D-Lib Magazine
March/April 2016
Volume 22, Number 3/4
Table of Contents
RAMLET: a Conceptual Model for Resource Aggregation for Learning, Education, and Training
Katrien Verbert, KU Leuven, Belgium
katrien.verbert@cs.kuleuven.be
Nancy J. Hoebelheinrich, Knowledge Motifs, USA
nhoebel@kmotifs.com
Kerry Blinco, Northern Territory Library, Australia
kerry.blinco@nt.gov.au
Scott Lewis, Austin, Texas, USA
slewis—OldWorldAviaries.com
Wilbert Kraan, University of Bolton, UK
w.g.kraan@ovod.net
DOI: 10.1045/march2016-verbert
Printer-friendly Version
Abstract
The Resource Aggregation Model for Learning, Education and Training (RAMLET) is a new IEEE standard, IEEE Std 1484.13.1™-2012, that has been developed to facilitate interoperability of existing standards for multimedia resource aggregations. Examples of such standards include METS and MPEG-21 Digital Item Declaration. These standards are used on a large scale for describing the structure of a collection of multimedia content. In addition, multiple structures can be specified to provide different paths through the same content. A limitation lies in the fact that they cannot interoperate. For instance, content structured in MPEG-21 cannot be reused in a METS context. This article presents different use cases in which the RAMLET standard enables interoperability of resource aggregation formats. We describe the RAMLET standard and mappings to other standards. In addition, we discuss lessons learned from the development process of this standard and future research challenges.
1 Introduction
Resource aggregation is both a process and the end result of that process. The process gathers resources and describes their structure, so that the resulting aggregation can be used for transmission, storage, and delivery to users [1]. The resource aggregation specifies how resources fit together into a coherent, structured whole. In addition, resources composing the resource aggregation can be structured in more than one way. As an example, a resource aggregation may collect a short video resource that explains the history of the Web, basic tutorials on HTML, CSS and Javascript and exercises related to these topics. A resource aggregation collects and structures these resources. In addition, multiple structures can be specified to provide different paths through the same content, such as starting first with a simple exercise for students with previous experience.
Different communities, such as the multimedia, library, technical documentation, and learning technology communities, have created their own specifications and standards for resource aggregations. Examples include the Metadata Encoding and Transmission Standard (METS), an initiative of the Digital Library Federation [7], the IMS Content Packaging (IMS CP) specification, which is predominantly used in the educational domain, and MPEG-21 Digital Item Declaration (MPEG-21 DID), a standard for the audio-visual content industry. OASIS OpenDocument and International Digital Publishing Forum EPUB also fit into this mold.
Often, a need exists to exchange resource aggregations among communities that may be using different aggregation formats. In these cases, it is necessary to map between aggregation formats, so that existing resource aggregations can be exchanged and reused in new and different contexts. To facilitate such exchange, there is a need for a common conceptual model that enables the interpretation and translation of different resource aggregation formats. The Resource Aggregation Model for Learning, Education and Training (RAMLET) is a new IEEE standard, IEEE Std 1484.13.1™-2012, that defines such a conceptual model for digital aggregations of resources for learning, education, and training applications. The RAMLET standard has been developed using an ontological approach. Five aggregation formats, IMS CP, METS, MPEG-21 DID, Atom, and OAI-ORE, were analyzed, and a core ontology was constructed that represents an abstract generalization of the aggregation formats. In addition, mappings have been defined between the RAMLET model and these resource aggregation formats to enable their interoperability. The approach enables the exchange and transformation of resource aggregations that are stored in different formats and the exporting of an aggregation for use in OAI-ORE, IMS CP, METS, Atom or MPEG-21 applications.
In this paper, we present our work on the development of RAMLET. Section 2 presents use cases that illustrate the need for the standard. Section 3 outlines the resource aggregation formats that were used for the development of RAMLET. Section 4 presents the RAMLET model and mappings that define crosswalks among aggregation formats. Finally, concluding remarks and critical reflections are presented.
2 Use Cases
This section presents several use cases that illustrate the need for the standard. The first use case illustrates exchange and reuse of resource aggregations among systems using different standards and specifications. Use Case 2 illustrates how the use of RAMLET can enable interoperability of systems that use their own internal format for resource aggregations. Seven other use cases have been described in [8].
Use Case 1
This use case addresses exchange and reuse of resource aggregations among systems using different specifications. For example, a system using METS might import resource aggregations that use IMS CP and MPEG-21 DID, and create a new resource aggregation.
Usage scenario
A content author in a university is developing a new resource aggregation and wishes to include resources from different sources, including learning resources, reference materials, and research data. The author searches for appropriate materials and retrieves each resource to an authoring system. The resources are exported from their repositories in resource aggregation formats specific to their respective repositories. The authoring system interprets the incoming resource aggregation formats and converts them to its native format.
The author then creates the new resource aggregation, including the imported resources, and makes the new resource aggregation available to the local learning management system (LMS) or run-time system (RTS). The new resource aggregation is in the aggregation format used by the authoring system. Figure 1 presents this scenario.
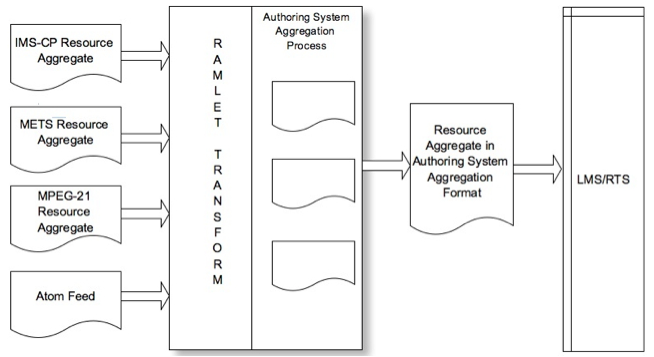
Figure 1: Use Case 1 ((IEEE Std 1484.13.1-2012 — Reprinted with permission from IEEE. copyright IEEE, 2012. All rights reserved.)
Use case summary: retrieve-interpret-aggregate-deploy
This use case addresses retrieving resource aggregations from diverse resource repositories that provide resource aggregations in different resource aggregation formats. The retrieved resource aggregations are interpreted, and converted into a single format that can be used by an authoring system and then aggregated into a new resource aggregation. The new resource aggregation can be deployed by an LMS or RTS that is limited to a single resource aggregation format.
Use Case 2
An LMS creates a time and context-sensitive resource aggregation and will import, store, and make available resource aggregations from systems using different specifications. For example, a system using its own internal format might import resource aggregations that use IMS CP, METS, MPEG-21 DID, and the format used by a student information store at the time they are required in the learning path.
Usage scenario
An LMS supports a learner by using and providing learning resources that are appropriate in the respective context of the learning situation and the individual requirements of the learner at a particular time. Such requirements may include accessibility preferences or needs in order to access the material. The LMS retrieves, provides, and aggregates required resources just in time and makes use of different sources that provide resources in different resource aggregation formats. Figure 2 presents this scenario.
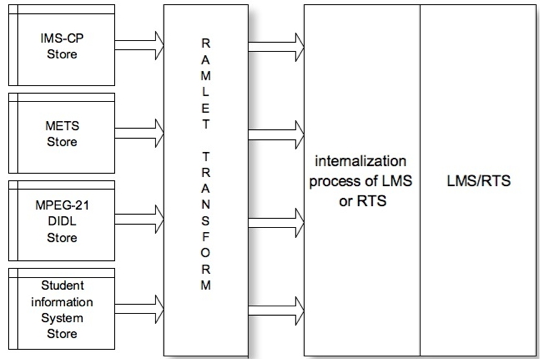
Figure 2: Use Case 2 ((IEEE Std 1484.13.1-2012 — Reprinted with permission from IEEE. copyright IEEE, 2012. All rights reserved.)
Use case summary: retrieve-interpret-internalize-deploy
This use case avoids building a complete resource aggregation prior to deployment. RAMLET supports transformation and interpretation of retrieved resource aggregations in diverse aggregation formats into a single format. The delivery system is able to produce an internal representation of the resource aggregation and to render the resources.
3 Resource Aggregations
This section briefly outlines the resource aggregation formats that were used in the development process of RAMLET: IMS CP, METS, MPEG-21 DID, Atom, and OAI-ORE. The structure and properties of the resource aggregation formats are described. Simple examples are included to illustrate the different constructs. Note that these examples are incomplete and much simpler than real world applications.
3.1 IMS CP
IMS CP is a specification that enables learning resources to be transported between educational environments. The specification was developed by the IMS Global Learning Consortium and plays a central role in the learning technology community.
An IMS content package contains two major components: an XML document called a manifest file that describes the content structure and associated resources of the package, and the content making up the content package. The manifest file is comprised of four sections:
- Metadata describes the content package as a whole. Metadata are usually included using the IEEE learning object metadata (LOM) standard, though it can rely on other schemas.
- Organizations contain the content structure of the learning resources making up a stand-alone unit or multiple units of instruction.
- Resources define the learning resources bundled in the content package.
- (sub)Manifest(s) describe any logically nested units.
The organizations section describes zero, one, or multiple organizations of the resource aggregation. Multiple organizations can provide learners with a variety of alternative structures for content. Each organization within the organizations section specifies how resources fit together into a hierarchically arranged sequence of items. These items point to a resource in the resource section. Listing 1 shows an example.

Listing 1: A simple IMS CP manifest document
3.2 METS
METS is a standard for encoding descriptive, administrative, and structural metadata regarding resources within a digital library [9]. The standard is maintained by the U.S. Library of Congress.
A METS document consists of seven sections:
- METS Header contains metadata describing the METS document itself, including the creator and editor.
- Descriptive Metadata may point to descriptive metadata external to the METS document, contain internally embedded descriptive metadata, or both.
- Administrative Metadata, also embedded or external to the METS document, provides information regarding how the files were created and stored, intellectual property rights, metadata regarding the original source object from which the resource aggregation derives, and provenance information.
- File Section lists files containing content that compose the resource aggregation. <file> elements may be grouped within <fileGrp> elements that can be used to organize individual file elements into sets.
- Structural Map is the heart of a METS document. As in IMS CP, it outlines a hierarchical structure for the resource aggregation, and links the elements of that structure to content files and metadata. Multiple structures can be specified.
- Structural Links capture the existence of hyperlinks between nodes in the hierarchy outlined in the Structural Map.
- Behavior can be used to associate executable behaviors with content. Such sections link resources with applications or programming code that are used to render or display the resource.
METS and IMS CP are similar. Both resource aggregation formats specify how resources fit together into a hierarchically structured whole, express metadata pertaining to the content, and provide an inventory of files. The distinction between administrative and descriptive metadata of METS is not available in IMS CP nor is behavioral information.
Listing 2 shows an example of a simple METS document. The <mets> element is the root element of the aggregation. The <mets:structMap> element corresponds to the IMS CP organization element. As with the IMS CP organization element, the <mets:structMap> represents the structure of content in a hierarchically arranged sequence of <mets:div> elements. In the example, the <mets:structMap> organizes content into a sequence of two physical pages. Each page division points to a single file by a <mets:fptr> element, which corresponds to an IMS CP resources element.
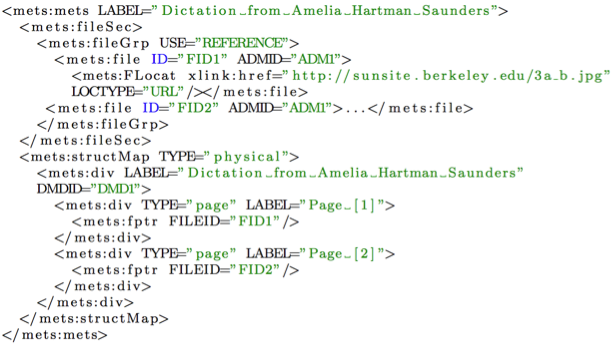
Listing 2: A simple METS document (adapted from [10])
3.3 MPEG-21 DID
MPEG-21 is a framework for networked digital multimedia, designed by the Moving Picture Experts Group. MPEG-21 describes a standard that defines the description of content and also processes for accessing, searching, storing, and protecting the copyrights of content.
The basic concept in MPEG-21 is the digital item. Digital items are structured resources, and include a standard representation, identification, and metadata. Digital items are defined by the MPEG-21 Digital Item Declaration (DID), a subpart of the standard, which defines the following entities:
- Container is a structure that allows digital items and/or containers to be grouped. As in METS and IMS CP, such an organization contains a hierarchically arranged sequence of items.
- Item or digital item is a grouping of sub-items and/or components that include resources and their descriptions. In IMS CP and METS, resources are listed separately.
- Component is a resource bound to all of its relevant descriptors. These descriptors are information related to a specific resource instance.
- Resource is an individual data stream, such as a video file, image, audio clip, or textual asset.
- Fragment designates a specific point or range within a resource. For example, a fragment may specify a specific point in time of an audio track.
- Descriptor introduces an extensible mechanism that can be used to associate textual metadata with other entities. Examples of metadata include information supporting discovery and rights expressions.
Another set of entities contains choice, selection, condition and assertion and allows the description of a digital item to be optional or available under specific conditions. For example, a choice may represent the choice between a high- or low-bandwidth Internet connection. Based on the selection made by a user, the conditions attached to an entity of a digital item may be fulfilled and the entity may become available [11]. Such conditional behavior is not available in METS or IMS CP.
Listing 3 shows an example of an MPEG-21 DID document. The DIDL element is the root element. A container element corresponds to IMS CP organization and METS structMap elements and describes the structure of the resource aggregation. In the example, the container element groups two item elements, track01 and track02. MPEG-21 items correspond to IMS CP items and METS div elements. These items bind components to descriptor elements. Such components, then, correspond to IMS CP Resource and METS file elements.
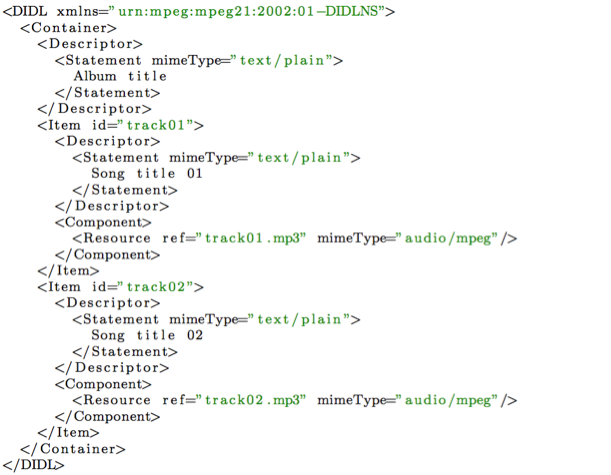
Listing 3: A simple MPEG-21 DID document
3.4 ATOM
Atom is an XML-based document format that describes lists of related information, known as feeds. Feeds are comprised of one or more entries, each with an extensible set of metadata. For example, each entry has a title.
Atom primarily addresses the syndication of web content, such as weblogs and news headlines, to websites and users.
Listing 4 shows a brief, single-entry, Atom feed document. The feed element is the root element of the aggregation. Metadata associated with the feed are represented by title, link, updated, author and id elements in the example. Feeds aggregate entries that are containers for information relating to one content element. Such entries correspond to IMS CP files, METS files, and MPEG-21 resources.
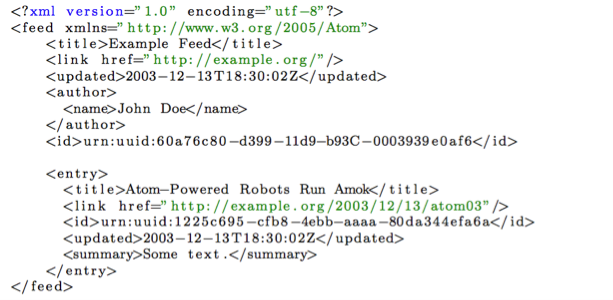
Listing 4: An Atom feed document
3.5 OAI-ORE
OAI-ORE defines standards for the description and exchange of aggregations of web resources. The OAI-ORE Atom is comprised of the followin elements:
- Aggregation refers to an aggregation of web resources. An aggregation has a URI that uniquely identifies the aggregation.
- Resource Map provides details about the aggregation. A resource map lists the resources that are parts of the aggregation, their interrelationships, and other properties. In addition, metadata describing the resource map can be included, such as modification date and author. A resource map is also assigned a URI.
- Proxy refers to an aggregated resource in a specific aggregation. This concept relates to an item in MPEG-21 and IMP CP and a div element in METS and represents an element in the resource map.
ORE supports serializations of Resource Maps in RDF/XML, RDFa and Atom. An example in Atom XML is shown in Listing 5.

Listing 5: A simple OAI-ORE document
4 RAMLET
Mappings between aggregation formats have been elaborated using different methods — including XSLT [10] and Perl scripts. RAMLET uses a Semantic Web approach in the form of a conceptual model to map between aggregation formats. The conceptual model describes the similarities of, and the relationships among, the components of the data models of various aggregation formats. It focuses on the structures of aggregation formats by analyzing and describing the characteristics of common structural elements, then abstracting and expressing them in ontological form as a core ontology.
4.1 Conceptual Model
To develop the conceptual model, the five aggregation formats, METS, MPEG-21 DID, OAI-ORE, Atom and IMS CP, were analyzed. The model was refined to avoid inconsistencies and then expressed as a core ontology. Mappings were then defined between the conceptual model and the aggregation formats and expressed as ontologies. These mappings are being published as IEEE recommended practices [2, 3, 4, 5, 6].
The conceptual model was first implemented in OWL and then expressed in human-readable tables in the IEEE standard. OWL was selected for use for formally expressing the structural concepts of the conceptual model and their interrelationships for the following reasons:
- OWL is an open specification.
- OWL allows the explicit expression of the relationships between components.
- OWL is part of a Semantic Web technology stack that was designed to deal with heterogeneous data.
- OWL is supported by readily available and well-developed tools, including open source tools that were available to the RAMLET Working Group.
A simplified version of the RAMLET model is presented in the first column of Table 1. This table presents concepts of RAMLET, and their corresponding concepts in existing standards and specifications. Relationships and constraints are not presented in the table. The ramlet:topNode class represents the root element of an aggregation. ramlet:descriptorObject is a wrapper for metadata, usually expressed using external standards. The distinction is made between administrative and descriptive metadata to represent the functional metadata segmentation of METS. Other subclasses of ramlet:descriptorObject define metadata elements that appear as XML attributes in the source representation of the resource aggregation formats. Because METS allows the most specific level of specification related to metadata, most metadata elements are derived from METS, including information regarding how the files were created and stored, intellectual property rights, and metadata regarding the original source object from which the aggregation derives. ramlet:generatingTool, ramlet:humanLanguage, ramlet:partyEmail, and ramlet:textType derive from Atom. ramlet:contentEncoding and ramlet:nodeVisibility derive respectively from MPEG-21 and IMS CP.
Classes for representing identifiers are defined for the aggregation (
ramlet:aggrega- tionID), local elements (
ramlet:elementID), and structural nodes (
ramlet:nodeID). A
ramlet:nodeID is a special kind of local identifier and can be found in METS.
ramlet:staticStructure represents the structure of the resource aggregation into a hierarchically arranged sequence of
ramlet:structureNodes.
ramlet:dynamicStructure and its subclasses describe a resource aggregation as being optional or available under conditions.
Table 1: A simplified version of RAMLET and corresponding mappings
| RAMLET |
IMS CP |
METS |
MPEG-21 |
Atom |
OAI-ORE |
| topNode |
manifest |
mets |
didl |
feed |
resourceMap |
| descriptorObject |
metadata |
mdWrap |
annotation; statement; descriptor |
category; term |
|
| administrativeDescriptorObject |
version |
amdSec |
|
|
|
| aggregationSchema |
schema |
profile |
schema |
|
|
| aggregationType |
|
metsType |
|
|
|
| alternateID |
|
ownerID; altRecordID |
|
|
|
| checksum |
|
checksum |
|
|
|
| checksumType |
|
checksumType |
|
|
|
| creationDate |
|
versDate; createDate; created |
|
Published |
|
| descriptiveDescriptorObject |
|
dmdSec |
|
summary; subtitle |
|
| descriptorTypeIndicator |
|
mdType; otherMdType |
|
scheme |
|
| encodingType |
|
|
encoding; contentEncoding |
|
|
| filesize |
|
size |
|
|
|
| generatingTool |
|
|
|
generator |
|
| humanLanguage |
language |
|
|
hRefLang |
|
| identiferType |
|
altRecordIDType |
|
|
|
| intendedUse |
|
use |
|
|
|
| modifiactionDate |
|
lastModDate |
|
updated |
|
| nodeVisibility |
isVisible |
|
|
|
|
| note |
|
note |
|
|
|
| party |
|
agent |
|
|
|
| provenance |
|
digiprovMD |
|
source |
|
| resourceProcessing |
|
transformFile; behavior |
|
|
|
| resourceType |
type |
|
|
|
|
| mimeType |
|
mimetype |
mimetype |
link.type |
|
| rights |
|
rightsMD |
|
rights |
|
| source |
|
sourceMD |
|
|
|
| status |
|
status; recordStatus |
|
|
|
| structureNodeType |
|
divType |
|
|
|
| technicalDescriptorObject |
|
techMD |
|
|
|
| textType |
|
|
|
content.type; text.type |
|
| wholeAggregationDO |
manifest.metadata |
metsHdr |
didlInfo |
|
|
| aggregateID |
|
objID |
didl-documentId |
id |
|
| elementID |
identifier |
ID |
identifier; targetID |
ID |
|
| nodeID |
|
contentIDs |
|
|
|
| digitalResource |
|
|
|
|
aggregatedResource |
| digitalResourceFragment |
|
|
fragment; anchor |
|
|
| staticStructure |
organizations |
structMap |
container |
|
|
| staticStructureType |
structure |
structMapType |
|
|
|
| staticStructureSet |
organizations |
|
|
|
|
| dynamicStructure |
|
|
container |
|
|
| dynamicStructureType |
|
btype |
|
|
|
| dynamicStructureID |
|
|
choiceId; selectId |
|
|
| assertion |
|
|
assertion |
|
|
| condition |
|
|
condition |
|
|
| choice |
|
|
choice |
|
|
| selection |
|
|
selection |
|
|
| maxSelections |
|
|
maxSelections |
|
|
| minSelections |
|
|
minSelections |
|
|
| defaultSelection |
default |
|
default |
|
|
| require |
|
|
require |
|
|
| except |
|
|
except |
|
|
| false |
|
|
false |
|
|
| true |
|
|
true |
|
|
| resourceProcessingSet |
|
behaviorSec |
|
|
|
| structureNode |
item |
div; fptr |
item |
|
proxy |
| anchor |
|
area |
anchor, fragment |
|
|
| anchorType |
|
beType; extType |
|
|
|
| beginPoint |
|
begin |
|
|
|
| componentTarget |
xPointer |
xptr |
|
|
|
| coordinates |
|
coords |
|
|
|
| endpoint |
|
end |
|
|
|
| extent |
|
extent |
length |
|
|
| shapeIndicator |
|
shape |
|
|
|
| stream |
|
stream |
|
|
|
| streamType |
|
streamType |
|
|
|
| groupingID |
|
groupID |
|
|
|
| hasOrder |
|
order; seq |
|
|
|
| transformOrdering |
|
transformOrder |
|
|
|
| hasRank |
|
|
precedence |
|
|
| icon |
|
|
|
icon; logo |
|
| inventory |
resources |
fileSec |
|
|
|
| locator |
hRef |
|
fragmentId; ref |
hRef; src |
|
| admRef |
|
admID |
|
|
|
| descriptiveRef |
|
dmID |
target |
|
|
| interfaceDefLink |
|
interfaceDef; mechanism |
|
|
|
| intraAggregationLink |
|
structLink |
|
|
|
| localRef |
identifierRef |
fileID |
|
|
|
| structRef |
|
structID |
|
|
|
| locatorDescriptor |
|
locType; otherLocType |
|
rel |
|
| parallel |
|
par |
|
|
|
| remoteNode |
iPointer |
|
|
|
|
| remoteDescriptorObject |
|
mdRef |
|
|
|
| remoteResource |
|
floCat |
|
|
|
| remoteTopNode |
|
mPtr |
|
|
|
| resourceAggregation |
|
|
|
|
aggregation |
| resourceGroup |
|
|
declarations |
|
|
| functionalResourceGroup |
resource |
fileGrp |
component |
|
|
| virtualResourceGroup |
dependency |
|
dependency |
|
|
| resourceWrapper |
|
binData; xmlData |
|
content |
|
| resourceWrapperSet |
|
fcontent |
|
content |
|
| fileDescriptor |
file |
file |
resource |
entry; link |
|
| title |
title |
label |
|
label; link.title; title |
|
| cardinalityLabel |
|
orderLabel |
|
|
|
4.2 Mappings
Mappings have been defined between the RAMLET model and IMS CP, METS, MPEG-21 DID, OAI-ORE and Atom. Table 1 summarizes these mappings.
cp:manifest, mets:mets, mpeg:DIDL, atom:feed and oai:resourceMap represent the root node of an aggregation and are mapped to ramlet:topNode. cp:metadata, mets:mdWrap, mpeg:annotation, mpeg:statement, mpeg:descriptor, and atom:category are wrappers for metadata and are mapped to the ramlet:descriptorObject class. If elements have similar semantics, such as mets:role and mets:otherRole, they are mapped to the same RAMLET class, in this case, ramlet:partyRole.
Mappings of the other elements proceed analogously. All the elements and attributes of IMS CP, METS, MPEG-21 DID, OAI-ORE, and Atom have been represented in the core RAMLET model and are mapped to their equivalent classes or subclasses. These mappings will be available as IEEE recommended practices.
4.3 Discussion
Ontology mappings defined by RAMLET are bidirectional, i.e., an IMS CP aggregation can be expressed using RAMLET terms and vice versa. To map resource aggregation instances from one aggregation format, such as IMS CP, to another, such as METS, two steps are required. First, a mapping is made from the IMS CP instance to the core ontology and then from the core ontology to the METS instance.
This approach can scale as the number of aggregation formats increases. To include a new aggregation format, such as RSS, only a bidirectional mapping between the core ontology and the new aggregation format would need to be expressed. Without the RAMLET conceptual model, instead of a single mapping from RSS to the core ontology, individual mappings from RSS to all other aggregation formats of interest would need to be developed (e.g., RSS to Atom, RSS to METS, RSS to MPEG-21 DID, etc.).
RAMLET provides an integrative conceptual model that covers IMS CP, MPEG-21 DID, METS, Atom, and OAI–ORE. Coverage of these aggregation formats implies that all data elements of these formats are represented in the conceptual model, which enables lossless transformation from the aggregation formats to the conceptual model. However, a potential loss of information exists when translating from an aggregation instance in one format to the core ontology and then to an aggregation instance in another format (e.g., METS to RAMLET to IMS CP), depending on the semantic overlap between the source and target aggregation formats. Although the transformation between resource aggregations is not always lossless, important structural relationships should be preserved, thus achieving a maximal preservation of meaning.
The core ontology can also be used to develop new aggregation formats, both because it records many of the components that have already been used in content aggregation, and — via the mappings — because it indicates how widely those components are used in existing formats. In addition, generalizations about how the various components relate to each other are captured by the core and mapping ontologies. Consequently, it is easier for communities to follow good practice and design new formats that stay within the bounds of the semantics of existing formats as much as possible, adding new functionality only where necessary.
Because the RAMLET core ontology and mappings have been formulated using standard Semantic Web technology, extensions to the ontologies can be easily accommodated by defining equivalence, refinement, inclusion, or any other relationship between the extensions and the existing ontology using OWL and other RDF vocabularies, such as RDF Schema (RDFS) and Simple Knowledge Organization Systems (SKOS).
When elements and attributes from schemas external to these aggregation formats have been used within them, such as xlink attributes, they have usually taken the form of object properties for associated RAMLET classes within each of the mappings.
5 Conclusion
In this paper, we have presented the RAMLET standard for structuring and exchanging resource aggregations. The standard enables implementers to assemble and structure resources and to export the resulting aggregations for use in IMS CP, METS, Atom, OAI-ORE, and MPEG-21 applications. In addition, aggregations available in different resource aggregation formats can be imported. Such interoperability is essential to enable sharing and reuse of multimedia resources on a global scale.
Previous attempts to enable such interoperability are limited to a crosswalk between IMS CP and METS, expressed in XSLT [10]. Such direct crosswalks cannot scale. If n is the number of resource aggregation formats, 2n transformation implementations are required for each new format to enable its interoperability with the other resource aggregation formats. RAMLET provides a generic approach that can scale as the number of resource aggregation formats increases, as only two transformation implementations are needed for a new format, one expanding RAMLET core, if necessary, and one mapping of the new aggregation format to RAMLET core.
The effort to create the RAMLET conceptual model was quite difficult at the beginning of the process until the working group came to agreement on the underlying principles to scope the work, and then came to agreement on an ontological approach to the expression of the conceptual model. While the latter decision was controversial at the time, it proved to be a pivotal decision for a number of reasons:
- The working group was able to developmentally build the conceptual model by allowing a focus upon one aggregation format at a time, then building on what had been previously done without starting from scratch for each new format;
- Collaborative development of the conceptual model was facilitated by allowing experts in each of the aggregation formats to initially express concepts expressed within "their" aggregation format by a common abstract framework that could be more easily questioned and refined by non-experts (in that aggregation format) and linguistic specialists;
- Each aggregation format could be expressed abstractly without regard to the rules of serialization in which it was expressed, e.g., both XML elements and XML attributes could be treated as simply classes without worrying about the XML rules for the relationships between them.
Because of the evolution of open source and web-based visualization tools for ontology creation (ultimately using Knoodl by Revelytix), the group was able to make significant progress without having each person develop expertise in any given software product.
The importance of a standard like RAMLET has been articulated by several researchers [13, 14, 15, 16] during the past decade. McDonough [16] indicates that:
"the strategy is to accept that the need for local community control over encoding practices is a valid one, that regional 'dialects' of markup languages are inevitable, and that we must find ways to facilitate information exchange across the boundaries of different communities' markup vernacular."
and
"the library community needs to shift from its current singular focus on schema development to a dual focus on both schema development and translation between schemas."
The RAMLET conceptual model currently covers IMS CP, METS, MPEG-21, OAI-ORE and Atom. Interesting future directions include extending the model for coverage of other aggregations formats, such as OASIS OpenDocument.
Finally, it is worth noting that the work presented in this paper has been standardized, but real world uptake is still in early stages. The conceptual transformations will need to be implemented and evaluated in a real world environment. Implementation options have been discussed by Kraan [12]. Evaluation of these options constitutes an important future line of research.
References
| [1] |
K. Blinco, L. Scott, N. Hoebelheinrich, W. Kraan and K. Verbert (eds). "IEEE Standard for Learning Technology — Conceptual Model for Resource Aggregation for Learning, Education, and Training", IEEE P1484.13.1™-2012. |
| [2] |
K. Blinco, L., Scott, N.J., Hoebelheinrich, W., Kraan, and K. Verbert (eds): 1484.13.2-2013 — IEEE Recommended Practice for Learning Technology — Metadata Encoding and Transmission Standard (METS) Mapping to the Conceptual Model for Resource Aggregation. |
| [3] |
K. Blinco, L., Scott, N.J., Hoebelheinrich, W., Kraan, and K. Verbert (eds): IEEE 1484.14.3 Recommended Practice for Learning Technology — ISO 21000-2:2005 Information Technology — Multimedia Framework (MPEG-21) — Part 2: Digital Item Declaration Mapping to the Conceptual Model for Resource Aggregation. |
| [4] |
K. Blinco, L., Scott, N.J. Hoebelheinrich, W. Kraan, and K. Verbert (eds): IEEE 1484.13.4 Recommended Practice for Learning Technology — IMS Content Packaging Information Model (CP) Version 1.2 — Mapping to the Conceptual Model for Resource Aggregation. |
| [5] |
K. Blinco, L., Scott, N.J., Hoebelheinrich, W., Kraan, and K. Verbert (eds): IEEE 1484.13.5 Recommended Practice for Learning Technology — IETF RFC 4287 — Atom Syndication Format — Mapping to the Conceptual Model for Resource Aggregation. |
| [6] |
K. Blinco, L., Scott, N.J., Hoebelheinrich, W., Kraan, and K. Verbert (eds): IEEE 1484.13.6 Recommended Practice for Learning Technology — Open Archives Initiative Object Reuse and Exchange Abstract Model (OAI-ORE) — Mapping to the Conceptual Model for Resource Aggregation. |
| [7] |
D. Greenstein and S. E. Thorin. "The Digital Library: A Biography". Washington, DC: Council on Library and Information Resources, Library of Congress, 2002. |
| [8] |
IEEE LTSC Working Group (2010). The RAMLET Project — Use cases. |
| [9] |
M.V. Cundiff. "An introduction to the Metadata Encoding and Transmission standard (METS)". Library Hi Tech, 22(1):52-64, 2004. http://doi.org/10.1108/07378830410524495 |
| [10] |
R. Yee and R. Beaubien. "A preliminary crosswalk from METS to IMS content packaging". Library Hi Tech, 22(1):69-81, 2004. http://doi.org/10.1108/07378830410524512 |
| [11] |
J. Bekaert. "Standards-based interfaces for Harvesting and Obtaining assets from Digital Repositories". PhD Thesis, Ghent University, April 25th 2006. PhD Advisors: Mil De Kooning and Herbert Van de Sompel |
| [12] |
W. Kraan. "RAMLET implementation study report", JISC-CETIS technical report, August 2008. |
| [13] |
D. Sloan, A. Heath, F. Hamilton, B. Kelly, H. Petrie, L. Phipps. "Contextual web accessibility-maximizing the benefit of accessibility guidelines". In Proceedings of the 2006 international cross-disciplinary workshop on Web accessibility, pp. 121-131, ACM, 2006. http://doi.org/10.1145/1133219.1133242 |
| [14] |
K. Fertalj, N. Božić-Hoić, H. Jerković. "The integration of learning object repositories and learning management systems". Computer Science and Information Systems, 7(3), 387-407, 2010. http://doi.org/10.2298/CSIS081127001F |
| [15] |
M. Meyer, C. Rensing, R. Steinmetz. "Multigranularity reuse of learning resources". ACM Transactions on Multimedia Computing, Communications, and Applications (TOMCCAP), 7(1), 1, 2011. http://doi.org/10.1145/1870121.1870122 |
| [16] |
J. McDonough. "Structural Metadata and the Social Limitation of Interoperability: A Sociotechnical View of XML and Digital Library Standards Development." In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). http://doi.org/10.4242/BalisageVol1.McDonough01 |
About the Authors
 |
Katrien Verbert is an Assistant Professor at the HCI research group of KU Leuven. She obtained a doctoral degree in Computer Science in 2008 at KU Leuven, Belgium. She was a post-doctoral researcher of the Research Foundation — Flanders (FWO) at KU Leuven. The fellowship was interrupted for two years for Assistant Professor positions at TU Eindhoven, the Netherlands (1 Jan. 2013 - 31 December 2013) and the Vrije Universiteit Brussel, Belgium (1 January 2014 - 31 January 2015). Her research interests include learning analytics, visualisation techniques, recommender systems for learning and digital humanities. She has been involved in several European and Flemish projects on these topics, including the EU FP7 ROLE and STELLAR projects. She was also involved in the organisation of several conferences and workshops (program co-chair EC-TEL 2016, workshop co-chair EDM 2015, program co-chair LAK 2013 and program co-chair of the RecSysTEL workshop series).
|
 |
Nancy J. Hoebelheinrich is a digital library, archives and data repository consultant specializing in Metadata and Content Management for geospatial and cultural heritage resources. Nancy is currently founder and owner of Knowledge Motifs LLC whose recent clients have included the Foundation for Earth Science, the American Geophysical Union, the California Historical Society, the California Digital Library, the Library of Congress, and Stanford University Libraries. Nancy has been active in a number of information and educational technology specification efforts including that of the ESIP Federation's Data Stewardship Committee, and Semantic Web Cluster, METS (Metadata Encoding and Transmission Standard), PREMIS (for preservation metadata), IMS Global specifications related to packaging, repository and resource list interoperability, digital rights expression and management, and the IEEE Learning Technology Standards Committee's RAMLET project.
|
 |
Kerry Blinco is the Assistant Director Digital Initiatives at the Northern Territory Library. Throughout a varied career in ICT in libraries and learning she has utilised the power of standards to provide innovative systemic opportunities to support service strategies. Kerry is currently a member of Standards Australia IT-19 and Chairs the IEEE LTSC WG-13 (RAMLET) Working Group. She has been a member of ISO, OASIS and IMS Global standards committees.
|
 |
Scott Lewis is a technical editor and writer from Austin, Texas. He has specialized in computer-based learning standards and documentation primarily related to portability and interoperability.
|
 |
Wilbert Kraan joined Cetis in 2002 as the Cetis Journalist. From there, he entered specification development work, starting with IMS where he became the chair of the Content Packaging 1.2 group. That specification is now an ISO standard. Wilbert has also worked on software architectures, first in an international partnership. Later, he moved into Enterprise Architecture modelling, and was instrumental in introducing the ArchiMate Modelling language to the UK higher education sector. More recently, Wilbert has championed the IMS Question and Test Interoperability 2.1 specification. Wilbert has also worked in a number of data integration projects and specifications.
|