D-Lib Magazine
September/October 2015
Volume 21, Number 9/10
Table of Contents
Enhancing the LOCKSS Digital Preservation Technology
David S. H. Rosenthal, Daniel L. Vargas, Tom A. Lipkis and Claire T. Griffin
LOCKSS Program, Stanford University Libraries
Point of Contact: David S. H. Rosenthal, dshr@stanford.edu
DOI: 10.1045/september2015-rosenthal
Printer-friendly Version
Abstract
The LOCKSS Program develops and supports libraries using open source peer-to-peer digital preservation software. Although initial development and deployment was funded by grants including from NSF and the Mellon Foundation, grant funding is not a sustainable basis for long-term preservation. The LOCKSS Program runs the "Red Hat" model of free, open source software and paid support. From 2007 through 2012 the program was in the black with no grant funds at all. The demands of the "Red Hat" model make it hard to devote development resources to enhancements that don't address immediate user demands but are targeted at longer-term issues. After discussing this issue with the Mellon Foundation, the LOCKSS Program was awarded a grant to cover a specific set of infrastructure enhancements. It made significant functional and performance improvements to the LOCKSS software in the areas of ingest, preservation and dissemination. The LOCKSS Program's experience shows that the "Red Hat" model is a viable basis for long-term digital preservation, but that it may need to be supplemented by occasional small grants targeted at longer-term issues.
1 Introduction
In 2010 a Blue Ribbon Task Force on Sustainable Preservation and Access [3] confirmed that the major obstacle preventing digital content surviving to be used by future scholars was economic. No-one had a sustainable business model providing adequate funding for the organizational and technical processes needed to assure preservation.
The LOCKSS1 Program started in 1998 with a small grant from the NSF [28]. The technology was developed into a production system with support from NSF, the Andrew W. Mellon Foundation and Sun Microsystems. Grants such as these are not a sustainable basis for long-term preservation. The LOCKSS Program planned to use the "Red Hat" business model of free, open-source software and paid support2. Libraries using the technology would subscribe to the LOCKSS Alliance and would receive support. In 2005 the Mellon Foundation gave the program a 3-year grant which had to be matched from LOCKSS Alliance income. After the grant period the program had to survive without grant funding.
The program met the grant conditions with a year to spare, and has operated in the black ever since. No grants were received from 2007 to 2012. Now, nearly 20 networks use the LOCKSS technology to preserve content including books, journals, government documents and collections stored in institutional repositories. Experience with operating the "Red Hat" model has been generally positive. It requires a development process yielding frequent small enhancements to the system that meet the evolving needs of the user community, and a consistent focus on reducing the costs the system imposes on both the users and the support organization.
The need for frequent small releases and reducing costs makes it difficult for the support organization to commit resources to infrastructure developments that, while not responding to immediate user needs, are necessary to handle foreseeable issues in the medium term. After earlier work involving the instrumentation of several LOCKSS networks to investigate their detailed behavior, the LOCKSS team had identified a number of such developments. In 2012, after discussions with the Mellon Foundation about them, the LOCKSS Program was awarded a grant that, over its three years, allowed for about a 10% increase in program expenditure. Below, we report on the results of this funding.
2 The LOCKSS Technology
The LOCKSS system ingests, preserves and disseminates content using networks of peers, sometimes called LOCKSS boxes [21]. Each peer is an independent computer running software called the LOCKSS daemon, implemented in Java, which performs all three functions. Each peer's LOCKSS daemon collects content independently by acting as a Web crawler, and disseminates it by acting as either a Web server or a Web proxy. The daemon is configured to collect content from a particular Web site via a plugin, a set of Java classes mostly defined in XML that understands how to crawl that site, and how to divide the site's content into Archival Units (AUs). An AU is typically a volume of a journal.
All LOCKSS networks run the same daemon software in different configurations. The enhancements were released to all networks, but initially only two production preservation networks enabled them in their configurations:
- The Global LOCKSS Network (GLN), a network of nearly 150 peers each under independent administration and each intended to hold only materials to which the host library subscribes.
- The CLOCKSS network, a Private LOCKSS Network (PLN) of 12 peers under central administration and each intended to hold exactly the same content.
2.1 Preservation
The preservation of content in LOCKSS networks depends on peers detecting damage to their content, and repairing it. The LOCKSS daemon's peer-to-peer polling mechanism detects damage by discovering disagreement between the content of the instances of the same AUs at different peers, and enables its repair by discovering agreement. A peer that detects damage to its AU requests a repair from another peer that has agreed with it about the same AU in the past. The LOCKSS system is intended to preserve copyright content. The peer from which a repair is requested knows it is not leaking content if it remembers the requestor agreeing in the past about the requested content. If it does, it knows it is replacing a pre-existing copy, not creating a new one.
Thus LOCKSS boxes at libraries form a peer-to-peer network which performs five functions:
- Location: enabling a LOCKSS box in the network to find at least some of the other LOCKSS boxes in the network that are preserving the same AU.
- Verification: enabling a LOCKSS box to confirm that the content it has collected for an AU is the same (matching URLs, with matching content) as other LOCKSS boxes preserving the same AU have collected, thus identifying and correcting errors in the collection process.
- Authorization: enabling a LOCKSS box that is preserving an AU to provide content from that AU to another LOCKSS box preserving the same AU in order to repair damage, because the other LOCKSS box has proved to this LOCKSS box that in the past it collected matching content from the publisher. This box is a willing repairer for the other box.
- Detection: of random loss or damage to content in an AU at a LOCKSS box in order that it might request repairs to the content from other LOCKSS boxes preserving the same AU.
- Prevention: of attempts at deliberate modification of content in an AU at multiple LOCKSS boxes in the network, by detecting that non-random change had occurred at multiple LOCKSS boxes.
LOCKSS boxes perform these functions by participating in polls [20]. When it has resources available, each box uses a randomized process to choose one of the AUs it holds. It calls a poll on it, becoming the poller, and inviting a number of other boxes to become voters in the poll. The poller generates a random nonce Np and sends it to the voters. Each voter generates a random nonce Nv and sends the poller a vote containing (Np,Nv,H(Np,Nv, content(AU)) where H() is a hash function and content(AU) is the content of each URL in the AU instance at that voter.
The poller receives each of the votes and verifies them by computing H(Np,Nv, content(AU)) for each vote using the content of each URL in the poller's instance of the AU. Matching hashes indicate agreement between the corresponding URLs in the AU instance at the poller and that voter, mismatches indicate disagreement. If a majority of the voters disagree with the poller, the poller determines that its content is damaged and requests a repair from one of its "willing repairers".
3 Technology Enhancements
The grant envisaged enhancements to the LOCKSS technology in three areas, ingest, dissemination and preservation.
3.1 Ingest
Content on the early Web was static. Each time a browser fetched the content at a URL it got the same content. A Web crawler such as Heritrix [24] could collect an individual Web site, or even the entire Web, by following the links in the content, and fetching each of them in turn.
As the Web evolves, it is less and less true that each time a browser fetches content at a URL it gets the same content.
3.1.1 Form-Filling
One early cause of this was pages containing forms requiring text input or menu selection to access the content. Examples include login pages, search boxes, pulldown menus, and radio buttons. The LOCKSS crawler had from the start special-purpose code to allow it to access content protected by login pages, but this code could not handle general form filling. Among the sites whose use of forms makes them difficult to collect are many federal and state Web sites vital to government documents librarians.
Before the grant, the LOCKSS team and Masters students at Carnegie-Mellon University's Silicon Valley campus prototyped powerful form-filling capabilities for the LOCKSS crawler. During the grant this prototype was re-written to use the JSoup HTML parser. It starts by identifying the forms in collected HTML. It then generates all possible user actions for them thus:
- All form tags and form elements from the JsoupHtmlLinkExtractor are converted into sets of URL components, which are then assembled to produce the possible URLs.
- To allow form tags, which if they have a form ID may be outside the form itself, to be correctly assigned, the document is searched for all forms with IDs. As form element tags with IDs are encountered they are attached to the form with the matching ID.
- Form submit or image elements are counted to make sure that at least one such element exists and any formaction attribute which may override the form's action is tracked.
- Forms without IDs are processed as soon as the close tag is encountered. Forms with IDs can only be processed after all other tags have been extracted.
- When a form is processed each form field is examined to determine the iterator that will generate the set of possible values for that element type from a set of strings supplied by the plugin, and any attributes specified by the field.
- A form emits URLs consisting of the form action followed by a question mark, then pairs of (name)=(value) separated by ampersands.
The generated action URLs are filtered by the plugin's crawl rules before being executed.
The mapping between form tags and iterators is shown in Table 1. The available iterators are:
- SingleSelectFieldIterator used to generate a [name, value] pair for each possible value.
- MultiSelectFieldIterator used to generate [name, value] pairs for a power set of all values.
- Plugin defined iterators are assigned to a field name, allowing the plugin to specify in detail how values for a text or number field should be generated. Examples include:
- IntegerFieldIterator generates all values within a plugin defined range of integer values with a fixed stepping interval.
- FloatFieldIterator generates all values within a plugin defined range of float values with a fixed stepping interval.
- CalendarFieldGenerator generates all values within a plugin defined range of dates with a fixed stepping interval.
- FixedListFieldGenerator generates all values from a plugin defined list of values.
- FormFieldRestrictions restricts the values of a field to a known set of permissible values either by explicitly excluding and/or including a list of values. Before a field is processed each value is checked against these restrictions before being added to the form collector for that field.
| Tag |
Required |
Multi-select |
Default Iterator |
| input:hidden |
Yes |
No |
SingleSelectFieldIterator |
| input:checkbox |
Opt |
Yes |
MultiSelectFieldIterator |
| input:radio |
Yes |
No |
SingleSelectFieldIterator |
| input:submit |
Yes |
No |
Submit |
| input:image |
Yes |
No |
Submit |
| button:submit |
Yes |
No |
Submit |
| select:option |
No |
Opt |
Opt defined |
| others |
Opt |
N/A |
Plugin defined |
Table 1: Form Tags & Iterators The effect of adding form-filling capability to the plugins for three journals typical of those using forms is shown in Table 2. The Total URLs column shows the number of URLs collected with form-filling, the Generated URLs column shows how many of them were the result of form-filling, and the Increase column shows the percentage increase in URL collection as a result of enabling form-filling. In these cases the investment of a combinatorial increase in crawling cost returns a significant increase in the amount of content harvested.
| Journal |
Form Collected |
Radio buttons |
Check boxes |
Total URLs |
Forms |
Generated URLs |
Increase |
| Intl. J. Geomechanics |
Citations |
6 |
1 |
1096 |
37 |
444 |
67% |
| J. Architectural Engineering |
Citations |
6 |
1 |
820 |
32 |
384 |
88% |
| Genome |
Citations |
3 |
0 |
820 |
121 |
242 |
44% |
Table 2: Single-volume increase in collection via form-filling. 3.1.2 AJAX
Currently, the major reason that the user's experience is different on every visit to many Web sites is that it is generated dynamically using AJAX (Asynchronous Javascript And XML) [34]. Instead of the browser downloading content from the Web server, parsing and rendering it, the browser downloads a program in Javascript, and runs it. This program interacts with potentially multiple Web servers to provide the dynamically changing user experience. The new HTML5 standard [33] builds on AJAX; in effect it changes the basic language of the Web from HTML, which is a document description language, to Javascript, which is a programming language.
This poses a major problem for Web preservation. Previously, a Web crawler could find the links to follow simply by parsing the content it obtained. With AJAX, and HTML5, the crawler has to execute the program it downloaded, watching to see what other content the program fetches. Executing content downloaded from the Web poses security and resource exhaustion risks for the Web crawler, just as it does for the browser. This is why cautious Web surfers protect themselves using browser plugins such as NoScript [10] to constrain the Javascript their browser will execute.
Before the grant, the joint CMU/LOCKSS team did proof-of-concept work using the Selenium browser automation system [14] to show how the LOCKSS crawler could be extended to collect AJAX content safely. The grant-funded work was based on lessons learned in this process, and on two subsequently available open-source software components:
- The Crawljax crawler [23] supplements the existing crawl mechanisms. It executes the dynamic elements on a page and captures the Document Object Model (DOM) [32] as it transitions between states. This allows for urls which are dynamically generated to be captured for more complete preservation of a site.
- The standard WARC file proxies capture all HTTP requests and responses as they occur and package them as WARC files (ISO 28500) [19]. These files are then processed by the LOCKSS daemon's WARC importer to store the captured information into the appropriate AU. It can then be parsed using the existing parser and crawl rules.
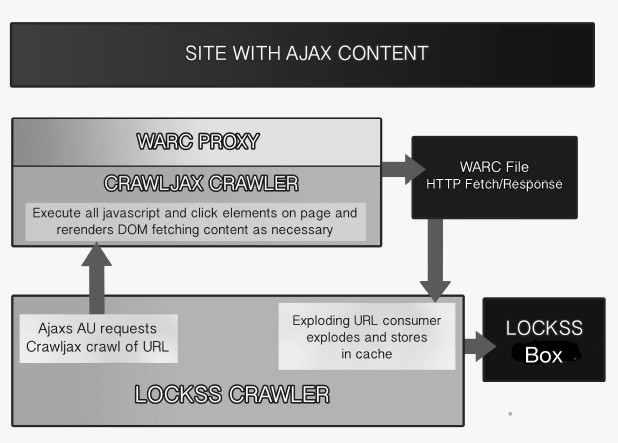
Figure 1: AJAX Crawler Structure
Crawljax is configured via a plugin that determines which elements on the targeted Web page are to be executed, and which proxy will be used to capture the HTTP(S) traffic generated by doing so. The proxies that can be used are:
- LAP, the Live Archiving Proxy [16] developed by the French Institut National de l'Audiovisuel (INA) [17], who were supported to open-source it by the International Internet Preservation Consortium (IIPC) [15].
- WarcMITMProxy [8], an open-source HTTP(S) proxy implemented in Python that outputs WARC files.
- And for testing and development, a Crawljax proxy plugin that outputs traffic in a simple JSON format.
In operation, crawling a site containing AJAX involves the following stages:
- A normal LOCKSS crawl whose plugin is configured for AJAX starts.
- The crawl continues as normal unless a URL is encountered which when matched against the plugin's crawl rules indicates the need for an AJAX crawl.
- The LOCKSS daemon starts two separate processes:
- The Crawljax service configured for a single page crawl of the URL in question.
- The selected proxy configured to capture the HTTP(S) traffic generated by Crawljax.
- Crawljax executes all of the Javascript on the page, and clicks on all the clickable elements in the page.
- The selected proxy captures the HTTP(S) requests from and responses to Crawljax's rendering of the page.
- When the page crawl completes Crawljax reports to the LOCKSS daemon the location of the WARC file generated by the proxy.
- The LOCKSS daemon "explodes" the WARC file, treating each component URL and content as if they had been collected by the LOCKSS crawler, including matching each against the plugin's crawl rules.
- Each matching URL and content is stored in the appropriate AU in the LOCKSS daemon's repository.
The process of executing all the Javascript and clicking on all the clickable elements in the page suffers from the same problem as with form-filling. The cost, already much higher than with form-filling, increases combinatorially with depth. It is impractical to use the AJAX crawler except on sites that rely heavily on AJAX, and lack any alternative means of collecting their content (see Table 3).
| Depth |
Crawl Time(s) |
DOM States |
URLs Visited |
| 1 |
124 |
21 |
14 |
| 2 |
3488 |
240 |
94 |
Table 3: Increase in cost with AJAX crawl depth. Examples of such sites are the journals of the Royal Society of Chemistry (RSC), in which Javascript is used in many ways, including to select which articles appear on an issue table of contents page. As following the links on the issue table of contents page is how the LOCKSS crawler normally finds the articles, this was a barrier to preservation. Figure 2 is a screen capture of a typical RSC table of contents page, showing the user experience. Figure 3 is a screen capture of the same page with Javascript disabled, showing what the LOCKSS crawler would see.
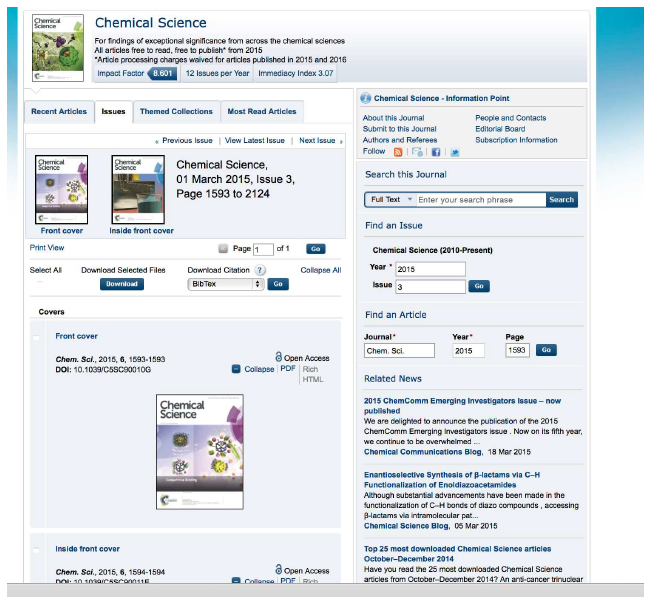
Figure 2: User view of RSC journal page
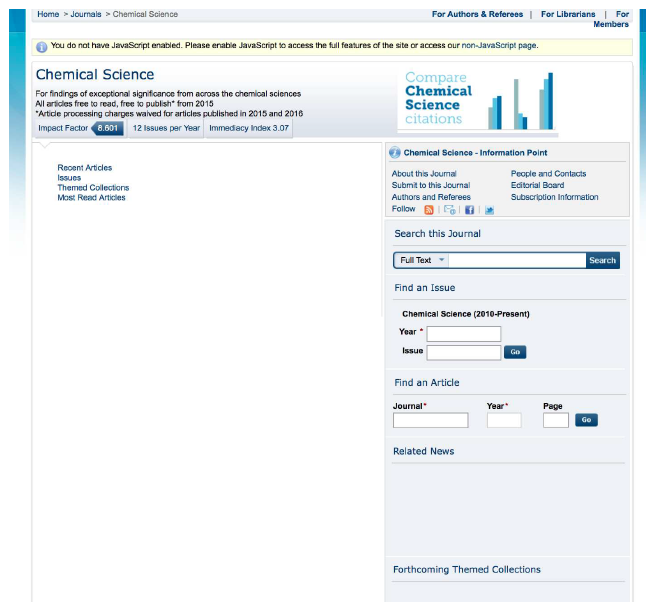
Figure 3: No-Javascript view of RSC journal page
The difficulty and cost of finding the content on heavily AJAX-ed sites is a problem not merely for preservation crawlers such as LOCKSS' and the Internet Archive's Heritrix [24], but far more importantly for search engines' crawlers such as the Googlebot [11]. Journals are strongly incentivized to make life easy for the Googlebot, so although one result of the grant is that the LOCKSS system can crawl pages such as the RSC's issue table of contents, doing so is less and less necessary. Figure 4 is a screen capture of the alternate to the page of Figure 2 that became available to crawlers during the grant. Many journals whose user experience is implemented largely by AJAX now provide such alternates.
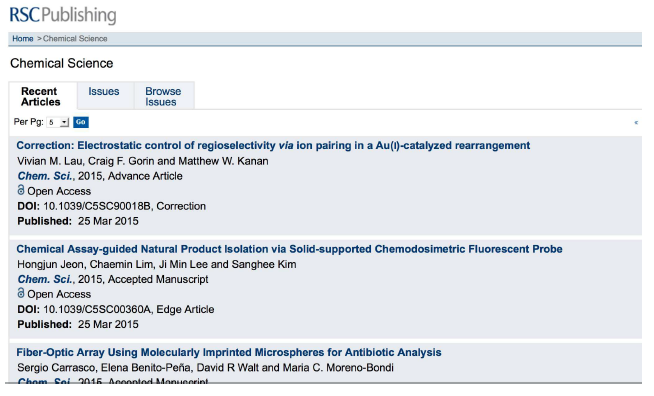
Figure 4: No-Javascript view of alternate RSC page
Although the AJAX support is fully functional it has not yet been released in the LOCKSS daemon for two reasons; issues with licensing and some security concerns remain to be addressed, and in most cases alternate, less expensive ways to collect the important content have been provided.
3.2 Dissemination
Access to preserved Web content, for example via the Internet Archive's Wayback Machine [18], has suffered from a fundamental technical deficiency. The URI (A) from which the preserved content was collected points to the original publisher; the URI (B) from which the preserved version may be obtained points to the archive that preserves it. The Web provided no way to navigate from A to B. This caused two problems:
- A reader wanting to see an earlier version of A had to know a priori about the existence of B; there was no general way to discover the possibly multiple archives preserving the state of B at different times.
- B would typically contain links to other Web content, such as C. A reader clicking on the link to C would see not the state of C as it was when B was current, but the state of C now. As they disseminated content, archives such as the Wayback machine rewrote the links to C in the preserved content B so that instead of pointing to the original publisher, they pointed to the corresponding preserved content. This rewriting process was complex, and error-prone. Failures led to user confusion as they viewed pages partly made up of preserved content, and partly of current content.
RFC 7089 [31], or Memento, is a Web standard that resolves these issues in an elegant and effective way by extending the content negotiation capabilities of the HTTP protocol to the time domain. Once it is fully deployed, it will allow Web browsers to specify a time in the past at which they want to view the Web, and transparently obtain the appropriate Mementos, or preserved content versions B of every URI involved, no matter which Web archive is preserving them. In effect, Memento will integrate all collections of preserved Web content into a single, uniformly accessible resource for readers.
Support for Memento is in two parts. The first is intra-archive. It allows each individual archive to respond to Web requests specifying a URI and a datetime by returning the Memento closest in time it has preserved, and associating with it links to the previous, next, first and last Mementos it has preserved. Under the grant, this functionality was implemented and released in the LOCKSS daemon.
The second part is called Memento Aggregation; it is inter-archive, satisfying Web requests for a URI at a datetime from whichever archive has the closest Memento in time by merging the Memento timelines from all available archives. Memento Aggregators can be thought of as search engines in the time domain. Prior to the grant, three problems with Memento's model of aggregation had been identified [27]. It assumes:
- All archived content is open access.
- Archives supply the Aggregator only with correct information.
- The Aggregator knows every Memento in every archive.
The first is not true. Many significant Web archives, for example the British Library's [13], are partly or wholly available only to readers physically at the Library. LOCKSS boxes hold both content which can be made freely available, such as that carrying Creative Commons licenses [7], and subscription content available only to readers at their host institution.
The second isn't true either. A malign archive could claim to have Mementos of URIs at "every minute of every day" [6], making other archives' much sparser collections effectively inaccessible. Archives need not be malign to have a similar effect. For example, the Internet Archive has Mementos of many subscription journal pages despite not having a subscription [26]. Because those journals' websites refuse to supply content to non-subscribers not, as the HTTP specification requires, with a 403 Forbidden error code but with a 200 Success code, the Internet Archive incorrectly thinks that their pages saying "You do not have a subscription" are useful Mementos.
The third is a scaling problem. The Internet Archive alone currently has more than 4.5∗1011 Mementos. Describing each to an Aggregator requires about 102 bytes, so just this one archive would need about 4.5∗1013 bytes, or 45TB. Clearly, practical Aggregators must use statistical techniques to guide browsers to archives that have a high probability of having an appropriate Memento. They cannot expect perfect accuracy.
During the grant the LOCKSS team contributed to research, primarily funded by the IIPC, into these problems but as yet they remain unresolved [1]. An aggregation capability was added to the LOCKSS daemon such that an institution's users using it will see Mementos from their institution's LOCKSS box, together with Mementos from other archives provided by a fall-back global Aggregator such as the Time Travel Service [22].
Assuming these problems can be resolved, these changes will mean that open access content preserved by the LOCKSS system will form part of the collaborative, uniform Web history resource enabled by Memento. In addition, readers of a library preserving subscription content using a LOCKSS box will see the preserved subscription content as a seamless part of this resource.
Because LOCKSS boxes were designed to preserve content obtained under their host library's subscriptions, they used the same IP address based access control method as the journal publishers did. Gradually, publishers are adding support for Shibboleth [25], which allows readers to access content to which their institution subscribes irrespective of their IP address.
To take part in the more integrated dissemination process enabled by Memento, LOCKSS boxes need a more flexible access control technology and Shibboleth is the obvious choice. We added Shibboleth support to the daemon, and in order to test it we connected one of our development LOCKSS boxes to Stanford's Shibboleth-based authentication infrastructure. In the test environment, the result was that a reader attempting to access the box would encounter first the normal LOCKSS administrator login sequence, then Stanford's two-factor authentication system. Figure 5 is a sequence of four screenshots, showing the LOCKSS login, the Stanford login/password page, the page for the Stanford hardware token, and finally the LOCKSS box's daemon status page.
These tests showed that the mechanism worked, but that we needed more experience of connecting to different institution's Shibboleth infrastructures before deploying it to the production networks would be feasible. We will be working with some PLNs to acquire this experience.
3.3 Preservation
In 2009 a pilot program instrumented the detailed behavior of LOCKSS boxes in the GLN, and compared them with LOCKSS boxes in PLNs. This comparison revealed a set of inefficiencies in the way the GLN performed the five polling functions, primarily because PLNs have fewer nodes preserving more homogeneous collections of content. The LOCKSS team proposed fixes for these inefficiencies, and implemented the ones that didn't require significant resources to good effect.
It didn't prove possible to divert sufficient resources from satisfying users' immediate concerns to implement the remaining fixes. These fixes fall into three groups: filtering, proof of possession polls, and symmetric polls.
The combined effect of the grant-funded work to implement these three sets of changes was expected to be a major decrease in the amount of computation, I/O, memory, and network traffic consumed by the LOCKSS software preserving a given amount of content in the GLN. Another way of looking at this is that libraries' existing investments in hardware resources to run LOCKSS software would, if provided with sufficient additional disk storage, be capable of handling the growth of the content available to preserve for much longer.
3.3.1 Filtering
Each LOCKSS box in the network collects its content directly from the publisher. As described in Section 3.1, much of this content is now dynamically generated, and will differ from one LOCKSS box to another. Examples are personalizations such as "Institution: Stanford University", watermarks such as "Downloaded 11/22/11 by 192.168.1.100", and lists of citing papers.
The prevalence of dynamically generated content makes it less and less likely that the copies at remote LOCKSS boxes available to repair any damage will be bit-for-bit identical to the local copy before it was damaged. For example, the offered repair may have
<div class="institution">"Institution: Edinburgh University"</div>
where the damaged copy had
<div class="institution">"Institution: Stanford University"</div>
Before an offered repair is accepted, two questions need to be answered:
- Is the repair functionally equivalent to the content it is repairing?
- Is the repair unaltered since it was originally collected?
LOCKSS boxes used the same polling mechanism to answer both questions. Over time, the increase of dynamic content is reducing its effectiveness. We proposed instead to use separate but synergistic mechanisms, adapting the ideas developed by students of Professor Mema Roussopoulos at Harvard's Computer Science department for exploiting local "polls" in the LOCKSS context to answer the second question [5], and reserving the existing LOCKSS polling mechanism to answer the first.
Content is defined as "functionally equivalent" by comparing it after filtering to remove the dynamic parts, such as personalizations. Content that is the same after these parts are removed is regarded as functionally equivalent. Removing the need for this filtering from the mechanism that assures that content is unchanged since collection allows the filtering process for functional equivalence to be more aggressive, and thus more robust against changes to the look-and-feel of the publisher's web site. We expected that in many cases it would be possible to filter everything except the content the author generated, which might for example be flagged with
<div class="text">"author's words"</div>
and the equivalent for formats other than HTML.
Experience over the last 7 years led us to believe that basing the determination of functional equivalence on more aggressive, and thus more robust filtering should materially reduce the load on the LOCKSS team of coping with changes to publishers' web sites.
3.3.2 Symmetric Polls
Before enhancement the LOCKSS polling mechanism used only asymmetric polls. These polls are asymmetric because the poller proves that its content agrees with that at the agreeing voters, but the voter does not prove that its content agrees with that at the poller.
A voter in a symmetric poll generates two nonces Nv and Ns. The vote it sends to the poller includes both. When a poller receives a vote containing Ns, while it is verifying the vote it computes a new vote containing (Np,Ns,H(Np,Ns, content(AU))) that it sends back to the voter. The voter verifies this return vote and, if it agrees, it has proof that its content matches that at the poller. An asymmetric poll with Q voters can create a maximum of Q "willing repairer" relationships; a symmetric poll with Q voters can create a maximum of 2Q. In practice most polls create fewer than these limits.
Symmetric polling was predicted to have a more significant effect on diverse networks such as the GLN, in which the probability that a random pair of peers both have instances of the same AU is low, than on tightly controlled networks such as CLOCKSS, where the probability is close to 1.
3.3.3 Proof of Possession
Recent CS research has distinguished between Proof of Retrievability (PoR) [4], and Proof of Possession (PoP) [2]:
- PoR processes the entire file, and guarantees that, during the proof, the prover had access to a complete, intact copy of the file in question.
- PoP samples the content of the file to provide high confidence that, during the proof, the prover had access to a copy of the file in question without proving that the copy was complete, and intact.
Because, for large files, even quite small samples can provide very high confidence that the prover has a copy, PoP can be much cheaper than PoR.
Before enhancement the LOCKSS polling mechanism used only PoR polls. They are PoR because each poll hashes the entire content of the AU instance at the poller and the voters. In the LOCKSS context, only detection and prevention actually require PoR, whereas location, verification and authorization can use PoP.
PoP polls were implemented by allowing a poller whose instance of an AU needs more "willing repairers" to include a modulus M along with Np. A URL is included in the vote, and thus its content hashed by each voter and the poller, only if the hash of a nonce and the URL's name modulo M is zero. Thus M = 2 includes about half the URLs in the vote. Since hashing is the major cost, PoP polls consume a factor of nearly M less resource at the poller and each voter than PoR polls.
3.3.4 Local Polls
PoP polls are not effective as integrity checks because they only examine a sample of the content. Their use must be combined with some means of compensating for this reduced integrity checking. Most digital preservation systems perform integrity checks by computing a hash of the content as it is ingested, storing both content and hash, and at intervals recomputing the hash of the content to compare with the stored hash. This results in either:
- A match. This indicates that either:
- The content and the hash are unmodified, or
- The content has been modified and the hash modified to match.
- A mis-match, indicating that either the content or the hash has been modified, or possibly both, but not so they match.
Techniques, for example based on Merkle trees, are available to detect modification of the hash [12], but alone they do not allow for recovery from the damage. Stored hashes are thus not an adequate basis for a system such as LOCKSS that must recover from damage, and that must defend against a wide range of threats [29]. The LOCKSS system did not, and still does not depend on storing hashes.
Local polls do use hashes computed at ingest and stored, but only as hints. A local poll on an AU computes the hash of the unfiltered content of each URL in the AU and compares it with the URL's stored hash. Any mis-match causes the poll's result to be disagreement, otherwise the result is agreement. An agreeing local poll reduces the AU's priority for a PoR poll, a disagreeing local poll raises it. The use of local polls can thus increase the interval between expensive PoR polls without increasing the intervals between integrity checks, thus reducing overall resource cost.
4 Preservation Performance
4.1 Monitoring
In order to prove that the preservation enhancements actually delivered their expected benefits, it was necessary to collect and analyze data describing the performance of the networks. The pre-existing data collection and analysis technology was inadequate to this task; it didn't collect enough data and failed to collect some parameters needed for meaningful analysis. As a result, a significant part of the enhancement effort involved developing improved data collection and analysis technology.
4.1.1 Data Collection
The data collection system is a modular Python framework developed during the grant to collect network performance statistics from individual LOCKSS daemons. The core functionality of the framework is to poll the administrative user interface of each peer in a network and to parse the returned XML into a Pythonic data structure for immediate use or storage into a MySQL database. The specific data to be collected and stored is defined by data collection plugins, essentially Python modules. All collected data is grouped into collections or observations which are tied to the date and time the collector instantiated.
Data was collected from every box in the CLOCKSS Archive. Some GLN box administrators choose to prevent data collection, and in other cases network performance is inadequate for consistent collection of the large volume of data required, so usable data is available from only a subset of the GLN's boxes. Because the conclusions we draw below are not based on absolute values, but on changes through time within the subset, the non-random nature of the GLN sample should not affect them.
4.1.2 Data Analysis
Subsets of the collected data are analysed by a tool implemented for this project in R [30] for numeric analysis and graph generation. Because the data set may span many observations and may not fit in memory, the tool fetches individual observations from the database for preprocessing then aggregates the results into printable and graph-able data.
The collected data can be analyzed in many ways; what follows is the simplest analysis that shows the effects of the preservation enhancements. After new content is released to a LOCKSS network for preservation, the LOCKSS boxes collect their copies, then call polls on them to locate other boxes holding the same content and establish "willing repairer" relationships with them. The less time it takes for this to happen, the better the polling process is working. For the whole period of our experiments, both networks had backlogs of newly released content that had yet to acquire sufficient willing repairers, so we were measuring how quickly additional willing repairer relationships could be created.
4.1.3 Definitions
The terms used in the performance analysis are defined as follows:
- The willing repairers of an instance of an AU at a peer in a network describes the set of other peers which have satisfied at least one of the following conditions in the most recent relevant poll:
- The other peer has voted in agreement with this peer in an asymmetric poll on this AU called by this peer in which this peer was in the majority.
- The other peer called a symmetric poll in which this peer voted in agreement with the other peer.
- A New Repairer Event (NRE) occurs whenever there is a change in the number of "willing repairers" an AU instance has, between successive observations by the data collector of that AU instance. We do not exclude the possibility of the number of repairers decreasing.
- The Days per Willing Repairer (DpWR) of an instance of an AU at a peer is the time between positive NREs at that AU instance. Since NREs are the result of polls, the DpWR depends on the rate at which polls occur in the network, which is stable over time.
- The aumedian of an AU instance at a peer is the median of the DpWR observed for that AU instance. The aumedian graph plots on the Y axis the proportion of the AU instances across all observable peers whose median DpWR falls within the interval on the X axis.
- The auidmedian of an AU is median of the set formed by the NREs of all instances of that AU across all observable peers. The auidmedian graph plots on the Y axis the proportion of AUs whose median DpWR across all their instances falls within the interval on the X axis.
In the following sections we show the aumedian and auidmedian graphs for data collected for the CLOCKSS and GLN networks. For each network, data was collected in three different periods:
- PreSymPoll — the period immediately preceding symmetric polls being enabled. For CLOCKSS, this dataset consists of 275,142 NREs from 12 peers, and for the GLN 980,230 NREs from 67 peers.
- PostSymPoll — the period between symmetric polls being enabled and PoP/Local polls being enabled. For CLOCKSS this dataset consists of 96,609 NREs from 12 peers, and for the GLN 365,536 NREs from 53 peers.
- PostPoPPoll — the period after PoP/Local polls were enabled. For CLOCKSS this dataset consists of 96,609 NREs from 12 peers, and for the GLN 532,387 NREs from 52 peers.
4.2 Symmetric Polls Only
The effect of enabling symmetric polling on the CLOCKSS network can be seen by comparing the before and after graphs in Figure 6 (comparing the aumedian graphs) which shows the most likely aumedian DpWR improved from between 30-60 to 10-20 days/repairer and Figure 7 (comparing the auidmedian graphs) which shows the most likely auidmedian DpWR improved from 50-60 to 10-20 days/repairer.
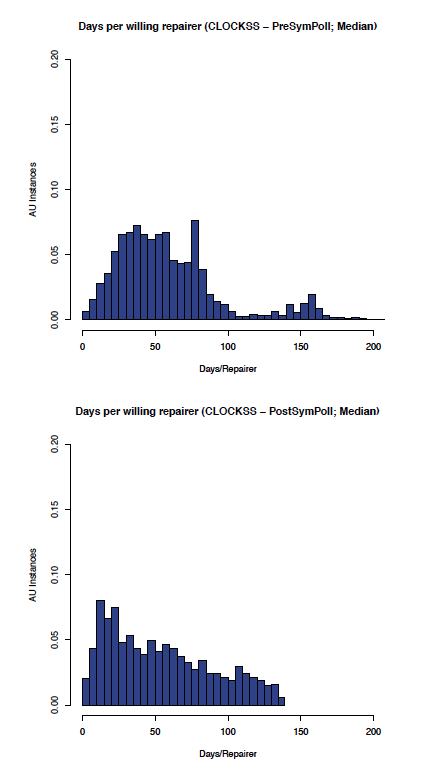
Figure 6: CLOCKSS: aumedian before and after symmetric polling
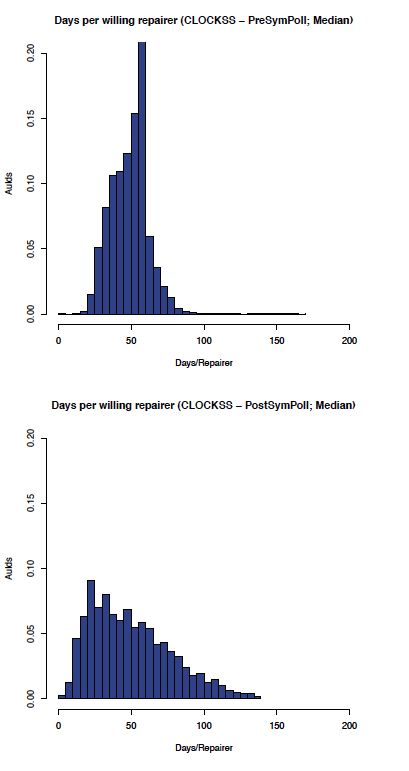
Figure 7: CLOCKSS: auidmedian before and after symmetric polling
Although the data is, as expected, noisier in the less controlled GLN, the effect of enabling symmetric polling can be seen by comparing the before and after graphs in Figure 8 (comparing the aumedian graphs) which shows the most likely aumedian DpWR improved from around 120 to under 30 days/repairer and Figure 9 (comparing the auidmedian graphs) which shows the most likely auidmedian DpWR improved from over 50 to under 30 days/repairer.
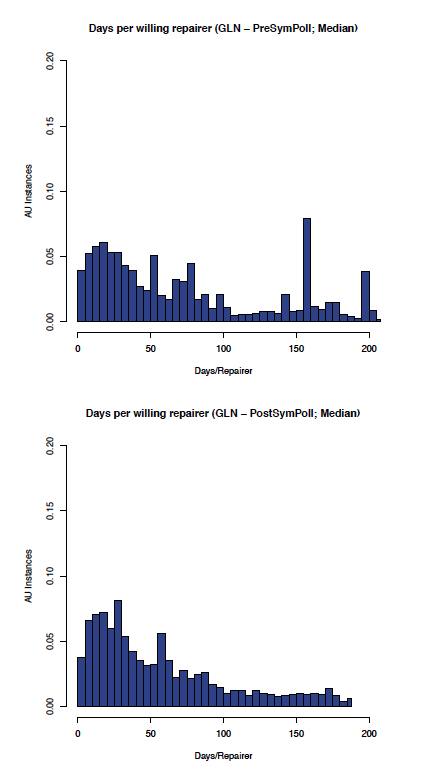
Figure 8: GLN: aumedian before and after symmetric polling
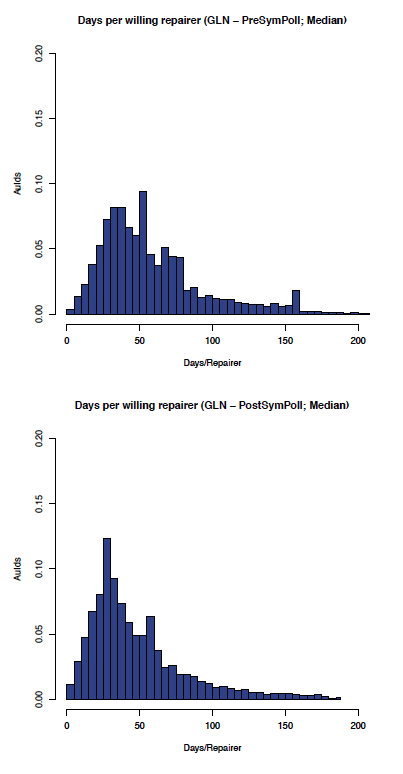
Figure 9: GLN: auidmedian before and after symmetric polling
As predicted, symmetric polling had a greater impact on the GLN than on the CLOCKSS network.
4.3 All Poll Enhancements
The effect of enabling Proof of Possession and Local polls on the CLOCKSS network can be seen by comparing the before and after graphs in Figure 10 (comparing the aumedian graphs) and Figure 11 (comparing the auidmedian graphs).
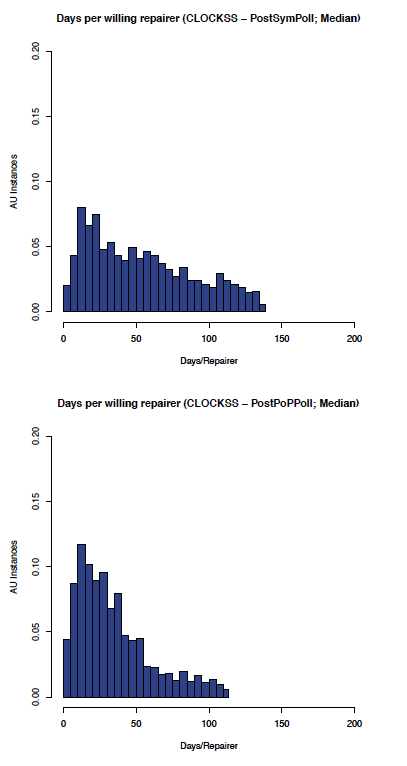
Figure 10: CLOCKSS: aumedian before and after PoP/Local polling
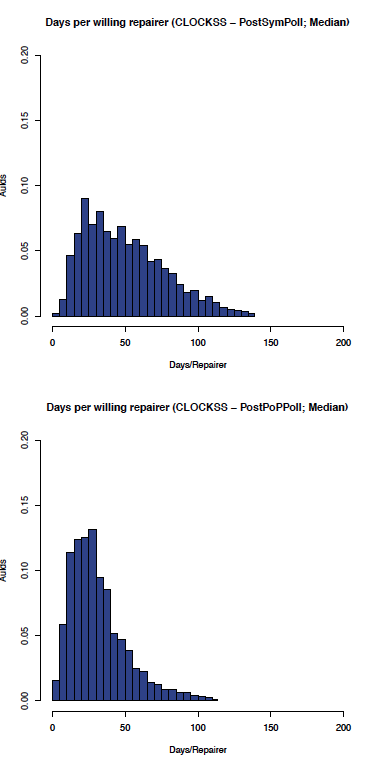
Figure 11: CLOCKSS: auidmedian before and after PoP/Local polling
As expected, the effect on the CLOCKSS network is not significant, although the auidmedian graph shows some improvement.
The effect of enabling Proof of Possession and Local polls on the GLN can be seen by comparing the before and after graphs in Figure 12 (comparing the aumedian graphs) which shows the most likely aumedian DpWR improved from about 30 to about 10 days/repairer and Figure 13 (comparing the auidmedian graphs) which shows the most likely auidmedian DpWR improved from about 25 to about 15 days/repairer.
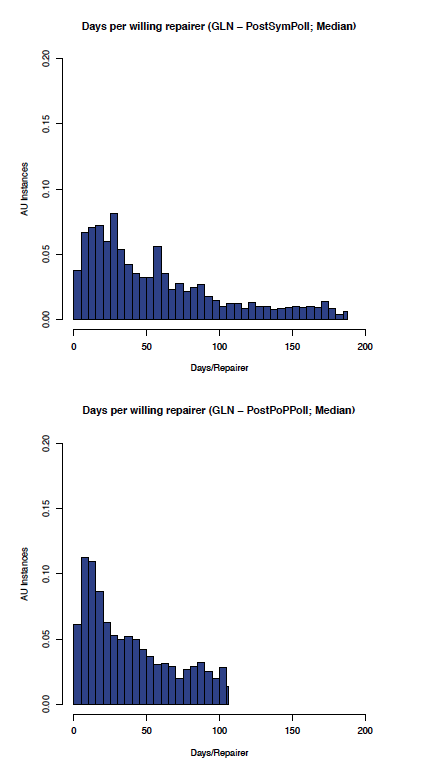
Figure 12: GLN: aumedian before and after PoP/Local polling
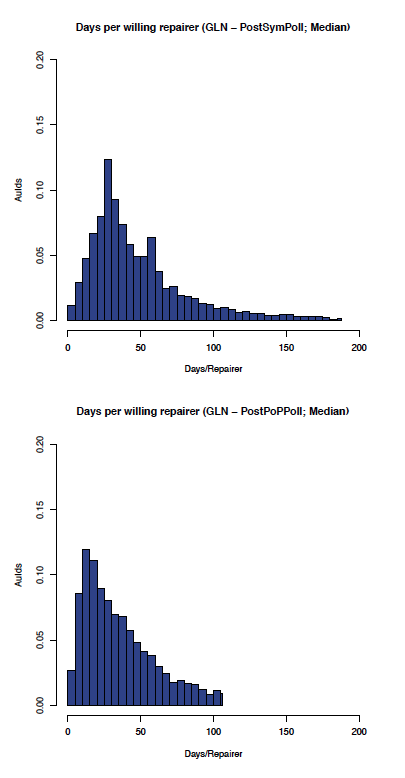
Figure 13: GLN: auidmedian before and after PoP/Local polling
4.4 Future Work
The effectiveness of these enhanced mechanisms depends upon the policies that peers use to decide when to call PoR, PoP and Local polls. Although the mechanisms are fully implemented and tested, the implementation of these policies is preliminary, and contains a number of tunable parameters which have been set to our best estimate of suitable values.
As will be evident, determining the effect of each policy and parameter change on the performance of a network takes a long time. The results above are the first step in an extended, gradual tuning process.
5 Conclusions
The Mellon Foundation grant allowed the LOCKSS Program to devote resources to making significant functionality and performance improvements to the system. Even in the areas of AJAX and Shibboleth, where deployment issues were not sufficiently resolved for immediate release, the basic mechanisms are in place and working. We expect that work to support initial deployment to individual PLNs will mean that these issues will be fully resolved by the time the broad user base requires these technologies.
It would have been difficult to do this without specific support. Although the experience of the LOCKSS Program suggests that the "Red Hat" model can be an effective business model for digital preservation, it may need to be supplemented at intervals by small, targeted grants if the infrastructure of the system is to keep pace with developments.
Acknowledgements
This work was primarily funded by the Andrew W. Mellon Foundation with additional support from the CLOCKSS Archive, and the libraries of the LOCKSS Alliance.
Notes
1 LOCKSS is a trademark of Stanford University. It stands for Lots Of Copies Keep Stuff Safe.
2 This business model was successfully pioneered by Michael Tiemann, David Vinayak Wallace, and John Gilmore at Cygnus Support [9], later acquired by Red Hat.
References
[1] Sawood Alam, Michael L. Nelson, Herbert Van de Sompel, and David S.H. Rosenthal. Archive Profiling Through CDX Summarization. In submission. Will appear in Lecture Notes in Computer Science, Vol. 9316.
[2] N Asokan, Valtteri Niemi, and Pekka Laitinen. On the usefulness of proof-of-possession. In Proceedings of the 2nd Annual PKI Research Workshop, pages 122—127, 2003.
[3] Blue Ribbon Task Force on Sustainable Digital Preservation and Access. Sustainable Economics for a Digital Planet, April 2010.
[4] Kevin D. Bowers, Ari Juels, and Alina Oprea. Proofs of retrievability: Theory and implementation. In Proceedings of the 2009 ACM Workshop on Cloud Computing Security, CCSW '09, pages 43—54, New York, NY, USA, 2009. ACM.
[5] Prashanth Bungale, Geoffrey Goodell, and Mema Roussopoulos. Conservation vs. consensus in peer-to-peer preservation systems. In IPTPS, February 2005.
[6] British Broadcasting Corporation. BBC News: Front Page, March 2000.
[7] Creative Commons. Web site.
[8] David Bern. WarcMITMProxy.
[9] John Gilmore. Marketing Cygnus Support — Free Software history.
[10] Giorgio Maone. NoScript.
[11] Google. Googlebot.
[12] S. Haber and W. S. Stornetta. How to Time-stamp a Digital Document. Journal of Cryptology: the Journal of the Intl. Association for Cryptologic Research, 3(2):99—111, 1991.
[13] Helen Hockx-Yu. Ten years of archiving the UK Web. In 10th International Digital Curation Conference, February 2015.
[14] Antawan Holmes and Marc Kellogg. Automating functional tests using selenium. In Agile Conference, 2006, pages 270—275. IEEE, 2006. http://doi.org/10.1109/AGILE.2006.19
[15] IIPC. International Internet Preservation Consortium.
[16] INA. INA-DLWeb Live Archiving Proxy.
[17] INA. Institut National de l'Audiovisuel.
[18] Internet Archive. The Internet Archive Wayback Machine.
[19] ISO. ISO 28500:2009.
[20] P. Maniatis, M. Roussopoulos, TJ Giuli, D. S. H. Rosenthal, and Mary Baker. The LOCKSS Peer-to-Peer Digital Preservation System. ACM TOCS, 23(1), February 2005.
[21] Petros Maniatis, Mema Roussopoulos, TJ Giuli, David S. H. Rosenthal, Mary Baker, and Yanto Muliadi. Preserving Peer Replicas By Rate-Limited Sampled Voting. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, pages 44—59, Bolton Landing, NY, USA, October 2003.
[22] Memento Development Group. About the Time Travel Service.
[23] Ali Mesbah, Arie van Deursen, and Stefan Lenselink. Crawling Ajax-based web applications through dynamic analysis of user interface state changes. ACM Transactions on the Web (TWEB), 6(1):3:1—3:30, 2012.
[24] Gordon Mohr, Michael Stack, Igor Ranitovic, Dan Avery, and Michele Kimpton. An Introduction to Heritrix: An Open Source Archival Quality Web Crawler. In IWAW04: Proceedings of the International Web Archiving Workshop, September 2004.
[25] R. L. Morgan, Scott Cantor, Steven Carmody, Walter Hoehn, and Ken Klingenstein. Federated Security: The Shibboleth Approach. EDUCAUSE Quarterly, 27(4), 2004.
[26] David S. H. Rosenthal. Memento & the Marketplace for Archiving. March 2013.
[27] David S. H. Rosenthal. Re-Thinking Memento Aggregation. March 2013.
[28] David S. H. Rosenthal and Vicky Reich. Permanent Web Publishing. In Proceedings of the USENIX Annual Technical Conference, Freenix Track, pages 129—140, San Diego, CA, USA, June 2000.
[29] David S. H. Rosenthal, Thomas S. Robertson, Tom Lipkis, Vicky Reich, and Seth Morabito. Requirements for Digital Preservation Systems: A Bottom-Up Approach. D-Lib Magazine, 11(11), November 2005. http://doi.org/10.1045/november2005-rosenthal
[30] R Core Team. R Language Definition. October 2014.
[31] Herbert van der Sompel, Michael Nelson, and Robert Sanderson. RFC 7089: HTTP Framework for Time-Based Access to Resource States — Memento, December 2013.
[32] W3C. Document Object Model (DOM) Level 1 Specification.
[33] W3C. HTML5: A vocabulary and associated APIs for HTML and XHTML.
[34] W3C. XMLHttpRequest Level 1.
About the Authors
 |
David S. H. Rosenthal has been a senior engineer in Silicon Valley for 30 years, including as a Distinguished Engineer at Sun Microsystems, and as employee #4 at Nvidia. 17 years ago he co-founded the LOCKSS Program at the Stanford University Libraries, and has been its Chief
Scientist ever since. He has an MA from Cambridge University and a Ph.D. from Imperial College, London.
|
 |
Daniel L. Vargas graduated from the University of California, Santa Cruz with a BA in mathematics. He has been working as a system administrator with the LOCKSS Program at Stanford University since 2009.
|
 |
Thomas Lipkis is Senior Software Architect of the LOCKSS program at the Stanford University Libraries, where he is primarily responsible for leading the design and implementation of the production LOCKSS system. His background includes work in operating systems, knowledge representation, manufacturing, communications and embedded systems.
|
 |
Claire Griffin is a Senior Software Engineer of the LOCKSS program at the Stanford University Libraries responsible for design and implementation of extensions to the LOCKSS platform. She previously worked a system developer for HighWire Press. She has a background in reputation systems, decentralized multiplayer online worlds and system platform development.
|
|