




Bei den roboterbasierten Suchdiensten wird eine automatisierte Volltextindexierung vorgenommen, es findet keine intellektuelle Indexierung statt. Die Volltextindexierung basiert auf der natürlichen Sprache, also den tatsächlich in den Dokumenten verwendeten Ausdrücken. Im Gegensatz zur intellektuellen Indexierung durch kontrolliertes Vokabular oder Thesauri, kommen in der natürlichen Sprache eine Vielzahl von Homonymen, Synonymen u.a. vor. Ein Wort kann verschiedene Bedeutungen haben, die sich nur aus dem Kontext erschließen (Homonyme). Andererseits kann das gleiche Konzept mit völlig unterschiedlichen Begriffen (Synonymen) ausgedrückt werden. Erschwerend kommt hinzu, daß die Dokumente in verschiedenen Sprachen vorliegen können. Dies schlägt sich in der Qualität der Ergebnisse nieder. Durch das Vorhandensein von Homonymen werden Dokumente gefunden, die keine Antwort auf die Fragestellung geben. Andererseits kann es durch das Vorhandensein unterschiedlicher Begrifflichkeiten und verschiedener Sprachen keine Sicherheit geben, alles zum Thema nachgewiesen zu haben.
Zusätzlich zur Indexierung des Volltextes werden von einigen Diensten einzelne Elemente der Dokumente (HTML-Elemente, bestimmte Dateitypen, wie Bilder, Töne etc., Metadaten) separat indexiert. Die Suchmöglichkeiten können dadurch verbessert werden, wenn diese Elemente auch speziell suchbar gemacht werden. Da die Dienste i.d.R. keine Aussagen zu ihren Indexierungsmethoden machen, können Rückschlüsse darauf nur aus den Möglichkeiten des Information Retrieval gezogen werden. Die Realisierungen bei den einzelnen Diensten werden daher im folgenden Abschnitt betrachtet.
Da die Indexierung nur geringe Möglichkeiten bietet, die Qualität der Treffermengen zu beeinflussen, können nur Methoden des Information Retrieval, die über die einfache Eingabe eines oder mehrerer Suchbegriffe hinausgehen, zur Verbesserung der Ergebnisse beitragen.
Im folgenden sollen weiterführende Methoden des Information Retrieval, die bei den roboterbasierten Diensten im Internet eingesetzt werden, beschrieben und im Hinblick auf ihren Nutzen für die Erhöhung von Precision oder Recall analysiert werden.[88] Es sind also besonders diejenigen Methoden interessant, die es dem Benutzer erlauben, über die ungeordnete oder natürlichsprachige Eingabe von Suchbegriffen hinaus das Suchergebnis zu beeinflussen.
Die angebotenen Methoden können unterteilt werden in solche, die zur Präzisierung und Einschränkung von Ergebnismengen eingesetzt werden können und solche, die zu einer Ausweitung der Suche führen, mit dem Ziel, möglichst umfassend alle Ressourcen zu einer Fragestellung zu finden. Einige Methoden können auch, je nach Anwendung, für beide Ziele verwandt werden.
Das Retrieval der meisten Suchdienste im Internet beruht auf dem best-match-Verfahren, oft ergänzt durch die Möglichkeit, in der erweiterten Suche Boole'sche Operatoren einsetzen zu können.
Boole'sche Operatoren können sowohl zur Reduktion als auch zur Vergrößerung gefundener Treffermengen dienen. Zur Einschränkung können neben AND und NOT Näheoperatoren (NEAR, BEFORE; ADJ ...) verwandt werden. Die Verknüpfung von Suchbegriffen mit Näheoperatoren wird inzwischen von den meisten großen Suchdiensten angeboten. Oftmals sind die Möglichkeiten hier jedoch eingeschränkter als z.B. von Online-Datenbanken bekannt. Es können selten exakte Wortabstände definiert werden. Die weitestgehenden Möglichkeiten bietet hier Lycos. Der Dienst gestattet es, den maximalen, mindesten oder genauen Wortabstand und die Reihenfolge der Begriffe im Text zu bestimmen.[89] Wichtig ist weiterhin die Möglichkeit der Verknüpfung von Operatoren durch Klammerausdrücke (nesting). Auch diese ist inzwischen bei vielen großen Suchdiensten gegeben.
Eine Ausweitung der Suche im Sinne erhöhten recalls ist durch die Trunkierung von Suchbegriffen und die Verwendung des OR-Operators möglich. Die Möglichkeit der Trunkierung gehört bei Online-Datenbanken zu den Standardfunktionalitäten. Sie ist bei Internet-Suchdiensten besonders wichtig, da diese automatische Volltextindexierung einsetzen und das Datenmaterial in natürlicher Sprache vorliegt. Die Trunkierung sollte dabei nicht automatisch erfolgen, sondern vom Nutzer steuerbar sein. Bei den großen Suchdiensten wird nutzergesteuerte Trunkierung allerdings nur von Alta Vista angeboten; weitere Dienste, wie Lycos reduzieren die Suchbegriffe z.T. automatisch auf ihre Wortstämme.
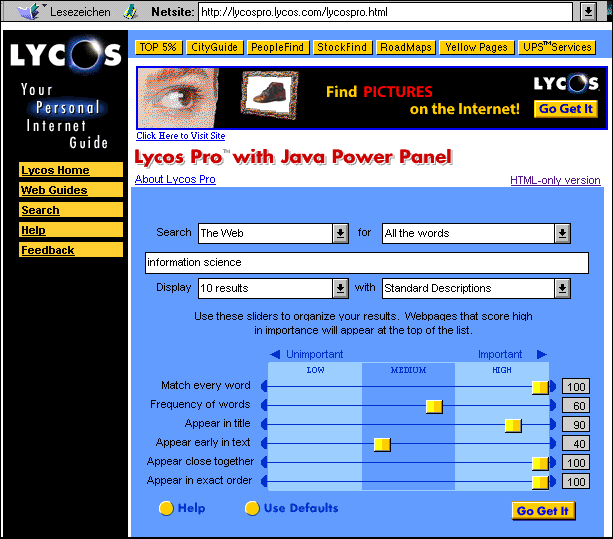
Bei der Verwendung des best-match-Verfahrens hat der verwendete Rankingalgorithmus einen erheblichen Einfluß auf die Präzision der Suchergebnisse. Dies gilt besonders bei großen Treffermengen. Der Nutzer ist meist auf das gute Funktionieren dieser Algorithmen angewiesen. Einzelne Dienste bieten jedoch die Möglichkeit an, die Rangordnung der Treffer aktiv zu beeinflussen. Bei der erweiterten Suche von Alta Vista (Advanced Search) kann die Rangordnung der Ergebnisse vom Benutzer durch die Eingabe von Begriffen in das Ranking-Feld bestimmt werden. Dokumente, welche die dort angegebenen Begriffe enthalten, werden zuerst angezeigt. Dabei können die für das Ranking maßgebenden Worte den Suchworten entsprechen, es können aber auch andere Begriffe sein. Da diese Begriffe nur Einfluß auf die Reihenfolge der Ergebnispräsentation haben, nicht auf die Treffermenge, dürfte sich diese bei Verwendung weiterer Worte für das Ranking nicht verändern. Dies funktioniert bei Alta Vista nicht korrekt. Auch Begriffe, die nur das Ranking beeinflussen sollten, verändern die Trefferzahl. Eine ähnliche Methode wird bei HotBot angewandt. Dort können bei den erweiterten Optionen (Super Search) unter "additional search terms" Worte eingegeben werden, die in den Ergebnisdokumenten enthalten sein sollten ("should contain the words"). Diese Begriffe sollen ebenfalls die Rangfolge der Ergebnisse beeinflussen. In der Praxis werden sie jedoch auch wie zusätzliche Suchbegriffe gewertet, haben also Einfluß auf das Ergebnis insgesamt, nicht nur auf die Reihenfolge der Anzeige. Differenziertere Möglichkeiten bietet Lycos mit dem Power Panel.[90] Der Nutzer kann hier die Gewichtung einzelner Elemente des Rankingalgorithmus, wie das Vorkommen des Wortes im Titel, die Häufigkeit und Stellung im Text etc., für die Ergebnisanzeige beeinflussen.
Abbildung 1: Lycos Power Panel (Stand: 13.1.1998)
Die Ergebnismenge kann weiterhin durch die Beschränkung der Suche auf bestimmte Protokolle, spezielle Datenbankinhalte, Medientypen oder einzelne Elemente der Dokumente eingegrenzt werden. Alta Vista und Infoseek z.B. ermöglichen eine Suche in den Beiträgen von Newsgruppen, bei Excite, Infoseek und HotBot kann in den aktuellen Meldungen von Nachrichtenagenturen gesucht werden und Magellan, Lycos und Excite (in den Power Search Options) gestatten es, eine Suche nur in den Kurzbeschreibungen ihrer manuell erstellten Verzeichnisse auszuführen.
Auch die Suche nach multimedialen Elementen, also Dateien in anderen Formaten als HTML, die oft innerhalb oder in Verbindung mit HTML-Dokumenten vorkommen, kann zur Präzisierung einer Suche eingesetzt werden. Alta Vista, Infoseek, Lycos, HotBot, der deutsche Suchdienst Kolibri u.a. ermöglichen die Suche nach Bildern, z.T. auch Tönen, Videos, JAVA appletts u.a. Dabei wird eine Suche in den entsprechenden Dateinamen durchgeführt bzw. es wird, wie bei HotBot, nur geprüft, ob ein bestimmter Dateityp oder eine Anwendung im Dokument enthalten ist. Eine Suche nach Bild- oder Audiodateien bestimmter Inhalte kann nur zu eingeschränkten Ergebnissen führen, da die Dateinamen nicht immer aussagekräftig sind. Weiterführende Suchmöglichkeiten nach Bildern bietet der dänische Teil des Nordic Web Index. Hier wurden auch Linktexte (anchor text), die auf Bilder verweisen, sowie bei Bildern in Texten (inline images) der gesamte zugehörige Abschnitt mit indexiert.
Zur Eingrenzung der Ergebnismenge und somit der Präzisierung der Suche kann auch beitragen, wenn statt im Volltext nur in einzelnen HTML-Elementen gesucht wird. Alta Vista, Infoseek, HotBot, Yahoo!, und OpenText ermöglichen, eine Suche auf die Titel der Dokumente oder deren URL zu beschränken. Eine Suche nur in auf den Seiten vorhandenen Links (citation indexing) kann dagegen zur Erhöhung des Recall genutzt werden, weil die Suche in den Linktexten (möglich bei Alta Vista und HotBot) oder den darunterliegenden URLs (Alta Vista, HotBot, Infoseek) zu zusätzlichen Dokumenten führen kann. Links entsprechen dabei Zitaten oder Literaturverweisen in gedruckten Publikationen. Sie verweisen auf Seiten, die im inhaltlichen Zusammenhang zueinander stehen. Die genannten Dienste weisen bei der Suche in den Texten oder URLs der Links diejenige Dokumente nach, die den Suchbegriff im Link enthalten (also die zitierenden Dokumente). Gegenwärtig bei keinem der genannten Dienste realisiert ist ein citation indexing in beide Richtung, wie bei den gedruckten Zitierindexen möglich (z.B. der vom Institute for Scientific Information herausgegebene Science Citation Index).[91] Dies bedeutet, daß nicht nur die zitierenden Quellen ausgegeben werden, sondern auch alle in diesen zitierten Dokumente. Damit kann der Aufbau eines Zitatennetzes zum Nachweis von Dokumenten zum gleichen Thema erleichtert werden. Ein spezieller Zitierdienst für WWW-Dokumente, der sowohl zitierende als auch zitierte Dokumente nachweist, ist der portugiesische Suchdienst Web Core. Dieser verzeichnet allerdings relativ wenige und vorrangig portugiesische Quellen.
Es wäre auch denkbar, weitere HTML-Elemente zu indexieren und suchbar zu machen, wie die Überschriften, das ADDRESS-Element u.ä. Dies würde aber voraussetzen, daß von den Autoren der Dokumente korrektes HTML geschrieben würde.
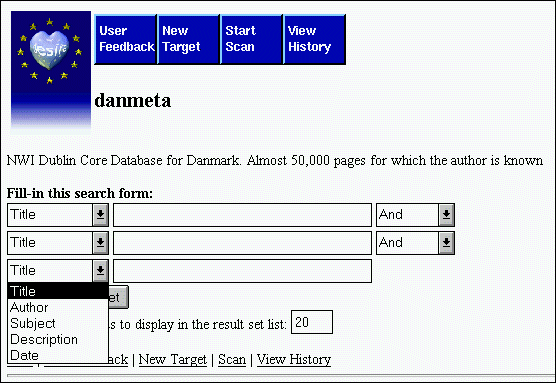
Großen Einfluß auf die Suchergebnisse kann die Indexierung und Suchbarmachung von Metadaten zu den Dokumenten im Internet haben. Als Metadaten werden - vor allem bei digitalen Ressourcen - Daten bezeichnet, die zur Beschreibung der Dokumente dienen und nicht diesen selbst zu entnehmen sind. Dies können Angaben zur inhaltlichen Charakterisierung der Ressource, wie Abstracts, Klassifikationscodes und Schlagworte, aber auch Informationen zu Autor, Erstellungsdatum, Zugangsbedingungen u.ä. sein. Metadaten können im HEAD des HTML-Dokumentes angegeben werden. Diese Möglichkeit war in den ersten HTML-Versionen nicht vorgesehen, die Bedeutung von Metadaten wurde erst später deutlich. Nur ein kleiner, wenn auch steigender Teil der HTML-Dokumente enthält bisher Metadaten. Die am häufigsten vorkommenden Meta-Elemente sind - neben automatisch generierten und für die Suche nutzlosen Angaben zum verwendeten Editor, Konverter o.ä. - Schlagworte und Kurzbeschreibungen der Dokumente.[92] Keiner der großen Suchdienste bietet bisher die Möglichkeit an, gezielt nach Metadaten zu suchen. Swiss Search ermöglicht die Suche in den Metaelementen keywords und description. Seit Oktober kann in dem deutschen Suchdienst Fireball nach verschiedenen Metadaten gesucht werden. Die Suche kann auf Angaben zur Zielgruppe, Autor, Urheberrecht, Beschreibung, Schlagworte, Thema, Seitentyp und Herausgeber eingeschränkt werden. Fireball stellt auch ein Eingabeformular zur Verfügung, das die Erstellung der Metadaten in der richtigen Syntax unterstützt. Es wird allerdings ein proprietäres Format verwendet, obwohl Standardvorschläge, wie das Dublin Core Element Set (DC)[93] existieren. Metadaten nach DC werden bisher nur in wenigen, kleineren Suchdiensten genutzt. Beispiele sind die Teilmengen des Nordic Web Index SWEMETA und DANMETA, weiterhin der in einer Testversion vorliegende HotMeta Broker des australischen MetaWeb Project; der MathN Broker sowie der fachspezifische, manuelle Dienst RUDI.
Abbildung 2: Eingabemaske für die Suche nach Metadaten in DANMETA (Stand: 21.1.1998)
Von den großen Suchdiensten berücksichtigen Infoseek, HotBot, Alta Vista und WebCrawler Metadaten immerhin indirekt, indem sie die Felder description und keyword (HotBot auch author) mit indexieren. Bei HotBot[94] beeinflussen die im Meta-Tag keyword vorkommenden Begriffe das Ranking der Ergebnisse.
Eine Suche kann auch durch die Einschränkung auf Dokumente einzelner Länder, Regionen, Sprachen oder Server präzisiert werden.
Es existieren einerseits Suchdienste, die nur Publikationen einer bestimmten Region, eines Landes oder einer Sprache verzeichnen, wie z.B. Fireball und Kolibri für deutschsprachige Quellen. Diese haben den Vorteil, innerhalb der gesetzten Grenzen umfassender sein zu können. Daneben bieten die großen, globalen Dienste zunehmend regionale Varianten mit der Option, die Suche auf die Dokumente einzelner Regionen zu beschränken. Aus der gesamten Datenbank werden dabei die Ressourcen bestimmter Domaingruppen (z.B. de, ch, at für den deutschsprachigen Raum) herausgefiltert. Dies ist für einige Länder bei Lycos, Infoseek und Excite verwirklicht. Auch HotBot, die europäischen Dienste Euroferret und EuroSeek sowie der simultane Suchdienst MetaCrawler gestatten die Eingrenzung der Suche auf einzelne Regionen oder Domains. Eine Eingrenzung nach Sprachen ist bei Alta Vista und EuroSeek möglich, wobei eine Spracherkennung durchgeführt zu werden scheint. Ein Filtern nach Domains oder Sprachen ist jedoch nur begrenzt hilfreich, da ohnehin die Sprache des Suchbegriffes meist schon eine Festlegung auf Dokumente einer Sprache bedeutet.
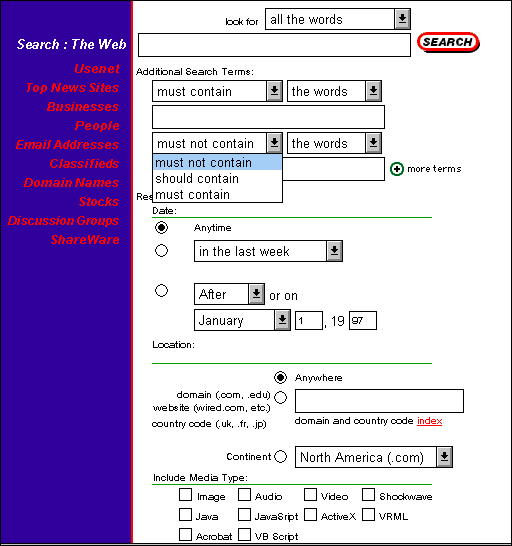
Eine weitere, sinnvolle Einschränkungsmöglichkeit bietet das Filtern nach dem Publikations- oder letztem Revisionszeitpunkt. Dies wird jedoch nur von HotBot und Alta Vista angeboten.
Abbildung 3: Eingabeformular HotBot Super Search mit verschiedenen Möglichkeiten der Präzisierung einer Suche (Gewichtung von Suchbegriffen, Datum, Domain, Medientyp) (Stand: 17.1.1998)
Eine fachliche Eingrenzung über eine Stichwortsuche hinaus ist bei den großen, generellen Suchdiensten nicht realisiert. Es würde die Verwendung von kontrolliertem Vokabular oder Klassifikationscodes voraussetzen, die z.B. in den Metadaten angegeben werden könnten. Fireball unterstützt in seiner Version von Metadaten auch die Zuordnung zu verschieden Sachgebieten. Schlagworte, Thesauri oder Klassifikationscodes werden bei bibliographischen Abstract- und Indexdatenbanken zu Erweiterung oder Einschränkung von Suchen eingesetzt. Keiner der roboterbasierten Suchdienste im Internet verwendet diese Mittel.
Den bisher vorgestellten Methoden ist gemein, daß sie das Wissen um die Möglichkeiten und die entsprechende Syntax bei den einzelnen Suchdiensten voraussetzen. Da diese Möglichkeiten bei den Diensten differieren, ist es nötig, die jeweiligen Hilfeseiten zu konsultieren. Daneben werden zunehmend Verfahren angeboten, die den Suchprozeß intuitiv unterstützen sollen.
Mehrere Dienste bieten Methoden zur Modifizierung von Suchanfragen an, die unter dem Begriff Frageerweiterung (query expansion) zusammengefaßt werden können. Excite und Magellan setzen z.B. ein Verfahren zur Konzeptsuche ein, Intelligent Concept Extraction (ICE) genannt. Dabei werden anhand statistischer Methoden Begriffe, die häufig in den gleichen Dokumenten und in der Nähe der Suchworte vorkommen, in die Suche einbezogen. Die Zuordnung weiterer Begriffe erfolgt statisch, d.h. nicht beim Suchprozeß selbst. Das Verfahren führt zu einer Ausweitung der Suche. Da die Erweiterung jedoch bei selten vorkommenden Begriffen nicht funktioniert und ansonsten nicht abgeschaltet werden kann, ist es für die Sucherweiterung nur begrenzt nützlich. Ein weiterer Nachteil dieser Methode ist, daß sie für den Nutzer nicht nachvollziehbar ist. Es werden weder die tatsächlich zur Suche verwendeten Begriffen noch die genauen Trefferzahlen getrennt nach Suchbegriffen angegeben.
Transparenter ist die Methode, auf der Basis der eingegebenen Suchbegriffe zusätzliche Worte anzubieten. Diese werden ebenfalls anhand statistisch ermittelter Nähe zu den originalen Suchbegriffen generiert. Aus ihnen können relevante Begriffe ausgewählt werden, die in eine erneute Suche mit einbezogen werden. Dies wird bei Alta Vista, Excite, Euroferret und in abgewandelter Form bei dem simultanen Suchdienst HotOIL angewandt, jedoch mit unterschiedlicher Funktionsweise. Die Implementierung bei Alta Vista, Refine genannt, dient zur Einschränkung der Suche. In der Version ohne Java können Gruppen von Worten entweder als für eine erneute Suche notwendig einbezogen ("Require") oder als irrelevant ausgeschlossen ("Exclude") werden. In der Java-Version kann dies auch für einzelne Begriffe entschieden werden. Außerdem werden die Wortgruppierungen als Graph angezeigt, der die Relationen der Begriffsgruppen untereinander verdeutlicht.
Abbildung 4: Refine-Funktion bei Alta Vista (graphische Darstellung) (Stand: 17.1.1998)
Das Verfahren führt in dieser Form in jedem Fall zu einer Einschränkung der Suche, die neuen Begriffe werden als Boole'sche AND- bzw. NOT-Verknüpfungen in eine erneute Suche einbezogen. Hilfreich ist hier vor allem die Möglichkeit, irrelevante Begriffe auszuschließen. Um ähnliche oder verwandte Worte zur Frageerweiterung nutzen zu können, ist es nötig, mit den vorgeschlagenen Begriffen eine neue Suche zu formulieren. Die bei Excite (Search Wizard) und Euroferret durchgeführte Frageerweiterung basiert demgegenüber auf dem best-match-Verfahren; bei Euroferret werden die Begriffe zudem auf die Wortstämme reduziert. Die Methode führt also zu mehr Treffern und daher zu einer Erweiterung der Ergebnismenge. Der Nutzen des Verfahrens liegt in einer Korrektur des Rankings der Ergebnisse. Es werden zuerst die Dokumente angezeigt, die alle oder möglichst viele der Suchbegriffe beinhalten. Relevante Treffer könnten somit weiter oben plaziert werden. Die Ergebnismengen erhöhen sich jedoch bei diesem Verfahren wesentlich und gehen in die Zehn- oder Hunderttausende. Gerade bei der Suche mit Synonymen oder ähnlichen Begriffen, die ja nicht zwangsläufig alle in einem Dokument vorkommen müssen, führt dies nicht zu einer wirklichen Verbesserung, da es unmöglich ist, alle Ergebnisse zu betrachten. Da die Methoden auf statistischen co-occurrence-Methoden beruhen, werden auch viele irrelevante Treffer angeboten.
Eine weitere Form der Frageerweiterung ist das relevance feedback auf der Basis von einzelnen Suchergebnissen. Dies wird von Excite, Magellan, WebCrawler und Euroferret angeboten. Infoseek und OpenText haben diese Funktionalität wieder zurückgezogen. Bei Excite, Magellan und WebCrawler kann eine neue Suche auf der Basis eines als relevant befundenen Treffers ausgeführt werden ("More like this"). Dabei werden in diesem Dokument vorkommende Worte für eine neue Suche verwendet. Eine Kontrolle der dabei einbezogenen Begriffe ist nicht möglich. Diese Methode führt in den gegenwärtigen Realisierungen oft zu relativ ungenauen Ergebnissen. Euroferret erlaubt es, mehrere relevante Dokumente zu markieren, die bei einer Suchverfeinerung berücksichtigt werden und bezieht diese in die Frageerweiterung durch Angebot zusätzlicher Suchbegriffe mit ein.
Abbildung 5: Frageerweiterung durch Auswahl weiterer Suchbegriffe sowie relevance feedback durch Markieren relevanter Treffer bei Euroferret (Stand: 17.1.1998)
Die Gruppierung der Suchergebnisse (Clustering) ist eine weitere Möglichkeit, den Nutzer bei der Eingrenzung der Ergebnismengen zu unterstützen. Diese Möglichkeit wird von Northern Light, einem seit August 1997 existierenden, roboterbasierten Suchdienst und Inference Find, einem simultanen Dienst angeboten. Die Gruppierung der Ergebnisse basiert bei beiden Diensten auf den URLs bzw. Domainnamen. Sind mehrere Treffer von einem Server, bildet dieser ein eigenes Cluster, sonst wird grob zwischen "European Sites", "Educational Sites", "Institution Sites" usw. unterschieden. Bei Northern Light finden sich Gruppierungen auf mehreren Ebenen. Diese Gruppierung kann bei großen Treffermengen hilfreich sein, um irrelevante Treffer auszuschließen.
Abbildung 6: Ergebnisgruppierung bei Inference Find (Stand: 13.1.1998)
Die vorgestellten Mittel zur Modifizierung der Suche sind Methoden des Information Retrieval, die versuchen, die Unzulänglichkeiten der Volltextindexierung auszugleichen. Sie orientieren sich zunehmend an den Bedürfnissen von Endnutzern und bauen Funktionalitäten aus, die ohne großes Vorwissen und Syntaxkenntnisse angewandt werden können. Die gegenwärtigen Implementierungen sind jedoch alles andere als ideal; sie führen nicht immer zu einer Verbesserung der Suchergebnisse. An die bei traditionellen Datenbanken mit intellektueller Indexierung vorhandenen Möglichkeiten präziser Suche auf der Basis von kontrolliertem Vokabular, Thesauri und Klassifikationscodes reichen sie in keiner Weise heran. Kein Dienst arbeitet bisher mit automatischer Klassifizierung auf der Basis eines der im Bibliotheksbereich etablierten Klassifikationssysteme.[95]
Die wichtigsten Funktionalitäten des Information Retrieval, die zur Erhöhung der Precision bzw. des Recall einer Suche beitragen, sind in der folgenden Tabelle zusammenfassend aufgeführt. Teilweise können sie, je nach Anwendung, für beide Zwecke eingesetzt werden.
[88] Eine Zusammenstellung der im folgenden beschriebenen Funktionalitäten mit Verweisen zu allen Diensten, die diese anbieten, findet sich online im WWW: Koch 1997a
[89] s. http://lycospro.lycos.com/, Hilfsseite Quick Reference (Javascript) (Stand: 8.12.1997)
[90] Lycos Power Panel: http://lycospro.lycos.com/lycospro-powerpanel.html (Stand: 8.12.1997)
[91] vgl. zu gedruckten Zitierindexen: Ockenfeld 1991, S. 352-353
[92] vgl. die Untersuchung des Vorhandenseins von Metadaten in den im Nordic Web Index verzeichneten Dokumenten: MDusage 1997
[93] vgl. z.B. DC 1997. Nähere Erläuterungen zu DC finden sich in Kap. 5.3.4.1.
[94] vgl. HotBot 1997, Abschn.: How does HotBot rank my search results?
[95] Inzwischen liegt der Suchdienst für deutsche, akadamische Quellen GERHARD in einer nichtöffentlichen Textversion vor. Dieser setzt automatische Klassifizierung nach der UDC ein. Vgl. Kap. 5.4.2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}