|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Herbert Van de Sompel Carl Lagoze Jeroen Bekaert Xiaoming Liu Sandy Payette Simeon Warner |
![]()
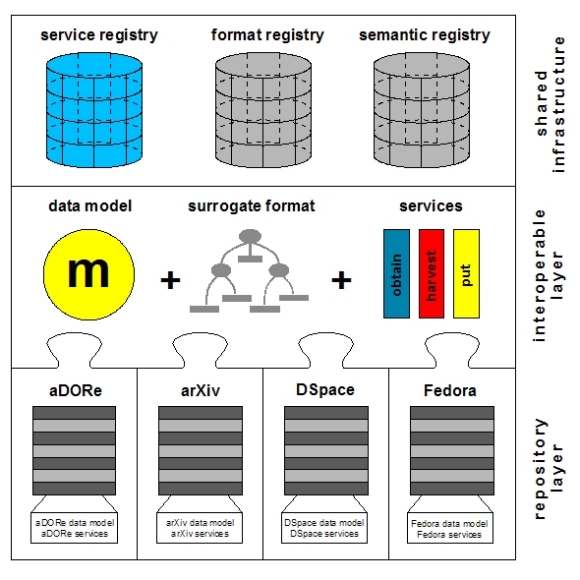
AbstractThis article describes an interoperability fabric among a wide variety of heterogeneous repositories holding managed collections of scholarly digital objects. These digital objects are considered units of scholarly communication, and scholarly communication is seen as a global, cross-repository workflow. The proposed interoperability fabric includes a shared data model to represent digital objects, a common format to serialize those objects into network-transportable surrogates, three core repository interfaces that support surrogates (obtain, harvest, put) and some shared infrastructure. This article also describes an experiment implementing an overlay journal in which this interoperability fabric was tested across four different repository architectures (aDORe, arXiv, DSpace, Fedora). We detail the implementation choices made in the course of this experiment. 1. Introduction and MotivationTwo years ago, in an opinion piece for D-Lib Magazine, we described our vision of a natively digital scholarly communication system enabled by an interoperable infrastructure with a wide variety of heterogeneous repositories as its foundation [1]. We described an infrastructure that would leverage the value of the digital objects hosted by those repositories by making them accessible for use and re-use in many contexts. In this infrastructure, repositories are not static components in a scholarly communication system that merely archive digital objects deposited by scholars. Rather, they are the building blocks of a global scholarly communication federation in which each individual digital object can be the starting point for value chains. Hence, scholarly communication itself is regarded a global workflow or value chain across repositories, with digital objects from repositories being the subjects of the workflow. This view of scholarly communication raises a variety of intriguing prospects and associated questions across the whole social-economic-legal-technical spectrum. The Pathways project funded by the US National Science Foundation focuses on the technical problem domain, thereby identifying the components required to facilitate the emergence of a natively digital, repository-based scholarly communication system. The research goal is to find the appropriate level of cross-repository interoperability that will provide the technical basis to realize the vision, and will stand a realistic chance of being implemented in existing and future repository systems. Our vision was inspired by the observation that the established scholarly communication system has not kept pace with the revolutionary changes that are occurring in scholarly research practices. A significant amount of scholarly communication has been brought into the digital realm. However, we argue that various properties of its paper-based ancestor were taken for granted in the transition, and were not challenged or revised in light of the fundamentally new capabilities offered by the digital, networked reality. Citation provides an obvious example of the possibility to rethink scholarly communication. In today's scholarly communication system, citation means including some textual information describing a cited paper at the end of the citing paper. These textual citations included in a digital manuscript are not natively machine-readable or machine-actionable. Various post-factum approaches have been devised to connect citing and cited papers by means of hyperlinks in the Web environment. These approaches include fuzzy metadata-based citation matching [2], the DOI-based CrossRef linking environment [3], and the OpenURL framework for context-sensitive linking [4,5]. The varying quality of citation metadata is just one of several reasons that the results of these approaches are less than perfect. Furthermore, these approaches are not easily extended into the realm of compound digital objects that contain datasets, simulations, visualizations and so forth. How should we rethink citation in a natively digital scholarly communication system? We think of citation as a particular type of re-use of the cited digital object in the context of the citing digital object. Imagine being able to drag a machine readable representation of a digital object hosted by one repository, and to drop it into the citing object that, once finalized, is ingested into another repository. Now imagine being able to do the same for the citing object, etc. Assuming that the machine-readable representations being dragged and dropped contain the appropriate properties, the result would be a natively machine-traversable citation graph that might span repositories worldwide. There are numerous other examples in scholarly communication of workflows across distributed repositories. These include the mirroring of digital objects for preservation purposes, the creation of repositories that host virtual collections of objects that are physically hosted in other repositories, the progression of units of scholarly communication through the registration-certification-awareness-archiving chain [1], and the re-use of datasets hosted by various repositories for the creation and publication of a new dataset. In order to enable such workflows, participating repositories will need some common interface to the world. Determining the nature of this interface is the subject of our Pathways explorations, and this article reports the insights that we have gained thus far. The remainder of this article is structured as follows. In Section 2, we introduce the core concepts of the Pathways interoperability infrastructure. In Section 3, we describe the choices that were made for the concrete implementation of these concepts to support an overlay journal workflow scenario. In Section 4, we describe the overlay journal environment and workflow. For a more detailed overview of the work reported, we refer to our recent paper "Pathways: Augmenting interoperability across scholarly repositories" [6]. 2. Overview of the Pathways Interoperability InfrastructureOur work exploits the expanding number and variety of heterogeneous repositories that hold managed collections of digital objects. We propose that the digital objects from these repositories can function as the units of scholarly communication in cross-repository workflows, and can also provide the raw materials for the creation of a variety of cross-repository services. In accordance with the rapidly emerging scholarly reality, we consider these digital objects to be compound in nature. That is, they are aggregations of datastreams with both a variety of media types and a variety of intellectual content types including papers, datasets, simulations, software, dynamic knowledge representations, machine readable chemical structures, etc. Table 1 lists the meanings and icons that we associate with the terms digital object, datastream and repository in this article.
Table 1: Definitions of digital object, datastream and repository used in this work. Figure 1 shows the relationship of the Pathways interoperability fabric to the interfaces and designs of individual repositories.
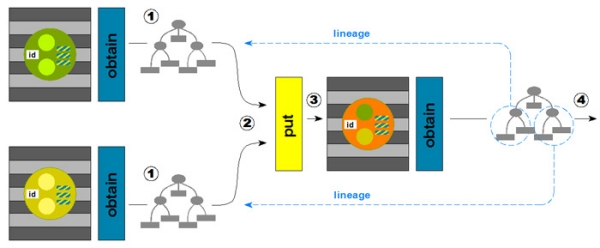
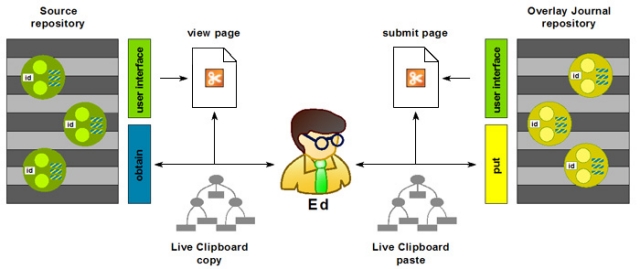
Table 2: Core components of the interoperability layer provided by repositories. 2.1 The foundation of multiple levels of interoperabilityRecall that the goal of the Pathways research is to identify the minimum level of interoperability to support cross-repository information re-use. The proposed interoperability fabric based on surrogates and three focused interfaces does not preclude other more advanced levels of interoperability. For example, surrogates could be used in conjunction with other public repository services and end-user applications. Also, the three core repository services need not necessarily be limited to surrogates only. The harvest and put services could support other structured formats, in the manner that OAI-PMH [9] supports multiple metadata formats. The obtain service could support a wide variety of services pertaining to an identified digital object and its constituent datastreams. The potential of defining such a rich service environment focused around a specific digital object was the motivation for distinguishing between the harvest and obtain services. Rich levels of the obtain functionality have been explored in the context of the aDORe project [11,12] and examples of service requests include obtaining a surrogate for an identified journal article, obtaining a PDF datastream of that same article, obtaining an audio version of the article by applying a text-to-speech transformation upon the PDF datastream, etc. Finally, the proposed Pathways Core data model (and its compliant surrogates) contains only those properties that we consider absolutely necessary. The model allows extensions to the core that would facilitate higher levels of interoperability that might be required by some communities, applications, and workflows.2.2. Example of the infrastructure in a workflowFigure 2 shows the core components of our proposed infrastructure in the context of an example workflow. At the left hand side, it shows two source repositories, each with a contained digital object. The repositories have obtain interfaces from which a surrogate for each digital object can be requested. These surrogates are then submitted to the put interface of a target repository. After this put operation, a variety of repository and workflow-specific operations can take place, and, eventually a new digital object results in the target repository. A surrogate for this new digital object can then be obtained from the target repository. Figure 2 also illustrates the concept of lineage. Lineage makes it possible to automatically record an audit trail (or evidential citation) for scholarly workflows within the fabric of the digital scholarly communication system. This audit trail would allow tracking back from any given digital object to its ancestors in the workflow that resulted in its creation. Finally, the figure also emphasizes the importance of digital object identity in the interoperability framework. Indeed, if we want to allow access to surrogates and recording of audit trails, then identification of digital objects is crucial. We observe that identification mechanisms as they are frequently used in scholarly communication (e.g., DOI) allow multiple copies of an identified object stored in different repositories to share the same identifier. This level of identification granularity is sufficient for current citation purposes. However, it is inadequate for recording an audit trail of a cross-repository value chain, which needs identity expressed at the granularity of copies of digital objects in specific repositories.
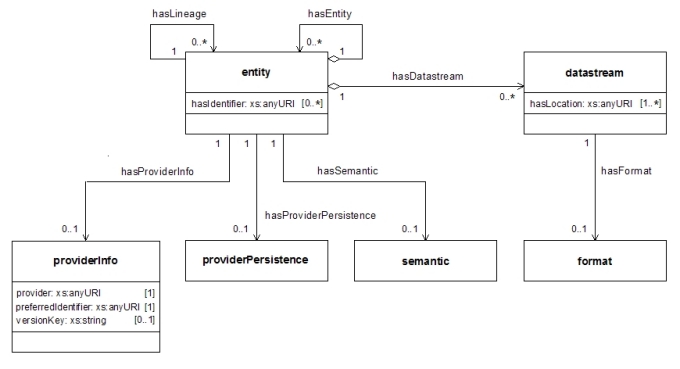
3. Components of the InfrastructureThe result of our work thus far is a prototype interoperability fabric. This prototype reflects design choices made in the context of the overlay journal prototype described in Section 4. We expect that a number of these choices will be revisited and may need to change in order to transition this prototype to a true interoperability specification. The remainder of this section describes the aspects of this design. 3.1 A common data model for representing digital objects.We have designed and experimented with a data model we call the Pathways Core [6,13]. Figure 3 shows a UML diagram of the model, and an OWL schema (encoded in XML) is included in Appendix B. The data model shares some characteristics with existing compound object models, such as MPEG-21 Digital Item Declaration [10]. It uses nested entities to represent recursive "digital objects within digital objects", it allows the association of multiple properties with entities, and uses the hasDatastream property to provide access to entities' constituent datastreams. We note that our current approach only allows by-reference inclusion of datastreams via providing their network locations (URL). Therefore, workflows and services that require or desire actual transfer of the constituent datastreams will need to (selectively) dereference these URLs after harvest, obtain or put. The manner in which we model access to datastreams raises a number of questions. Can datastreams be delivered by-reference (as in our current approach), by-value (the datastream embedded within the surrogate) or both? Or to put it differently: should surrogates be shallow or deep copies of a digital object, or can they be both? Perhaps the answer lies in the notion of "levels of interoperability" described earlier. Consequently, should support for shallow copies be the minimally required level? At the time of writing, even the authors of this article actively debate these questions. We are in agreement that a shallow copy approach has the advantage of pushing potential intellectual property rights issues pertaining to datastreams outside of the core interoperability fabric. From related work at JISC [14], we are starting to understand the complexities involved in an interoperable solution to support putting deep copies into repositories. And we point out that not all value chain scenarios require the transfer of all datastreams of a digital object. Mirroring for digital preservation is a notable example of the need for a "deep copy" capability.
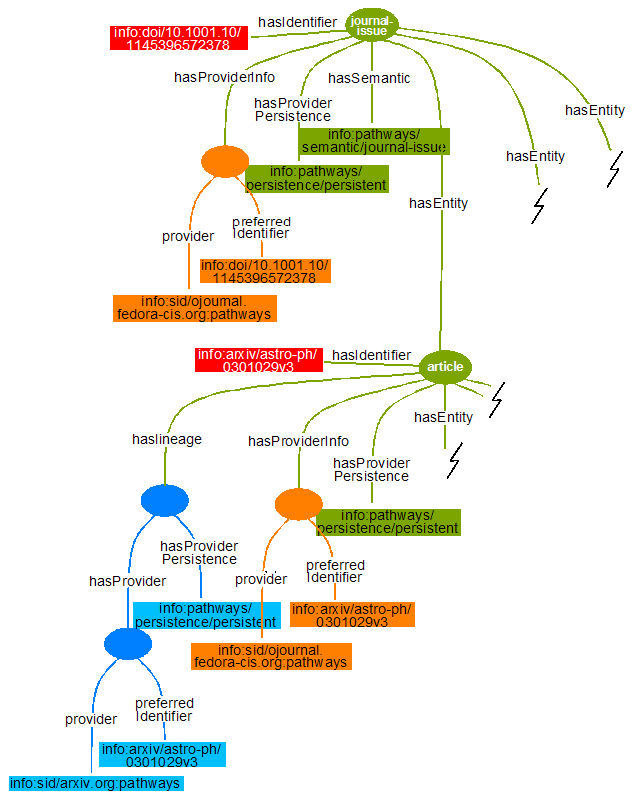
On the other hand, there is no disagreement about the need for clear notions of identity and lineage in the model. They are essential for recording workflows, which we argue are central to our process-oriented approach to scholarly communication. Historically, identifiers have been a source of considerable debate. We argue that it is unrealistic to propose an interoperable fabric that mandates the use of specific identifier schemes. Therefore, our design supports the use of URIs that conform to a variety of schemes and the use of these URIs in the following aspects of the data model:
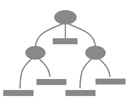
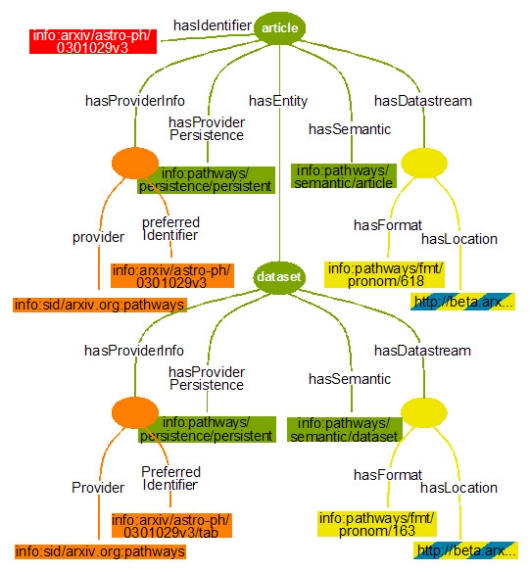
The hasLineage property expresses that a digital object is the result of a workflow that includes other originating digital objects. The value of this property for an entity is the hasProviderInfo identity of the entity (or entities) from which the new entity derives, thus expressing both the origin repository of the source object, its identity within that repository, and its version semantics. Repositories should maintain the lineage chaining when they create a new digital object in response to a put request, thereby maintaining a record of the workflow across repositories. To do this, they should record the providerInfo of a put surrogate, and subsequently include it in the hasLineage information of any surrogates of the new digital object. We note that attaching a hasProviderInfo property to an entity makes the entity available for re-use in other contexts. This is because hasProviderInfo is an unambiguous identity for the entity; it contains all essential keys to obtain a surrogate for the entity from the origin repository. Since the model is recursive – entities can contain entities – re-use of sub-entities is enabled. A new entity can be the result of a workflow that originates in sub-entities of other entities, as long as such sub-entities have a hasProviderInfo property. Which (sub-)entities will be made available for re-use is expected to be the subject of best practices at the level of repository systems and scholarly communities. 3.2 A format for serializing digital objects as surrogatesWe use RDF/XML to represent and transmit Pathways Core surrogates of digital objects. Table 4 in Appendix A shows a surrogate for the digital object from arXiv with identifier info:arxiv/astro-ph/0301029v3; Figure 4 shows a graphic representation of that surrogate. In the illustrated surrogate, the digital object corresponds to the root entity element, shown in the Figure as the "article" circle at the left top. The details of this example are as follows:
3.3 Three core repository servicesobtain – As argued by Bekaert [12], the OpenURL Framework Standard [16] provides a suitable platform for the concrete definition of an obtain service. The OpenURL ContextObject submitted to an obtain service would at least consist of Descriptors for:
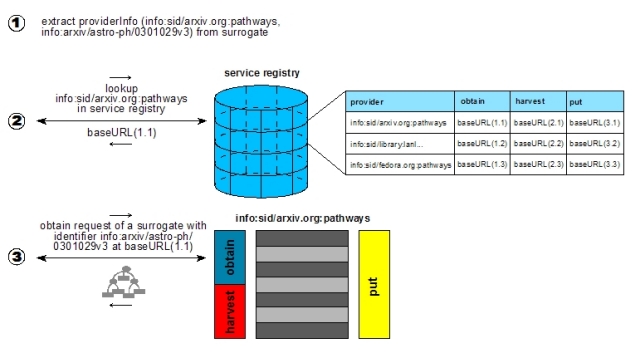
It is interesting to note that the OpenURL Standard allows for the inclusion of other ContextObject entities, such as the Requester, hence offering the potential for a context-sensitive obtain service environment. Because of this flexibility we used OpenURL for the implementation of the core obtain service in the overlay journal prototype. Once a surrogate has been retrieved, say through incremental harvesting, all information needed to construct a future obtain request to retrieve a fresh surrogate is contained in the providerInfo triple (provider, preferredIdentifier, versionKey) of the surrogate itself. The resolution of this triple into a surrogate works as follows (see Figure 5):
harvest – A harvest service allows collecting batches of surrogates of digital objects. It could be implemented using various technologies such as the OAI-PMH [9], RSS [17], Google Sitemaps, or with a subset of more elaborate technologies such as SRU/W [18]. We believe that harvest should include a facility that allows some forms of selective collecting. The simplest, and perhaps most useful, form of selective collecting is to allow downstream applications to harvest surrogates only for those digital objects that were created or modified after a given date. This echoes the OAI-PMH, a well-established harvesting technology within the digital library community. We thus chose to use OAI-PMH for the overlay journal prototype, and each participating repository implemented an OAI-PMH-based harvest service with the following properties:
put – The put interface facilitates interoperable transmission of surrogates from a source repository to one or more target repositories. In our current shallow-copy implementation of surrogates, a put operation can be understood as a request for deposit of a digital object. The put interface, in combination with a surrogate, is intended as a means for transmitting just enough information to enable a receiving repository to make decisions on how to process a surrogate – without anticipating or assuming an underlying repository's requirements for ingest. The Atom Publishing Protocol [19] or SRU Record Update [20] could be considered for the implementation of the put service. In the overlay journal prototype, a simple HTTP POST was used. 3.4 Shared infrastructureA service registry is fundamental to the interoperability framework, as it facilitates locating the core service interfaces of participating repositories. This registry has the identifier of a repository (provider from providerInfo) as its primary key, and at minimum stores the actual network location of the obtain, harvest and put services. Thus, given a surrogate with providerInfo (provider, preferredIdentifier, versionKey), it is possible for an application to use provider as a look-up key in the service registry and then retrieve the location of the core service interfaces for the repository identified by provider. Once this information is available, actual service requests can be issued against those interfaces (see Figure 5). It should be noted that, in contrast to other repository federation approaches such as ADL-R [21], aDORe [22], CORDRA [23], and the Chinese Digital Museum Project [24], the proposed framework does not require a registry of all digital objects from all contributing repositories in order to locate a digital object given its identifier. As shown in Figure 5, the Pathways approach achieves locating a digital object by a combination of:
We believe that this approach has a better chance of remaining scalable as the number of digital objects in the environment grows over time. One candidate technology for the service registry is the JISC Information Environment Service Registry (IESR) specification [25], which has been implemented by both MIMAS in the UK and by the Ockham project in the USA. OAI-PMH, SRU and OpenURL interfaces to service registry records are available for both implementations. An alternative approach would be to follow the concepts of service autodiscovery in which clues about the location of service interfaces are embedded in HTML pages [26]. Since the environment of the overlay journal prototype was rather small, a lightweight, ad-hoc implementation of the service registry was deployed. In addition to this lightweight service registry, we used information from PRONOM [27] to build a format registry. Collaborating repositories used identifiers from this registry as the values for the format property that can be attached to datastreams in surrogates. Also, an ad-hoc list of coarse granularity scholarly content types (see Appendix E) expressed as info URIs [28] was shared across collaborating repositories; terms from the list were used as values for the semantic property that can be attached to entities in surrogates. 4. The Overlay Journal PrototypeAn overlay journal is a journal that does not publish any original articles, but rather selects articles that exist elsewhere, adds certain value to the selection, and publishes the result as a service to its user base. In our prototype, "Ed", the editor of the overlay journal, sets out to create a new journal issue. Ed doesn't go about his job in the usual manner in which he might copy the URL of the user interface pages that provide access to the selected articles, copy some bibliographic information from those pages that describe those articles, and paste it all into his overlay journal system. Instead, Ed follows the Pathways workflow approach, moving surrogates for the objects he is interested in from their hosting repositories and submitting those surrogates to his own Overlay Journal repository. In doing so, he moves machine-readable structured representations of actual digital objects around, not snippets of their HTML splash-page representation. The exact nature of the processes in the Overlay Journal repository that result from putting surrogates are outside of the scope of the interoperability framework. Actions might include dereferencing some or all of the constituent datastreams referenced by the source surrogates (for example, at least the bibliographic metadata datastream), addition of some datastreams, properties and/or structure as required by the target repository environment, etc. Of special importance for the establishment of an audit trail of the workflow that produced the new journal issue is the recording of the providerInfo of the source surrogates. This information can then be used as values for the hasLineage property in the surrogates that will eventually be available for this new journal issue digital object. The remainder of this section describes the environment that was deployed for the experiment, and then provides a sequential summary of Ed's workflow. 4.1 The overlay journal prototype environmentThe overlay journal experiment occurred in the February-April 2006 timeframe. A distributed environment was deployed on systems at Cornell University, HP, and the Los Alamos National Laboratory. The components were as follows:
4.2 The Overlay Journal workflowA movie of the overlay journal workflow is available from the Open Video Project (MPEG-4, size 59.80 Mb; QuickTime, size 90.30 Mb) and from the Pathways web site (QuickTime, size 90.30 Mb). This movie demonstrates the workflow that Ed follows to create a new issue for his overlay journal in a heterogeneous repository environment empowered by the Pathways interoperability fabric. A storyboard for the movie is as follows:
5. ConclusionThis article has shown that it is possible to build scholarly value chains across heterogeneous, distributed repositories by introducing an interoperability fabric consisting of a shared data model for the representation of digital objects, a format to serialize digital objects into surrogates compliant with that data model, three core repository interfaces (obtain, harvest, put) that support surrogates, and some shared infrastructure. And, through the introduction of a repository-centric identification approach combined with a lineage concept, it has also shown that it is possible to record audit trails of scholarly value chains into the very foundation of the scholarly communication system. This work reflects growing interest in the notion of repository federation. Related work such as the CORDRA effort, the Chinese DSpace Federation, and the Dutch DARE project also suggest that object re-use across various contexts is achievable through the introduction of a shared interoperable layer. The recent "Augmenting Interoperability" meeting [36], which was supported by the Mellon Foundation, Microsoft, the Coalition for Networked Information, the Digital Library Federation and the Joint Information Systems Committee further demonstrates the growing interest in leveraging the intrinsic value of scholarly digital objects beyond the borders of the hosting repository. We believe that interest in this type of federation is sufficiently strong to move beyond prototypes and to support an effort to formally specify this next level of interoperability across repositories. Such an effort would help realize the vision of a natively digital, repository-centric scholarly communication system. Through the support of the Mellon Foundation a two-year international initiative to define this interoperability fabric has started in October 2006. The initiative is aptly named Object Reuse and Exchange (ORE), and it is coordinated by Carl Lagoze and Herbert Van de Sompel. In the same manner that work on the OAI-PMH began, this initiative will start with the appointment of an international advisory board and technical committee. References1. Van de Sompel, H., Payette, S., Erickson, J., Lagoze, C., & Warner, S. (2004). Rethinking scholarly communication. Building the system that scholars deserve. D-Lib Magazine, 10(9). Retrieved from <doi:10.1045/september2004-vandesompel>. 2. Bergmark, D., & Lagoze, C. (2001). An Architecture for Automatic Reference Linking. Lecture Notes In Computer Science; Vol. 2163 / 2001. Research and Advanced Technology for Digital Libraries: Proceedings of the 5th European Conference (pp. 115-126). London, UK: Springer-Verlag 3. CrossRef home page. Retrieved from <http://www.crossref.org>. 4. Van de Sompel, H., & Beit-Arie, O. (2001). Open linking in the scholarly information environment using the OpenURL framework. D-Lib Magazine, 7(3). Retrieved from <doi:10.1045/march2001-vandesompel>. 5. Van de Sompel, H., & Beit-Arie, O. (2001). Generalizing the OpenURL framework beyond references to scholarly works: The Bison-Futé model. D-Lib Magazine, 7(7/8). Retrieved from <doi:10.1045/july2001-vandesompel>. 6. Warner, S., Bekaert, J., Lagoze, C., Liu, X., Payette, S., & Van de Sompel, H. (accepted for publication). Pathways: Augmenting interoperability across scholarly repositories. International Journal on Digital Libraries. Preprint available at <http://arxiv.org/abs/cs/0610031>. 7. Kahn, R., & Wilensky, R. (1995). A framework for distributed digital object services. Retrieved from <http://hdl.handle.net/cnri.dlib/tn95-01>. 8. Kahn, R., & Wilensky, R. (2006). A framework for distributed digital object services. International Journal on Digital Libraries, 6(2), 115-123. See <doi:10.1007/s00799-005-0128-x>. 9. Lagoze, C., Van de Sompel, H., Nelson, M. L., & Warner, S. (Eds.). (2003). The Open Archives Initiative protocol for metadata harvesting (2nd ed.). Retrieved from <http://www.openarchives.org/OAI/2.0/openarchivesprotocol.htm>. 10. International Organization for Standardization. (2005). ISO/IEC 21000-2:2005. Information technology -- Multimedia framework (MPEG-21) -- Part 2: Digital Item Declaration (2nd ed.) Geneva, Switzerland. 11. Bekaert, J., Balakireva, L., Hochstenbach, P., & Van de Sompel, H. (2004). Using MPEG-21 DIP and NISO OpenURL for the dynamic dissemination of complex digital objects in the Los Alamos National Laboratory Digital Library. D-Lib Magazine, 9(11). Retrieved from <doi:10.1045/february2004-bekaert>. 12. Bekaert, J. (2006). Standards-based interfaces for harvesting and obtaining assets from digital repositories. PhD Dissertation, Faculty of Engineering, Ghent University. Retrieved from <http://hdl.handle.net/1854/4833>. 13. Bekaert, J., Liu, X., Van de Sompel, H., Lagoze, C., Payette, S., Warner, S., & Van de Sompel, H. (2006). Pathways Core: A Data Model for Cross-Repository Services. In Proceedings of the 6th ACM/IEEE Joint Conference on Digital libraries. New York, NY: ACM Press. See <doi:10.1145/1141753.1141863>. 14. Deposit API. Retrieved from <http://www.ukoln.ac.uk/repositories/digirep/index/Deposit_API>. 15. National Information Standards Organization. (2003). Namespace of Source Identifiers used in the NISO OpenURL Framework. Retrieved from <http://www.openurl.info/registry/docs/pdf/info-sid.pdf>. 16. National Information Standards Organization. (2005). ANSI/NISO Z39.88-2004: The OpenURL Framework for Context-Sensitive Services. Bethesda, MD: NISO Press. Retrieved from <http://www.niso.org/standards/resources/Z39_88_2004.pdf>. 17. RSS specifications. Retrieved from <http://www.rss-specifications.com/rss-specifications.htm>. 18. SRU: Search/Retrieve via URL. Retrieved from <http://www.loc.gov/standards/sru/>. 19. Hoffman, P & Bray, T. (2006). Atom Publishing Format and Protocol (atompub). Retrieved from <http://www.ietf.org/html.charters/atompub-charter.html>. 20. SRU Record Update. Retrieved from <http://srw.cheshire3.org/docs/update/>. 21. Jerez, H., Manepalli, G., Blanchi, C., & Lannom, L.W. (2006). ADL-R: The First Instance of a CORDRA Registry. D-Lib Magazine, 12(2). Retrieved from <doi:10.1045/february2006-jerez>. 22. Van de Sompel, H., Bekaert, J., Liu, X., Balakireva, L., & Schwander, T. (2005). aDORe. A Modular, Standards-based Digital Object Repository. The Computer Journal, 48(5), 514-535. See <doi:10.1093/comjnl/bxh114>. 23. Rehak, D. R., Dodds, P., & Lannom, L. (2005). A Model and Infrastructure for Federated Learning Content Repositories. In D. Olmedilla, N. Saito & B. Simon (Vol. Eds.), Proceedings of the WWW'05 Workshop on Interoperability of Web-Based Educational Systems Vol. 143, Chiba, Japan. 24. Tansley, R. (2006). Building a Distributed, Standards-based Repository Federation: The China Digital Museum Project. D-Lib Magazine, 12(7/8). Retrieved from <doi:10.1045/july2006-tansley>. 25. Information Environment Service Registry. Retrieved from <http://iesr.ac.uk/metadata/>. 26. Chudnov, D., Cameron, R., Frumkin, R., Singer, R. & Yee, R. (2005). Opening up OpenURLs with Autodiscovery. Ariadne, Issue 43. Retrieved from <http://www.ariadne.ac.uk/issue43/chudnov/>. 27. Darlington, J. A practical online compendium of file formats. (2003). RLG Diginews 7(5). Retrieved from <http://www.rlg.org/legacy/preserv/diginews/v7_n5_feature2.html>. 28. Van de Sompel, H., Hammond, T., Neylon, E., & Weibel, S. (2006). The "info" URI scheme for information assets with identifiers in public namespaces (IETF RFC 4452). Retrieved from <http://www.ietf.org/rfc/rfc4452.txt>. 29. Smith, M., Barton, M., Bass, M., Branschofsky, M., McClellan, G., Stuve, D., et al. (2003). DSpace: An open source dynamic digital repository. D-Lib Magazine, 9(1). Retrieved from <doi:10.1045/january2003-smith>. 30. Tansley, R., Smith, M., & Walker, J. H. (2005). The DSpace Open Source Digital Asset Management System: Challenges and Opportunities. Lecture Notes in Computer Science: Vol. 2769. Research and Advanced Technology for Digital Libraries: Proceedings of the 9th European Conference (pp. 242-253). Heidelberg, Germany: Springer-Verlag. 31. Payette, S., & Lagoze, C. (1998). Flexible and Extensible Digital Object and Repository Architecture (FEDORA). In C. Nikolaou & C. Stephanidis (Vol. Eds.), Lecture Notes in Computer Science: Vol. 1513 / 1998. Research and Advanced Technology for Digital Libraries: Proceedings of the 2nd European Conference (pp. 41-60). Heidelberg, Germany: Springer-Verlag. 32. Lagoze, C., Payette, S., Shin, E., & Wilper, C. (2005). An architecture for complex objects and their relationships. International Journal on Digital Libraries, 6(2), 124-238. See <doi:10.1007/s00799-005-0130-3>. 33. Live Clipboard Technical Introduction. Retrieved from <http://spaces.msn.com/editorial/rayozzie/demo/liveclip/liveclipsample/techPreview.html>. 34. John Ellson. WebDot Home Page. Retrieved from <http://www.graphviz.org/webdot/>. 35. Nutch. Open-source web search software built on lucence and java. Retrieved from <http://lucene.apache.org/nutch/>. 36. Augmenting interoperability across scholarly repositories. Retrieved from <http://msc.mellon.org/Meetings/Interop/>. AcknowledgmentsWe thank:
This work was supported by NSF award number IIS-0430906 (Pathways). Appendix A
Table 4 : Pathways Core RDF/XML surrogate for the digital object from arXiv with Appendix B: OWL for Pathways Core data model
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns="info:pathways/core#"
xml:base="info:pathways/core">
<owl:Ontology rdf:about="info:pathways/core">
<rdfs:label rdf:datatype="http://www.w3.org/2001/XMLSchema#string">pathways core
</rdfs:label>
<owl:versionInfo rdf:datatype="http://www.w3.org/2001/XMLSchema#string">$Date: 2006-04-
04 16:47:03 -0600 (Tue, 04 Apr 2006) $</owl:versionInfo>
<rdfs:comment rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Pathways Core
data model and OWL Schema by:
Jeroen Bekaert, Los Alamos National Laboratory
Xiaoming Liu, Los Alamos National Laboratory
Herbert Van de Sompel, Los Alamos National Laboratory
Carl Lagoze, Cornell University
Sandy Payette, Cornell University
Simeon Warner, Cornell University
Creation of the Pathways Core data model was supported by NSF award
number IIS-0430906 (Pathways).
</rdfs:comment>
</owl:Ontology>
<owl:Class rdf:ID="providerPersistence"/>
<owl:Class rdf:ID="format"/>
<owl:Class rdf:ID="semantic"/>
<owl:Class rdf:ID="providerInfo">
<owl:equivalentClass>
<owl:Class>
<owl:intersectionOf rdf:parseType="Collection">
<owl:Restriction>
<owl:cardinality
rdf:datatype="http://www.w3.org/2001/XMLSchema#int">1
</owl:cardinality>
<owl:onProperty>
<owl:DatatypeProperty rdf:ID="provider"/>
</owl:onProperty>
</owl:Restriction>
<owl:Restriction>
<owl:onProperty>
<owl:FunctionalProperty rdf:ID="preferredIdentifier"/>
</owl:onProperty>
<owl:cardinality
rdf:datatype="http://www.w3.org/2001/XMLSchema#int">1
</owl:cardinality>
</owl:Restriction>
<owl:Restriction>
<owl:onProperty>
<owl:FunctionalProperty rdf:ID="versionKey"/>
</owl:onProperty>
<owl:maxCardinality rdf:datatype="http://www.w3.org/2001/XMLSchema#int">1
</owl:maxCardinality>
</owl:Restriction>
</owl:intersectionOf>
</owl:Class>
</owl:equivalentClass>
</owl:Class>
<owl:Class rdf:ID="datastream">
<owl:equivalentClass>
<owl:Class>
<owl:intersectionOf rdf:parseType="Collection">
<owl:Restriction>
<owl:cardinality rdf:datatype="http://www.w3.org/2001/XMLSchema#int">1
</owl:cardinality>
<owl:onProperty>
<owl:ObjectProperty rdf:ID="hasFormat"/>
</owl:onProperty>
</owl:Restriction>
<owl:Restriction>
<owl:minCardinality rdf:datatype="http://www.w3.org/2001/XMLSchema#int">1
</owl:minCardinality>
<owl:onProperty>
<owl:DatatypeProperty rdf:ID="hasLocation"/>
</owl:onProperty>
</owl:Restriction>
</owl:intersectionOf>
</owl:Class>
</owl:equivalentClass>
</owl:Class>
<owl:Class rdf:ID="entity"/>
<owl:ObjectProperty rdf:ID="hasSemantic">
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
<rdfs:range rdf:resource="info:pathways/core#semantic"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="hasLineage">
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
<rdfs:range rdf:resource="info:pathways/core#entity"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="hasEntity">
<rdfs:range rdf:resource="info:pathways/core#entity"/>
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="hasDatastream">
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
<rdfs:range rdf:resource="info:pathways/core#datastream"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="info:pathways/core#hasFormat">
<rdfs:domain rdf:resource="info:pathways/core#datastream"/>
<rdfs:range rdf:resource="info:pathways/core#format"/>
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#FunctionalProperty"/>
</owl:ObjectProperty>
<owl:DatatypeProperty rdf:about="info:pathways/core#provider">
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#FunctionalProperty"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#anyURI"/>
<rdfs:domain rdf:resource="info:pathways/core#providerInfo"/>
</owl:DatatypeProperty>
<owl:DatatypeProperty rdf:about="info:pathways/core#hasLocation">
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#anyURI"/>
<rdfs:domain rdf:resource="info:pathways/core#datastream"/>
</owl:DatatypeProperty>
<owl:DatatypeProperty rdf:ID="hasIdentifier">
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#anyURI"/>
</owl:DatatypeProperty>
<owl:FunctionalProperty rdf:about="info:pathways/core#preferredIdentifier">
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#anyURI"/>
<rdfs:domain rdf:resource="info:pathways/core#providerInfo"/>
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#DatatypeProperty"/>
</owl:FunctionalProperty>
<owl:FunctionalProperty rdf:ID="hasProviderPersistence">
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#ObjectProperty"/>
<rdfs:range rdf:resource="info:pathways/core#providerPersistence"/>
</owl:FunctionalProperty>
<owl:FunctionalProperty rdf:about="info:pathways/core#versionKey">
<rdfs:domain rdf:resource="info:pathways/core#providerInfo"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#string"/>
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#DatatypeProperty"/>
</owl:FunctionalProperty>
<owl:FunctionalProperty rdf:ID="hasProviderInfo">
<rdfs:range rdf:resource="info:pathways/core#providerInfo"/>
<rdfs:domain rdf:resource="info:pathways/core#entity"/>
<rdf:type rdf:resource="http://www.w3.org/2002/07/owl#ObjectProperty"/>
</owl:FunctionalProperty>
</rdf:RDF>
Appendix C: OpenURL-based obtain requestsTable 5 shows OpenURL-based obtain requests for providerInfo with and without versionKey. Note that neither this specific OpenURL Application, nor the KEV metadata format that it uses (identified by info:ofi/fmt:kev:mtx:pw) are currently registered in the OpenURL Registry.
Table 5 : Syntax of OpenURL-based obtain requests Appendix D: XML Schema for RDF/XML transport in OAI-PMH
<schema xmlns="http://www.w3.org/2001/XMLSchema"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
targetNamespace="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
elementFormDefault="qualified"
attributeFormDefault="unqualified">
<annotation>
<documentation>
Schema to allow inclusion of RDF in OAI-PMH responses. This schema simply
defines the root element (rdf:RDF) and then says that the contents should
have 'lax' validation (i.e. no schema required). Use this by including
the following in the root element:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xsi:schemaLocation="http://www.w3.org/1999/02/22-rdf-syntax-ns#
http://www.openarchives.org/OAI/2.0/rdf.xsd">
Simeon Warner
$Id: rdf.xsd,v 1.1 2006/04/05 15:28:58 simeon Exp $
</documentation>
</annotation>
<element name="RDF" type="rdf:rdfType"/>
<complexType name="rdfType">
<annotation>
<documentation>Content may be in any namespace (namespace=##other, see
http://www.w3.org/TR/xmlschema-1/#declare-openness) and
the elements are only validated if a schema is available that
uniquely determines the declaration (processContents="lax", see
http://www.w3.org/TR/xmlschema-1/#declare-openness)
</documentation>
</annotation>
<sequence>
<any namespace="##other" processContents="lax"/>
</sequence>
</complexType>
</schema>
Appendix E: Semantic identifiers used in the overlay journal prototypeinfo:pathways/semantic/abstract info:pathways/semantic/article info:pathways/semantic/article-fulltext info:pathways/semantic/bibliographic-citation info:pathways/semantic/bibliography info:pathways/semantic/collection info:pathways/semantic/data info:pathways/semantic/data-collection info:pathways/semantic/dataset info:pathways/semantic/dataset-primary info:pathways/semantic/dataset-revision info:pathways/semantic/descriptive-metadata info:pathways/semantic/doctoral-thesis info:pathways/semantic/figure info:pathways/semantic/graph info:pathways/semantic/image info:pathways/semantic/journal info:pathways/semantic/journal-article info:pathways/semantic/journal-issue info:pathways/semantic/masters-thesis info:pathways/semantic/metadata info:pathways/semantic/photo info:pathways/semantic/refereed-article info:pathways/semantic/scholarly-work info:pathways/semantic/software info:pathways/semantic/table info:pathways/semantic/text info:pathways/semantic/thesis info:pathways/semantic/unrefereed-article info:pathways/semantic/video info:pathways/semantic/webpage Copyright © 2006 Herbert Van de Sompel, Carl Lagoze, Jeroen Bekaert, Xiaoming Liu, Sandy Payette, and Simeon Warner |
||||||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/october2006-vandesompel
|