 |
D-Lib Magazine
May/June 2015
Volume 21, Number 5/6
Table of Contents
Semantic Description of Cultural Digital Images: Using a Hierarchical Model and Controlled Vocabulary
Lei Xu
Wuhan University, Hubei, China
xlei@whu.edu.cn
Xiaoguang Wang
Wuhan University, Hubei, China
whu_wxg@126.com
DOI: 10.1045/may2015-xu
Printer-friendly Version
Abstract
Semantic description and annotation of digital images is key to the management and reuse of images in humanities computing. Due to the lack of domain-specific hierarchical description schema and controlled vocabularies for digital images, annotation results produced by current methods, such as machine annotation based on low-level visual features and human annotation based on experts' experiences, are inconsistent and of poor quality. To solve this problem, we propose a semantic description framework for content description, based on information needs and retrieval theory. The framework combines the semantic description with a domain thesaurus. In this paper we describe the relationship between the semantic levels under this description framework. We conduct a preliminary test with this method in the cultural heritage field using digital images of the Dunhuang frescoes. We discuss the effect of semantic granularity on the annotation cost, from the point view of image semantic description granularity, and control strategies for an image's semantic description quality. Our findings show that this framework is applicable to the description of cultural digital image content.
Keywords: Image Annotation, Semantic Description, Hierarchical Model, Domain Vocabulary
1 Introduction
In the Web 2.0 era, managing and reusing digital images has become a tough problem because the quantity of images being stored is growing dramatically. Metadata, which serves as an informative index or even as a substitute for the data itself sometimes, has achieved a lot in organizing digital images effectively. However, existing metadata schemas mainly focus on describing the shallow attributes of images, such as date, location, sizes and format, but lack the necessary specifications for true image content description. In particular, the "semantic gap" between low-level features and the high-level semantic content of images has impeded the semantic retrieval of image content for many years. No general guiding framework for image semantic description exists, which has led to inconsistent and low quality, missing, incorrect, or meaningless semantic annotation in projects. Automatic annotation approaches based on machine learning techniques also have not reached a satisfactory level of development. Consequently a large number of digital images are not fully used for humanities computing [1].
Cultural digital images, for example cultural heritage fresco digital images or digital images or paintings of historic sites, may help to preserve the original objects by substituting for them when they are not suitable to be touched or visited any more due to their age. There may be many stories behind them that are valuable for memories and studies. In this article we will discuss image description problems in the cultural field, especially those of frescoes and paintings, but the ideas and methods used in this study are also suitable for other cultural image descriptions.
The Dunhuang frescoes digital images are our object of research. They constitute a special area in the field of Chinese cultural heritage. These frescoes are gems of the human cultural patrimony and are appreciated for both their artistic and humanities research value. With the popularization of digitizing objects of cultural heritage, researchers created an extensive number of digital images of the Dunhuang frescoes, allowing wide dissemination of these images and thus laying a foundation for relevant studies. However, because of the lack of semantic annotations, these images are not used to the fullest extent possible. To uncover the semantic information embodied in digital images of the Dunhuang frescoes and improve access to them, a semantic description method must be developed. This will not only benefit automatic semantic annotation and retrieval, but also publishing and presenting these cultural heritages on the semantic web.[2]
In the following sections we will first review the studies related to semantic annotation of digital images, and then propose a semantic annotation method along with a hierarchical model framework and a domain vocabulary for cultural digital images. This method is designed to achieve standardization of artificial annotation content for cultural digital images thus laying a foundation for automatic annotation by machine. Although the method described in this paper is mainly designed for frescoes it also could be transformed easily to other similar fields by replacing the domain vocabulary.
2 Related Research
2.1 Digital image semantic annotation approaches
Valid annotation is crucial to the management, preservation, analysis and sharing of digital images. Generally, the more detailed the image annotation, the higher the cost, but retrieval effectiveness is better, and vice versa. There are two approaches to image annotation: manual annotation and automatic annotation. Manual annotation is carried out by experts with the help of metadata standards and controlled vocabularies. Recently, several image annotation frameworks and software tools were developed for manual annotation, such as the Text-Image Linking Environment project, DM project [3], imageMAT project, SharedCanvas project [4], and Islandora project.
Digital image annotation by machine is currently a frontier research topic in the field of computer graphics. The key idea behind image semantic annotation is to create an efficient method to map un-annotated images to existing semantic categories. The annotation process involves image visual feature extraction and annotation model building. Image visual features include color, texture and shape, etc. The main methods for feature extraction are based on the whole picture, area, or objects in it. The representation methods for these features are the histogram, regional characteristics, visual word bag and the size invariant features transform (SIFT) and so on. Automatic annotation models for images are generally based on statistical and machine learning models. Latent Semantic Analysis (LSA), probabilistic Latent Semantic Analysis model (pLSA) and Latent Dirichlet Allocation (LDA), etc., are of the generative type. Support Vector Machine (SVM), Bayes Discriminant Model, and Gaussian Mixture Model (GMM), are examples of the discriminative type. The two types of models can be combined to boost performance [5].
Currently, research on automatic annotation has been fruitful, but there are still many problems to be solved. Especially in the cultural field, the "semantic gap" between visual features and high-level semantic content of an image is still difficult to bridge. Due to the lack of a domain specific, standardized semantic description framework, the quality of automatic semantic annotation is difficult to judge and the significance of annotation results is also hard to evaluate.
2.2 Digital image metadata formats
A digital image metadata format refers to a set of image description and management terms, widely used in libraries and museums. Visual Resources Association (VRA) is a common description format for images and works in digital cultural heritage management. Exchangeable image file format (EXIF), ia standard set of metadata for digital images, includes items such as shutter, aperture, focal length, and other equipment information collected during shooting. DIG35 is a widely used format which provides users with a simple and agile access. There are other metadata formats for digital images, such as Dublin Core, EMP, SVG, etc.
Multimedia Content Description Interface (MPEG-7) is a popular international multimedia annotation standard, which provides a series of tools for image content description, such as Descriptors, Description Schemas, Description Definition Language and the relationships between them, and Description Defined Language used for description information. MPEG-7 supports a variety of audio and visual resources, including free text, statistics, multi-dimensional space-time structure, subjective and objective attributes, production attributes and combination information, etc. MPEG-7 is not for a specific field, but it provides the broadest possible support for images, audio, video and other multimedia resources.
Joan Beaudoin also proposed a contextual metadata framework for digital preservation of cultural objects from eight dimensions: Technical, Utilization, Physical, Intangible, Curatorial, Authentication, Authorization, and Intellectual. [31]
In general, the existing image metadata formats are designed principally to describe the external features of images to facilitate image indexing, preservation, retrieval and discovery. Due to a lack of high-level semantic content description, however, these metadata fail to support further semantic retrieval, content analysis, and knowledge discovery for humanities computing. Although there are some metadata designed to describe an image's semantic content, such as the subject or meaning of images, taking the metadata meaning in Joan Beaudoin's research for example, the value of this metadata was not structural at all — it is textual only. In order to reveal entity objects and their relationships in the image content, and high-level semantic information such as scenes and activities, we have to create a more detailed semantic description framework for image annotating.
2.3 User retrieval requirements for digital images
To describe and annotate digital images, we need to understand user needs pertaining to searching for images or using images, specifically the information in the images users really care about, in Semantic Based Image Retrieval (SBIR).
From the perspective of cognitive psychology, Jörgensen extracted 12 types of image description elements, such as people, objects, color, content/story, and visual elements obtained through an analysis of the descriptive text of needed images [7]. Cunningham, et al., described user image retrieval needs with eight basic elements: image metadata, content, genre, occasion, color, example, affect, abstract [8]. Shatford proposed a three-layer image needs classification model including general concept, specific concept, and abstract concept. Each layer has four dimensions: people, time, location, and content [9].
Jamis and Chang proposed a ten layer model for user image needs description on the basis of Shatford's model. The four layers at the bottom of the hierarchy are related to perception, including image type/technology, color, shape and texture. The six layers at the top of the hierarchy inherit from Shatford's three-layer model, but it adds two additional layers for each layer in Shatford's model: layers for objects contained in images as well as a layer for the whole scene shown in the image [10]. Batley defines four types of image requirements: specific, general/named, general/abstract and general/subjective [11]. These research results were integrated by Hollink, et al., who proposed a description framework for a text description and the visual features of images from the user's perspective [12].
2.4 Semantic description of digital images
The objects, scenes, and their relations comprise part of the description content of images. We must consider the details, terms used or semantic layers in the process of image description, otherwise the description content of the images will be inconsistent with user queries.
The hierarchical semantic description of images has been recognized by many researchers. In literature, the word "hierarchy" is equally used for both composition and inheritance relations. Epshtein and Ullman build a hierarchy of visual features [13]. They start with an informative fragment and search recursively for smaller informative fragments in it. Fidler and Leonardis build a hierarchy of image parts using unsupervised statistics [14]. Each layer is built by via the composition of features of the previous layers. Lower layers are built from simple features, and higher layers describe more complex ones. Ahuja and Todorovic build a hierarchy of object parts in images based on their co-occurrence in a same object [15].
Rege, et al., build a semantic hierarchy based on users' experiences and their feedback [16]. Categories of parts stem from the information extracted through the feedback and the hierarchical organization of images is able to be determined, and more intuitive search and browsing are also allowed. Eric and Thonnat classify objects top-down [17]. When going down the hierarchy, a category has sub-categories in which feature extraction can be adapted depending on the candidate category, and objects could be classified. Torralba, et al. [18] use many tiny images, with nearest neighbors. Because these images are labeled with WordNet nouns, they can categorize images at different levels using a hierarchical vote, where a label also votes for its parents. Fan, et al., [19]; [20]; [21] propose a hierarchical boosting algorithm based on ontology and WordNet allowing image annotation at different generic levels.
The existing research has proved that the hierarchical descriptions of images basically stem from the structured vocabularies' hierarchies. Though semantic hierarchies and structured vocabularies are crucial to the success of image annotation, there is still not a unified standard for image description [22].
3 Semantic description of cultural digital images
3.1 The hierarchical model
We propose a hierarchical semantic model for digital image description. When integrating semantic layer information for images from the perspective of user demands, the twelve kinds of image description elements that Jörgensen [7] summarized have a corresponding layer in our semantic hierarchy model. Cunningham's [8] eight image elements have involved common image metadata. We can also find a corresponding place in a behavior semantic layer that represents the four dimensions (people, content, time and location) proposed by Shatford [9]. The description layers for image requirements proposed by Jaimes and Chang [10] include general, specific and abstract concepts. These concepts come from users' knowledge, expressed through corresponding thesauruses or general vocabularies. Therefore, on the basis of the image semantic layer, our proposed model adds general, specific and abstract concepts to the top of the hierarchical model. As for the object layer, we can divide the object classification into three levels (the general, specific and abstract concepts) when we describe a specific object. This classification task can be completed using domain ontologies or other classification terminologies and vocabularies. In our work, we integrate the general, specific and abstract concepts and other corresponding vocabularies into the high-level Hierarchical Semantic Model. Our proposed model makes the description content for images comprehensive, therefore better meeting user image retrieval requirements. The description of the framework is shown in Figure1.
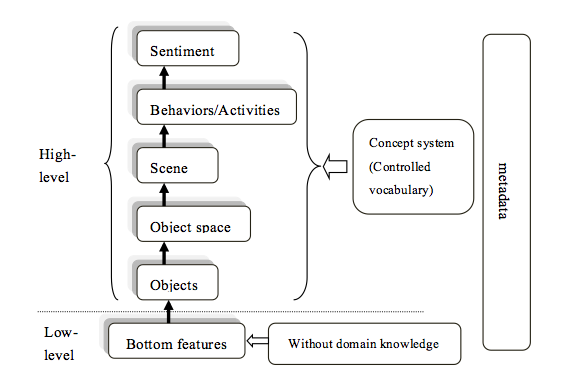
Figure 1: Hierarchical semantic model for digital images
- Bottom Features. Image color, texture, and shape are features that exist in an image. This information can be extracted automatically by pattern recognition and graph learning technology, or a mix of methods. However, the Dunhuang fresco digital images are digital copies of artistic works which are the expression of the real world or an abstract world. The spatial relationship among objects in the frescoes may be different from the relationship reflected in the pixel distance found in digital images. The scene and sentiment information in frescoes are different from that of the real world. In the literature (Liang Guanyu, 2000), experimental results showed that using the feature extraction methods mentioned previously to identify high-level semantic information is not completely suitable for frescoes. In this paper, we will not delve further into details of the extraction methods for bottom visual features of cultural digital images.
- Objects. The description of objects is the most important part of the hierarchical semantic model. Here, we divide the description content of objects into two categories: classification and attributes. In addition to metadata and visual features, objects in an image have their own properties, such as the name, gender, attitude, and other attributes related to specific characters in the image. Using pattern recognition to determine high-level semantic content is problematic, so these attributes cannot be entirely recognized through bottom visual feature extraction. We need to use corresponding domain-specific controlled vocabularies or ontologies to describe them, such as the Dunhuang studies dictionary [25] and other vocabularies.
- Object Space. Object space can be divided into three categories: direction relations of an object area in the digital image level, the topological relations reflected in objects themselves, and semantic spatial relations among objects. We use the spatial relationship description in the MPEG-7 framework to describe Dunhuang frescoes (see Table 1). The spatial description scheme in MPEG-7 includes object spatial direction relations, topological relations, and semantic space relations.
| Relation Type |
Examples |
| Space Direction Relations |
topof, bottomof, leftof, rightof, middleof |
| Topological Relations |
nearby, within, contain, adjacentto |
| Semantic Space Relations |
belongsto, partof, relatedto, consistsof |
Table 1: Object Space Relation Description
A spatial semantic relation is the logical relationship among objects, such as affiliation, dependency, correlativity, among others. These descriptions usually cannot be extracted automatically. Spatial direction relations can be extracted automatically according to the regional location of objects, but the confirmation of the direction depends on the methods used to divide object areas (such as rectangles, circles, etc.) and the methods used to calculate the direction (such as the center of mass, or the bottom edge of area based methods, etc). Different methods may lead to different outcomes. Spatial direction relation data can be used to describe topological relations. For example, the "middle of" relation between objects may be the "within" topological relation. However, it depends on context.
- Scene. The parts of an image other than the main objects can be called the scene. A scene contains environment, such as rain, snow, etc. Scene data can be used to solve some of the ambiguity at the image semantic level. For example, images of the same people may express different meanings in different scenes. Without understanding the differences, we may get a wrong result. Identifying scenes can provide the context necessary to understand the semantic content. Different people may have different opinions on what the main objects are. We can use human visual attention mechanisms [26] to identify the main or significant areas of an image, or the regions that users are interested in. There are differences between a scene painted in frescoes and the real world. We can identify the scene by background color, texture, shape, and visual features of digital images shot in the real world, for example, a large green zone in an image may represent green grass in the real world. Scenes in frescoes with different artistic compositions describe the real world differently and cannot be obtained by the same method. Some scenes are mixed, such as the alternation of inside and outside scenes. Moreover, the scenes painted in frescoes are not real and some frescoes contain scenes, such as story paintings and JingBian paintings, while others do not contain scenes, such as figure paintings and pattern paintings, and in other frescoes we cannot distinguish the specific scene effectively. In this paper, we divide scenes into three types: geographic scenes, time scenes and weather scenes. A geographic scene includes sky, indoor, outdoor, lake, river, mountain, sea, field, etc. A time scene contains spring, summer, autumn, winter, morning, evening, noon, etc. A weather scene contains rain, snow, wind, thunder, lightning, sunshine, etc. It should be noted that some geographic scenes, such as a lake, a sea, or a mountain, may be described in the object layer, but the theme of Dunhuang frescoes is primarily Buddhist stories, so we usually put these words or terms in the scene layer.
- Sentiment. There are two points of view in image sentiment description. The first is people's subjective feelings about the entire image, such as their feelings when they see red or green color, and this is not our focus. Another is the emotions of the characters themselves in the image, such as anger, serenity, etc. Psychologists divide human emotions into six types [27]: happiness, surprise, fear, sadness, disgust, and anger. These can be applied to the classification of affections in our description framework. However, the emotions exhibited by characters in images could be differently interpreted by different annotators. Or the image could be too vague to ascertain an emotion. Therefore, sentiment recognition of characters in images requires a combination of characters and the environment around them. For example, the emotion of characters in a celebration can be described as "happy". However, in general, sentiment information cannot be extracted automatically.
3.2 Semantic association in image content
Through the above analysis, the complicated semantic relationships are expressed. Furthermore, an object itself also has inherent attributes. To avoid confusion, the object's attributes are divided into two facets, the data attributes that reflect the inherent characteristics of the object, and the object relation attributes which reflect the interjacent characteristics between objects.
Since characters appear frequently in Dunhuang frescos, we give a detailed description of the characters' attributes. Table 2 presents some of the data attributes of characters.
| Property |
Value Range |
| Gender |
male, female |
| Eye Color |
blue, green, etc. |
| Action |
walk, sit, kneel, run, jump, etc. |
| Head Direction |
up, down, left, right, etc. |
| Direction |
up, down, left, right |
| Hands Action |
lift, cross before breast, etc. |
| Posture |
chubby, delicate |
| Backlight color |
yellow, white, etc. |
Table 2: Some Data Attributes of Characters
The relationships between objects can be divided into three levels: relationship at the object space level (Table 1), relationship in behavior level, and other relationships that can be used as object properties. We have already discussed the object space and behavior level relations, so we will focus on the object property relation in this section.
First, we should determine the differences between behavior level relation and object property relation. For example, the behavior "shooting an arrow", implies the meaning of a relationship as "a figure holds a bow", but for "dancing" behavior, the case is different. In another example, the object property "with Clothes On" implies behavior by the verb "wear". These two kinds of relationships complement each other and enrich the semantic associations between objects. The verbs such as "play", "dress" or other similar terms are very numerous and jumbled if they are treated as object properties; therefore, image content that can be described at the behavior level or as a space relationship will not be described as object properties. When the description information cannot be obtained at the behavior level, we will consider description using the object property. The general object properties are summarized and shown in Table 3 below.
| Object Property |
Explanation |
Range |
| Hold |
figures' and other objects' relations |
lift, support from under, clasp, etc. |
| Clothes |
figures' headwear, clothes, accessories |
— |
| Social Relationship |
relationships among people in society |
disciple, minister, etc. |
| Pattern |
pattern on objects |
pattern on clothes, utensils, buildings |
Table 3: The Object Relation Attributes
Figure 2 explains the relationship between the semantic layers of images. The object layer is the center of this model. The other high-level semantic layers rely on the object layer. The collection of objects forms the main body of an image, but an object has its own properties. It produces associations through object properties, spatial relation information, and behavior data between objects. The behavior layer depends on the object layer and becomes connected to the scene layer. Digital images themselves have metadata description properties. The visual characteristics of digital images also have different property description methods.
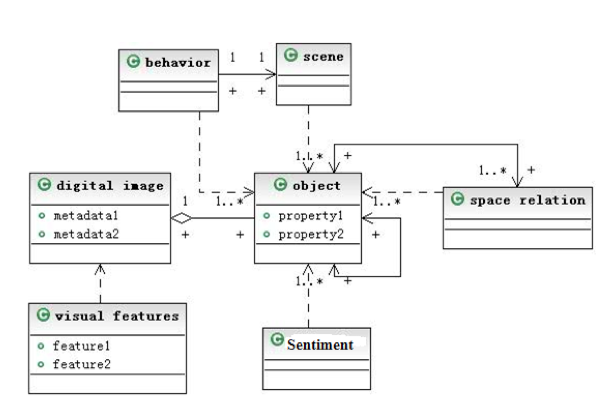
Figure 2: Correlation Diagram of Image Semantic Levels
3.3 Thesaurus of cultural digital image content
Domain terms are good descriptors of the field and contain the characteristics of objects to be described. For example, the classification of Dunhuang frescoes's Buddha involves a lot of fresco terms, such as flying apsaras, bodhisattva, etc. We refer to the "Dunhuang studies dictionary" [25] and other research literature [28] about the classification of Dunhuang frescoes to sort out professional terms in this field and classify these vocabularies effectively. Finally, we formed a classification thesauri system for the Dunhuang frescoes. The Dunhuang frescoes content classification system is shown in Table 4. It is classified according to Figure 2 and only shows the classification of terms in the highest level of each layer of the semantic hierarchy model.
| Semantic Level |
Classification Terms |
| Object |
people, animal, plant, utensil, vehicle, building, clothes, pattern |
| Object Space |
direction relations, topological relations, semantic relations |
| Behavior |
recreational and sports activities, production and living, Buddhism activities, general behavior |
| Scene |
geographic scene, time scene, weather scene |
| Sentiment |
happiness, surprise, fear, sadness, disgust, anger, serene |
Table 4: Top-level Classification Terms of Dunhuang Frescoes
The terminologies that appear most frequently in relation to Dunhuang are scattered in semantic layers of objects (such as people, building, clothes, etc.) and behaviors (such as JingBian, music dance, production and living, etc). The objects and behaviors terms can make the field characteristics of Dunhuang frescoes stand out, but the object space, scene, and sentiment semantic information is universally used through the analysis and used not only in fresco digital image fields but also in other areas. The description of classifications may be the same and differences may be not obvious when we describe the object space, scene, and sentiment of a digital image in another field.
4 Description methods and examples
4.1 Hierarchical description method
Considering users' demands for image retrieval and the semantic hierarchical model of the image content comprehensively, we propose a hierarchical description method combined with domain-specific terms. We reference the conceptual context + focus and zoom [29] for graphical information visualization. First, we describe the content as a whole to accommodate most of the content found in the images; this is the overall description content. In this phase, we use metadata combining the top-level classification from domain-specific terminologies as shown in Table 4, such as behavior and scene information. On the basis of the fixed size of the area of vision, we continue to amplify the image and describe it, using local information. At this stage, we do not use metadata any longer; instead, we use object, object space relationships, scene, behavior and sentiment layer terms to describe images, combining these terms with subprime terminologies, or lower level terms, to describe the cultural digital image. We keep describing the image until it cannot be divided into smaller objects. This method is, in essence, a kind of granularity analysis method. When we exaggerate images gradually, we make more fine-grained observations. High-level terms correspond to generalized concepts and terms at the bottom correspond to specific concepts that represent users' different understandings of an image. The key to hierarchical description is information fusion at all levels using the principle of granularity.
The advantage of hierarchical description is that the lower layer of an image carries more description information, because it inherits description information from the surrounding graphical environment; thus, it is unnecessary to describe a certain area of an extraction from the digital image alone. The part extracted contains the upper inheritance information; we only need to change the metadata content slightly for the area changed by the extraction operation. The hierarchical description method can also satisfy users' needs for image retrieval from different angles. There are more details in objects. These description details, however, are limited by controlled terms.
4.2 Application example of digital image description framework
The Dunhuang fresco digital image description standard can be applied to the Dunhuang fresco image annotation system, retrieval system, the classification of frescoes, and facet browsing. The fundamental purpose of image description and annotation is to meet users' needs for image retrieval, connecting users' requirements and image descriptions, solving the dilemma of "No relevant search results". We provide below a description on an actual image using the semantic hierarchical model mentioned previously. Table 5 presents the semantic description results for Figure 3.

Figure 3: Scattering flowers and flying Apsaras [30]
| Semantic Level |
Description |
| Bottom visual features |
color histogram, texture, shape, etc. |
| Object |
First level |
scattering flower, flying Apsaras, lotus, auspicious clouds |
| Second level |
parts of object such as Apsaras' torso, limbs, figure's clothing, wreaths, belt |
| Object Space |
Space direction |
Apsaras is in upper part of the image, lotus is in lower part of the image |
| Topology |
Apsaras is above auspicious clouds |
| Semantic space |
Apsaras object consists of head, torso, limbs, etc. |
| Scene |
outdoor scene, sky scene, hill |
| Behavior |
Objects |
Apsaras, lotus, auspicious clouds |
| Content |
Apsaras scattering flower (scattering flower is a term in Dunhuang)
Apsaras clothes belt (clothes is a object property)
Apsaras hold lotus (hold is a object property)
|
| Location |
sky |
time |
middle tang dynasty |
| Sentiment |
serene |
Table 5: Description Results for Figure 3 Using the Semantic Hierarchical Model
The hierarchical description method makes a comprehensive description of all objects in the image feasible. For example, in the description shown in Figure 3, the description of the character object can be divided into two levels. The first level is the individual level and the second is part of the individual level. Of course, objects can still be divided into smaller parts, for example the description of a statue fresco with drawn-in details. The head can be further divided into hair ornament, backlight, eyes, eyebrows, nose, ears, and mouth. A further description process is necessary, because Dunhuang fresco researchers summarized the characteristics and style of certain periods by observing the figures' face distributions, postures, and facial expressions. The description of the object space relations and the scene are easy compared to the object layer. We must grasp main characteristics of images to make the description standardized and comprehensive. It is easy to process object space and scene. For instance, the head and torso of a character in a fresco has a topof relationship, but we prefer to use semantic space relation, such as consistof, to express the relationship that a character's head and torso are parts of the body. In describing the layer of behavior, we used Dunhuang terminologies to standardize the results and used terms or unified verbs to describe the content of behaviors. From this analysis, we conclude that while description of the sentiment level is relatively simple, sentiment recognition is difficult, but based on the scene and behavioral information combined with the character's facial expression, we can describe an emotion using a word like "serene" for this character.
The properties of objects in images need to be described according to the granularity and identifiably of images. In Figure 3, the character in the image whose dress color is brown, is female, the figure is chubby, both hands are lifting a lotus, the neck wears wreaths, etc. These can be described by their properties and produce semantic associations with other objects in the image.
In addition, Table 5 does not represent a full record of Figure 3. Much descriptive information about this image is omitted, such as the title, size, format, etc., because the approach we proposed came primarily from user needs, and we focused on image semantic content rather than the external features of the image. The main semantic content is described according to our approach, but other content was not.
5 Discussion and Conclusions
5.1 Granularity and cost
As discussed previously, we must improve the description granularity of images if we want to guarantee the comprehensiveness of those descriptions. The granularity of image descriptions includes the granularity of description terms and the hierarchical descriptions. Description term granularity depends on the way images are divided by domain terms, while the granularity of hierarchical description depends on the control of the image level during the process of actual image description creation. In general, description term granularity and image hierarchical granularity are consistent with each other. However the comprehensiveness and granularity of image description are restricted in practical cultural digital image description processes, given the different data volume to be annotated, the differences of specific applications, human and capital investment, etc. If description data is too fine, a describer's work will be so large as to be unmanageable, and the complexity of annotation will be too large. On the contrary, the annotation effect will suffer if the granularity is too coarse.
There are some principles we must follow when we describe cultural digital images. The description data should be rough when objects in frescoes are abstract, and finer when the objects are described in detail; some characters not prominent in images could be annotated in the top level rather than the bottom level, etc. Some cultural digital images have adornment, natural scenery, and decorative patterns as frames. We can identify the complete subject of the images according to these decorative patterns to avoid missing semantic descriptive information. Because cultural digital images may include antiques, some of the content cannot be identified effectively. Images that cannot be identified or confirmed through literature are not described in our research.
5.2 Quality control
From the view of information source control, we choose domain-specific terms such as the "Dunhuang studies dictionary" supplemented with other scholars' research as the source of the terms. We provide complete concepts and entry words that have been sorted, classified, and identified with the help of experts in the field. In the information generation phase, we guaranteed the quality of the description terms' clarity, consistency, scalability, accuracy and comprehensiveness, etc. In the information output stage, we investigated the quality of terms by analyzing the organization, form, ease of sharing, and versatility of description results. At the information use phase, quality control work on terms will be carried out by analyzing the application scope, effect, social value, and significance of the description framework in practical application.
In this paper we presented a cultural digital image description framework. According to our analysis, either the RDF (Resource Description Framework) or OWL semantic format are a suitable organization form for image description results. Both can link all layers of a semantic hierarchy model and represent the information about object properties. Organization form research will be addressed in detail in our future work.
5.3 Portability
The portability of this description framework is directly related to its application scope. The framework proposed in this paper depends on a specific area only and has nothing to do with any specific application. It does not involve the use of a software or hardware environment and does not depend on any system environment. This framework can be applied in different fields of image description work, especially for painting digital images. The open standard ensures that it can coexist with other description specifications and is easy to replace. Because it is related to domain-specific fields such as Dunhuang frescoes, portability of the framework depends on its extensibility. The semantic hierarchy of this image description framework can be used for description of any digital images. The main differences lie in the varied semantic description content resulting from the change of concept systems related to specific fields, as well as the change in image metadata according to different application requirements. Spatial relations, scene and sentiment semantic hierarchies have generality in different domains. The object and behavior hierarchy, however, partly depend on a specific domain. This framework can be used in interdisciplinary applications by changing the domain concept system, and redefining relations between objects.
5.4 Future work
In this paper, we propose a semantic description method for Dunhuang fresco digital images. This method has already been applied to some image samples in our project as a proof of concept, and in the future, more digital images of Dunhuang frescoes will be described according to this approach. An image description framework is not unique when we describe images in actual processes. We need to weigh the pros and cons of various factors when determining the weight of each part of this framework according to demands and different applications. This is especially true in task or domain oriented applications. Moreover, an image description process may be not completely finished according to this framework. We need to design image annotation tools with extended interfaces to ensure sharing and extension of descriptions relevant to different applications in the future.
In the next stage we will design annotation tools for cultural digital images according to the digital image description framework described in this paper. We will focus on the specific organizational form of image annotation information by referencing the Open Annotation Data Model.
Acknowledgements
This research is funded by National key basic research development plan of China (973 plan, 904171200). This research is also partly supported by Youth talent support plan of China.
References
[1] Schreibman, S., Siemans, R., & Unsworth, J. (Eds.). (2004). A companion to digital humanities. Malden, MA: Blackwell.
[2] Benjamins, V. R., Contreras, J., Blázquez, M., Dodero, J. M., Garcia, A., Navas, E., & Wert, C. (2004). Cultural heritage and the semantic web. In The Semantic Web: Research and Applications (pp. 433-444). Springer Berlin Heidelberg. http://doi.org/10.1007/978-3-540-25956-5_30
[3] Martin Foys, Shannon Bradshaw. (2011). Developing Digital Mappaemundi: An Agile Mode for Annotating Medieval Maps, Digital Medievalist 7.
[4] Sanderson, R., Albritton, B., Schwemmer, R., & Van de Sompel, H. (2011, June). Sharedcanvas: a collaborative model for medieval manuscript layout dissemination. In Proceedings of the 11th annual international ACM/IEEE joint conference on Digital libraries (pp. 175-184). ACM. http://doi.org/10.1145/1998076.1998111
[5] Yang, C., Dong, M., & Hua, J. (2006). Region-based image annotation using asymmetrical support vector machine-based multiple-instance learning. In Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on (Vol. 2, pp. 2057-2063). IEEE. http://doi.org/10.1109/CVPR.2006.250
[6] Carneiro, G., Chan, A. B., Moreno, P. J., &l Vasconcelos, N. (2007). Supervised learning of semantic classes for image annotation and retrieval. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 29(3), 394-410. http://doi.org/10.1109/TPAMI.2007.61
[7] Jörgensen, C. (1998). Attributes of images in describing tasks. Information Processing & Management, 34(2), 161-174.
[8] Cunningham, S. J., Bainbridge, D., & Masoodian, M. (2004, June). How people describe their image information needs: A grounded theory analysis of visual arts queries. In Proceedings of the 4th ACM/IEEE-CS joint conference on Digital libraries (pp. 47-48). ACM. http://doi.org/10.1145/996350.996362
[9] Shatford, S. (1986). Analyzing the subject of a picture: a theoretical approach. Cataloging & classification quarterly, 6(3), 39-62.
[10] Jaimes, A., & Chang, S. F. (2000). A conceptual framework for indexing visual information at multiple levels. IS&T/SPIE Internet Imaging, 3964, 2-15.
[11] Batley, S. (1988). Visual information retrieval: browsing strategies in pictorial databases. In International online information meeting. 12 (pp. 373-381).
[12] Hollink, L., Schreiber, A. T., Wielinga, B. J., & Worring, M. (2004). Classification of user image descriptions. International Journal of Human-Computer Studies, 61(5), 601-626. http://doi.org/10.1016/j.ijhcs.2004.03.002
[13] Epshtein, B., & Uliman, S. (2005, October). Feature hierarchies for object classification. In Computer Vision, 2005. ICCV 2005. Tenth IEEE International Conference on (Vol. 1, pp. 220-227). IEEE. http://doi.org/10.1109/ICCV.2005.98
[14] Fidler, S., & Leonardis, A. (2007, June). Towards scalable representations of object categories: Learning a hierarchy of parts. In Computer Vision and Pattern Recognition, 2007. CVPR'07. IEEE Conference on (pp. 1-8). IEEE. http://doi.org/10.1109/CVPR.2007.383269
[15] Ahuja, N., & Todorovic, S. (2007, October). Learning the Taxonomy and Models of Categories Present in Arbitrary Images. In ICCV (pp. 1-8). http://doi.org/10.1109/ICCV.2007.4409039
[16] Rege, M., Dong, M., & Fotouhi, F. (2007). Building a user-centered semantic hierarchy in image databases. Multimedia systems, 12(4-5), 325-338. http://doi.org/10.1007/s00530-006-0049-6
[17] Eric Maillot, N., & Thonnat, M. (2008). Ontology based complex object recognition. Image and Vision Computing, 26(1), 102-113. http://doi.org/10.1016/j.imavis.2005.07.027
[18] Eakins, J. P. (2002). Towards intelligent image retrieval. Pattern Recognition, 35(1), 3-14. http://doi.org/10.1016/S0031-3203(01)00038-3
[19] Fan, J., Gao, Y., & Luo, H. (2007, July). Hierarchical classification for automatic image annotation. In Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval (pp. 111-118). ACM. http://doi.org/10.1145/1277741.1277763
[20] Gao, Y., & Fan, J. (2006, October). Incorporating concept ontology to enable probabilistic concept reasoning for multi-level image annotation. In Proceedings of the 8th ACM international workshop on Multimedia information retrieval (pp. 79-88). ACM. http://doi.org/10.1145/1178677.1178691
[21] Fan, J., Gao, Y., Luo, H., & Jain, R. (2008). Mining multilevel image semantics via hierarchical classification. Multimedia, IEEE Transactions on, 10(2), 167-187. http://doi.org/10.1109/TMM.2007.911775
[22] Tousch, A. M., Herbin, S., & Audibert, J. Y. (2012). Semantic hierarchies for image annotation: A survey. Pattern Recognition, 45(1), 333-345. http://doi.org/10.1016/j.patcog.2011.05.017
[23] Eakins, J. P. (1996, May). Automatic image content retrieval-are we getting anywhere?. In ELVIRA-PROCEEDINGS (pp. 121-134).
[24] Liang Guanyu. (2000). Storage and Retrieval for the Archive Data and Fresco Image of MoGao Grotto. Institute of computing technology of the Chinese academy of sciences.
[25] Ji XianLin. (1998). Dunhuang studies dictionary.Shanghai dictionaries press.
[26] Bulthoff, H. H., Lee, S. W., Poggio, T. A., & Wallraven, C. (2003). Biologically motivated computer vision. Springer-Verlag.
[27] Ekman, P., Friesen, W. V., & Ellsworth, P. (1972). Emotion in the human face: Guidelines for research and an integration of findings.
[28] Zheng Binglin, Sha Wutian. (2005). Introduction to Dunhuang grottoes. art Gansu Culture Press.
[29] Cockburn, A., Karlson, A., & Bederson, B. B. (2008). A review of overview+ detail, zooming, and focus+ context interfaces. ACM Computing Surveys (CSUR), 41(1), 2. http://doi.org/10.1145/1456650.1456652
[30] Zheng Ruzhong, Tai Jianqun. (2002). Dunhuang grottoes corpora: Apsaras picture scroll. The Commercial Press.
[31] Beaudoin, J. E. (2012). A Framework for Contextual Metadata Used in the Digital Preservation of Cultural Objects. D-Lib Magazine, 18(11), 2. http://doi.org/10.1045/november2012-beaudoin2
About the Authors
 |
Lei Xu is a postdoctoral researcher at the School of Information Management of Wuhan University in China. He received his PhD degree from the same university in May 2014. His research interests include ontology development and evaluation, complex networks, semantic web, and digital libraries.
|
 |
Xiaoguang Wang is a Professor at the School of Information Management of Wuhan University in China. He currently works on Semantic Publication and Knowledge Discovery. His interests include digital humanities, scientific knowledge, and networks.
|
|