D-Lib Magazine
January 1998
ISSN 1082-9873
Using Automated Classification for Summarizing and Selecting Heterogeneous Information Sources
![[*]](http://pharos.alexandria.ucsb.edu/icons/foot_motif.gif)
R. Dolin
D. Agrawal
A. El Abbadi
J. Pearlman
Alexandria Digital Library Project
Department of Computer Science
University of California, Santa Barbara
Santa Barbara, California 93106

Introduction
Information retrieval over the Internet increasingly requires the filtering of thousands of heterogeneous information sources. Important sources of information include not only traditional databases with structured data and queries, but also increasing numbers of non-traditional, semi- or unstructured collections such as Web sites, FTP archives, etc. As the number and variability of sources increases, new ways of automatically summarizing, discovering, and selecting collections relevant to a user's query are needed. One such method involves the use of classification schemes, such as the Library of Congress Classification (LCC) [10], within which a collection may be represented based on its content, irrespective of the structure of the actual data or documents. For such a system to be useful in a large-scale distributed environment, it must be easy to use for both collection managers and users. As a result, it must be possible to classify documents automatically within a classification scheme. Furthermore, there must be a straightforward and intuitive interface with which the user may use the scheme to assist in information retrieval (IR).Our work with the Alexandria Digital Library (ADL) Project [1] focuses on geo-referenced information, whether text, maps, aerial photographs, or satellite images. As a result, we have emphasized techniques which work with both text and non-text, such as combined textual and graphical queries, multi-dimensional indexing, and IR methods which are not solely dependent on words or phrases. Part of this work involves locating relevant online sources of information. In particular, we have designed and are currently testing aspects of an architecture, Pharos, which we believe will scale up to
heterogeneous sources [4]. Pharos accommodates heterogeneity in content and format, both among multiple sources as well as within a single source. That is, we consider sources to include Web sites, FTP archives, newsgroups, and full digital libraries; all of these systems can include a wide variety of content and multimedia data formats.
Pharos is based on the use of hierarchical classification schemes. These include not only well-known `subject' (or `concept') based schemes such as the Dewey Decimal System and the LCC, but also, for example, geographic classifications, which might be constructed as layers of smaller and smaller hierarchical longitude/latitude boxes. Pharos is designed to work with sophisticated queries which utilize subjects, geographical locations, temporal specifications, and other types of information domains. The Pharos architecture requires that hierarchically structured collection metadata be extracted so that it can be partitioned in such a way as to greatly enhance scalability [3]. Automated classification is important to Pharos because it allows information sources to extract the requisite collection metadata automatically that must be distributed.
We are currently experimenting with newsgroups as collections. We have built an initial prototype which automatically classifies and summarizes newsgroups within the LCC. (The prototype can be tested below, and more details may be found at http://pharos.alexandria.ucsb.edu/ ). The prototype uses electronic library catalog records as a `training set' and Latent Semantic Indexing (LSI) [5] for IR. We use the training set to build a rich set of classification terminology, and associate these terms with the relevant categories in the LCC. This association between terms and classification categories allows us to relate users' queries to nodes in the LCC so that users can select appropriate query categories. Newsgroups are similarly associated with classification categories. Pharos then matches the categories selected by users to relevant newsgroups. In principle, this approach allows users to exclude newsgroups that might have been selected based on an unintended meaning of a query term, and to include newsgroups with relevant content even though the exact query terms may not have been used. This work is extensible to other types of classification, including geographical, temporal, and image feature.
Before discussing the methodology of the collection summarization and selection, we first present an online demonstration below. The demonstration is not intended to be a complete end-user interface. Rather, it is intended merely to offer a view of the process to suggest the "look and feel" of the prototype. The demo works as follows. First supply it with a few keywords of interest. The system will then use those terms to try to return to you the most relevant subject categories within the LCC. Assuming that the system recognizes any of your terms (it has over 400,000 terms indexed), it will give you a list of 15 LCC categories sorted by relevancy ranking. From there, you have two choices. The first choice, by clicking on the "News" links, is to get a list of newsgroups which the system has identified as relevant to the LCC category you select. The other choice, by clicking on the LCC ID links, is to enter the LCC hierarchy starting at the category of your choice and navigate the tree until you locate the best category for your query. From there, again, you can get a list of newsgroups by clicking on the "News" links. After having shown this demonstration to many people, we would like to suggest that you first give it easier examples before trying to break it. For example, "prostate cancer" (discussed below), "remote sensing", "investment banking", and "gershwin" all work reasonably well.
Methodology
Hierarchical classification is fundamental to the way that Pharos uses metadata for collection summarization and selection. Pharos is dependent on each source's extracting and distributing this information about its collection. For classification to be practical as an aid to distributed source selection, it must be an automated procedure at the source. Since we wanted to show that automated classification could be successfully applied, we processed our collections (i.e., newsgroups) in the same manner that we would expect to happen at individual information sources. Geographical classification within a spatial database, where each item has spatial coordinates associated with it, is straightforward. However, classifying semi- or un-structured digital text within a subject classification is more difficult. Automated text-based subject classification has been shown to be fairly successful, using techniques such as sublanguage terms [11], LSI [7], and inverted term lists [8]. These results indicate that subject-based automated classification is sufficiently accurate to characterize sources for comparison purposes, where even order of magnitude estimates can greatly aid in filtering out most irrelevant sources.In general, automated classification requires several components. First and foremost of these is the collection itself; clearly this must be in a digital form to facilitate content-based classification. The second component is a classification scheme, often a hierarchical tree, which organizes the concepts of a particular information domain. The third is a pre-classified training set of items which the system uses to characterize each node of the classification scheme. This characterization is generally some type of abstract space within which classification nodes are placed. The position of the nodes in this space serves to specify syntactically the semantics of the nodes. For example, such a space may consist of a large dimensional term space where documents are placed based on the term frequencies of their content. The fourth and final component is an information retrieval system.
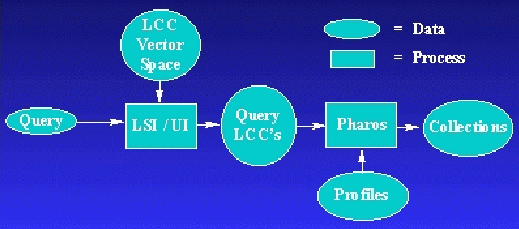
The information retrieval system serves two purposes. First, it actually builds the abstract space via some type of mapping or index structure, and then places the classification nodes as reference points within the space. The second purpose of the information retrieval system is to accept queries as input and return a set of ranked classification nodes as output, where the ranking is determined by the relevancy of the nodes to the query. This is the step which actually classifies new items within the classification scheme. While these components are sufficient to automatically classify a single collection, Pharos additionally requires that a summarization, or profile , of each collection be built so that multiple collections can be compared. This is accomplished by taking the classification results of each item in a collection and aggregating them into the individual collection-wide profile.
For this experiment, we implemented this abstraction as follows. We used 2500 Usenet newsgroups as individual collections, each newsgroup being considered a separate information source,
and used the LCC as the classification scheme. We used newsgroups for several reasons. First, they are an easily available source of thousands of different collections. Second, newsgroups are typically uncontrolled, and their content tends to be based on a distributed consensus; in other words, they are messy, consisting of many unrelated articles, `spams', misspellings, etc. In that sense, newsgroups represent an extreme of digital collection that could be most chaotic. Hence, if we can bring order to this chaos, then it should be easier to deal with more structured digital collections, which are typically administered by a professional (i.e., if we can work with newsgroups, we can work with anything). Third, the name of a newsgroup gives some quick check on the relevance of the returned collections to the users' queries.
For the classification scheme, we chose the top portion of the LCC scheme (the LCC Outline). We use the LCC Outline because it is a wide, multi-topic hierarchy (at least it is reasonably hierarchical among the 4214 nodes in the upper part of the tree that form the Outline). As a training set, we used 1.5 million electronic catalog records from the UCSB library. These records were in "MAchine-Readable Cataloging" (MARC) format. Each of them contains information about a single holding, including its LCC call number (which is the encoding system that embody the LCC), its title, and descriptions of the holding's subject matter. Finally, we used LSI [5] for the IR system, a commonly used IR research tool.
Building an Online LCC OutlineAs previously discussed, we require an online classification scheme in order to classify documents automatically. The LCC contains 21 top-level subject categories, such as "Science", "Law", and "Political Science". Each top-level category is assigned a single letter, such as "Q" for Science. Beneath each of these are sub-categories, usually with a two-letter notation; for example, "Q: Science" includes "QC: Physics", "QE: Geology", and ten others. After the two-letter notation, further differentiation is usually denoted by way of numerical ranges. For example, "QC 221-246" denotes "Acoustics, Sound", while "QC 501-766" denotes "Electricity and Magnetism". This hierarchy continues down many levels.
Once we chose the LCC, we could not find an electronic version of it.
, we describe some of the details of building an online version of the LCC Outline because some of the difficulties of doing so involved the structure of the LCC itself, rather than simply being a result of normal programming problems.
Building an LCC Term Vector SpaceAfter constructing an online version of the LCC Outline, we next needed to construct a relationship between terms and the LCC categories. For example, the category "RJ 1-570: Pediatrics" might be associated with terms such as "children", "hospital", and "measles", while the category "QA 75.5-76.95: Electronic Computers, Computer Science" might be associated with "database", "algorithm", and "cryptography". Although we chose to use a vector space model, which follows closely the techniques used by LSI in TREC [6], any IR system could have been substituted, as explained in Appendix B
Automatically Classifying the NewsgroupsOnce we have constructed the LSI term vector space, we use this data to characterize newsgroups within the LCC and use the resulting collection profile as required by Pharos. Each newsgroup, which is treated as a separate collection, requires its own profile. A profile is compiled by processing the individual news articles within each newsgroup. The articles are passed as queries to LSI, which returns a ranked list of LCC categories. In effect, this procedure treats the document as if it were a query and automatically classifies the query -- or document -- into the LCC. The documents are then compiled into a profile in the form of an LCC tree where each node contains the percentage of articles in that newsgroup associated with that node in the tree. Details and examples of this process are discussed in Appendix C
Once we have built profiles for our newsgroups, we must then allow users to retrieve those newsgroups which are most relevant to their queries. This requires a semantic mechanism that enables users to map their query concepts into the LCC tree. From here, they can decide which nodes in the tree best represent their search criteria. We accomplish this in two ways. The obvious and perhaps most straightforward way is to provide users with an online version of the LCC and allow them to walk up and down the tree until they find the correct node. But as has been pointed out in the literature [5], this is a difficult process for the user. For example, if someone is looking for the subject of prostate cancer, there are relevant nodes in distant parts of the tree. These include not only "surgery" and "internal medicine", both beneath "medicine", but also "immunology" and "anatomy", beneath "science". Thus, using the classification scheme effectively requires a more sophisticated understanding of its structure than most users, particularly casual ones, typically possess. Clearly, a more effective approach is required.
We, therefore, provide a more sophisticated mechanism of searching the LCC, as outlined in Figure 1. We first map the user's query terms into the previously constructed LCC term vector space, and then return to the user those nodes in the tree which receive the highest weighting from LSI. These terms are linked to the online LCC Outline in the interface, allowing the user to then navigate those specific parts of the tree which have shown to be relevant. This component of the UI is similar to the work of Chen [2].
Once the user has selected a node in the LCC tree, we then wish to return an appropriate set of newsgroups. This is the function of Pharos, which in the simplest version used here, linearly ranks the newsgroups based on the returned LSI weightings. We currently do this ranking in three manners. The first is to use the absolute counts of documents among all the profiles. Thus the newsgroups with the largest numbers of articles for the selected node are given the highest weights. However, we find that newsgroups with large numbers of articles tend to dominate this list, even if they are fairly irrelevant overall. So we also weight the newsgroups based on the relative counts. That is, we give the highest weights to those newsgroups which have the largest percentage of their articles contained in the query node. A third, more sophisticated combined weighting algorithm, multiplies the log of the absolute count (plus one) with the relative count. This is one of many possible ways of attempting to return those newsgroups with both large relative and large absolute document counts.
Evaluation
Once we have constructed summaries for each newsgroup, we need to evaluate their use for source selection. As an example of a successful query, we show the result of querying the prototype with the keywords, "prostate cancer". The top ten LCC nodes returned by the system are shown in Table 1 in decreasing order of relevance (as determined by LSI's ranking). In this case, the system was able to match the query terms quite accurately to nodes in the classification tree. These nodes are distributed beneath three main nodes in the tree: "RM: Therapeutics, Pharmacology", "RC: Internal Medicine, Practice of Medicine", and "QR: Microbiology". Upon choosing, for example, "RC 254-282: Neoplasms, Tumors, Oncology (including cancer and carcinogens)" as the query node, the next step is to select the relevant collections.
Table 1: Top Ten LCC Categories Related to `Prostate Cancer' LCC ID LCC Category Description RM 270-282 Serum Therapy, Immunotherapy RC 254-282 Neoplasms, Tumors, Oncology (including cancer and carcinogens) QR 189-189.5 Vaccines QR 201 Pathogenic Micro-Organisms, By Disease, A-Z QR 186 Immune Response QR 186.5-186.6 Antigens RC 633-647.5 Diseases of the Blood and Blood-Forming Organs QR 186.7-186.85 Antibodies, Immunoglobulins QR 180-189.5 Immunology QR 355-502 Virology
The top ten newsgroups selected by sorting on the query node "RC 254-282" are shown in Table 2 in decreasing rank order for each weighting scheme. The majority of newsgroups suggested in this manner are relevant to the query and potentially good sources of information. However, as seen in the list of newsgroups under the absolute weighting scheme, newsgroups such as misc.jobs.offered and rec.sport.pro-wrestling are not highly relevant overall. They are ranked highly because of the large number of articles in the newsgroup, some of which touch on topics related to the query.
Table 2: Top Ten Newsgroups, by Weighting Scheme, for Query Node "RC 254-282: Neoplasms, Tumors, Oncology (including cancer and carcinogens)" Relative Combined Absolute sci.med.diseases.cancer sci.med.diseases.cancer sci.med sci.med.immunology sci.med misc.jobs.offered sci.med.prostate.cancer sci.med.pharmacy sci.med.diseases.lyme sci.med.aids sci.med.diseases.lyme sci.med.nutrition sci.med.diseases.hepatitis misc.health.alternative sci.med.pharmacy misc.health.aids misc.health.aids sci.med.diseases.cancer sci.med.prostate.prostatitis sci.med.diseases.hepatitis rec.pets.dogs.health sci.med.laboratory sci.med.prostate.prostatitis misc.health.alternative sci.med.diseases.als sci.med.aids rec.arts.comics.marketplace sci.med.pharmacy sci.med.cardiology rec.sport.pro-wrestling
We presented the "prostate cancer" query to show how the system can retrieve collections successfully. Not surprisingly though, the query results are not always so useful. Therefore, we present the most common limitations of the system using the following four examples. We also discuss the causes of the problems and their possible solutions.
Windsurfing: Limits in the Classification Scheme
Suppose, instead, a user is attempting to find newsgroups related to windsurfing. The query, "windsurfing", returns with the top-ranked LCC node "GV 770.3-840: Water Sports: Canoeing, Sailing, Yachting, etc.", which seems appropriate. However, in the lists of newsgroups suggested for this node, rec.windsurfing is ranked at most 96 (using the relative weighting scheme). In fact, this node is the top one within which this newsgroup gets classified, implying that our classification scheme is closely associating this newsgroup with this classification node. Even the node "GV 200.6: Water Oriented Recreation" ranks this newsgroup with a maximum of 48 (using the combined weighting scheme). In fact, the only node which ranks this newsgroup among its top ten is "G 540-550: Seafaring Life, Ocean Travel, etc." The problem is that windsurfing gets lost in the more general topic of water-based recreational activities, even though the first two nodes mentioned are both at the bottom of the LCC Outline tree. In other words, these two nodes are as specific in these subjects as the classification scheme gets. This is a problem of a mismatch between the specificity of the query with that of the classification scheme. Using more specialized trees would help (in this case, one that specializes in, say, recreation and leisure activities).
Investment Clubs: Limits in Available Information Sources
In another query, "investment clubs", a user was attempting to locate information about clubs that deal with personal financial investment. The query response included the seemingly appropriate LCC node "HG 179: Personal Finance". However, at the time the query was posed, the "misc" newsgroups had not yet been processed, including, for example, misc.invest, misc.invest.mutual-funds, etc. Clearly the system can do no better than the content of the digital collections available to it. Once these newsgroups had been included, they showed up prominently in the set of suggested newsgroups. It is not clear though that even the investment newsgroups would be appropriate sources for this particular query. In this case, the system is limited by the sources available, and there is nothing that the system can do about it.
Environmental Sciences: Limits in the Training Set
Suppose we want information about "Environmental Sciences", and by traversing the LCC, select "GE 50: History" (of environmental sciences). We find that the newsgroups suggested have little to do with environmental science, but rather more to do with history in general. The reason is that we have no MARC records about this topic, thus the only term associated with this node is "history". As a result, even if there are newsgroups relevant to the history of environmental sciences, we are unable to classify them as such, and therefore unable to retrieve them at query time. A larger or more diverse collection of MARC records would help prevent this problem. We could also include terms from parents and children of nodes for which we have no MARC records.
Jobs: Limits of the Weighting Schemes
One problem that occurs with the selection of newsgroups is that weightings which involve the absolute number of articles tend to be overly dominated by very large newsgroups. The suggested newsgroups are currently presented to the user in three columns, corresponding to the three different weighting schemes being used: relative, absolute, and combined (
). It is apparent after looking over several of the results that one newsgroup completely dominates the absolute weighting: misc.jobs.offered. Even though there are on average approximately 400 articles per newsgroup that we have processed so far, the median is much lower, approximately 100. However, there are over 50,000 articles in misc.jobs.offered, by far the greatest amount of any of the currently processed newsgroups. Another problem is that this newsgroup is fairly heterogeneous, with job listings related to all areas of the classification. As a result, if there is even a slight relevance of a small fraction of these articles to any topic, this newsgroup can receive the highest absolute weighting. In fact, it often has a weighting one or two orders of magnitude higher than the next newsgroup, and therefore would even show up among the best newsgroups based on the combined weighting scheme.
Using a different combined algorithm helps solve the problem. For example, we actually use a minimum relative weighting which is allowed in the combined weighting scheme; thus if a newsgroup does not receive, say, at least a 0.1% relative weighting, it can not be included in the combined weighting scheme. This type of restriction removes misc.jobs.offered from most of the LCC categories under the combined weighting scheme, except for those which have an emphasis in the newsgroup.
While this problem might seem particular to this newsgroup, it is in fact likely to be a common problem among general digital sources of information, where collection sizes vary widely, as do their degree of heterogeneity. This problem will have to be addressed if we hope to direct users and their queries to sources that they will consider useful.
Discussion
Some Perspectives on Automatic Text ClassificationThis technique is equally applicable to any digital text collection, including web sites, file systems, and FTP text archives. It is an interesting search technique which may add precision to many types of searches at web search engines. For example, if integrated into existing search engines, it could provide another avenue into the mass of documents available for retrieval.
Another interesting result of this work is that job postings were classified. As mentioned, the newsgroup with the most articles was misc.jobs.offered, with over 50,000 articles for the two-week period for which we took our snapshot. The classification of this newsgroup indicated what type of jobs were being offered over the Internet during this time period. For example, the four LCC nodes which received the highest weightings in this newsgroup were "HF5546-5548.6: Office Organization and Management", "TS155-194: Production Management", "T58.6-58.62: Management Information Systems", and "QA76.75-76.765: Computer Software". Clearly, these are popular positions in the current (1997) job market. This is a simple method of compiling a rough profile on the current job market. Furthermore, applying IR techniques directly to this newsgroup would assist job searchers in filtering the 50,000 job offers to extract ones which more or less meet their criteria. It is also interesting to note that the top categories of misc.jobs.offered had a very high overlap with the top categories of misc.jobs.resumes.
It is perhaps worth noting that once an association between documents and a classification hierarchy has been made, the UI can be built in any language. There is no reason that the query side and the document side need to be in the same language, since they both get mapped into an intermediate tree structure which is independent of either side. The only requirement is the availability of a training set (e.g. MARC records) in the languages of choice.
Automatic Classification of Non-textual Aspects of Documents
While the TREC and related work focuses on subject-based text retrieval, one could use a gazetteer or time-name table to identify geographic or temporal references within text-based documents in order to classify collections within geographical or temporal classification schemes. In addition, more sophisticated techniques such as those used in GIPSY [15] can be used to extract geographical references from plain text. On the other hand, non-text documents such as maps, aerial photographs, and satellite images are often already cataloged with spatial extents, making geographic classification much simpler. Automatically extracting subject information from maps and images, such as identifying vegetation in a map or a particular object in an image, would allow such documents to be automatically classified within, for example, LCC; such capabilities are ongoing research issues [13]. Yet another application of this technique is the incorporation of image feature vectors [12]. Given a hierarchical feature vector thesaurus, one could automatically classify images in much the same way as we are currently classifying news articles. Although there are several methods of characterizing and classifying image features (textures, colors, shapes, etc.), the Pharos design is sufficiently general that it can work equally well with any (hierarchical) image classification scheme.
We would also like to experiment with using other fields from the MARC records. For example, we could easily build a mapping from authors' names to subjects. This would allow us to build a more sophisticated UI whereby users could search not only on subject keywords, but also on authors, institutions, etc. However, once the interface has mapped these into the LCC, we obtain the same scalable retrieval mechanism as before. Beyond these extensions, however, we would like to extract the geographical and temporal subfields from within the subject areas of the MARC records. We believe that this information could be used to construct geographical and temporal profiles which would allow the type of extended, multi-profile searching for which Pharos is designed.
AcknowledgementsWe would like to thank Bellcore for the use of LSI and Sue Dumais at Microsoft Research for her help with it. We would also like to thank many of the staff at UCSB and its library for all their help.
Copyright © 1998 R. Dolin, D. Agrawal, A. El Abbadi, J. Pearlman


hdl:cnri.dlib/january98-dolin