Digital Libraries: Searching Is Not Enough
What We Learned On-Site
Andreas
Paepcke
Stanford
University
paepcke@cs.stanford.edu
D-Lib Magazine, May 1996
ISSN 1082-9873

Andreas
Paepcke
Stanford
University
paepcke@cs.stanford.edu
D-Lib Magazine, May 1996
For many people, 'Digital Library' evokes the image of a giant repository of on-line information. Users would access this repository, submit a search, and walk away happy with their information.
The main research problems derivable from this starting point are scaling and information finding: If only we can provide good performance for the standard information retrieval metrics of recall and precision when accessing very large collections, we will have a Digital Library.
This image of what users should be able to do with Digital Libraries is far too narrow. That became evident from a series of interviews conducted with workers in a large, diverse company producing computers, computer peripherals, medical-, and microwave equipment. The goal was to learn about information needs and habits of workers in technical work settings. Occupations of our informants included technical support, marketing, software integration, finance, electronics product design, chemical analysis instrument design and design/manufacture of computer printers. The interviews were semi-structured and were conducted within the interviewee's work space. We had an opportunity to view information artifacts, and in some of the cases, we witnessed the work being conducted.
This exploration pointed towards a research direction for Digital Libraries that included not just search, but four other aspects of user tasks. It suggested a vision for Digital Libraries that supported users throughout several phases of their work.
A full analysis of the material along dimensions of information use in groups can be found in the upcoming July issue of the CSCW Journal. Here, I will summarize a few of the findings that inform Digital Library research, and I will suggest some ways that our preliminary observations might enter into future research. The intent for the article is to be open- ended and to suggest starting points for investigation. Some of these investigations have been pursued over the years in specialized communities of the computer- and social sciences. But the context of Digital Libraries offers the opportunity not only to add additional research aspects, but to integrate and renew many previously isolated efforts.
I draw examples from two of the settings visited during the study. The first is a customer support center. It consists of tens of engineers organized into departments. Each department supports some range of the company's products. Customers phone in with problems they encounter. Each call gets routed to an appropriate customer engineer. Each engineer keeps logs of all actions taken. These logs are collected in a database available to all engineers in the facility and to other support engineers world-wide. Other on-line sources include manuals, lists of available software patches, and product specifications.
The second setting is a large operating division designing and manufacturing computer printers. Informants there were marketing personnel, managers, mechanical engineers, electrical engineers and manufacturing engineers. On-line information included e-mail, parts and vendor information, and previous designs.
Many of the requirements suggested by our findings are applicable to general-purpose, public Digital Libraries. Some are important to smaller, organization-internal libraries. All of them attest to the fact that interactions with information include much more than traditional information retrieval. What emerged as guidance for Digital Library research is summarized in the following figure:
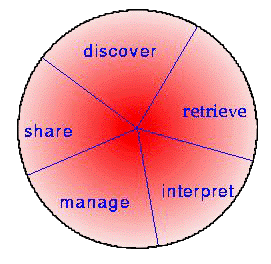
The main activities the interviews brought to light can be partitioned into five categories: locating and selecting among relevant sources, retrieving information from them, interpreting what was retrieved, managing the filtered-out information locally, and sharing results with others. These activities are not necessarily sequential, but are repeated and interleaved. Here is a sketch of each activity in turn.
A new printer was to be designed that was to be less costly than the current model. Previous analysis had shown that the paper feed was one of the most expensive parts of the current model, so an engineer was assigned to redesign it. His first problem was to understand why paper feeds were currently designed the way they were. He eventually extracted everything related to paper feed design, but the information was embedded in a surprisingly heterogeneous collection of material that took more than four months to amass. Much of that time was spent identifying and collecting relevant information, including old project documentation and the lab notebooks of engineers who had worked on previous projects. The particular work groups no longer existed. Participants had left or been reassigned.
He extracted from this stack of material everything related to paper feed design. Most of these documents had been created for reasons other than what the engineer needed to use them for, making their structure less than optimally suited for this new purpose.
These shifts in reasons for seeking out sources that were originally structured for other uses is a common problem with resource discovery. Documentation of a mechanical chassis design may, for example, be optimized to make life easy for the manufacturing engineer who needs to design production facilities, rather than for an engineer trying to extract design rationale two years later.
Another problem with source discovery is that often the sources are no longer available. This is one of the times where people come into the picture.
"Computers are terse and unfriendly; humans are scattered and have ego problems." This is how one of the support people described the trade-off between using computers or human beings as sources of information. Yet colleagues were very frequent sources of information for many of the workers interviewed. One of the support engineers explained that she would exhaust the on-line sources first. If this did not solve her problem, she would consult the colleagues in her immediate group, sometimes sharing the on-line information she already found. When a problem required consultation with a neighboring support group responsible for a different set of products, members of that group were involved next. Information transferred to them, however, was more carefully trimmed to be concise. Sometimes information transfer to others needs instead to be augmented to make up for missing material that is commonly known within the immediate working group.
For Digital Library research this means that in addition to resource discovery, informal information transfer among on-line, human and other off-line sources needs support. It should, for example, be possible to easily filter or augment information from on-line sources to be suitable for transfer to human consultants with differing focus or vocabulary, or to use information obtained from one source as input to another.
More generally this means that information needs to be stored and delivered with the capability to be discovered and made useful in service of multiple, varying purposes.
What was striking in many of our settings was the vagueness of the questions needing answers. The paper feed is a good example: "Why was this paper feed designed this way?" Another example is "which person in the organization might be able to give advice on buying the best hard disk?" Of course, these questions are not vague at all to human beings, but they are currently inappropriate for submission to computerized search.
Many of the well-known requirements for information retrieval were re-affirmed in our settings. This includes the need for query refinement facilities or the difficulty of searching over non-textual sources.
Overviews need to be constructed. For our paper feed engineer, this might mean a collection of 'all the information having to do with the mechanical components of the paper feed'.
Trends must be discovered. For example, the marketing branch of the printer division needed to understand trends in color printing to guide decisions regarding the next member of a printer family: is the market primarily looking for better print quality, or for lower price?
Correlations must be explored. For example, in the electronic design setting, the question arose whether pre-design simulation really helped build better products. Visualizations of historical and current defect data might have been of help in this context.
Once a feeling for the retrieved information has been developed, useful bits and pieces are usually extracted and retained for further use. This leads to the next set of problems.
These activities meant that information extracted from customers over the phone and from local service databases in pursuit of solving multiple unrelated problems was accumulating in the engineer's work space. All this information needed to be ready for use during frequent context shifts. Local data management facilities were needed for the engineer to manage these multiple information working sets.
This short-term organization of information extracted from a large shared collection is one management need. In some of the settings studied, a longer-term management problem was evident as well. Users in these settings had constructed a two-tiered information environment. The first tier was the central collection, but they also maintained a permanent local 'cache' of frequently needed information. For example, in the printer group, a central library of vendor addresses and product information was maintained by the company. Manufacturing engineers gratefully extracted information from these facilities. But because it was easy for updates of these large repositories to lag behind, the engineers also kept local copies of selected records and kept them up to date with the newest information. Since the engineers needed these records, they maintained them well. In addition to the temporary, task-specific local information, engineers therefore also needed support for their own second information tier outside of the library.
This often meant that new information artifacts needed to be constructed from the accumulated pieces of previously retrieved and newly acquired information. These new artifacts are 'information compounds'. For example, once a customer support problem is solved, the final solution needs to go back into the shared base of on-line knowledge. This is often an information compound, as explained by one of the engineers:
I found, say, four or five calls that really explain [some given problem] well from a couple of different angles. You know, I doubt if you'll find the perfect one [entry] that answers everything. You're likely to find a cluster of ones that, in the aggregate, provided good summarization.
It can be tricky to build facilities that allow users to construct compounds in such a way that the individual pieces can either stay up to date as base data changes, or remain unchanged over time. In either case, the best locally constructed information artifact is often truly useful only when it can be shared with others.
As an example, consider the manufacturing engineers who were each carefully maintaining second-tier records for the vendors they interacted with. Unfortunately, they had no way of pushing this information back into the shared vendor data repository. The irony was that even though the shared central store was a useful resource, the best maintained information was not shared because the second information tier in this environment was distributed, but not shared. The same happened in the customer support group where one engineer kept a scrap book of particularly useful 'pearls of wisdom'. These were facts learned through trial and error, small excerpts from manuals, or printouts of key e-mail messages pertaining to some difficult problem. Another engineer had constructed a matrix of features supported in successive versions of a particular product she was supporting. This was an information compound hanging on her wall.
Neither of these second-tier pieces of information were shared. This lack of collaboration was not caused by ill-will of the producers, nor was it due to lack of general applicability of the information. Dissemination was simply too cumbersome for the very busy environment they lived in. Just as high school students and others use physical libraries today to engage in collaborative work, Digital Libraries need to be places for sharing.
One difficulty is that the same information sometimes needs to be presented differently for different people. The following quote from a marketing team illustrates this:
We spend a lot of time trying to figure out ways to represent [the information] so that management can understand it. Okay, that's the most difficult thing is, say you have this list of features... but management wants to see a quick and dirty diagram that shows them: "Oh, it's very obvious to me that we need to implement x, y and z and we'll be fine."
Just as information must be stored in ways that make it usable for varying purposes, it must be possible to transform information to make it usable for varying people.
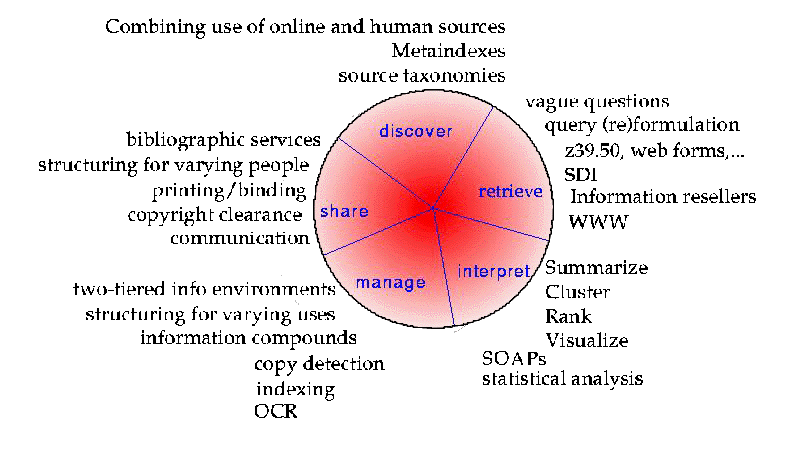
This time, the circle is annotated with requirements and some technologies under development or in use throughout the research and commercial communities. SDI stands for Selective Dissemination of Information. SOAP stands for Seal Of APproval, and OCR stands for Optical Character Recognition.
The challenge for Digital Library research is to allow users to move freely in the circle space to get their work done. In general, users will be involved in multiple tasks at the same time. They will need to move back and forth among these tasks, and among the five areas of activity. They need to find, analyze, and understand information of varying genres. They need to re-organize the information to use it in multiple contexts, and to manipulate it in collaboration with colleagues of different backgrounds and focus of interest. Digital Libraries at their best will be a place to do this.



hdl://cnri.dlib/may96-paepcke