Robert C. Plotkin and
Michael S. Schwartz
IBM T.J. Watson
Research Center
Hawthorne, NY
D-Lib Magazine, May 1997
Note: This paper will be presented at the SMPTE '97 Conference in Sydney, Australia on Thursday July 3rd, 1997.
![]()
Abstract
Film, videotape and multimedia archive systems must address the issues of editing, authoring and searching at the media (i.e. tape) or sub media (i.e. scene) level in addition to the traditional inventory management capabilities associated with the physical media.
This paper describes a prototype of a database design for the storage, search and retrieval of multimedia and its related information. It also provides a process by which legacy data can be imported to this schema. The Continuous Media Index, or Comix system is the name of the prototype. An implementation of such a digital library solution incorporates multimedia objects, hierarchical relationships and timecode in addition to traditional attribute data. Present video and multimedia archive systems are easily migrated to this architecture.
Comix was implemented for a videotape archiving system. It was written for, and implemented using IBM Digital Library version 1.0. A derivative of Comix is currently in development for customer specific applications. Principles of the Comix design as well as the importation methods are not specific to the underlying systems used.
Contents
- The Comix Continuous Media Model
- Base Class and Extensions
Remap - Data Import to a Hierarchical System
The increasing number of applications of digital libraries for continuous media users require a standardization of the underlying database model to allow for coherent methods to extract and import data.
Historically, database systems in the media industries were employed to manage video, or other physical media for inventory purposes. With the rapid growth of digital editing solutions and desktop computing, data access and management has migrated from the computer room to editors, reporters, stock footage consumers and other users in the continuous media community.
Contextual data about the content of managed assets in legacy systems was part of the base system design, or followed soon afterwards. These enterprise systems predated the availability of image compression or delivery mechanisms, and so sometimes did not anticipate the need to index material in a finer granularity than 'tape' or 'story'. With the prevalence of MPEG-I and -II encoders and decoders as well as JPEG and M-JPEG systems, it is now a reality that content owners can index material with key frame or full-motion compression of data for supporting reference and delivery in a timecode aware manner.
This paper describes Comix, which is based on a hierarchical database class architecture and contains continuous media specific relationships. The object oriented approach allows for more structured search and retrieval of multimedia assets as well as a growth path for users to integrate new digital media types into their digital library systems.
Searching of the data is, in some regards, one of the key elements of a digital library. There is not much need for a library system if you can not get to the data, and get to it in a meaningful way! However, to facilitate the logical retrieval and access of the data once found, a well-defined database scheme needs to be in place. While this paper will not spend much time on the search aspects of the system, the implementation (and follow on system) employ numerous search engines for this purpose. The hierarchical design does facilitate the search process and organized retrieval of data by way of the process driven data organization. The design of the data schema is intended to match the more typical data interactions, and thus allow for more rapid data manipulations.
The design and implementation of this system exemplify the trend in database systems for media management. While more traditional database systems store the actual data, and thus comprise the whole data object, this new breed of media management systems provides a somewhat different function.
Solutions like this for a video tape archive store ancillary data about the asset (the physical tape on the shelf) and store digital representations of that asset in the database. The possibility to store multiple representations of the same original has far reaching implications and with that, more demanding database design requirements. For instance, a tape may have high-resolution editable format data as well as low-resolution browse-quality representations of a piece of media. Additionally, single frames, or even computer models used in the final form may be stored in the system. It can be seen, that some traditional storage methods may not allow for the easy access and management of the multiple digital representations of the original piece. The Comix prototype is designed to handle such current and potential future data requirements.
Comix was originally created as a set of software tools that define, populate and help administer a digital library database system for continuous media. Continuous media, for the purposes of Comix can be defined as multimedia material that has time associated with it such as film, video or audio. Ancillary material associated with the multimedia such as script text or still images (key frame representations) are also part of the continuous media family, when associated with a timecoded segment of material.
Where a traditional inventory control approach to this domain ends, Comix continues. Not only are the physical assets tracked, but digital representations, whether still images or full-motion video, are indexed in a time accurate manner.
In actuality, this model can be applied to other media types, but much of the infrastructure is designed for storing, referencing and retrieving continuous media data.
While no single database model will fulfill the requirements of all digital library customers, it is intended that for those in the continuous media fields, that the Comix database schema will provide a fundamental architecture for new design, conversion from legacy systems, and growth into new technologies.
The design of this system attempts to address the needs of customers such as:
- Film and Video Archives (Educational, Stock, etc.)
- Video Production
- Animation Production
- Asset Tracking
by providing a hierarchical approach to asset management, both from an informational approach (meta data about stored assets) as well as from a physical (inventory) one. Comix has a hierarchical data model. This model is constructed in the digital library by use of what Comix defines as base classes. These index classes are database tables with a certain number of fixed attributes (or table columns). By hard coding these base classes, Comix may rely on their existence for certain critical data manipulation algorithms such as data loading. The rationale for the base classes is process driven. By evaluating how various users in the continuous media industry access and use their data, it was natural to discern a pattern and create the base class design. Combining base classes and user defined base class extensions will allow for rapid architectural design and implementation for any enterprise or new digital library systems when the customers are in the business of using or managing continuous media.
It is critical for continuous media customers to be able to identify data within a piece of media (video) in a time coherent fashion. For instance if a clip is being viewed by a user, it is imperative that the user be able to retrieve specific information about the segment being viewed, not the entire tape in general. If a newscast is being viewed, then the timecode of the story needs specific reference. It is not satisfactory for a thirty minute tape to index ten separate stories as one blob of data. Each of the stories has a timecoded segment, and thus should have individual access.
Similarly, if a film studio has saved background information about a scene in a movie and has this information in the DL, then access methods to this information need to exist. For instance, if a computer model for some 3D animation is used for a scene, then when one is browsing the video and stops, a drill-down application must be able to identify the data associated with the particular scene.
Whereas typical digital library systems focus on multimedia component storage in addition to the necessary parametric and free text query, this system extends this basic database design to incorporate a generic timecode model that will allow for data to be indexed and referenced in a frame accurate manner.
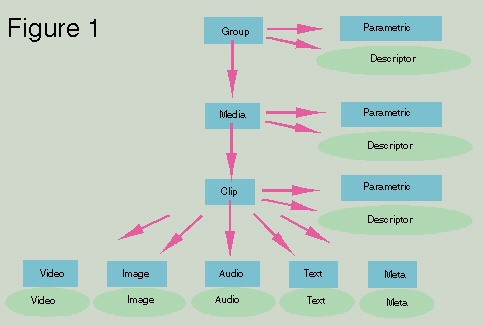
The class hierarchy shown in figure 1 is a simplified view of the relationships between continuous media database classes. The rectangles represent base and class extensions (to be explained in detail later) and the ovals represent objects stored in object servers.
Base Class |
Description |
Relation / Comment |
Group |
Information about a project, assignment, etc. |
Groups may contain groups. |
Media |
Physical information about video tape and format |
Many-to-one relation to a group. I.e. can be many ‘tapes’ to one project. |
Clip |
Timecode information. One chapter or section of material may be indexed. |
Many to one per media, but can map one clip to entire media or even group. |
Content: Video, Audio, Text, etc. |
Content specific information. Transcripts, Scripts, Video, Matte Paintings - anything that requires individual indexing. |
All content classes are associated to a clip. Many contents can be referenced to one clip allowing for timecode specific drill down. |
Parametric |
For many-to-one key word fields, there may be many user defined parametric classes. |
Reference to Clips, Media and Group for specific keywords |
Descriptor |
For the case where a simple predefined text description is not enough, a text blob may be attached to each of the base classes. |
A mirror of the first n characters may be stored with the base class for quick search and/or reference. |
Table 1 describes in detail the various class objects in the hierarchy.
One database design can not be applied to all cases, but one architecture may. The purpose of this system is not to replace user data fields with new ones, but to index user data fields in a system that allows for continuous media specific structured use and interaction.
The Dewey decimal system does not impose naming on books or topics, but allows a book library to store and retrieve materials in an organized way. Comix provides a design for a series of base classes and base class attribute fields. These base classes have a fixed hierarchical relationship that form the core of the storage and retrieval technology. The class definitions are process driven - that is, they are based on how users access their data.
Customization for any (and all customers) is through class extensions. All user data is correlated in accordance with the base class hierarchy. Methods are then provided to extend these base classes at the time of data importation.
Since the fundamental hierarchy is fixed, and because the key fields are fixed, sample code for data extraction and front ends can easily be duplicated for new instances of the database. This translates into rapid development times for custom installations in the continuous media field.
The base class hierarchy in its skeletal form may not meet the needs of all database implementations due to the implied single inheritance from clip to media to group. The raw model shows a one-to-one relationship from clips to media to groups. While groups may contain other groups, a scenario that occurs in real life, but is not implied by the base model, is the case where clips (or components) may relate to multiple groups. For instance, a script for a news segment may occur in multiple programs (groups) and thus will need reference to those groups. The data and index for this story should only be referenced once.
To solve this situation, the references from clip to media and group will allow multiple entries. A clip may have reference to one or many media and group elements, and a media element may have reference to one or many group elements.
In order to take a flat legacy data system and create a hierarchical database from it, it is necessary to 'remap' the old data to the hierarchical model of the Comix system.
The process for data importation is as follows:
- Export data from legacy system into tables representing the groups defined above, and for the customer, in a one-to-one mapping between columns of user data and new data.
- Run the importer on these tables so that the data can be indexed both into DB tables and by user reference.
Part one implies that the user has completely designed the new target architecture and that the user is capable of performing the appropriate SQL / report commands on the legacy system to create the appropriate tables.
The remap process, in simple terms, is a method by which data tables from a legacy system are imported to the new system. The essence of this process is that the original key information from the legacy system is preserved through the use of the remap files, and the speed by which the data can be imported and indexed is greatly improved over traditional techniques. The remap files are used in the load process to build cross reference tables in the new system - this cross reference file functioning as a performance enhancement for the new system.
A typical database system, such as DB2 allows you to construct views which can act as a cross reference between related tables. However, this process would be relatively slow if you are trying to obtain performance which is in the sub-second time range. The methods to materialize views are extremely slow when dealing with large databases and this causes you to create an intermediate table which in this case is the cross reference table. The cross reference table relates tables which are related by a common key.
Also, a view would become extremely complicated with unions to take care of all the cases which are needed to construct relationships. For instance in the case of 3 tables you have to consider when a key is in all 3 tables, when a key is in 2 tables and when a key belongs to only one table. There are 7 possible cases which means 7 different selects need to be written and a union has to be applied to each one. The general case deals with 2n-1 possible selects, where n is the number of tables, unioned together. With DB2 you can only join 15 tables together and with the remap process you can deal with as many files as you can have open at one time. This is another reason why the remap process is superior to the standard database techniques.
You could construct the cross
reference tables using standard database techniques as opposed to
using the remap process and will notice with 3 tables which are
at least 1 million rows each the database techniques are about
100 times slower than the remap process. With 4 tables it is
about 1000 times slower. This is the reason why the remap process
is a vast improvement over the standard database techniques.
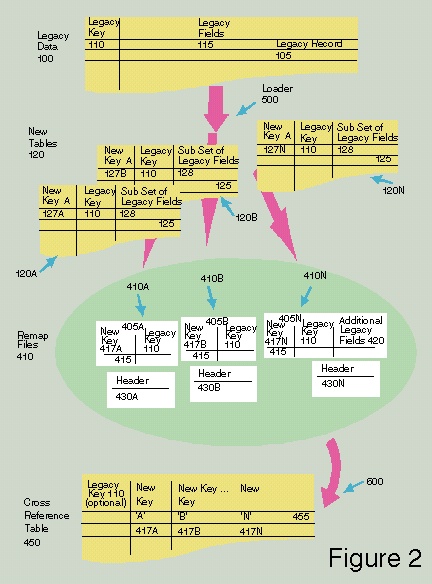
Figure 2 depicts how data is exported and loaded into a new database system. It also shows a cross reference table. This diagram shows the original data has an original key with user fields. The original key is a unique key for the table. The new tables are loaded from the original data into a database system which generates a new key for each table which contains a subset of user fields. The cross reference table is generated from these new tables by taking the new key from each new table and optionally the original key with all the new keys which share the same original key. The remap files are used to generate the cross reference table without performing an exhaustive search since the remap files were created during the loading of the new tables.
The need for external cross
reference tables may or may not be necessary depending on the
type of database system being used. For some object management
systems which do not have the rich relational operators, a
separate cross reference table may be necessary or desired to
enhance search and relational operators within the hierarchical
representation of the data.
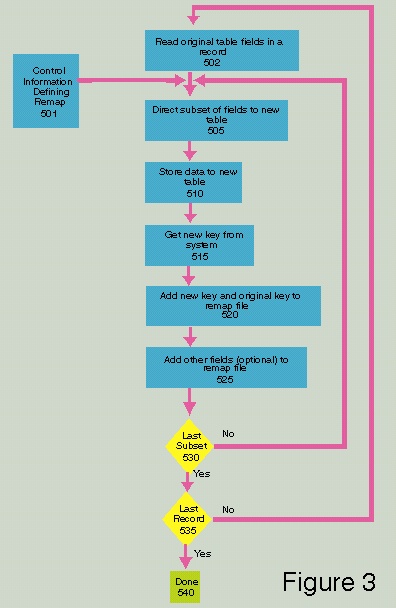
Figure 3 is a diagram of the data
remapping process. Box 502 reads a record containing the original
table fields. Box 501 contains control information defining what
fields are to be remapped to what remap file and which fields are
to be loaded into which table. Box 505 sets up a record which
contains a subset of fields which are to be stored into a new
table. Box 510 stores the data into the new table. Box 515
obtains the new key (system generated unique key) from the
database system. Box 520 adds the new key and original key to the
remap file which is used to build the cross reference table(s).
Box 525 adds other fields (optional) to the remap file if they
were specified in the control information for said remap file.
Box 530 asks whether this is the last subset for this record to
deal with. If not, one goes to Box 505 and creates another record
in a remap file which was specified in the control information.
Otherwise, Box 535 asks if this is the last record for this
table. If no, one goes to Box 502 and reads in another record and
uses the control information again to build the remap files.
Otherwise, one goes to Box 540 and one has built the remap files.
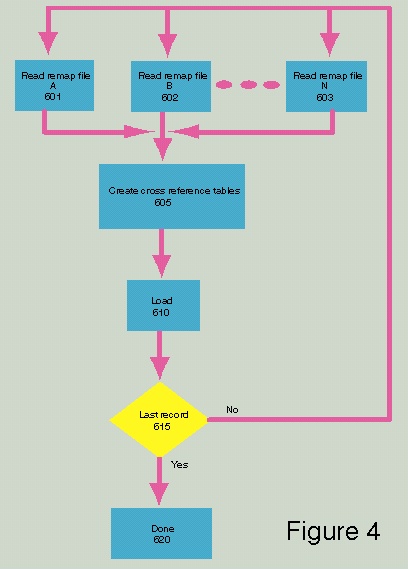
Figure 4 shows how the cross reference is generated from the remap files. Boxes 601, 602 and 603 show a set of remap files which one sorted by the original key. One opens and reads a record from each of the remap files. Box 605 creates a cross reference record which contains the new key from each remap file which had the same original key. This process does not require a search method it only needs to compare original keys in a linear fashion. Box 610 loads the record into the specified cross reference table. Box 615 asks if this is the last record. If not, one goes to boxes 601, 602 and 603 and continues the process of building the cross reference table. If yes, one goes to Box 620 and they are done.
While the remap process is intended as a means to load and re-index material quickly and efficiently, it also provides for enhancements in day-to-day operation of the new database system. The cross reference table that it generates enables one to perform a quicker search for a relationship between tables than performing joins. The cross reference table is a type of intermediate table which improves search performance. This an important enhancement and shows how the cross reference table is so important when dealing with multiple tables. It enables the reduction of the number of joins you would normally do to perform a search of tables for a general query.
The approach taken for the Comix design allowed for the implementors to create and administer data in a real world scenario. While many varying designs or design philosophies may be presented for solutions in this domain, the Comix model has shown success for a legacy database with the number of records in the 106 range.
The methods for data migration allowed for the rapid development and testing of the data model, and in some ways allowed for a much better data schema.
- The ability to import and then test large data sets is key in the development process, and usually not possible due to the time constraints involved in converting flat data models to hierarchical ones.
- Creating a fast and efficient method for data migration, regardless of target data model complexity, frees the designer to create an appropriate data model based on data relationships rather than data migration limitations. (It was estimated that using conventional conversion methods, the process would take 10 to 100 times slower for the prototype model. The authors believe that the migration process described would allow for arbitrarily large hierarchies in other cases, and while conventional methods would become cost prohibitive as far as the load time is concerned, the above method would not demonstrate the same slow down in performance.
It is not the intent of the authors to propose that this is the only or even the best solution for data management of video or other continuous media archives, however, the exercise of creating the prototype and testing the data model hypothesis with large samples of real world data showed that:
- Time is well spent testing the data model with large data sets before progressing to a final data design.
- Hierarchical data models for continuous media material are better than traditional flat data models.
- Hierarchical grouping allows quicker and more efficient solutions to queries because of the built in data relationships.
A patent application has been filed by IBM and the authors for the remapping process described in this paper.
The authors would like to acknowledge the help of JoAnn Brereton, from the Telecommunication and Media ISU of IBM for her invaluable help in the implementation of the prototype (and follow on) of Comix; to Bob Liang and Hamed Ellozy, the senior managers for the project, for their guidance and support; and to Ann Gan for her help in the user interface design.
C. J. Date. An introduction to database systems Volume 1, Fourth edition. 1990. Addison-Wesley. ISBN 0201513811.
IBM ImagePlus VisualInfo Application Programming Reference Volume 2, Version 2, Release 1. 1996. International Business Machines Corp. SC31-9061.
IBM Digital Library Application Programming Reference Volume 1. 1996 International Business Machines Corp. SC26-8652.
IBM Dictionary of Computing, Eighth Edition. 1987. International Business Machines Corp. SC20-1699.
IBM Database 2 Command Reference for common servers Version 2. 1995. International Business Machines Corp. S20H-4645.
Copyright and Disclaimer Notice
(C) Copyright IBM Corp. 1997. All Rights Reserved. Copies may be printed and distributed, provided that no changes are made to the content, that the entire document including the attribution header and this copyright notice is printed or distributed, and that this is done free of charge.
We have written for the usual reasons of scholarly communication. This report does allude to technologies in early phases of definition and development, including IBM property partially implemented in products. However, the information it provides is strictly on an as-is basis, without express or implied warranty of any kind, and without express or implied commitment to implement anything described or alluded to or provide any product or service. IBM reserves the right to change its plans, designs, and defined interfaces at any time. Therefore, use of the information in this report is at the reader's own risk.
Intellectual property management is fraught with policy, legal, and economic issues. Nothing in this report should be construed as an adoption by IBM of any policy position or recommendation.



hdl:cnri.dlib/may97-plotkin