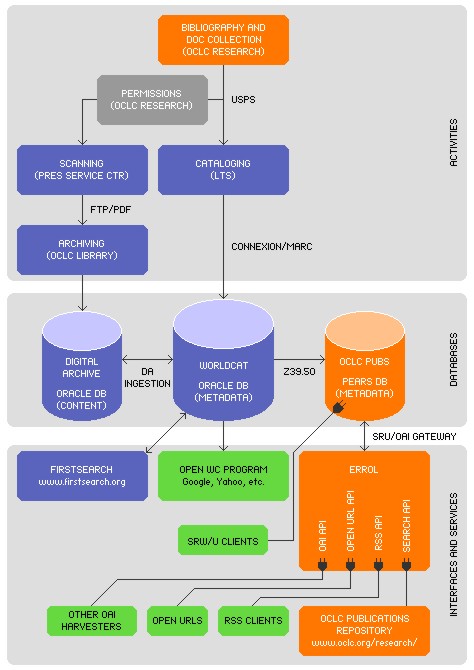
How It All Happens: Architecture & Data FlowWorldCat was and is our starting point; we use WorldCat as a "registry" for our holdings. That said, the architecture used is quite modular and could be reconfigured to accept catalog records from a variety of sources. We chose to use WorldCat because we found that WorldCat provides more bang for the buck: having records in WorldCat ensures that the records are accessible in FirstSearch and by major search engines via the Open WorldCat Program, as well as all the other access points our architecture provides. In our architecture, all of the other access flows virtually automatically from the act of cataloging an item into WorldCat. WorldCat has its own (optional) metadata creation utility (Connexion), and there are no cataloging transaction costs to enter original records into WorldCat. This workflow also fits neatly into existing library workflows and requires no additional training. In essence, the cost of the project is the cost of labor of cataloging the items into WorldCat (and this need not be full MARC) [Note]. First we catalog our publications into WorldCat. For practicality's sake we catalog our preprints using some minimal level of cataloging (level K—MARC or level 3—DC), with an 856 ‡3 field for the preprint. We then build onto this record as the document is published by adding additional 856 ‡3 fields for the postprint. (Acknowledging the experience of many institutional repositories that it is unlikely authors would have the time or inclination or habit to catalog their own work, we used professional catalogers and, where needed for older materials, professional scanners for our project.) We opted to use OCLC Connexion as our metadata creation utility, but any system would work. Our repository records are identified by a holding symbol unique to the project. In the 25 years of OCLC Research's existence, OCLC had already lost a handful of items (i.e., we have citations for originally paper-based items, for which even the authors have no copies), and so where we own copyright or have permission from the copyright holder, we store full-text of documents in the OCLC Digital Archive [9]. This too is optional to our architecture. Using Z39.50 [10] access, we then run an automated script that ports our MARC records from WorldCat into a Pears database [11], which is open source. WorldCat via Z39.50 provides no mechanism for getting only records that have changed, so we get all the records and Pears is smart enough not to replace records that have not changed. As soon as a record appears in our Pears database, it is available as OAI metadata, and to SRW/U clients, RSS clients, and search application program interfaces (APIs). We catalog into WorldCat, where it surfaces in FirstSearch, Connexion, and in public search engines via the WorldCat Open Access program; and when the record additionally appears in Pears, it is available for searching in our repository's interface (where it can appear as MARC or other formats we define), as an RSS feed, and for OAI harvesting.
Inside the Black Box: Core TechnologiesAlthough we used OCLC services for our implementation, a repository could be built without these. The essential requirement for this architecture is a combination of OAI and SRW/U access to the data. In our case, the Pears database was connected to an open-source standards-based SRW/U server, which was connected to an open-source standards-based OAI server, which was connected to an open-source ERRoL server [12], which applies the power of standards-based XSLT [13] to bring it all together as a holistic unit . Pears technology, first introduced into the open source community by OCLC in 2000, is database engine software. Pears databases have features that make them ideal for storing hierarchically structured data, such as bibliographic records, authority records and text documents. The open-source software includes all the utilities to build and maintain a Pears database. SRW (Search/Retrieve Web Service) and SRU (Search/Retrieve URL Service) are companion Web Service protocols for querying Internet indexes or databases and returning search results. SRW/U forms a standard web-based text-searching interface drawing heavily on the abstract models and functionality of Z39.50, without Z39.50's complexity. They are built using common web development tools (WSDL [14], SOAP [15], HTTP [16] and XML [17]). Although the OAI-PMH harvesting component could have been built directly on top of the Pears database as a sibling to the SRW/U search component, we chose to register this SRW/U service in an SRW Registry [18] instead, which automatically provides OAI access to the data as a value-added service. Although this layering may be less efficient, it demonstrates how the SRW/U and OAI standards can build on each other. In this way, similar publication repositories systems can be created from a lone SRW/U service while letting the SRW Registry provide the necessary OAI component. The same effect could have been achieved the other way around. The ERRoL service component can be thought of as a central clearinghouse for all services related to a data repository. The resolution of requests to the ERRoL service involves issuing a variety of web service requests behind the scenes and then transforming and manipulating the responses into something new (typically with XSLT). Although interaction with OAI repositories is the foundation of the ERRoL service, its capabilities aren't limited to OAI. By describing related services in the OAI Identify response (such as SRW/U), the ERRoL service can manipulate them as well with a common XSLT stylesheet that provides seamless integration across all services and protocols. The user experience of our repository—everything you see including the "SRU interface"—is presented via XSLT stylesheets. The output formats (Dublin Core and brief citations) are produced by performing XSLT crosswalks on the MARC records at runtime. This crosswalk capability is provided by the SchemaTrans service, which is discussed in the December D-Lib Magazine article, "A Repository of Metadata Crosswalks" [19]. Several of the core technologies used in the repository are also described in a preprint entitled "Metadata Switch" [20]. ConclusionOur repository was built using lightweight, modular, inexpensive services, and we found these to be highly flexible in building our repository. At the repository manager's end, the only requirement is to catalog items into WorldCat. For that effort, the consumer gets all this magic: RSS, OAI, SRW/U, ERRoLs. We analyzed the cost of this repository, from conception to present. The retrospective project (approximately 900 items) took a total of .25 FTE to implement. This included project management and planning time, copyright permissions time, cataloging costs, scanning costs, web page design time, and implementation time. Our permissions, cataloging and scanning costs were about $10.00/record [Note]. We challenged an OCLC developer to implement a new repository from scratch, to get some sense for how difficult this would be. It took him 1 hour to bring up the repository. (Of course, this did not include the content--bibliography, metadata creation, permissions, and digitization of full text.) The basic development costs for our own repository are "sunk", i.e. the components have been developed and are freely available. It's our assumption that others may want to replicate this sort of repository, and/or that IT groups might want to use some of these components in similar or more creative ways. We continue to develop and enhance the ERRoL service and to revamp the underlying architecture of our publications repository. People interested in replicating this architecture should feel free to contact us for the latest developments. AcknowledgementsThe following people worked on the OCLC Research Repository: Bob Bolander, Ginny Browne, Christine Guenther, Shirley Hyatt, Ralph LeVan, Lance Osborne, Linda-Ann Sturgeon, and Jeffrey A. Young. NoteOur implementation included use of OCLC FirstSearch and the OCLC Digital Archive. OCLC membership, FirstSearch, and Digital Archive incur fees, but these are optional to the architecture, and "sunk" for OCLC member institutions that already have them. These fees are not included in our cost figures, though cataloging and scanning labor and expenses are included. References [Links checked March 9, 2005.][1] OCLC Research Repository <http://www.oclc.org/research/publications>. [2] SRW/SRU (Search/Retrieve Web Service / Search/Retrieve URL Service) Publications Interface <http://alcme.oclc.org/srw/search/ORPublications>. For SRW/SRU general information, see <http://www.oclc.org/research/projects/webservices/default.htm>. [3] OCLC Research Publications OAI repository <http://errol.oclc.org/orpubs.oclc.org.srw2oai?verb=Identify>. [4] WorldCat <http://www.oclc.org/worldcat/default.htm>. [5] FirstSearch <http://www.oclc.org/firstsearch>. [6] Open WorldCat program <http://www.oclc.org/worldcat/open/default.htm>. [7] OCLC Research Repository RSS feed <http://errol.oclc.org/orpubs.oclc.org.rss?metadataPrefix=oai_dc>. [8] OCLC Research and the OpenURL Registry <http://www.oclc.org/research/projects/openurl/default.htm>. [9] OCLC Digital Archive <http://www.oclc.org/digitalarchive/default.htm>. [10] Z39.50 <http://www.oclc.org/research/projects/z3950/default.htm>. [11] Pears <http://www.oclc.org/research/software/pears/default.htm>. [12] ERRoLs <http://www.oclc.org/research/researchworks/errol/default.htm>. [13] XSLT Stylesheets <http://www.w3.org/TR/xslt>. [14] Web Service Definition Language (WSDL) <http://www.w3.org/TR/wsdl>. [15] Simple Object Access Protocol (SOAP) <http://www.w3.org/TR/soap/>. [16] Hypertext Transfer Protocol (HTTP) <http://www.w3.org/Protocols/>. [17] Extensible Markup Language (XML) <http://www.w3.org/XML/>. [18] ERRoLs SRW registry <http://errol.oclc.org/srwRegistry.oclc.org.html>. (Don't let the fact that this SRW Registry is itself implemented using ERRoLs distract you from its described purpose. ERRoL services, which are explained next, are occasionally incestuous in this way.) [19] Godby, Jean Carol, and Jeffrey A. Young, 2004. A Repository of Metadata Crosswalks. D-Lib Magazine 10 (12): December. <doi:10.1045/december2004-godby>. [20] Dempsey, Lorcan, Eric Childress, Carol Jean Godby, Thomas B. Hickey, Diane Vizine-Goetz, and Jeffrey A. Young, 2004. Metadata Switch: Thinking About Some Metadata Management and Knowledge Organization Issues in the Changing Research and Learning Landscape. Forthcoming in LITA Guide to E-Scholarship [working title], ed. Debra Shapiro. Preprint available at <http://www.oclc.org/research/publications/archive/2004/dempsey-mslitaguide.pdf>. Copyright © 2005 OCLC Online Computer Library Center, Inc. |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/march2005-hyatt
|