 |
D-Lib Magazine
November/December 2014
Volume 20, Number 11/12
Table of Contents
Discovering and Visualizing Interdisciplinary Content Classes in Scientific Publications
Theodoros Giannakopoulos, Ioannis Foufoulas, Eleftherios Stamatogiannakis, Harry Dimitropoulos, Natalia Manola and Yannis Ioannidis
University of Athens, Greece
{tyiannak, johnfouf, estama, harryd, natalia, yannis}@di.uoa.gr
doi:10.1045/november14-giannakopoulos
Printer-friendly Version
Abstract
Text visualization is a rather important task related to scientific corpora, since it provides a way of representing these corpora in terms of content, leading to reinforcement of human cognition compared to abstract and unstructured text. In this paper, we focus on visualizing funding-specific scientific corpora in a supervised context and discovering interclass similarities which indicate the existence of inter-disciplinary research. This is achieved through training a supervised classification — visualization model based on the arXiv classification system. In addition, a funding mining submodule is used which identifies documents of particular funding schemes. This is conducted, in order to generate corpora of scientific publications that share a common funding scheme (e.g. FP7-ICT). These categorized sets of documents are fed as input to the visualization model in order to generate content representations and to discover highly correlated content classes. This procedure can provide a high level monitoring which is important for research funders and governments in order to be able to quickly respond to new developments and trends.
Keywords: Text Mining, Text Visualization, Funding Mining, Classification, Dimensionality Reduction, Scientific Corpora
1. Introduction
One of the most important tasks in data mining applications, especially when large datasets are involved, is visualizing the textual content. In general, this is a way of representing what particular document corpora refer to, in terms of content, which has obviously major importance for a wide range of textual information available in the Web. When it comes to the particular case of scientific documents, the respective text analytics and visualization tasks [2, 7, 6, 3] are particularly interesting due to their content richness and diversity. Modern digital libraries that store scientific documents are not limited to simple searching and storing functionalities but also try to provide text mining facilities that result in either semantic enrichment of the scientific content or high-level content statistics and visualizations. Such infrastructures help research funders, scientists, researchers and policy makers to understand content changes and trends.
In this paper we present a method for discovering interdisciplinary research efforts through a supervised text classification and visualization technique. In particular, we adopt a well-defined classification system and scientific dataset, namely the arXiv library. This is a rather simple categorization covering a wide range of content 130 classes from Computer Science, Biology, Physics, etc. Our purpose is to visualize the content of text corpora and to extract and visualize strong correlations between different content classes (e.g. between computer vision and biology). This is achieved through a supervised classification/visualization procedure, using the arXiv dataset as training data and classification scheme. In the sequel, a simple funding mining module is used to extract sets of publications that share a common funding scheme. This is used input to the classification-visualization module that generates content representations and discovers interclass content similarities.
The proposed system has been implemented under the OpenAIREplus EU project titled, "2nd-Generation Open Access Infrastructure for Research in Europe" (283595). This EU project aims to build an information infrastructure of scientific publication and data repositories and to implement EC's open access policies through services that effectively connect publications to scientific data and funding information. This is achieved through text mining techniques towards the automatic classification, indexing and clustering of scientific corpora, funding information mining, content visualization and link mining. In the context of such an infrastructure, such visualization applications can be rather useful tool for research administrators, especially in the case that such techniques are connected to funding schemes. In particular, it can assist the research administrators in the process of strategy or policy making, since it will provide them with an optical description of the content distribution for particular funding schemes.
2. Method
2.1 Supervised Classification and Visualization
The core of the automatic text classification and visualization functionality has been already described in [4], so please resort to that publication for further details. Here, we give a brief description of this supervised procedure. In, general the purpose of the classification-visualization module is:
- to provide a simple way of text classification. This is achieved through a typical text feature extraction sequence of procedures (tokenization, stopword removal, stemming and word frequency extraction). This is followed by a simple classification step, equivalent to the Naive Bayes classifier [8]
- to represent the content of each document class in the 2D space. This is achieved through a supervised dimensionality reduction technique [4]. based on clustering and Self-Organizing-Maps [5]. The result of this step is a pair of coordinates in the 2D space for each class of the supervised task.
Both the classification and visualization steps are supervised; therefore, a predefined taxonomy is needed. In this work we have selected to use the arXiv classification scheme. This is a large archive for electronic preprints of scientific publications, covering a wide range of fields. The arXiv categorization is rather simple: 2 levels of hierarchy with a total of almost 130 class labels in the second level. These 2nd level labels are organized in 7 general categories (let us call them superclasses from this point), for example "Computer Science—Data Structures and Algorithms". We have simply used the 2nd level labels, without taking into consideration the hierarchical structure of the taxonomy. In total, around half a million of abstracts have been used for training both the classification and visualization functionalities.
2.2 Inter-class similarity and normalization
The aforementioned joint classification visualization process is used to classify an unknown document to a set of classes, each one of which has been statically mapped to a 2-D point so that similar classes correspond to close points in the 2-D space. Each time, the module provides soft outputs, i.e., class probability estimations, and represent each of the classes in the 2-D space. So in order to extract corpora text visualizations, we simply need to apply this procedure to a set of documents: this results in a set of output class probabilities, therefore the whole corpus is represented by triplets of (a) average 2-D class coordinates and (b) a respective aggregated class probability. In addition, in order to discover interclass similarities, for each document we store the k highest class probabilities, where k is a user-defined parameter. This is stored in a interclass similarity matrix CSM, each element CSM(i,j) of which corresponds to the aggregated sum of class probabilities P(i) and P(j) for the cases that classes i and j have co-appeared in the same document.
Then this aggregated interclass similarity matrix is normalized based on the initial class visualization coordinates that have been extracted in a supervised manner during the training phase. In particular, each interclass similarity element is normalized based on an exponential distribution of the distance between the two corresponding class points that have been calculated during the training phase:
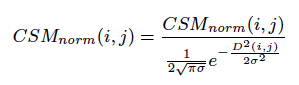
where D(i,j) is the Euclidean distance (in the 2-D space) between the class representations, as they have been extracted during the training of the visualization model. The meaning of this process is to emphasize interclass similarities that correspond to "apriori" (i.e. based on the training data) dissimilar content classes. An example of this normalization process is shown in Figure 1 where two graphs are presented: (a) the original interclass similarity graph (based on the aggregation process described above) and (b) the normalized interclass similarity graph based on the apriori class positions in the 2-D visualization space. The initial similarity graph has groups of nodes (content classes) from the same arXiv superclass compared to the normalized graph where the distant classes are promoted. These graphs are presented here to indicate the change that results from the normalization process. However, we have selected to use chord diagrams as the final representation method, as they provide a sufficient way to illustrate directed or undirected relationships among a group of entities (in our case content classes).
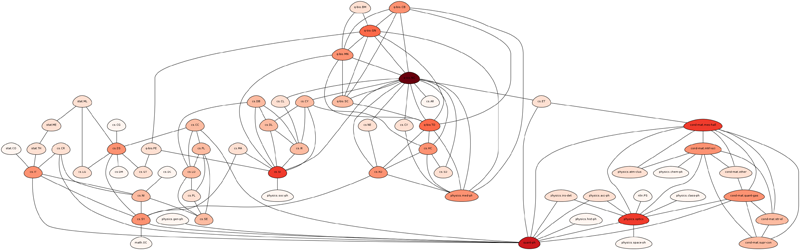
Figure 1: Graph that visualizes the normalization process performed on the interclass similarities.
(View larger version of Figure 1.)
2.3 Fund mining
The content classification, visualization and inter-class similarity extraction is performed on set of documents. As stated before, in this paper we focus on funding-specific scientific publications. This is the purpose of the fund mining module: to detect and recognize funding schemes for every input text. The initial aim was to identify EU FP7-funded documents, however, recently this was extended to also include Wellcome Trust projects.
The funding mining module first does some pre-processing (stop word removal, etc.) on the text of each publication and it then scans the text to extract possible matches using patterns, and it finds matches against the current known lists of project grant agreement numbers and/or acronyms for various funding bodies. Contextual information is also used in order to provide a confidence value for each match and to filter out any false positives. The funding mining submodule has been extensively evaluated against a large number of publication corpora from library resources (arXiv, PLoS, etc.). The resulting accuracy was over 99%. More information on algorithmic details and implementation issues can be found in [4].
3. Dataset
We have adopted the arXiv dataset and classification scheme for training the supervised models. For demonstrating both the content visualization and funding mining modules, we have used (a) an independent subset of the arXiv data archive and (b) a subset of PubMed. The funding mining module has extracted in total more than 12 of fund-classified scientific documents, using three funding schemes, namely the PEOPLE, ICT and ERC funding categories. The detailed statistics of these datasets is shown in Table 1.
Table 1: Publication distribution per data provided and funding scheme
| Funding Category |
Number of Publications — ARXIV |
Number of Publications — PubMed |
| PEOPLE |
3490 |
1399 |
| ICT |
1403 |
920 |
| ERC |
3886 |
1516 |
4. Results
In this section, we present some of the visualizations and inter-class similarities statistics. For the shake of space economy, in the context of this paper we have only focused on a single funding scheme, namely the FP7-ICT funding category. We have chosen this particular funding scheme because of its plurality in subject areas and its huge number of funded projects (and therefore respective publications). Furthermore, the research areas of this scheme are well represented by the adopted supervised taxonomy (arXiv).
For comparison purposes, we are also presenting the corresponding visualization results for two additional datasets of particular domain-specific research areas:
- the European Signal Processing Conference (EUSIPCO), organized by the European Association for Signal Processing (EURASIP). This is a rather domain-specific and limited (in terms of interdisciplinary content) dataset. We have selected to present the visualizations of this set as a case of low-interdisciplinarity.
- a small corpus of publications related to cognitive computation. This is a research area of high interdisciplinarity, as it covers many areas from psychology, mathematics and machine learning.
Figures 2, 3 and 4 present the chord diagrams for the ICT, EUSIPCO and Cognitive Computation corpora respectively. The content classes are organized in a circular layout and links between them correspond to (normalized) inter-class similarities. Different colors correspond to different arXiv superclasses (e.g. Computer Science). A complete set of (clearer and interactive) visualizations can be found here. The highest interdisciplinarity between the classes of the Cognitive Computation dataset is obvious (as expected) from the existence of many inter-class links. On the other hands, the EUSIPCO dataset leads to a more non-interdisciplinary representation.
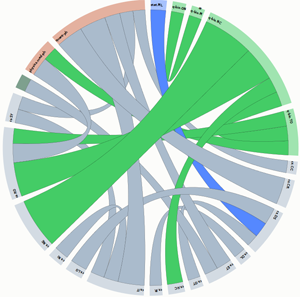
Figure 2: Chord diagram for the ICT dataset
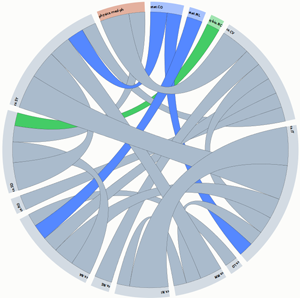
Figure 3: Chord diagram for the EUSIPCO dataset
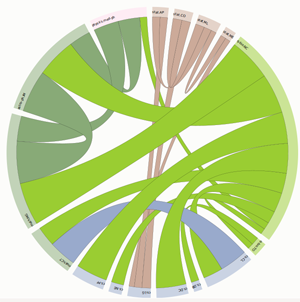
Figure 4: Chord diagram for the Cognitive Computation
dataset
Tables 2 and 3 present the most dominant pairs of similar arXiv classes in the corresponding dataset (ICT and EUSIPCO). These are the inter-class normalized similarities as described in Section 2. It can be seen that for the ICT funding scheme, there are obvious interdisciplinary links between several arXiv classes (e.g. robotics-neurons & cognition). For the case of the EUSIPCO dataset, most of the major inter-class similarities appear between classes of the same arXiv superclass, with an exception between computer vision and medical physics. A complete list of the arXiv subject classes and superclasses descriptions can be found in [1].
Table 2: Most important normalized inter-class similarities
for the ICT funding scheme
| arXiv class 1 |
arXiv class 2 |
Normalized Similarity |
| cs.NE |
q-bio.NC |
1.00 |
| q-bio.NC |
cs.RO |
0.67 |
| cs.RO |
physics.med-ph |
0.38 |
| cs.LG |
cs.DS |
0.33 |
| cs.HC |
q-bio.NC |
0.31 |
| stat.ML |
cs.DS |
0.30 |
| cs.NI |
cs.IT |
0.29 |
| physics.med-ph |
q-bio.TO |
0.28 |
| cs.SY |
cs.IT |
0.27 |
| cs.DL |
cs.IR |
0.24 |
Table 3: Most important normalized inter-class similarities for the EUSIPCO conference publications (years 2011 - 2013)
| arXiv class 1 |
arXiv class 2 |
Normalized Similarity |
| cs.IT |
cs.NI |
1.00 |
| cs.IT |
cs.SY |
0.88 |
| cs.CV |
physics.med-ph |
0.75 |
| cs.SD |
cs.SY |
0.72 |
| cs.SY |
cs.MM |
0.57 |
| cs.SD |
cs.NA |
0.53 |
| cs.IT |
cs.NA |
0.53 |
| cs.CV |
cs.IT |
0.44 |
| cs.SY |
stat.CO |
0.43 |
| cs.SD |
phys.med-ph |
0.41 |
| cs.NA |
cs.CV |
0.41 |
| cs.NA |
stat.ML |
0.40 |
5. Conclusions
We have presented a supervised method towards visualization and interclass similarity extraction for scientific corpora. The method has been trained on the arXiv dataset and classification system, while funding schemes have been extracted on more than 12K publications in order to generate the corpora that are used in the core mining procedures. Interclass similarity representations and corresponding measures have been presented for the ICT funding scheme, while for the shake of comparison, we have also illustrated content representations from a domain-specific conference.
6. Acknowledgements
The research leading to these results has received funding from the EU's FP7 under grant agreement no. RI-283595 (OpenAIREplus).
References
[1] arXiv. Cornel University Library article archive.
[2] K. W. Boyack, B. N. Wylie, and G. S. Davidson. Domain visualization using vxinsight® for science and
technology management. Journal of the American Society for Information Science and Technology, 53(9):764—774, 2002. http://doi.org/10.1002/asi.10066
[3] S. Fukuda, H. Nanba, and T. Takezawa. Extraction and visualization of technical trend information from research papers and patents. D-Lib Magazine, 18(7/8), 2012. http://doi.org/10.1045/july2012-fukuda
[4] T. Giannakopoulos, E. Stamatogiannakis, I. Foufoulas, H. Dimitropoulos, N. Manola, and Y. Ioannidis.
Content visualization of scientific corpora using an extensible relational database implementation. In Theory and Practice of Digital Libraries—TPDL 2013 Selected Workshops, pages 101—112. Springer, 2014.
[5] T. Kohonen. Self-Organizing Maps (3rd ed.). Springer-Verlag New York, Inc., 2001.
[6] F. Osborne and E. Motta. Exploring research trends with rexplore. D-Lib Magazine, 19(9):4, 2013. http://doi.org/10.1045/september2013-osborne
[7] R. M. Patton, C. G. Stahl, J. B. Hines, T. E. Potok, and J. C. Wells. Multi-year content analysis of user facility related publications. D-Lib Magazine, 19(9):5, 2013. http://doi.org/10.1045/september2013-patton
[8] I. Rish. An empirical study of the Naive bayes classifier. In IJCAI 2001 workshop on empirical methods in artificial intelligence, volume 3, pages 41—46, 2001.
About the Authors
 |
Theodoros Giannakopoulos received the Degree in Informatics and Telecommunications from the University of Athens (UOA), Greece, in 2002, the M.Sc. (Honors) Diploma in Signal and Image Processing from the University of Patras, Greece, in 2004 and the Ph.D. degree in the Department of Informatics and Telecommunications, UOA, in 2009. His main research interests are pattern recognition, data mining and multimedia analysis. He is the coauthor of more than 20 publications in journals and conferences and the coauthor of a book titled "Introduction to Audio Analysis: A MATLAB Approach". http://www.di.uoa.gr/~tyiannak/
|
 |
Ioannis Foufoulas (BSc in Informatics and Telecommunications, University of Athens, MSc student in Advanced Information Systems) is currently a research associate at the Department of Informatics and Telecommunications of the University of Athens. He participates in EU-funded project OpenAIREplus and he is interested in database systems, machine learning and data/text mining. http://www.johnfouf.info/
|
 |
Eleftherios Stamatogiannakis (Diploma in Electrical and Computer Engineering, National Technical University of Athens, School of Electrical and Computer Engineering) is currently a research associate at the Department of Informatics and Telecommunications of the University of Athens. He has participated in numerous EU-funded R&D projects (recently: OpenAIRE, OpenAIREplus, TELplus, Optique) as a research associate. http://www.madgik.di.uoa.gr/el/content/lefteris
|
 |
Harry Dimitropoulos (BSc(Eng) in Electrical & Electronic Engineering, City University London, MSc and PhD in Information Processing & Neural Networks, King's College London) is currently a research associate at IMIS, ATHENA RC and at the Department of Informatics and Telecommunications of the University of Athens; before 2003 he was a research associate at the Image Processing Group, King's College London. His present research interests include knowledge discovery, data mining, text mining, and data curation & validation. He has participated in numerous EU-funded R&D projects (recently: MD-Paedigree, OpenAIRE, OpenAIREplus, ESPAS, Health-e-Child), frequently as work-package leader and project management team member. http://www.madgik.di.uoa.gr/people/harryd
|
 |
Natalia Manola is a Senior Software Engineer holding a B.Sc. in Physics from the University of Athens, Greece, and an M.Sc. in Electrical and Computer Engineering from the University of Wisconsin at Madison, USA. Her professional experience consists of several years of employment as a Software Engineer, Software Architect, Information Technology Administrator, and Information Technology Project Manager by companies in various Information Technology sectors in the US and Greece. The systems she has designed and implemented include biotechnology and genetic applications, embedded financial monitoring systems, heterogeneous data integration systems and end-user personalized functionalities on digital libraries. She is currently the project manager of OpenAIRE/OpenAIREplus, and has participated and technically managed several R&D projects (DRIVER & DRIVER-II, ESPAS, CHESS) funded by the European Union or by the national government. http://www.madgik.di.uoa.gr/content/natalia
|
 |
Yannis Ioannidis is currently a Professor at the Department of Informatics and Telecommunications of the University of Athens. In early 2011 he also became the President and General Director of the ATHENA Research and Innovation Center; in addition, since April 2011, he serves as the Acting Director of the Institute of Language and Speech Processing of ATHENA. He received his Diploma in Electrical Engineering from the National Technical University of Athens in 1982, his MSc in Applied Mathematics from Harvard University in 1983, and his Ph.D. degree in Computer Science from the University of California-Berkeley in 1986. Immediately after that he joined the faculty of the Computer Sciences Department of the University of Wisconsin-Madison, where he became a Professor before finally leaving in 1999. His research interests include database and information systems, personalization and social networks, data infrastructures and digital libraries & repositories, scientific systems and workflows, eHealth systems, and human-computer interaction, topics on which he has published over one hundred articles in leading journals and conferences. He also holds three patents. Yannis is an ACM and IEEE Fellow (2004 and 2010, respectively) and a recipient of the VLDB "10-Year Best Paper Award" (2003). http://www.madgik.di.uoa.gr/people/yannis
|
|