 |
T A B L E O F C O N T E N T S
J A N U A R Y / F E B R U A R Y 2 0 1 7
Volume 23, Number 1/2
ISSN: 1082-9873
https://doi.org/10.1045/january2017-contents
E D I T O R I A L S
Special Issue
Editorial by Laurence Lannom, Corporation for National Research Initiatives
RepScience2016
Guest Editorial by Amir Aryani, Australian National Data Service; Oscar Corcho, Departamento de Inteligencia Artificial, Universidad Politécnica de Madrid; Paolo Manghi, Istituto di Scienza e Tecnologie dell'Informazione, Consiglio Nazionale delle Ricerche; Jochen Schirrwagen, Bielefeld University Library
A R T I C L E S
From Data to Machine Readable Information Aggregated in Research Objects
Article by Markus Stocker, PANGAEA, MARUM Center for Marine Environmental Sciences, University of Bremen
Abstract: Data interpretation is an important process in scientific investigations. It results in information and gives data meaning. As a case in point, earth and environmental scientists interpret data — increasingly often collected in large-scale environmental research infrastructures — to gain information about the studied environment. Information is typically represented to suit human consumption — in natural language text, figures and tables designed for expert processing. Building on a case study in aerosol science, we discuss how information resulting in data interpretation can be represented as machine readable information objects, here of type Interpretation. As the main contribution, we present the aggregation of interpretations in Research Objects. Together with data, metadata, workflows, software, and articles, interpretations are contextual resources of scientific investigations. The explicit aggregation of interpretations in Research Objects is arguably a further step toward a more complete representation of the context of scientific investigations.
The Scholix Framework for Interoperability in Data-Literature Information Exchange
Article by Adrian Burton and Amir Aryani, Australian National Data Service; Hylke Koers, Elsevier; Paolo Manghi and Sandro La Bruzzo, Istituto di Scienza e Tecnologie dell'Informazione, Consiglio Nazionale delle Ricerche; Markus Stocker, Michael Diepenbroek and Uwe Schindler, PANGAEA, MARUM Center for Marine Environmental Sciences, University of Bremen; Martin Fenner, DataCite
Abstract: The Scholix Framework (SCHOlarly LInk eXchange) is a high level interoperability framework for exchanging information about the links between scholarly literature and data, as well as between datasets. Over the past decade, publishers, data centers, and indexing services have agreed on and implemented numerous bilateral agreements to establish bidirectional links between research data and the scholarly literature. However, because of the considerable differences inherent to these many agreements, there is very limited interoperability between the various solutions. This situation is fueling systemic inefficiencies and limiting the value of these, separated, sets of links. Scholix, a framework proposed by the RDA/WDS Publishing Data Services working group, envisions a universal interlinking service and proposes the technical guidelines of a multi-hub interoperability framework. Hubs are natural collection and aggregation points for data-literature information from their respective communities. Relevant hubs for the communities of data centers, repositories, and journals include DataCite, OpenAIRE, and Crossref, respectively. The framework respects existing community-specific practices while enabling interoperability among the hubs through a common conceptual model, an information model and open exchange protocols. The proposed framework will make research data, and the related literature, easier to find and easier to interpret and reuse, and will provide additional incentives for researchers to share their data.
Supporting Data Reproducibility at NCI Using the Provenance Capture System
Article by Jingbo Wang, Ben Evans and Lesley Wyborn, National Computational Infrastructure, Australia; Nick Car, Geoscience Australia; Edward King, CSIRO, Australia
Abstract: Scientific research is published in journals so that the research community is able to share knowledge and results, verify hypotheses, contribute evidence-based opinions and promote discussion. However, it is hard to fully understand, let alone reproduce, the results if the complex data manipulation that was undertaken to obtain the results are not clearly explained and/or the final data used is not available. Furthermore, the scale of research data assets has now exponentially increased to the point that even when available, it can be difficult to store and use these data assets. In this paper, we describe the solution we have implemented at the National Computational Infrastructure (NCI) whereby researchers can capture workflows, using a standards-based provenance representation. This provenance information, combined with access to the original dataset and other related information systems, allow datasets to be regenerated as needed which simultaneously addresses both result reproducibility and storage issues.
Graph Connections Made By RD-Switchboard Using NCI's Metadata
Article by Jingbo Wang, Ben Evans and Lesley Wyborn, National Computational Infrastructure, Australia; Amir Aryani and Melanie Barlow, Australian National Data Service
Abstract: This paper demonstrates the connectivity graphs made by Research Data Switchboard (RD-Switchboard) using NCI's metadata database. Making research data connected, discoverable and reusable are some of the key enablers of the new data revolution in research. We show how the Research Data Switchboard identified the missing critical information in our database, and what improvements have been made by this system. The connections made by the RD-Switchboard demonstrated the various use of the datasets, and the network of researchers and cross-referenced publications.
Opening the Publication Process with Executable Research Compendia
Article by Daniel Nüst, Markus Konkol, Edzer Pebesma and Christian Kray, Institute for Geoinformatics; Marc Schutzeichel, Holger Przibytzin and Jörg Lorenz, University and State Library, Münster
Abstract: A strong movement towards openness has seized science. Open data and methods, open source software, Open Access, open reviews, and open research platforms provide the legal and technical solutions to new forms of research and publishing. However, publishing reproducible research is still not common practice. Reasons include a lack of incentives and a missing standardized infrastructure for providing research material such as data sets and source code together with a scientific paper. Therefore we first study fundamentals and existing approaches. On that basis, our key contributions are the identification of core requirements of authors, readers, publishers, curators, as well as preservationists and the subsequent description of an executable research compendium (ERC). It is the main component of a publication process providing a new way to publish and access computational research. ERCs provide a new standardisable packaging mechanism which combines data, software, text, and a user interface description. We discuss the potential of ERCs and their challenges in the context of user requirements and the established publication processes. We conclude that ERCs provide a novel potential to find, explore, reuse, and archive computer-based research.
Conquaire: Towards an Architecture Supporting Continuous Quality Control to Ensure Reproducibility of Research
Article by Vidya Ayer, Cord Wiljes, Philipp Cimiano, CITEC, Bielefeld University; Christian Pietsch, Johanna Vompras, Jochen Schirrwagen and Najko Jahn, Bielefeld University Library
Abstract: Analytical reproducibility in scientific research has become a keenly discussed topic within scientific research organizations and acknowledged as an important and fundamental goal to strive for. Recently published scientific studies have found that irreproducibility is widely prevalent within the research community, even after releasing data openly. At Bielefeld University, nine research project groups from varied disciplines have embarked on a "reproducibility" journey by collaborating on the Conquaire project as case study partners. This paper introduces the Conquaire project. In particular, we describe the goals and objectives of the project as well as the underlying system architecture which relies on a DCVS system for storing data, and on continuous integration principles to foster data quality. We describe a first prototype implementation of the system and discuss a running example which illustrates the functionality and behaviour of the system.
Towards Reproducibility of Microscopy Experiments
Article by Sheeba Samuel, Frank Taubert and Daniel Walther, Institute for Computer Science, Friedrich Schiller University Jena; Birgitta König-Ries and H. Martin Bücker, Institute for Computer Science, Friedrich Schiller University Jena, Michael Stifel Center Jena for Data-driven and Simulation Science
Abstract: The rapid evolution of various technologies in different scientific disciplines has led to the generation of large volumes of high dimensional data. Studies have shown that most of the published work is not reproducible due to the non-availability of the datasets, code, algorithm, workflow, software, and technologies used for the underlying experiments. The lack of sufficient documentation and the deficit of data sharing among particular research communities have made it extremely difficult to reproduce scientific experiments. In this article, we propose a methodology enhancing the reproducibility of scientific experiments in the domain of microscopy techniques. Though our approach addresses the specific requirements of an interdisciplinary team of scientists from experimental biology to store, manage, and reproduce the workflow of their research experiments, it can also be extended to the requirements of other scientific communities. We present a proof of concept of a central storage system that is based on OMERO (Allan et al., Nature Methods 9, 245-253, 2012). We discuss the criteria and attributes needed for reproducibility of microscopy experiments.
HyWare: a HYbrid Workflow lAnguage for Research E-infrastructures
Article by Leonardo Candela and Paolo Manghi, Istituto di Scienza e Tecnologie dell'Informazione, Consiglio Nazionale delle Ricerche; Fosca Giannotti, Valerio Grossi and Roberto Trasarti, KDD Lab, ISTI CNR, Pisa, Italy
Abstract: Research e-infrastructures are "systems of systems", patchworks of tools, services and data sources, evolving over time to address the needs of the scientific process. Accordingly, in such environments, researchers implement their scientific processes by means of workflows made of a variety of actions, including for example usage of web services, download and execution of shared software libraries or tools, or local and manual manipulation of data. Although scientists may benefit from sharing their scientific process, the heterogeneity underpinning e-infrastructures hinders their ability to represent, share and eventually reproduce such workflows. This work presents HyWare, a language for representing scientific process in highly-heterogeneous e-infrastructures in terms of so-called hybrid workflows. HyWare lays in between "business process modeling languages", which offer a formal and high-level description of a reasoning, protocol, or procedure, and "workflow execution languages", which enable the fully automated execution of a sequence of computational steps via dedicated engines.
Enabling Reproducibility for Small and Large Scale Research Data Sets
Article by Stefan Pröll, SBA Research, Austria and Andreas Rauber, Vienna University of Technology, Austria
Abstract: A large portion of scientific results is based on analysing and processing research data. In order for an eScience experiment to be reproducible, we need to able to identify precisely the data set which was used in a study. Considering evolving data sources this can be a challenge, as studies often use subsets which have been extracted from a potentially large parent data set. Exporting and storing subsets in multiple versions does not scale with large amounts of data sets. For tackling this challenge, the RDA Working Group on Data Citation has developed a framework and provides a set of recommendations, which allow identifying precise subsets of evolving data sources based on versioned data and timestamped queries. In this work, we describe how this method can be applied in small scale research data scenarios and how it can be implemented in large scale data facilities having access to sophisticated data infrastructure. We describe how the RDA approach improves the reproducibility of eScience experiments and we provide an overview of existing pilots and use cases in small and large scale settings.
N E W S & E V E N T S
In Brief: Short Items of Current Awareness
In the News: Recent Press Releases and Announcements
Clips & Pointers: Documents, Deadlines, Calls for Participation
Meetings, Conferences, Workshops: Calendar of Activities Associated with Digital Libraries Research and Technologies
|
|
F E A T U R E D D I G I T A L
C O L L E C T I O N
Harvard-Smithsonian Center for Astrophysics
The Harvard-Smithsonian Center for Astrophysics (CfA), an amalgam of the Smithsonian Astrophysical Observatory and the Harvard College Observatory, is the largest astronomy research organization in the world.
The CfA has a long history of supporting text and data mining for astronomy. The CfA's John G. Wolbach Library is the world's largest astronomy research library, and Harvard's archive of glass photographic plates is also the worlds largest.
The first modern archive/data center to support space astronomy missions was built at the CfA to support the Einstein X-Ray mission; this work continues with the Chandra Data Archive.
The pioneering Smithsonian/NASA Astrophysics Data System(ADS) was begun at the CfA a quarter of a century ago. It one of the world's most important scholarly digital libraries, used essentially daily by every working astronomer, as well as several tens of thousands of physicists. The ADS was described in the November 1999 issue of D-Lib Magazine.
The ADS now has metadata for more than 11 Million articles, and the full text of nearly every astronomy article ever written, and a large fraction of the refereed physics literature, more than 5 million articles. Besides the standard web based client the ADS maintains an open, sophisticated text mining API.

Figure 1
(Used with permission.)
Figure 1 combines some text and data mining capabilities of the ADS to show the breadth of current CfA research. Beginning with an ADS query for all refereed papers in the astronomy database where the 1st, 2nd, or 3rd author has an affiliation from either Harvard or Smithsonian and a publication year of 2016, currently 360 papers; next these papers are linked into a network by bibliographic coupling (references in common), the Louvain community detection algorithm is run on the network, and the resulting clusters of papers are named by a tf/idf analysis of the combined titles. The cluster sizes represent their recent download activity. This feature was built by Alexandra Holachek of the ADS staff; a real-time updated version is here.
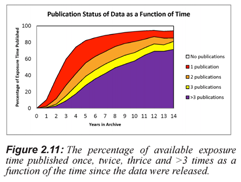
Figure 2
(Used with permission.)
Figure 2 shows the increasing importance of archival data from the Chandra mission; a large and increasing fraction of the total journal article output of the telescope is based on the re-use of older data from the archive. This analysis was made possible by the automated (using the ADS API) and manual text mining/curation of the astronomy literature to discover all papers which use Chandra data. These curated lists of papers are also included in the ADS along with links to the original archival data. Sherry Winkelman of the Chandra staff is responsible for this effort.
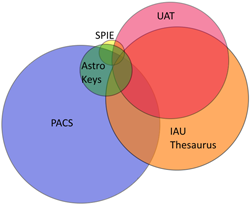
Figure 3
(Used with permission.)
Figure 3 shows schematically the relations between the several thesauri and vocabulary lists used as sources and the Unified Astronomy Thesaurus (UAT). The UAT is a large international effort to create a standard vocabulary for describing astronomical text and data, replacing the old and incompatible systems currently in use. The project is managed at the CfA by Katie Frey of the CfA Library staff and Alberto Accomazzi, the ADS principle investigator.
D - L I B E D I T O R I A L S T A F F
Laurence Lannom, Editor-in-Chief
Allison Powell, Associate Editor
Catherine Rey, Managing Editor
Bonita Wilson, Contributing Editor
|