D-Lib Magazine
January/February 2017
Volume 23, Number 1/2
Table of Contents
From Data to Machine Readable Information Aggregated in Research Objects
Markus Stocker
PANGAEA/MARUM, University of Bremen, Germany
http://orcid.org/0000-0001-5492-3212
mstocker@marum.de
https://doi.org/10.1045/january2017-stocker
Abstract
Data interpretation is an important process in scientific investigations. It results in information and gives data meaning. As a case in point, earth and environmental scientists interpret data — increasingly often collected in large-scale environmental research infrastructures — to gain information about the studied environment. Information is typically represented to suit human consumption — in natural language text, figures and tables designed for expert processing. Building on a case study in aerosol science, we discuss how information resulting in data interpretation can be represented as machine readable information objects, here of type Interpretation. As the main contribution, we present the aggregation of interpretations in Research Objects. Together with data, metadata, workflows, software, and articles, interpretations are contextual resources of scientific investigations. The explicit aggregation of interpretations in Research Objects is arguably a further step toward a more complete representation of the context of scientific investigations.
Keywords: Data, Information, Interpretation, Research Object, Semantic Web, Linked Data
1 Introduction
Bourne et al. (2012) expressed the vision of "a future in which scientific information and scholarly communication more generally become part of a global, universal and explicit network of knowledge." In this vision, networked knowledge objects explicitly represent "every significant element of the discourse," including, but not limited to, elements such as data, software, workflows and claims. To enable this vision, the authors suggest that the predominant artefacts of scholarly communication, i.e. scientific journal articles and monographs, need to be revised toward an "enriched form of scholarly publication that enables the creation and management of relationships between knowledge, claims, and data." The proposed unit and form of knowledge exchange centers on the Research Object (De Roure and Goble, 2009; Bechhofer et al., 2010), an abstract structure that relates the products of a research investigation, including articles but also data and other research artefacts.
Data interpretation is an important process in many if not most research investigations. It results in information, which is thus a product of an investigation. Information is typically represented to suit human consumption — in natural language text, figures and tables designed for expert processing. Unfortunately, in these forms scientific interpretations of data are hardly machine readable or processable.
Building on a case study in aerosol science, namely for the study of atmospheric new particle formation, we present how Research Objects can aggregate machine readable objects that represent information resulting from data interpretation. To this end, we introduce Interpretation as an additional resource type that Research Objects may aggregate. In our case study, information is obtained by extraction from data using machine learning. It is thus software agents that execute data interpretation.
Aamodt and Nygård (1995) proposed a unified definitional model of data, information, and knowledge from the perspective of a computational information processing system. For the sake of simplicity, we focus here on data and information, and the process of data interpretation. However, the proposed approach can arguably be extended to knowledge. We will briefly discuss this possibility in Section 5.
According to the definitional framework proposed by Aamodt and Nygård, data are syntactic entities, i.e. observed symbols without meaning for the system concerned, and are input to interpretation processes. Information is interpreted data, i.e. symbols with meaning, and output from data interpretation. It is "through an interpretation process that a syntactic structure is transformed into a semantic, meaningful entity." Data interpretation occurs "within a real-world context and for a particular purpose." Following the example by Aamodt and Nygård, a series of signals from a sensor are data while 'decreased blood pressure' is information. We build on this definitional model of data, information, and knowledge.
The paper is structured as follows. In Section 2 we present the selected case study. In Section 3 we briefly introduce the notion of Research Object and present how we extend a Research Object Model with an additional resource type for interpretations. In Section 4 we discuss the extension for an application in the domain of our case study. In Section 5 we discuss the proposed extension. We briefly highlight the application of the extension to Distributed Scholarly Compound Objects. Following Aamodt and Nygård's framework, we discuss how information about theme, space, and time can be structured in abstract knowledge objects. We highlight situational knowledge objects, i.e. objects that structure information about real-world situations, and the aggregation of such objects in Research Objects. Finally, we highlight a possible role of persistent identifiers. We close this paper with concluding remarks in Section 6.
2 Case Study
The selected case study is in aerosol science, for the study of atmospheric new particle formation events. Stocker et al. (2014) present the application in more detail. Here we provide an overview of the key elements.
New particle formation (NPF) is an atmospheric event whereby, under certain atmospheric conditions, new particles form and grow in size, through processes such as coagulation and condensation. The events have been well documented in a wide variety of environments all over the world (Kulmala et al., 2004). They are studied because aerosol particles affect Earth's radiation balance by scattering or absorbing solar radiation; because particles can grow large enough to act as cloud condensation nuclei and may thus activate to cloud droplets resulting in further radiation scattering; and because particles can influence quality of life, for instance by affecting human health.
The study of NPF relies on the detection and characterization of these atmospheric events at monitored locations in time and space. Central to these tasks is the measurement of particle size distribution for polydisperse aerosols. Measurement is performed by a Differential Mobility Particle Sizer (DMPS) for particle number concentration of several discrete diameter sizes in the nanometer range, on average a few samples per hour. The resulting data, as measured over the course of a day at a specific location in space, can be visualized to assess the presence and the characteristics of an event (Dal Maso et al., 2005). Figure 1 displays an example DMPS data visualization for a day and location at which a NPF event occurred, specifically on March 26, 2011 at the Station for Measuring Ecosystem-Atmosphere Relations (SMEAR II) in Hyytiälä, Finland.
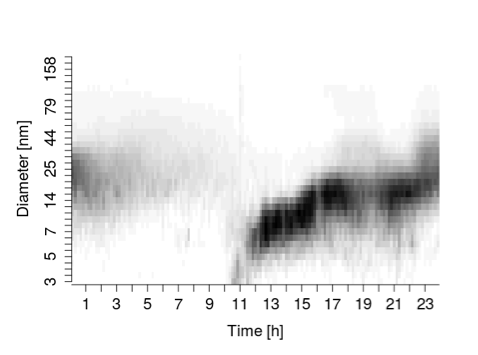
Figure 1: Visualization of DMPS data collected by the Station for Measuring Ecosystem-Atmosphere Relations (SMEAR II) on March 26, 2011 in Hyytiälä, Finland. The dark region reflects the observed signature of a real-world atmospheric new particle formation event, starting around noon, and a high number concentration of particles with growing diameter over time.
Daily data are typically stored as data files or in (relational) databases (Junninen et al., 2009). Stocker et al. (2014) utilize the RDF Data Cube Vocabulary (QB) (Cyganiak et al., 2014) to represent daily data as QB DataSet, and an RDF database to manage RDF data. Such datasets are identified by Uniform Resource Identifier (URI). The Resource Description Framework (RDF) (Manola et al., 2004) is the (meta-)data model used for dataset representation. We can utilize the SPARQL (Prud'hommeaux and Seaborne, 2008) query language to retrieve datasets from an RDF database.
Different event classifications have been proposed in order to characterize detected NPF events. The criterion established by Hamed et al. (2007) is based on event clarity. The clarity of event days can be strong, intermediate, or weak. Days during which no NPF event is observed are classified as non-event. As the occurrence of a NPF event and its clarity are assessed manually, visualization of processed measurement data plays a central role in these scientific investigations (Hamed et al., 2007).
Stocker et al. (2014) have presented an automated workflow, whereby daily DMPS data are first processed to a feature vector and the vector is then classified using machine learning. In this use case, machine learning classification is a two-step process, whereby the first step implements the detection of a NPF event during a day by classifying the vector into event or non-event day, and, for an event day, the second step implements the characterization of the NPF event by classifying the vector into strong, intermediate, or weak clarity.
The output of machine learning is information, i.e. data interpreted in a real-world context and for a particular purpose. It is the result of data interpretation carried out automatically by software agents that implement and execute machine learning classification. Specifically, software agents take vectors for processed daily DMPS data as input and, for event days, return assertions about instances of the following class as output:
Class: NewParticleFormationEvent
SubClassOf: AtmosphericEvent
that hasClarity some {weak, intermediate, strong}
and hasClarity exactly 1
Thus, a NPF event is an atmospheric event with either weak, intermediate, or strong clarity. The following assertions characterize the detected NPF event e with strong clarity:
Individual: e
Types: NewParticleFormationEvent
Facts: hasClarity strong
Figure 2 represents the assertions about the NPF event e graphically as an RDF graph. Note that in RDF all terms, including hasClarity and the individuals e and strong, are URIs. Here, hasClarity is a shorthand for ex:hasClarity, which is (typically) expanded to the URI http://example.org#hasClarity. URIs identify terms, globally.
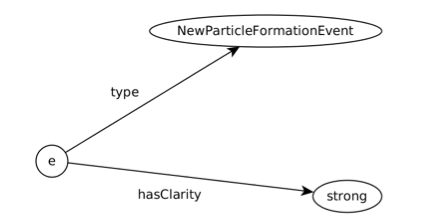
Figure 2: RDF graph representation of the assertions about the NPF event e.
In the Semantic Web, term semantics can be described formally by means of RDF Schema (Brickley and Guha, 2014) and the Web Ontology Language (Hitzler et al., 2012). For instance, about atmospheric events we may further state that
Class: AtmosphericEvent
SubClassOf: sweet:Event
that sweet:hasRealm only sweet:Atmosphere
whereby Event, hasRealm and Atmosphere are terms of the SWEET ontology (Raskin and Pan, 2005).
Reflecting on the model proposed by Aamodt and Nygård, in this case study of the daily DMPS data and the vector resulting from processing such data are observed symbols without meaning for the system concerned. DMPS data for a particular day and the corresponding feature vector used in classification each form a dataset. In contrast, the assertions about a NPF event are information for the system concerned. The object represented graphically in Figure 2 is an interpretation information object. Interpretations aggregate information obtained in data interpretation, and represent such information formally so that information is machine readable.
3 Research Objects
Research Objects (ROs) are "semantically rich aggregations of resources that bring together data, methods and people in scientific investigations" (Bechhofer et al., 2013). They aggregate resources "used and/or produced in a given scientific investigation" (Belhajjame et al., 2013). We provide a concise overview of the basic aggregation structure of an RO following the RO Model proposed in Wf4Ever (Belhajjame et al., 2012a), a FP7 research project that addressed challenges associated with the preservation of scientific experiments in data-intensive science, including best practices for the creation and management of Research Objects.
According to the Wf4Ever RO Model, an RO aggregates resources and annotations about them (Belhajjame et al., 2012b). Resources can be datasets, papers, software, annotations. Annotations are associations of additional information with resources. ROs support access to the identification of aggregated resources, and possibly access to the resources themselves (Belhajjame et al., 2013).
The core constructs of the RO Model relevant to the basic aggregation structure are the classes ResearchObject, Resource, and Annotation. Resource "represents a resource that can be aggregated within a research object." ROs aggregate one or more resources. Resource types include Dataset, Paper, Software, and Annotation. Annotations are used to describe ROs, aggregated resources, and relations between resources.
In addition to annotations for the day T when it was created and who created it, an example basic RO in our case study aggregates the dataset d1 with the DMPS data for day T and the dataset d2 with the feature vector for processed DMPS data for day T. Both datasets d1 and d2 are instances of the class Resource and, specifically, the Wf4Ever class Dataset. Here, d1 and d2 are URIs identifying QB datasets and are thus (also) instances of the class QB DataSet.
We propose to extend the RO Model with an additional Resource type for machine readable objects representing information resulting from data interpretation. We call the additional type Interpretation. Figure 3 extends the basic aggregation structure of an RO as proposed by Belhajjame et al. (2012b) with the new Resource type.
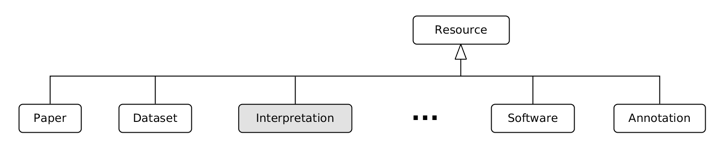
Figure 3: Research Object Model Resource types including the proposed Intrepretation.
4 Application
We demonstrate how the RO Model can be used to describe aggregations of resources relevant to our case study on atmospheric new particle formation, in particular interpretation information objects. Listing 1 summarizes the most important RDF statements of the RO and the aggregated resources.
@prefix dct: <http://purl.org/dc/terms/> .
@prefix ex: <http://example.org#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix ore: <http://www.openarchives.org/ore/terms/> .
@prefix qb: <http://purl.org/linked-data/cube#> .
@prefix ro: <http://purl.org/wf4ever/ro#> .
@prefix swrc: <http://swrc.ontoware.org/ontology#> .
@prefix wf4ever: <http://purl.org/wf4ever/wf4ever#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
|
| < > |
a
ore:aggregates
dct:created
dct:creator |
ro:ResearchObject ;
ex:d1, ex:f1, ex:d2, ex:s1, ex:e ;
"2011-03-26"^^xsd:dateTime ;
[ a foaf:Person; foaf:name "Markus Stocker" ] .
|
| ex:dl |
a
swrc:doi
|
wf4ever:Dataset, qb:DataSet ;
<https://doi.org/10.6084/m9.figshare.3565635> .
|
| ex:fl |
a
swrc:doi
|
wf4ever:Image ;
<https://doi.org/10.6084/m9.figshare.3567273> .
|
| ex:d2 |
a
swrc:doi
|
wf4ever:Dataset, qb:DataSet ;
<https://doi.org/10.6084/m9.figshare.3571146> .
|
| ex:s1 |
a
swrc:doi
|
wf4ever:Software ;
<https://doi.org/10.6084/m9.figshare.3571212> .
|
| ex:e |
a
ex:hasClarity
|
ex:NewParticleFormationEvent, ro:Interpretation ;
ex:strong .
|
Listing 1: Example Research Object that aggregates an Interpretation object representing information about a NPF event detected and characterized by interpreting processed DPMS data. The Resource Object is published at https://doi.org/10.6084/m9.figshare.4028940.
The RO aggregates five resources, identified as ex:d1, ex:f1, ex:d2, ex:s1, and ex:e. The two QB datasets d1 and d2 are for the DMPS data and the corresponding feature vector, respectively, on March 26, 2011. Dataset d1 is a collection of 144 observations each with 38 components. Dataset d2 is the result of processing d1 using Singular Value Decomposition. The RO also aggregates Figure 1 (ex:f1) as well as the R script (ex:s1) used to generate the figure and the two datasets. In an attempt to make the work presented here reproducible, these resources are published and persistently identified by DOIs.
The RO aggregates a fifth resource, namely the interpretation. Identified by ex:e, the interpretation formally describes the detected and characterized NPF event. The interpretation information object is the result of classifying the feature vector represented by the QB observation, singleton element of dataset d2, using machine learning. Following Aamodt and Nygård's model, the QB observation is data, an observed symbol without meaning for the system concerned. Machine learning implements the data interpretation process and the resulting interpretation is interpreted data with meaning for the system concerned. Please refer to Stocker et al. (2014) for more details about the machine learning classification tasks and implementation.
5 Discussion
As scientific data is interpreted for their meaning within a real-world context and for a particular purpose, we have suggested that information gained from data via the process of data interpretation is a resource that can be represented formally using Semantic Web technologies and, as our main contribution, can be aggregated in Research Objects. We have proposed a simple extension of an existing Research Object Model to explicitly include an additional resource type for machine readable objects representing information resulting from data interpretation. We have demonstrated the proposed extension for an application in aerosol science, specifically for the detection and characterization of atmospheric new particle formation events in observation data by a differential mobility particle sizer.
For the sake of simplicity, we limited the discussion here to data and information, in particular information about the theme of interest, i.e. events of atmospheric new particle formation. In addition to information about the theme, also relevant is information about time and space, i.e. information for when and where events occur. Furthermore, aerosol scientists may characterize events with information other than event clarity, such as event duration and the rate at which newly formed aerosol populations grow during an event (Dal Maso et al., 2005). Hence, systems gain information of heterogeneous type.
In addition to data and information, the model by Aamodt and Nygård (1995) also considers knowledge. According to the authors, knowledge is learned information, i.e. "information incorporated in an agent's reasoning resources." Information is the output of a learning process, i.e. output of a process "in which new information is integrated into an existing knowledge structure."
For our case study, Stocker et al. (2014) have argued that in detecting and characterizing atmospheric new particle formation events, aerosol scientists gain information about situations occurring in the monitored environment. The authors have proposed to structure related information for theme, space, and time and represent the structured object as a situational knowledge object using the Situation Theory Ontology (Kokar et al., 2009). Following the approach used to aggregate interpretation information objects, it is arguably straightforward to see how situational knowledge objects can be aggregated in Research Objects.
Knowledge objects may be of heterogeneous type. Depending on the application, a system may acquire information about (environmental) processes. Rather than situational knowledge objects, such a system may thus represent processual knowledge objects. Moreover, in representing information and knowledge objects, systems may commit to different ontologies. We are not discussing these matters further as we limit ourselves to the observation that information and knowledge objects aggregated in Research Objects can have arbitrary complex structure and semantically rich machine readable and processable descriptions.
Concepts and models other than the Research Object with, however, comparable purpose have been proposed in the literature. The RMap Project (Hanson et al., 2015), which aims at preserving "the many-to-many complex relationships among scholarly publications and their underlying data" (see RMap Project Overview White Paper) and builds on features of the Semantic Web, has introduced the Distributed Scholarly Compound Object (DiSCO). DiSCOs are designed to aggregate one or more resources into a single object. DiSCO resources are identified by URI. Being RDFS resources, they can be subjects or objects in RDF statements. The URIs ex:d1, ex:f1, ex:d2, ex:s1, and ex:e used in our application are URIs and resources in RDF statements. They can be represented as DiSCO resources and can be aggregated in DiSCO instances. DiSCOs can thus also aggregate machine readable information objects representing data interpretation results.
Naturally, interpretation of data and the learning of knowledge are ubiquitous processes in research. Examples can be found in the literature. For instance, Grainger (2010) discusses the construction of global knowledge of tropical forest change. The author underscores that environmental scientists "have a responsibility to make clear global knowledge statements."
Grainger models the construction of composite knowledge of forests by a "chain of knowledge exchange cycles." With the exception of the first cycle, each consecutive cycle can be divided into five stages: (1) collection of data and information; (2) construction of information; (3) reporting of information; (4) verification of information; (5) synthesis of verified information to construct knowledge. The first cycle is concerned with data collection. The remaining cycles "convert data into primary, secondary and tertiary information and knowledge."
Remote sensing data is collected for the construction of global knowledge of tropical forest change. With raw data processing we obtain primary information, e.g. on forest area or timber volume. With primary information processing we obtain secondary information, e.g. on changes in total forest area. With secondary information processing we obtain tertiary information, e.g. on the spatial coincidence of forests with high carbon density and biodiversity. Knowledge is constructed by analysis of primary, secondary or tertiary information. For instance, information analysis results in knowledge of the causes of forest area change or the rates of deforestation.
Grainger discusses knowledge construction for tropical forest change in great detail. In contrast, we have only discussed the key elements of our use case in aerosol science. However, contrary to Grainger, we sketch how information can be represented formally by software systems and, more importantly, how information objects representing data interpretations can be aggregated in Research Objects as first class citizens, akin to data, metadata, workflows, software, papers and other outputs.
Information resulting from data interpretation involves concepts and relations of an ontology. Semantic Web technologies arguably provide a suitable framework for creating ontologies and curating, accessing, processing, and using information obtained in data interpretation. In socio-technical systems, such as environmental research infrastructures, ontologies are shared between human and technical agents. They are typically created by human agents, and technical agents are developed with commitment to ontologies, their terms and semantics. This approach ensures that information is represented explicitly and formally, and can thus be managed by computer systems. We think ontologies, and possibly Semantic Web technologies, are key elements of advanced software systems in environmental knowledge infrastructures (Stocker, 2017).
Another aspect worth highlighting is the possibility of associating Persistent Identifiers (PIDs) to interpretations aggregated in Research Objects. Naturally, the same can be said for Research Objects themselves. A PID is an association between a character string and a resource. PIDs enable unambiguous reference and access to resources. The Digital Object Identifier (DOI), widely used in article citations, is arguably the best known PID type. PIDs may be actionable, meaning that an agent may resolve a PID to access the associated resource.
It is straightforward to integrate PIDs in Research Objects. Following the example in Section 4, in addition to (or instead of) the name of the creator, the example resource could relate the ORCID iD of the creator using the dbo:orcidId property as follows:
< > a ro:ResearchObject ;
dct:creator [ a foaf:Person; dbo:orcidId "0000-0001-5492-3212" ] .
where dbo: stands for the namespace of the DBpedia (Auer et al., 2007) ontology. With this relation, the creator is unambiguously identified and further information about the person may be retrieved, through ORCID. The same can be said for datasets aggregated in Research Objects. Datasets may be deposited in (disciplinary) data repository, such as the PANGAEA Data Publisher for Earth & Environmental Science (Diepenbroek et al., 2002). Data repositories increasingly often assign DOIs to published datasets. Datasets aggregated in Research Objects could relate to DOIs. We have demonstrated this for figshare DOIs.
In the future, scientific information and knowledge repositories may manage interpretations of data and learned information as machine readable and processable knowledge objects identified by PIDs, possibly aggregated in Research Objects.
6 Conclusion
Researchers interpret scientific data. The resulting information flows into research artefacts such as articles, figures, slides, models, or software. In these forms, information and corresponding semantics are hardly machine readable, as information is locked in the particular medium — be it the natural language text of an article, the pixel data of an image, or the parametrization of program code.
As scholarly communication increasingly moves from print (or print-like digital) research artefacts, i.e. articles, to include a plurality of artefact types, the community has questioned and revisited the traditional methods of publication and information exchange and proposed novel artefact types that improve on aspects such as reusability, reproducibility, identity, and traceability of scientific information. One such proposal is the Research Object.
We have briefly reviewed the notion of Research Object and argued that in addition to data, metadata, workflows, etc., Research Objects can also aggregate machine readable and processable objects representing information resulting from data interpretation.
As our main contribution, we have extended a Research Object Model to include the Interpretation resource type, i.e. the abstract class for (machine readable) objects representing information resulting from data interpretation. Thus, Research Objects not only aggregate datasets utilized as input to data interpretation and workflows implementing data interpretation processes, but also the information resulting from data interpretation.
We have presented the proposed extension for an application in aerosol science, for the study of atmospheric new particle formation. Given daily datasets with observation values for particle size distribution of polydisperse aerosols measured by a differential mobility particle sizer, data are interpreted using machine learning to detect and characterize events of atmospheric new particle formation occurring at the location of measurement on any given day. We have presented how daily Research Objects can aggregate relevant datasets, including raw and processed sensor observation values, as well as interpretation information objects for detected and characterized atmospheric new particle formation events.
Though we have limited the discussion to information, the approach can arguably be extended to knowledge, and specific knowledge types such as situational knowledge or processual knowledge. The approach can also be adapted to structures other than the Research Object that similarly aggregate (identifiers of) scholarly resources, such as the Distributed Scholarly Compound Object. Some of these aspects could be addressed in future work.
In conclusion, the ubiquity of data interpretation in scientific investigations suggests that the output of interpretation, i.e. information, should be considered as a further research artefact that may be aggregated as machine readable information in Research Objects, or similar structures.
Acknowledgements
This work was supported by the THOR Project. The THOR project is funded by the European Union under H2020-EINFRA-2014-2 (Grant Agreement number 654039). Aerosol data was obtained programmatically via the SmartSMEAR API.
References
| [1] |
Aamodt, A., Nygård, M. (1995). Different roles and mutual dependencies of data, information, and knowledge — An AI perspective on their integration. Data & Knowledge Engineering, 16(3):191-222. https://doi.org/10.1016/0169-023X(95)00017-M |
| [2] |
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., Ives, Z. (2007). DBpedia: A Nucleus for a Web of Open Data. The Semantic Web, 4825:722-735. https://doi.org/10.1007/978-3-540-76298-0_52 |
| [3] |
Bechhofer, S., De Roure, D., Gamble, M., Goble, C., Buchan, I. (2010). Research Objects: Towards Exchange and Reuse of Digital Knowledge. Nature Precedings, Nature Publishing Group. https://doi.org/10.1038/npre.2010.4626.1 |
| [4] |
Bechhofer, S., Buchan, I., De Roure, D., Missier, P., Ainsworth, J., Bhagat, J., Couch, P., Cruickshank, D., Delderfield, M., Dunlop, I., Gamble, M., Michaelides, D., Owen, S., Newman, D., Sufi, S., Goble, C. (2013). Why linked data is not enough for scientists. Future Generation Computer Systems, 29(2):599-611. https://doi.org/10.1016/j.future.2011.08.004 |
| [5] |
Belhajjame, K., Corcho, O., Garijo, D., Zhao, J., Missier, P., Newman, D.R., Palma, R., Bechhofer, S., Garcia-Cuesta, E., Gómez-Pérez, J.M., Klyne, G., Page, K., Roos, M., Ruiz, J.E., Soiland-Reyes, S., Verdes-Montenegro, L., De Roure, D., Goble, C.A. (2012a). Workflow-Centric Research Objects: A First Class Citizen in the Scholarly Discourse. In Proceedings of the ESWC2012 Workshop on the Future of Scholarly Communication in the Semantic Web (SePublica2012), Heraklion, Greece. |
| [6] |
Belhajjame, K., Garijo, D., Corcho, O., García Cuesta, E., Soiland-Reyes, S. (2012b). Wf4Ever Research Object Ontologies and Vocabularies Primer. |
| [7] |
Belhajjame, K., Klyne, G., Garijo, D., Corcho, O., García Cuesta, E., Palma, R. (2013). Wf4Ever Research Object Model 1.0. |
| [8] |
Bourne, P.E., Clark, T., Dale, R., de Waard, A., Herman, I., Hovy, E.H., Shotton, D. (2012). Force11 White Paper: Improving The Future of Research Communications and e-Scholarship. |
| [9] |
Brickley, D., Guha, R. (2014). RDF Schema 1.1. W3C Recommendation. |
| [10] |
Cyganiak, R., Reynolds, D., Tennison, J. (2014). The RDF Data Cube Vocabulary. W3C Recommendation. |
| [11] |
Dal Maso, M., Kulmala, M., Riipinen, I., Wagner, R., Hussein, T., Aalto, P., Lehtinen, K. (2005). Formation and growth of fresh atmospheric aerosols: eight years of aerosol size distribution data from SMEAR II, Hyytiala, Finland. Boreal Environ. Res., 10(5):323-336. |
| [12] |
De Roure, D., Goble, C. (2009). Lessons from myExperiment: Research Objects for Data Intensive Research. eScience Workshop. |
| [13] |
Diepenbroek, M., Grobe, H., Reinke, M., Schindler, U., Schlitzer, R., Sieger, R., Wefer, G. (2002). PANGAEA—an information system for environmental sciences. Computers & Geosciences, 28(10):1201-1210. https://doi.org/10.1016/S0098-3004(02)00039-0 |
| [14] |
Grainger, A. (2010). Uncertainty in the construction of global knowledge of tropical forests. Progress in Physical Geography, 34(6):811-844. https://doi.org/10.1177/0309133310387326 |
| [15] |
Hamed, A., Joutsensaari, J., Mikkonen, S., Sogacheva, L., Dal Maso, M., Kulmala, M., Cavalli, F., Fuzzi, S., Facchini, M., Decesari, S., et al. (2007). Nucleation and growth of new particles in Po Valley, Italy. Atmos. Chem. Phys., 7(2):355-376. https://doi.org/10.5194/acp-7-355-2007 |
| [16] |
Hanson, K.L., DiLauro, T., Donoghue, M. (2015). The RMap Project: Capturing and Preserving Associations amongst Multi-Part Distributed Publications. In Proceedings of the 15th ACM/IEEE-CS Joint Conference on Digital Libraries, pp. 281-282. ACM. https://doi.org/10.1145/2756406.2756952 |
| [17] |
Hitzler, P., Krötzsch, M., Parsia, B., Patel-Schneider, P. F., Rudolph, S. (2012). OWL 2 Web Ontology Language Primer (Second Edition). W3C Recommendation. |
| [18] |
Junninen, H., Lauri, A., Keronen, P., Aalto, P. (2009). Smart-SMEAR: on-line data exploration and visualization tool for SMEAR stations. Boreal Environment Research, 14(4):447-457. |
| [19] |
Kokar, M.M., Matheus, C.J., Baclawski, K. (2009). Ontology-based situation awareness. Information Fusion, 10(1):83-98. https://doi.org/10.1016/j.inffus.2007.01.004 |
| [20] |
Kulmala, M., Vehkamäki, H., Petäjä, T., Dal Maso, M., Lauri, A., Kerminen, V., Birmili, W., McMurry, P. (2004). Formation and growth rates of ultrafine atmospheric particles: a review of observations. Journal of Aerosol Science, 35(2):143-176. https://doi.org/10.1016/j.jaerosci.2003.10.003 |
| [21] |
Manola, F., Miller, E., McBride, B. (2004). RDF Primer. W3C Recommendation. |
| [22] |
Prud'hommeaux, E., Seaborne, A. (2008). SPARQL Query Language for RDF. W3C Recommendation. |
| [23] |
Raskin, R.G., Pan, M.J. (2005). Knowledge representation in the semantic web for Earth and environmental terminology (SWEET). Computers & Geosciences, 31(9):1119-1125. https://doi.org/10.1016/j.cageo.2004.12.004 |
| [24] |
Stocker, M., Baranizadeh, E., Portin, H., Komppula, M., Rönkkö, M., Hamed, A., Virtanen, A., Lehtinen, K., Laaksonen, A., Kolehmainen, M. (2014). Representing situational knowledge acquired from sensor data for atmospheric phenomena. Environmental Modelling & Software 58:27-47. https://doi.org/10.1016/j.envsoft.2014.04.006 |
| [25] |
Stocker, M. (2017). Advancing the Software Systems of Environmental Knowledge Infrastructures. In A. Chabbi and H. Loescher (Eds.), Terrestrial Ecosystem Research Infrastructures: Challenges, New developments and Perspectives. CRC Press. (In Press) |
About the Author
Markus Stocker holds a PhD in Environmental Sciences (Informatics) from the University of Eastern Finland and a MSc in Informatics from the University of Zurich, Switzerland. He is interested in environmental knowledge infrastructures. Currently, he is a postdoctoral research associate with PANGAEA, the Data Publisher for Earth & Environmental Science, at the MARUM Center for Marine Environmental Sciences, University of Bremen, Germany. He has several years of professional experience in software development with interests in semantic web technologies, environmental sensor networks, data management and data mining as well as formal representation of mined information and knowledge.