|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Nancy Y. McGovern,
<nm84@cornell.edu>
|
![]()
IntroductionThe Internet Archive's role in preserving web content determined the outcome of a trademark trial last spring. The case pitted Playboy Enterprises against Mario Cavalluzzo, the owner of a pay-for-porn website. Playboy sued him, claiming that his sexcourt.com site infringed on the company's trademark name for a cable show. In a dramatic courtroom scene, Playboy's Internet research manager, Cindy Johnston, introduced evidence that the company's use of the name predated Cavalluzzo's. She used the Internet Archive's Wayback Machine to demonstrate that sexcourt.com's earliest appearance on the web was January 1999, four months after Playboy aired the first installment of its cable show. Johnston indicated that she frequently used the Wayback Machine to check on trademark infringements. Cavalluzzo's lawyer trumped her, however, submitting evidence that the website was on the Internet by May 14, 1998, four month's prior to the release of the cable show. Playboy settled out of court, assuming ownership of the domain name for an undisclosed amount of money.ii There are numerous web archiving projects around the globe.iii Virtually all are premised on capturing sites. Yet, those of us interested in digital preservation are aware of both the strengths and the weaknesses of the Internet Archive and other similar efforts to preserve the web by copying it.iv We know, too, that websites are vulnerable due to the use of unstable uniform resource locators (URLs), poor site management, and hacker attacks. Despite frequent updates to server software, variable institutional take-up of available patches illustrates that site managers are slow or inconsistent in responding to potential security threats. Hacking concerns frequently make front-page news. Just recently, Vincent Weafer of Symantec Corporation called a peer-to-peer approach used by hackers, PhatBot, the "virtual Swiss Army knife of attack software."v In their efforts to combat these mounting threats, cultural institutions face diminishing resources for protecting an ever-growing amount of web content worth preserving. Much of this content is neither owned nor controlled by these institutions, so even if economics weren't a factor in assuming protective custody, legal and technical barriers would be. Although institutions cannot simply take in whatever they would like to protect, there is an expanding array of tools that can be used to cast a virtual preservation net over large and comprehensive sets of digital resources. Unlike most web preservation projects, Cornell University Library's Virtual Remote Control (VRC) initiative is based on monitoring websites over time—identifying and responding to detected risk as necessary, with capture as a last resort. We are building a VRC toolbox of software for cultural heritage institutions to use in managing their portfolio of web resources. This initiative builds on work funded by the National Science Foundation and The Andrew W. Mellon Foundation (see acknowledgements).vi The objectives of the VRC approach are to:
The VRC moniker can be expressed as follows:
VRC leverages risk management as well as the fundamental precepts of records management to define a series of stages through which an organization would progress in selecting, monitoring, and curating target web resources. The first part of this article presents the stages of the VRC approach, identifying both human and automated responses at each stage. The second part describes the development of a toolbox to enable the VRC approach. The conclusion sets out our intentions for the future of VRC. VRC in ContextSince the mid-1990s, organizations and individuals increasingly have maintained at least one website that enables their primary functions, documents activities, announces achievements, delivers products, and/or broadcasts information. The pages of an institution's website may contain a wide array of content utilizing many different file formats and delivery mechanisms with varying but inevitable rates of change over time. In embracing risk management, the Virtual Remote Control approach allows for, but does not presume, custody of target web resources. Our underlying premise is that good web management practice, comprehensive monitoring and evaluation, and effective response and mitigation, when needed, form the foundation for effective web preservation. The intent of the VRC model is to provide organizations with an approach that:
Organizational Stages in VRCOur risk management program consists of six stages that constitute the VRC framework.vii VRC uses a bottom-up approach, analyzing data about pages and sites to build a base of risk knowledge specific to individual sites and cutting across the range of target sites (the technological perspective). A top-down approach (the organizational perspective) is then used to apply organization-specific requirements. Table 1 illustrates how the organizational VRC stages align with the technological stages as presented in our earlier work.
Table 1. Aligning Classic Risk Management with VRC Stages Manual versus Automated MeansThough our ideal might be a fully automated process from initial identification of a web resource through its eventual demise, we recognize that at least initially the process would be more manual than automated. VRC does not remove the human factor in each stage, but seeks to automate as much of the process as possible to maximize efficiency, comprehensiveness, cost-effectiveness, and accuracy. In the first rounds of development, the process consists of alternating interactions between humans and tools, summarized in Table 2. The sequence of the roles listed in each stage indicates which is primary (listed first) or secondary.
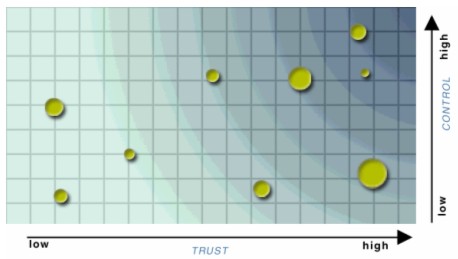
Table 2. Summary of Human-Toolbox Interaction in VRC Organizational Stages Identification The identification stage is the starting point for the VRC approach. An organization begins with one or more web resources it is interested in monitoring and evaluating. Web search tools offer the means to identify resources continually, systematically, and comprehensively.viii VRC Scenario: A staff member compiles and periodically reviews a list of web resources of interest and submits each new URL for evaluation. In this stage, VRC tools would manage the list of URLs, allowing access to the inventory by various means, e.g., subject, file type, creator. Evaluation A website, by its nature, changes over time. Once it is identified as of potential interest, a baseline profile of the site is needed to determine the scope, structure, and status of the site. What can we know about the site and how it is managed? That is the essence of the evaluation stage. VRC Scenario: A staff member submits a URL for evaluation. A VRC tool generates a baseline Web Resources Profile for it, tracking Page, Site, and Server level elements. The rate of change in these elements would then be documented during the evaluation period. Appraisal This stage supports value assessment based on attributes such as relevancy to the organization's collection(s); significance (essential, desirable, ephemeral); archival role (primary archives for resource, informal agreement for full or partial capture, other); maintenance (rating for key indicators of good site management); redundancy (captured by more than one archive); risk response (time delay and action based on test notifications); capture requirements (complexity of site structure, update cycle, MIME types, dynamic content, and behavior indicators); and size (number of pages, depth of crawl required, etc.). VRC Scenario: The staff member could generate summary reports for a particular topic for use in evaluating (or reevaluating) individual sites or groups of sites. S/he would view the Web Resources Profile, filling in the Value elements and, if applicable, the Agreement and Known Redundancy elements. A module of the VRC toolbox would track the status of agreements; assist the staff in establishing new agreements by compiling all information for use in negotiating the agreement; capture each element as the agreement gets completed; and manage any rights information that result from the agreement. This information would be used for monitoring the sites over time and in devising appropriate responses to detected risks. Strategy The strategy stage assists the organization in establishing risk parameters for individual sites as well as classes of web resources. Changes defined as risk in one organizational context may be insignificant in others. As illustrated in Figure 1, an organization can assess a resource based on perceived value (represented by dot size), the organization's trust in its stability (horizontal axis), and the level of control the organization can exert over it (vertical axis). A site's location on the grid indicates level of monitoring effort. For instance, sites located in the bottom left quadrant (low trust, low control) would deserve a higher monitoring level than those in the top right (high trust, high control). Resulting strategies may range from passive monitoring, to notifying site managers of potential risks, to actively capturing and managing web resources. Invoking active control measures will generally require formal agreements between a site's maintainer and the organization that wants to ensure its longevity.
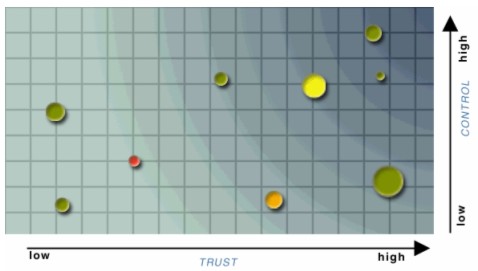
Ongoing monitoring will support the enhancement of strategies. The extent to which resources can be managed at the resource class level, based on effective characterization of the resources into page and site models, rather than at the individual resource level, will determine the ability of an institution to manage a growing body of web resources. VRC Scenario: Using the Value/Control/Trust grid with individual and group resource profiles, the VRC Toolbox would propose the Monitoring Frequency and Risk Level for each resource. These elements might be adjusted over time in response to monitoring results and event-based elevations in risk. The organization can approve or modify the frequencies and levels proposed by the VRC toolbox. Once approved, a VRC module would automatically monitor and record information for each monitoring cycle. Detection The detection stage supports ongoing monitoring at the page and site level. Detected changes are correlated to risk parameters established for each site. Potential loss or damage is assessed and possible responses proposed. VRC Scenario: A VRC tool would note detected risks, using the Value/Control/Trust grid. A watch (yellow), warning (orange), or act (red) indicator would highlight resources where risk is detected. By clicking on the affected resource, a staff member could review the full risk report.
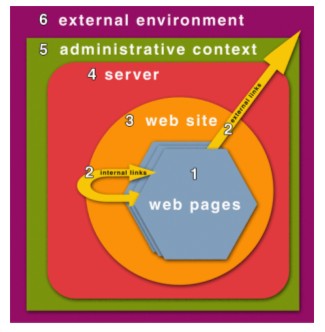
Response The VRC response module will present the organization with a list of responses, some of which may be automatically undertaken based on the site profile (e.g., temporarily cache site pending further action). Response selections and preferences will be captured and used to refine and extend responses. VRC scenario: Appropriate risk-response pairs will be devised over time using the accumulated rules, changes, and risk levels. Using these risk-response pairs and the risk level approved by the institution, VRC tools would automatically notify the site owner about the detected risk, provide the proposed response, take action in response to the risk, or present the risk report to staff for further action. VRC Monitoring LevelsAll six VRC stages may require or respond to information gathered at any of the context levels of the Web Resource Context Layer model (see Figure 3). We have modified the contextual layers that were first presented in our earlier work:ix
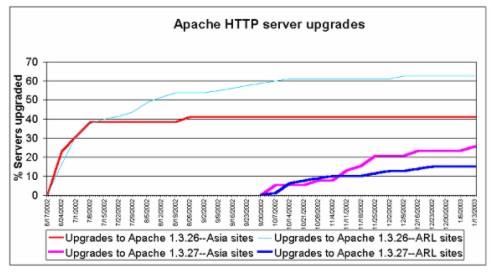
We have examined monitoring functions at the four inner layers on selected test sets of websites.x Work on the external administrative and environmental layers require agreements with potential monitoring organizations and test sites. For example, monitoring at the page level will allow us to identify indicators of the deep web and track those indicators over time, but monitoring deep web content presumes explicit permission as well as appropriate techniques. The lines between the layers can blur. For example, the term site management may convey different meanings to different people. We distinguish between website management (layers 3 and 4) and physical site management (layer 5). The former entails managing site content and operations within a server's software environment, primarily dealing with issues such as use of good design principles, adherence to standards, and software maintenance. Physical site management pertains to managing a server within a physical setting encompassing issues such as the degree to which hardware is secured from malicious acts (theft or vandalism), the use and maintenance of temperature, humidity, flood, and fire controls and alarms, the regularity of data backup, and redundancy measures. A site may have superb website management, but sloppy physical site management and therefore be extremely vulnerable. The server level provides interesting examples as well as challenges. Server-level Monitoring Much about the environment in which a website runs can impact the site's reliability and risk profile. For example, how vulnerable is the web server software and hardware to data loss and network disruption? Though such details are generally hidden from remote probing, some characteristics that would enrich a site's risk profile over time are available. Anything that can be learned is useful, since problems affecting high-level components like networks and servers may pose a threat to multiple sites. Software utilities can determine whether a machine is reachable on the network and whether the web server is responsive. Frequent outages and lengthy downtime may be indicative of poor maintenance. In some cases, specific information about server software in use is available. Server vulnerabilities put site content at risk from possible deletion or unauthorized modification. Patches and new versions of Microsoft IIS and Apache servers are released frequently. Using daily monitoring, we conducted a small study to document the uptake of a key server software security patch by potentially affected test sites among members of the Association of Research Libraries (ARL) and political communication sites in Southeast Asia. On June 18, 2002, the widely used version 1.3 Apache HTTP server received an important security update to version 1.3.26 and a less critical upgrade to version 1.3.27 on October 3, 2002. Figure 4 shows the server update rate of the two new versions at 80 ARL installations and 39 sites in Asia over a seven-month period following the release of the first upgrade. In both groups, about 40% installed version 1.3.26 within three weeks of its availability. During the next six months, there was virtually no further upgrade activity amongst the Asia sites, while the ARL sites took longer to level off at around 60% uptake. The less critical upgrade to version 1.3.27 had an even slower and lower level of uptake, with greater long-term activity amongst the Asia sites.
More than a year out from the initial announcement of its availability, a quarter of the ARL sites still had not upgraded to Apache 1.3.26, and some were running HTTP server versions as much as five years old. Although not necessarily a sign of inattention, such observations could be cause for concern in the presence of other indicators of neglect. Populating the VRC ToolboxEach stage in the process requires appropriate tools, and the VRC toolbox needs to be defined in terms of small, medium, and large sizes to meet the requirements of various organizational contexts in which it could be deployed. The VRC Toolbox objectives are to:
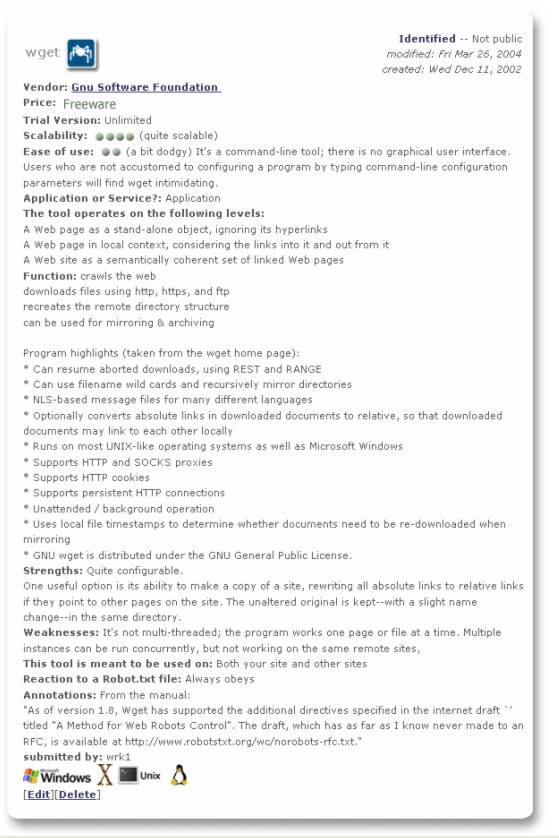
Web Tool Evaluation ProgramOur goal is to create a toolbox that is scalable, technically feasible, affordable, and constructed as much as possible from open source tools for interoperability and extensibility. As a first step, we have created an evaluation program, through a process described in the sections below, which includes an inventory of web tools we identified, selected, and tested. The inventory's purpose is to identify and measure the functionality of available tools. The inventory entries include data on cost, vendor, strengths, capabilities, scalability, adaptability, compatibility, and other factors. We provide a public version of the nascent tool inventory and will make the full version of the entries accessible to researchers on other web analysis projects. We are compiling requirements informed by the tool testing that identify general characteristics for all tool categories, define common and suggested functionality within tool categories, and highlight potential overlaps between the categories. The specification will allow organizations to plug in available and preferred tools to size their program and integrate tools as appropriate. Literature Review Our literature review focused on tools and processes for evaluating websites. Three somewhat interrelated areas have received significant study—credibility, quality, and accessibility. Most credibility and quality studies are aimed at understanding what characteristics correlate with those attributes, rather than the development of tools to assess and enforce them in web design. One exception is the WebTango Project, a website quality evaluation tool based on large-scale statistical analysis of highly rated sites.xi Accessibility, the least subjective of the three areas, lends itself most easily to automation. Explicit accessibility guidelines have been around for years, which have facilitated the development of automated accessibility evaluation tools.xii The existence of explicit guidelines and tools for evaluating compliance has also led to the creation of at least one website for tool testing.xiii This Violation Site is designed as a foil to determine how well the assessment tools do their job. There have been additional efforts to document or review existing tools, which we identify on our VRC Web Tools Resources page. Most of these tools are designed for site self-assessment rather than remote monitoring to profile risk by a third party. Tool Category Development The earliest web-related software tools were simple HTML editors, developed to speed the creation of web pages during the rapid expansion in content of the mid-late 1990s. As the web grew and matured, tools for site building became more sophisticated and began to incorporate maintenance functions, such as automatic HTML code generation and validation, browser compatibility testing, and link functionality checking. The explosive growth in e-commerce sites of the late 1990s saw the introduction of new tools to monitor a site's availability, performance, and usage as well as create maps to simplify navigation. All of these tools have a distinctive inward-looking focus, designed for use by site owners and operators. Web crawlers, the first of the outward-looking web tools, also came early in the tool design cycle. Built to meet the need for indexing the young but rapidly growing web, crawlers were typically closely guarded, custom-made tools not designed for commercial distribution. Another outward-looking web tool designed for general consumption came about from the unwillingness of web users to cede content monitoring control to website developers. In the aftermath of failed "push" technology programs, innovations such as RSS (Rich Site Summary) and change detection tools allowed users to track changes to their favorite websites. However, none of these tool classes was designed with VRC functions in mind. Even web crawlers were not initially seen as archiving tools, since early crawling efforts discarded the captured pages after they'd been indexed. Those currently in use for preservation purposes are devoted to capturing sites, not monitoring their status. Change detection tools, though clearly designed for external monitoring purposes, are marketed for current awareness and competitive intelligence purposes, not preservation. Thus, if we had limited our search only to tools explicitly designed for external monitoring, we would have found slim pickings. Instead, we included any tool category that would contribute to building a complete and accurate risk assessment profile for a site. Selecting Representative Tools for Testing Our selection encompassed products from large and small enterprises, commercial and open source, subscription services and downloadable applications, and from vendors all over the world. We then whittled down the candidates by evaluating product literature and eliminating those that did not seem to be well supported or well maintained (e.g., no updates within the past three years). We limited our first round of testing to products readily available as subscription services or Windows binaries, though some products for other platforms are in the tool inventory. Excluded were Macintosh-only products and those for Unix/Linux, as well as products requiring installation of programming language packages such as perl and Java. Our ultimate goal is to populate the toolbox primarily with open source software. Based upon our literature review and associated explorations, we have identified eight tool categories, as defined in Table 3.
Table 3. Tool Categories A summary of each category with observations and results from this phase of tool testing is available on the VRC site. Here are a few examples from the tool category explorations:
Tools Mapped to Organizational StagesOur initial mapping of tool categories to organizational stages (Table 4) indicates the value of combining tools at various stages, underlying the need for tool interoperability. It also suggests categories that currently offer greater options for automation, thus increasing the ratio of tool-to-human effort.
Table 4. Anticipated Roles of Tools at each VRC Stage Tool-related IssuesThere are additional issuesxv to consider in using tools such as these to implement the VRC approach. We present just some of the cross-category themes that have emerged during our tool exploration. Local vs. Remote VRC needs tools that can work on sites that are managed by other institutions. Many tools impose restrictions on use beyond a site under direct control. For instance, site mappers are generally marketed for use by web developers and site mangers. Although many applications allow mapping to any valid URL, the functionality may be limited (e.g., editing and uploading a site map). There are two basic differences between websites one creates and those one does not. The first has to do with what can be seen. Files managed by the web server that are beyond the boundaries of the page structure are invisible. This is not the "deep web" problem. The deep content of a site is available if one has authorization to view it. What is not available is data that could enhance risk assessment, such a database structures, in-line scripting, and server log files. These remain hidden from view. The second difference has to do with the way the Internet works. HTTP and FTP protocols enable access to others' sites, but the limitations of those protocols restrict third party access. In other words, site managers have the advantage of viewing files directly on their own computers; third parties are limited to the intervention of servers and middleware that process raw files before sending off complete web pages. Many of the tools we are evaluating—particularly within the categories of change management, link checking, html validation, site management, site mapping, and site monitoring—were designed to assist in building and maintaining sites. They can be valuable, in differing degrees, for analyzing sites owned by others, but both content and accessibility will be limited. Purveyors of website monitoring tools have different ideas about whether their products are designed strictly for self-monitoring. Of those we identified, approximately 2/3 either explicitly forbid their use on external sites or give no indication that external usage is authorized. External monitoring authorization is most often signaled by a contract clause that states "you agree not to publish or disclose any information about sites you do not own." However, some manufacturers encourage use of their products to monitor competitors' sites as a marketing strategy to sell their product or service. Impact of Monitoring We know that monitoring can affect the performance of target websites. Weighing the impact of monitoring on target sites is an important consideration in implementing the VRC approach. "While humans click through a site at about a page every few seconds, a fast crawler trying to get thousands of pages a minute could bog down or crash small sites—similar to how a denial-of-service attack looks."xvi Web resources of interest may be maintained by non-profit and other organizations that may incur charges per visit, or suffer other impacts from well-intentioned visits. Consider the following hypothetical scenario: Five hundred libraries are monitoring a site containing five hundred pages, and they each use three tools on the site once a month. Collectively, that would make a total of 750,000 requests. In a 30-day month there are 2,592,000 seconds. On average, requests would be made every three-and-a-half seconds. That figure is true only if the libraries coordinate their monitoring activities. The load on the target site's server is very different, though, if those five hundred libraries independently decide to run their three tools on the first of the month between 00:00 and 23:59 GMT. The average load that day, produced by testing tools alone, would be more than eight pages per second. The worst case would occur when all those libraries start all three tools at, say, midnight on the first of the month. The target then receives somewhere near 1500 requests in that first second. Table 5 shows the log analysis results from a site mapper test on the VRC Test Site that illustrates potential site impact. The tools behave in very different ways. The range of responses underscores the need for systematic, comparative web tool testing that this evaluation program addresses.
Table 5. Comparison of the Impact and Results of Five Site Mapper Toolsxvii The politeness factor (how frequently the tool asks the server for a page) differs greatly from tool to tool (see the frequency range in the Requests columns in Table 5). The programs crawl the site in different ways, too. The VRC Test Site comprises 142 files. As you can see from the summary of the crawls, the minimum number of requests any of the five tools made was 229. We have not found easily discernable patterns that would indicate the logic of the crawling action in any of the site mappers. All of them made requests for URLs ending with a directory name and for the index file in the same directory, i.e., two different requests for the same file. HEAD requests, asking for just the HTTP header, were used by two of the site mappers, presumably before they requested the actual files—this potentially doubles the number of requests. Two made requests for partial files, not downloading the complete files, but only specific file types. These repeat requests increase the potential impact on the monitored site, a significant factor to consider in evaluating tools. VRC Test SiteAs we began exploring tools and monitoring experiments, we realized the value of having our own control site to test against. The site is based upon the premise that if one can anticipate expected results from a site when the tool is applied, one can better assess tool effectiveness. We developed the Test Site for our own purposes, but we used a formal process to document and implement it, so as to make it usable by other web analysis projects. Full documentation of the Test Site's development process is available on the site.
The site contains html pages, images, multimedia files, scripts, deep directory structures, broken links and other kinds of errors, restricted pages, and more. Every page, every link, every resource is documented in a documentation.xml file. An HTML version of the documentation is available. There are also links to machine-readable transformations of the documentation—e.g., a text-only list of URLs for every element. We developed the site by creating a list of requirements based on our experience building, maintaining, and monitoring websites. Included are examples of website features and possible error states. (A few, such as a user's ability to induce a change-state in the site, will be implemented later.) We then tested the site with wget, HTTrack, and Mercator, three powerful web crawlers. We improved the site after comparing the crawling results and the known elements and are currently evaluating tools using the stable version 1.0 of the VRC Test Site. We have begun exploring the use of versions of the site for replicating and detecting iterative change over time. VRC and the FutureJust as Playboy Enterprises found it could not rely solely on the content of the Internet Archive to win the porn trademark trial, our work on the Virtual Remote Control project leads us to conclude that crawlers—the most commonly used tools in web archiving—are necessary but insufficient to implement a web preservation program based on risk management. Crawlers and tools geared towards capture form the foundation of notable web archiving efforts undertaken by the Internet Archive, the Nordic Web Archive, the National Library of Australia, and the California Digital Library.xviii In the context of the VRC toolbox, however, it is important to distinguish between web crawling and web crawlers. Web crawling is the ability to traverse websites via links. This capability is common to many web tools. Of course, web crawlers excel at crawling, but other tools can be used to traverse sites via links to great effect for other purposes than capture, and return different results about the content or status of sites and pages. We know that our toolbox will include web crawlers. Though VRC monitoring relies primarily on metadata captured from target sites and the intent is to predict risks to avoid loss, the option to capture full pages for more-active monitoring means that the last known version of pages or sites may be cached, providing a safety net for failed or failing resources. The VRC toolbox concept allows for all of these eventualities. It also defines a systematic mechanism for tool testing and selection. Our results to date indicate a logical correlation between good site management and reduced risk. Although our emphasis is on third-party monitoring, detection, and mitigation, we also know that slight improvements in site creation and management could yield powerful results. Site managers can promote a site's preservability and enhance its participation in a risk management program. The team has developed an initial list of site management indicators for use by Cornell faculty in creating their own sites. For instance, our data gathering revealed that while the HTTP protocol provides a rich syntax for communication between server and client through the use of headers, few of the fields are consistently used. Only three fields—date (a general header that identifies the date and time of response), content type (an entity heading that provides the MIME type), and server (a response header that provides some information about the web server software)—were returned for virtually every page of the Association of Research Libraries (ARL), Consortium of University Research Libraries (CURL), and Asia test sites (100%) and for 98% or higher of our other test sites. These fields are useful for current and long-term management. Other desirable header fields for preservation purposes are not consistently used. For example the percentage occurrence of content-length and last-modified fields ranged from 35% to 85% in our test sites. The identification of these and other indicators of good management practice could form the basis of web content preservability guidelines, similar in nature to the W3C's content accessibility guidelines.xix We will continue to develop a data model for tracking risk-significant information and populate a knowledge base of tools and processes that could be characterized as a risk analysis engine. Through specific projects, both at Cornell and in tandem with others, we will continue data mining at the page and site levels using crawl data to identify potential risks and develop risk-response pairs appropriate at various organizational stages and scaled for small, medium, and large efforts. Cornell welcomes the opportunity to work with other web preservation initiatives to further develop this approach. AcknowledgementsThe Digital Libraries Initiative, Phase 2 (Grant No. IIS-9905955, the Prism Project) supported the work described in this paper, as well as the Andrew W. Mellon Foundation Political Communications Web Archiving grant (http://www.crl.edu/content/PolitWeb.htm) awarded to CRL in which the Virtual Remote Control (VRC) team participated during 2003. The VRC team would like to acknowledge the work of Erica Olsen, a researcher on the project during 2003 who developed the tool inventory application and designed the VRC logo and tool category icons. Notes and Referencesi A number of individuals participated in the course of this research. Currently, the VRC team consists of: Anne R. Kenney (Project Advisor), Nancy Y. McGovern (Project Manager), Richard Entlich (Senior Researcher), William R. Kehoe (Technology Coordinator), and Ellie Buckley (Digital Research Specialist).
ii NewsDay.com, "An Un.com-mom Revelation in Porn-Name Case," by Anthony M. DeStefano, April 10, 2003, http://pqasb.pqarchiver.com/newsday/322964731.html?did=322964731&FMT iii See the list of web archiving projects on the VRC site: http://irisresearch.library.cornell.edu/VRC/webarchiving.html. iv Anne R. Kenney, Nancy Y. McGovern, et al, "Preservation Risk Management for Web Resources: Virtual Remote Control in Cornell's Project Prism," D-Lib Magazine, January 2002, doi:10.1045/january2002-kenney. v Washington Post, "Hackers Embrace P2P Concept," by Brian Krebs, March 17, 2004. vi Kenney, et al; Political Communications Web Archiving: A Report to the Andrew W. Mellon Foundation, Council of Research Libraries, et al, 2004. vii For more information on the VRC stages see the website at: http://irisresearch.library.cornell.edu/VRC/stages.html. viii D. Bergmark. Collection Synthesis. In Proceedings of the Second ACM/IEEE-CS Joint Conference on Digital Libraries, p. 253-262, 2002. http://portal.acm.org/citation.cfm?doid=544220.544275. ix The authors first introduced this model in Kenney, et al, D-Lib Magazine, January 2002. x More information about monitoring is accessible on the VRC website: http://irisresearch.library.cornell.edu/VRC/monitoring. We identified these sets of websites for monitoring and evaluation purposes: Association of Research Libraries (ARL) - 123 sites; Consortium of University Research Libraries (CURL) -26 sites in the UK; political and nonprofit organizations in Asia - selection of 54 sites; .gov sites - 56 sites; state library sites - 56 sites; .com sites - 58 Fortune 500 company and 66 emerging technology company sites. xi Ivory, Melody Y., and Marti A. Hearst, "Statistical Profiles of Highly-Rated Web Sites," CHI 2002, Changing the World, Changing Ourselves, April 20-23, 2002 at: http://webtango.berkeley.edu/papers/chi2002/chi2002.pdf. The Tango Project site is at: http://webtango.ischool.washington.edu/. xii See, for example, the W3C's Web Content Accessibility Guidelines 1.0 at: http://www.w3.org/WAI/eval/, and the U.S. government's Section 508 standards at: http://www.section508.gov). WC3's Evaluation, Repair, and Transformation Tools for Web Content Accessibility at: http://www.w3.org/WAI/ER/existingtools.html and Section 508 Accessible Tools and Resources at: http://www.section508.gov/index.cfm?FuseAction=Content&ID=122. xiii Described in Kirchner, Michele, "A Benchmark for Testing the Evaluation Tools for Web Pages Accessibility," Proceedings of the Fifth IEEE International Workshop on Web Site Evaluation, http://star.itc.it/Papers/2003/wse2003b.html. xiv Log analyzers is an example of a type of tool that was not included in this phase of the web tool evaluation: http://irisresearch.library.cornell.edu/VRC/catother.html. xv The VRC contains other tool issue discussions: http://irisresearch.library.cornell.edu/VRC/catoverview.html. xvi "Distributed high-performance web crawlers: A survey of the state of the art," by Dustin Boswell, December 10, 2003 at: http://www.cs.ucsd.edu/~dboswell/PastWork/WebCrawlingSurvey.pdf. xvii The Tool column identifies the Site Mappers we tested: SiteMapper (SM), Custo (C), SiteXpert (X), PowerMapper (PM), and Site Map Pro (SMP). The Time columns note the start time and run time in seconds for the test. The Requests columns documents the number of requests and the frequency—a request was made every n seconds. The Bytes column notes the total number of bytes for all pages requested by the tool, and the number of bytes for pages with status code 200. The Status Codes columns note the number of pages in each status code category found by the tool. These are HTTP status codes that equate to: 200 = okay, 206 = Partial Content, 301 = Moved Permanently, 304 = Not Modified, 403 = Forbidden, 404 = Not Found, and 500 = Internal Server Error. The full set of HTTP status codes and definitions is available at: http://www.ietf.org/rfc/rfc2616.txt. See the VRC site for a more detailed report on this and other tool tests: http://irisresearch.library.cornell.edu/VRC/testing.html. xviii The Nordic Web Archive enables capture and access to stored versions of resources: http://nwatoolset.sourceforge.net/index.php?doc=aboutNwaToolset. The Internet Archive (http://www.archive.org/) provides researcher access to its tool area, which also has a primary focus on capture and access to stored versions. The PANDORA archive is a digital archive program that uses a crawler: http://pandora.nla.gov.au/. Two recent projects, the California Digital Library (http://www.cdlib.org/programs/Web-based_archiving_mellon_Final.pdf) and the Political Communications Web Archiving Project (http://www.crl.edu/content/PolitWeb.htm) produced critical reviews of web crawlers. xix W3C, op. cit., http://www.w3.org/WAI/eval/. Copyright © 2004 Nancy Y. McGovern, Anne R. Kenney, Richard Entlich, William R. Kehoe, and Ellie Buckley |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2004-mcgovern
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||