|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Catherine C. Marshall |
![]()
1. IntroductionA decade ago, there was scant evidence that anyone was concerned about the long term fate of today's digital material outside of a few stalwarts in the Library and Information Science and Computer Science communities (see, for example [Rothenberg, 1995] or [Kuny, 1998]). But more recently, articles about digital archiving have begun to show up in the mainstream press (see, for example [Hafner, 2004]). This concern has finally begun to trickle down from broadly recognized and valued institutional, scientific, and cultural assets to everyday personal digital belongings (see, for example [Beagrie, 2005])1. Underlying the technical discussions of digital archiving are two unifying assumptions: (1) preservation will rely on the ability to represent individual digital objects – academic papers, datasets, multimedia creative works, and so on – in such a way that they may be decoded and accurately rendered many years hence (see, for example, [Lesk, 1995; Heminger and Robertson, 1998; Lorie, 2002; or Gladney, 2006])2; and (2) trusted repositories will be used to store and exchange these individual digital objects (see, for example, [Jantz, 2005; Smith, 2005; or Kotla et al., 2007]). Thus the problem is usually framed as a confluence of file formats, computing platforms, digital media properties, and trusted network storage facilities – in short, it is a problem readily addressed by a handful of registries and services coupled with "storage in the cloud". We can dust off our hands and walk away. But do these two assumptions adequately reflect the problem as it is experienced by consumers who at this point have been using personal computers for one or possibly two decades? Indeed they do not. I will argue that this perspective is a radical (and possibly dangerous) simplification if we actually examine the current technological and social environment along with the kinds of digital materials that consumers have begun to amass. While institutional archiving efforts are making great strides forward, consumers are unintentionally flirting with digital brinkmanship. This argument is not intended to undermine our need to reliably decode the burgeoning number of file formats or our need to find network storage solutions that are robust over the long haul. Rather, my aim is to more fully explore the long term storage, maintenance, and access of personal digital assets, with an emphasis on preserving the materials that have emotional, intellectual, and historical value to individuals. It is these everyday digital artifacts – the things that people cherish the most – that would seem to have the most uncertain fate if we simply continue to move forward on the current technological trajectory. In this article, I will explore a set of issues that have emerged through a series of five past studies and informal observations collected over time [Marshall et al., 2006; Marshall et al., 2007; Marshall, 2007; Marshall, 2008; McCown et al., to appear]. These issues suggest a broadened view of how we might undertake personal digital archiving, both broadly (for consumers) and more narrowly (for academics, scholars, researchers, and students); some of these issues may also carry over into the realm of institutional archiving, although that is not my aim. The participants in the studies on which I draw are diverse; the only common element of their backgrounds is that they have amassed a significant number of digital assets, material they value and on which they rely. Most of the participants are not computer experts; rather they are experts in using particular applications (e.g., Photoshop), equipment (e.g., digital video cameras), and services (e.g., social networking sites such as Live Spaces, Flickr, or YouTube). Most recently I have conducted a set of interviews with professional computer science researchers to investigate whether the general principles that emerged from earlier studies apply to people who are more technology-savvy. The concerns among these diverse populations are reassuringly similar; some of the details, however, do vary. I note any variance when it arises in the discussion. 2. The Archiving InstinctIndividuals rarely view their own stuff as requiring curation: curation is for objects in museums. They feel no compunction to label photos, preferring instead to chuck them into a shoebox with the idea that they might paste them into a photo album later when they have more time. Personal records may be filed, albeit haphazardly, to be dealt with when taxes are prepared, cars are maintained, or homes are sold. Books and CDs are crammed onto shelves to be searched visually. Although there are countervailing trends such as scrapbooking or lifehacking, neither reflects a universal impulse. Most people prefer to treat their personal artifacts casually; they are aware that some of the things they save will be valuable to them or their families in the future, but they don't have the time or the patience to invest the upstream effort, nor do they have the prescience to know which things they will eventually care about. In short, benign neglect is good enough to preserve many emotionally, intellectually, or financially important physical objects until they are wanted or needed. Ironically, benign neglect may be safer than naïve archiving. Witness the music lover who transferred at-risk vinyl recordings to expensive reel-to-reel tape 20 years ago: at this point, the tape may be more fragile and difficult to play than the original vinyl records. Furthermore, this attempt to predict value ignores the "long tail" phenomenon we've come to rely on in the last few years: these recordings are now no longer rarities, but rather are readily available through large digital music stores such as Amazon.com and are no more expensive than any modern recording. So why should we worry about personal digital archiving? Many people don't and might regard such worry as ultimately foolish. Won't personal digital archiving solve itself as the digital generation comes of age? It easy to write off digital archiving as a concern of worry-warts, compulsives, pessimists, and Luddites. From this perspective, once the digital generation has grown up, many of the barriers to keeping digital belongings will have dropped away. Consumers will store their files in the cloud routinely, so there will be fewer issues associated with maintaining local storage. Furthermore, as network storage becomes ever cheaper, people will be able to keep everything – every document they have created; every photo they have snapped; every movie and song they have downloaded; every bit of sensor data that has been recorded on their behalf; and every medical and financial record that pertains to them – without the anxiety of trying to anticipate the future worth of any item. Surely a library of format decoders will make it possible to revisit these materials when the need arises. It's not worth the time or effort to do anything but store the digital items now – we'll worry about their disposition later, when we discover that we want them or need them. It's a seductive view of the digital landscape. But it's not very realistic. First, it's important to shatter the myth that the digital generation will shed the problems of the generation before them. It appears to be just the opposite: the more comfortable people are with computers and the more they can do with them, the more they stand to lose. Indeed, all the data we have gathered bears this out. If we examine peoples' current archiving strategies, it becomes evident why. How people archive nowIt is misleading to claim that people don't take any steps to preserve the digital materials that are important to them. They often encounter tips about saving files, instituting backup procedures, and implementing good data safety and hygiene practices. For example, during an interview study [Marshall et al., 2006], one participant pulled out a (hardcopy) clipping she had saved from the local newspaper titled, "Saving files with a CD-RW drive," although she confessed she didn't know how to use her CD writer yet. Invariably people realize that their valuable digital assets are at risk, and they have every intention of addressing this risk. Indeed they perceive benign neglect to be a dangerous course to take and have the scars – lost baby pictures, missing documents and records, art projects that can't be viewed, novels in-progress saved on obsolete storage media – to prove it. What do people do, given that they know that doing nothing is risky business? These are six of the most common strategies that I have encountered:
I describe each method briefly below and discuss the most apparent flaws with the strategy. For some, personal backups are confounded with long-term archives; these consumers feel that if they were to lose anything, they would be able to reclaim it from their system backup. If they have performed the backups correctly, over the short term this belief is not unreasonable. Regular backups protect against accidental deletions and catastrophic hardware malfunctions. The problem is that a short term solution cannot be extrapolated to work over decades, although it is natural to do so. Furthermore, if pressed, even sophisticated users can't produce the system or file backups they claim to have made, nor would they know where a particular item was or how to retrieve it if they could. It is surprising how many people have made backups without ever trying to perform a restore, or have restored files and accidentally overwritten later versions. System backups simply aren't designed for long term storage and retrieval. Many knowledgeable users think of their current computing environment as a de facto host for their personal digital archive; they blend active local files with the files they have accumulated over time. In other words, when consumers buy a new computer, they take advantage of the ever-increasing storage capacity and move all the files they had on their old computer directly onto the new one. And they intend to continue this practice into the foreseeable future. Some merge the old files into the new file system; others segregate the transferred files into a discrete branch of the file hierarchy such as "My Old Documents". In theory, this practice ensures that significant portions of an individual's digital assets are centralized and accessible on their current system; pragmatically, however, this solution does not scale over time. A My Old Old Documents strategy assumes that little important escapes the seine of local storage; that digital stewardship consists of merely moving files around; and that conventional desktop browsing and search facilities scale over time. If we probe any of these assumptions, we find that none of them are true. It is not unusual for consumers to write the most valuable of their files to external media and to put that media – a succession of floppy disks, zip drives, external hard drives, CDs, DVDs, and other storage solutions of the moment – aside in a safe place, possibly at a physical remove (such as a safety deposit box). Of the ways people archive now, this one most closely matches the kind of benign neglect with which we archive physical materials like photos and important paper documents. We set aside the things that matter in a special place, and hope they will be there when the time comes to retrieve them. Accidental destruction of physical media is thus addressed and we know where the important assets are. Of course, this strategy falls apart upon closer inspection: the storage media is vulnerable in many ways (the bits are stored in an opaque format and the media deteriorates over time) and once a substantial number of CDs or DVDs has been amassed, there is no easy way of determining what is written on an individual disk. In other words, a label like "photos March 07" will not be particularly helpful in March, 2027. Furthermore, there's ample evidence that CDs and other backup media do not have the lifespan we originally thought they did. Anecdotal evidence finds at least 10% of shiny media is no good from the get-go.3 The availability of free email with virtually unrestricted storage (such as Hotmail) has given rise to a new archiving strategy: people send themselves (or other people that they trust) important files as attachments, using the email metadata as an easy way of indexing and organizing the files. Research on personal information management reveals that email is a singularly effective nexus for organizing one's digital assets [Whittaker et al., 2006]. In this setting, email is used less as a way for communicating with other people (a niche increasingly filled by social networking sites and software) and more for communication with a future version of oneself. There are even automated backup utilities such as MailStore Home4 that take advantage of this strategy. Email provides us with some important clues about how people might manage an archive; unfortunately, over a significant time period, email may compound the archiving problem (see [Marshall, 2007] for a comprehensive discussion of what happens to multiple email stores and email attachments as the years pass). As a recent variant on the email-as-archive strategy, consumers may spread files over a variety of social media sites [Marshall et al., 2007]. For example, the same videos may be published and shared on YouTube, GoogleVideo, and the Internet Archive. A set of photos may be posted to Windows Live Spaces, Flickr, Zooomr, and DeviantArt. Because the social media sites have different audiences, emphases, and capabilities, these personal collections may not fully overlap. It is left to the individual to make sure he or she has made sufficient copies of a particular digital object to feel safe and to track the health and viability of the external sites and their accounts on these sites. Because social media sites differ in so many ways – their policies, audiences, and capabilities vary to a significant extent – individuals use them to share different subsets of their personal collections; this leads me to believe that people will ultimately resist centralized archival storage in the cloud, preferring instead to mix and match among the many special-purpose sites that have arisen. Finally, in desperation, some computer users simply save the entire platform they used to create particular files. They may not use the platform in question any more – laptops may be stacked up in a closet or an old PC may be hidden in the basement – but the files, the applications needed to open them, and the operating system and computer hardware are all on hand, ready to be resuscitated when a file is needed. Interestingly, even though this solution may be employed by less sophisticated computer users, it pays implicit attention to all the many elements necessary to actually conserve a set of digital assets. Experience teaches us that computers stored this way may not spring to life when the boot button is pressed, however, and as time progresses, it seems like this type of full conservation imposes an increasingly heavy burden on the individual. Just how many clunky old computers and obsolete peripherals should we have to stash away to make sure we can get at our digital belongings in years to come? It is important to notice that these strategies share many of the same assumptions, assumptions that translate readily to the challenges I will describe in the next section. Individuals assume:
For if there is one constant across all kinds of people doing all kinds of things on computers, it is that they do not remember what they have buried in the dark recesses of their file systems or where they have stored what they do remember. Even five year old digital files can seem dusty and inscrutable, and people often store things in more places – on more devices, external media, and networked sites and services – than they can remember. These four assumptions reveal just the most obvious problems. There are many others hidden under the general rubric of curation. What happens if the material is encrypted and the key is long lost? What happens if a particular Digital Rights Management scheme has embedded assumptions that prevent an individual from copying the protected files a sufficient number of times to maintain them on up-to-date hardware? What happens if malware infects archived files, undetected? Obviously there are too many issues to enumerate here, but it is clear that the existing solutions optimistically employed by today's most prolific computer users are inadequate to keep their digital belongings safe for a lifetime (and beyond). Each of these challenges – digital stewardship, tracking distributed storage, detecting asset value, and long term access – will be addressed in turn in the next section. Once these challenges have been laid out, in Part 2 of this article I will explore the implications they have on the design and architecture of personal digital archives. Finally, in the concluding section of Part 2, I argue briefly that the time has come to pay attention to the personal side of digital archiving; I also caution against taking all these dire warnings too seriously and flirt briefly with the role of loss and forgetting. 3. Four Challenges for Personal Digital ArchivingAt any given point in time, most of us are sanguine about our digital belongings. We may have lost files in a hard drive crash at some time in the past5 or have a difficult time recovering others because we no longer have a working peripheral to handle obsolete storage media, but this loss seems minor in the grand scheme of things. Abstractly we feel confident of our ability to store digital material and recover it when we need it. In private communication a few years ago, a respected colleague opined: "Seriously: what's the hangup? As long as I take out the photos and look at them every decade or so, it's a piece of cake. We buy a computer every few years, spend a few minutes moving our documents folder to the new machine, we're done. You aren't suggesting that, come 2054, nobody will remember how JPEG works?" This offhand comment expresses the tacit general sentiment about digital archiving rather well: If we make a minimal effort to maintain the digital assets that we have, the archiving problem will take care of itself. As long as storage capacities keep growing, we will just take what we have with us each time we upgrade to new hardware. Moreover, even arcane file formats – that notorious bugaboo of the most pessimistic writings about digital archiving – are not cause for concern. Even if it is no longer in active use, a format as ubiquitous as JPEG will continue to be decodable into perpetuity. Surely other people have as much invested in their digital photo albums as we do, and it is in their interest to continue to be able to render these photos on the screen or print them on paper. We will have the bits and be able to locate decoders. What more will we need? But underlying my colleague's offhand comment are some remarkable assumptions that may haunt him in years to come. What are these assumptions and what are the challenges they represent? Let's take apart this remark and examine it more carefully. 3.1 Digital stewardshipAs long as I take out the photos and look at them every decade or so, it's a piece of cake. How many of us have photo prints that we haven't looked at in a decade? Would we be willing to abandon any photos we haven't looked at in a decade, sight unseen? Even simply taking out our photos and opening them one-by-one to keep them up to date represents a significant digital stewardship effort, especially if we have been taking advantage of digital photography's key strengths, cheap and easy recording and the ubiquity of digital cameras in phones and other mobile devices. The invisible burden of stewardship is a major personal digital archiving challenge. Benign neglect is a reasonably effective policy for the care of physical assets, but a dangerous strategy for their digital equivalents. It is rare for people to remember all the digital things they have amassed and where they have put them, so they can't even begin to estimate how much work it would be to "look at [my photos] every decade or so." Digital belongings accumulate far too quickly for us to contemplate any kind of laborious curatorial process. Moreover, if we examine how consumers manage routine IT tasks in their home computing environments, it is easy to see that digital archiving would add an undue burden to already tenuous ad hoc support arrangements. As a rule, the most competent person in a household is roped into performing much of the IT support for that household (or possibly for multiple households). Often these ad hoc IT people are unavailable for long stretches of time and the household's computing infrastructure slowly deteriorates – printers no longer print; laptops become infected with viruses; applications remain partially installed; preferences revert to default values; and so on. Bit by bit, computers slow down and peripherals stop working. Household members start coming up with strange folk tales about what's wrong and what it would take to set them to right [Marshall et al., 2006]. In dire situations, consumers may drop their PCs off at a local computer repair shop or call in an electronics retailer's Geek Squad. This solution not only requires that consumers articulate the problem (a process that may provoke considerable anxiety), but also that they are willing to pay for the maintenance. They don't know how much it will be, but they are certain that it won't be cheap. In fact, it may be cheaper to purchase a new computer and move on. And so they do. All too often, even if they're technically recoverable, the local files on the old computer are lost forever. Of course, this situation is not as dire as I present it: individuals may rely on community and social networks as a safety net for rescuing their own digital belongings [Jones and Dumais, 2002]. In some cases, this may even be a formal arrangement: One person in a household may assume the curatorial role and maintain the digital photo album; another household member may be the keeper of the music. In other cases, the arrangement is less formal: people use community photo sites like Flickr as a place where they can locate other peoples' photos that they consider to be part of their own digital history. Finally, there are occasional cases where people use their friends and family as de facto backups for their own stuff. For example, a student who lost a document on a virus-infected computer was able to reclaim it from her cousin: "Even my personal statement was saved onto that computer [a virus-infected laptop]. Then luckily, I also emailed it to my cousin, Celia,6 at her house. ... So I said, "Celia, do you still have my UCLA personal statement. She's like, "Yeah." So I said, "Okay, can you please email it." So then that's how I actually got it back to this computer." Another study participant who had lost promotional materials for an elementary school fundraising effort talked about how she also lost the trust of her peers: [The school fundraising material] was another thing that went [in my computer crash]. ... It was our first auction, and we did this hard work, and it all went. And I thought, 'let's just shoot ourselves.' And everyone was like, 'Donna'll7 have it. Don't worry about it.'... That was really a drag. .... So we've been working our butts off to get it back. So now someone else is in charge of all that input. And as an extra thing, I have it too. But I'm not the one in charge of it. And I'm not the one that's in charge of backing it all up then." Although storage in the cloud would seem to ameliorate some of the most immediate difficulties – at least there's no need to maintain local storage or set up a home RAID array – digital stewardship is no less necessary. What's on each account? Where and when was it posted there? How do I log on? What is the account's retention policy? Hence, our first major challenge to overcome is individuals' (justifiable) unwillingness to spend very much energy on curation, while taking advantage of a natural tendency to rely on the existing social fabric to keep digital assets safe. Digital stewardship is difficult and it doesn't seem to be getting very much easier. 3.2 Distributed assetsWe buy a new computer every few years. It is not unusual for households to buy a new computer every few years – or to have more than one computer at any given time. Nor is it unusual for people to have multiple email accounts, a variety of social networking or media sharing identities, and many different temporary places to store files (on removable media, on external drives, and so on). Without even thinking, consumers allow service providers such as banks and brokerages to store the primary copy of financial records. They may also think of some of the published media that they now own as being entirely replaceable using a digital library or an online store. Individuals' digital belongings are necessarily distributed over many different stores, some overlapping, and some completely independent. It is key to this argument to remember that a person's digital belongings are distributed among different stores for a variety of reasons. What are some of the more common reasons that people replicate files?
This is surely not a comprehensive list of the many reasons people maintain separate copies of their files in lots of different places, nor is it a complete list of where people put them. It suffices to say that digital belongings are spread far and wide, and data archiving is not the central motivation for this distribution. Let's look more closely at an example from an interview conducted as part of the study described in [Marshall et al., 2006]. The informant's immediate computing environment is set up in a 250 square foot studio apartment; it consists of a recently acquired PC and a Mac that is not currently working. She uses network services to store email attachments and material that is published on websites; a significant portion of her digital assets are stored on offline media or cannot be reached through an existing network connection. Needless to say, this list of data stores in Table 1 is not comprehensive, but it is an apt illustration of the principle described in this subsection. It is important to realize that this informant does not maintain any of these stores by herself; during our interview with her, she mentioned at least three different friends who perform ad hoc IT support for her. Each of them has a specialty, and they often come to blows over what should be done in the name of providing her with computer support.
Table 1. An example of the distribution of collections and collection subsets
In this informant's storage scheme, the reference copies of her favorite photos from one photo shoot were left on the camera's flash memory and copied many times – to share them with men she was dating, to modify them using Photoshop, to back them up, to restore them to a new hard drive, and to publish them on the web. The copies were by no means identical; they differed in resolution, in file format, and in name, and some were edited in other ways. These photos are stored in at least two formats (jpeg and psd), saved under at least four filenames (including the original name generated by the camera), and spread over at least six file systems, including the camera's flash memory, her local PC hard drive, her old hard drive (now in a PC at someone else's home), and in the attachments store of several of her "sent" email folders, stored on network services. Thus there may be more than a dozen versions of a photo she liked, each subtly different from the last. It is important to realize that this distribution is mostly invisible to most consumers. They conceive of their stuff symbolically as being in one centralized, authoritative place: "We buy a new computer every few years" is a symptomatic claim. Moving files from one PC to its successor is not actually creating an archive. Why is this intentionally distributed storage and ad hoc partial replication a problem? After all, as we saw earlier, people have ample justification for putting their digital belongings in different places (or for leaving them in place, as for example in the case of financial or medical records). Why isn't it simply a safeguard? At the time of storage, replication is a valuable safeguard. But as time passes, the status of these distributed stores changes: ISPs go out of business; unused accounts are deactivated; people change their institutional affiliations (for example, students graduate and lose their university accounts). Furthermore, data entrusted to services and remote stores may be cared for in a manner different than the individual expects: an ISP may fail to perform periodic backups or refresh older storage systems; service providers may fail to issue the appropriate notifications; and so on (see [McCown et al., to appear] for a more complete discussion of how data entrusted to services disappears). Finally, local storage is subject to all the known problems: hard drive failures and accidental erasures; removable media deterioration or loss; media obsolescence; and peripheral storage device failure or obsolescence. One way or another, a collection copied in three places is reduced to two copies, then one. An individual is seldom aware of this digital brinksmanship. Finally the last copy disappears, and it is not until the consumer tries to access the items that he or she realizes that an entire collection is gone. In a past survey, we found that about two-thirds of the reported cases of data loss had three causes: (1) services being discontinued; (2) ISP policies or IT practices that respondents were unaware of; or (3) accounts being deactivated or lost [Marshall et al., 2007]. Other non-technological causes of data loss included police raids, hacking, and death of the account owner. Contrary to the standard picture of data loss that involves disk crashes or media failure, these losses were not abrupt and catastrophic; rather, they were the result of normal business policies and practices. 3.3 Value and accumulation[We] spend a few minutes moving our documents folder to the new machine. One common archiving strategy – especially among knowledgeable computer users – is to do exactly as my correspondent described: move My Documents wholesale to the new computer. As data transport speed and storage capacity increase apace, this method of archiving digital files is reassuringly invisible; it takes almost no time and little effort. What is hidden in this strategy is that it allows files to simply accumulate without regard to value or provenance. Where did this file come from? Why do I have it? These questions cannot be answered without recording an item's provenance at the outset and maintaining it over time as the item is moved from store to store. Some consumers anticipate accumulation as a problem and ruthlessly (and often arbitrarily) eliminate files when the mood strikes them; however, because digital stuff accumulates so quickly, it is doubtful that anyone can cull and keep track of all that they have effectively. When asked if he ever got rid of digital stuff, one study participant said: "Yes, but not in any systematic manner. And not by pruning old stuff. It's more like, I have things littering the desktop and at some point it becomes unnavigable... A bunch of them would get tossed out. A bunch of them would get put in some semblance of order on the hard drive. And some of them would go to various miscellaneous nooks and corners, never to be seen again." I have observed this type of spontaneous clean up effort repeatedly during field studies. It is an impulse that strikes all kinds of computer users, varying little in its execution – a small number of files are quickly and symbolically deleted. Sometimes people create subdirectories and impose additional order. But this impulse rarely extends beyond the situation at hand. It's just too time-consuming, and the immediate rewards are slight (if not negative, because restructuring one's files makes them instantly harder to find). This notion of value is the nexus where principles and practices collide. People often will assert a general principle that is belied by their actual practices. It is instructive to look at four of the most common contradictions between what people say and what they do:
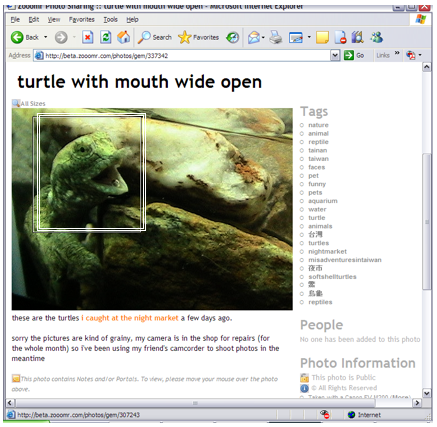
These contradictions are discussed at greater length in [Marshall, et al., 2006], but I will review them in summary because they have important implications for the design of any type of personal digital archiving service or application. Ad hoc replication. Certainly any digital archivist or computer scientist would agree that one of the chief advantages of digital materials is the ease with which they can be copied and that making copies is a sound strategy for ensuring that collections are safe. The successful distributed LOCKSS system [Maniatis et al., 2005] is based on this principle. It is no surprise that consumers also recognize replication as a very basic and effective strategy. However, in practice, most individuals fail to implement simple replication schemes (for example, periodic file backup), even given the availability of easy-to-use applications and services such as Microsoft's One Care. It is not unusual for consumers to acknowledge that collections are safer if they are stored in multiple places, but usually files are copied only on an ad hoc basis – as a side-effect of one of the actions described in the previous subsection – rather than methodically replicated. Backup regimens are frequently abandoned because there is no appropriate storage media available. Hence simple file replication is, at best, irregular and not dependable. Digital clutter. As we have noted in previous studies, the term "pack rat" is unquestionably a pejorative for most people, even those who enjoy collecting things [Marshall and Bly, 2005]. Although one can be a digital pack rat with no outward signs of accumulation, many individuals still regard their excess digital baggage as shameful. If files haven't been accessed or are not immediately recognized, they are candidates for the digital scrap heap. For example, one informant told us that he should delete some files we were looking at with him because, "I haven't looked at this stuff in a long time... [In the future] I will become a lean, mean organizing machine"). Another, talking to her partner, said, "I don't know what that is. You might as well delete it as far as I'm concerned." Periodic loss. Periodic loss is regarded as inevitable and in principle as a way of controlling clutter, much like forest fires may be used to clear brush to support the health of the overall ecosystem. This phenomenon comes to the forefront when people talk about their email, which tends to accumulate quickly. Because email involves many small hard-to-cull items (individual messages) and is harder to replicate or back up than other types of files (people often don't know where or how email is stored in the file system or in web-based email applications), it is a good illustration of this principle. This fire-like quality of the periodic loss of digital belongings does not escape informants. Indeed, they frequently refer to real or anticipated loss as being like a fire, something you have to move beyond. It is almost as if individuals are afraid to say that a digital file is valuable, so likely they feel they are to lose it. As we discussed the 13,000 messages in his Inbox, one informant told us "There's nothing life threatening even if I lost it [his email]. Like, I have hard copies ... or I could write them again. ... If they were totally lost it wouldn't be the end of the world." Replacement. Finally, and importantly for the later discussion of the implications of these studies on service design, it seems that many people have come to rely on the replaceability of anything that is stored on the Internet – if you have downloaded a digital file once, you can find it and download it again: "I can log in somewhere and get this stuff." Even purchased items are regarded as ultimately replaceable: it is easier to contemplate buying something a second time than it is to perpetually worry about its safety: "My pictures and my documents are more important [than my mp3s]. Because music you could always go and buy. Or you could always go and burn it somewhere else." What do these principles and the contradictory behaviors ultimately tell us? They underscore the difficulty of stating, admitting, or predicting value of digital assets. People are more apt to demonstrate value through ad hoc replication of a file than they are to explicitly declare something to be valuable. To say that a digital item is valuable is to admit how little control we have over our digital belongings; it also adds cognitive overhead to a process (getting organized) that people already feel is overwhelmingly taxing [Jones, 2004]. The value of digital assets changes over time with changing circumstances: An informal photo may not have been valuable when it was taken, but may become so if the person in the photo dies. Finally, it is important to people to be able to cull their files, even if they don't actually end up doing so very effectively or completely; just as the hypothetical photo becomes more valuable when its subject dies, it becomes absolutely disposable if its subject has instigated a painful divorce. In this way, it is hard to imagine an archiving application that keeps everything as being emotionally viable. Deletion is an important way for people to exert their own control over their digital assets; without this control, consumers may be unwilling to risk using an application or service.8 Thus the value of digital items is nuanced and depends on many factors, factors that may be similar to the concerns we have when we informally archive our important physical belongings, but magnified by the sheer quantity of material. We might demonstrate an item's worth by what we do with it – how often we access it, how many times we copy it, whether we email it to ourselves, whether we take some trouble to clarify its provenance (for example, by renaming it), and who we share it with. Some efforts we might assume have inherent worth because of the labor or creativity that went into producing the artifact, or the number of intermediate versions that have been saved. Finally, some items may actually be less valuable than others because they were downloaded from a trusted source like a digital library that guarantees replacement. 3.4 Retrieval from long-term storageSeriously: what's the hangup? ... You aren't suggesting that, come 2054, nobody will remember how JPEG works?" Let's jump ahead to 2054. Will we really be worried about how JPEG works, or will we simply not know what we have and where we have stored it? Most future-looking scenarios assume that we will more or less remember what we have, and know roughly what we're looking for. Moreover, there's a tacit assumption that we'll be fishing for it in a centralized repository, ala MyLifeBits [Gemmell et al., 2006], and decoding what we want as we go. Yet most of us have had the experience of looking in a cardboard box of personal treasures and discovering items that we'd absolutely forgotten: in this situation, it is the item itself that is evocative. We would never think to look for it; nor would it be apt to figure prominently in a large heterogeneous collection. Finally, it is doubtful that we would invest very much time, effort, or money to decode and render unknown items. This type of retrieval is neither searching nor browsing; it is re-encountering. The item itself is essential to making sense of its place in our lives and remembering why we have kept it. Physical belongings are stored in such a way that re-encounter is not only possible; it is also likely. We store items of great value together. But this is certainly not true of digital belongings. Earlier in this section, I explained how digital belongings are stored in a distributed fashion, on- and offline, on various sorts of removable media, on old computers, and on the many different computers we use. They are stored as email attachments, as part of blogs, on web sites, and held by different sharing services. Digital belongings are ultimately stored according to what people are planning to do with them and exigencies of the moment. That we have them at all is partially a side-effect of what we've done with them previously. The distributed, highly replicated nature of our personal accumulations puts a different spin on search strategies. A very different set of issues will need to be addressed than we've tackled so far with Internet search (which is necessarily adversarial) [Henzinger et al., 2002], exploratory search of complex information resources [Marchionini, 2006], and desktop search (which is necessarily precise – we know what we want when we begin looking for it) [Dumais et al., 2003]. Collections will be very large, spread out, cryptically encoded, of unknown provenance, and full of complete and partial replicas of individual items. Where is the highest fidelity copy of this photograph? Where is the unedited copy of this photograph? What is the provenance of this photograph? We don't remember what we have; we may not remember the many places where we have stored things; yet we may want something specific or at least something that is remembered in a very specific way. An example of distributed copies It is easy to see how different services and server-side capabilities will result in important differences among the copies that are stored on each of them. It is evident from our previous studies that respondents have already lost track of where they've put different digital artifacts, even if they can still remember the reasons for storing things where they did. The following snippet of IM conversation illustrates this; RES is the respondent, INT is the interviewer: [11:09:24 PM] RES: [There are] 6 [online places where I store things] in all. 1.) school website, 2.) blogspot, 3.) wordpress.com (free blog host, different from wordpress.org), 4.) flickr, 5.) zooomr (for pictures, they offer free "pro" accounts for bloggers, but even for non-pros, they don't limit you to showing your most recent 200 pics only unlike flickr), 6.) archive.org [11:10:42 PM] INT: I ask just because you seem to have stuff in a lot of different places (so far two different blog sites, flickr, youtube, msnspaces, ... maybe yahoo?)... [11:11:07 PM] RES: oh right.. youtube because people always tell me that they don't feel like downloading my quicktime files from archive.org RES, a young artist/animator, is storing media projects that she wants to share on different services according to the audiences she feels that they reach and the varying functionality of the services. She also has used some of the services as backups because she feels that they will be stable into the foreseeable future. If we pick out a single example, a photo that has been stored on several photo sharing sites, the differences among the copies are evident. Figure 1 shows the photo on its original site. This site, Zooomr, is aimed at professional photographers and supports within-photo captioning and linking. The respondent has written a narrative description of the photo and assigned it a series of tags in English and Chinese; the tags do not reflect a controlled vocabulary. The photo is stored in five sizes, from a thumbnail through a size (516x372) that is reduced from the resolution of the original on her camera. Because the site is oriented to photographers, there is structured metadata describing the photographic process. There are also site-specific statistics such as how many times the photo has been accessed and how many other sites refer to it. The respondent has also put the photo on several other photo- and art- sharing sites and has included it in several different blog posts. Each instance has its own title, narrative, caption, and tags, aimed at the audience of the site. Similarly, each site offers measures of popularity (how often the photo has been viewed, how many times it has been linked to, ratings assigned to it by viewers, and possibly viewer comments.)
Specifically, the differences among the various copies can be categorized this way:
The complexities of this kind of distributed storage of copies become evident if we push this example into 2054. Suppose this is indeed the photo that best satisfies the user's search – which copy should a search engine return? The one that's at the highest resolution? The one with the earliest date? The one with the latest date? Should the searcher be made aware of all the other copies? Should the metadata be consolidated or not? Are the popularity metrics still relevant? If a "best" copy is determined, does the searcher need to know about the others and the collections they are in? Although this example is seemingly trivial (will she even want this photo of a turtle in 47 years? Will she remember it? Will she want to re-use it in a different project?), we can envision this as being a greater issue if these are photos of a family member or if the photos have won awards in competitions. These problems of not-quite-duplicate copies extend to other areas. For example, consider the case of the scientist who has stored a dataset in multiple places to share it and to back it up. Over time, she has used different gap-filling algorithms to complete the dataset, so the copies aren't exactly the same. Nor do they seem equivalent to the scientist. Finding all the copies and being able to characterize the differences among them seems like it will be an important aspect of long-term search that is very different from the type of duplicate elimination that is part of web search today. Duplicate elimination is a bigger challenge when it's your own data. 4. From observations to implicationsFrom this discussion, it is apparent that the very same characteristics that make personal digital assets attractive – the ease with which they are created, edited, copied, and shared; the fact that they don't take up real space; and the long tail phenomenon, to name a few – also make digital stewardship a far greater burden. Consumers walk a delicate tightrope between euphoria (for you can do so much that you could never do before) and uncertainty (this new world is complex, and one is never as sure-footed as seems to be necessary). In Part 2 of this article, I examine what the four challenges I enumerated in Part 1 imply for personal digital archiving. What are the mechanisms, services, metaphor, and institutions that can address these challenges? It should be no surprise that some of them exist already and just need to be repurposed, and others will need to be developed, with considerable imagination, from scratch. AcknowledgmentsI'd like to thank Catharine van Ingen for many helpful discussions about storage, media, and archiving and Sara Bly and Francoise Brun-Cottan for invaluable fieldwork assistance and data analysis help. Michael Nelson and Frank McCown (and their terrific Warrick "Lazy Preservation" application) were the main impetus for finding out about lost websites. Will Manis and Jeff Ubois have both been great sounding boards for these ideas as they've taken shape. Notes1. There has also been a steady stream of "how to" columns that provide advice about data safety. For example, see Manes, 1998. 2. These references are intended as high-profile exemplars of different approaches. There is a substantial body of serious work to-date on sustainable representation of digital objects and on long-term digital storage strategies. Recently, several conference series have been inaugurated based on specific interest in digital preservation and sustainable repositories. Enumeration of all of them is impractical and orthogonal to the aims of this article. 3. I learned this disquieting fact during a series of helpful conversations with Catharine van Ingen, a senior architect at Microsoft. 4. <http://www.mailstore.com/en/mailstore-home.aspx>; Jeff Ubois pointed out the availability of this utility in a recent email. 5. In recent studies, excluding a study that deliberately recruited people who have lost websites, a conservative interpretation of the data confirms that more than half of the informants have lost vital digital files. 6. Informants' names are changed. 7. The informant is referring to herself here. 8. If there is any doubt of this, witness users' frustration when gmail did not allow them to delete messages. Although gmail was strong on retrieval References[Beagrie, 2005] N. Beagrie, "Plenty of Room at the Bottom? Personal Digital Libraries and Collections." D-Lib Magazine, 11, 6 (June 2005). <doi:10.1045/june2005-beagrie>. [Dumais et al., 2003] S. T. Dumais, E. Cutrell, E., J. J. Cadiz, G. Jancke, R. Sarin and D. C. Robbins, "Stuff I've Seen: A system for personal information retrieval and re-use." Proceedings of SIGIR 2003: 72-79. <http://doi.acm.org/10.1145/860435.860451>. [Gemmell et al., 2006] J. Gemmell, G., Bell, R. Lueder, "MyLifeBits: a personal database for everything." Communications of the ACM, 49 (1): 88-95. <http://doi.acm.org/10.1145/1107458.1107460>. [Gladney, 2006] H.M. Gladney, "Principles for Digital Preservation." Communications of the ACM, 49 (2): 111-116. <http://doi.acm.org/10.1145/1113034.1113038>. [Hafner, 2004] K. Hafner, "Even Digital Memories Can Fade." New York Times, November 10, 2004. <http://www.nytimes.com/2004/11/10/technology/10archive.htm>. [Heminger and Robertson, 1998] A.R. Heminger and S.B. Robertson, "Digital Rosetta Stone: a conceptual model for maintaining long-term access to digital documents." Proceedings of HICSS'98, Vol. 2., Hawaii, 1998, pp. 158-167 <doi:10.1109/HICSS.1998.651695>. [Henzinger et al., 2002] M. Henzinger, R. Motwani, and C. Silverstein, "Challenges in web search engines." ACM SIGIR Forum 36 (2): 11-22. <http://doi.acm.org/10.1145/792550.792553>. [Jantz, 2005] R. Jantz, "Digital Preservation: Enabling Technologies for Trusted Digital Repositories." D-Lib Magazine, 11, 6 (June 2005) <doi:10.l045/june2005-jantz>. [Jones, 2004] W. Jones, "Finders, Keepers? The present and future perfect in support of personal information management." First Monday, 9, 3 (March, 2004) <http://www.firstmonday.org/issues/issue9_3/jones/index.html>. [Jones, et al., 2002] W. Jones, S. Dumais, and H. Bruce, "Once found, what then? : a study of 'keeping' behaviors in the personal use of web information." Proceedings of ASIST 2002, 39 (1): 391-402. <doi:10.1002/meet.1450390143>. [Kotla et al., 2007] R. Kotla, L. Alvisi, and M. Dahlin, "SafeStore: A Durable and Practical Storage System." Proceedings of Usenix Annual Technical Conference (USENIX 2007), CA, 2007, pp. 129-142. <http://www.usenix.org/events/usenix07/tech/kotla/kotla_html/index.html>. [Kuny, 1998] T. Kuny, "A Digital Dark Ages? Challenges in the Preservation of Electronic Information." International Preservation News, 17 (May 1998). <http://www.ifla.org/IV/ifla63/63kuny1.pdf>. [Lesk, 1995] M. Lesk, "Preserving Digital Objects: Recurrent Needs and Challenges." Proceedings of the 1995 National Preservation Office (NPO) Conference (Brisbane, Queensland, Australia, November 27-30, 1995), National Library of Australia, Canberra, Australia, 1995. <http://www.lesk.com/mlesk/auspres/aus.html>. [Lorie, 2002] R. Lorie, "A Methodology and System for Preserving Digital Data." In Proceedings of JCDL'02 (Portland, Oregon, July 14-18, 2002). ACM Press, New York, NY, 2002, pp. 312-319. <http://doi.acm.org/10.1145/544220.544296>.
[Manes, 1998] S. Manes, "Personal Computers; ... But With Luck and Diligence, Treasure-Troves of Data Can Be Preserved." New York Times, April 7, 1998.
<http://query.nytimes.com/gst/fullpage.html?res=9B05E4DD113AF934A35757C0A96E958260 [Maniatis et al., 2005] P. Maniatis, M. Roussopoulos, T. Giuli, D. Rosenthal, M. Baker, and Y. Muliadi, "LOCKSS: A peer-to-peer digital preservation system." ACM Transactions on Computer Systems, 23(1): 2-50, Feb, 2005. <http://doi.acm.org/10.1145/1047915.1047917>. [Marchionini, 2006] G. Marchionini, "Exploratory search: From finding to understanding." Communications of the ACM, 49(4): 41-46. <http://doi.acm.org/10.1145/1121949.1121979>. [Marshall, 2007] C.C. Marshall, "How People Manage Personal Information over a Lifetime." In Personal Information Management (Jones and Teevan, eds.), University of Washington Press, Seattle, Washington, 2007, pp. 57-75. <http://www.csdl.tamu.edu/~marshall/PIM%20Chapter-Marshall.pdf>. [Marshall, 2008] C.C. Marshall, "From Writing and Analysis to the Repository: Taking the Scholars' Perspective on Scholarly Archiving." To appear in Proceedings of JCDL 2008. (Pittsburgh, PA, June 16-20, 2008), New York: ACM Press. [Marshall et al., 2006] C.C. Marshall, S. Bly, and F. Brun-Cottan, "The Long Term Fate of Our Personal Digital Belongings: Toward a Service Model for Personal Archives." Proceedings of Archiving 2006. (Ottawa, Canada, May 23-26, 2006), Springfield, VA: Society for Imaging Science and Technology, pp. 25-30. <http://arxiv.org/abs/0704.3653>. [Marshall et al., 2007] C.C. Marshall, F. McCown, and M.L. Nelson, "Evaluating Personal Archiving Strategies for Internet-based Information." Proceedings of Archiving 2007, Arlington, Virginia, May 21-24, 2007, Society for Imaging Science and Technology, Springfield, VA, 2007, pp. 151-156. <http://arxiv.org/abs/0704.3647>. [Marshall and Bly, 2005] C.C. Marshall and S. Bly, "Saving and Using Encountered Information," Proc. CHI'05, pp. 111-120. <http://doi.acm.org/10.1145/1054972.1054989>. [McCown et al., to appear] F. McCown, C.C. Marshall, and M.L. Nelson. "Why Websites Are Lost (and How They're Sometimes Found)," to appear in Communications of the ACM. [Rothenberg, 1995] J. Rothenberg, "Ensuring the Longevity of Digital Documents." Scientific American (Jan 95), 42-47. <http://www.clir.org/pubs/archives/ensuring.pdf>. [Smith, 2005] M. Smith, "Eternal Bits: How Can We Preserve Digital Files and Save Our Collective Memory?" IEEE Spectrum, July 2005, 22-27. <http://spectrum.ieee.org/print/1568>. [Whittaker et al., 2006] S. Whittaker, V. Bellotti, and J. Gwizdka, "Email as personal information management." Communications of the ACM, 49 (1): 68-73. <http://doi.acm.org/10.1145/1107458.1107494>. Copyright © 2008 Catherine C. Marshall |
||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/march2008-marshall-pt1
|