D-Lib Magazine
January/February 2017
Volume 23, Number 1/2
Table of Contents
Supporting Data Reproducibility at NCI Using the Provenance Capture System
Jingbo Wang
National Computational Infrastructure, Australia
http://orcid.org/0000-0002-3594-1893
jingbo.wang@anu.edu.au
Nick Car
Geoscience Australia
http://orcid.org/0000-0002-8742-7730
nicholas.car@ga.gov.au
Edward King
CSIRO, Australia
http://orcid.org/0000-0002-6898-2310
edward.king@csiro.au
Ben Evans
National Computational Infrastructure, Australia
http://orcid.org/0000-0002-6719-2671
ben.evans@anu.edu.au
Lesley Wyborn
National Computational Infrastructure, Australia
http://orcid.org/0000-0001-5976-4943
lesley.wyborn@anu.edu.au
Corresponding Author: Jingbo Wang, jingbo.wang@anu.edu.au
https://doi.org/10.1045/january2017-wang
Abstract
Scientific research is published in journals so that the research community is able to share knowledge and results, verify hypotheses, contribute evidence-based opinions and promote discussion. However, it is hard to fully understand, let alone reproduce, the results if the complex data manipulation that was undertaken to obtain the results are not clearly explained and/or the final data used is not available. Furthermore, the scale of research data assets has now exponentially increased to the point that even when available, it can be difficult to store and use these data assets. In this paper, we describe the solution we have implemented at the National Computational Infrastructure (NCI) whereby researchers can capture workflows, using a standards-based provenance representation. This provenance information, combined with access to the original dataset and other related information systems, allow datasets to be regenerated as needed which simultaneously addresses both result reproducibility and storage issues.
Keywords: Provenance, Workflow, Big Data
1 Introduction
The National Computational Infrastructure (NCI) at the Australian National University (ANU) has co-located over 10 PBytes of national and international Earth Systems and Environmental data assets within a High Performance Computing (HPC) facility, which is accessible through the National Environmental Research Data Interoperability Platform (NERDIP) [1]. Datasets are either produced at the NCI, stored from instruments, or replicated as needed from external locations. In many cases this data is processed to higher-level data products which are also stored and published through NERDIP. The datasets within these collections can range from multi-petabyte climate models and large-volume raster arrays, down to gigabyte size, ultra-high resolution datasets. All data collections are currently in the process of being quality assured in order to be made available via the web services. Most data collections at the NCI are dynamic — datasets grow spatially or temporally, models/derivative products are revised and rerun, and whole datasets are reprocessed as analysis methods are improved. Additionally, some products require the generation of multiple intermediate data sets. At the scale of NCI it is not easy to justify storing all the previous versions of datasets and intermediate datasets or to of track, store and republish all the subsets of datasets generated and referred in publications.
To address these issues, we decided to integrate a provenance information service. Provenance information can be defined as "information about entities, activities, and people involved in producing a piece of data or thing" [2,3]. Through the implementation that is described below, we have enabled a service that allows us to fully describe how datasets or subsets have been generated, and that allows the history of such datasets to be referenced, such as for methodological citation within third-party publications. This is particularly useful for authors submitting papers to high-impact journals such as Nature and Science where space is at a premium [4]. A common example of provenance is scientific workflow. "Scientific workflows provide the means for automating computational scientific experiments, enabled by established workflow execution engines, like Apache Taverna, Kepler, VisTrails or Galaxy. A workflow-centric research object contain the application-specific workflow definition, annotated with wfdesc, and combined with a PROV-based execution trace of one or more workflow runs, including inputs and outputs" (see researchobject.org) [5].
The NCI represents provenance information from all processes according to a standardised data model known as PROV-DM [2]. The information is stored as RDF documents in an RDF graph database, which is then published via a HTTP-based API as a combination of web pages and data. We describe how a provenance information service is implemented at NCI. Then we demonstrate a provenance use case using satellite images processing applied in oceanography to show the workflow and provide proof that the whole process can be repeated by following the detailed provenance report. Providing provenance information also supports the quality assurance and quality control (QA/GC) processes for the NCI, which ensures that there is a trust-worthy, standardised and fully-described record that can be integrated within programmatic workflows that can then be reported and published via a centralised information service.
2 Methodology
We list the generic steps required for establishing provenance capture at NCI:
- Systems — establishment of central provenance management infrastructure;
- Modelling — of workflows/processing for which we require provenance. Modelling must be in accordance with PROV-O [6] standard for interoperability;
- Data management — of the data which the workflow or process uses or generates. The data must be identified with URIs (see next section) stored as per the NCI's data management policy;
- Reporting implementation — the reporting process must record the modelled versions of the workflow; and
- Reporting operations — reporting from the process must continue each time the process is run. This can be accomplished when runs occur or after the event if the reporting implementation reads from log files or similar.
In this paper, we focus on the Systems, Modelling and Data management component (see Section 3). Once established, this service can be used by multiple workflow and reporting processes. The others occur per-reporting process. To demonstrate the efficacy of this approach, we have provided a case study in Section 4 used for generation of ocean colour products using a computational pipeline on NCI's supercomputer.
3 NCI's Provenance Capture System
3.1 Provenance data model and architecture
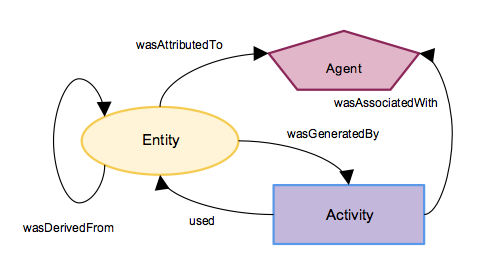
Figure 1: The basic classes and relationships of PROV-DM, drawn in accordance with the PROV Ontology [3].
The basic classes and relationships of PROV-DM are shown in Figure 1. Entities and Agents (things and people/systems) represented in the provenance information always have metadata representations both within and outside the provenance information management system. As such, an ecosystem of services is required. NCI uses a PROMS Server for its provenance information management system, a Persistent Identifier Service, the NCI's Metadata Management System and an off-the-shelf content management system. These are described in the following sections (3.2 and 3.3).
3.2 PROMS Reporting System
The core structure of the NCI provenance capture system is the Provenance Management System (PROMS) [6, 7] which consists of an API and an underlying RDF store. The API is constrained to only accept Reports from registered Reporting Systems and ensure they are conformant both with PROV-O [8] and as well as NCI-specific metadata requirements.
Figure 2 shows a template information model for data processing at the NCI with common examples items found there. Process inputs could be datasets, algorithms, toolkits, software packages, or configuration files. The process is run by a user, or an instrument (such as an X-ray detector), or an automated workflow engine. The output of the process could be an artefact — a report, datasets, images, research articles, or a video. Important metadata about the process being conducted (e.g., timestamp of the operation) are also captured in the provenance store. Information within the provenance store can be potentially tracked in real time so as to capture actions of a user's behavior, such as when a user runs executable code that performs data processing.
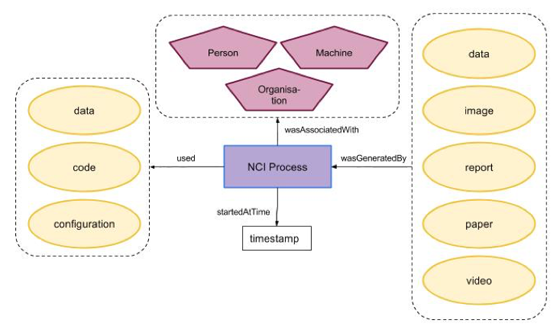
Figure 2: A template information model for data processing, conformant with PROV-O.
The class images are those from Figure 1 and their labels indicate real examples of those class instances found at the NCI.
Figure 3 demonstrates linear and nonlinear data process scenarios. PROMS can capture both very well.
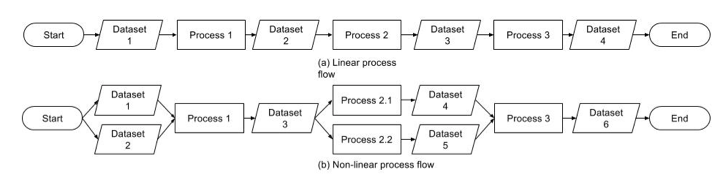
Figure 3: Flowchart of different types of workflows captured by PROMS.
The PROMS Server supports three levels of provenance information reporting, all of which are represented as PROV-O-compliant documents:
- Basic: contains a title, basic process metadata such as a starting and ending time and is mainly used for testing.
- External: a high-level process description, including a listing of the data consumed and produced by a process: the detailed process is described as a black box.
- Internal: provides details of the internal steps and intermediate datasets of a process, as well as the data consumed and produced.
Figure 4 shows a graphical representation of the information in a PROMS External report, as shown in a web page by the PROMS Server. The Entity, Activity and Agent objects are linked to queries so that, when clicked in a web browser, the diagram is dynamically redrawn with the clicked object as the focus. Links for objects with metadata in dataset or agent catalogues lead directly to those representations. The NCI manages persistent link (URI) services, and a series of metadata repositories and content management systems that are the targets of dataset and agent links.
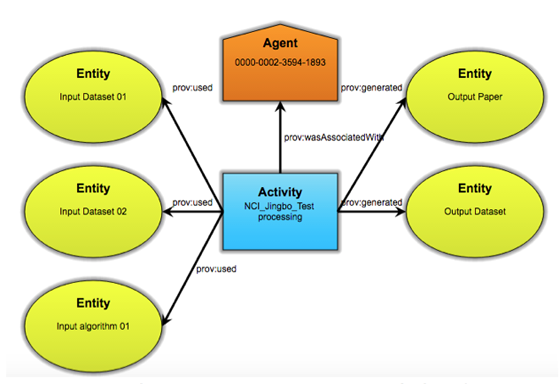
Figure 4: Sample External report displayed on PROMS interface
3.3 Data Management Services
A well-managed, mature data management system is essential for provenance information to be valuable. It becomes almost impossible to confirm that a product was produced with the correct data if that data is not well-managed [9]. NCI uses a number of tools and services as part of its data management infrastructure that are used by the provenance system:
Metadata catalogue. NCI has implemented metadata catalogues in a hierarchical structure so that they are both extensible and scalable. To support collection-level data management, a Data Management Plan (DMP) has been developed to record workflows, procedures, key contacts and responsibilities. The elements of the DMP are recorded in an ISO19115 [10] compliant record that is made available through a catalogue for metadata display and exchange [11]. Figure 5 shows the NCI's catalogue hierarchy. The top-level catalogue hosts collection/dataset level metadata, which can be harvested by other data aggregators. Each project then has a specific instance hosting more granular metadata. The lower-level catalogues are given host names according to the pattern of geoNetwork{NCI-PROJECT-CODE}.nci.org.au (e.g., https://geonetworkrr9.nci.org.au/).
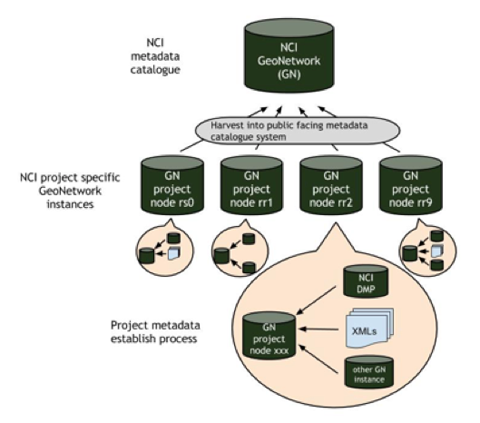
Figure 5: Scalable GeoNetwork infrastructure to support various metadata display and exchange purposes.
Internal Content Repository. Within an Internal PROMS report, many internal datasets, documents, and images will be represented. Most of the time they are not intended for external publication, therefore they are not stored in a product catalogue, nor do they have an NCI product identifier (such as DOI) minted for them. However, in order to preserve complete provenance information, some of these internal items such as documents, are stored in a Content Management System (CMS) and NCI URIs are minted to identify them.
Persistent Identifier Services. The NCI has a Persistent Identifier Service (PID Service) [12] to manage the Uniform Resource Identifier (URI) of the entities. Persistent identifier is an integral part of the semantic web and linked data applications. The service enables a stable reference for persistent identifiers using an approach that intercepts all incoming HTTP requests at the Apache HTTP web server level, passes them through to the PID Service dispatcher servlet which then implements a logic to recognize a pattern of an incoming request, compares it with one of the patterns configured in the PID Service that is stored in a persistent relational data store, and performs a set of user defined actions. The service allows URI tracking through a dedicated interface, database lookups and rule mapping lists. NCI's PID service is configured [13] as a broker to map between original URL and uniformed URI. It applies to catalogue entries, data services endpoints, content management system entries, as well as vocabulary service (see Figure 6).
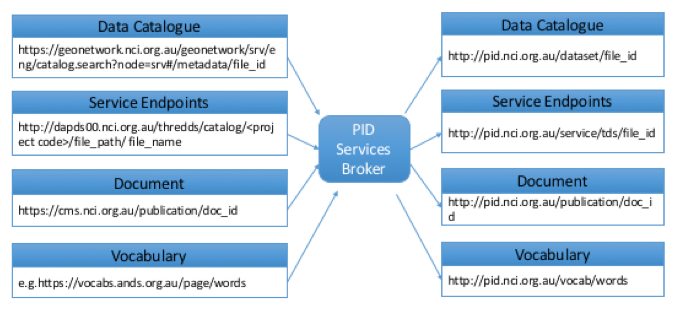
Figure 6: PIDs service infrastructure.
Dataset URIs follow the pattern http://pid.nci.org.au/dataset/{ID}. This URL will map to the individual dataset's catalogue URLs, e.g., https://geonetwork.nci.org.au/geonetwork/srv/eng/catalog.search#/metadata/{ID}. The catalogue {ID}s used are universally unique identifiers (UUID), which means the catalogue entries they identify can be easily moved between different catalogue instances so that the corresponding persistent URI remain the same, with only the redirection mapping needing to be changed. The multiple catalogues' entries are harvested into the PID Service's lookup tables, so the dataset URI mappings can be automatically made. The PID Service uses a dedicated database server to perform mapping lookups. This is a much faster technique for large numbers of mappings than the alternative through Apache or application code [12]. Figure 7 shows the example UUID and PID URI mapping which takes precedence over the URI pattern based mapping. A script has been written to harvest the multiple catalogues' entries into the PID service thus keeping URI redirects always up-to-date.
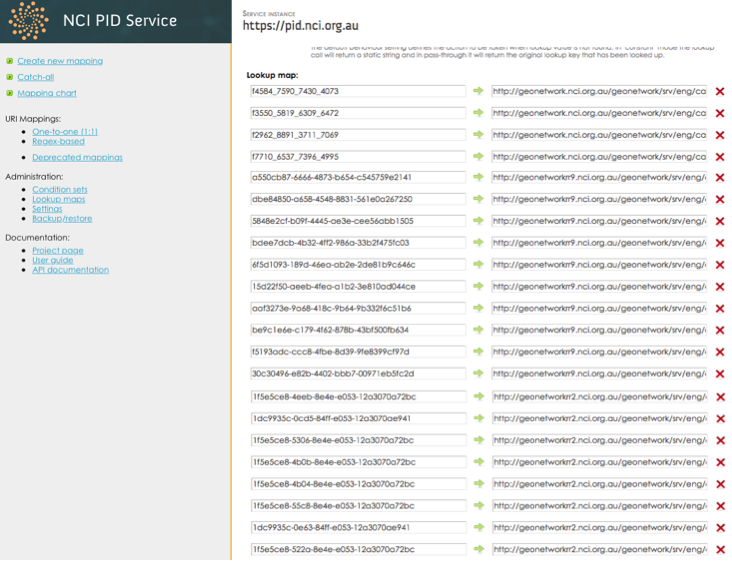
Figure 7: Screenshot of the lookup table when multiple GeoNetwork instances exist.
4 Ocean Colour Data Processing Application
We now provide an example of how a scientific workflow has been recorded using NCI's provenance capture system.
4.1 Overview
Ocean colour observations are multispectral measurements, made from Earth observing satellites, of sunlight reflected from within the surface layer of the ocean. Under particular circumstances the spectral observations can be used to quantify the concentrations and properties of optically active substances in the water. The predominant source of such measurements over the past 14 years has been the Moderate Resolution Imaging Spectroradiometer (MODIS) sensor carried on the NASA/Aqua spacecraft. As part of the eReefs Marine Water Quality monitoring program, the Commonwealth Scientific and Industrial Research Organisation (CSIRO) developed ocean colour algorithms adapted specifically to the environment of the Great Barrier Reef (GBR) region to derive in-water concentrations of chlorophyll-a, sediments and coloured dissolved organic matter from MODIS/Aqua observations. These algorithms, which first compensate for the effects of the atmosphere and then retrieve the in-water concentrations, rely critically upon correctly calibrated satellite observations as input, and use the Australian MODIS time series collection supported by IMOS at the NCI.
4.2 Ocean Colour Workflow
The complete data processing workflow consists of several steps, including preparation of the input data, application of the customised algorithms, and post-processing to facilitate their use by other researchers. These individual steps are enumerated below and shown in Figure 8 (see [14] for a complete description):
- Assembling the data (Level-0 granules);
- Calibration and geolocation (Level-0 to Level-1b);
- Generation of ancillary fields (Level-1b to Level-2);
- Data selection and masking;
- Atmospheric correction;
- In-water inversion (deriving concentrations of optically active substances);
- Regridding (conversion of satellite grids to map projection);
- Mosaicing (joining multiple satellite images to provide more complete coverage);
- Data distribution and access.
Steps 1-3 are part of a separate data processing workflow that precedes the GBR-specific analyses and are not included in the provenance reporting discussion here. For practical processing operational reasons, the provenance modelling groups the remaining steps 4-10 into three stages (see Appendix Figure 1-3).
4.3 Provenance Report
The goal of the provenance reports in this case is to help the user rerun the ocean colour processing workflow. Figure 9 is the screenshot of an External view of a report as shown by the PROMS Server. Users are able to click each entity to drill down and find what datasets/code are available for access.
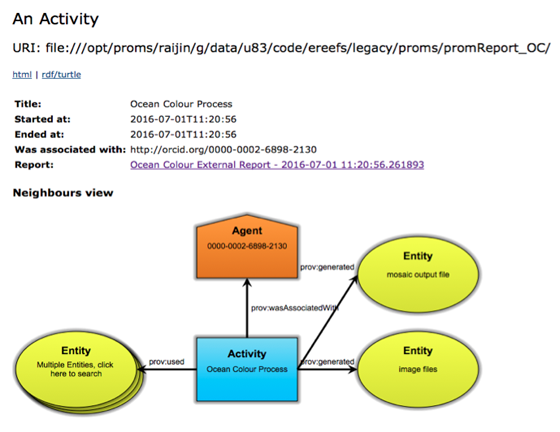
Figure 9: Ocean Colour data process provenance report.
One of the key components in the provenance report is the input entity URIs which uniquely identify the versions (and locations) of processing codes, datasets, and ancillary data so that all the initial information required to re-run the processing can be obtained. For example, the ocean colour processing uses the data that is available through NCI's NERDIP OPeNDAP data service through endpoint URLs that are the input dataset entity's value. The agent is the researcher who ran the process. We use the researcher's ORCID identifier, which provides information about the researcher, such as their publications, institution, role, and other relevant research characteristics. The outputs of the processing are generated and stored at NCI. In this application, the Ocean Colour product as well as the product description are the output entities of the provenance report. The Ocean Colour product dataset is published through the NCI OPeNDAP service. The dataset also has a catalogue entry stored in NCI's metadata repository. In that case, the URI minted using NCI's PID service (see Section 3.3) is used as the dataset catalogue URI. When a user clicks that URI, the user is redirected to NCI's metadata GeoNetwork catalogue. The URI for the ocean color processing code is the URL of CSIRO source code repository.
A list of different types of provenance reports is available from NCI's provenance server. Users can select one that matches the level of process granularity that they are interested in.
4.4 Staff Resource Effort
The staff resources needed to establish the Ocean Colour reporting indicated in Section 2 were:
- Part-time work over several months to implement the central information services;
- Several days work from three people (an Ocean Colour product owner and modellers) to model the Ocean Colour process as per PROV-O;
- Reorganisation of the Ocean Colour workflow itself for better modularisation within the lifetime of this project which eased modelling;
- A week to implement logging within the Ocean Colour workflow that could be used to establish PROV-O reports from each workflow run;
- A small amount of work for data management, as the Ocean Colour workflow was already using managed NCI storage for inputs and outputs — storage location URIs were able to be used directly; and
- A day or two to schedule reporting to work continuously.
5 Summary and Discussion
Reviewers and users of any research publication that is based on data processing or digital laboratory experiments will need to be able to independently determine how any published results have been calculated. The key is to share the end-to-end workflow with the audience so that the paper is transparent and results are reproducible. NCI has built a comprehensive provenance infrastructure to support transparency of research and to varying levels, reproducibility. The provenance report enables the transparency required by following the PROMS report.
We have demonstrated that our approach is a significant enhancement of that provided in a traditional research paper. We have demonstrated within a real-world example using the Ocean Colour data processing workflow. The overall provenance capture system and its supporting repository management, such as data catalogs and an internal content management system, provides the necessary information ecosystem to support this use-case. We also confirmed how persistent identifier services have increased the inherent robustness of the system by having UUID as the key element, instead of using vulnerable URLs. With all the codes, source data, and configuration information within the system, users are able to see how each dataset was produced. The internal provenance report clearly defines every step of the process.
The next workflow to be implemented at the NCI is a genomics data processing pipeline. While this workflow is completely different to that used for the Ocean Colour process, it will also use the catalogues, data and provenance storage systems described here. Mapping of the genomics workflow to PROV-O has commenced and is proceeding smoothly. This indicates that other systems that require provenance reporting need only concentrate on their system-specific parts of the method outlined in Section 2.
References
| [1] |
Evans, B., Wyborn, L., Pugh, T., Allen, C., Antony, J., Gohar, K., Porter, D., Smillie, J., Trenham, C., Wang, J., Ip, A., and Bell, G., 2015. The NCI High Performance Computing and High Performance Data Platform to Support the Analysis of Petascale Environmental Data Collections. Environmental Software Systems Infrastructures, Services and Applications, (pp. 824-830). 11th IFIP WG 5.11 International Symposium, ISESS 2015 Melbourne, VIC, Australia, March 25–27, 2015. |
| [2] |
Moreau, L., and Missier, P., 2013. PROV-DM: The PROV data model. World Wide Web Consortium Recommendation, 30 April 2013. |
| [3] |
Hartig, O., 2009. Provenance Information in the Web of Data. LDOW, 538. |
| [4] |
Baker, M., 2016. 1,500 scientists lift the lid on reproducibility. Nature, 533, 452-454. |
| [5] |
Belhajjame, K., Zhao, J., Garijo, D., Gamble, M., Hettne, K., Palma, R., Mina, E., Corcho, O., Gómez-Pérez, J.M., Bechhofer, S., Klyne, G., Goble, C., 2015. Using a suite of ontologies for preserving workflow-centric research objects, Web Semantics: Science, Services and Agents on the World Wide Web. https://doi.org/10.1016/j.websem.2015.01.003
|
| [6] |
Car, N., 2013. A method and example system for managing provenance information in a heterogeneous process environment — a provenance architecture containing the Provenance Management System (PROMS). 20th International Congress on Modelling and Simulation, Adelaide, Australia. Adelaide: 20th International Congress on Modelling and Simulation. |
| [7] |
Car, N., 2014. "Inter-agency standardised provenance reporting in Australia". eResearch Australasia Conference, October 27 - 30, 2014, Melbourne Australia. |
| [8] |
Lebo, T., Sahoo, S., and McGuinness, D., 2013. "PROV-O: The PROV Ontology," W3C recommendation, 2013. |
| [9] |
Fitch P., Car, N., and Lemon, D., 2015. Organisational provenance capacity implementation plan: a report for Geoscience Australia. CSIRO. |
| [10] |
ISO (2015). "ISO19115-1:2014. Geographic information — Metadata — Part 1: Fundamentals". Standards document. (Online paywalled). International Organization for Standardization, Geneva. |
| [11] |
Wang, J., Evans, B., Bastrakova, I., Ryder, G., Martin, J., Duursma, D., Gohar, K., Mackey, T., Paget, M., Siddeswara, G., and Wyborn, L., 2014. Large-Scale Data Collection Metadata Management at the National Computation Infrastructure. American Geophysical Union Fall meeting, San Francisco, USA, December 13-17, 2014. |
| [12] |
Golodoniuc, P., 2013. Persistent Identifier Service (PID Service). Wiki web page by the Solid Earth and Environment GRID. |
| [13] |
Wang, J., Car, N., Si, W., Evans, B., and Wyborn, L., 2016. Persistent Identifier Practice for Big Data Management at NCI. eResearch Australasia 2016. |
| [14] |
King, E., Schroeder, T., Brando, V., and Suber, K., 2013. "A Pre-operational System for Satellite Monitoring of Great Barrier Reef Marine Water Quality", Wealth from Oceans Flagship report. |
Appendix
The figures below show the provenance modelling grouped into three stages.
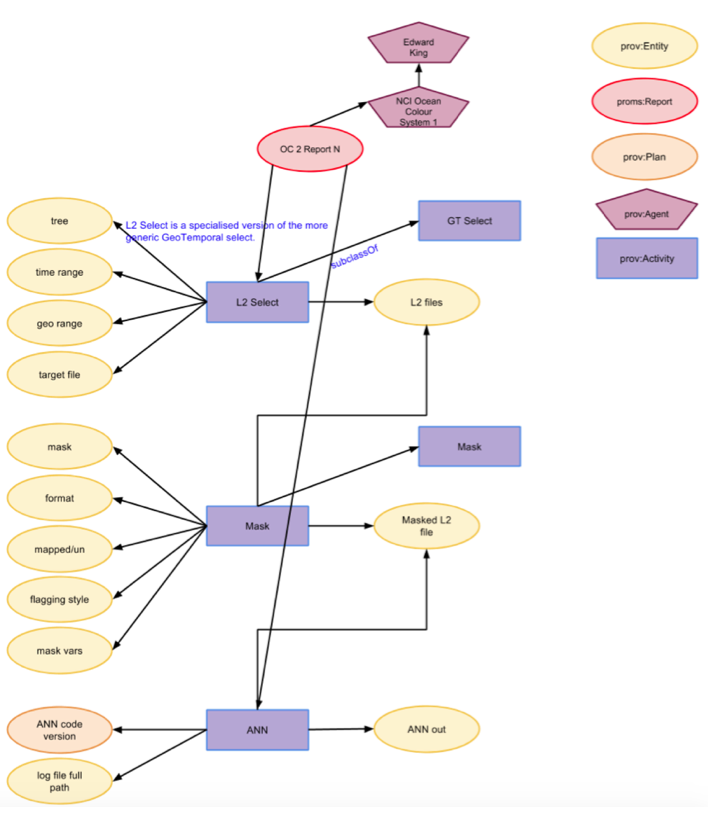
Figure 1: Select the data, apply the mask and run the ANN.
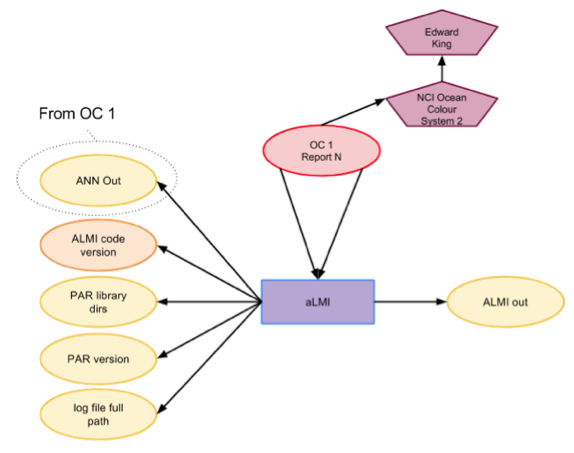
Figure 2: Run the aLMI on the individual outputs of Figure 1.
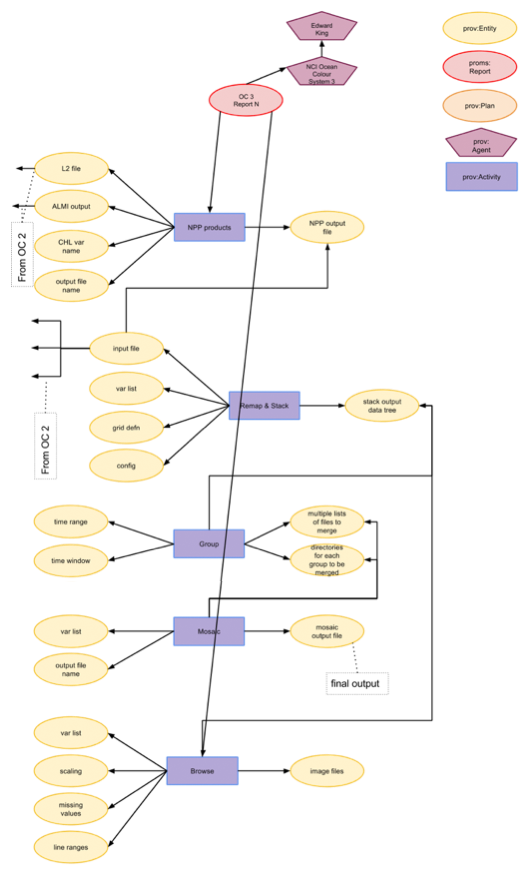
Figure 3: Take ANN outputs and remap and mosaic. There is also an NPP step which maybe should be separate.
About the Authors
Jingbo Wang is the Data Collections Manager at the National Computational Infrastructure where she is leading the migration of data collections onto the RDS (Research Data Service) funded filesystems. Dr. Wang's focus is on building the infrastructure to support data management, data citation, data ingest publishing logistics and provenance capture system. She is also interested in how to provide the best data services to the research community through provenance, graph database, etc., technology. As a geophysicist, she is also working and how to advance the science through interdisciplinary research that combines the HPC/HPD platform with the massive geophysical data collection at NCI.
Nicholas Car is the Data Architect for Geoscience Australia, Australia's geospatial science government agency. He formerly worked as an experimental computer scientist at the CSIRO, building semantic web and other IT systems to manage government and research data. At GA his role is to provide advice to the agency on its data management and systems and to lead the data modelling team. His research interests include information modelling, provenance and the semantic web, all three of which he believes are vital for transparent and reproducible digital science. He is heavily involved with inter-agency and international metadata and Linked Data collaborations including co-chairing the Research Data Alliance's Research Data Provenance Interest Group and as a member of the Australian Government Linked Data Working Group. He is tasked with delivering an internal 'Enterprise Data Model' for GA and its corresponding external (public) representation.
Edward King leads the ocean remote sensing team at CSIRO in Hobart, Tasmania. Dr. King is a specialist in the management and exploitation of large scale remote sensing time series in both terrestrial and marine applications, particularly using the NCI. As a task leader in the multi-institution eReefs partnership, he was responsible for applying regionally tuned optical remote sensing algorithms to a 14-year collection of daily satellite imagery to assess water quality on Australia's Great Barrier Reef.
Ben Evans is the Associate Director of Research, Engagement and Initiatives at the National Computational Infrastructure. Dr. Evans oversees NCI's programs in highly-scalable computing, Data-intensive computing, data management and services, virtual laboratory innovation, and visualization. He has played leading roles in national virtual laboratories such as the Climate and Weather Science Laboratory (CWSLab) and VGL, as well as major international collaborations, such as the Unified Model infrastructure underpinning the ACCESS system for Climate and Weather, Earth Systems Grid Federation (ESGF), EarthCube, the Coupled Model Inter-comparison Project (CMIP), and its support for the Intergovernmental Panel on Climate Change (IPCC).
Lesley Wyborn joined the then BMR in 1972 and for the next 42 years held a variety of science and geoinformatics positions as BMR changed to AGSO then Geoscience Australia. In 2014, Dr. Wyborn joined the ANU and currently has a joint adjunct fellowship with NCI and the Research School of Earth Sciences. She has been involved in many Australian eResearch projects, including the NeCTAR funded Virtual Geophysics Laboratory, the Virtual Hazards, Impacts and Risk Laboratory, and the Provenance Connectivity Projects. She is Deputy Chair of the Australian Academy of Science 'Data for Science Committee'. In 2014 she was awarded the Australian Public Service Medal for her contributions to Geoscience and Geoinformatics, and in 2015, the Geological Society of America, Geoinformatics Division 2015 Outstanding Career Achievement Award.