Digital Labels for Digital Libraries
Universal Library Project
School of Computer Science
Carnegie Mellon University
Pittsburgh, Pennsylvania
D-Lib Magazine, October 1996
ISSN 1082-9873

D-Lib Magazine, October 1996
At the Universal Library Project, we seek to significantly facilitate the process of providing Internet access to paper-based books and periodicals and other authored works. We have set out to achieve this goal through practical demonstrations in two areas:
Such demonstrations of document acquisition and use can be found through our site. We also aim to facilitate the electronic publishing process by the contribution of basic research where an answer may require empirical study or new contributions to theory and technology in software and communications. In keeping with our research mission, this article describes some empirical research results that may be important in achieving a practical infrastructure for Internet access to documents originating in paper. It then attempts to tie these empirical research results into the ongoing development of component software systems and network object headers and descriptors for distribution on the Internet and its extension to digital television.
An element of a digital library collection on the net has different requirements from an element of a library collection for other media, such as print. These requirements are reflected in differences in the development and use of cataloguing labels (or, alternatively, "declarative metadata"). Of particular interest to us are labels that apply to books that have been scanned and converted for viewing on the web or that have been written and formatted expressly for web viewing. Based on the experience in actually employing these labels, we are developing policies of label development and use, and label form and disclosure.
This article will present a system of label development and use to provide a person with control of the presentation of book content. We claim the system of labels presented here operates well for 88% of the books that were freely available on the World Wide Web as of August 1, 1996. By "presentation control," we mean the capability to observe a book by the sentence, paragraph, browser screen-full, section, chapter, book, index, contents, or collection. In making our granularity claim, we show operational proof with our Universal Library Book Object that a person can access any of the books by a screen-full at a time.
Reading books by the screen-full is a good proof of a functional labelling system, a complete and sufficient declarative language, but it has limited utility in practice. Most web browsers will efficiently scroll, search, or skip through long text. The practical utility of displays by the screen-full becomes apparent in two scenarios: People often express a desire to compare scans of the original printed pages with the HTML text. Also, a person may only want to look at a few book pages, but finds the book is stored as a large file that requires significant download time. One salient example of this would be searching through a collection of books or periodicals for screen-fulls (paragraphs, sections, chapters, etc.) on a given subject.Such searching requires brokered URLs (Universal Resource Locators) that allow existent search engines to form indices of books or book collections, indexed by the screen-full. In our Universal Library Book Object, you can peruse the vast majority of books that are publicly readable on the web by the browser screen-full. In our Universal Library Search Object, you can search the same vast majority of all the books on the web for keywords, and see those screen-fulls of those books that contain those keywords. Technically, the Book Object currently requires a caching, or temporary storage, operation onto Carnegie Mellon University computers so, to appreciate the technology, it is best to first try our demonstrations where the caching operations have already been established.
This article also discusses a system of labels that are declarative and publicly defined. Such labels are in a form that provides additional properties of being globally unique, persistent, self-defining, and available through multiple autonomous authorities. On the surface this framework is consistent with labels that are URLs or URNs (Universal Resource Names). But we show labels that are not host-identified or, necessarily, MIME object identified. A fundamental purpose of this article is to introduce broader requirements for labels than have been entertained simply for URLs or URNs (and the like), and yet show that common underlying syntax, semantics, and authority structure can apply more broadly to publicly disclosed and distributed declarative labels.
As presented, the Universal Library Project is adopting a subset of URN-style labels that are further qualified to meet the SMPTE 298M (Society of Motion Picture and Television Engineers) specification for header/descriptors for use in Advanced Television digital data streams. Such labels can be employed as we demonstrate their use in the Universal Library "Book Object" and "Search Object" but could also be employed in more general SGML markup schemes or even in network routing or digital television transmission schemes.
In a wide area network, labels for objects do not have to reside where the objects reside. Indeed, the World Wide Web digital library today provides distributed services. For example, the OCLC book cataloguing data exists in one site, while the full text of books exist in other sites. There are also sites, such as our own , that tie the standard library cataloguing information with the full text locations. Similarly, Universal Library Labels do not have to reside with the full text locations of books. This difference between consolidated and distributed services is illustrated below:
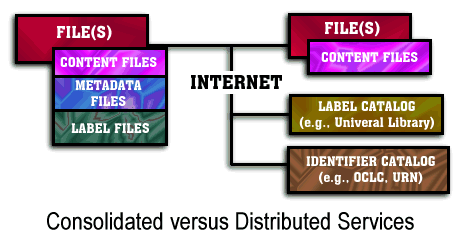
However, for simplicity, we have defined our label system such that our book and search object will look first at the source location for the full text for our metadata labels, and then will consult our local catalogue, before abandoning any particular reformatting or permissioning.
The Universal Library Book Object is intended to let you read a book off the web the way you would like to read it, by giving you book presentation options. You can either download the whole book as a single HTML or ASCII MIME object. Download by the screen-full. Download by the section or chapter. You can have the book in HTML, in ASCII, in Postscript, in RTF, or image GIF. In short, you don't have to read the book in the same form in which it is stored on the remote server. Such conversion of original presentation format is already common in printer drivers, although we also provide a means to permission use.
To complement the users' freedom to read the book in the form in which they desire to read it, the Book Object also has complementary provisions by which a book owner can control or restrain the freedoms allowed. This includes not only presentation constraints, but also permissions to print or permissions that may require monetary payments. The Universal Library Book Object is still a work in progress, but we have now overcome a few of the more fundamental hurdles in establishing the question of its feasibility.
As the key experimental case, we have developed labels for presenting any book, regardless of its originally stored presentation form, by the browser screen-full (i.e., by the "browser page"). We reasoned that if we can achieve this conversion, then we can handle other, related, conversions such as presentation by the chapter, presentation by the paragraph, and presentations in formats other than HTML. While the experimental case is possibly not the most difficult case of conversion, it is a defining case from which any other types of conversion must draw.
We have developed two sets of labels to date. One we call "the Friedman File Parsing Labels" (after Eric Friedman, the Yale student who developed the labels), and the other we call "the McMullan Book Presentation Labels" (after Jason McMullan, the CMU student who developed these labels). The reason for two sets, rather than one, can be seen in the figure below by contrasting, again, the needs of wide area networks versus local, monolithic, computer applications. In the "application style" model on the right side of the figure, the files containing the book data and metadata are read into a common underlying representation where the semantics are uniformly defined. This is typically achieved by providing an API (Application Program Interface) to the representational layer, and then another API so as to handle different window systems or browsers which, in the present case, would be the MIME API.
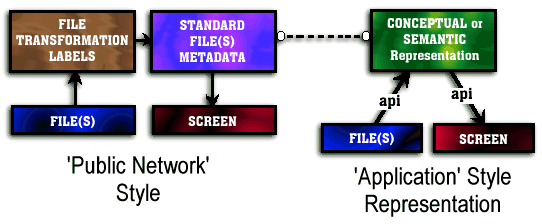
However, if we are to achieve truly distributed and open cataloguing of books on the web, we believe there should be explicit, declarative, file transformation labels that do not require writing special software, and explicit screen presentation labels that also do not require writing special software. The latter labels, if already present in the file representation of a book on the web, imply no file transformation is necessary to achieve the desired screen presentation. They represent the semantic markup on a standard content form and thus correspond, as illustrated on the left side of the above figure, to the "common semantic representation" utilized in monolithic applications. For the screen-full experiment, the file transformation labels are the Friedman File Parsing Labels and the standard file(s) metadata labels are the McMullan Book Presentation Labels. The two label systems permit a well-defined conversion to take place between the stored form of a book and its ordinary metadata (such as the Title and Author) along with a desired presentation of that book by the user. The "common semantic representation" is embodied as a standard file or caching object with presentation metadata.
If someone stores a book in a new form not anticipated by the existing Friedman labels, he need only add appropriate labels to the Friedman label set and prove consistency and sufficiency by demonstrating the automatic conversion to the standard form plus McMullan labels. The McMullan labels provide the reference for the validity of the addition of Friedman labels, and vice versa. It follows that a natural extension of this concept would include printer labels. But there are already numerous examples of such printer label systems in widespread use that are typically tied to the labels defined by file name extensions, such as ".txt" ".ps" and ".rtf".
The Friedman File Parsing Labels were developed by canvassing the stored forms of approximately 1800 free-to-read books available on the web as of August 1, 1996. While the number of books continues to increase rapidly increase, the number of new methods for storing and formatting books is not increasing as quickly. We expect that 80-90% of the books on the web can be handled with these labels. By way of illustration, here are some catalogue entries with the Friedman labels appended as capitalized letter codes:
9000000700@Consideration of the Nutrition Components of the Sick Child@EDITOR Allen, Lindsay H./Hows on, Christopher P.@http://www.nap.edu/readingroom/books/sickchild/contents.html@ C D G BT BU BK
9000000710@Guadalcanal@Anderson, Charles Robert@http://imabbs.army.mil/cmh-pg/guadal.htm@ B C
9000000720@Winesburg, Ohio@Anderson, Sherwood@ftp://uiarchive.cso.uiuc.edu/pub/etext/gutenberg/etext96/wnbrg11.txt@ A B CW
9000000730@3D Graphics Programming with QuickDraw 3D@Apple Computer@@http://dev.info.apple.com/ insidemac/quickdraw3d/Contents.html@ C D G BT BU K1#BT#BU BN
The McMullan Book Presentation Labels describe a standard file system representation for a book and a standard file system representation for book metadata. In using a standard file system representation, consistent caching and database representation can be assured. The objective of the McMullan Book Presentation Labels is to differentiate book pages in different presentation formats (such as HTML, image TIFF, or RTF) to provide standard cataloguing metadata such as book Title and Author, and also to provide indexing, such as a table of contents, for which page hyperlinks can be obtained.
The McMullan Book Presentation labels employ standard file metadata descriptors. This is one example of a McMullan labelling of a book from one of the National Academy of Sciences Press books on our web site:
The Universal Library Book Object makes use of these descriptors to present books on the web for viewing by the screen-full. Click here to see the book object.
The Universal Library Search Object requires a third set of labels that turns out to be the URLs (or URNs) that the Universal Library Book Object generates to display its browser screen-full pages. The need for brokered URLs becomes apparent in considering what the Universal Library Search Object must accomplish.
The Universal Library Search Object serves third-party search engines that are building or modifying their indexes; it does not serve the user directly. Indeed, it is not far off base to think of the Universal Library Search Object as the Book Object for search engine robots or spiders.
All, or nearly all, web search engines will first build an index of the web, and, then, through the index built, rapidly provide answers to queries. This is much as a person does with the index in any book. The Search Object only works with the index building aspect of a search engine. The search engine asserts the way it wants to have the book information, by the paragraph, screen-full, page, section, chapter, book, book collection, and is then issued this information in this way along with the Book Object URL that will display each desired chunk.
We assume that once a search engine has built an index of a book or a book collection, that the writers of the search engine will provide their own query interface. But, the answers to any query will want to point back to content in the books. This is the reason that the Search Object issues Book Object URLs to display book chunks. When a person interacts with the search engine, it provides the list of matching chunks to his query. So, for example, the Excite search engine may provide the list of book screen-fulls from many books that contain the words "Einstein" and "relativity."
This set of Book Object URLs constitutes the final, third, set of labels. Since these change as the web changes, their form is defined as Book Object CGI parameters. As an example, here is screen-full two of a book as served by the National Academy of Science Press version of our Book Object:
/mrp- cgi?ulabel=ul.index_toc_preface.page.2&label=ul.book.80010&type=html&index=toc
The URL so common on the World Wide Web today is a declarative, and therefore persistent, label that defines one unique client-server transaction. The uniqueness is global in as much as there are a handful of registration authorities that can allocate domain names and ethernet hardware addresses. The URN proposal decouples the ethernet hardware addresses and creates what amounts to domain name authorities brokered through a strict two-level hierarchy of network registries (Global and Public, Local and Private) to connect the hardware locations or true URLs. Once an entity owns a domain name, it can, without further permission from the domain name registration authority, extend the name by prepending as we have done with the prepend of "www.cmu.edu" with "www.ul.cs.cmu.edu", or by postpending, as in "www.cs.cmu.edu/Web/books.html ." Because the rules for prepending and postpending are strict and the registration authorities are careful not to issue duplicate domain names, such labels are globally unique.
The Header-Descriptor Working Group of the Society of Motion Picture and Television Engineers (SMPTE), of which I am a member, is charged with the task of creating labels for advanced digital television streams. We have also confronted the problem of generating globally unique and persistent labels. The proposed solution, now published as SMPTE 298M, borrows on another pre-existing label standard used in X.25 networks (as opposed to the Internet's TCP/IP networks) and codified as ASN.1 ("Abstract Syntax Notation 1") Object Identifiers. What is interesting about ASN.1 Object Identifiers is that they are highly similar to URNs (they lack a fixed hardware address and depend therefore on registration authorities) but they also offer three advantages:
1. Once an entity applies for and owns his own "base identifier," he becomes an explicit and autonomous registration authority for other authorities, and there is only one ultimate authority. This is the combined United Nations body known as ITU/ISO the "International Telecommunications Union" and the "International Standards Organization" (administered in the United States by ANSI).
2. There is law in most all countries of the world that makes it illegal to counterfeit these ASN.1 Object Identifiers assuming you have applied for and obtained the United Nations granted authority to produce them. Thus, for example, X.25 ASN.1 Object Identifiers, common in banking, trace authorities. In addition, from the same ASN.1 Object Identifier hierarchy, but in a different region of its name space, telephone numbers are guaranteed to be unique worldwide. It is illegal in Germany, for example, to mimic a U.S. telephone exchange and number. Aside from the question of whether anybody enforces these laws, it is interesting that this mechanism for naming provides global uniqueness and persistence. It also provides autonomous authority for which international counterfeiting sanctions already exist. It was partly because of this globally-enforced legal authority that the SMPTE 298M Universal Label proposal was made.
3. Because URLs have corresponding 48 bit hardware Ethernet addresses, they can be efficiently routed electronically. URNs have no such addresses and depend on ASCII comparison software for routing. The SMPTE 298M proposal, in contrast, provides a single efficient "binarization" technique for the textual names, called "Basic Encoding Rules" and therefore was designed to incorporate binary efficiencies similar to those obtained with URLs.
A common criticism of ASN.1 has been that it is too general, complicated, and archaic, to be of much interest on the Internet or other modern communications systems. However, the SMPTE 298M proposal puts extreme limits on what is allowed for SMPTE Universal Labels. It essentially restricts any such label to an ASN.1 Object Identifier (for all intents and purposes, a domain name with prepends), and a postpended arbitrary ASN.1 "Octet String" (an "octet" is an eight-bit character). Thus the SMPTE Universal Label, as it is defined for other authorities than SMPTE itself (which is a simple Object Identifier), conforms to a URN-like structure in semantic and syntactic components. It is developed as a path down a tree with a root authority prepending a local authority, and that local authority prepending local directives. The problem of having SMPTE 298M Universal Labels and URLs (URNs, or whatever) conform is a problem of deciding root authority and deciding formats. Under the SMPTE 298M proposal, the root is ISO/ITU, but an authority under the ISO/ITU can be autonomous as long as it provides accounting records to ISO/ITU of further autonomous authorities that it has granted.
Strictly speaking, if we were making a Venn diagram and we ignored what are essentially formatting rules about ASCII expression, ASN.1 is one circle, URL another circle, and SMPTE Universal ASCII Labels is the intersection of the two. By way of example, here is one authority, hyperstamps.com as registered with InterNIC, and {joint-ISO-ITU(2) country(16) US(840) organization(1) hyperstamps(113732)}, or, simply numerically, {2 16 840 1 113732} as registered with ANSI. Since both base IDs are guaranteed to be globally unique and persistent, one, hyperstamps.com, can stand uniquely for the other, {2 16 840 1 113732}. Furthermore, since both grant authority to the entity "hyperstamps" to issue postpended path attributes, the hyperstamps authority may choose, at its own discretion, to make those path attributes the same for descriptors in both cases.
We have therefore set out to have all Universal Library Labels qualified as SMPTE 298M labels and also as URLs. So, for example, a Friedman Label would be ul.cs.cmu.edu/labels/Friedman/A or, alternatively, {joint-ISO-ITU country US organization "Universal Library" labels Friedman A}. In either case, this path provides the Universal Library's registered definition for the Friedman Label A as well as a descriptor that can be employed in decoding material bearing that label. This label policy reflects a convergence for digital libraries for both the Internet and Advanced Television systems that, we believe, is potentially good for the long haul.
For more background on alternative labelling schemes, an extensive set of comparisons and contrasts is detailed here.
The Digital Labels discussed in this article have included Friedman Labels, McMullan Labels, and Book Object URLs. The Friedman and McMullan labels are distinguished in that these are not handles, object identifiers, or headers. They are object attributes or descriptors. The Book Object URLs are like URNs, or object identifiers, and name digital library objects. The Friedman and McMullan labels are declarative, scalar, descriptors in that they provide a means for interpreting the digital library objects. A scalar descriptor is usefully persistent and globally unique if it applies for all time on an object. It is usefully globally unique if there is a desire, as we have, to permit other groups to code alternative solutions to file retrieval, cache handling, and browser presentation problems.
Providing descriptors with eternal status is especially useful in the situation of bringing out-of-copyright or out-of-print works to the web. The technology available for this activity involves scanning books and converting the books to HTML. However, the expense of a full scale HTML conversion is on par with re-typesetting a book. One way to avoid some of this cost is to simply publish the scanned images of the book pages and then permit an incremental process of republishing at high quality if the community desires it. It seems important to have descriptors of book forms that permit interim, in process, or alternative manifestations of books on the web. Therefore these universal descriptors must, on face value, be persistent and globally unique.
We have only begun to touch the surface of useful declarative descriptors for digital library objects. For example, another class of important descriptors comes out of the legal domain in describing rights and obligations on the use and distribution of authored material. Material may even pass through patented processes requiring automatic royalty payments. The hyperstamps web site experiment that I developed employs SMPTE Universal Labels to assert legal claims, although much more exhaustive treatments of the legal issues can be found elsewhere. The hyperstamps demonstration provides one illustration of how these rights and obligations may pass not only along the Internet but through broadcast media as well.
The work has really only just begun in understanding digital labels for digital libraries. The Universal Library Project assumes that network objects should be in broad, unfettered, distribution, and that brokering of these objects can be seen as forms of object transformation. This is a more general notion that encompasses the URN and other "specific broker" approaches. Ockerbloom's work describes how the labels presented here may reside as attributes of network objects that are brokered (converted) by differing widely-distributed, owned, and operated, agents. It is our present intent to further develop the Universal Library labels so as to behave as attributes in convertible network objects and to provide object converters such as can be seen with the Book Object and the Search Object.



hdl:cnri.dlib/october96-thibadeau