A Brief Update on the Alexandria Digital Library Project
Constructing a Digital Library for Geographically-Referenced
Materials
Contributed by:
Terence R. Smith
Professor of Computer Science
Professor of Geography
University of California, Santa Barbara
Director, Alexandria Digital Library Project
smithtr@cs.ucsb.edu
D-Lib Magazine, March 1996
ISSN 1082-9873
Introduction
The goal of the Alexandria Project Digital Library (ADL) is to
build a distributed digital library (DL) for geographically-referenced
materials. A central function of ADL is to provide users with
access to a large range of digital materials, ranging from maps
and images to text to multimedia, in terms of geographical reference.
An important type of query is ``What information is there in the
library about some phenomenon at a particular set of places?''.
From the Internet, both users and librarians can access various
components of ADL, such as its catalog and collections, through
powerful, graphical interfaces without having to know where these
different components are located on the Internet.
Approach
The main aspect of ADL's strategic approach involves:
1. A focus upon access to the many classes of collection items,
including non-traditional items, by geographical reference;
2. The development of the user interface (UI) and catalog components
of the DL architecture;
3. Accessibility to the ADL catalog and collections via the Internet
for a wide variety of users;
4. Close interaction and interoperability with other DL activities
by way of Internet-related technologies;
5. A process of incremental,
evolutionary design and implementation of ADL that takes advantage
of critical technological developments, and especially Internet-related
technologies; and
6. Digitally-supportable extensions to traditional library functionality.
In particular, the transitions from our initial stand-alone rapid
prototype (RP) in early 1995, to our first World Wide Web prototype
(WP) in late 1995, to our publicly-available testbed in mid-1996,
to our million-item operational library in mid-1997, are being
made in incremental steps that build upon each other and upon
a basic four-component architecture. This architecture involves:
(1) user interface components that support graphic and text-based
access to the other ADL components and services; (2) a distributed
catalog component that metadata and search engines permitting
users to identify holdings of interest; (3) a distributed storage
component containing the digital holdings; and (4) an ingest component
allowing librarians to store new holdings, extract metadata from
the holdings, and add metadata to the catalog.
A variety of technologies being applied and developed in each
of the four components. The graphical/geographical interface is
supported by a variety of Internet-related technologies, such
as browsers and programmable browsers. Access to the holdings
is by way of a catalog component that supports spatially-based
metadata models and content-based search techniques. Currently,
such techniques employ gazetteers for map documents and texture
features for image documents. Browsing and the delivery of large
items is supported by progressive delivery techniques based on
wavelet technology. The high-performance servers that support
the library operation are being based in part on approaches that
involve parallel computing.
Progress
The research and development in our first cycle activity, lasting
six months, yielded a stand-alone rapid prototype (RP) testbed
library, which was based on commercial database management systems
and geographic information system technology. The RP was distributed
for evaluation by major users as a CD-ROM.
The research and development in our second cycle of activity,
lasting six months, led to a ``Web prototype'' (WP) testbed library
accessible from the World Wide Web (WWW), but with current accessibility
limited to a small number of major users and project partners.
This system involved the development of a complex WWW interface,
a catalog for metadata, and the preliminary applications of research
results relating to image processing and parallel computing technologies.
Conceptually, the WP UI is a collection of HTML "pages"
implementing three major search capabilities: map browsing; gazetteer
queries; general catalog queries.
As well as control/configuration and help/glossary links, the
user interface (UI) is designed around a state transition model
with each state representing a WWW form or page, some of which
include partial or complete query results. The HTML code for the
WP UI is generated dynamically by approximately 15K lines of Tcl
code running in a NaviServer HTTP server.
The primary function of the both the map browser and the gazetteer
pages is to allow the user to define spatial extents or regions
for catalog searches. The map browser allows these search regions
to be defined explicitly (by zooming and panning a base map),
while the gazetteer defines them implicitly (as the footprints
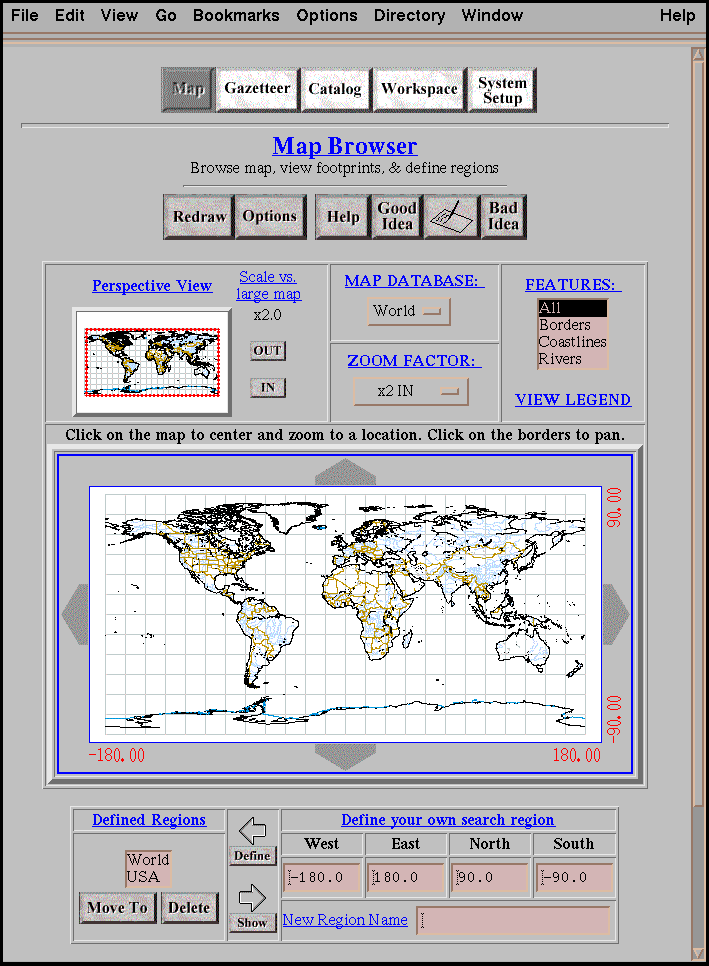
corresponding to place names and feature types.) Figure 1 shows
a screen dump of the map browser.
The visible portion of the map browser's base map (the display
window) is the default search footprint (the query window), but
this relationship can be modified (e.g., the user may specify
a subset of the display window, or may direct that the display
window be completely ignored.) The base map is also the background
on which the gazetteer and catalog query result footprints are
drawn. The base map images are dynamically generated by a Common
Gateway Interface (CGI) application based on the Xerox PARC Map
Viewer [http://www.parc.xerox.com/map/],
which we have modified to support generic labeling, fast panning, and graphic overlays.
Figure 1: The map browser component of the interface.

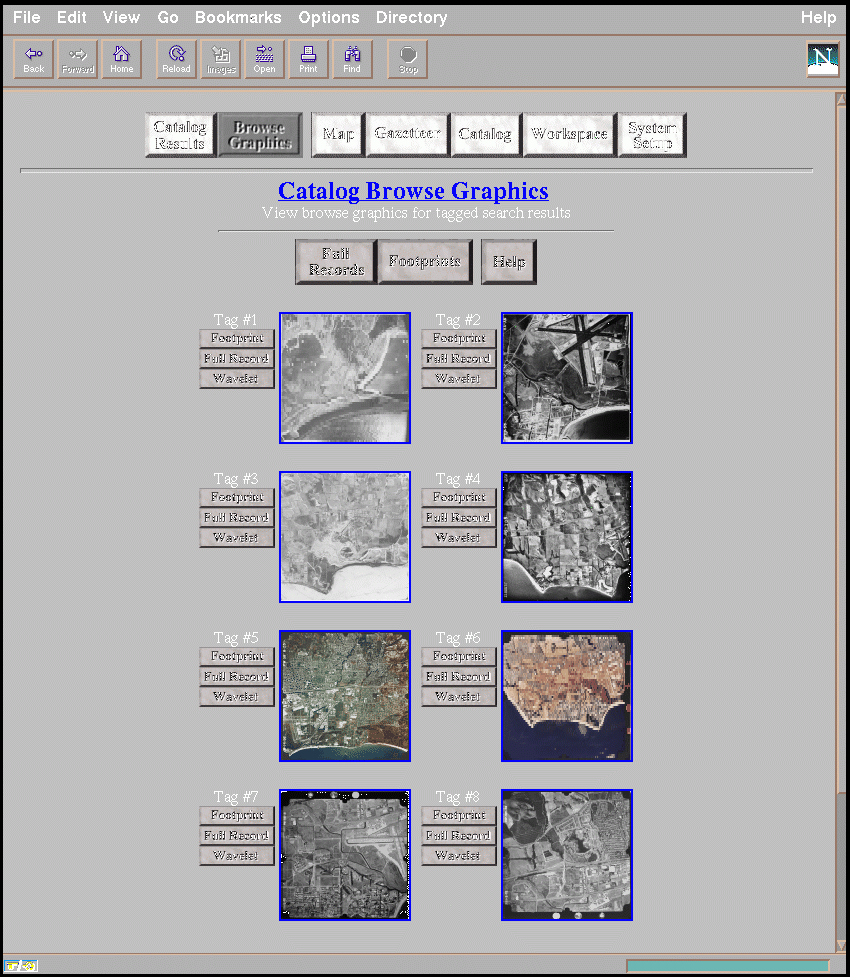
Figure 2: The browse graphic display returned from a query.
Gazetteer queries may interact with the map browser. For example,
if the current map browser query window contains the USA but not
Europe, then a gazetteer query with the place name set to "Paris"
(and the query window enabled) will return Paris, Texas but not
Paris, France. The map browser, in turn, may be directed to reset
the query window to the minimum bounding geographic rectangle
for the gazetteer query results.
Query windows resulting from gazetteer-map browser interactions
are ultimately passed to the catalog page for incorporation into
catalog queries. In addition to geographic footprints, the catalog
page allows the user to search against any of the metadata fields
(such as theme, time, or author) in the ADL catalog, expressed
as textual or numeric values.
Catalog queries are assembled from user input into a generic conjunctive
normal form (CNF) representation, and then translated to the specific
query language (currently SQL) of the catalog DBMS . Query results
are converted to HTML tables, with hyperlinks to browse images
and on-line holdings. Query results are presented incrementally,
with a subset of the metadata fields displayed initially and complete
fields subsequently displayed for user-selected holdings. The
format and fields used in the query results are completely user-configurable.
Queries may also return the footprints of ADL holdings, which
may be displayed on the map browser base map. Unfortunately, it
is common for many more footprints to be returned from a catalog
query than can be shown intelligibly on the map browser's relatively
small display. When footprints of multiple data holdings are displayed
on the same map, it is difficult to distinguish which footprint
is associated with which item. We continue to experiment with
heuristics and visual aids (such as clustering and labeling) for
disambiguating "crowded" footprints. In Figure we show
examples of the browse graphics that may be returned as the partial
results of a query.
The WP UI stores all user configuration parameters, query statements,
and current query result sets in a separate (from the catalog)
database maintained by the NaviServer HTTP server. This state
information may also be stored on request on the client side in
"hidden" HTML form variables. This allows a user to
save an ADL "session" by using the browser's save-page
feature. The session may be restored by reloading the saved page.
Otherwise, state maintenance is handled entirely by the server,
with only a minimal opaque handle used on the client side to identify
the current session.
The WP is proving to be an excellent model for the testbed libraries
that we are currently developing, and for an operational library
that we are now designing. The main goal of the current cycle
is to make the testbed accessible to anyone with a WWW connection
by mid-1996. This involves developing major collections of DL
documents and servers with appropriate power. A goal of the next
cycle will be to construct an operational library of over a million
items by mid-1997.
Recent Accomplishments
Recent accomplishments include the following:
1. Distribution of CD-ROM of rapid prototype of ADL, which
is being tested and evaluated by many data users/producers.
2. Design and implementation of a web prototype of ADL, which
is a system accessible from WWW and is being tested by variety
of agencies.
3. Design and construction of metadata schema for ADL, which
is based on FGDC/USMARC and is being used by several organizations.
4. Implementation of content-based retrieval in ADL, involving
access to digitized maps by named earth surface feature and access
to digitized images by named texture feature.
5. Implementation of progressive browsing and delivery of
images.
6. Development of parallel servers based on multicomputers.
Plans
Our plans include the following:
1. Creation of a testbed accessible to anyone from the WWW, available by mid-1996
which provides access to significant collections.
2. The design and construction of a new component of the ADL interface
that is based on a multi-level ``Alexandria Atlas'' and that supports
graphical/geographical access to many classes of documents by
geographic reference.
3. The design and implementation of advanced models of geographical
access using complex and fuzzy geographic footprints.
4. The development of a general model of metadata and a catalog
based on this model that integrates many forms of metadata.
5. The development of significant collections of maps, images,
and text with the aim of having a million-item, operational library
by mid-1997.
6. Interoperability with other DLs (University of California, Berkeley; Stanford University; University of
Illinois, Urbana-Champaign).
7. Significant extensions of content-based search functionality
based on gazetteers, and image texture, color, and multispectral
images.
8. Support for a high-performance library based parallel computing
technology.
Technology Transition, Sharing, and Partnering
We are developing our catalog and metadata component in close
cooperation with a variety of partners, including CIESIN, Central
Imagery Office, ERDAS, ESRI, Hughes, Library of Congress, NASA,
Oracle, USGS, and US Navy. We are sharing the metadata schema
that we developed with various groups (e.g. CIESIN). We are making
our testbed facilities available to various organizations facing
a need to store their collections in publicly-accessible form
(e.g. Sierra Nevada Ecology Project, Mojave Desert Ecosystem Project).
We are providing versions of our system for testing purposes in
the applications of cooperating partners (e.g. USGS).
We are interacting closely with three of the DLI projects in developing
interoperable libraries, and sharing our expertise in spatially-indexed
information.
To date, the most significant event in the development of the
Alexandria Digital Library has been the construction of a WWW-accessible
prototype. This prototype integrated acceptable versions of all
four basic components (interface, catalog, storage, and ingest)
and employed significant image-processing and parallel processing
technology. The system is currently being tested by various partners
and is the basis for the publicly-accessible testbed system
that is currently under development and that will be made available
in mid-1996.
For further information, see http://alexandria.sdc.ucsb.edu
Acknowledgements
The Alexandria Digital Library Project is a consortium of universities, public institutions, and private
corporations headed by the University of California at Santa Barbara, and supported by NSF, ARPA, and
NASA under cooperative agreement NSF IRI94-11330.
Copyright © 1996 Terence R. Smith


 hdl://cnri.dlib/march96-smith
hdl://cnri.dlib/march96-smith