D-Lib Magazine, September 1997
The link to the demo that supports this story has been changed. The correct URL is: www.antiquebooks.net. Change made at the request of the author, March 4, 1998. The Editor

There are many projects underway that seek to digitize rare and precious old books (IBM) and also projects, such as the Gutenberg project, to convert old books to ASCII or machine readable, form. The Universal Library Project has recently experimented with improving viewing fidelity applied to the problem of old books, whether the old books are precious or not. We are also less concerned with the extraction of ASCII text. The idea, instead, is to preserve the pleasures of reading an old book. This is similar in spirit to the common practice of preserving antique furniture and other items even though a particular antique may not be of museum quality. We therefore simply call our result "antique books." Some of our early results can be viewed at "http://www.ul.cs.cmu.edu/antique."
The objective of antique books is to present the pages of the book as they actually appear, discolored pages, pictures and print, in full color, approximating the experience of reading the actual book. Because the Universal Library Project seeks to provide free web viewing of books, the technical problem that we had to address was how to take full color images of book pages and display them, in a highly readable fashion, on the web. We have already addressed the problems of viewing full text on modern books jointly with the National Academy Press.
As with our previous work, our general method has been to take a systemic approach that seeks to appropriately combine sophisticated technology from the disciplines of imaging and man-machine interaction to yield a result uniquely appropriate to the subject matter and the purposes at hand. So, for example, rather than assume that the problem is solved if we can provide a page image in a certain number of kilobytes, we choose to decide the problem is solved if we address what is commonly desired of the antique book by a prospective and eager reader. Indeed, the first books that we have chosen for our site were chosen because they were fun to read.
This user-oriented approach to antique books has fundamentally different requirements from other approaches to digital libraries. For example, the problem of antique books is not at all similar to the problem faced by a librarian. A librarian must be interested in gaining access to the book, not in the reader's experience of it. It is also not at all similar to the problem faced by the archivist who wishes to have views preserved for scholarly research. The present approach is that of a publisher, or re-publisher, who wishes to preserve, as best possible, the intent of the original publisher both in his intent for page layout and in gaining audience. But even though our purposes are distinct from those of librarians and archivists, we also wind up preserving high-resolution, archival quality, scans and also making these books universally accessible on the World Wide Web in electronic form.
Our view is that people will probably lose interest if the experience itself is not engaging. These are old books, after all. The experience that we seek is the experience of viewing the old book itself. We take the position, in the technology for antique books, that part of the enjoyment of reading the text is viewing the pages. In keeping with this theme, our antique books attempt to provide viewing where the reader can easily trade off different grades of viewing fidelity against page display speed, even while reading the book. Furthermore, while our method attempts to retain accuracy in the view, it also attempts to improve the view of the page over the page's actual appearance. As the head of the copy machine department at Canon, Inc., was once heard to say, "a copy must look better than the original for people to like the copy." The trick is to discover a technique that enhances the photographically accurate view without making the view artificial. This obviously has been widely achieved in modern copiers, but, to our knowledge, has never been attempted for "web views" of old book pages.
This article therefore describes the method that we have arrived at after our experimentation and study of appropriate imaging and man-machine technology applied to this new domain we call antique books.
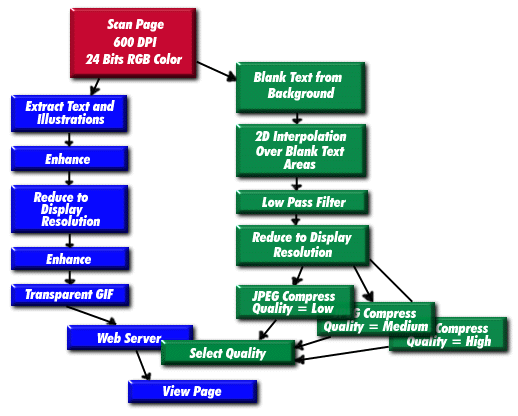
Scanning. Our method begins by scanning or digitally photographing the pages at a resolution of at least 600 dots per inch (about 40 per millimeter) in full 24 bit color. At first glance, this may seem to be higher resolution than is necessary for many old books, but, in fact, even the oldest book printing technologies are capable of routinely generating fine detail. Modern printing technologies, such as Offset and Gravure commonly yield detail that would require scanning at 2400 dots per inch. Furthermore, while 600 dots per inch is usually perfectly sufficient for Letterpress with carved plate engravings, common to most books that are out of copyright, detail on a U.S. dollar bill, Intaglio technology that is almost two centuries old, goes as fine as .001 inch. The rule of thumb, derived from standard signal theory, is to have two pixels spanning the finest distinct feature to be recovered. This implies that a U.S. dollar bill should be imaged at 2000 dots per inch if the objective is to preserve all the fine lines. The fine detail in modern Offset and Gravure can be significant (repeatable) even to .0001 inch in halftones, but, as the name 'halftone' implies, the effective detail by a color camera can usually be captured fully by scanning in the 2400 dot per inch range. In any event, the requirement of this technique is that print detail be fully and clearly captured in the original image with a bias towards oversampling.
Part of the enjoyment of an antique book are the print imperfections. Such imperfections are commonly manifest in excessively fine detail. The features in this case are often smaller than can be intentionally produced through the printing processes. However, we have found that the 600 dots per inch image capture for the letterpress books provides enough visual accuracy to render print imperfections in a satisfactory, if not completely accurate, fashion. This same principle, that some non-focal aspects of the image can be successfully approximated while others need to be highly accurate, also seems to hold for the non-printed components of the image.
Print Separation. Following image capture, the next step is to separately process the 'printed' and 'non-printed' components of the image. The concept is simple. The printed component is characterized by high spatial frequency (fine detail), while the background, paper and defect, component is characterized by no need for high spatial frequency. Since the print is usually black, monochrome, duochrome, or some such, and the paper and defect rich in color, we preserve the background color subtleties without preserving background detail. It is this step that gives the "improved view" quality to the page.
The step is slightly counterintuitive because we do not extract the print from the image and process the result as background. Instead we extract the print from the image, and independently generate a background by blanking print from the image. Independent parameters for the two operations are computed based on generally accepted image processing principles. The reason for this bifurcation is that this independence gives great control over the eventual appearance of the rendering. Furthermore, since the display resolution is several times (more than two times) less than the scan resolution, aliasing artifacts that would be normal to such independent processing will tend to vanish at display resolution (72 dots per inch usually).
Print Enhancement. Rendering the print now follows its own course. First we apply a Laplacian enhancement, then we average down to display resolution, then we apply a Laplacian enhancement to the print at display resolution. A Laplacian enhancement is a standard signal processing technique that simultaneously smoothes and makes edges sharper (it is often called "image sharpening"). A good book describing this and other signal theory-based image processing techniques is Ernest Hall's "Computer Image Processing and Recognition."
The first enhancement tends to cause detail to be preserved through the averaging process while the final enhancement helps remove the "defocussed" look that is common for averaging techniques.
Print Storage. The next element of the print processing is to save the result as a "transparent GIF" file. The GIF format is chosen for the same reason as the JPEG format is chosen later: both are supported default formats for most web browsers. We wanted to create a technique that does not require any "plugins" or other code downloads to a web client, while nevertheless achieving excellent digital compression of the original image. Generally speaking, the original page image is over twenty megabytes, but the processed image, both print and background is around 50 kilobytes (400 to 1 compression is achieved by this technique). Because the technique focuses on achieving display resolution, a higher resolution source (e.g., 2000 dots per inch) will only yield better compression ratios while preserving acceptable visual evidence of detail. As display technology improves to provide higher resolution displays, the effective compression ratios will decrease, but we also expect that Internet bandwidth will also increase, compensating for the discrepancy induced. More important, the fundamental properties of our technique as discussed here should not change until display resolution approximates the scan resolution (viz., is more than half scan resolution).
The GIF format is also chosen for another reason. GIF provides for "transparency" (more generally, a special case of "alpha channels"). The print GIF is actually a transparent GIF in the browser. The transparent part shows through the background.
Non-Print Processing. The background of the page is processed and turned into a true HTML "background" type. The nature of this processing is fundamentally different from the nature of the processing for the print. As shown in the diagram above, the first step is to blank the text areas. This blanking is through an interpolation process on the text areas, which computes a color value based on the distances and colors of the other, non-text pixels in the vicinity. Any number of interpolation strategies will tend to work since the real objective is to preserve background value in the averaging step needed to go to display resolution. We have also found that a "low pass filter" (removing of fine detail) before the averaging step will also help in improving compression performance for the JPEG step after averaging to go to display resolution. The JPEG step is given three alternative "quality" settings (as defined in the JPEG standard) having to do with preserving detail spatially and in subtlety in color. JPEG tends to be supported by all web browsers and tends to yield much better compression of continuous tone (low spatial frequency) image data. Finally, JPEG is a common HTML "background" MIME type.
Once the foreground, print image, and the background, non-print, images are computed, the view can be merged in the browser by the two views. Furthermore, the non-print images can be selected for quality in order to vary the fidelity of the view of the original page.
HTTP and HTML Issues. The only unfortunate problem that we have encountered with this technique is the problem of aligning the foreground and background images in the browser. The HTML specification does not allow the explicit alignment of a background image with an overlaying transparent GIF image. Therefore, for the antique book pages to work, we have found it necessary to ask the person directly the browser and the platform that is being employed in viewing the book (this cannot always be correctly inferred from the information available from standard server queries of the browser). A correction to this problem would be an explicit relative alignment tag in a future version of HTML or a tag-mechanism for defining view coordinate system as is common in computer graphics. Alternatively, browser manufacturers could be more diligent in distinguishing browser name by browser characteristics.
This concludes the presentation of the basic book page appearance technique. A side effect of the print extraction component is that the print can be submitted to standard optical character recognition techniques for creating full text indices of antique books. It should also be mentioned that the description of the essential properties of the technique does not contain implementation specific detail as might be required for dealing with particular scanners, particular implementations of the above image processing techniques, and particular parameterizations needed for particular books.
The "web cover" of the antique book also contains a brief preface to the edition that describes the book content in modern terms. Because this is the web, and because we believe that everybody should be allowed to be a critic, we also provide a method to provide public comments about the book. If the book were truly there for scholarly use, it would make sense to allow the book to be marked up employing a sense of overlay on every page, but since these books are simply to be read and may have questionable scholarly value, we believe the public commenting mechanism to be superior. Finally, when we compute the optical character recognition results in order to compute a word or topic index of the book, we restrict the number of words or topics. This is a typical "publishing" decision made to simplify access to material in the book at the expense of a full concordance.
We have also observed more objectively that it is possible to preserve the full color appearance of an antique book and, in fact, to enhance the appearance, by selectively processing the print and the non-print image. This has the advantage of improved image compression without the need for going beyond standard browser image compression support. It also has the advantage of providing for ready utilization of standard optical character recognition techniques for the purpose of creating full text indexes.
A very interesting counterpoint to the technique we have described, is the 'Adobe Capture' philosophy that says that all the print on a page should be substituted with ASCII text and matching fonts. While the current commercial product for Adobe Capture is not yet perfected in this way, it is interesting to consider a more advanced form of Adobe Capture that allows print imperfections to be rendered by deviation maps. Such a methodology, although technically quite demanding, may well yield much better results, with much better control over page appearance while maintaining reproduction quality.



hdl:cnri.dlib/september97-thibadeau