|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Andrew Waugh |
![]()
AbstractThe Public Record Office Victoria (PROV) commissioned a digital archive in late 2005. During the design and implementation of this digital archive, considerable attention was paid to the ingest function that accessions digital objects into the archive. In particular, the archive was designed to process large transfers, and particular care was taken to support archivists in managing the transfer and handling the inevitable errors. In this article we describe the design of the ingest function, and the lessons we have learnt about ingest. 1. IntroductionThe Public Record Office Victoria (PROV) is the state archive of the Australian state of Victoria. It has a statutory responsibility for overseeing the creation and management of records for state government agencies, and for ensuring the preservation of records of permanent value to the state of Victoria. In 2001 the state government allocated $5.5 million Australian to PROV to obtain a digital archive. The contract to build the digital archive was awarded to Fujitsu Australia Limited (then DMR Consulting). The digital archive was commissioned in late 2005. The archive provides OAIS [6] compliant end-to-end digital archive functionality, from ingest, through management, to access. The digital archive was designed and implemented within the context of the Victorian Electronic Records Strategy (VERS) [18]. This strategy was developed by PROV in the late '90s to provide a framework for the long-term preservation of digital records. VERS prescribes for Victorian government agencies a preservation strategy that has the following elements:
This article describes the design and implementation of the ingest function of PROV's digital archive. The ingest function is defined in the OAIS model. It performs the process of accepting digital objects from producers and entering them into the digital archive. At PROV we believe that the ingest function is critical to the cost effective long-term preservation of digital objects. It is the conduit through which the objects pass into the digital archive and is crucial to the efficient transfer of those objects into permanent storage. If this function is utilised effectively, then it acts as a gatekeeper, ensuring that objects have consistency of structure, content and compliance with relevant business rules. If used ineffectively, on the other hand, it becomes a bottleneck, causing delays to what should ideally be a seamless and largely automated process. If the ingest function is too difficult for the producer of a digital object to use, producers appear to prefer to purchase more storage instead of transferring objects to an archive. This means few objects in the archive and probable eventual substantial loss of the objects as producers come up against the challenges of long-term preservation. On the other hand, too much flexibility in the ingest function means that the archive contains an inconsistent collection of objects, making management, preservation, and access difficult and expensive, or making it expensive to achieve consistency. The remainder of this article describes the ingest function of PROV's digital archive. The next section discusses the literature. Section 3 provides a description of the overall transfer process, of which ingest is a small part. Next, in Section 4, the ingest function is described at a high level, focussing on generic end-to-end issues. The following section describes the special features used to assist in ingesting very large transfers. This was a particular design focus as the ingest function is designed to process thousands of objects at a time, and even a small fraction of errors will overwhelm the ability to diagnose or repair the errors. The sixth section briefly describes lessons we learnt using a commercial EDMS as a basis for a digital archive, and Section 7 lists the design changes that we would make in hindsight. In all of these sections our experiences at PROV with what did work, and what did not are described. The article concludes with a summary of the major lessons from our experience in designing and implementing an ingest function for a digital archive. The design of the digital archive was a team effort, and I would like to thank my colleagues at PROV for many helpful comments about this article. 2. The literatureIngest is defined in the Open Archival Information Service (OAIS). The ingest entity provides: [...] the services and functions to accept Submission Information Packages (SIPs from Producers [...] and prepare[s] the contents for storage and management within the archive. Ingest functions include receiving SIPs, performing quality assurance on SIPs, generating an Archival Information Package (AIP) which complies with the archive's data formatting and documentation standards, extracting Descriptive Information from the AIPs for inclusion in the archive database, and coordinating updates to Archival Storage [i.e. permanent storage] and Data Management [i.e. indexing] (p4-1). The description of the ingest function in the OAIS reference model is at a very high level. In designing an actual implementation we found it most useful for orientation and as a checklist. The OAIS relationship between information producers and archives is further expanded in the Producer-Archive Interface Methodology Abstract Standard (PAIMAS) [7]. PAIMAS identifies the different phases of transferring information and defines the objectives, actions, and results of each of these phases. Two of the three phases relate to the negotiation of the transfer, not the actual ingest process. This abstract standard has been turned into a model transfer guide for university records by Glick and Wilczek [13]. This guide will be referred to as appropriate in the following sections, but in general the ingest function in our digital archive follows section B of the guide. The major difference is that we do not transform the incoming digital objects (as this is done prior to the ingest function), and that we perform the checks described in part B5 (Final Appraisal) much earlier to allow quick feedback to the producer. General guidance on ingest strategies is given by Erpanet in [11]. Actual implementations of ingest functions have received comparatively little attention in the literature. While the documentation of public domain systems such as Fedora [12] and DSpace [10] describe their ingest processes, these two systems are focussed on ingesting relatively small numbers of objects at one time and do not discuss the underlying design decisions. One particularly interesting published study on ingest is the Archive and Ingest Handling Test (AIHT), which was carried out as part of the U.S. National Digital Information Infrastructure and Preservation Program (NDIIPP) [2, 3, 4, 8, 15, 16, 17]. AIHT tested the feasibility of transferring a large collection (57,000 digital objects, roughly 12 gigabytes in size) from one digital archive to another. This test highlighted that even digital archives that normally ingested relatively small numbers of objects at one time could expect at some point to have to ingest huge collections. This would occur when collections were transferred (or duplicated) from one institution to another, or relocated from one digital archive to its successor; a very likely scenario with current technology refresh rates. Key lessons that apply to ingest from this test are referred to in appropriate sections of this article. 3. The transfer processAs an established archive, PROV has processes in place for transferring physical records covering the negotiation, management, and execution of the transfer. Most of these processes are format independent. For example, the judgement of whether a record is of permanent value to the state of Victoria does not change just because the record is (or is not) digital. Consequently, the ingest function was designed to fit in with the larger business process dealing with the transfer of records from the creating agencies to PROV. This allowed the design of the digital archive to focus on the technical issues of ingest. To give some idea of the relative complexities of transfer versus ingest, the model transfer guide [13] contains 31 pages on negotiating a submission agreement (i.e. the broader transfer process) and only 16 pages on the transfer and validation itself (i.e. ingest). We believe that the focus on the wider issues of transfer in PAIMAS [7] and the model transfer guide [13] makes the digital archive as a whole seem larger and more complex than, and separate from, the existing business of an archive. With VERS, PROV already had a well articulated and accepted strategy for digital records in the Victorian government. Consequently, the ingest function was naturally designed around the VEO format used in VERS as the submission information package (SIP) [19]. The VEO format is also used as the Archival Information Package (AIP) within our digital archive. This meant that our ingest function did not contain a SIP to AIP transformation process. VERS assumes that the normalisation of metadata and content occurs at the organisation transferring the objects, not at the archive. This decision was made on simple economic grounds. Even within Victoria, there are hundreds, if not thousands, of systems producing digital objects that could be transferred to PROV. Each of these systems potentially holds different metadata, and the content could be in any format. Further, the agency owning the source system has access to technical resources about the system, its metadata, and data formats that we do not have. PROV may not even have access to the applications necessary to open the formats used by the agency. Requiring producers to perform the normalisation focuses this cost where the resources, organisational knowledge, and expertise are available and the costs can be controlled. This approach contradicts one of the conclusions from the AIHT. In the AIHT, Shirky concluded that making requirements (specifically metadata requirements) on producers was counterproductive. Producers without the technical competence to undertake their own preservation would also be incapable of fulfilling complex requirements on submission conditions. Archives, he felt, would be forced to abandon their requirements, fulfil the requirements themselves, or forego preserving the digital objects. We agree that it can be difficult for an archive to require producers to fulfil submission requirements. However, we believe that the ingest function of a digital archive should be designed for the case where the submission requirements are met. In the situation where the producer cannot or will not meet the submission requirements, the archive can act as a surrogate and preprocess the digital objects into the required format. This drastically simplifies the design of the ingest function itself as it need only handle the 'normal' case. The complexity of meeting the submission requirements is then isolated in a separate module that can be tailored to each specific transfer situation. Finally, it is necessary to consider the handling of errors in the transfer process. The producer may not include agreed digital objects (or may include others); digital objects may be lost in the physical relocation to the archive; the archive may detect errors in digital objects during the ingest process; the ingest function may lose objects due to programming or operational errors; or the message accepting responsibility of the digital objects may be lost. To handle these situations we implemented a simple positive acknowledgement protocol. Until the producer receives a message from the archive accepting responsibility for a digital object, the producer must retain a copy of the object and be prepared to resubmit it until an acceptance message has been received. The digital archive must be prepared to receive multiple copies of a digital object and, if necessary, resend the acceptance message. This protocol ensures that digital objects are reliably transferred even though they may be lost by the producer, the physical transfer, or the ingest function. A useful by-product of this approach is that it also supports a robust disaster recovery model whereby the originator of the objects retains custody until final, permanent, secure storage of the objects. 4. The ingest functionThe initial design of the ingest function was based on the OAIS model, with certain ideas taken from the National Archives of Australia ingest function. The design, however, quickly evolved beyond this base. The key design goal for the ingest function was to cost effectively process large transfers. The eventual design has the following features:
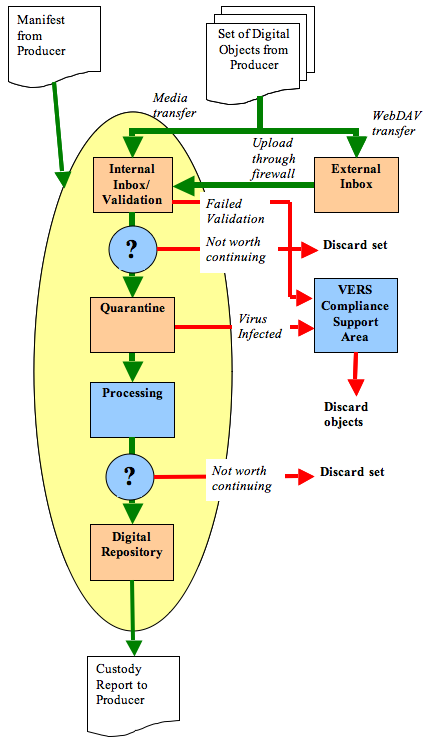
A diagram of the PROV ingest function is shown below.
The basic unit of work in the ingest function is the set. A transfer is composed of one or more sets, each of which normally contains many digital objects. The size of the sets is negotiated for each transfer between the administrator of the digital archive and the producers. This allows, for example, the size of a set to be tuned to optimise processing by the producer, during physical relocation, or processing at the archive (particularly optimising throughput). Sets are also used to resubmit digital objects within a transfer after they have failed to be ingested in a previous set. This forms part of the positive acknowledgement protocol mentioned in the previous section. Each set is described by a manifest that lists every object that is intended to be within the set. Ingest of a set commences with the receipt of the manifest. The manifest is loaded into the digital archive and triggers the creation of a new workflow job that will control ingest of the set. In addition, an initial report can be produced from the manifest to allow the archivist responsible for the transfer to check that the contents of the set are as agreed in the transfer agreement. Digital objects from the producer can arrive at the archive in two ways. They can be directly loaded across the internet to an external inbox using the WebDAV protocol over HTTPS. For security reasons, a separate inbox (with unique user id and password) is automatically created for each set when the manifest is loaded, and this inbox is automatically closed once all the objects have been uploaded. From the external inbox the objects are automatically staged through the firewall to an internal inbox. Alternatively, digital objects can be submitted on physical media (CDs, DVDs, Ultrium LTO tapes, or DDS tapes) and the objects directly loaded by an administrator to the internal inbox. The objects are validated as they are loaded into the internal inbox. Validation is a quality control check to ensure minimum standards on the objects being entered into the digital archive. It is equivalent to part B2 (Validation) of Glick and Wilczek's model guide. The minimum standards will be different for each archive, but at PROV they are that:
One limitation of our current validation processing is that we do not use a format validation tool such as JHOVE [9, 14] or DROID [5]. This is of concern to us, as one of the findings from the AIHT was that it was common for the format of objects to be incorrectly described. Format validation is also important in VERS, as we impose restrictions on the features allowed to be used in formats in order to reduce the difficulties of long-term preservation. While it was intended to incorporate a format validation tool, a suitable test environment was not available during the implementation of the digital archive. After validation, the sets become part of a workflow system that passes through three steps: quarantine, processing, and permanent storage in the digital repository. Before the workflow starts, however, there is a control point at which the transferring archivist has the option to cancel processing of the set. In making this decision, the archivist uses two reports produced as a result of loading the set into the internal inbox. The first report 'Reconcile Set Report' has a number of sections. The first section lists the digital objects that were missing from the set and the digital objects that should not have been present. The second section lists the result of the validation for each digital object. The third section lists each unique error encountered in validating the set and, for each error, lists the affected digital objects. The final section summarises the earlier sections, giving the number of digital objects for each error, which is particularly useful in determining the overall health, or otherwise, of the sets. The second report 'Set Report' lists each object and gives each error (if any) that was found in the object. After examining the reports, the transfer archivist can approve the movement of the set from the inbox to the quarantine area or delete it. Approved sets move to the quarantine area. Here they are isolated for a period of time (currently one week) before they are checked for viruses a second time. This quarantine period was inspired by the National Archives of Australia digital archive and is intended to provide a period in which new viruses can be identified and appropriate tests developed. The value of the quarantine period is the subject of much debate within the team as digital objects passing to an archive can be expected to be of significant age. Hence an additional week or month of quarantine is unlikely to catch any additional infections. Objects that pass the second virus check are passed to the processing area. In the initial design, only one virus scan was performed (at the end of the quarantine period), and the validation report was produced when the set moved into the processing area. This was logical as the transfer archivist could then inspect and perform minor repairs to the set in the processing area. The problem was that no feedback could be given to the producers of the digital objects until the expiration of the quarantine period. This was considered to be very unresponsive, and so validation processing was moved to the inbox, a second virus scan was added, and a control point was added prior to the quarantine area. Abrams [1] supports this by suggesting that validation should occur at (or before) point of deposit as the earlier errors are caught, the easier and cheaper they are to fix. The processing area allows archivists to examine the objects in a set, group objects with particular characteristics, perform minor corrections to the metadata, delete objects from the set (e.g. that are not wanted or have errors), and perform management functions such as setting access status. It is equivalent to part B5 (Final Appraisal) of Glick and Wilczek's model guide. It should be noted that to prevent infection of PROV's systems, the ingest workflow function does not allow archivists to examine the content of digital objects while they are in the inbox or quarantine areas, that is, prior to being virus checked. The processing area is consequently the first place that the content of the digital objects can be examined. There is a second control point at the end of the processing area. Once the transfer archivist is satisfied with the set, they can approve the movement of the set to the digital repository. Alternatively, they can delete the set from the ingest function if it is decided that it is not worth continuing to process the set. During the move to the digital repository, the records are stored in two geographically dispersed sites with automated failure detection and recovery. At this point PROV can be confident that the digital objects are securely stored and we can formally take responsibility for preservation (custody) of the objects. This is achieved by sending the producer a Custody Report that lists the identifiers of every digital object within the set for which responsibility has been accepted. Receipt of this document allows the producer to delete (if desired) its copy of the digital object. Movement to the digital repository is equivalent to part B4 (AIP Formation) and B6 (Formal Accession) of Glick and Wilczek's model guide. An archive should only accept responsibility for digital objects when they have been permanently stored. If it accepts responsibility when the digital objects are received, the ingest function must be absolutely reliable and can never lose objects. This dramatically increases the complexity and development cost of the ingest function (including the storage system that supports the ingest function), and magnifies the scope for operator error. In addition, it makes the interaction with the producer more complex as objects transferred in error (or with errors) must be formally transferred back to the producer. Finally, the digital archive produces a report that lists the fate of every digital object received in a set. The validation report, the custody report, and this reconciliation report are retained by PROV to document the ingest of this set. Digital objects that fail validation or virus checking are automatically removed from the set to the VERS compliance support area (VCSA). Here archivists can examine the objects to determine the cause of the failure. The producer is notified of the results of this investigation so that the producer can correct the problem and resubmit the failed objects in a new set. Objects in the VCSA are eventually discarded. Archivists can also manually remove and discard digital objects from the set in the processing area. This might occur, for example, if the objects had been transferred in error. All operations performed on digital objects during ingest are captured in an audit log. We found that it was important to generate specific archival audit events (e.g. that validation was performed and the result), rather than capture the low level system events (e.g. document checked out) automatically generated by the system. The problem with capturing low level events was that it was difficult to determine what happened, particularly as the sheer number of events obscured the higher level archival events. The downside of capturing all events on all digital objects is that the audit table is the single largest-growing table in the database supporting the digital archive. We plan to review what events are being recorded, and when and how the audit table can be archived (if at all). 5. Bulk processingA key design decision was that the digital archive would be capable of ingesting very large collections of objects (normally between 1,000 and 100,000 objects). This reflected the existing practice of ingesting physical records. Negotiations with agencies since the digital archive has gone live have supported this decision. In part, such large collections reflect the administrative overhead in setting up a transfer, including negotiation, and performing quality assurance. The digital archive was carefully designed to minimise the management overhead of transferring very large collections. All operations are performed upon groups of digital objects, primarily the set. A particular issue with processing large sets is the handling of errors. As the AIHT final report noted "even small errors create management problems in large archives". We recognised in the design phase that with large sets even a very low error rate would overwhelm the archivist's ability to isolate and diagnose problems. With 10,000 objects, even a 1% error rate would mean 100 failed objects. To find and isolate these individual objects would be a challenge, and then there was a further challenge to inspect the failed objects and determine the error. We also recognised that the opposite situation (a high error rate) was equally challenging. Consider a 10% error rate on a 10,000 object collection. This would mean 1,000 failed objects that would have to be individually removed from the set – a challenging task to perform manually – and then the cause of the error would have to be determined for each of these objects. Considerable thought was given to the handling of errors with the goal of reducing the workload on the archivist attempting to isolate the failed objects and diagnose the problem. The approach taken was to group together objects with the same failure mode and to process them as a group. During validation a group is created within the set for each failure condition encountered. The failed object is linked within each applicable failure group. An object may have multiple failures, and in this case it would be placed in several failure groups. If the failure is catastrophic (e.g. virus infection, or a DTD failure), the group is created in the VERS compliance support area and the object is removed from the set. If the failure is minor (e.g. an inconsistency amongst the metadata), the group is created within the set in the processing area. In either case, the archivist can examine a representative sample of the failed objects within the group to determine the cause of the failure. Once the failure has been identified, the entire group can be repaired (in the case of a minor failure in the processing area) or deleted. The reports generated by the ingest function are the key for an archivist to understand what is happening to a set as it is ingested. Consequently the organization of the information in the reports requires careful thought. We have found that it is particularly important to collect together all the instances of particular errors so that frequently occurring warnings do not obscure rarer more serious errors. Instance counts assist the archivist in understanding the seriousness of a particular error; does it affect all objects, or only a few? 6. The technologyThe digital archive, including the transfer process, was implemented using Documentum, a commercial off the shelf electronic document management system (EDMS). In retrospect, the use of a commercial EDMS as the basis for a digital archive had both positives and negatives. The advantage was that an EDMS provides a rich pool of well implemented and tested modules. The contractors estimated that the use of these modules saved around half of the code development. The disadvantage is that the fundamental operational model of a commercial EDMS is different from that of PROV's digital archive. An EDMS is designed to operate on a single object at one time. A typical use scenario is that the user checks out a document from the repository, edits it, and checks a new version back into the repository. This single object at a time model is in stark contrast to PROV's digital archive where the focus is on processing objects in bulk – performing the same operation on thousands of objects at the same time. Consequently, a very significant amount of code needed to be written to wrap these single operations into operations that could work on collections of objects, particularly in handling partial failures gracefully. This custom code is, of course, an ongoing maintenance problem, and reduces throughput. Additionally, by wrapping a customised bulk processing capability around the existing single-object processing capabilities in Documentum, we haven't actually optimised the core processing of each object. There are likely to be much more efficient ways of doing this that we cannot access via our existing solution. 7. LessonsSince we have commissioned the digital archive, experience with ingesting digital objects has suggested the following:
8. ConclusionIn our experience with designing, implementing, and using an ingest function, we have found that the following features are important for digital archives that must ingest large numbers of digital objects:
9. References1. Abrams S, Knowing what you've got: format identification, validation, and characterisation, Joint DCC/LUCA Workshop, 2006, <http://www.dcc.ac.uk/events/archives-2006/Abrams_LUCAS-2006.ppt> visited 12 October 2007. 2. Abrams S (et al), Harvard's Perspective on the Archive Ingest and Handling Test, D-Lib Magazine, December 2005, Vol 11 No 12, <http://www.dlib.org/dlib/december05/abrams/12abrams.html> visited 12 October 2007. 3. Anderson M, LeFurgy B, The Archive Ingest and Handling Test: Implications of Diverse Content and Diverse Repository Practice, Joint Conference on Digital Libraries (JCDL) 2006, <http://sils.unc.edu/events/2006jcdl/digitalcuration/Lefurgy_jcdl_paper_3_wgl%20_2_.pdf> visited 12 October 2007. 4. Anderson R, Frost H, Hoebelheinrich N, Johnson K, The AIHT at Stanford University, Automated Preservation Assessment of Heterogeneous Digital Collections, D-Lib Magazine, December 2005, Vol 11 No 12, <http://www.dlib.org/dlib/december05/johnson/12johnson.html> visited 12 October 2007. 5. Brown A, Automatic Format Identification Using PRONUM and DROID, Digital Preservation Technical Paper 1, The National Archives, 7 March 2006, <http://www.nationalarchives.gov.uk/aboutapps/fileformat/pdf/automatic_format_identification.pdf> visited 12 October 2007. 6. CCCDS, Reference Model for an Open Archival Information System (OAIS), Consultative Committee for Space Data Systems, Blue Book, January 2002, <http://public.ccsds.org/publications/archive/650x0b1.pdf> visited 12 October 2007. Also published as ISO 14721:2003. 7. CCCDS, Producer-Archive Interface Methodology Abstract Standard, Consultative Committee for Space Data Systems, Blue Book, May 2004, <http://public.ccsds.org/publications/archive/651x0b1.pdf> visited 12 October 2007. 8. DiLauro T, Patton M, Reynolds D, Choudhury G.S, The Archive Ingest and Handling Test, The Johns Hopkins University Report, D-Lib Magazine, December 2005, Vol 11 No 12, <http://www.dlib.org/dlib/december05/choudhury/12choudhury.html> visited 12 October 2007. 9. Donnelly M, JSTOR/Harvard Object Validation Environment (JHOVE), Digital Curation Centre Case Studies and Interviews, March 2006, <http://www.dcc.ac.uk/resource/case-studies/jhove/case_study_jhove.pdf> visited 12 October 2007. 10. DSPACE, DSPACE System Documentation: Functional Overview, <http://www.dspace.org/index.php?option=com_content&task=view&id=149> visited 16 May 2007. 11. ERPA, Ingest Strategy, erpaGuidance, Electronic Resource Preservation and Access Network, September 2004, <http://www.erpanet.org/guidance/docs/ERPANETIngestTool.pdf> visited 12 October 2007. 12. Fedora, Ingest and Export of Digital Objects, Fedora 2.2, <http://www.fedora.info/download/2.2/userdocs/digitalobjects/ingestExport.html> visited 12 October 2007. 13. Glick K, Wilczek E, Ingest Guide for University Electronic Records, Version 3, Fedora and the Preservation of University Records, 2005, <http://dca.tufts.edu/features/nhprc/reports/3_1_draftpublic2.pdf> visited 12 October 2007. 14. HUL, JHOVE – JSTOR/Harvard Object Validation Environment, <http://hul.harvard.edu/jhove/> visited 12 October 2007. 15. Nelson M, Bollen J, Manepalli G, Haq R, Archive Ingest and Handling Test, The Old Dominion University Approach, D-Lib Magazine, December 2005, Vol 11 No 12, <http://www.dlib.org/dlib/december05/nelson/12nelson.html> visited 12 October 2007. 16. Shirky C, AIHT: Conceptual Issues from Practical Tests, D-Lib Magazine, December 2005, Vol 11 No 12, <http://www.dlib.org/dlib/december05/shirky/12shirky.html> visited 12 October 2007. 17. Shirky C, Library of Congress Archive Ingest and Handling Test (AIHT) Final Report, June 2005, NDIIPP, <http://www.digitalpreservation.gov/library/pdf/ndiipp_aiht_final_report.pdf> visited 12 October 2007. 18. PROV, Management of Electronic Records PROS 99/007 (Version 2.0), Public Record Office Victoria <http://www.prov.vic.gov.au/vers/standard/version2.htm> visited 12 October 2007. 19. Waugh A, The design of the VERS Encapsulated Object, Experience with an Archival Information Package, International Journal on Digital Libraries, Volume 6 No 2, April 2006, p184-191 <doi:10.1007/s00799-005-0135-y>. Copyright © 2007 Public Record Office Victoria |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/november2007-waugh
|