 |
D-Lib Magazine
November/December 2015
Volume 21, Number 11/12
Table of Contents
PubIndia: A Framework for Analyzing Indian Research Publications in Computer Science
Mayank Singh, Soumajit Pramanik and Tanmoy Chakraborty
Indian Institute of Technology, Kharagpur, India
{mayank.singh, soumajit.pramanik, its_tanmoy}@cse.iitkgp.ernet.in
DOI: 10.1045/november2015-singh
Printer-friendly Version
Abstract
This paper describes PubIndia, a framework for analyzing the growth and impact of research activities performed in India in the computer science domain, based on the evidence of scientific publications. We gathered and analyzed a massive publication dataset of more than 2.5 million papers in the computer science domain with rich metadata information associated with each paper. Specifically, we attempted to analyze the temporal evolution of the collaboration pattern and the shift in research work among different topics, and made a thorough comparison between Indian and Chinese research activities. A preliminary analysis on a subset of papers on Natural Language Processing extracted from the large dataset revealed that Indian researchers tend to collaborate with researchers outside of India quite often; however Chinese researchers tend to work among themselves. We also show the evolutionary landscape of different keywords that indicate how the importance of individual keywords varies over the years.
1 Introduction
Computer science comprises a wide array of research areas ranging from the applied to the theoretical. Over the last fifty years, this domain has moved from infancy to adulthood. The history of this development is peppered with contributions that attempted to increase computational speed while significantly reducing the physical size of computers so that they could be more meaningfully used. Computer science is of central importance to India for its impact on the national economy and society at large, and its role in shaping India as a technology superpower. The landscape of the progress of Indian research is surely not flat; it would be interesting to thoroughly study how it has been influenced by global as well as subcontinental (e.g., China) research activities.
Many publications track research trends, analyze the impact of a particular paper on the development of a field or topic, and study the relationships between different research fields. The Web of Science has collected data since 1900 on nearly 50 million publications in multiple scientific disciplines and analyzed it at various levels of detail by looking at the overall trends and patterns of emerging fields of research and the influence of individual papers on related research areas. Several researchers have [5, 6] explored methods and visualizations for scientific research and analyzed the impact of each research area quantified by the collective cross-disciplinary citations of each paper. Recently, a few researchers attempted to analyze the trend of computer science research over the last five decades and more precisely drew relationships between funding and publications related to new topics [2, 4]. From an Indian perspective, research was conducted for the field of medicine [3, 7], and a thorough report was submitted by the Department of Science and Technology, Government of India, in order to study bibliometric indices of India's scientific publication outputs from 2001 through 2010.
In this paper, we describe PubIndia, a framework specifically for analyzing Indian research activities based on the evidence of scientific publications. For this purpose, we gathered and analyzed a massive publication dataset of papers in the computer science domain curated from Microsoft Academic Search (MAS). The crawled dataset contains more than 2.5 million papers along with rich metadata information about each paper — a unique index of the paper, the title of the paper, the name of the author(s), the affiliation of the author(s), the year of publication, the venue of publication, the related field(s)1 of the paper, the keyword(s) and abstract of the paper, and the references. After a series of initial preprocessing, the data was cleared and structured for computational purposes and was made publicly available as a shared dataset from CNeRG (see the "Resources" tab). In particular, we focused on the following research agenda:
- performing a comparative analysis of global research profiles, specifically for India and China;
- discovering how research in India has been influenced by subcontinental and global research and vice versa;
- discovering trends and patterns of collaboration by Indian researchers with subcontinental and other foreign researchers and how such intra- and inter-country collaborations affect overall research quality;
- studying the influence of funding on research performance;
- developing an India-specific knowledge repository;
- determing metrics for analyzing the progress in academic careers.
We aim to develop PubIndia as an analytical framework specifically for analyzing Indian research publications that will enable us to visualize the trend of Indian research activities from three different perspectives — author-specific, topic-specific and field-specific. In this study we focus on Natural Language Processing (NLP), one of the current and vibrant research areas in the computer science domain, and conduct a comparative analysis between the research in India, in China, and across world. Our initial analysis uncovered a series of interesting results. A few of them are:
- the average team size (average number of authors per paper) tends to be larger in Chinese research than in Indian research;
- although the absolute count indicates that the tendency to collaborate with the other researchers is higher for Chinese researchers as compared to Indian researchers, the normalized values strictly conform to the fact that around 43.5% of Chinese papers were coauthored by Chinese only researchers, while the same count among Indian researchers is just 22%;
- both China and India started with only two topics derived from Latent Dirichlet Allocation model; however from 2006 through 2010 the number of Chinese topics doubled compared to the Indian topics.
2 Dataset Description
We crawled one of the largest publicly available datasets, Microsoft Academic Search (MAS), which houses over 4.1 million publications and 2.7 million authors. We collected all the papers published in the computer science domain and indexed by MAS2. The crawled dataset contains more than 2 million distinct papers which are further distributed over 24 fields of computer science. Moreover, each paper is accompanied by a variety of bibliographic information: the title of the paper, a unique paper index, the named-entity disambiguated author(s) of the paper and their affiliations, the year and the type of publication, the related field(s) that the paper contributes to, the abstract and the keyword(s) of the paper, and the list of research papers that it cites. Besides analyzing the topics, one can also construct several academic networks such as a citation network, collaboration networks among authors and among institutes, a keyword-author bi-partite network, and so on. The process of data crawling, the pre-processing steps to clean the raw data and some general statistics pertaining to the dataset can be found here. As mentioned earlier, in this paper,we focus specifically on the set of papers related to Natural Language Processing (NLP) published between 1967 and 2010.
2.1 Demarcating papers by country
We collected all possible names (first names and surnames)3 of different nationalities (i.e., Indian, Chinese, Japanese, Polish, English, German, French, Russian, etc.) and prepared dictionaries for Indian and Chinese authors separately. We annotated each author with his/her nationality by matching the first name/surname in the dictionary. We manually annotated those names which did not appear in any of the dictionaries. Then we annotated each paper by one country (e.g. C) if at least one of the following two criteria is satisfied: (i) the first author of the paper belongs to C, (ii) majority of authors belong to C. The complete dataset in NLP contains 17,551 authors. Table 1 shows the statistics for authors after the annotation phase.
Table 1: Number of Indian and Chinese authors.
| Statistics |
Count |
| Indian Authors |
494 |
| Chinese Authors |
2,657 |
| Others |
16,260 |
3 Prototype of PubIndia
An initial prototype of PubIndia is available. At this time it has three major components: keyword evolution, topic distribution and research collaboration.
3.1 Keyword evolution
We extract all the scientific keywords associated with each paper present in our dataset. Furthermore, we use Kea, a keyword extraction tool on the text documents [8] and mine keywords from the abstract of each paper. The set of keywords includes only unigrams and bigrams. The "Keywords" tab points to the page where three options need to be selected:
- unigrams/bigrams
- 5-years time-window
- the number of keywords that the user wants to be displayed
The most frequent keywords are displayed using a pie chart (as shown in Figure 1(a)) along with their absolute (solid line) and percentage (broken line) counts. By clicking on each keyword, the user can observe the temporal evolution of the absolute and the percentage counts of that keyword as shown in Figures 1(b)-(c). For instance, the evolution landscapes of two unigrams, "Language" and "Translation" are shown in Figure 1(b) and Figure 1(c) respectively. Even though the overall usage count increases for both of them, the percentage usage of "Language" decreases significantly, whereas for "Translation", both the usage counts tend to increase. This is quite evident from the fact that the prior implementations of language-processing tasks typically involved the direct hand coding of large sets of rules, while the newer implementations are mostly based on statistical machine learning.
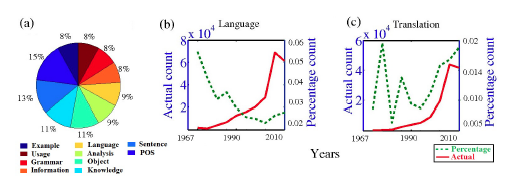
Figure 1: (a) Pie chart showing the keyword distribution in 2012; actual and percentage counts for two unigrams: (b) "Language" and (c) "Translation".
3.2 Topic distribution
An important question that has so far remained unanswered is whether the individual patterns of research topics of the countries/continents affect global behavior. Therefore, we further analyze how the shift of research topics in global research correlates with that of Indian and Chinese research. For this analysis, we collect the title and the abstract of each paper and make a separate document. Then we use Latent Dirichlet Allocation (LDA)4 [1] and extract 100 topics from the entire corpus. Note that a topic is represented by a set of most representative words. Then we tag each paper by its most probable topic. In the "Topic" tab, there are three options which need to be selected:
- whether the user wants to visualize topics per year or in a 5-year time window
- a particular year or a particular 5-year time window
- the number of topics that the user wants to be displayed
After selecting the parameters, a pie chart (as shown in Figure 2(a)) is generated with the probability of each topic in the selected year/time-window. If the user clicks on one of the topics in the pie chart, the word cloud corresponding to that topic is shown where the size of each word is proportional to the probability of that word being included in that topic as shown in Figure 2(b). At the bottom of the panel, a comparison is drawn to show how the percentage of research in that topic has progressed over the years worldwide vis-à-vis in India and in China as shown in Figure 2(c). A broad analysis on the topic distribution as shown in Figure 3 reveals an interesting observation that both China and India started with just two topics; however from 2006 to 2010, the number of Chinese topics doubled compared to the Indian topics. Thus we conclude that the Chinese are working on more diverse topics while the Indians remain focused on fewer topics.
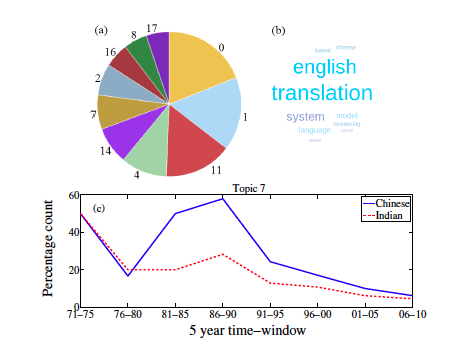
Figure 2: (a) Pie chart showing the topic distribution in a certain year/time window, (b) tag cloud for Topic 7, and (c) percentage count of research work conducted on Topic 7 in India and in China over the years.
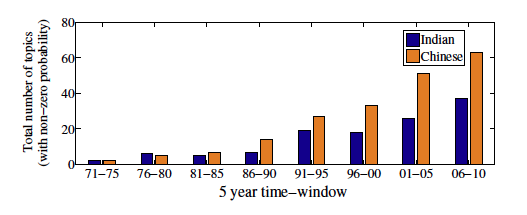
Figure 3: Total number of topics (with non-zero probability) in Indian and in Chinese research over the years.
3.3 Correlating different research activities
We further attempt to draw a correlation between the topical patterns of research activities in India and in China. As mentioned in Section 3.2, we extract the top 100 topics from both Indian and Chinese publications. Then for each topic, we conduct the following steps: we measure the fraction of papers published in that topic from 1967ѿ2010 individually for Indian and Chinese research; we use Pearson correlation to measure how the year-wise research patterns in India and China correlate with each other and with the global research pattern. Then we make an average of these correlation values for all the topics.
However, we posit that what is possibly more important is to investigate if a topic that is at the peak in India at any point in time emerges as the dominant one in China in the near future, or vice versa. This would then indicate that what one country finds important today is adopted by the other within a few years. In order to quantify the delayed similarity, we define the following two notations: lead(x, y, t): the event x took place t years before the event y; lag(x, y, t): the event x took place t years after the event y. For instance, lead(IND,CHI,4) indicates the correlation between the percentage count of papers in Indian research at t with that in Chinese research at t + 4 averaged over all the topics, that essentially indicates how the Indian research at a given point in time would affect Chinese research after 4 years.
In Table 2, we show the correlations by varying the time point t from 0 to 5. We observe that the global research is mostly aligned with the Indian research (Lead(GLO; IND; t) = Lag(GLO; IND; t) = 0.49) which is followed by the correlation between global and Chinese research.
Table 2: Pearson's correlation coefficient among the research trends (GLO: Global, IND: India, CHI: China).
| Pairs |
Time (t) |
| 1 |
2 |
3 |
4 |
14 |
6 |
| Lead (GLO,IND,t) |
0.49 |
0.39 |
0.29 |
0.25 |
0.06 |
0.05 |
| Lag (GLO,IND,t) |
0.49 |
0.03 |
0.07 |
0.07 |
0.10 |
0.08 |
| Lead (GLO,CHI,t) |
0.42 |
0.34 |
0.31 |
0.23 |
0.11 |
0.11 |
| Lag (GLO,CHI,t) |
0.42 |
0.12 |
0.05 |
0.14 |
0.25 |
0.04 |
| Lead (CHI,IND,t) |
0.25 |
0.14 |
0.13 |
0.14 |
0.11 |
0.08 |
| Lag (CHI,IND,t) |
0.25 |
0.19 |
0.22 |
0.13 |
0.12 |
-0.03 |
3.4 Effect of collaborations
With the exponential growth of the number of published papers over the years as shown in Figure 4(a), it has become a common practice among researchers to collaborate with researchers from other institutes. One of the early evidences of such collaborative research is the average team size per paper. We measure the average team size in a particular year by averaging the number of authors per paper published in that year. The result in Figure 4(b) shows an increasing trend for both countries, along with the global trend. We notice that the team size per paper tends to be higher in Chinese research as compared to the others, whereas Indian research tends to have a lower team size. Figure 4(c) makes the scenario even more clear by showing that the absolute number of cross-continent collaborative papers also increases with time.
The collaboration among global and Chinese researchers seems to be higher compared to the same among India and China. Surprisingly, a pattern of the normalized count of papers unfolds a completely opposite trend that Chinese researchers collaborate a lot with each other (around 43.5% of Chinese papers have been coauthored by only Chinese researchers), while the same collaboration measure among Indian researchers is just 22%. The conclusion is that even if the collaboration between China and the rest of the world seems to be larger due to the sheer volume of papers published by China every year, Chinese researchers are still confined to intra-country collaborations, which is rarely observed in India. However, the probability of forming collaborations among Indian and Chinese researchers is less. Similar comparisons in terms of the collaborative pattern can be found in the "Comparison" tab of PubIndia.
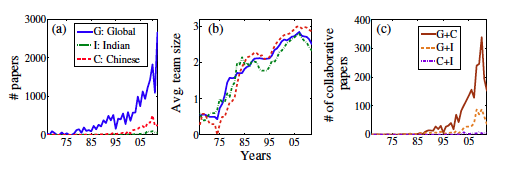
Figure 4: Increase in (a) the number of papers, (ii) the average team size and (iii) the number of collaborative publications over the years for India and China as compared to the global pattern.
4 Conclusions and Future Work
In this paper we described the initial design of PubIndia, a framework for analyzing scientific publications particularly related to Indian research and for comparing that research with other sub-continental research, such as that of the Chinese. In the preliminary version of this framework, we particularly focused on the papers related to Natural Language Processing and analyzed the collaboration pattern of Indian and Chinese researchers with each other, and with global researchers. We further analyzed the increase and decrease in the importance of different keywords over the years. While comparing the topical alignment among country-wise research activities, we observed that Indian research is mostly correlated with global research.
In addition to building the framework on the entire dataset, we intend to incorporate the following functionalities into our framework:
- Comparative analysis of researchers' profiles based on citations and h-index. We would like to compare the current career profiles of prolific Indian researchers in the computer science domain working in various parts of the world with the ones who have chosen to settle in India.
- Inclination to publish in top-tier venues and the success rate. This module would attempt to identify how much Indian computer science researchers are inclined to publish papers in top-tier publications. If they are found not to be successful, then the reasons should be identified.
- Comparative analysis of the reputation of publication venues (journals/conferences). Another important indicator of a country's standard of research is the quality of the conferences organized inside the country, and although recently the number of Indian publication venues has increased significantly, the important question of whether that growth is in line with the quality of the research in India can still be raised. This module would attempt to answer this question.
- Influence of funding on research performance. Despite significant investments from government and private agencies, and the importance of those investments to long-term economic growth, there is surprisingly little evidence indicating whether the expenditures have been utilized properly in research and development. Therefore, we intend to study:
- how government/private funding influences the present computer science research in India;
- how different the Indian funding policy is from that in China and abroad;
- the proportion of funds flowing from different agencies in comparison to the research output.
- Designing India-specific scientific knowledge repository. Finally, we would like to develop a public repository such as DBLP dedicated to Indian publications in the computer science domain. In addition, we would like to design a search engine such that Indian research could easily become noticed by the global research community.
Notes
1 The sub-areas like Algorithms, Artificial Intelligence, Databases constitute the fields of computer science domain.
2 The crawling process took around six weeks and was completed in August, 2014.
3 The major sources of collecting all possible names and surnames are as follows: http://20000-names.com, http://surnames.behindthename.com, http://genealogy.familyeducation.com and http://www.first-names-meanings.com.
4 We use "gensim" python library for LDA measure.
References
[1] D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation. J. Mach. Learn. Res., 3:993-1022, Mar. 2003.
[2] T. Chakraborty, S. Sikdar, N. Ganguly, and A. Mukherjee. Citation interactions among computer science fields: a quantitative route to the rise and fall of scientific research. Social Network Analysis and Mining, 4(1), 2014. http://doi.org/10.1007/s13278-014-0187-3
[3] B. Gupta and A. Bala. A scientometric analysis of indian research output in medicine during 1999-2008. J Nat Sci Biol Med, 2(1):87-100, 2011. http://doi.org/10.4103/0976-9668.82313
[4] A. Hoonlor, B. K. Szymanski, and M. J. Zaki. Trends in computer science research. Commun. ACM, 56(10):74-83, 2013. http://doi.org/10.1145/2500892
[5] J. Moody. The structure of a social science collaboration network: Disciplinary cohesion from 1963 to 1999. American Sociological Review, 69(2):213-238, 2004. http://doi.org/10.1177/000312240406900204
[6] A. Porter and I. Rafols. Is science becoming more interdisciplinary? measuring and mapping six research fields over time. Scientometrics, 81(3):719-745. http://doi.org/10.1007/s11192-008-2197-2
[7] K. Satyanarayana and A. Sharma. Biomedical journals in India: some critical concerns. Indian J Med Res., pages 119-122, 2010.
[8] I. H. Witten, G. W. Paynter, E. Frank, C. Gutwin, and C. G. Nevill-Manning. Kea: Practical automatic keyphrase extraction. In Digital Libraries, pages 254-255, New York, USA, 1999. ACM. http://doi.org/10.1145/313238.313437
About the Authors
|