|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Shigeki Sugita, Kunie Horikoshi, and Masako Suzuki Shin Kataoka E. S. Hellman Keiji Suzuki |
![]()
1. IntroductionLink resolvers are extremely effective tools that offer appropriate means of obtaining primary documents from licensed e-journals, open access journals, library print holdings and through Interlibrary Loan requests. Link resolver software and services are now available from a number of vendors and have been deployed in many types of organizations all over the world. However, link resolvers have not been offering satisfactory article-level resolution for Open Access (OA) documents that have been accumulated in repositories such as arXiv1 and RePEc,2 and in institutional repositories (IR). One approach to providing access to documents in repositories is to offer search links targeting services such as Google Scholar3 and OAIster4 that harvest records from many repositories. However, this is unsatisfactory for the following reasons:
This problem was discussed among some of the universities in Japan, including Hokkaido University and Kyushu University. The result of the discussion was a determination that the link resolver should search the items registered in IRs and display a link to the repository version only when usable documents are found. When this mechanism is achieved, the following effects are obtained:
To implement the mechanism by which the resolver only displays usable items, we must accumulate the metadata (DOI, ISSN, title, volume, issue and page, etc.) for each repository in a machine-readable format. A central service provider is needed to collect the necessary metadata from each repository and enable searching from a link resolver. To research this strategy, in May 2006 five universities and an institute in Japan initiated the Access path to Institutional Resources via link resolvers (AIRway) Project.5 The Openly Informatics Division of OCLC, which is the vendor of the 1Cate link resolver software,6 joined this project to provide implementation of the strategy in a production link resolver. As the first stage of the AIRway project, a coordinated experiment integrated the 1Cate with the IR "HUSCAP" from Hokkaido University.7,8 In the experiment, 1Cate instantaneously and automatically queries HUSCAP and displays the context sensitive link to the document on HUSCAP. The outline of the rest of this article is as follows: Section 2 provides an overview of the framework of the project. Sections 3 and 4 describe the implementation details of the repository server at Hokkaido University and the link resolver at OCLC Openly Informatics. In Section 5, we summarize the integrated trial implementation and discuss future opportunities for the AIRway Project. 2. FrameworkOpenURL link resolver systems can be thought of as systems that read metadata describing items desired by users and then use this metadata to query one or more knowledgebases that record where items reside. By combining knowledgebase queries with regional, institutional, or personal configurations, a list of one or more fulfillment links can be presented to the user. Viewed in this framework, the task of integrating link resolvers with IRs is simply a matter of inserting the repository "where" information into the knowledgebase and configuration environment of the link resolver. There are several ways in which this can be done:
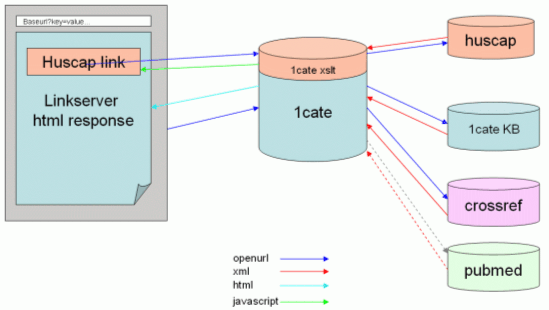
There are issues preventing each of these approaches from being universal solutions. Approaches #1 and #2 are both quite attractive, but they will require significant effort in the production, maintenance and distribution of the IR holdings data or local IR holdings server. Approach #4 is unsatisfactory because of the typically low success rate of the IR search links. For this project we chose to pursue approach #3. The components of the system are depicted in Figure 1. A user clicks on an OpenURL link, and the user's browser software requests services from a link resolver configured for the user's institution. The link resolver returns an HTML page to the user. The user's browser assembles the HTML page and makes an additional request to the link resolver, which in turn queries the IR server and sends the query response on to the user.
3. IR Query Server: HUSCAP ImplementationThe implementation of the IR query server used by the AIRway Project was HUSCAP. HUSCAP uses DSpace version 1.3.2,9 an open-source IR software system jointly developed by MIT and the Hewlett-Packard Company. The Hokkaido University implementation of this project aimed to use the functions of DSpace as much as possible. First of all, we redefined the data, because the necessary metadata to accomplish this project was not defined as part of the standard DSpace system.10 Next, we analyzed the request by OpenURL, retrieved the HUSCAP database and mounted an OpenURL resolver function on DSpace, which returns a response in the proper form. The form of the response was developed specifically for the AIRway Project. 3.1 Redefinition of MetadataBecause DSpace was designed to store the full variety of information resources that an organization produces, the default set of metadata is quite general, and the only metadata item designated to store detailed information for journal articles is "identifier.citation". Therefore it was insufficient to accomplish this project. Consequently, we added the metadata elements shown in Table 1. DSpace already provided a mechanism to add metadata elements, (administrators can add metadata elements, and the metadata input fields can be defined by a configuration file), so the program did not have to be modified for our system. We created a function to get the metadata to support the added metadata elements using CrossRef from DOI names and using PubMed from PMID numbers. It is necessary to retrieve records by these metadata elements, but this was already prepared in DSpace, so the retrieval item was added in the configuration file. Table 1. Added Metadata Element
3.2 Implementation of OpenURL ResolverDSpace has a simple OpenURL resolver function in its standard configuration. However, this function extracts the title and the author from the OpenURL request, executes the retrieval, and returns the result on the retrieval result screen. It was not possible to use this for the AIRway project because only usable results were desired. Therefore we decided to implement a formal OpenURL resolver for AIRway. We adopted a method that performed the analysis, the retrieval and the judgment of the retrieval result of the OpenURL request in one Servlet program, using the framework of DSpace, and then forwarded the result to the JSP file and converted it into the specified XML form. 3.2.1 Analysis of OpenURL RequestThe AIRway implementation corresponds to the both versions 0.1 and 1.0 of OpenURL. First, it automatically determines the OpenURL version, then, the request is forwarded to a corresponding analytical program that extracts search items. The OpenURL 1.0 library developed by Jeff Young at OCLC was used for the analysis of OpenURL 1.0 requests. It thus handles requests using By-Value, By-Reference, and Inline metadata ContextObjects. We have developed our own analytical program of the OpenURL 0.1 request. 3.2.2. Search of HUSCAP DatabaseWe conduct a Search Query in the DSpace style using the search item obtained by analysis of the request and executing the search. The search is executed step by step until a single result is obtained, as follows:
The "status attribute" (explained below) for the above-mentioned search result is set as follows: If the number of search hits is one, "resolved" should be set. If (c) or (d) search hits are plural, "multiresolved" should be set. If the number of search hits is zero or the number of (a), (b) or (e) search hits is plural, "unresolved" should be set. When an error occurs while executing, "malformed" should be set. 3.2.3. Creation of the Search ResultTo respond to the originating request, we use the data set retrieved as above to make an XML file, as discussed in Section 3.3. This function uses JSP, and it is possible to correspond to changes in the definition flexibly. The JSP can be determined by whether the result succeeds or fails, so the description of JSP is simple. 3.3 Definition of Response FormWe decided to return the search query response as an XML file, and we looked for a suitable form for that but were unable to find one. Therefore we decided to define a new format and have tried to make it a standard and simple one. The definition of the schema of this form has been made public at <http://eprints.lib.hokudai.ac.jp/ir.xsd>. The result of the query is specified by the status attribute of root element <result>. The child element of the <result> element is a repeatable <record> element when its status is "resolved" or "multiresolved". The <record> element contains link information for retrieving the document (<url> element), repository name (<repository> element), an indication between publisher versions and author versions of papers (<resource_version> element), DOI and PMID, the identifier in the pertinent articles (<identifier> element) and the bibliographic metadata for articles (<metadata> element). The <metadata> element uses XML Metadata Format for Journals (info:ofi/fmt:xml:xsd:journal), as registered in the OpenURL registry, to contain the bibliographic metadata. When the status is "unresolved" or "malformed", only the error information is set as a child element of the <result> element. 4. 1CATEThe link resolver we used in this demonstration project is the production version of 1Cate, an OpenURL solution produced by OCLC Openly Informatics. 1Cate is implemented in a three-tier architecture. The back end is a MySQL 4.1 database running on a linux server; Middleware is an XML data source implemented in a Java Servlet running in the Tomcat Servlet container on the same server running the MySQL server. The front end link resolver servlet runs in Tomcat on a second server and uses an open-source dynamic text engine called "JSText" (http://openly.oclc.org/1cate/developer.html) to combine data from the data source with presentation templates specified in the server instance. To keep the link resolver extremely responsive, we used a javascript-based technique to incorporate an IR query into the user's result page. In this technique, a remote javascript is invoked to write out dynamic content into the user's web page. In our case, the javascript is composed using a separate 1Cate thread that retrieves an xml response from the IR server, then invokes XSLT on the server-side to format the javascript response. This process is outlined in Figure 1. If results are returned in the IR server response, the javascript writes an html hyperlink to the user result page; if not, nothing is written to the user's page. The display can be easily tweaked; for example, a button image or explanatory text can be presented by changing the XSLT used to process the IR server response. In this way, links to the IR can be presented in the link resolver result page only when the user's desired object is available from the repository. 5. ConclusionIn the AIRway Project implementation, a query for the presence of a requested document in a specific organization's repository was triggered by a user's query to a link resolver, and the result was woven into the user options window. While targeting only a single IR is expedient for the present demonstration stage of the project, to return the results most efficiently when plural IRs are targeted will require using one or both of the following two methods:
In the AIRway project, we plan to proceed with approach (b) by using OAI-PMH to collect the metadata of project member universities and of any institutions in or out of Japan who are interested in this project. To this end, we recently have begun cooperative work with some other universities in Japan. However, in the future, we also would like to see link resolvers take advantage of approach (a) where fruitful. AcknowledgementWe received the project consignment from the research and development program of the "Next-Generation Scientific Information Resources Infrastructure"11 of the National Institute of Informatics (NII), under which we performed a part of this research and development. Notes1. ArXiv, <http://arxiv.org/>. 2. RePEc, <http://repec.org/>. 3. Google Scholar, <http://scholar.google.com/>. 4. OAIster, <http://oaister.umdl.umich.edu/>. 5. AIRway Project, <http://airway.lib.hokudai.ac.jp>. 6. 1CATE, <http://openly.oclc.org/1cate/>. 7. HUSCAP, <http://eprints.lib.hokudai.ac.jp/index.en.jsp>. 8. SUZUKI Masako and SUGITA Shigeki, "From Nought to a Thousand: The HUSCAP Project", Ariadne, Vol. 49 (October 2006), <http://www.ariadne.ac.uk/issue49/suzuki-sugita/>. 9. DSpace, <http://www.dspace.org/>. 10. Metadata: Technology: DSpace Federation, <http://dspace.org/technology/metadata.html>. 11. Next-Generation Scientific Information Resources Infrastructure, <http://www.nii.ac.jp/irp/index-e.html>. (DOI metatag corrected on 3/26/07.) Copyright © 2007 Shigeki Sugita, Kunie Horikoshi, Masako Suzuki, Shin Kataoka, E. S. Hellman, and Keiji Suzuki |
||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/march2007-sugita
|