|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
William Y. Arms Manuel Calimlim Lucia Walle |
![]()
|
EScience is a popular topic in academic circles. As several recent reports advocate, a new form of scientific enquiry is emerging in which fundamental advances are made by mining information in digital formats, from datasets to digitized books [1][2]. The arguments are so persuasive that agencies such as the National Science Foundation (NSF) have created grant programs to support eScience, while universities have set up research institutes and degree programs [3][4]. The American Chemical Society has even registered the name "eScience" as a trademark. Yet behind this enthusiasm there is little practical experience of eScience. Most of the momentum comes from central organizations, such as libraries, publishers, and supercomputing centers, not from research scientists. For instance, the international Digging into Data Challenge has a set of readings on its home page [5]. All are enthusiastic about data-driven scholarship, but only one of them reports on practical experience, and it describes how central planning can be a barrier to creativity [6]. In this article we describe our experience in developing the Cornell Web Lab, a large-scale framework for eScience based on the collections of the Internet Archive, and discuss the lessons that we have learned in doing so. Sometimes our experience confirms the broad views expressed in the planning papers, but not always. This experience can be summarized in seven lessons:
Lesson 1: Build a laboratory, then a libraryThe Cornell Web Lab is not a digital library. It is a laboratory for researchers who carry out computationally intensive research on large volumes of web data. Its origins are described in [7] and the preliminary work in building it in [8]. When we began work on the Web Lab, we expected to build a research center that would resemble a specialized research library. The center would maintain selected web crawls and an ever-expanding set of high quality software tools. Everything would be carefully organized for large numbers of researchers. Most eScience initiatives follow this approach. In developing services for eScience and eSocial science, the instinct is to emphasize high quality, in both collections and services. Agencies such as the NSF have seen too many expensive projects evaporate when grants expired. Therefore, they are looking for centers that will support many researchers over long periods of time. The DataNet solicitation from the NSF's Division of Cyberinfrastructure is an example of a program with stringent requirements for building and sustaining production archives [9]. This is a high risk strategy. All libraries are inflexible and digital libraries are no exception. They require big investments of time and money, and react slowly to changing circumstances. The investments are wasted if the plans misjudge the research that will be carried out or are bypassed by external events. In contrast, in a laboratory such as the Web Lab, if new ideas or new opportunities occur, plans change. Rough edges are the norm, but the collections and services are flexible in responding to new research goals. The Web Lab does not provide generic services for large numbers of researchers; it gives personalized support to individuals. Most of the funds received from the NSF are used for actual research, including support for doctoral students and postdoctoral fellows. The NSF gets an immediate return on its money in the form of published research. As an example of how research interests change, when we began work on the Web Lab, we interviewed fifteen people to find how they might use the collections and services. One group planned to study how the structure of the web has changed over the years. This is a topic for which the Internet Archive collections are very suitable. But the development of the Web Lab coincided with the emergence of social networking on the web, commonly known as Web 2.0. The group changed the thrust of their research. They are now using web data to study hypotheses about social networks. For this new research they need recent data covering short time periods; links within pages are more important than links between pages. The Internet Archive datasets are less suitable for this work, but this group has used the other facilities of the Web Lab heavily. (As an example of their work, see [10].) Lesson 2: For sustainability, keep the number of staff smallFinancial sustainability is the Achilles' heel of digital libraries. While it is comparatively easy to raise money for innovation, few organizations have long-term funding to maintain expensive collections and services. The success stories stand out because they are so rare. The efforts of the National Science Digital Library are typical. The program has studied its options for a decade without finding a believable plan beyond continued government support [11]. Part of the sustainability problem is that a digital library can easily become dependent on permanent employees. If there is a gap in funding, there is no money to pay these people and no way to continue without them. Supercomputing centers suffer from the same difficulties: large staffs and high fixed costs. Almost by accident, the Web Lab has stumbled on a model that minimizes the problems of sustainability. Its development has been made possible by NSF grants, but is does not need large grants to keep going. The Web Lab budget can and will fluctuate, depending on the number of researchers who use it and their ability to raise money. There may even be periods when there is no external support. But the base funding that is needed to keep the lab in existence is minimal. There are no full time employees to be paid. Undergraduates and masters students have done much of the development. The equipment has a limited life, but the timing of hardware purchases can be juggled to match funding. The computers are administered by Cornell's Center for Advanced Computing, which provides a fee based service, currently about $25,000 per year. So long as these bills are paid, the lab could survive a funding gap of several years. Lesson 3: Extract manageable sub-collectionsThe data in the Web Lab comes from the historical collection of the Internet Archive [12]. The collection, which has over 1.5 billion pages, includes a web crawl made about every two months since 1996. It is a fascinating resource for social scientists and for computer scientists. The primary access to the collection is through the Internet Archive's Wayback Machine, which provides fast access to individual pages. It receives about 500 requests per second. Many researchers, however, wish to analyze large numbers of pages. For this they need services that the Wayback Machine does not provide. The initial goal of the Web Lab was to support "web-scale" research, looking for patterns across the entire web and seeing how these patterns change over time. To satisfy this need, four complete web crawls have been downloaded from the Internet Archive, one from each year between 2002 and 2005. These four crawls are summarized in Table 1.
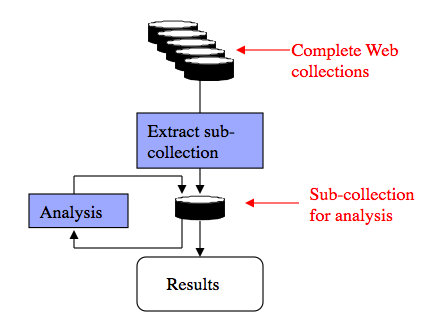
Table 1. Four web crawls In practice, we have found that few people carry out research on the entire web. Most researchers do detailed analysis on sub-collections, not on complete crawls. For example, one group is studying how the US Government web sites (the .gov domain) evolved during the period 2002 to 2005. Another group wanted all pages from 2004 that referenced a certain drug. The research process is summarized in Figure 1.
To extract sub-collections from the four web crawls listed in Table 1, we have built a relational database with basic metadata about the web pages and the links between them. Table 2 lists some of the tables in the database and the numbers of records in each. Notice that the link table contains all the links from every page, so that this data can be used for analysis of the link structure of the web. The database is mounted on a dedicated server, with four quad processors, 128 GB memory, and 159 TB disk. The total size of the database and indexes is 54 TB.
Table 2. Records in the Web Lab database While the underlying collections are large, the sub-collections used for research are much smaller, rarely more than a few terabytes. The standard methodology is to use the database to identify a sub-collection defined by a set of pages or a set of links, and download it to another computer for analysis. For most analyses, researchers do not need supercomputers. Lesson 4: Look beyond the academic communityThe academic community has limited capacity to develop and maintain the complex software used for research on large collections. Therefore we must be cautious about where we place our efforts and flexible in adopting software from other sources. Until recently, relational databases were the standard technology for large datasets, and they still have many virtues. The data model is simple and well understood; there is a standard query language (SQL) with associated APIs; and mature products are available, both commercial and open source. But relational databases rely on schemas, which are inherently inflexible, and need skilled administration when the datasets are large. Large databases require expensive hardware. For data-intensive research, the most important recent development is open source software for clusters of low cost computers. This development is a response to the needs of the Internet industry, which employs programmers of varying expertise and experience to build very large applications on clusters of commodity computers. The current state of the art is to use special purpose file systems that manage the unreliable hardware, and the MapReduce paradigm to simplify programming [13][14]. While Google has the resources to create system software for its own use, others, such as Yahoo, Amazon, and IBM, have combined to build an open source suite of software. The Internet Archive is an important contributor. For the Web Lab, the main components are:
Hadoop did not exist when we began work on the Web Lab, but encouragement from the Internet Archive led us to track its development. In early 2007 we experimented with Nutch and Hadoop on a shared cluster and in 2008 established a dedicated cluster. It has 60 computers, with totals of 480 cores, 960 GB memory, and 270 TB of disk. The full pages of the four complete crawls are being loaded onto the cluster, together with several large sets of link data extracted from the Web Lab database. This cluster has been a great success. It provides a flexible computing environment for data analysis that does not need exceptional computing skills. Several projects other than the Web Lab use the cluster, and it was recently used for a class on Information Retrieval taken by seventy students. Lesson 5: Expect researchers to understand computing, but do not require them to be expertsPeople are the critical resource in data-intensive computing. The average researcher is not a computer expert and should not need to be. Yet, at present, every research project needs skilled programmers, and their scarcity limits the rate of research. Perhaps the greatest challenge in eScience and eSocial science is to find ways to carry out research without being an expert in high-performance computing. Typical researchers are scientists or social scientists with good quantitative skills and reasonable knowledge of computing. They are often skilled users of packages, such as the SAS statistical package. They may be comfortable writing simple programs, perhaps in a domain specific language such as MatLab, but they are rightly reluctant to get bogged down in the complexities of parallel computing, undependable hardware, and database administration. In the Web Lab, we have used three methods for researchers to extract and analyze data: (a) Web based user interfaces
(b) Packages and applications
(c) End user programming
If eScience and eSocial science are to be broadly successful, researchers will have to do most of their own computing, but some tasks will still require computer experts. Every year computers get bigger, faster, and cheaper. Yet every year there are datasets that strain the limits of available computer power. As that limit is approached, everything becomes more difficult. In the Web Lab, tasks that need high levels of expertise include the transfer of data from the Internet Archive to Cornell, extraction of metadata, removal of duplicates, the construction of the relational database, and the tools for extracting groups of pages from complete web crawls. These are all heavily data intensive and stretch the capacity of our hardware. Individual tasks, such as duplicate removal or index building, can run for days or even weeks. Experts are needed, but projects do not need to hire large numbers of programmers. The Web Lab has managed with a very small professional team. The authors of this paper are: a faculty member who has supervised most of the students, a programmer who is an expert in relational databases, and a systems programmer with extensive experience in large-scale cluster computing. All are part time. Most of the work has been done by computer science students, as independent research projects. Their reports are on the web site [20]. Some of the reports are disappointing, but others are excellent. This is an inefficient way to develop production-quality software, but provides a marvelous educational experience for the students. More than sixty of them are now in industry, mainly in technical companies, such as Google, Yahoo, Amazon, and Oracle. Lesson 6: Seek generalities, but beware the illusion of uniformityBecause so much of the vision of eScience has come from central organizations, there is a strong desire to seek for general solutions. The names "eScience" and "Cyberscholarship" might imply that there is a single unified field, but this uniformity is an illusion. Terms such as "workflow", "provenance", "repository", and "archive" do not have a single meaning, and the search for general approaches tends to obscure the very real differences between subject areas. Workflow provides a good example. Any system that handles large volumes of data must have a process for managing the flow of data into and through the system. For the Web Lab, a series of student projects has developed such a workflow system [21]. This manages the complex process of downloading data from the Internet Archive, making back-up copies at Cornell, extracting metadata, and loading it into the relational database. But every workflow system is different. In [22], we compare three examples, from astronomy, high-energy physics, and the Web Lab. Each project uses massive data sets, and the three workflows have some superficial similarities, but otherwise they have little in common. While there is a danger of wasting resources by building general purpose tools prematurely, once an area becomes established it is equally wasteful not to create standard tools for the common tasks. The Web Lab is currently in the process of converting some of its programs into an open source application suite for research on Web graphs. This suite has the following components. (a) Control program
(b) Data cleaning
(c) Programs for analysis of graphs
Lesson 7: Keep operations local for flexibility and expertiseData-intensive computing requires very large datasets and large amounts of computing. Any eScience project has to decide where to store the data and where to do the computation. Superficially, the arguments for using centralized facilities are appealing. Cloud computing is more than a fashion. The commercial services are good and surprisingly cheap. For instance, a Cornell computer science course has been using Amazon's facilities for the past two years with great success. The NSF is pouring money into supercomputing centers, some of which specialize in data-intensive computing. It is easy to be seduced by the convenience of cloud computing and supercomputing centers, but the arguments for local operations are even stronger. When a university research group uses a remote supercomputer, a small number of people become experts at using that system, but the expertise is localized. With local operations, expertise diffuses across the organization. If a university wishes to be an intellectual leader, it needs the insights that come from hands-on experience. Here are some of the benefits that the Web Lab's local operations have brought to Cornell.
Local control brings flexibility. When an Information Retrieval class wanted to use the cluster for an assignment, nobody had to justify the use of the lab; there was expertise at hand to write special documentation; researchers were asked to minimize their computing during the week that the assignment was due; the system administrator installed a new software release to support the class; and there was collective experience to troubleshoot problems that the students encountered. For data-intensive computing, the common wisdom is that it is easier to move the computation to the data rather than the data to the computation, but bulk data transfers are not difficult. One way to move data over long distances is to load it onto disk drives and transport them by freight. This approach has been used successfully both by the Internet Archive to move huge volumes of data internationally, and by colleagues who move data from the Arecibo telescope in Puerto Rico to Cornell. For the Web Lab, the Internet Archive persuaded Cornell to use the Internet for bulk data transfer, in order to minimize the staff time that would have been needed to locate and copy data that is distributed across thousands of servers. The Web Lab has been a test bed for data transfer over the high-speed national networks and our experience has proved helpful to the Internet Archive. One of the benefits of local operations is that the legal and policy issues are simplified. Most large data sets have questions of ownership. Many have privacy issues. These are much easier to resolve in local surroundings, where each situation can be examined separately. In the Web Lab, the underlying data comes from web sites. The Internet Archive is careful to observe the interests of the copyright owners and expects us to do so too. In permitting Cornell to download and analyze their data, the Internet Archive is dealing with a known group of researchers at a known institution. They know that universities have organizational structures to protect restricted data, and that privacy questions are overseen by procedures for research on human subjects. Recently, several of the Internet corporations have made selected datasets and facilities available for research. For example, Google and IBM have a joint program, which is supported by the NSF [27]. These programs are much appreciated, but inevitably there are legal restrictions that reduce the flexibility of the research. It easier to carry out research on your local computers, with locally maintained datasets. AcknowledgementsThis work would not be possible without the forethought and longstanding commitment of the Internet Archive to capture and preserve the content of the Web for future generations. This work is funded in part by National Science Foundation grants CNS-0403340, SES-0537606, IIS 0634677, IIS 0705774, and IIS 0917666. The computing facilities are based at the Cornell Center for Advanced Computing. Much of the development of the Web Lab has been by Cornell undergraduate and masters students. Details of their work are given in the Web Lab Technical reports: <http://www.infosci.cornell.edu/weblab/publications.html>. As a footnote, it is interesting to list the nationalities of the faculty, students, and staff who have worked on this project. Here is the list for the people whose nationality is known: Bangladesh, Great Britain, China, Germany, India, Korea, Lebanon, Mexico, New Zealand, Pakistan, the Philippines, Poland, Russia, Saudi Arabia, Taiwan, Turkey, Venezuela, and the United States. References[1] William Arms and Ronald Larsen (editors). The Future of Scholarly Communication: Building the Infrastructure for Cyberscholarship. NSF/ JISC workshop, Phoenix, Arizona, April 2007. <http://www.sis.pitt.edu/~repwkshop/SIS-NSFReport2.pdf>. [2] Amy Friedlander (editor). Promoting Digital Scholarship: Formulating Research Challenges in the Humanities, Social Sciences and Computation. Council on Library and Information Resources, 2008. <http://www.clir.org/activities/digitalscholar2/index.html>. [3] See, for example, the University of Washington eScience Institute. <http://escience.washington.edu/>. [4] See, for example, the M.Sc. in eScience at the University of Copenhagen. <http://www.science.ku.dk/uddannelser/kandidat/eScience/>. [5] Digging into Data Challenge. <http://www.diggingintodata.org/>. [6] Venter, Craig. Bigger faster better. Seed, November 20 2008. <http://seedmagazine.com/stateofscience/sos_feature_venter_p1.html>. [7] William Arms, Selcuk Aya, Pavel Dmitriev, Blazej Kot, Ruth Mitchell, and Lucia Walle. A research library based on the historical collections of the Internet Archive. D-Lib Magazine, 12 (2), February 2006. <doi:10.1045/february2006-arms>. [8] William Arms, Selcuk Aya, Pavel Dmitriev, Blazej Kot, Ruth Mitchell, and Lucia Walle. Building a research library for the history of the Web. ACM/IEEE Joint Conference on Digital Libraries, 2006. <http://www.cs.cornell.edu/wya/papers/Arms2006a.doc>. [9] National Science Foundation. Sustainable Digital Data Preservation and Access Network Partners (DataNet). 2008. <http://www.nsf.gov/pubs/2007/nsf07601/nsf07601.htm>. [10] D. Crandall, L. Backstrom, D. Huttenlocher, and J. Kleinberg. Mapping the World's Photos. WWW 2009 (forthcoming). <http://www.cs.cornell.edu/~crandall/papers/mapping09www.pdf>. [11] Paul Berkman. Sustaining the National Science Digital Library. Project Kaleidoscope, 2004. <http://www.pkal.org/documents/Vol4SustainingTheNSDL.cfm>. [12] The Internet Archive's home page and the Wayback Machine are at: <http://www.archive.org/>. [13] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google File System. 19th ACM Symposium on Operating Systems Principles, October 2003. <http://doi.acm.org/10.1145/945445.945450>. [14] Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. Usenix SDI '04, 2004. <http://www.usenix.org/events/osdi04/tech/full_papers/dean/dean.pdf. [15] For information about Apache Hadoop see: <http://hadoop.apache.org/>. [16] The Lucene family of search engines is part of the Apache Jakarta project: <http://lucene.apache.org/>. [17] Heritrix is the Internet Archive's open source web crawler: <http://crawler.archive.org/>. [18] Wioletta Holownia, Michal Kuklis, and Natasha Qureshi. Web Lab Collaboration Server and Web Lab Website. May 2008. <http://www.infosci.cornell.edu/weblab/papers/Holownia2008.pdf>. [19] Felix Weigel, Biswanath Panda, Mirek Riedwald, Johannes Gehrke, and Manuel Calimlim. Large-Scale Collaborative Analysis and Extraction of Web Data. Proc. 34th Int. VLDB Conf., 2008. pp. 1476-1479. [20] The Web Lab technical reports are at <http://www.infosci.cornell.edu/weblab/publications.html>. [21] Andrzej Kielbasinski. Data Movement and Tracking, Spring 2007 Report. May 2007. <http://www.infosci.cornell.edu/weblab/papers/Kielbasinski2007.pdf>. [22] W. Arms, S. Aya, M. Calimlim, J. Cordes, J. Deneva, P. Dmitriev, J. Gehrke, L. Gibbons, C. D. Jones, V. Kuznetsov, D. Lifka, M. Riedewald, D. Riley, A. Ryd, and G. J. Sharp. Three Case Studies of Large-Scale Data Flows. Proc. IEEE Workshop on Workflow and Data Flow for Scientific Applications (SciFlow). 2006. [23] Vijayanand Chokkapu and Asif-ul Haque. PageRank Calculation using Map Reduce. May 2008. <http://www.infosci.cornell.edu/weblab/papers/Chokkapu2008.pdf>. [24] J. Kleinberg. Authoritative sources in a hyperlinked environment. Journal of the ACM, Vol. 46, No. 5, September 1999, pp. 604-632. [25] Xingfu Dong. Hubs and Authorities Calculation using MapReduce. December 2008. <http://www.infosci.cornell.edu/weblab/papers/XingfuDong2008.pdf>. [26] Jacob Bank and Benjamin Cole, Calculating the Jaccard Similarity Coefficient with Map Reduce for Entity Pairs in Wikipedia. December 2008. <http://www.infosci.cornell.edu/weblab/papers/Bank2008.pdf>. [27] National Science Foundation. CISE – Cluster Exploratory (CluE). 2008. <http://www.nsf.gov/cise/clue/>. Copyright © 2009 William Y. Arms, Manuel Calimlim, and Lucia Walle |
||||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/may2009-arms
|