|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Donald Beagle |
![]()
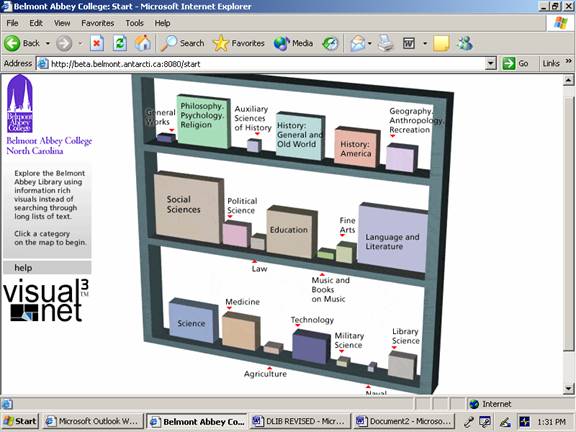
AbstractThe concept of c-space is proposed as a visualization schema relating containers of content to cataloging surrogates and classification structures. Possible applications of keyword vector clusters within c-space could include improved retrieval rates through the use of captioning within visual hierarchies, tracings of semantic bleeding among subclasses, and access to buried knowledge within subject-neutral publication containers. The Scholastica Project is described as one example, following a tradition of research dating back to the 1980's. Preliminary focus group assessment indicates that this type of classification rendering may offer digital library searchers enriched entry strategies and an expanded range of re-entry vocabularies. This article is based on invited papers presented at the Alliance for Innovation in Science & Technology Information conference, "Evolving Digital Libraries," Santa Fe, NM, October 21-22 2002, and at the NELINET conference, "The Cutting Edge Catalog: Challenging Traditions," Worcester, MA, November 22, 2002. IntroductionThose of us who work in traditional libraries typically assume that our systems of classification: Library of Congress Classification (LCC) and Dewey Decimal Classification (DDC), are descriptive rather than prescriptive. In other words, LCC classes and subclasses approximate natural groupings of texts that reflect an underlying order of knowledge, rather than arbitrary categories prescribed by librarians to facilitate efficient shelving. Philosophical support for this assumption has traditionally been found in a number of places, from the archetypal tree of knowledge, to Aristotelian categories, to the concept of discursive formations proposed by Michel Foucault [1]. Gary P. Radford has elegantly described an encounter with Foucault's discursive formations in the traditional library setting: "Just by looking at the titles on the spines, you can see how the books cluster together...You can identify those books that seem to form the heart of the discursive formation and those books that reside on the margins. Moving along the shelves, you see those books that tend to bleed over into other classifications and that straddle multiple discursive formations. You can physically and sensually experience...those points that feel like state borders or national boundaries, those points where one subject ends and another begins, or those magical places where one subject has morphed into another..." [2] But what happens to this awareness in a digital library? Can discursive formations be represented in cyberspace, perhaps through diagrams in a visualization interface? And would such a schema be helpful to a digital library user? To approach this question, it is worth taking a moment to reconsider what Radford is looking at. First, he looks at titles to see how the books cluster. To illustrate, I scanned one hundred books on the shelves of a college library under subclass HT 101-395, defined by the LCC subclass caption as Urban groups. The City. Urban sociology. Of the first 100 titles in this sequence, fifty included the word "urban" or variants (e.g. "urbanization"). Another thirty-five used the word "city" or variants. These keywords appear to mark their titles as the heart of this discursive formation. The scattering of titles not using "urban" or "city" used related terms such as "town," "community," or in one case "skyscrapers." So we immediately see some empirical correlation between keywords and classification. But we also see a problem with the commonly used search technique of title-keyword. A student interested in urban studies will want to know about this entire subclass, and may wish to browse every title available therein. A title-keyword search on "urban" will retrieve only half of the titles, while a search on "city" will retrieve just over a third. There will be no overlap, since no titles in this sample contain both words. The only place where both words appear in a common string is in the LCC subclass caption, but captions are not typically indexed in library Online Public Access Catalogs (OPACs). In a traditional library, this problem is mitigated when the student goes to the shelf looking for any one of the books and suddenly discovers a much wider selection than the keyword search had led him to expect. But in a digital library, the issue of non-retrieval can be more problematic, as studies have indicated. Micco and Popp reported that, in a study funded partly by the U.S. Department of Education, 65 of 73 unskilled users searching for material on U.S./Soviet foreign relations found some material but never realized they had missed a large percentage of what was in the database [3]. Radford also mentions those books that bleed into other classifications. An example here would be "Living Under Apartheid: Aspects of Urbanization and Social Change in South Africa." The use of "urbanization" in the subtitle validates its HT classification, but this work clearly could also be significant to a researcher whose primary interest is South Africa or apartheid. So this book is bleeding into subclass "DT 1701-2405 South Africa," and more specifically "DT 1757 Apartheid." While this particular title includes searchable keywords that clearly trace the bleeding, many others do not, and lead us (through a gruesome extension of our 'bleeding' metaphor) to the related issue of buried knowledge. We all know that monographs, to a greater extent than journal articles, can contain substantive sections of content related to fields other than those represented in the overall classification, title, or even secondary subject headings, and thus remain undiscovered in traditional library searches. Such instances reveal the potential power of digital libraries. In my own research for an article on the sociotechnical networks of scholarly communication, I used title-keyword and subject-keyword searches across the netlibrary academic e-book collection to retrieve some twenty titles related to the topic of actor-network theory. But then, through a collection-wide full-text keyword search, I uncovered sixty-seven additional texts, including one entitled: "Intellectual Property Rights and the Dissemination of Research Tools in Molecular Biology" [4] Actor-network theory appears nowhere in the book's title, subject headings, or even internal chapter headings, yet serves as a focal point for an insightful discussion called "the data stream perspective" that proved vital to my own research [5]. These examples suggest that some mechanism to relate keyword searching and classification structure in a digital library setting may offer advantages, but may also require new conceptual tools. This leads me to introduce the corollary concept of c-space. As proposed here, c-space would be a construct comprising visual representations of all fields of knowledge or domains of discourse, meant to answer the need for a language-neutral, format-neutral medium through which theories about abstract knowledge and the representation of its various physical manifestations may be articulated and tested. An analogy may be made to the metaphor of "desktop" in computer operating systems. Today it is commonplace to compare the desktops of various OS environments (Windows, Macintosh, Linux). C-space could be viewed as a desktop upon which visual metaphors would help users relate content containers (books, journals, digital texts) to searchable catalog records, metadata surrogates, and classification structures. The concept of c-space originated in a conversation with Isaac Asimov in October 1978. Asimov had come to North Carolina's Research Triangle to deliver the keynote address at the Governor's Conference on Libraries [6]. At that time, several years before the IBM personal computer and more than a decade before the World Wide Web, Asimov's view of the library of the future focused on the potential construction of a vast computerized meta-index to all knowledge, as if indexes in the back of every printed book on the planet could be copied (with entries still coded to their respective sources), cumulated, and sorted into one enormous and constantly growing searchable list [7]. My conversation with Asimov (which began due to the coincidence of our both staying at the Velvet Cloak Inn in Raleigh, and both roaming the lobby at the same moment) centered on speculation about the dynamics of this meta-index, and the insights it might offer researchers into the growth of knowledge. Each entry in the meta-index could be considered a "keyword vector," visualized as lines drawn from each word to a cluster of surrogates representing texts containing that word. Clearly, such vectors would not be evenly distributed. Words like "star," "galaxy," or "telescope" would have many more vectors to texts on astronomy than to texts on biology. The opposite would be true for keywords like "cell," genome," or "microscope." However, books about exobiology, the search for life beyond earth, would presumably show an interesting conflation of those keyword vectors. Even though the meta-index had nothing to do with classification per se, it seemed that an objective measurement of keyword vector clusters across its domain would lead inexorably back to a description of discursive formations. Equally interesting, keyword vector-clusters in a digital library could point to relevant chunks of content otherwise lost within publication containers, such as the data-stream discussion mentioned above. We ended our discussion wondering what the domain of a meta-index might be called, and converged on the term c-space, meant then as a shorthand term for a region that could meaningfully relate content, cataloging, and classification. In the years since, my students have speculatively enlarged it to include communication, cognition, curriculum, and inevitably, cyberspace. As one frames it in ever more general ways, one might view c-space as a visualization umbrella potentially encompassing these and other more specific domains (whether or not they happen to be labeled with words beginning with "c"). For one example, I will turn to a discussion of a specific c-space visualization project now under way at Belmont Abbey College, called Scholastica. The Scholastica ProjectThe Scholastica Project was initiated at Belmont Abbey College in 2001 to explore a possible instantiation of c-space in a real-world setting. Following the lead of Svenonious [8], Chan [9], and other researchers in the 1980's and 1990's (see Appendix A), we wished to 1) include LCC captions as coordinate elements in an online catalog, 2) provide users with browseable visual renderings of the LCC classes and subclasses associated with those captions, 3) display target-surrogates for all library holdings — print and digital — associated with those classes, and 4) provide a keyword search mechanism allowing users to simultaneously query both individual holdings records and LCC captions. This was made possible through the acquisition of VisualNet software from antarcti.ca systems, founded by Tim Bray, better known as one of the co-developers of XML. VisualNet generates a graphical analogue to the conceptual spaces of hierarchical subject fields or categories. These fields can contain nested subfields, which are assembled into diagrammatic maps by the vector graphics rendering capabilities of Internet Explorer, Netscape, and other Web browsers. Across the field and subfield sections of its maps, VisualNet can distribute arrays of coded targets corresponding to entries in an associated XML-formatted database. The user can click the targets to retrieve bibliographic records, free-text records, or digital content files. Targets are coded to represent varietal elements of multi-format collections, so that the user can distinguish among print books, e-books, websites and media files, yet also browse them as though they were all shelved together in LC classification order [10]. To distinguish our particular project from the general VisualNet product it was based on, we designated it "Scholastica." To distinguish Scholastica from the traditional OPAC in the minds of students, we characterized it at first as a "classification browser," emphasizing how students might use it to mouse-click around the entire LCC universe of discourse [11]. Figure 1 shows the current start screen of Scholastica [12]. The main LCC classes are represented as colored fields arrayed on a metaphorical bookshelf. The fields dynamically resize themselves, reflecting the relative size of their constituent holdings. Even this small innovation delighted many faculty and students when it was first introduced.
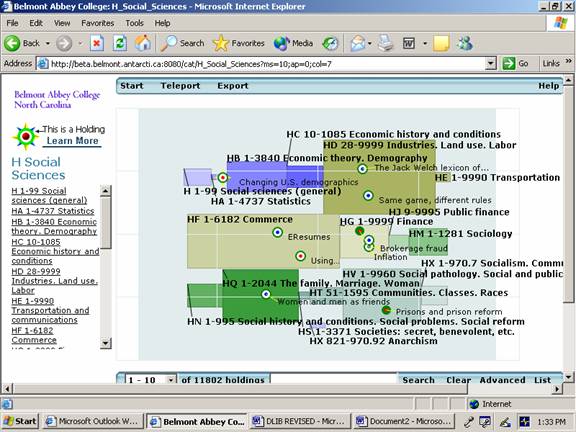
Users can click on any subject field to drill down to more specialized levels of the classification. In Figure 2, the user has clicked on Social Sciences and retrieved the subclasses as an array of fields drawn left-right/top-bottom. Each field is labeled with its LCC call number and caption in boldface type. Scholastica also displays a sampling of targets representing holdings. Red targets are print books, blue are e-books, small globes are websites, projector icons are videos, etc. Mousing over each target retrieves a brief bibliographic summary. Our display currently defaults to 10 sample targets per screen, whether the screen is displaying one subclass or several. A drop-down box on the bottom menubar allows the user to increment the size of this display sample. For our project, we chose to define the sampling based on the criteria of newness. For any display, the first 10, 20, 30, xxx...targets represent the newest 10, 20, 30, xxx... items added to that part of the library collection. In addition, by repeatedly clicking the "next 10" feature, the user can trigger sequential resets of the sampling that reveal successively older layers of the collection (further recalling Foucault's "archaeology of knowledge.") For orientation, the user will also find the LCC call numbers and captions displayed in a traditional top-down list on the left side of the screen.
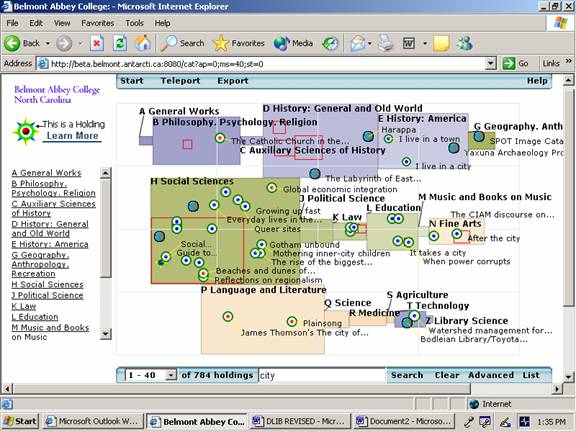
At the bottom of the start screen the user can enter one or more keywords to query the database. Figure 3 shows the result of a search on "city," where one sees:
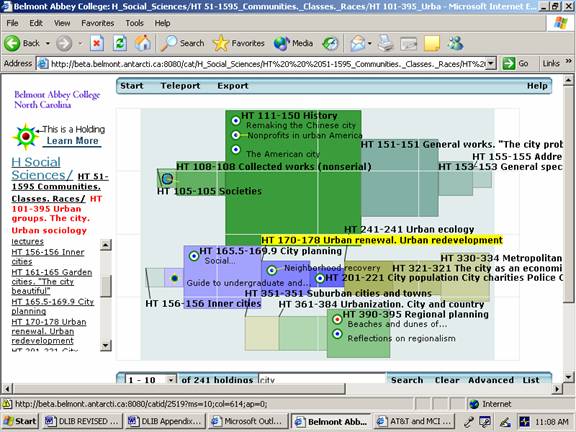
The largest of these red rectangles is found within H Social Sciences, and turns out to be the same subclass example described earlier: H Social Sciences/ HT 51-1595 Communities. Classes. Races./HT 101-395 Urban groups. The city. Urban sociology. Clicking within that red rectangle reveals the display in Figure 4, detailing the internal structure of the HT 101-395 subclass, with the usual initial sampling of 10 of the 245 holdings. However, these 245 holdings are now not restricted to specific target records containing the word "city." The assumption here is that a student searching for "city" might be interested in any book found under "city" in a subclass caption, whether or not that book itself contains the keyword in its bibliographic record. To demonstrate this, one can click down another level into subclass HT 170-178 Urban renewal. Urban redevelopment (highlighted in yellow in Figure 4) where one finds three e-books and two print books on urban renewal, with records similar to the following: Call No: HT177.C5 The key point here is that the word "city" appears nowhere in the full bibliographic records for any of these books. In a traditional OPAC keyword search on "city" this entire subclass, and all of its holdings, simply falls through the cracks. But in Scholastica the entire subclass is not only retrieved with all of its holdings, but is actually highlighted as a relevant discursive formation by virtue of its placement within a red rectangle. Note also, in Figure 4, that the subclass caption containing that keyword is highlighted in a red font on the left side of the display.
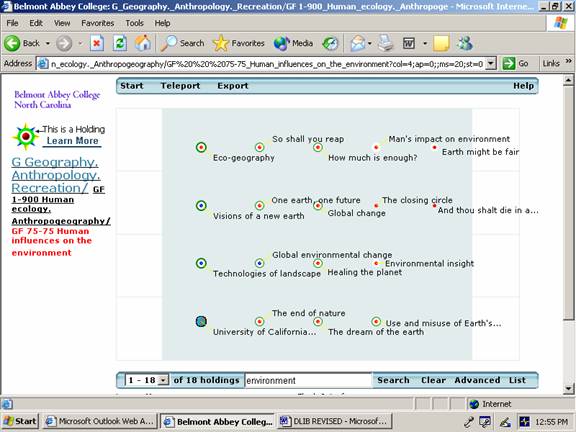
AssessmentWhile this brief overview has described only a few of Scholastica's interesting features, it is sufficient to provide context for the initial round of student focus group assessment. Forty students were given identical questionnaires structured around a keyword search on the term "environment." This extremely general search term was deliberately chosen to see how well students could navigate the multidisciplinary displays they would retrieve. For context, they were told to imagine themselves as majors within the new college concentration of "environmental science" within the Biology Department. Twenty students executed the search on Scholastica, twenty others on a traditional web-based OPAC. The questions were designed to elicit student discovery of both enriched vocabulary and expanded range of strategy, the two issues stressed by the earlier research articles described in Appendix A. Our findings, while preliminary, appear to support the predictions of Svenonious and Chan. Students searching the traditional OPAC retrieved a typical browse list of summary title information, and were asked describe what strategies they would likely use for the continuation of their search. They averaged two strategies: Strategy 1. Students extracted or extrapolated additional keywords found in the summary titles of the browse list, which could be used for re-entry searches, Strategy 2. Students clicked into detailed records for one or more specific titles and then identified additional keywords found in subject tracings. When asked to list the keywords thus extracted from these strategies, students averaged three keywords of interest. Students doing the equivalent search on Scholastica described five re-entry strategies: Strategy 1. Students extracted or extrapolated additional key words found in the summary titles. Strategy 2: Students clicked into specific holdings records and selected additional keywords from subject tracings. Strategy 3. Students extracted or extrapolated key words found in LCC captions. Strategy 4. Students clicked on LCC captions to drill down to other hierarchical levels and unearth more holdings targets. Strategy 5. Students clicked on a red outlined rectangle (when one was present) to select a specific subclass associated with a caption containing the keyword. When asked to list the keywords extracted from these strategies, students using Scholastica averaged seven words of interest. Students were then asked to apply one of their chosen strategies and list a follow-up set of keywords found in the second stage search. Two of every five students in the OPAC groups listed longer vocabularies after their second stage search, while four of every five students in the Scholastica group recorded longer vocabulary lists. However, the important question of whether students with a preference for "googling" will proceed on their own to second stage searches (beyond the artificial setting of a focus group) remains unasked and unanswered by this preliminary study. The focus group study also indicated that the keyword-in-caption issue described earlier for "city" was in no sense an isolated case. The keyword search on "environment" drew a red rectangle around GF 75 Human influences on the environment. Only nine of the eighteen holdings in this subclass, shown in Figure 5 as a summary display, featured the word "environment" anywhere in their bibliographic records. Similarly, within another red rectangle for TD 878-894 Special types of environment, one finds thirty-six holdings (all identified by students as highly relevant to their search on "environment") but only fifteen of those titles would have been retrieved by a keyword search on that word in a traditional OPAC. Moreover, the range of subject heading keywords for holdings under these two subclasses [landscape, ecology, nature, pollution, atmospheric, greenhouse, ozone, global, soil, metals, noise] suggests that keyword distribution across multidisciplinary c-space imposes relatively high cognitive overhead on cross-referenced controlled vocabulary search-and-retrieval, and that visual subclass groupings linked to keyword captioning may be more economical [14]. This relates to further theoretical implications discussed in Appendix B.
These findings must be qualified by noting that all 40 students had completed library instructional sessions offered to incoming freshman where they were introduced to the searching features of both the OPAC and Scholastica. We are not willing to exclude any of our students from the college's prescribed exposure to library orientation and information literacy simply to secure subjects for a usability study. However, this also allows me to comment on the unique potential of Scholastica as an instructional tool. We have found that by asking students for declared majors or areas of interest, we can lead them through a visual tour of the relevant sections of knowledge in Scholastica, relating the topical subclasses in a more vividly descriptive way than one could by enumerating the indented headings of an LCC outline. We then use target sampling to help students distinguish the types of books typically found in various subclasses, giving them the same sort of "feel" for collection structure described by Radford. It must also be stated here that while LCC captions add an extremely interesting contextual feature to a keyword-searchable database, they are presently imperfect for this role, even in a visualization matrix. Had they been originally developed for this function, one can imagine them developing into a powerful linguistic mapping scheme [15]. However, of all the technical apparatus of the cataloging and classification process, the LCC captions would probably be the easiest to revise and refine. This is true partly because caption revision could leave existing call number notation intact and associated book sequencing unchanged, and partly because existing captions are not entrenched elements of today's OPACs. A coordinated effort to improve captioning could lead to a richly textured semantic net capable of displaying keyword vector clusters in more sophisticated and powerful ways than today seen in Scholastica. Print book classification, for example, has been constrained by the need to shelve each volume in a unique classificatory niche. But c-space can accommodate multidimensional classification with differentiated targeting. "Shadow" targets could be created for titles that straddle multiple discursive formations. The primary target of our earlier example "Living Under Apartheid: Aspects of Urbanization and Social Change in South Africa," could remain under HT 101-395, while also casting a shadow target under DT 1701-2405 South Africa. And in a digital library setting where data could be gathered on keyword vectors into actual content containers (rather than just MARC records), one could set a visibility threshold to retrieve and map holdings where the keyword occurs within any section of text more than 5, 10, 20, xxx... times, perhaps in association with other keywords or other content features such as citation patterns. ConclusionThis study makes no assertion, of course, that LCC represents an optimal description of the underlying structure of discursive formations. Some theorists, as noted in Appendix B, dispute the validity of classification per se, while others argue for alternative frameworks. However, LCC does offer researchers the considerable advantage of a huge cumulative experience base, flowing from its current role as a sequencing system for tens of millions of monographs in thousands of libraries. One can certainly attend conferences and speculate about any number of theoretical systems of knowledge organization that might someday replace LCC and DDC. But if one wishes to test any visualization schema in a contemporary academic setting, whether it be a general concept like c-space or a specific instantiation like Scholastica, the case for LCC seems compelling. Similarly, the potential of c-space visualization should not be viewed as being constrained by the current capabilities of VisualNet or any other software product. The history of innovation suggests that we would be well-served by multiple visualization products offering various approaches. Whether the market is sufficiently robust to support competition among multiple vendors at this time is questionable [16]. One series of focus groups cannot justify a claim that c-space visualization should replace traditional OPACs. But our experience with Scholastica suggests that this type of classification browser can serve as a valuable adjunct for instruction and multidisciplinary research, while also securing for the library an XML-formatted database for further research and development. References[1] Foucault, Michel. The Archaeology of Knowledge. Harper & Row, New York, 1976. 245p. [2] Radford, Gary P. "Trapped in Our Own Discursive Formations: Toward an Archaeology of Library and Information Science." Library Quarterly, 73(1) January 2003. p. 3. [3] Micco, Mary and Popp, Rich. "Improving Library Subject Access (ILSA): A Theory of Clustering Based in Classification." Library Hi Tech 45(12:1) 1994. p. 56. [4] Hilgartner, Steven. "Access to Data and Intellectual Property: Scientific Exchange in Genome Research," in Intellectual Property Rights and the Dissemination of Research Tools in Molecular Biology, Washington, D.C. National Academy Press. 1997. p. 30. [5] Beagle, Donald. "The Sociotechnical Networks of Scholarly Communication," Portal: Libraries and the Academy 1(3) October 2001. pp. 441-449. [6] Johnson, Leonard L. "Report from the President: The Governor's Conference on Libraries." North Carolina Libraries 36(3) Fall 1978. p. 1. [7] Asimov, Isaac. "Of Past and Future Libraries." Proceedings of the N.C. Governor's Conference on Libraries, Raleigh: NC. October 19, 1978. [cassette tape]. [8] Svenonious, Elaine. "Use of Classification in Online Retrieval." Library Resources & Technical Services. 27(1) Jan/Mar 1983. pp. 76-80. [9] Chan, Lois Mai. "Library of Congress Classification as an Online Retrieval Tool: Potentials and Limitations." Information Technology & Libraries. September 1986. pp. 181-192. [10] Beagle, Donald. "Visualizing the Digital Commons." The Charleston Advisor. 4(1) July 2002. Available at: <http://www.charlestonco.com/features.cfm?id=95&type=np> [11] Miller, Ron. "Content Management Case Studies," EContent. 26(5) May 2003. p. 24. [12] Scholastica beta site, at <http://beta.belmont.antarcti.ca:8080/start> [13] Dahlberg, Ingetraut. Ontical Structures and Universal Classification. Bangalore: Sarada Rangathanan Endowment for Library Science, 1978. p. 50. [14] Waller, Nicole. "You Are Here: Will Libraries Go to Antarcti.ca to Transform the OPAC?" American Libraries. 33(6), June/July 2002. pp. 72-74. [15] Vizine-Goetz, Diane. "Classification Schemes for Internet Resources Revisited." Journal of Internet Cataloging 5(4) 2002 p. 5. Note: Vizine-Goetz identifies updated captions, new terminology, and more links to other vocabularies as needed improvements to library classification schemes. [16] Walter, Mark. "Making Maps for Browsing the Stacks," Seybold Report. 2(4) May 20, 2002. pp.21-22. Copyright © Donald Beagle |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/june2003-beagle
|